3D-R1、Scene-R1、SpaceR论文解读
目录
一、3D-R1
1、概述
2、方法
3、实验
4、不足
二、Scene-R1
1、概述
2、方法
3、训练细节
4、实验
三、SpaceR
1、概述
2、方法
3、训练细节与实验
这三篇论文有一些共性均引入了强化学习,采用DeepSeek-R1中的GRPO强化学习框架,通过引入格式奖励、感知奖励、语义奖励等来提升模型在3D复杂场景、视频空间中的推理能力。
但是Scene-R1构建主动视觉定位方法,与主流SOTA并不一致,偏VLA,3D-R1是3D多模态多任务空间推理、视觉问答、视觉定位等问题,SpaceR解决空间时序推理问题。
一、3D-R1
1、概述
动机:现有的3D VLMs在推理和泛化能力上存在局限,主要有两方面,一是高质量空间数据的缺乏,现有的3D-VL相关数据集,虽然提供场景和标注,但是大多为caption信息,没有空间复杂推理的数据。二是静态视角假设,大多数模型依赖固定,预设视角观察3D场景,这与人类通过移动和变换视角去理解环境方式差别很大,限制了模型的泛化能力。
2、方法
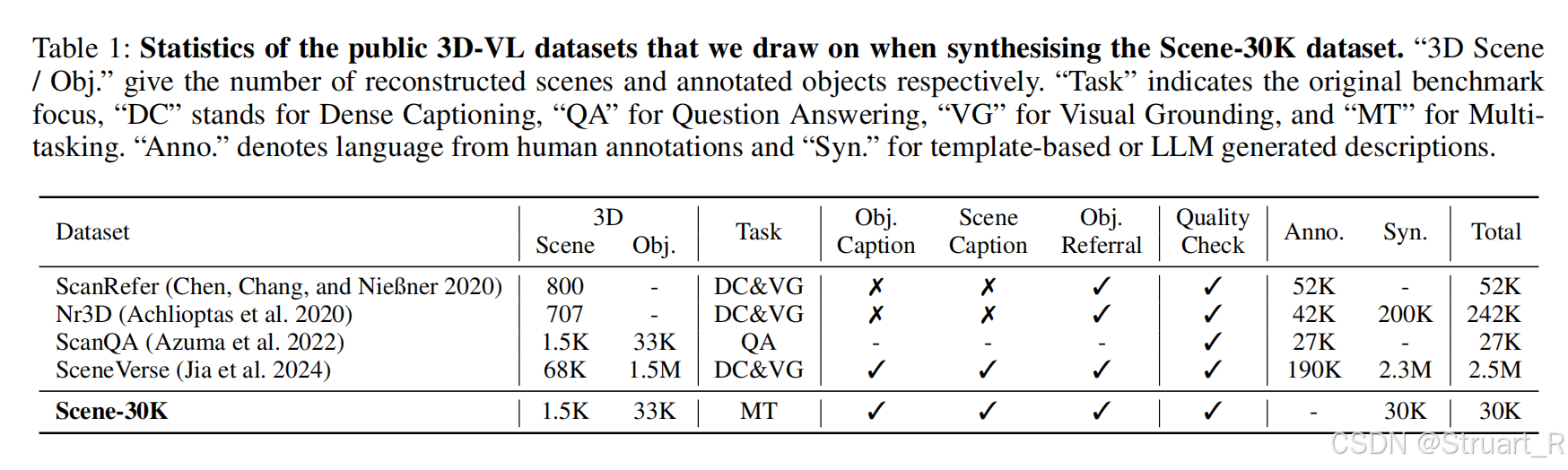
构建Scene-30K高质量CoT合成数据集
首先利用大语言模型(应该是3D-VLM),实现场景点云生成场景描述的数据集这一步已经由前人做过,此时获得了ScanQA,ScanRefer,Nr3D,SceneVerse等数据集,之后通过一串Prompt信息,利用Gemini 2.5Pro模型,基于现有的3D-VL数据集,自动生成包含详细推理步骤的问答对。数据信息如右侧:Question:......,<think>......</think>,<answer>......</answer>。
这种数据集就是Scene-30K数据集,可以清晰教会模型如何逻辑分解和逐步推理,为后续冷启动提供一个基础。
冷启动阶段
冷启动原理:冷启动时一种监督微调的初始化策略,在3D-R1中,使用合成的Scene-30K数据集,对基础模型进行预训练。最终实现格式的规范化和模型的稳定性。推理过程锁定<think>...</think>中,最终答案锁定在<answer>...</answer>
冷启动动机:因为如果直接对3D-R1直接使用强化学习会面临两大问题,推理不连贯性,RL训练初期CoT序列破碎,缺乏逻辑性,与答案严重偏离,只为追求奖励。训练不稳定性,纯RL优化会导致收敛困难,而长期收敛不足模型容易忽略格式约束。
冷启动过程基于Qwen2.5-VL-7B-Instruct主干网络
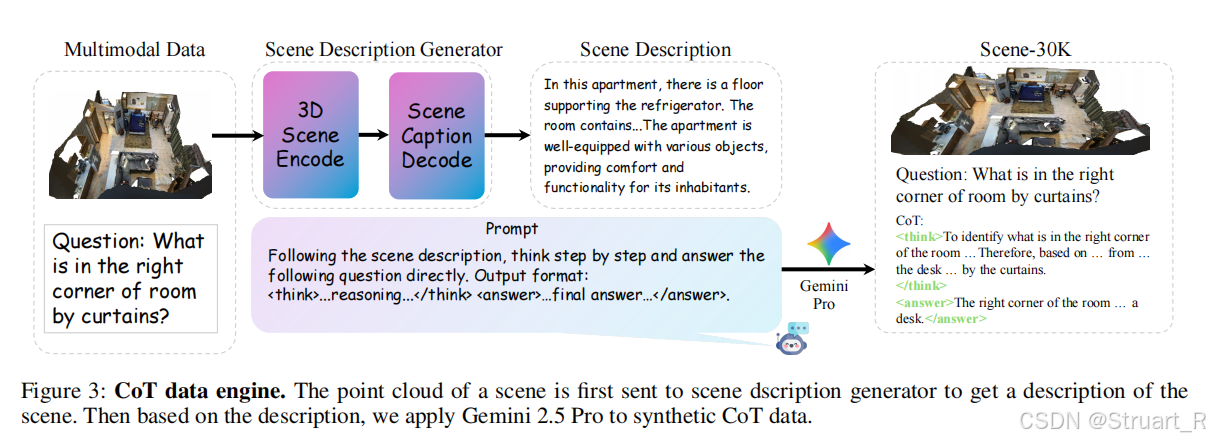
3D-R1主干网络
3D-R1主干网络由四个Encoder,一个VLM,两个Decoder构成。其中四种Encoder分别为text,image,point cloud,depth四个模态。其中点云编码器和深度编码器分别使用PointNet++和Depthanythingv2,点云解码器应该是用的PointNet++实现的,Text解码器仍然用VLM的。
RLHF强化推理
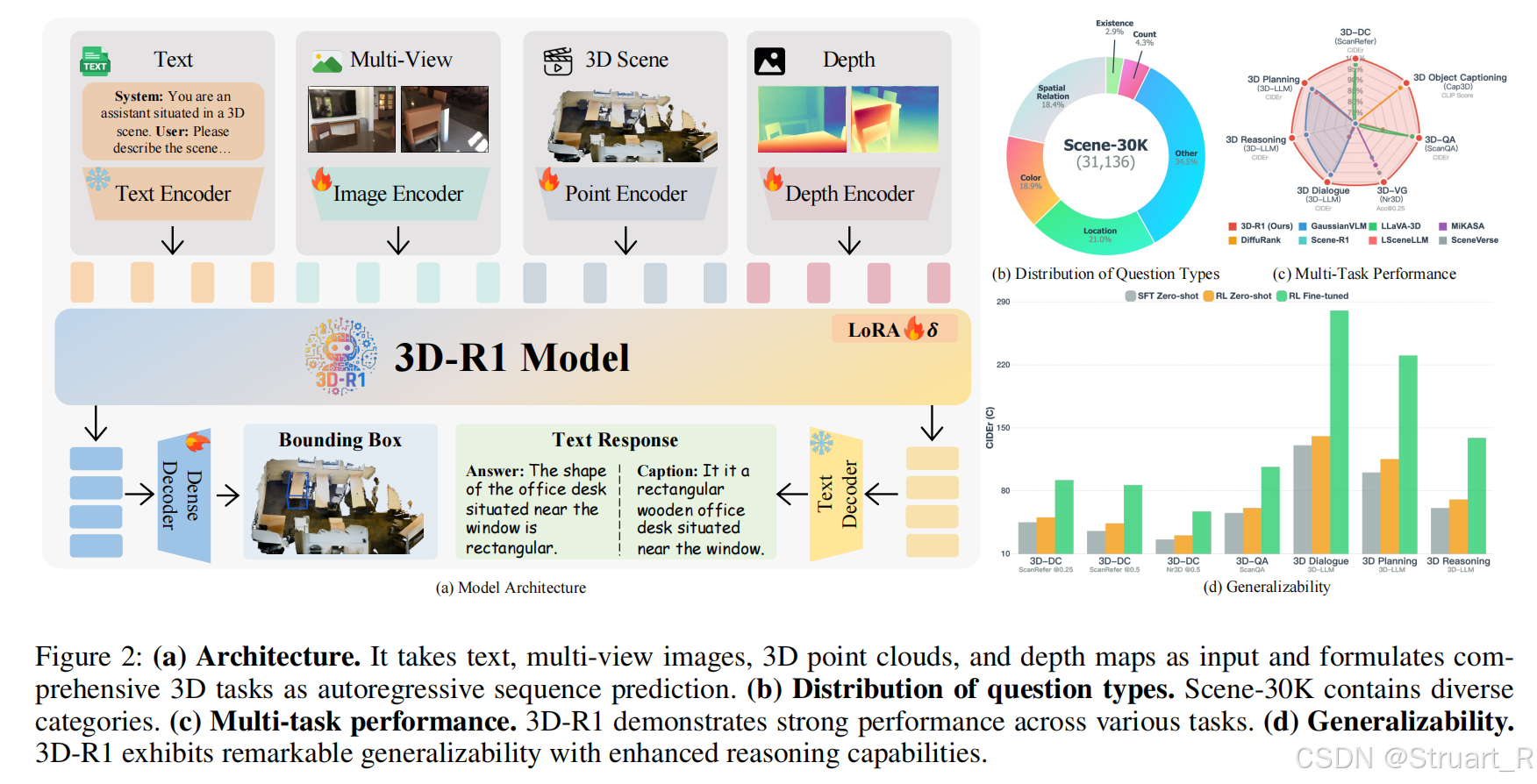
引入感知奖励、语义相似性奖励、格式奖励来实现推理能力增强。其中感知奖励评估模型对3D物体位置定位的准确性,语义奖励评估语义贴近度,格式奖励优化模型格式。看下图的公式即可。现在比较关系,对于感知问题,模型是如何获得准确的物体bbox位置的。
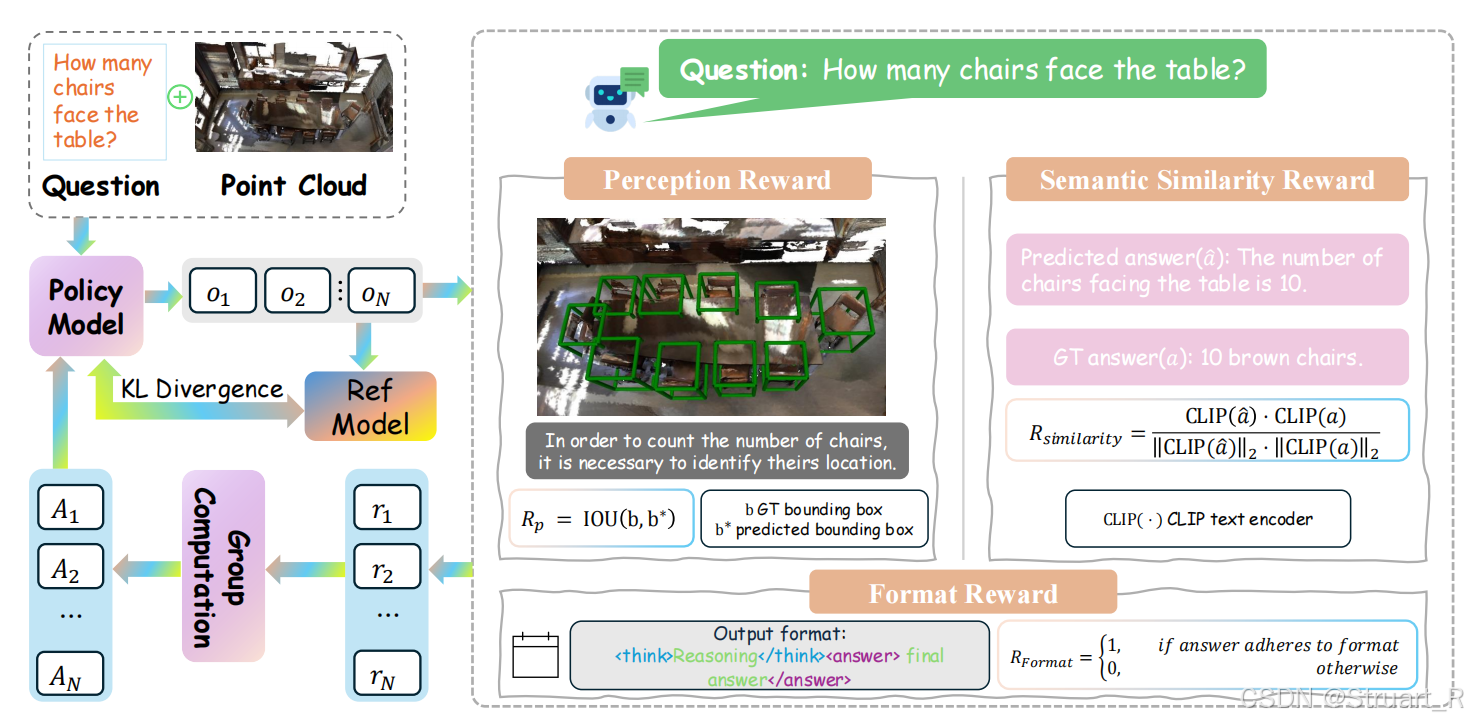
GRPO奖励计算方式与以往一致。
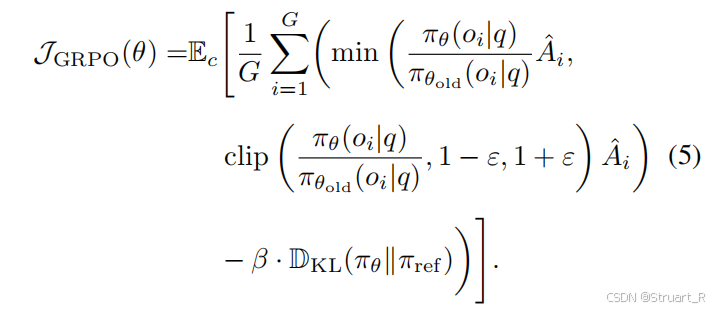
动态视角选择策略
这一部分用于Image的选择上,你可以理解为对于图像编码器的输入,需要输入一组图片,因为我现在有一个场景ply文件,我不能随机渲染一组图片,那样可能有些图片与语义不相关,另外也不能覆盖整个3D场景。所以设计了一个动态视角选择策略,来挑选特定的渲染视图作为输入。
首先对于3D场景点云,先在通过均匀采样或是关键位置采样,得到不同位姿下的渲染视图,(大量),之后基于SigLIP这种预训练视觉编码器提取语义CLIP特征。
然后引入三类互补的评分函数,包括文本到3D对齐,视图到3D覆盖度
,文本和视图跨模态对齐
,公式如下,其中
为文本信息,
为3D点云信息,
为遍历所有待选图像信息中的一个,
为特定的一个渲染视图,
均为特定的encoder。
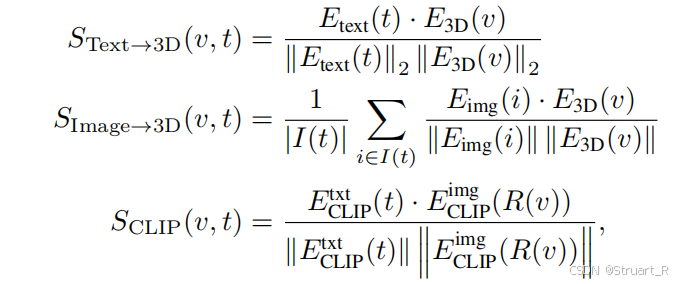
最后设置权重融合三个评分函数,其中,保证视觉信号互补,
独立调控,利用一个L2损失约束
逐步接近目标值。目标函数为:
可以这样理解,动态视角选择的权重优化也是一个模型,一般采用一个定位IoU的模型来计算IoU,并通过定位IoU模型的损失,来优化上述的三个权重,这样这样一个权重训练好了,这个评分函数也就确定了,之后每次丢入一个场景点云,可以获得不同渲染视图下的评分,每一轮取评分最高的K个视图(6个)进入后续的3D-R1下游任务中。
3、实验
实验主要分为3D密集描述,3D物体描述,3D视觉问答,多任务泛化性。
3D密集描述在ScanRefer和Nr3D上进行测试,ScanRefer专注3D密集描述(DC)和3D视觉定位(VG),主要以对象级别上下文感知关系为主,主要描述准确性和定位精度。Nr3D同样支持这两个任务,强调复杂指代表达,包含大量的合成语言末班,需要明确空间约束信息,推理难度较高。
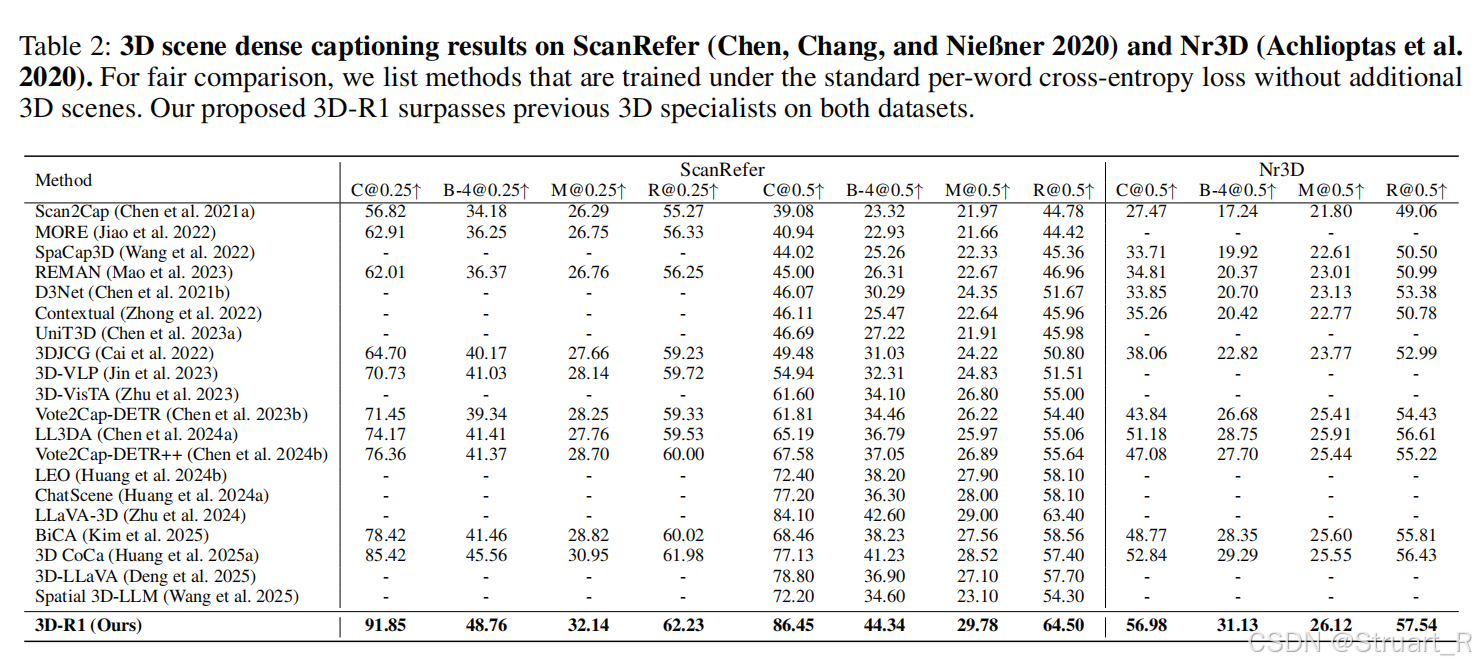
3D问答,主要依赖ScanQA数据集,包含27000组问答对,需要结合空间推理与语义理解信息设计。
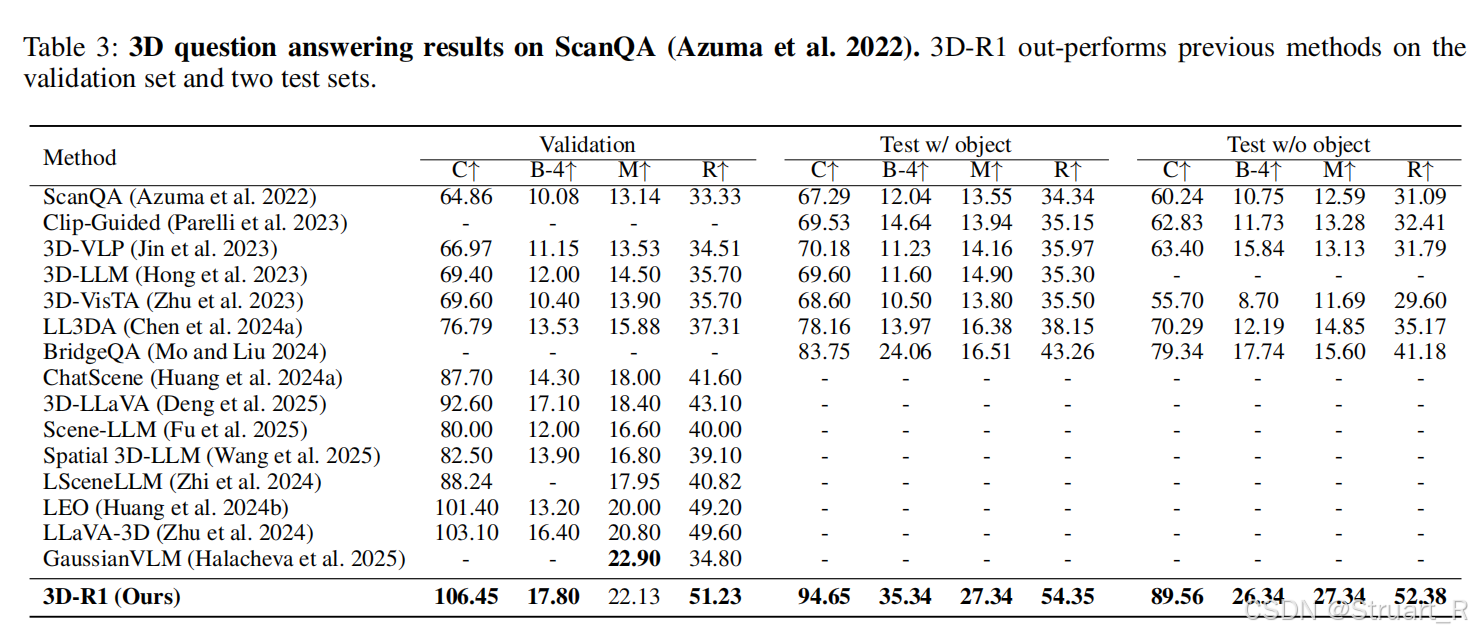
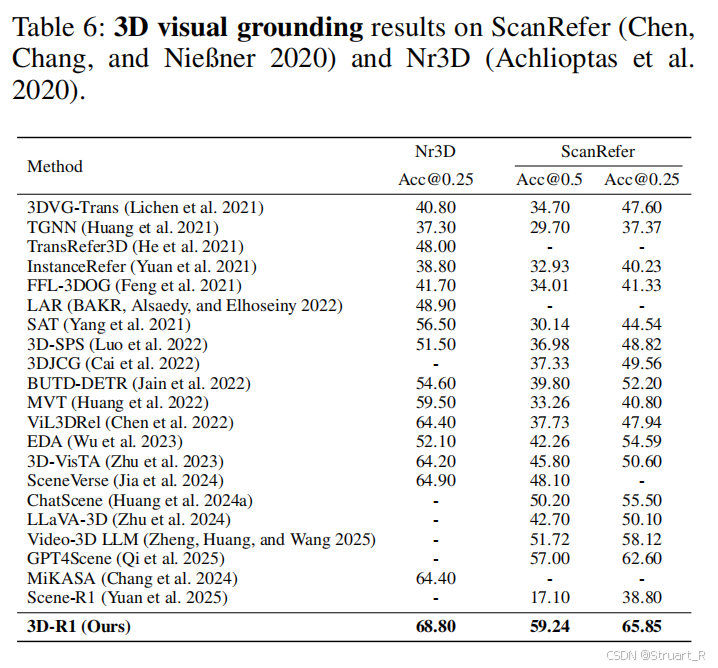
3D物体描述来自于Cap3D数据,基于ShapeNetCore的3D模型库,覆盖55个物体类别,通过DiffuRank方法生成描述。主要是针对单一物体上的描述进行评估。评估指标中,除了以往的正确率,还有幻觉率得分和CLIP相似度。
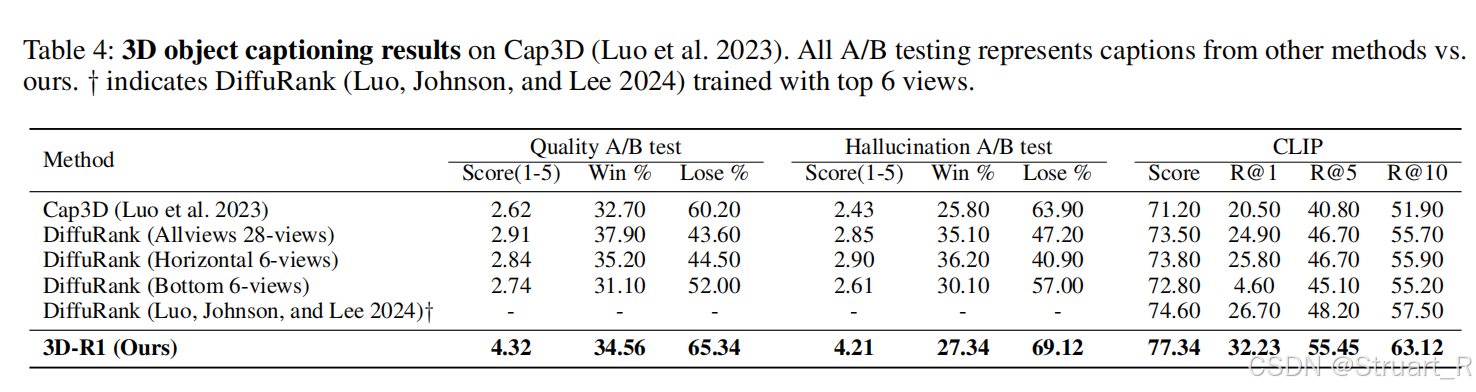
3D对话与规划通过3D-LLM来测试,3D推理通过SQA3D来测试。相较于传统的3DQA而言,3D对话与规划,引入多轮对话机制,分析动态视角中的问题,3D推理需要引入假设性的问题,而非真实存在的问题,比如移动物体,拆门等假设性问题,再去考虑空间约束和时间逻辑。
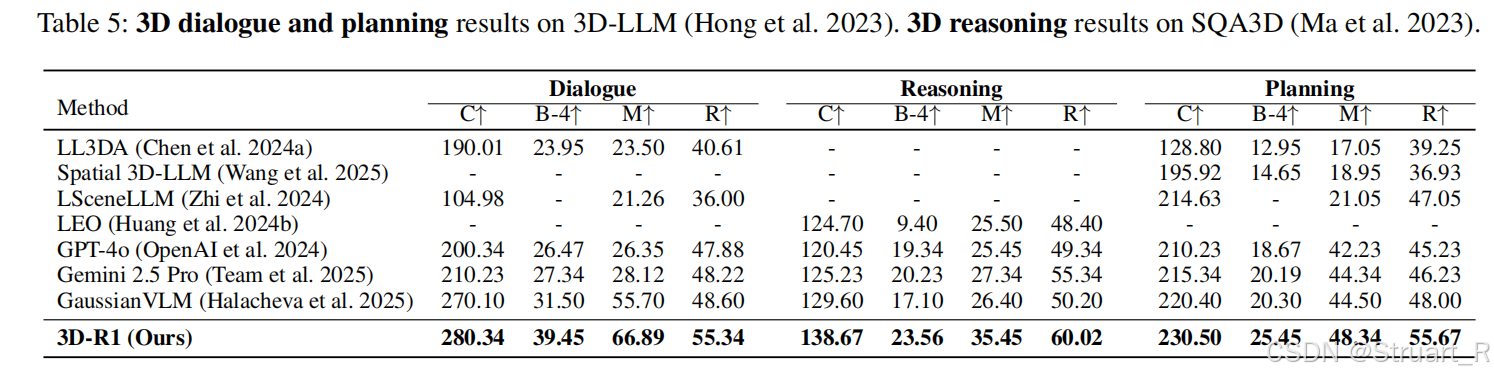
3D视觉定位同样依赖ScaneRefer和Nr3D数据。只考虑物体的准确性问题。
4、不足
(1)基于合成场景分析,未来需要考虑合成场景与真实场景的差异
(2)GRPO学习缺乏时序性
(3)动态视图设计缺乏交互性。
二、Scene-R1
1、概述
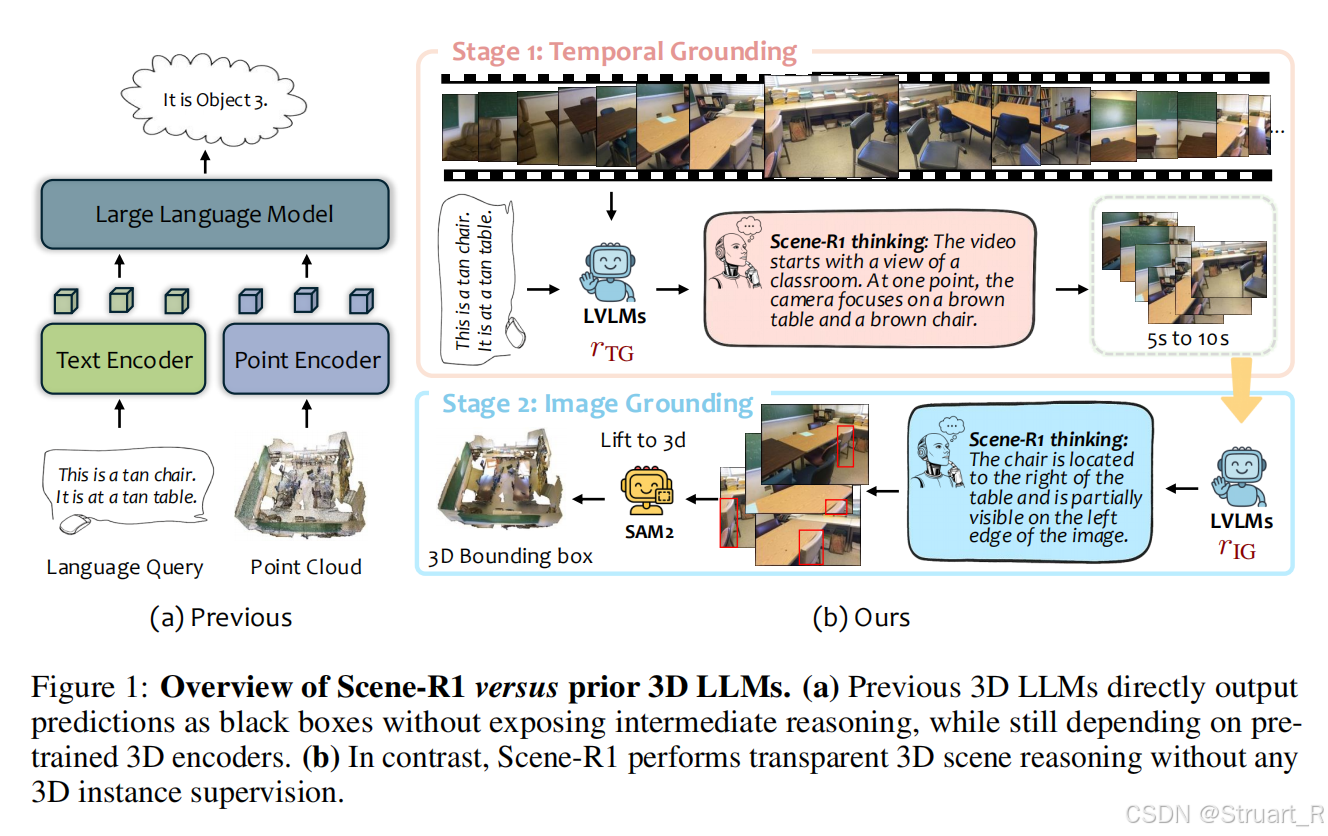
Scene-R1的研究动机,主要是现有3D-LLMs存在两个问题,一个是黑盒问题,模型直接输出3D边界框或文本答案,缺乏中间思维链,导致难以解释和调试。一个是依赖3D标注,需预训练的3D检测器提供准确的标注信息,
2、方法
传统方法依赖3D检测器作为输入,而Scene-R1通过视频时序与空间定位,无需任何点云级标注即可实现透明推理。
Scene-R1采用双阶段定位框架,基于Qwen2.5-VL多模态大模型构建,数据基于RGB-D的ScanNet数据集
阶段一:时序定位,输入RGB-D视频帧序列+自然语言查询,定位目标对象出现的连续时间窗口。比如毛巾位于淋浴区左侧墙壁,梯子在毛巾后方。<answer>15.8 to 20.3</answer>
时序定位奖励计算如下:
先根据预测时间起始,通过固定FPS换算到fps帧上
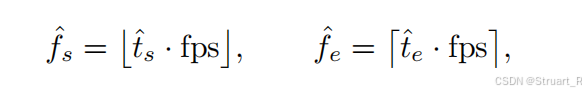
之后定义一个预测时间集合,同样也有一个真实的时间集合
,并计算他两个的时间IoU作为奖励的一部分。
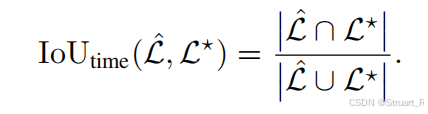
另一部分是格式奖励,同样的要保证输出含有严格的思维链格式,思考过程放在<think>...</think>中,答案包裹在<answer>...</answer>中。
总奖励为:
![]()
阶段二:图像定位,输入阶段1筛选的视频片段,逐帧预测目标对象的2D边界框(JSON格式){"bbox_2d": [x₁, y₁, x₂, y₂], "label": "cabinet"}
这一部分奖励包含三部分,IoU奖励,json奖励,和格式奖励。
对于第帧预测的一个2D bbox,一定有他的坐标
,真实的坐标定义为
,IoU奖励如下:
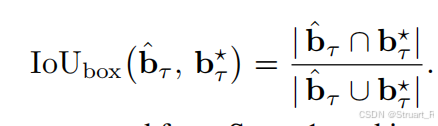
同样的json奖励如果格式完全满足json格式则输出1,否则为0。
![]()
格式奖励与以往相同。
总奖励:
![]()
阶段三:2D到3D升维,用SAM2生成2D像素级掩码,并结合深度图(来自于数据自带的depth)与相机位姿,将掩码反投影至3D空间,并聚合多帧点云生成实例级3D边界框。从而绕过3D检测器,直接利用数据集中自带的RGB-D视频几何信息。
另外也提出用强化学习来实现3D视觉问答的优化,引入了两个3DVQA中任务性能判定的指标EM和EM-R。
EM:评估模型生成答案与标准答案之间的严格一致性,预测答案完全匹配(字符级相同)且格式完全合规时,才计为正确(得1分),否则0分。
EM-R:引导模型生成格式正确且答案精确的输出,采用双阈值惩罚机制,比EM更严格。预测答案完全匹配且格式完全合规时,记为完全正确,得1分;答案错误但格式正确,扣0.5分;格式错误,直接扣1分。
奖励模型如下:
![]()
3、训练细节
Scene-R1数据集采用多源易购数据集联合训练,包括3D定位,推理,视觉问答任务。
数据集
ScanRefer:ScanNet (Kinect传感器),专注3D视觉定位,数据仅需2D框标注,无点云信息
SQA3D:ScanNet渲染视角,专注3D视觉问答,包含问题 答案信息
SceneFun3D:Faro激光扫描,功能推理,包含动作参数与语言描述。
模型架构
主干网络仍是Qwen2.5-VL-7B大模型,输入视觉token和文本token,视觉token中包含RGB帧序列和深度图信息,位姿。
训练过程应该是两阶段,时序定位和图像定位分开训的。
视频数据处理
采样率为2 FPS,保持帧率x像素数小于等于12.8M。视频片段构成为RGB帧,深度图,相机位姿三元组。
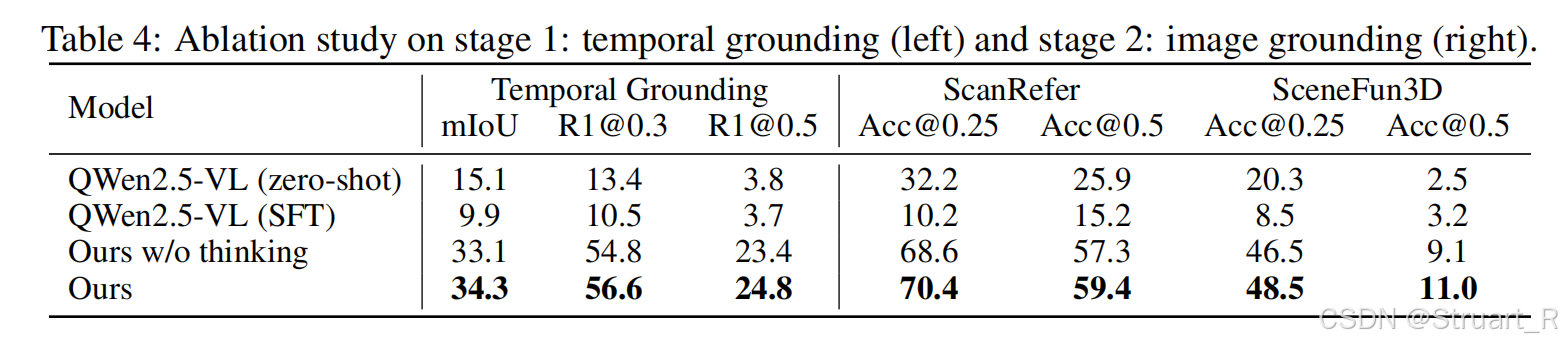
4、实验
这个体现了视觉定位的完整过程,先基于文字描述确定对应文字信息的相关帧(LVLM推理),再通过固定帧信息得到准确的物体bbox位置(LVLM推理),经过SAM2分割得到像素掩码,并反投影到3D点云,最后根据特征匹配将掩码传播到特定相邻帧中,得到3Dbbox框,并把特定相邻帧重建。

任务驱动的主动定位能力,相当于我利用LVLM的推理能力,通过任务驱动,第一阶段确定到我的要求上(回到上一张图的逻辑),之后主动推理出我需要的3Dbbox信息。

这个论文相比于其他论文还是有很大区别的,相当于自己开了一个新的route,然后实现时序上的主动定位。
三、SpaceR
1、概述
SpaceR是在3D-R1和Scene-R1之前出的一篇论文,主要是针对视频空间推理上引入强化学习的初期工作,一方面缺乏高质量数据集,现有数据集未针对空间推理任务进行优化,导致模型训练数据不足,另一方面,传统SFT训练无法实现深度推理,所以引入强化学习和可验证奖励来实现更高的推理性能,提升MLLMs在视频空间推理中的能力。
SpaceR的核心创新包括一个高质量SpaceR-151k数据集,以及加入了地图想象机制和GRPO算法的SG-RLVR训练框架。SpaceR在多个空间推理基准测试中取得了SOTA结果。
2、方法
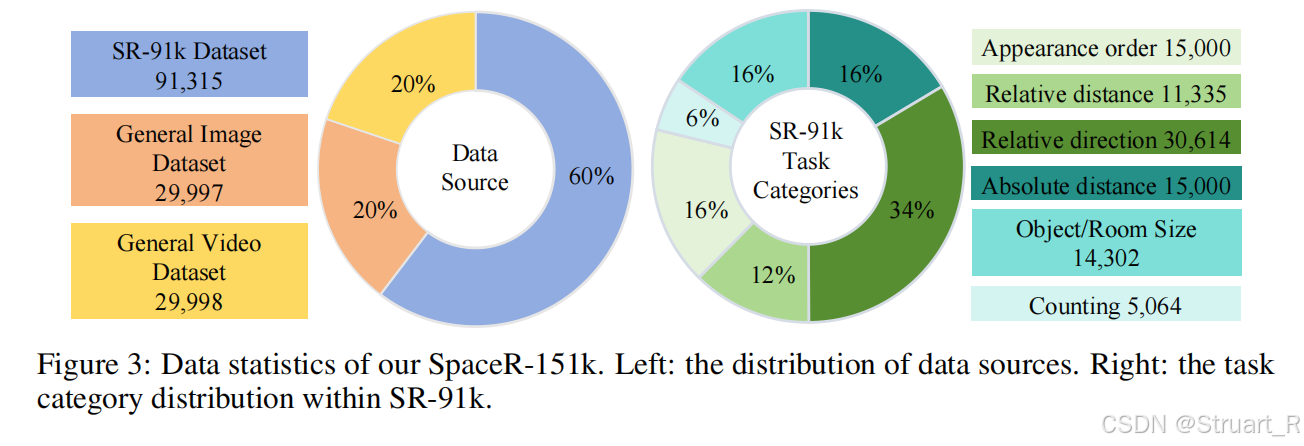
SpaceR-151k数据集
SpaceR-151k数据集是专为视频空间推理任务设计的混合数据集,包含151310个样本,基于3D室内场景重建数据集ScanNet定制的空间推理数据集SR-91k,以及通用多模态理解数据集Video-R1-260k中重采样的6万条问答实例。
具体处理方法如下:
(1)数据收集
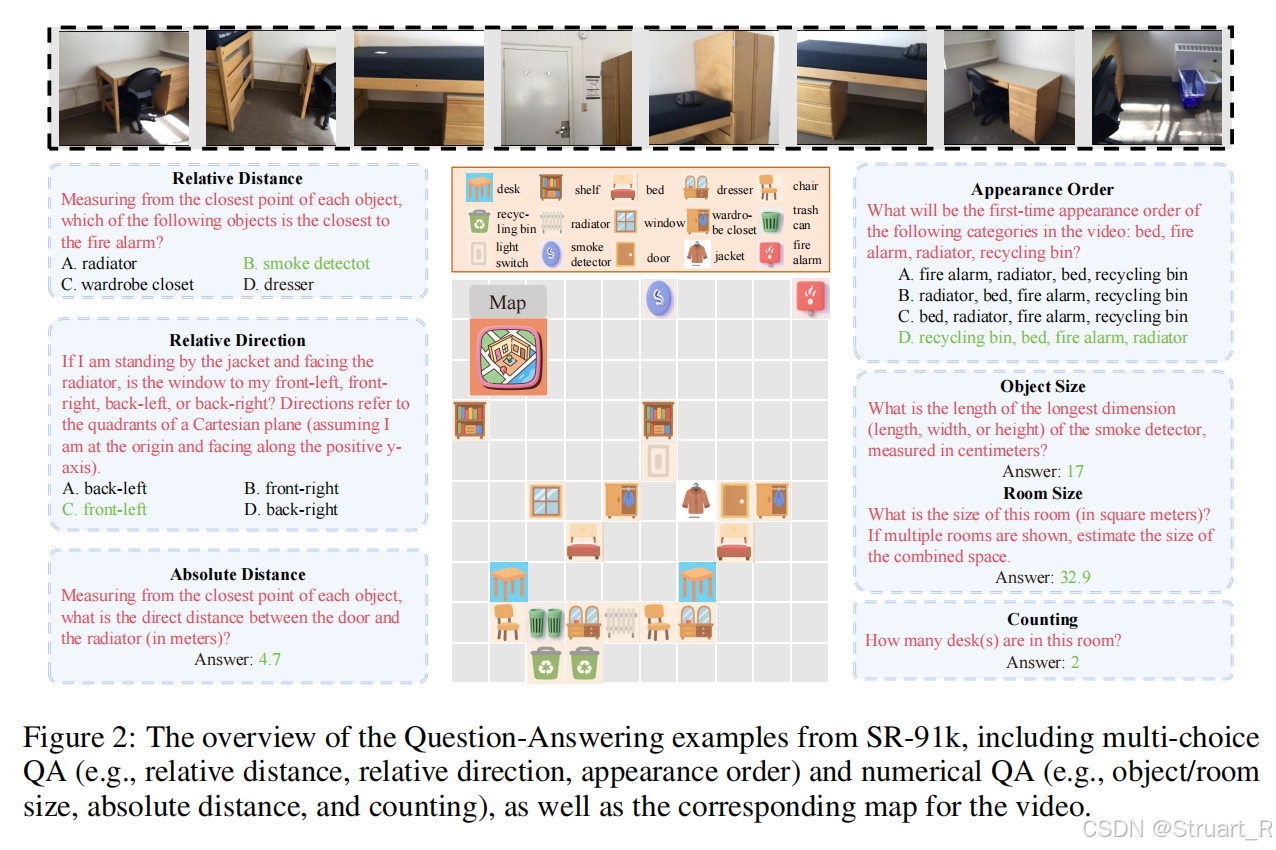
ScanNet数据集,现将原始数据集转换为结构化元信息(物体类别,外观索引,边界框坐标),视频生成将RGB帧重采样为24FPS视频片段,模拟真实视频流。空间地图构创建10x10网格地图,通过物体边界框中心点投影到2D坐标,记录物体分布。示例:<map>{'chair':[[2,3],[5,3],[6,3]],'table':[[3,3]]}<\map>
Video-R1-260k数据集均匀采样6w个QA样本,多选、数值、OCR、自由文本、回归任务,确保通用视频理解能力。
(2)QA生成
基于ScanNet元信息,生成六类空间推理问题,相对距离,相对方向,出现顺序,物体/房间尺寸,绝对距离,计数。
(3)数据过滤
对于ScanNet数据三重过滤策略,场景多样性控制(限制每个视频QA数量,避免单一场景主导数据集),多选QA去偏(随机打乱正确答案的选项位置,消除总选同样比如”C”选项的偏好),数值QA校准(剔除噪声物体,调整数值分布,避免极端偏移,移除与评测基准VSI-Bench重叠视频)。
SG-RLVR框架
SG-RLVR框架基于GRPO的强化学习,我们先不考虑模型的Backbone,因为这个论文主要讨论的是这个强化学习方法。
首先是可验证奖励函数,提出了三种奖励机制,格式奖励,任务奖励,长度奖励。
(1)格式奖励:与以往相同,强制响应结构,思考过程放在<think>...</think>中,答案包裹在<answer>...</answer>中。
(2)任务奖励:分为多选任务
,数值任务
,通用任务奖励
。多选任务答案完全匹配则为1,其他情况为0。数值任务基于相对误差的多阈值评估:
通用任务来自Video-R1论文,包括OCR任务,自由格式
,回归任务
,这三者并行,只会出现一个任务,换句话说任务奖励就是五个奖励并行。OCR任务基于Word错误率(WER)计算,自由格式指标计算真标注与模型输出之间的ROUGE-1,ROUGE-2,ROUGE-L指标上的平均分确定。回归奖励计算响应值与真实值之间的相对距离。
其中在任务奖励中,受到任务的影响,每一个任务下只计算特定的奖励,所以每一个奖励的值域均为[0,1],而且这个奖励会间接影响到地图奖励上。
(3)长度奖励:限制响应长度在中,避免冗长或过简推理。
之后是地图想象机制,也就是对于这个构建好的地图与真实布局之间的误差,如何进行正确的奖励。首先我们知道初始情况生成了一个10x10的室内网格地图,标记物体坐标,作为空间认知的中间表示。
地图奖励:量化生成地图与真实布局之间的误差。其中M=10为网格大小,为预测坐标,
为真实坐标,真实坐标来自于ScanNet元数据。另外设置权重
,受物体数量影响,物体数量越多权重越大,突出高频物体的准确性,地图奖励公式如下:
最后将可验证奖励函数与地图奖励整合,地图奖励只在任务奖励正确的情况下()引入,激励模型深度空间推理,总奖励信息为
。
![]()
后面的强化学习反馈模型严格执行GRPO算法。
3、训练细节与实验
因为这个模型对于框架的依赖不强,最后讨论,这里使用Qwen2.5-VL-7B-Instruct作为模型主干,并给予SpaceR-151k数据集性微调。数据集采用16帧视频,每一帧128x128,并生成8个候选答案。
空间推理和视频理解
benchmark的介绍:
(1)VSI-Bench:专注于视频空间推理,要求模型从视频序列中推断3D空间布局(如物体位置、距离、方向),包含超过5,000个QA对,覆盖288个真实室内场景视频(如家庭、办公室、工厂)。问题类型包括多选和数值回答,例如:"Which object is closest to the stove?"(相对距离)或"Calculate the room size in square meters"(房间尺寸)。
(2)STI-Bench:评估空间与时间联合理解能力,强调真实世界视频中的空间关系(如物体位移、方向)和时间动态(如运动轨迹)。包含8个子任务,其中SR_sub为重点子集,包含6个空间推理任务分别为:
-
Dimensional Measurement(尺寸测量,如物体大小)。
-
Displacement & Path Length(位移与路径长度)。
-
Ego-Centric Orientation(自我中心方向,如"物体在摄像机的左侧还是右侧?")。
-
Spatial Relation(空间关系,如物体相对位置)。
-
Speed & Acceleration(速度与加速度)。
-
Trajectory Description(轨迹描述)。
(3)SPAR-Bench:专门设计用于空间理解评估,从基础感知(如物体检测)到高级推理(如多视图空间整合)。包含7,000+ QA对,分为单视图空间推理和多视图空间重建。
(4)Video-MME:评估通用视频理解能力,覆盖广泛场景(如日常活动、事件描述),不局限于空间推理。包含900个视频和2,700个多选问题(平均每视频3个问题),问题类型包括对象识别、事件描述和简单推理,如"What is the main activity in this video?",作为多模态理解的综合测试床,强调模型对视频内容的整体召回与解释能力。
(5)TempCompass:专注于时间感知能力,要求模型理解视频中的时序动态(如事件顺序、持续时间)。包含410个视频和7,540个问题,涉及时间推理任务,例如:"Did event A happen before or after event B?",量化模型对时间动态的建模能力,补充空间推理基准的不足。
(6)LongVideoBench:评估长上下文视频理解,处理长达1小时的视频,涉及跨片段信息整合。包含6,678个多选问题,覆盖多样主题(如纪录片、演讲),需模型记忆和关联远距离内容。
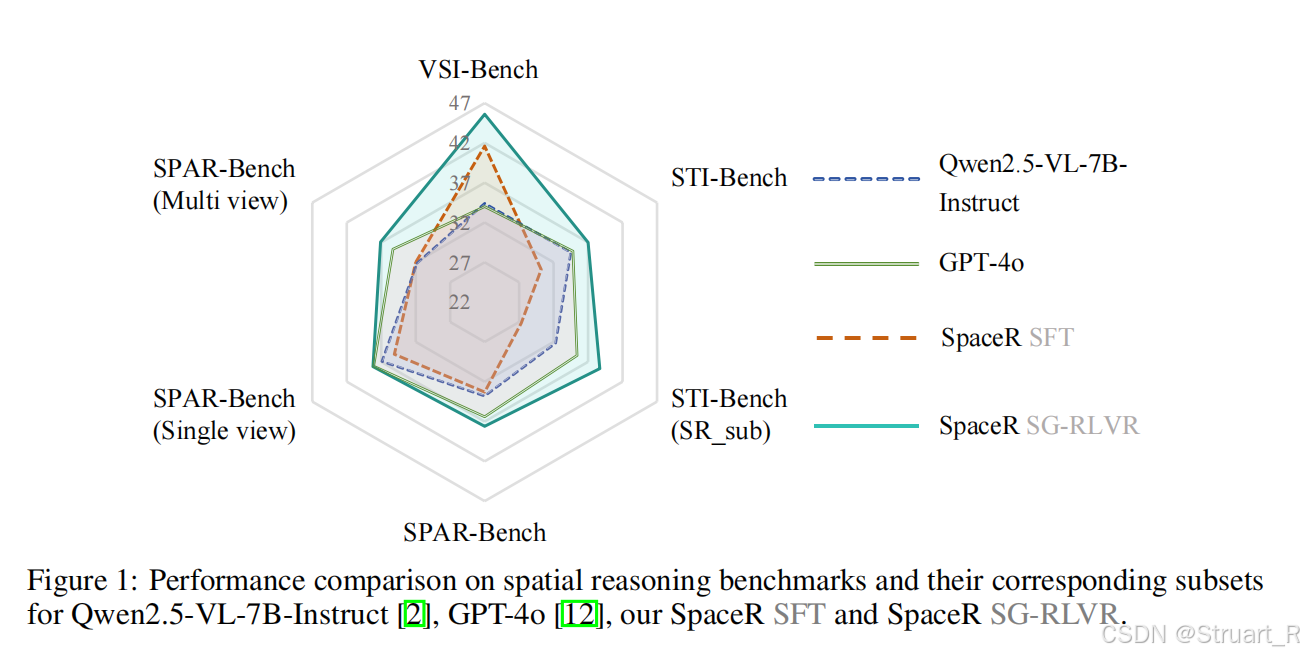
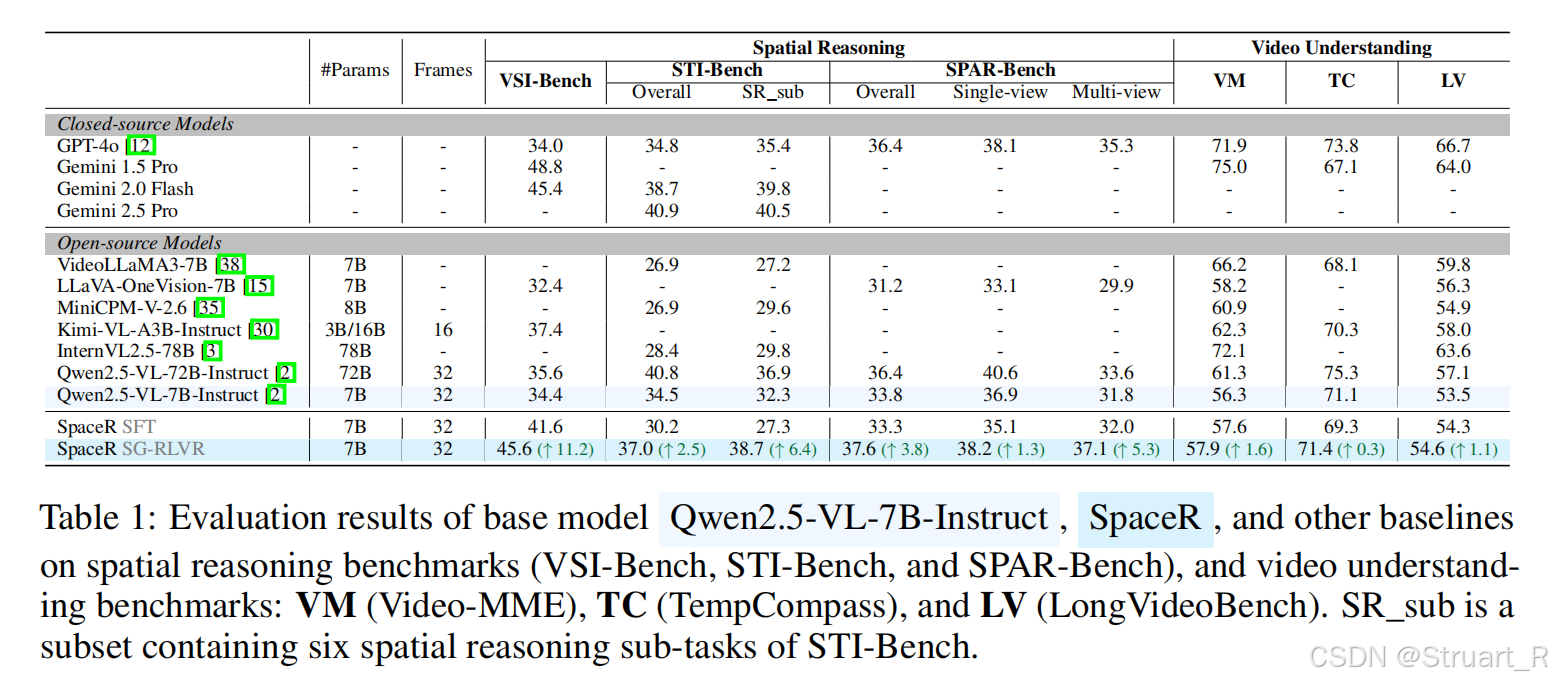
Spatial reasoning相关benchmark下,远超过Qwen2.5-VL-7B-Instruct的基准模型,并且超过SFT训练下的SpaceR。Video Understanding相关benchmark中没有体现出具体的优势,甚至略有下降。但是目的是为了保证模型没有严重的下降对于时序,长上下文信息的通用性。所有基准均采用多选或数值QA格式,保证可以验证强化学习的奖励计算。
数据采样的影响
在SpaceR中提到了一个数据采样的问题,主要是通过随机采样降低数据集使用,以及防止一些困难样本而导致训练不稳定。
这里面针对SR-91k数据集中利用Qwen2.5-VL-7B-Instruct先生成8个候选,测试是否基准模型可以实现空间推理,对于学习价值低(8个全对),标注噪声大(8个全错)的进行删除,保留那些在当前Qwen2.5下模型表现不稳定的样本,并使其覆盖六类空间任务,避免类别偏差。
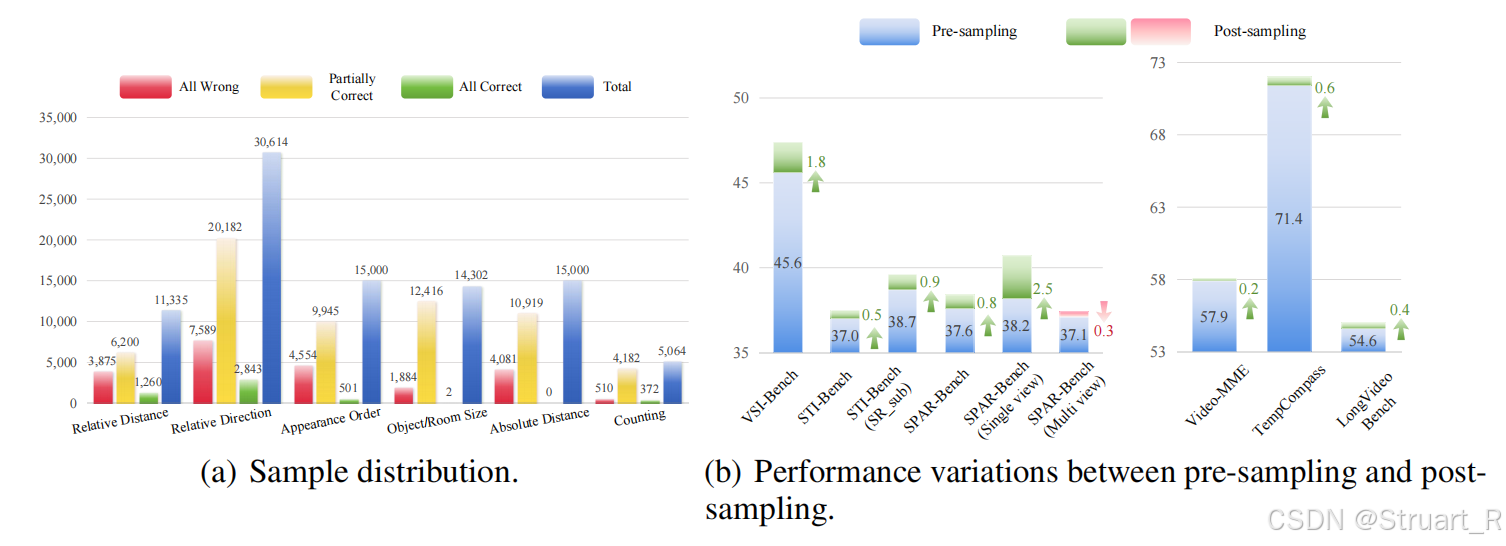
经过采样后,不需要原来那么多的数据,仍然可以达到近似的性能。
参考论文:
[2507.23478] 3D-R1: Enhancing Reasoning in 3D VLMs for Unified Scene Understanding
[2506.17545] Scene-R1: Video-Grounded Large Language Models for 3D Scene Reasoning without 3D Annotations
[2504.01805] SpaceR: Reinforcing MLLMs in Video Spatial Reasoning