考研408《计算机组成原理》复习笔记,第三章(6)——Cache(超级重点!!!)
一、基础概念
在主存已经想尽办法升级了之后,速度还是不够匹配CPU
所以又诞生了Cache,比主存更快匹配CPU
说人话:
- Cache的用处就是把CPU目前一段时间要频繁使用的数据、指令,【复制一份】到Cache
- 然后CPU先去Cache找,能找到数据就直接用;不能找到数据,才去主存找
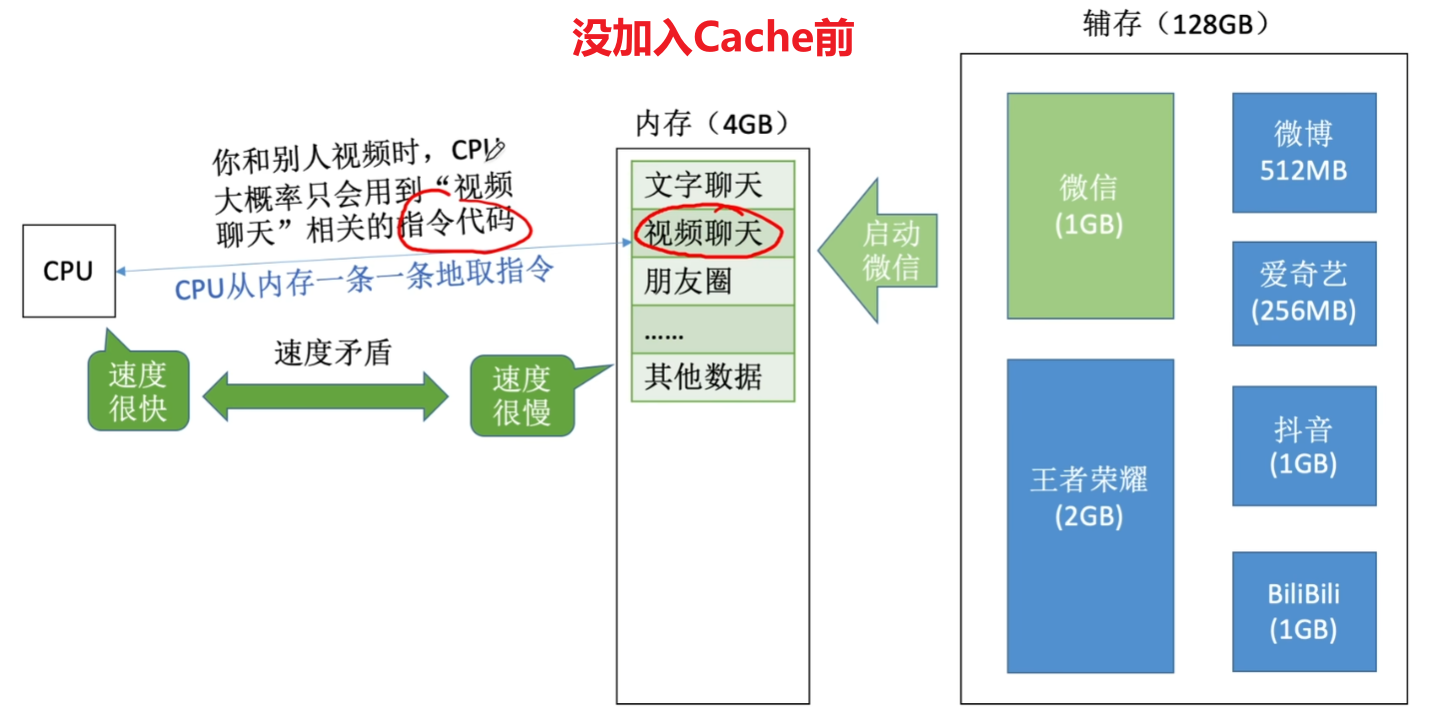
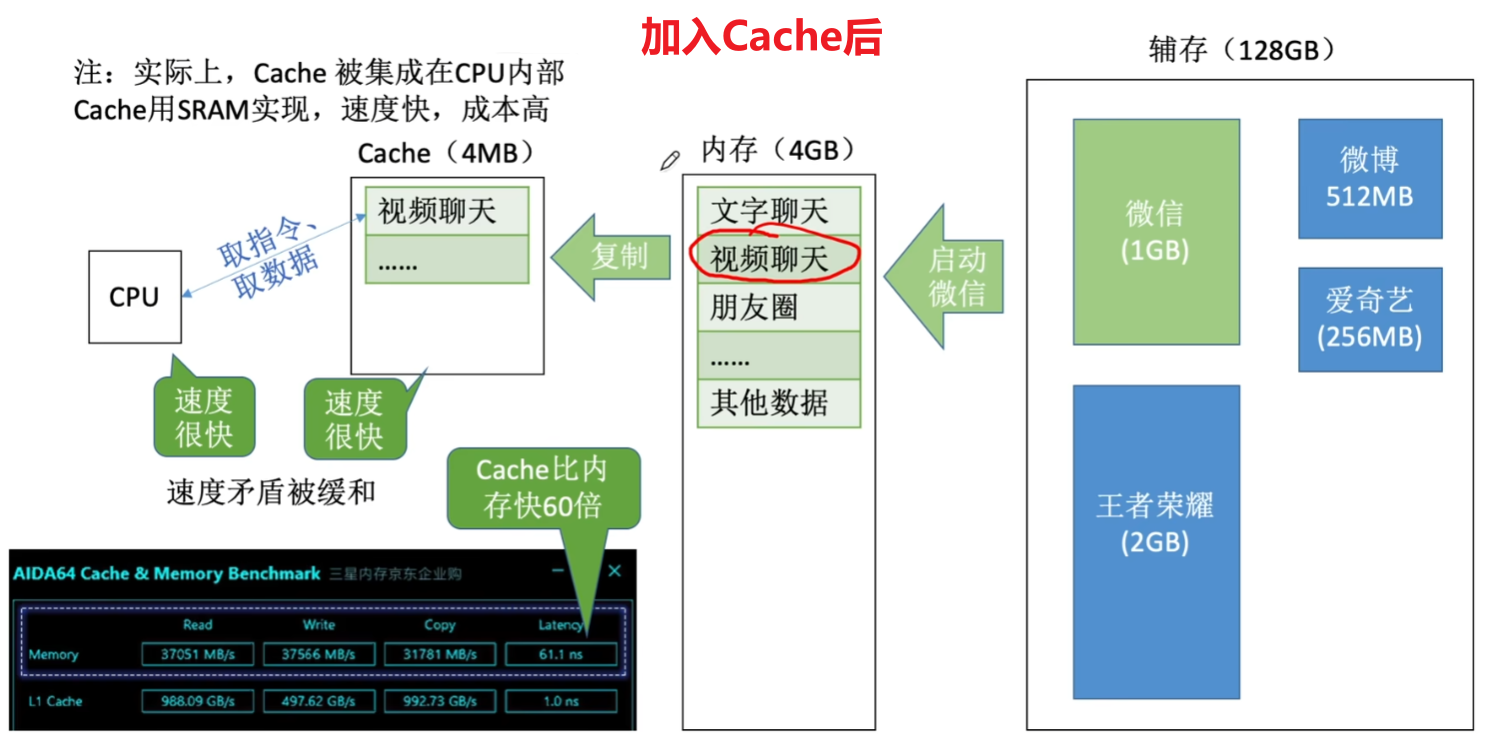
二、Cache【程序局部性】概念

具体例子解释:
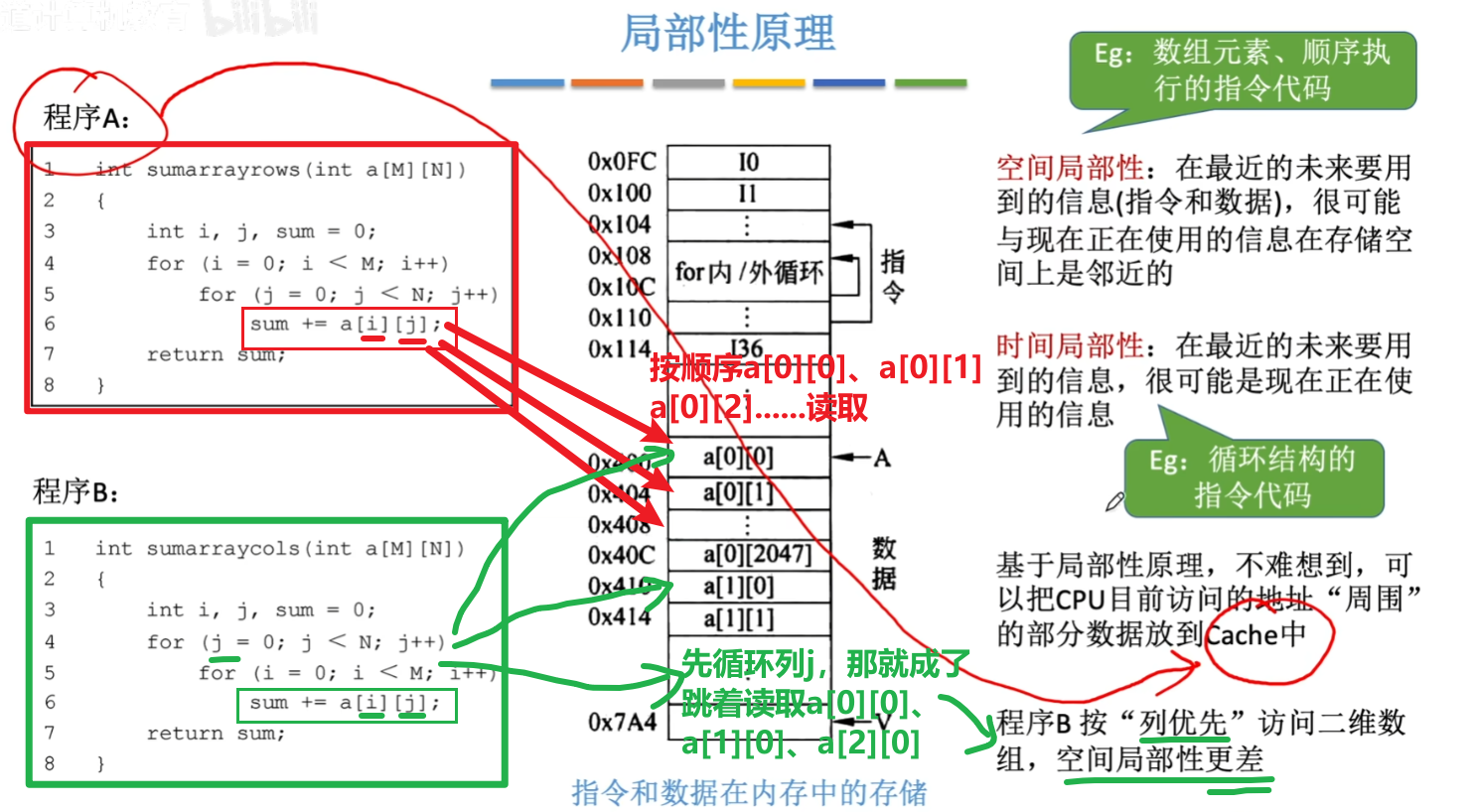
- 比如下面的程序,用到【循环】,那么里面的【变量i、j、sum、a[i][j]】、【指令sum+=a[i][j]】都会被短时间内频繁连续使用很多次,这就叫【时间局部性】
- 注意:如果一个循环只里访问的数组的每一位1次,那么数组就不具备【时间局部性】
- 而a[i][j]这个数组,按循环要访问的顺序就是:a[0][0]、a[0][1]、a[0][2]、a[0][3]、a[0][1].......a[n][n-1]、a[n][n],那么这些数据都是连续邻近地排列着的,每一个未来要访问地数据都跟上一个紧挨着,这就叫【空间局部性】
- 而注意,程序A的循环算法是让数组【按行再按列】找数据,就是按顺序一路找下去,【空间局部性好】
- 程序B的循环算法是让数组【按列再按行】找数据,就是跳着“一行一行”地找,【空间局部性差】
- 注意:单个、多个变量都不具备【空间局部性】,因为他们排列的位置随机,并不是想数组那样挨着的
例题



三、Cache性能分析
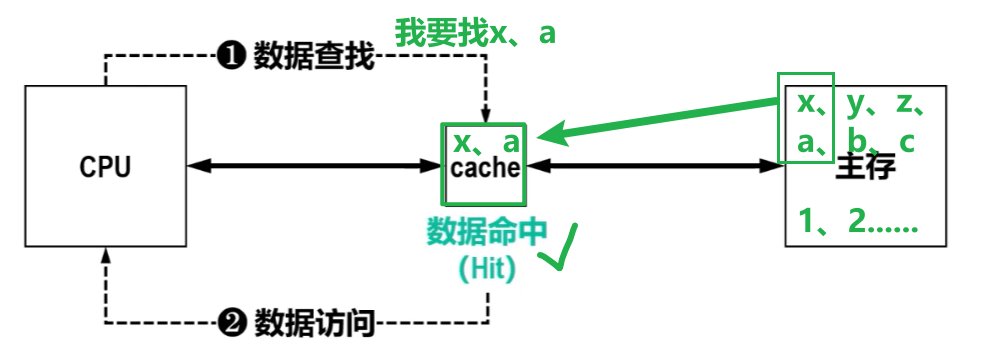
【Cache命中率:H(Hit)】

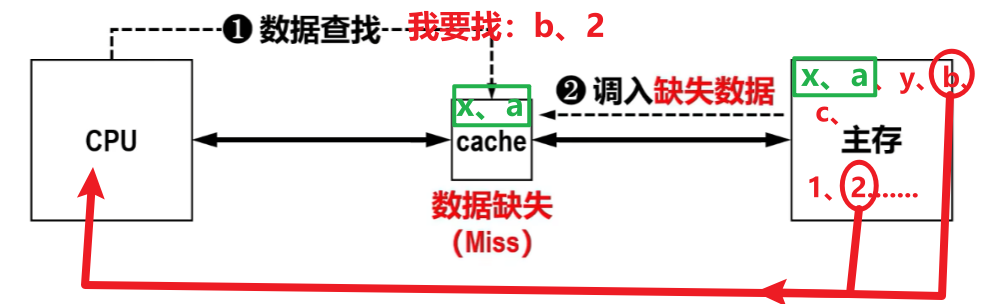
【缺失率:M(Miss)】
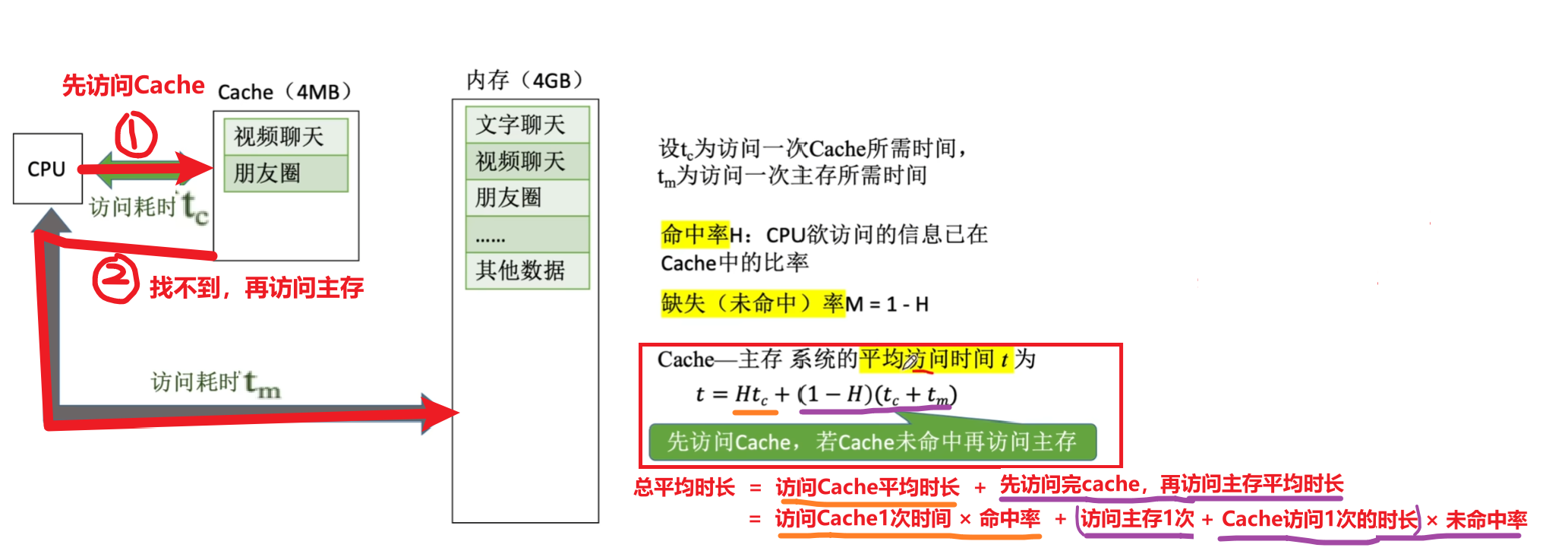
【Cache-主存系统】的平均访问时间公式
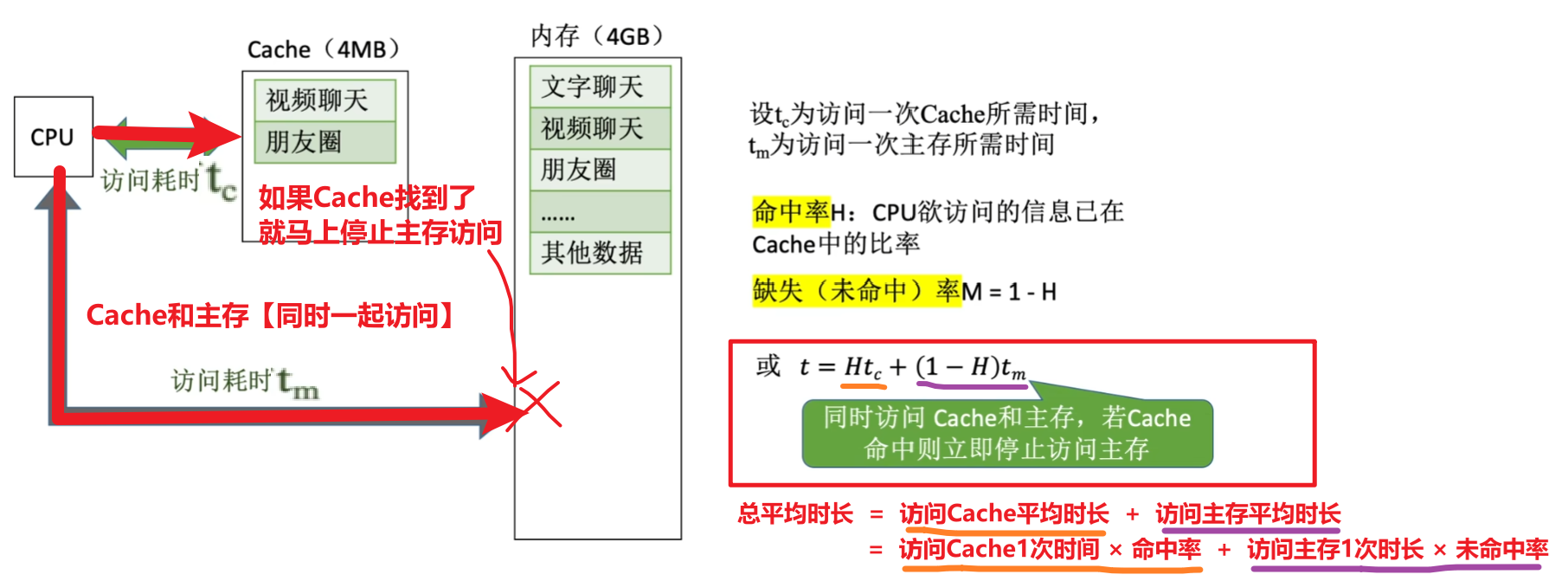
例题


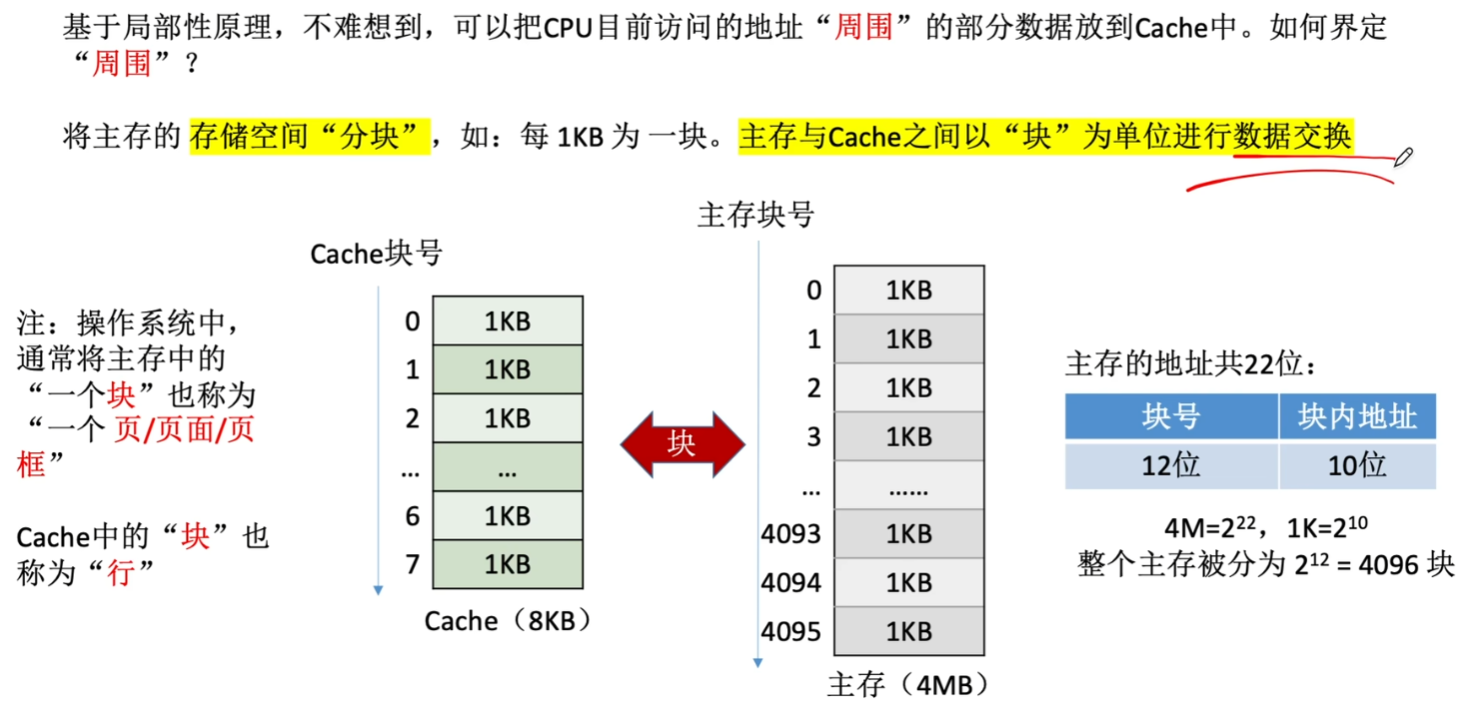
四、Cache的映射(超级重点)
1、Cache和主存之间的数据单位是【块】
留意一下:
- 主存里的【块】也叫【页/页面/页框】;
- 【块】可以理解为【多个存储单元的一个分组】!!!
- 块只是它两的传输数据的单位,不是最小的存储单位!!!!!!!
- Cache里的【块】也叫【行】
- 【块】可以理解为【多个存储单元的一个分组】!!!
- 块只是它两的传输数据的单位,不是最小的存储单位!!!!!!!
- 每次访问主存的时候,数据也一定一定一定一定会被【复制到Cache】
注意!!!
- 【CPU和主存】、【CPU和Cache】之间的数据传送单位是【字】!!!
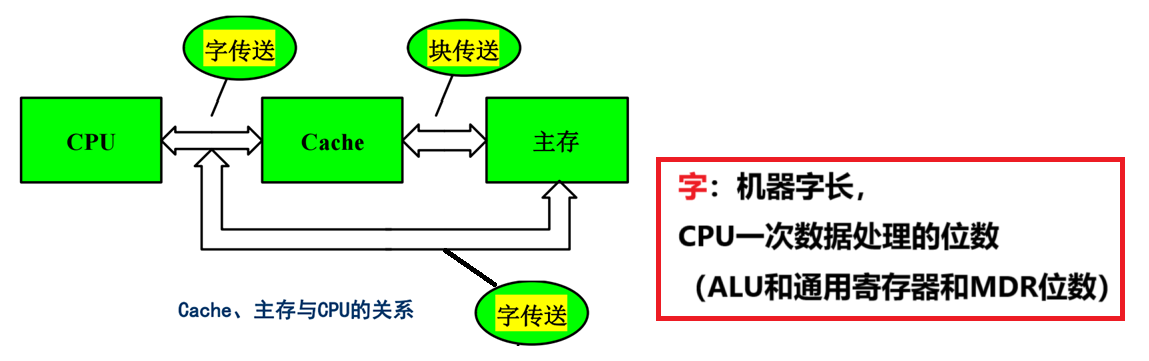
【其他二者的知识点】
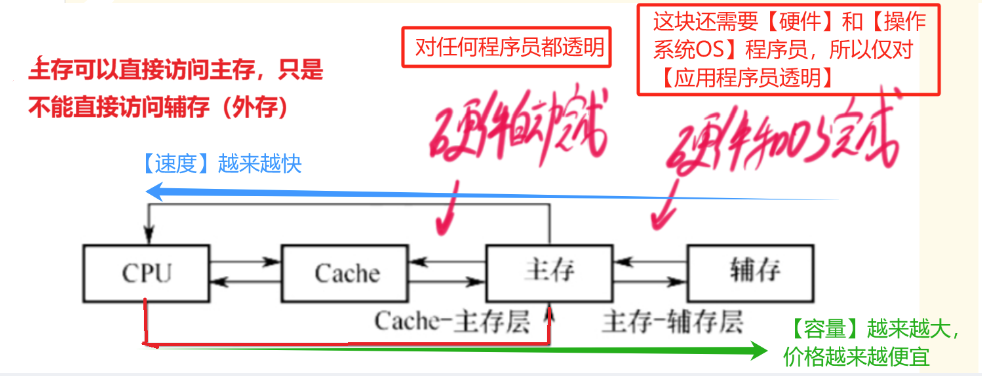
- 1、【Cache-主存】系统运行流程
- 【Cache和主存】之间完全靠 硬件 自动完成(对所有程序员透明)
- 【主存和辅存】之间要 硬件+OS 完成(仅对应用程序员透明)
- 2、Cache用的是SRAM存储芯片;主存用的是DRAM存储芯片(具体是SDRAM:同步DRAM,具体知识点去我以前的文章回顾)
- 3、Cache和主存的采用【独立编址】!!!
- 【独立编址】:地址不续上,你是你我是我
- 【共同编址】:虽然存储体分开,但是地址能续上
例题:

疑问(后面要解决的问题):

2、Cache的3种映射方式

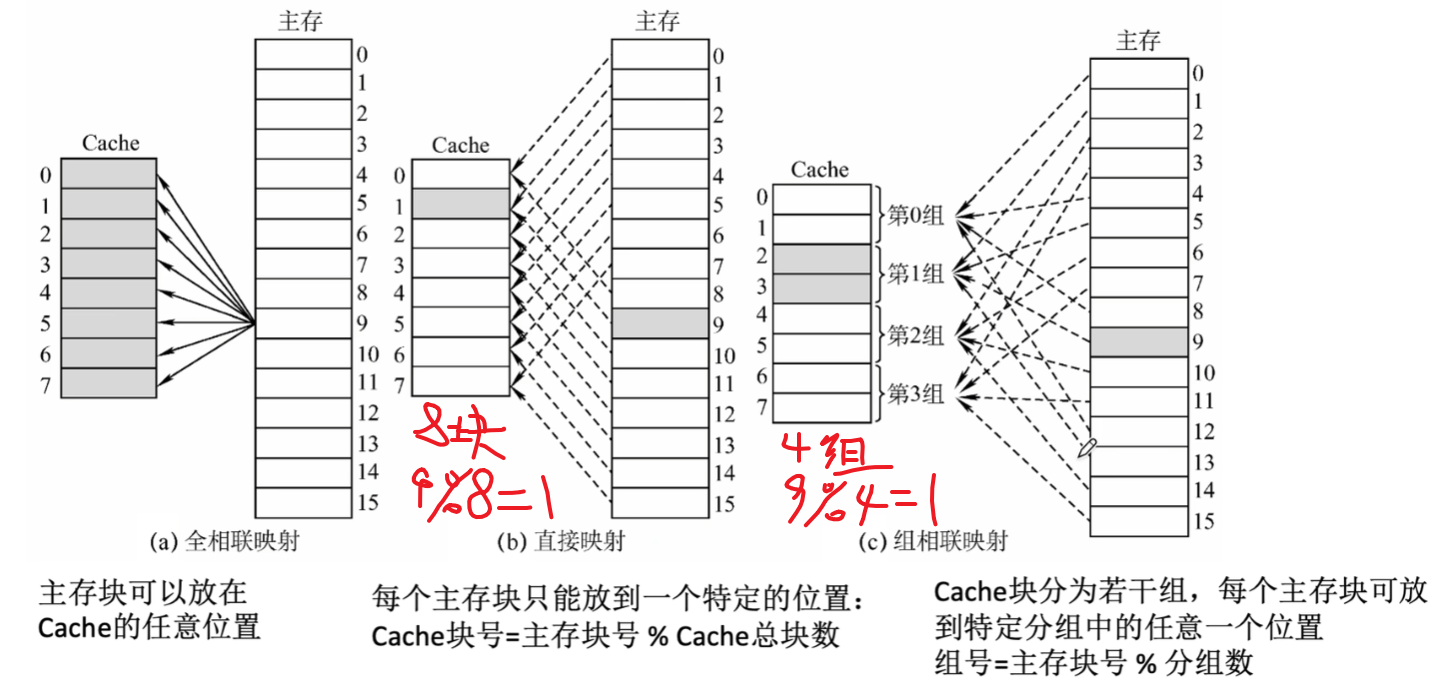
1)宏观粗略概念,【主存的块】要放到【Cache的什么位置】:
先宏观大概理解一下,就是靠3种映射方式:
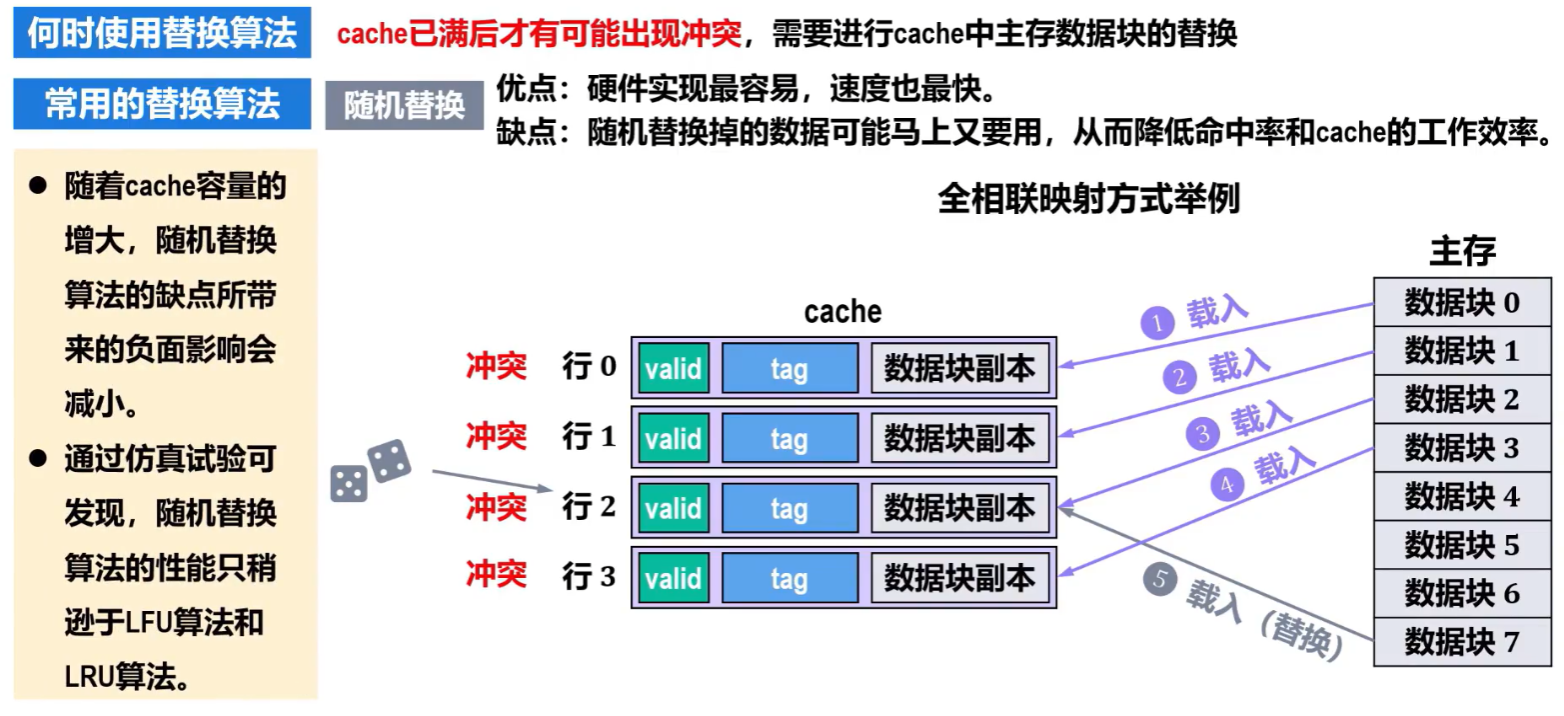
- 全相联映射:【主存的块】可以放【Cache任意位置】
- Cache块冲突概率低,只要有空闲块,就有可能被随机存入
- 空间利用率高
- 命中率高
- 标记速度较慢、成本也高(经常要用按内容寻址的【相联存储器】)
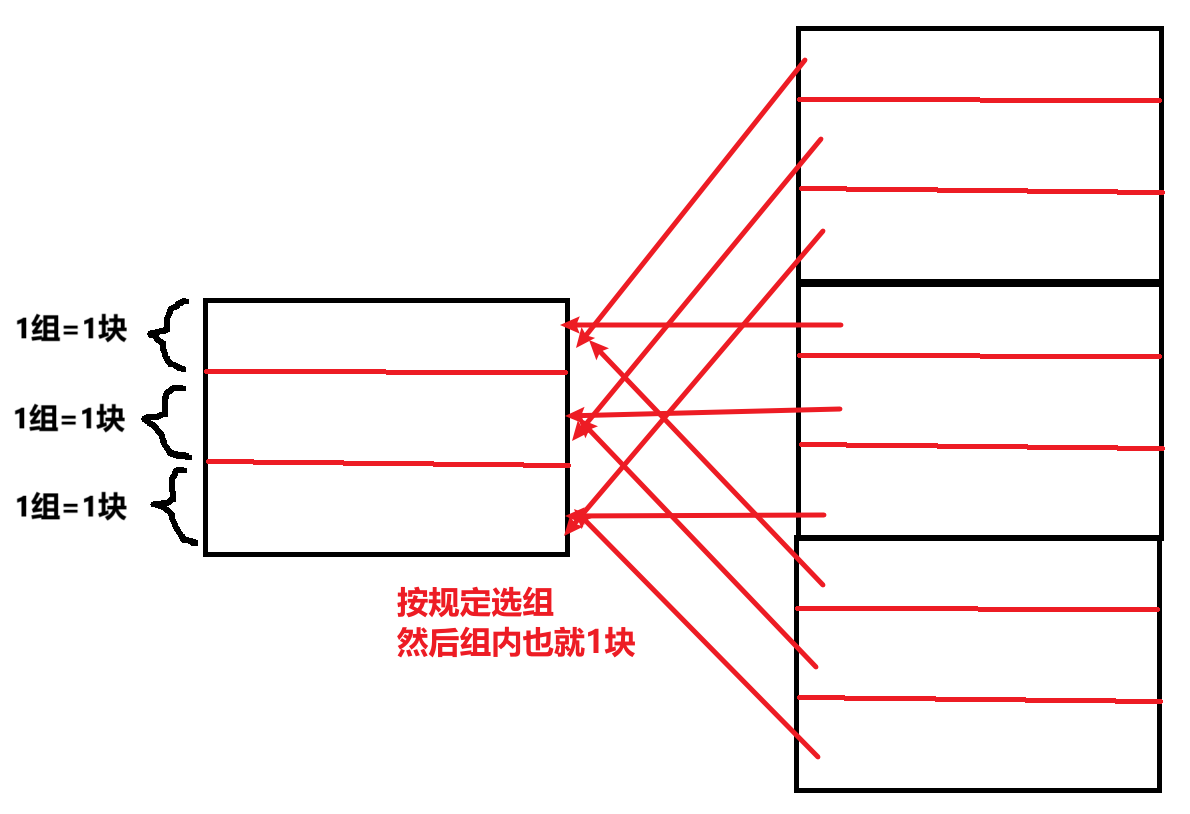
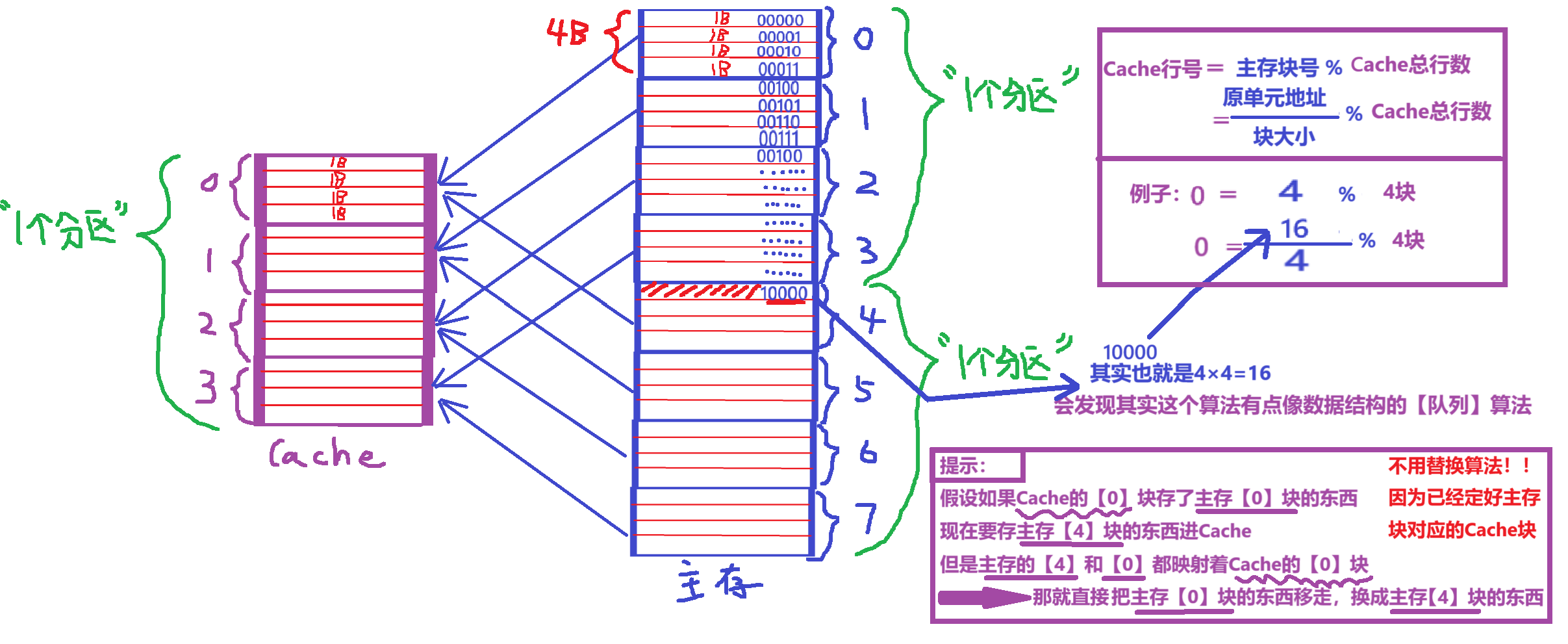
- 直接映射:【主存的快】放在【Cache的:主存块号 % Cache总块号 = Cache块号】
- 相反,块冲突率高(因为你都规定了每个主存块必须放Cache哪一块,那有多个主存块对应一个Cache块,就会冲突)
- 空间利用率最低!(比如多个主存块指定存0号Cache块,但实际Cache其他块都空闲,却没办法存入)
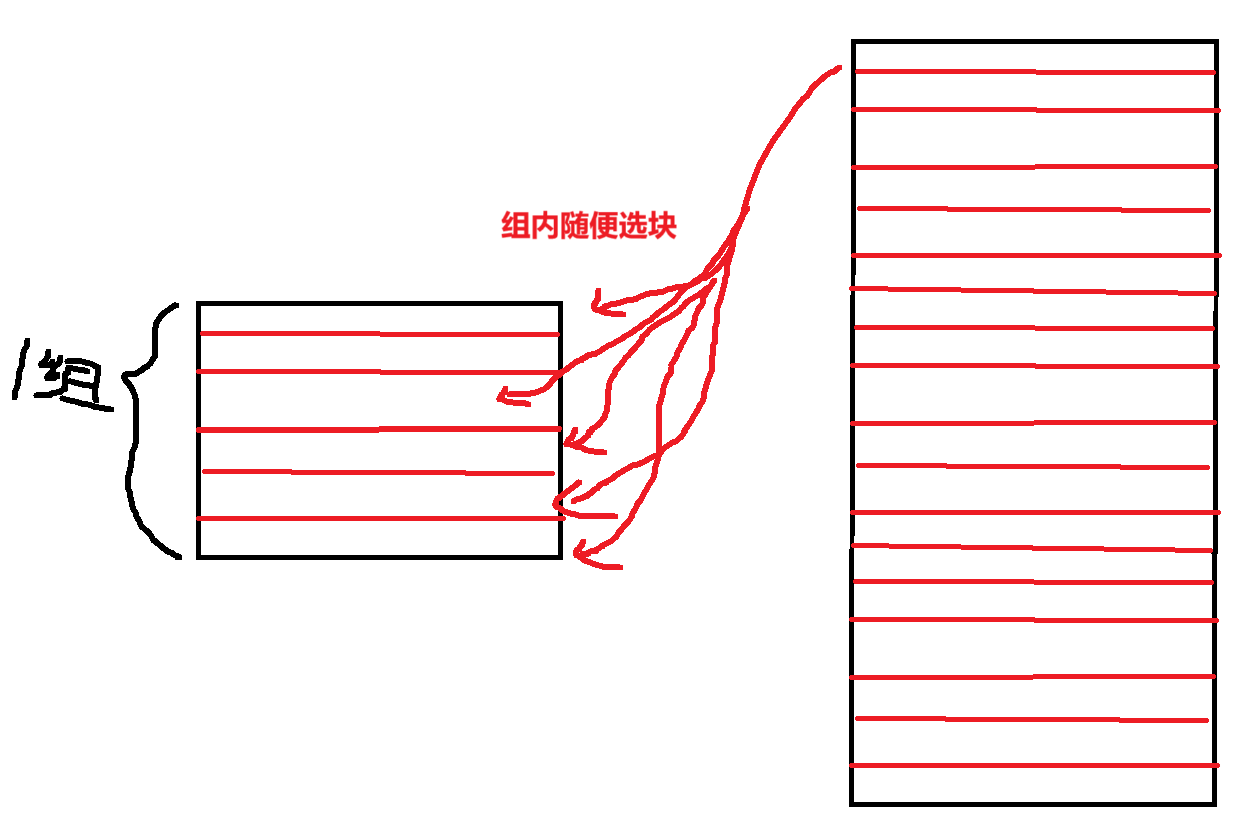
- 级相联映射:【主存的块】放在【Cache的:主存块号 % Cache分组 = Cache分组号】
- 是对上面两种方式的【折中方法】
- 每个组间采用【直接映射】
- 组内的块采用【全相联映射】
- 【组数=1】时,变成【全相联映射】(一组里的哪一块随机选)
- 【组数=Cache行数】时,变成【直接映射】(其实就是意思一组就一块)
2)那【Cache又怎么知道自己的块】对应的是【主存的哪个位置】:
首先统一的方式是:
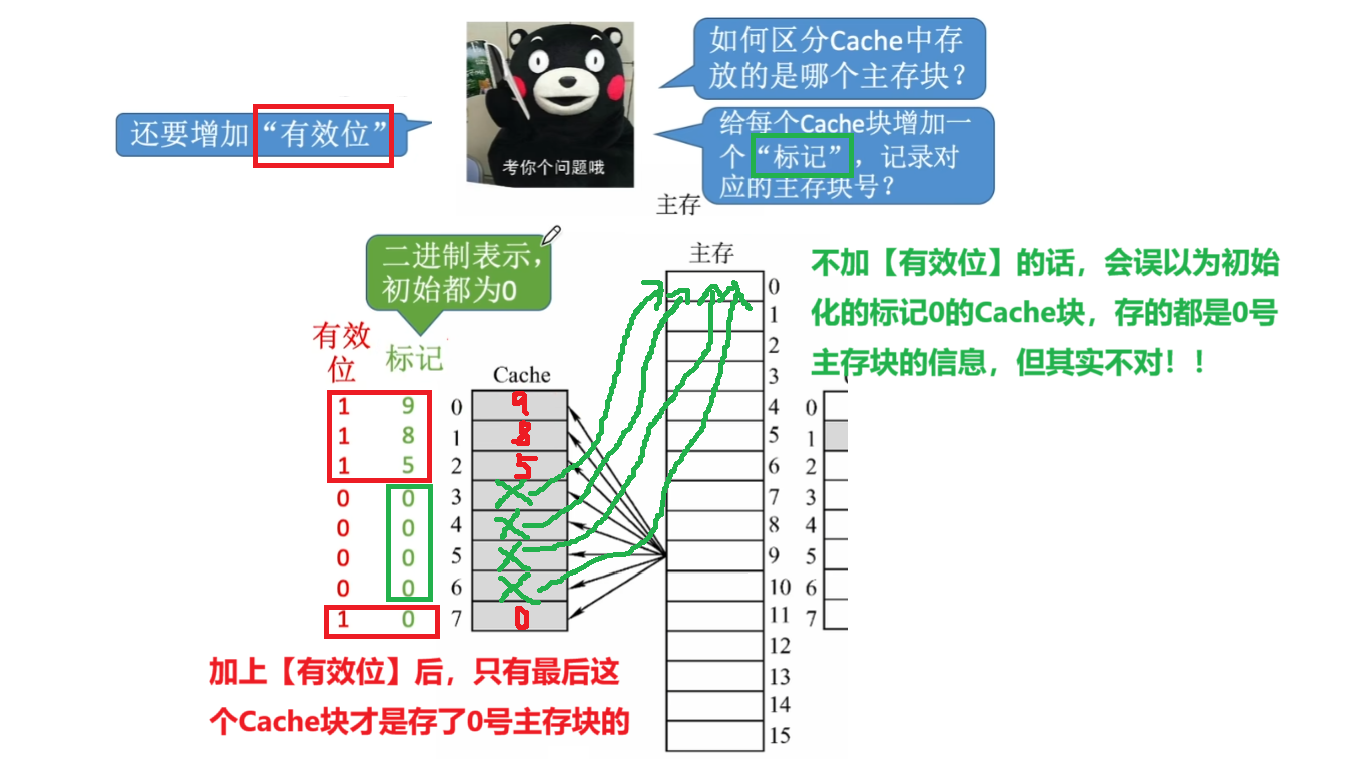
- 在Cache的【块地址】设置成:【有效位】+【标记位】+【Cache自己的块号】
- 其中【标记位】就是对应【主存的块地址】
- 【有效位】是确定这个【Cache块到底有没有存主存的数据】(因为要避免【标记位】刚好是【主存块地址】,但实际有没有存东西的情况)
3)总体流程和微观细节(重中之中!!!!)
王道和湖工大这里的图片画得都是一坨屎,说白了,直接看下面得讲解就明白了:
- 1、首先要知道CPU访问Cache的一个【数据(块里面的最小单元)】的流程:
- ① 首先CPU里的MAR地址寄存器只有:主存原本正常的一个【存储单元形式】的地址
- ② 然后因为Cache要和主存之间用【块】进行互换数据,所以【主存“存储单元形式”的地址】需要被 “翻译” 成【主存“块形式”的地址】
- ③ 最后把根据 “翻译好”的【主存“块形式”的地址】去 “映射” 成【Cache“块形式”的地址】!!
- 至此大功告成,CPU的【原始主存数据地址】变成了【Cache的实际地址】,CPU就可直接去Cache找数据了,如果找不到就说明“未命中”,到时再去主存找这个数据
(先不用管图片里的地址为什么是000001、为什么主存2^64个存储单元、翻译后的地址有什么变化,这些后面都会讲,只需要知道【翻译后的地址,地址本身不变,只是部分比特位的意义变了】)
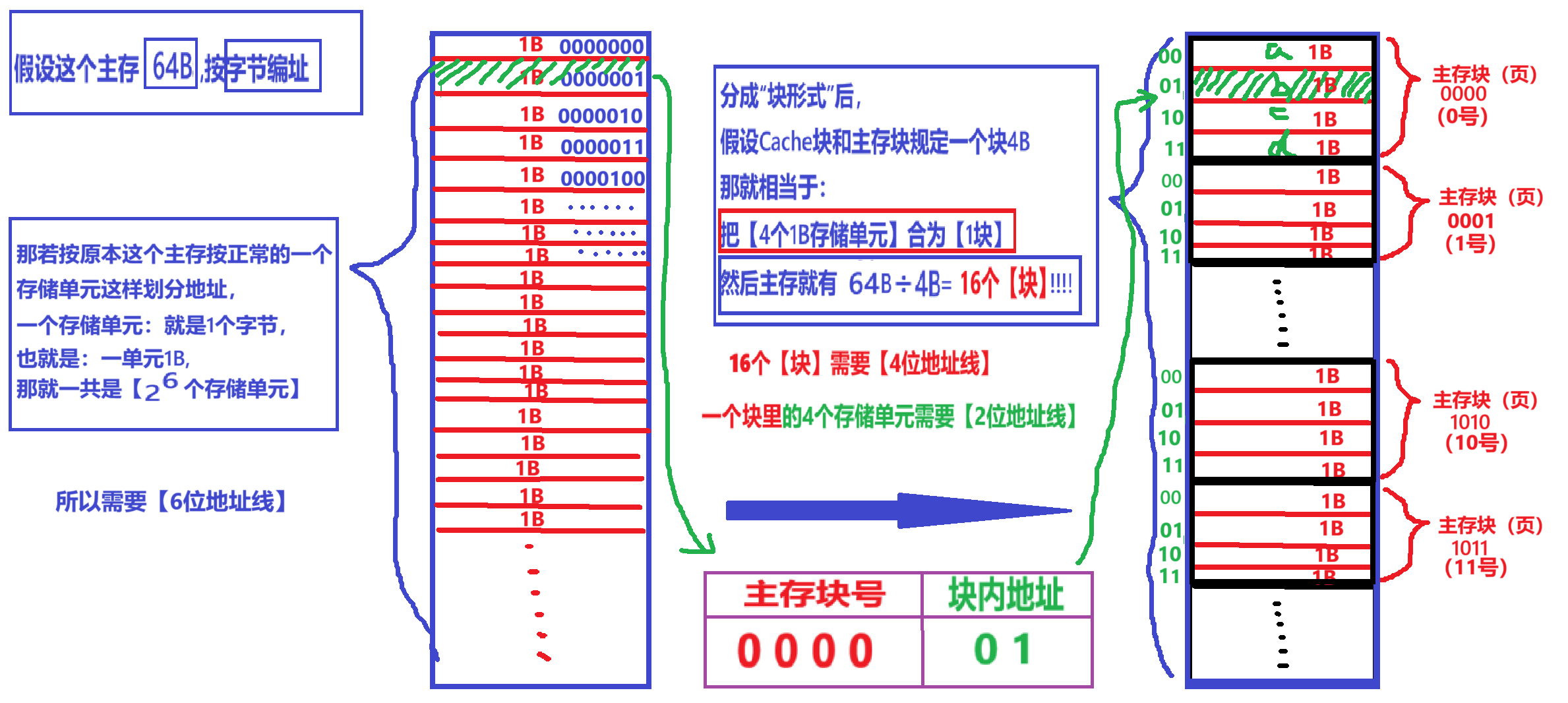
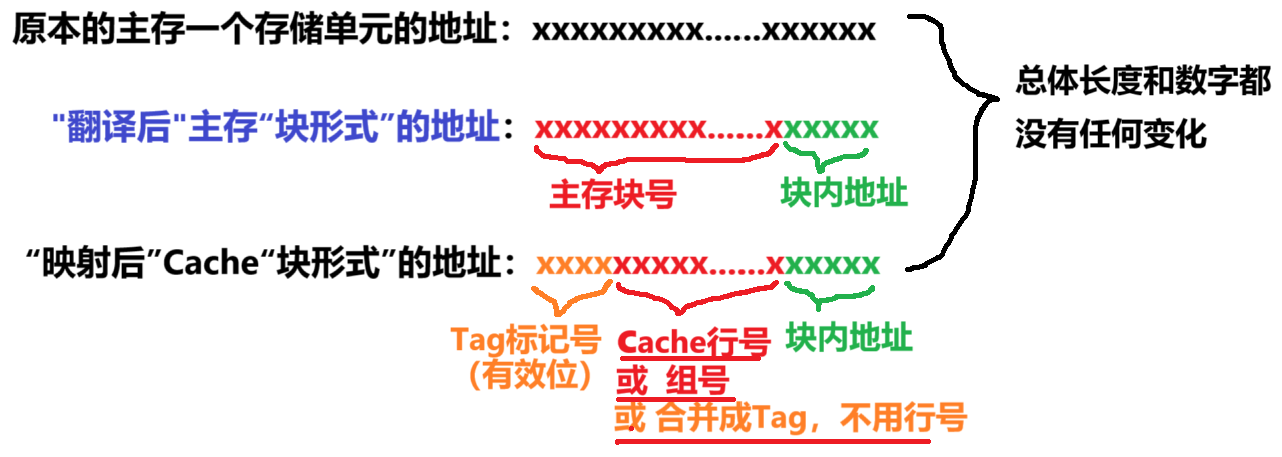
- 2、然后看第二步:【主存“存储单元形式”的地址】 “翻译” 【主存“块形式”的地址】
- 首先记住:【主存“块形式”的地址】统一翻译成【主存块号 + 块内地址】
- 具体是怎么 “翻译” 的,看下图例子:不知道为什么地址是那样的话,回顾一下地址线的知识点,一开始如果一个主存【2^6个存储单元】,那不就对应【6位地址线】嘛;一个主存分【2^4个块】,那不就对应【4位地址线】;一个块里【2^2个存储单元】,不就对应【2位地址线】
- 3、第三步:【主存“块形式”的地址】 “映射” 成【Cache“块形式”的地址】
- 这里其实没法一下子展示出来,因为针对【3种不同的映射方式】,【Cache“块形式”的地址】都是不一样的,只能暂时做个大概印象,后面会讲
- 总结:不管是【主存结构 “翻译”】,还是【Cache结构 “映射”】
- 本质都是【地址本身丝毫变化】,只有【比特位的意义变了】
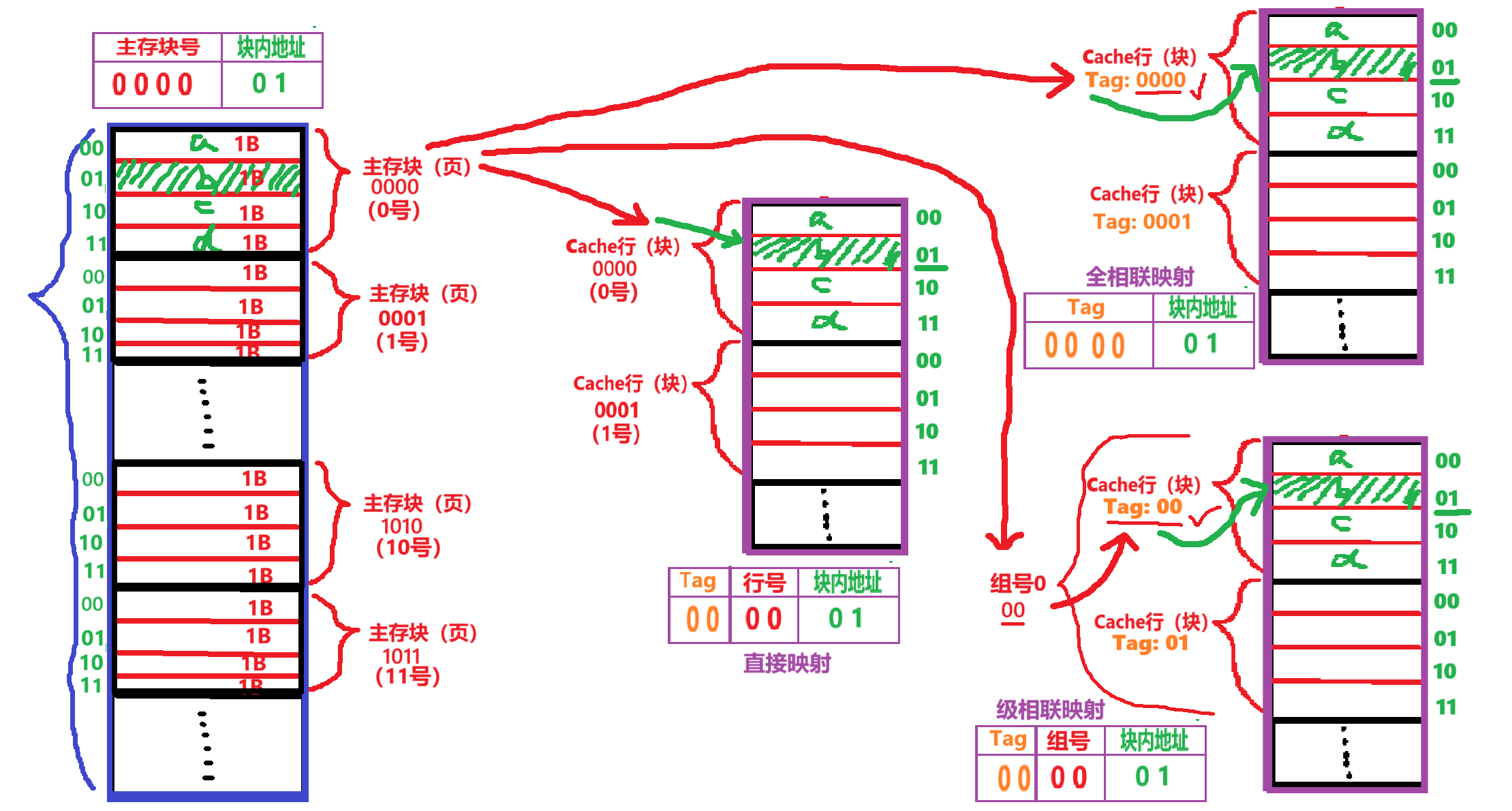
【直接映射】具体细节
宏观上:
- 求【Cache的行号】
- 第一种算法:对应映射于【主存的块号 % Cache总行数】
- 第二种算法:把完整地址展开成2进制,然后根据【主存“存储单元形式”的地址】——>【主存块号 + 块内地址】——>【Tag标记】+【Cache行号 + 块内地址】
;
微观上:
- 前面我们说过了【主存“块形式”的地址】统一翻译成【主存块号 + 块内地址】
- 然后我们也说了Cache的完整块地址应该【Tag标记】+【Cache行号 + 块内地址】
- 【Cache行号 + 块内地址】只是【Cache自己的实际块地址】
- 【Tag标记】是主存某个块存进Cache之后,【标记这块来自主存的哪一块(Cache认爹)】
- 【主存的块号 % Cache总行数】这个算法也可以发现,【主存0】、【主存4】、【主存8】、【主存12】......块居然都可以映射成【Cache 0】,那肯定得标记一下到底是哪个
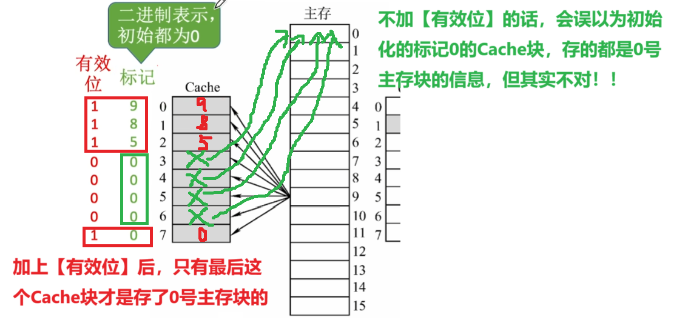
- 还有一个【有效位】,但不包括在地址里,【有效位】是避免 “认爹乌龙”
- 比如一开始初始化,Cache没有任何来自主存的数据,那每一个块的【标记】都是【0】,难道代表Cache每一块都存了【主存0号块】吗?肯定得
- 又或者【主存0】的数据【abc】存入【Cache 0】,现在CPU把【Cache 0】的【abc】改成【fuck】,那就要把【有效位改成0】,因为【主存0】的原数据已经不在【Cache 0】了
总结:
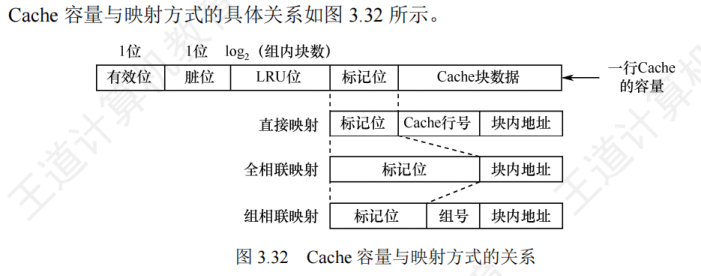
- 那么我们需要记住【主存块地址结构】、【Cache行地址结构】、【块号映射计算】这几个重点(其中【Cache行地址结构】的【有效位】先不包含在内,后面再解释为什么)
- 提示:题目中说到的【Cache行大小】、【数据块大小】我们默认只包含了一个Cache行的【数据部分】,但实际一个Cache行还包括别的信息
- 所以如果题目说【Cache行:4B】,问:“【一个Cache行总容量】”,就一定要把其他的【Tag位】+【有效位】+【脏位】+【替换算法位】+【数据区:4B】全部算上!!!
(后面会讲)

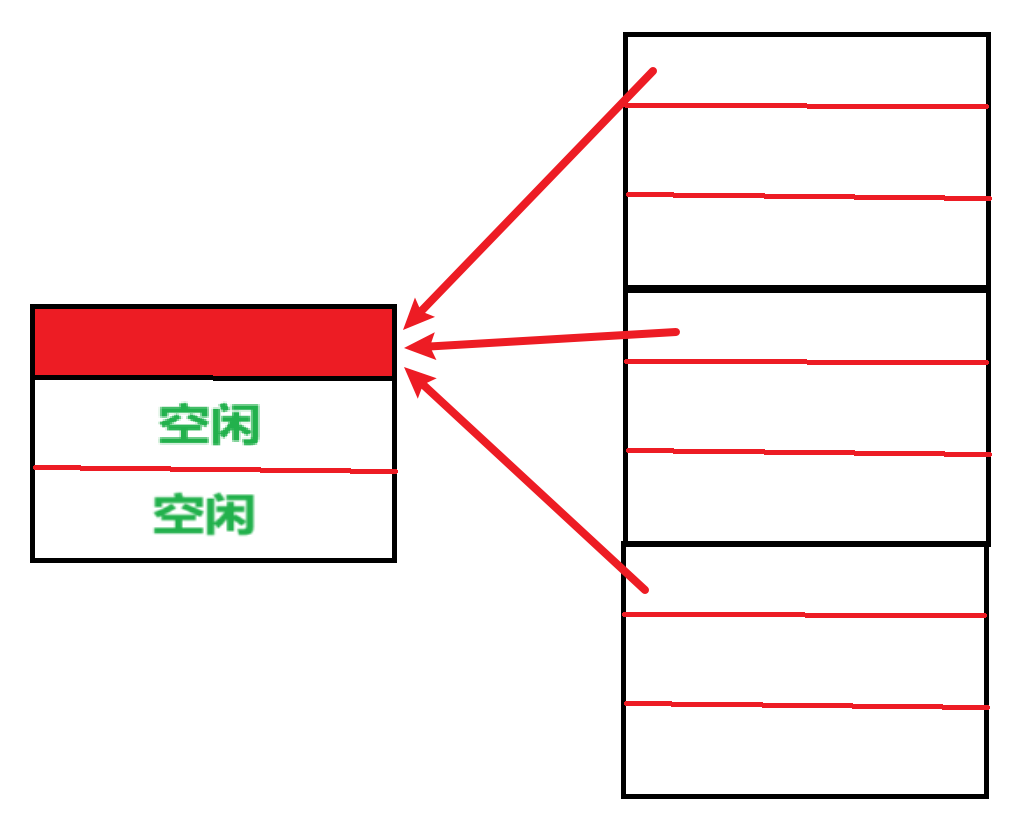
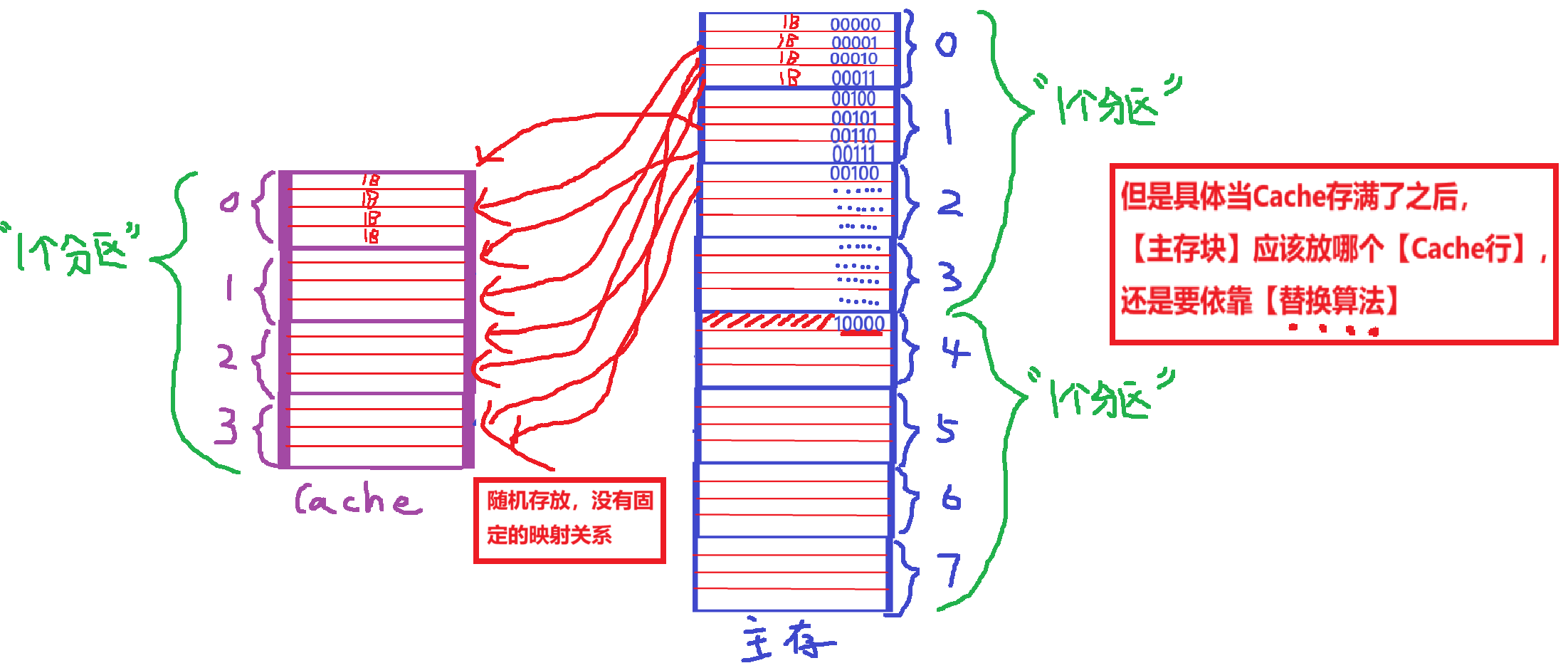
【全相联映射】具体细节
宏观上:
- 求【Cache的行号】:随便放,爱放哪放哪
- (除非Cache存满了,要替换的时候需要【替换算法】,后面会讲)
微观上:
- 【主存块地址结构】:依旧统一翻译成【主存块号 + 块内地址】
- 【Cache行地址结构】:变成了【Tag标记 + 块内地址】
- 【Tag标记】:因为随机存放,所以取消了【Cache行号】,而合并成了【Tag标记】
- 但是可以发现Cache块的【Tag标记】和【主存块号】是1-1对应的,不再是多个“多个主存爹”对“一个Cache儿子”
- 【块内地址】:和主存的【块内地址】一样
- 【有效位】不包括在地址里,但是依旧还是那个作用

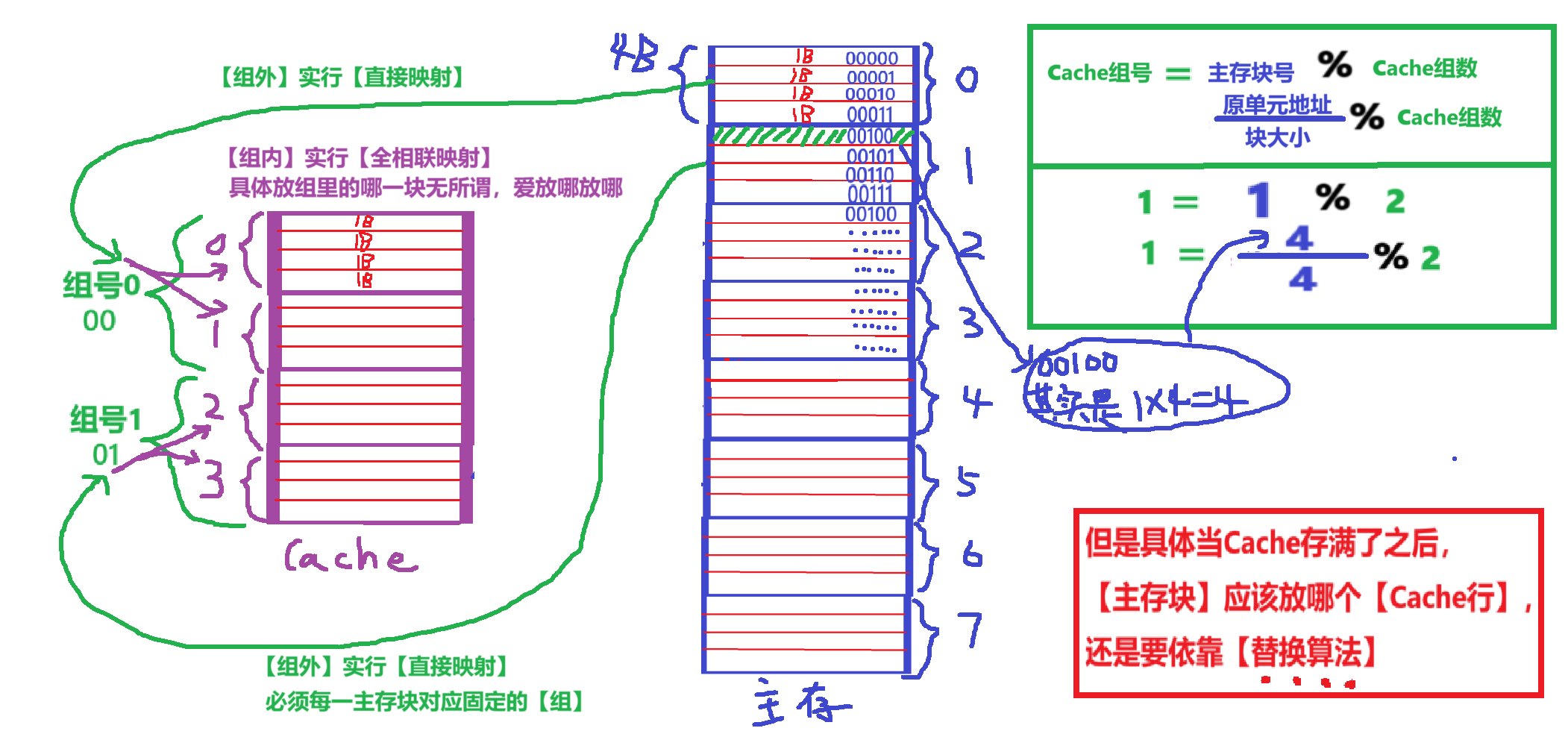
【级相联映射】具体细节
宏观上:
- 求【Cache的组号】:【组外】用【直接映射】,公式是:
- 第一种算法:对应映射于【主存的块号 % Cache的组数】
- 第二种算法:把完整地址展开成2进制,然后根据【主存“存储单元形式”的地址】——>【主存块号 + 块内地址】——>【Tag标记】+【Cache的组号 + 块内地址】
- 求【Cache的块号】:【组内】用【全相联映射】,爱放哪放哪
- (除非Cache存满了,要替换的时候需要【替换算法】,后面会讲)
微观上:
- 【主存块地址结构】:依旧统一翻译成【主存块号 + 块内地址】
- 【Cache行地址结构】:变成了【Tag标记】+【Cache的组号 + 块内地址】
- 【Tag标记】:又变成了“多个主存爹”对应“1个Cache儿子”,另外【Tag标记】标记的是【组内块存的是哪个主存块】
- 【Cache的组号】:题目说【N路组相联】意思就是Cache分成【N组】,每个主存块和Cache组号1-1对应
- 【块内地址】:和主存的【块内地址】一样
- 【有效位】:不包括在地址里,但是依旧还是那个作用

【对比实际容量 和 映射方式】
五、Cache替换算法
1、直接映射
不用【替换算法】,说过了,直接映射按算法规则已经固定死每个【主存块】对应哪一个【Cache行】了。
所以让Cache满了之后,要存入某个【主存块】,会直接把它对应的【Cache行】给换掉!!!!
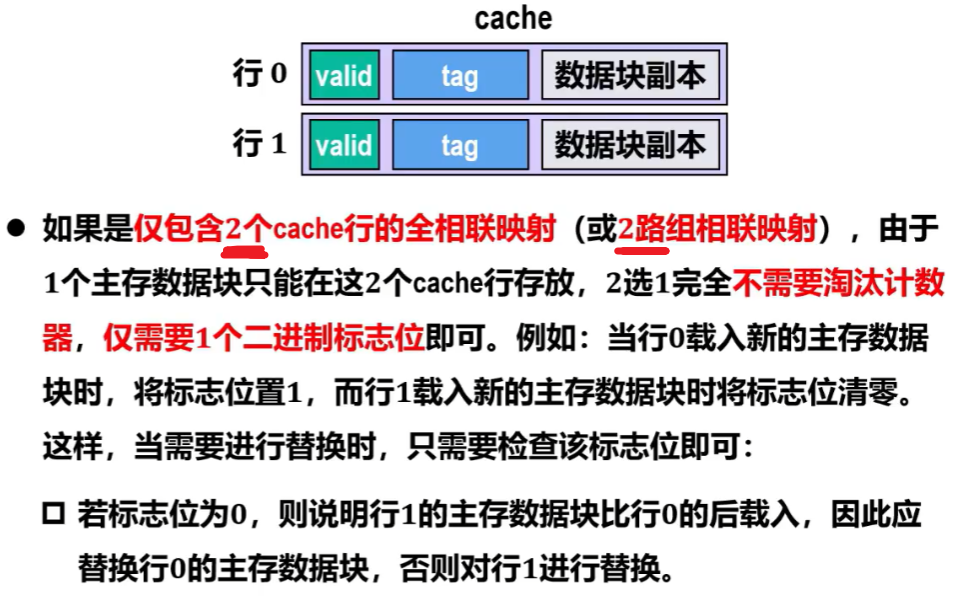
2、全相联映射 和 级相联映射
它两一个是【整个Cache所有块 “随机映射”】、一个是【组内的块 “随机映射”】,所以究竟要替换哪一块,还是需要一些算法来规定的
【随机算法(RAND:Random)】
没什么可说的,和它的直接映射关系一样,随机随心所欲,爱换哪里换哪里!
缺点:就是【命中率降低】,乱替换很容易把下次要用到的有用的数据换掉
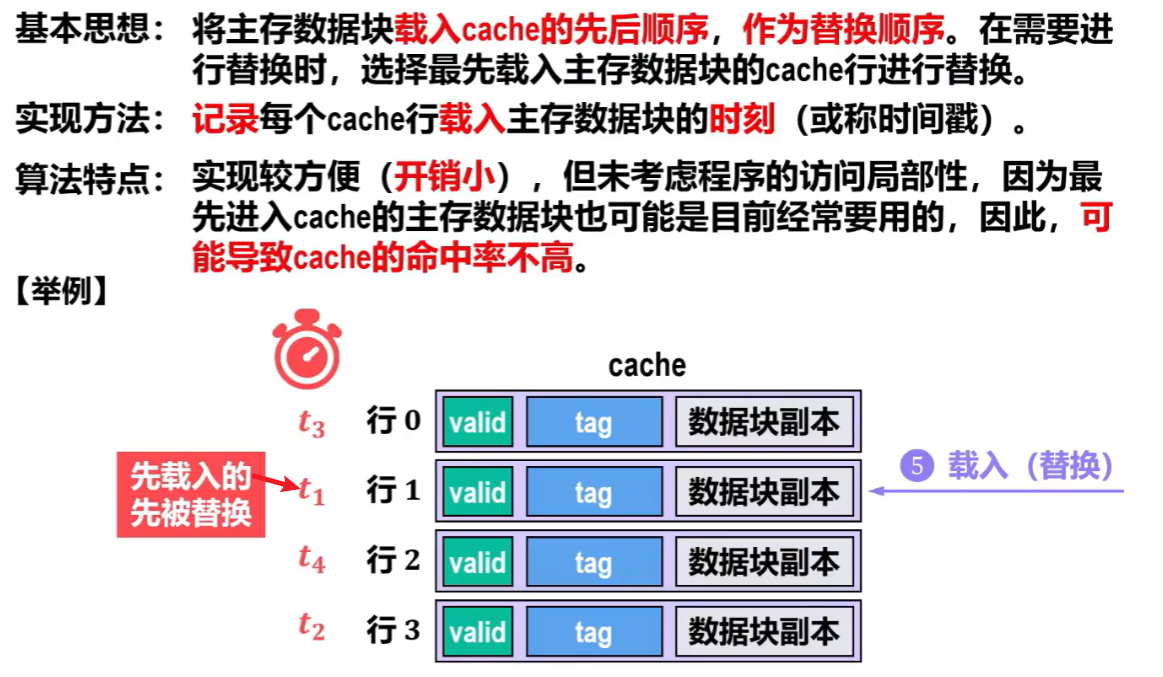
【先进先出算法(FIFO:First In First Out)】
哪个块先存入数据,就先替换谁,有点像数据结构的队列 “先进先出” 概念
特点:每个行都有时间记录器,开销小
缺点:【命中率依旧不高】,这个逻辑本身就没什么用,先载入的行并不代表人家后面就不会被经常访问了啊......
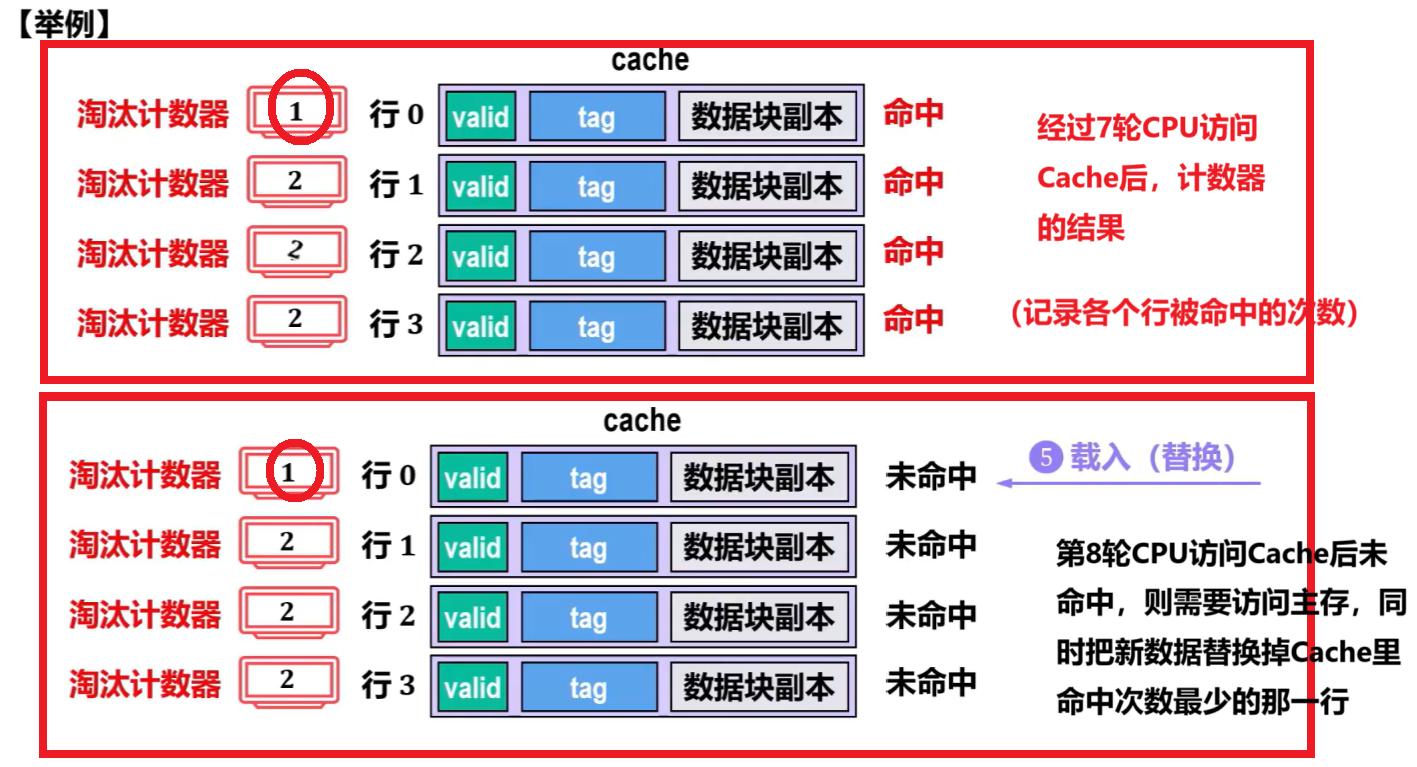
【最不经常用算法(LFU:Least Frequently Used)】
特点:每个行都有【淘汰计数器】,被访问命中一次就【+1】
淘汰、替换的时候选【计数器最少】的;
- 但是如果有不止一个【计数器最少】的,那就再采用【随机算法】或【先进先出】
缺点:成本开销大;而且【被访问命中最多】不代表【最近最经常访问】,不能反映近期访问情况

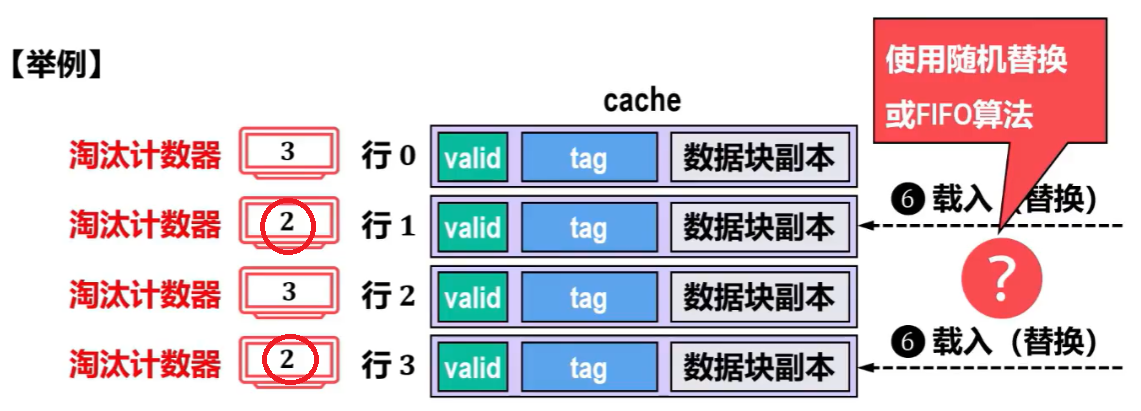
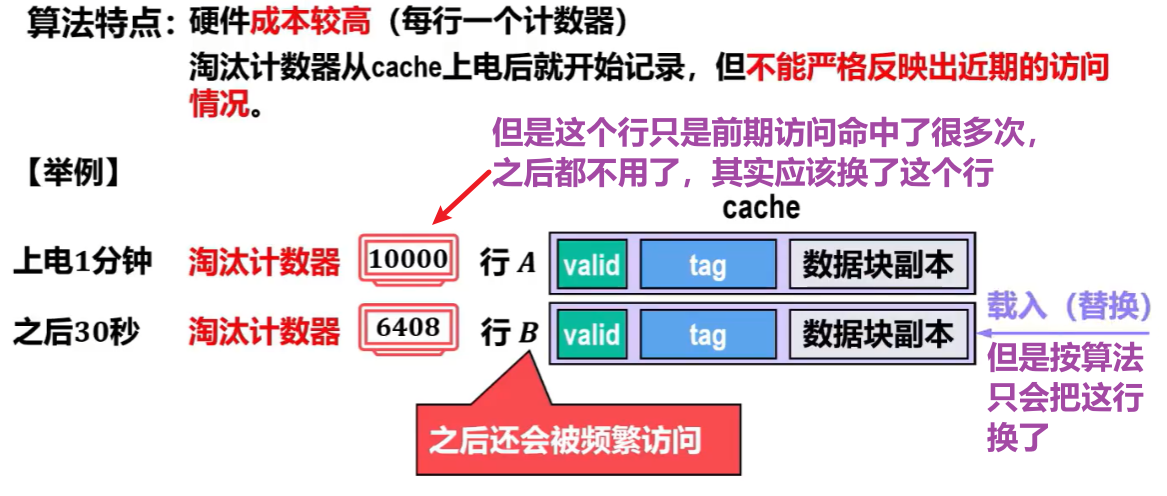
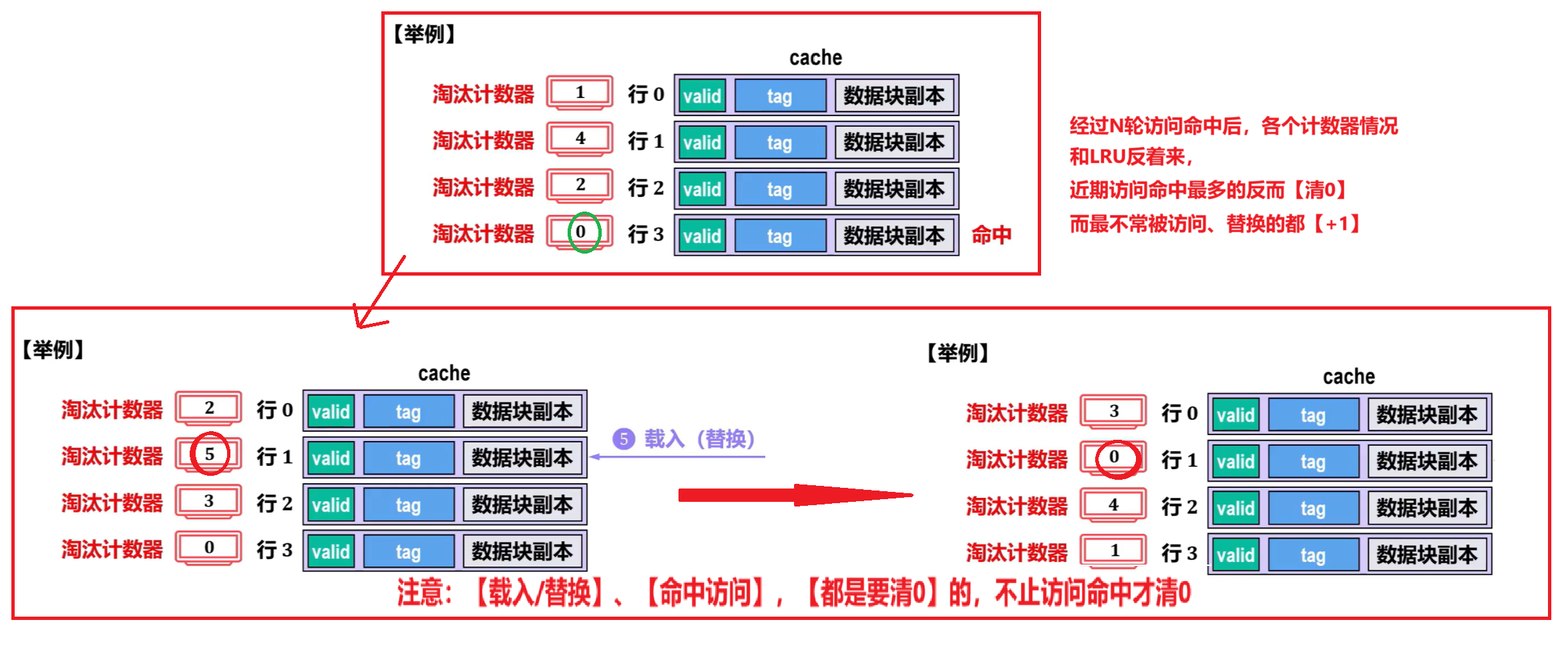
【近期最少使用算法(LRU:Least Recently Used)】
特点:
- 和【最不经常用算法】一样每个行都有【淘汰计数器】
- 但是替换条件和【最不经常用算法】反着来,能【突出近期使用情况,有局部性】
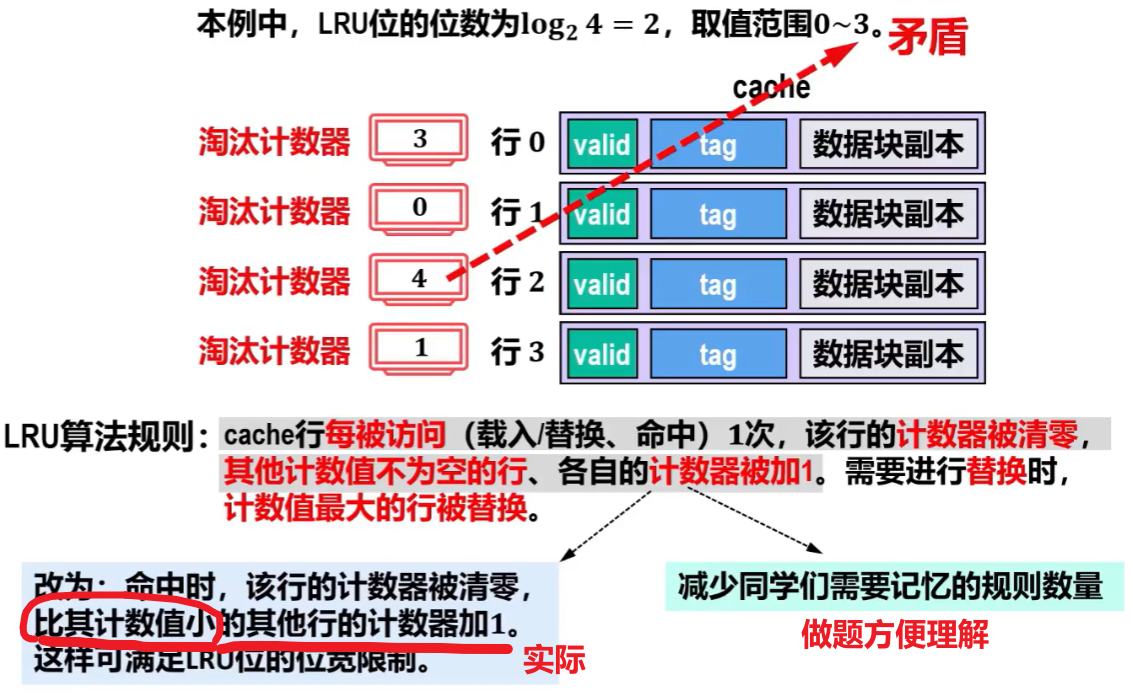
- 近期一被访问命中,就计数器【清零】,其他未命中的反而【+1】(但实际是,计数器值比该计数器值小的行才会【+1】)
- 只替换【计数器值最多】的行
- 另外,不是只有【访问命中】才【清零】;【被替换】也会【清零】
;
另外,淘汰计数器的数值的二进制位数叫【LRU位】
用几位LRU来表示计数器数值?————>N路组相联,就【
】位
;
但是这么少的LRU位,怎么能表示大量的计数器值?
其实计数器并不是只要没命中就 “疯狂【+1】”,而实际是前面说的:“只有比【命中行的计数器值小的】行的计数器才会【+1】”,这样就会让计数器值不会大么大到超过LRU位数可表示的数值


另外提示:
回顾:
有点类似《计网》里的【二进制信号】,当传输信号是【二进制信号】时,
也就是【一个码元】=【1比特信号】,所以【波特率】=【比特率】
六、Cache的写策略(一致性问题)
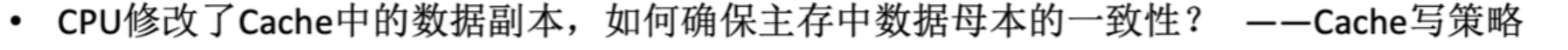
前面解决了2个问题,都是涉及【读操作】的;
现在还剩一个问题:“CPU写入Cache或主存时,如何保证二者互相【对应的块】要数据一致?”
记住,这些操作全都是和【写操作】有关的,和【读操作】无关!!!!!
1、脏数据
当CPU写入数据后:
- 【Cache】和【主存】数据不一致的情况,那些新写入的数据就叫【脏数据】
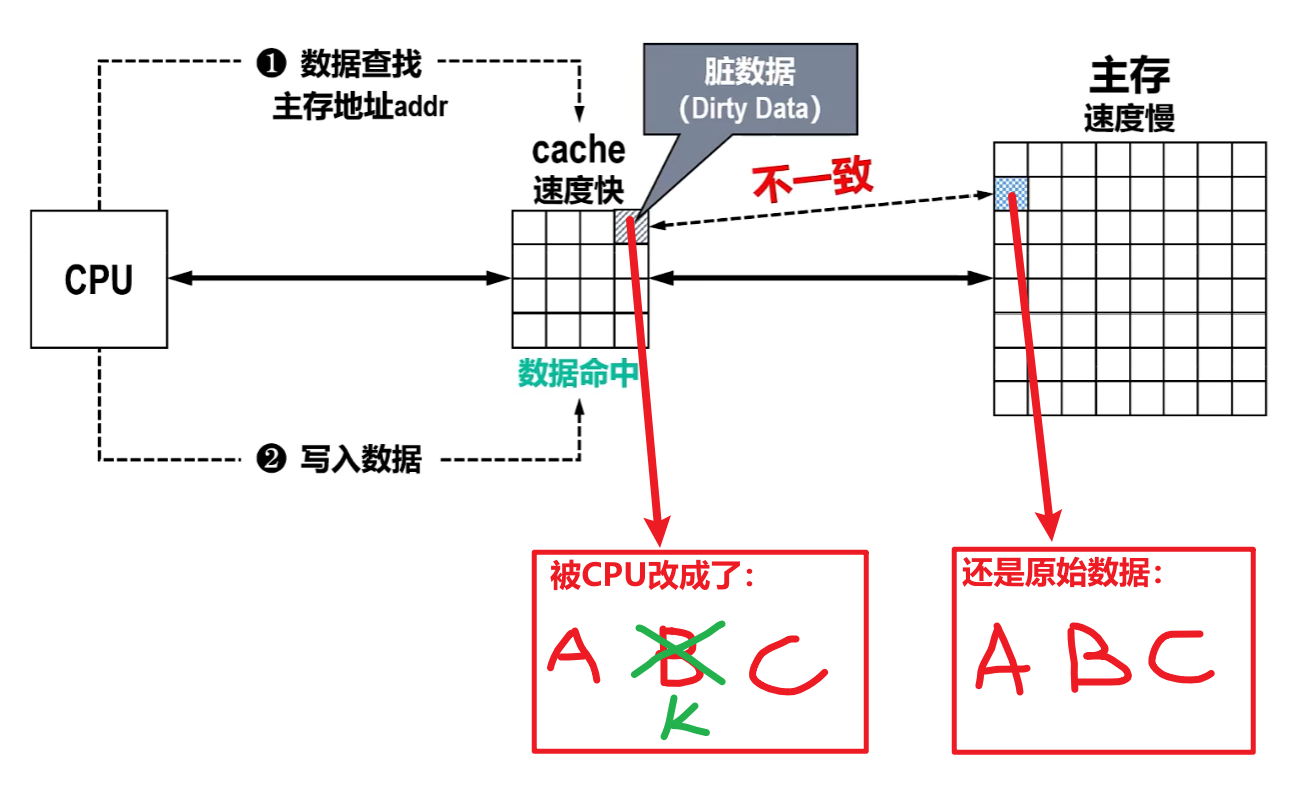
2、【写命中】情况策略(在Cache改数据)
1)全写法(直写法、写穿、Write-through)
- 人话:
- CPU直接一次性把【Cache】和【主存】一起改了!!
- 那么以后主存替换这块Cache的时候,直接换掉就行,因为自己的这个主存块也早被更新了
- 优点:没有脏数据,也就是不存在数据不一致情况
- 缺点:更新写入速度慢,一次写入又要改Cache、又要改主存,Cache效率低(增加主存访存次数)
;
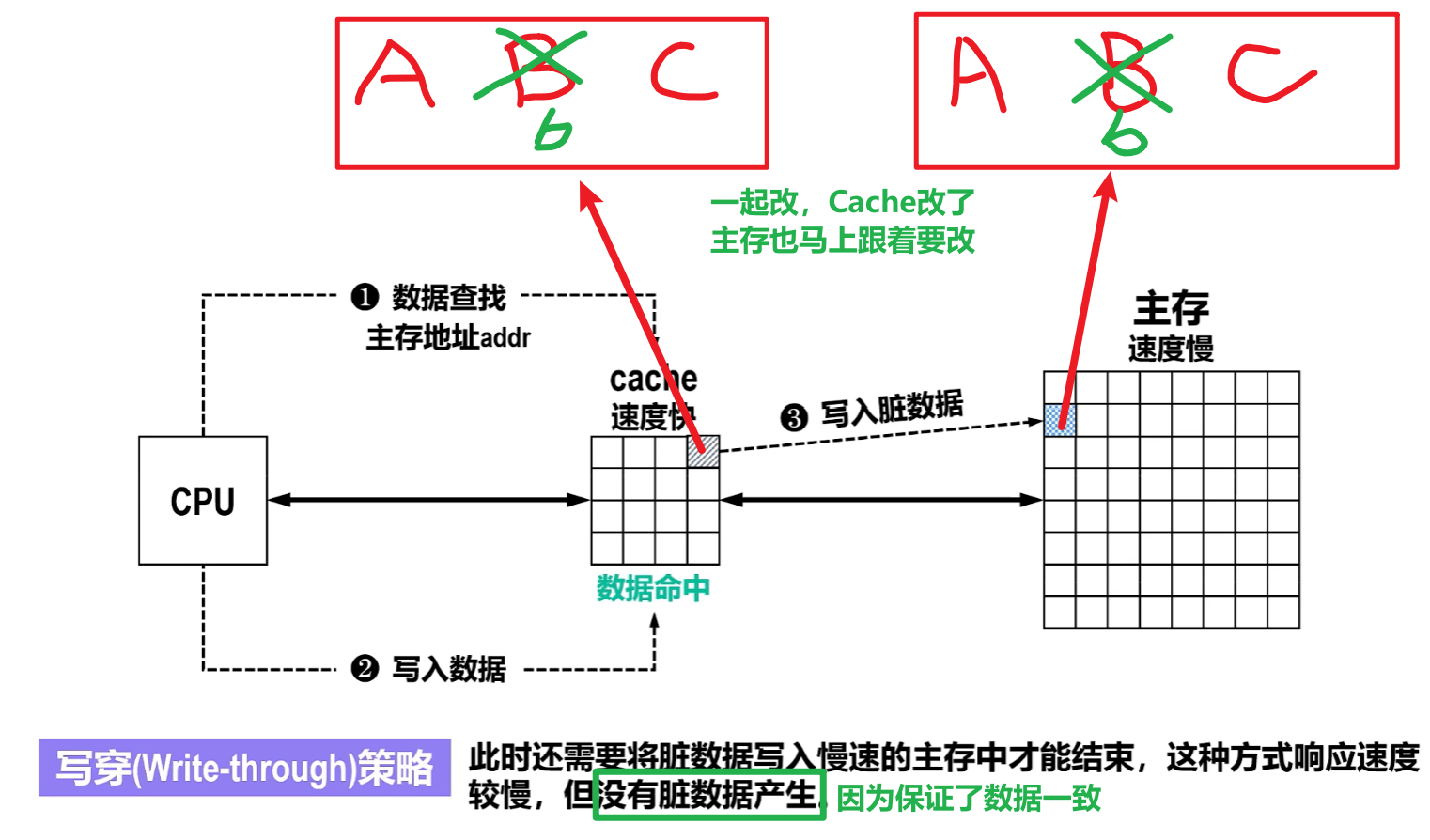
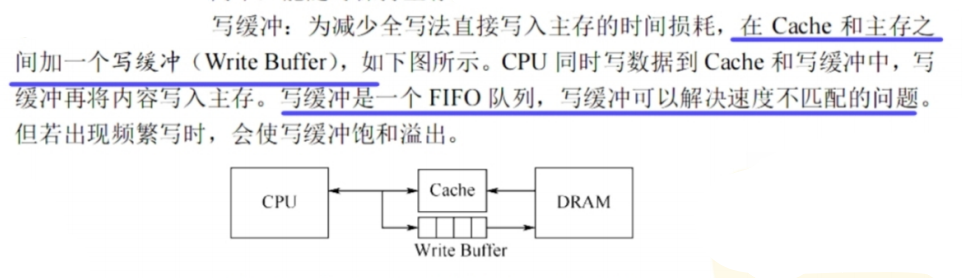
提示:但是为了解决速度慢
- 还在【Cache和主存之间】加入了【写缓冲(Write-Buffer)】
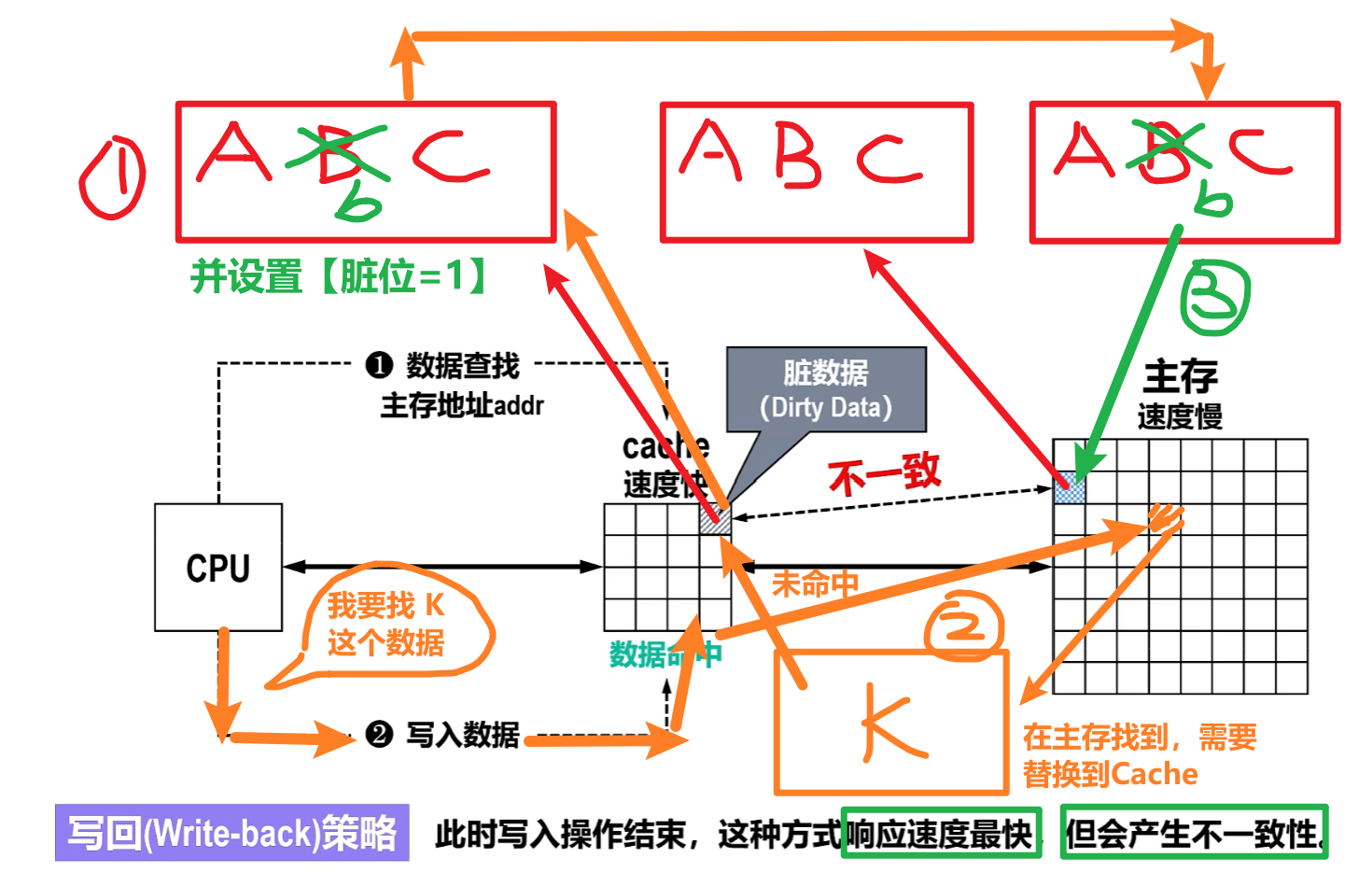
2)回写法(写回、Write-back)
- 人话:
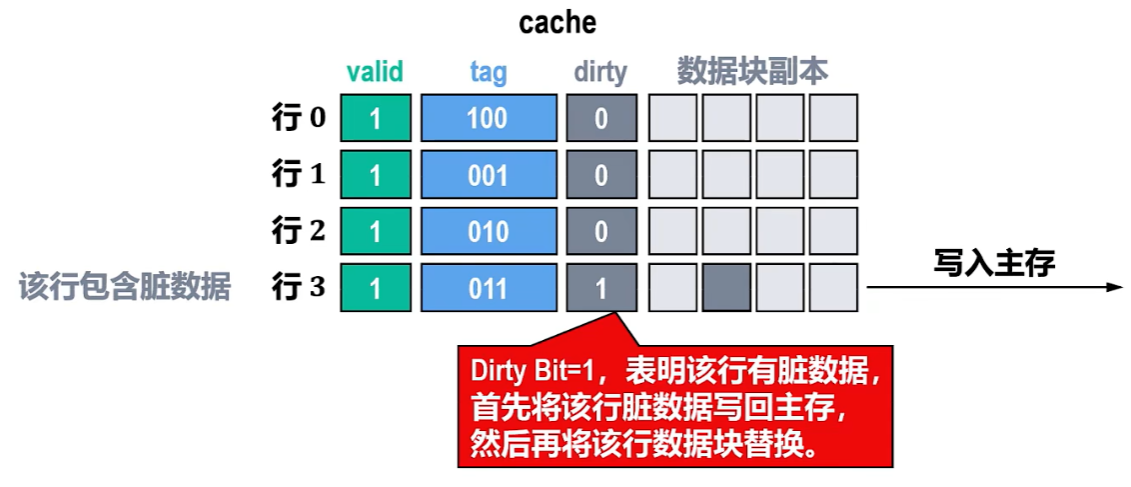
- CPU只改写【Cache】!!但是要设置【脏位=1】
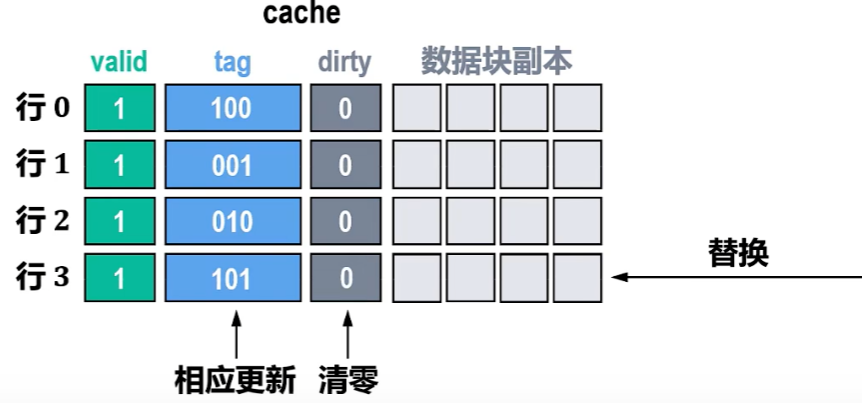
- 直到下次Cache未命中时,要把主存块【替换了刚刚的Cache块】
- 这时检查到这个Cache块【脏位=1】,然后需要把更新数据写回到主存
- 如果替换时Cache块【脏位=0】,说明这个块没有改写过,无需写回主存
- 优点:减少主存访存次数,Cache效率提高
- 缺点:会有一段时间存在数据不一致,有脏数据
3、【未写命中】情况策略(在主存改数据)
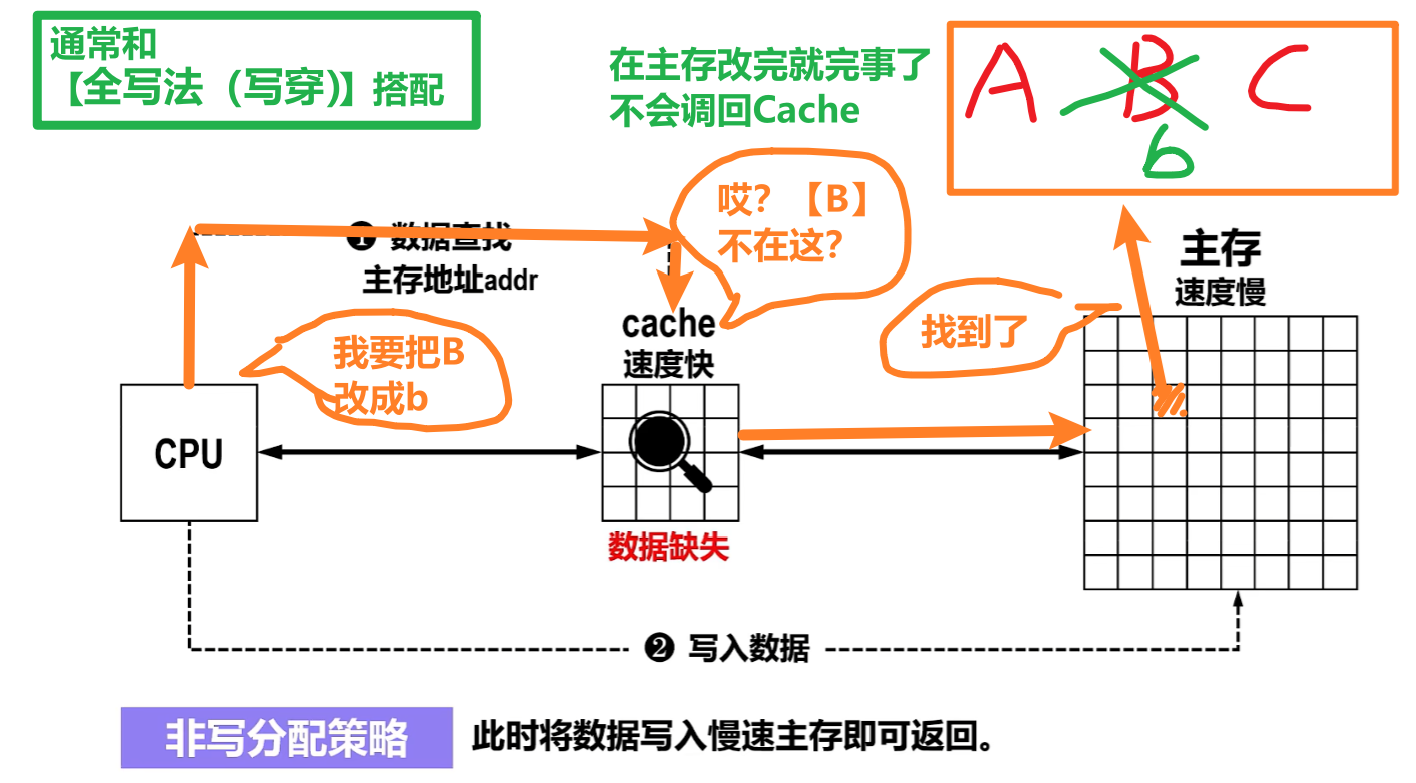
1)非写分配法(Not-Write-Allocate)
人话:
- CPU只改【主存块】
- 通常和【全写法】搭配
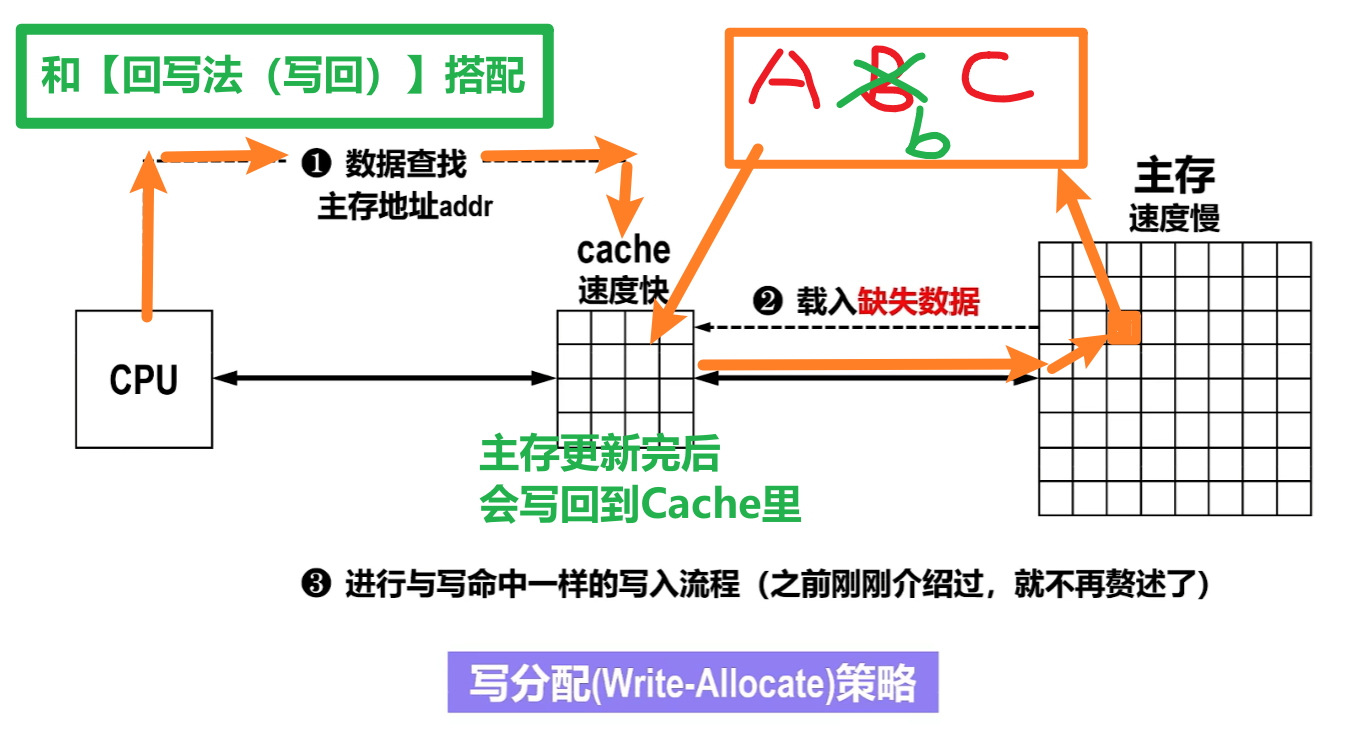
2)写分配法(Write-Allocate)
- 人话:
- CPU改完【主存块】还要改【Cache块】
- 通常和【回写法】搭配
- 优点:利用了程序的空间局部性
- 缺点:每次【写不命中】都要从主存读一块到【Cache】