CVPR 2025 | 即插即用,动态场景深度感知新SOTA!单目视频精准SLAM+深度估计
1. 【前言】
本文提出一种可从动态场景的普通单目视频中准确、快速且稳健估计相机参数和深度图的系统。该系统基于深度视觉SLAM框架,经精心修改训练和推理方案,适用于复杂动态场景的真实世界视频,包括相机视差较小的视频。其关键创新是将单目深度先验和运动概率图整合到可微分SLAM范式,分析视频中结构和相机参数的可观测性,引入不确定性感知的全局BA方案,能高效获取一致的视频深度且无需测试时网络微调。大量实验表明,该系统在相机姿态和深度估计上显著优于先前及同期研究,运行时间更快或相当。
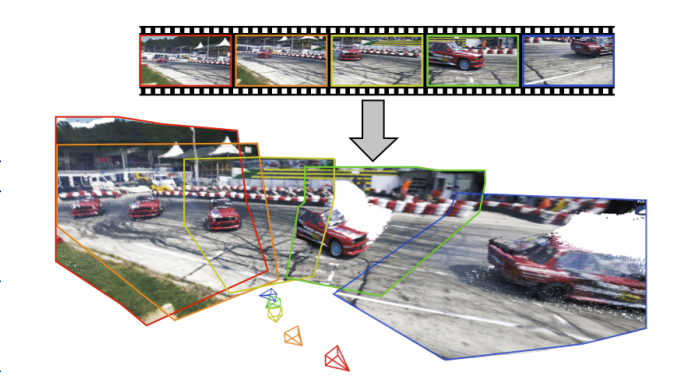
2. 【论文基本信息】

- 论文标题:MegaSaM: Accurate, Fast, and Robust Structure and Motion from Casual Dynamic Videos
- 论文链接:https://arxiv.org/abs/2412.04463
- 项目链接:https://github.com/mega-sam/mega-sam
- 核心模块:基于深度学习的可微分束平差(BA)层,运动概率图预测模块,单目深度先验整合模块,不确定性感知的全局BA方案,一致性视频深度优化模块
➔➔➔➔点击查看原文模块,以及获取更多即插即用模块合集
3. 【创新点】
3.1 整合单目深度先验与运动概率图
引入额外网络预测物体运动概率图,结合成对流动置信度形成权重,通过两阶段训练(静态预训练+动态微调)提升动态场景处理能力,增强训练稳定性。
3.2 不确定性感知的全局BA
基于拉普拉斯近似估计变量不确定性,据此动态调整单目深度正则化及焦距优化,解决相机参数约束弱时的鲁棒性问题。
3.3 高效一致的视频深度优化
固定相机参数,通过一阶优化(含流动重投影、时间一致性、深度先验损失)获取高分辨率深度,无需网络微调,采用新损失函数提升效率与精度。
3.4 改进初始化策略
训练与推理阶段均整合单目深度先验,优化视差、相机姿态及焦距初始化方式,提升有限基线和复杂动态场景下的跟踪精度。
➔➔➔➔点击查看原文模块,以及获取更多即插即用模块合集
4.【算法框架与核心模块】
4.1 算法框架
算法框架分为两个主要阶段。第一阶段为深度视觉SLAM框架,通过可微分束平差(BA)层处理输入的单目动态视频,完成相机参数(姿态、焦距)和低分辨率视差的估计,期间整合单目深度先验进行初始化,并借助两阶段训练学习动态场景中的运动概率;第二阶段在已知相机参数的情况下,通过一阶优化获取高分辨率且一致的视频深度。整体流程通过不确定性感知的全局BA方案提升稳健性,最终输出相机参数和一致的视频深度。
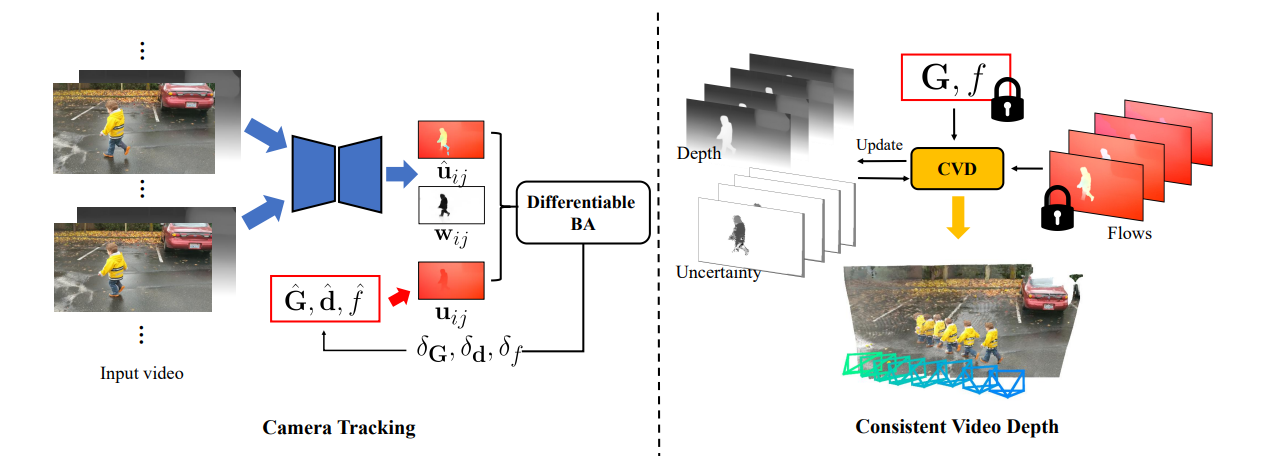
4.2 核心模块
4.2.1 深度视觉SLAM模块
- 功能:估计相机参数(姿态G^i∈SE(3)\hat{G}_i \in SE(3)G^i∈SE(3)、焦距f^\hat{f}f^)和低分辨率视差d^i\hat{d}_id^i。
- 核心公式:
- 2D对应场及置信度预测:(u^ijk+1,w^ijk+1)=F(Ii,Ij,u^ijk,w^ijk)(\hat{u}_{ij}^{k+1}, \hat{w}_{ij}^{k+1}) = F(I_i, I_j, \hat{u}_{ij}^k, \hat{w}_{ij}^k)(u^ijk+1,w^ijk+1)=F(Ii,Ij,u^ijk,w^ijk)
- 刚性运动对应场推导:uij=π(G^ij∘π−1(pi,d^i,K−1),K)u_{ij} = \pi\left(\hat{G}_{ij} \circ \pi^{-1}(p_i, \hat{d}_i, K^{-1}), K\right)uij=π(G^ij∘π−1(pi,d^i,K−1),K)
- 优化目标:C(G^,d^,f^)=∑(i,j)∈P∥u^ij−uij∥∑ij2\mathcal{C}(\hat{G}, \hat{d}, \hat{f}) = \sum_{(i,j) \in \mathcal{P}} \|\hat{u}_{ij} - u_{ij}\|_{\sum_{ij}}^2C(G^,d^,f^)=∑(i,j)∈P∥u^ij−uij∥∑ij2,其中权重∑ij=diag(w^ij)−1\sum_{ij} = \text{diag}(\hat{w}_{ij})^{-1}∑ij=diag(w^ij)−1
4.2.2 运动概率学习模块
- 功能:通过两阶段训练预测运动概率图mim_imi,优化动态场景下的跟踪性能。
- 核心公式:
- 权重调整:w~ij=w^ij⋅mi\tilde{w}_{ij} = \hat{w}_{ij} \cdot m_iw~ij=w^ij⋅mi
- 训练损失:Ldynamic=Lcam+wmotionLCE\mathcal{L}_{\text{dynamic}} = \mathcal{L}_{\text{cam}} + w_{\text{motion}} \mathcal{L}_{\text{CE}}Ldynamic=Lcam+wmotionLCE
4.2.3 不确定性感知全局BA模块
- 功能:基于参数不确定性调整优化策略,提升系统稳健性。
- 核心公式:
- 不确定性近似:∑θ≈diag(−H(θ∗)−1)\sum_{\theta} \approx \text{diag}(-H(\theta^*)^{-1})∑θ≈diag(−H(θ∗)−1)
- 正则化权重设置:wd=γdexp(βd⋅med(diag(Hd)))w_d = \gamma_d \exp(\beta_d \cdot \text{med}(\text{diag}(H_d)))wd=γdexp(βd⋅med(diag(Hd)))
4.2.4 一致深度优化模块
- 功能:在已知相机参数时,获取高分辨率一致深度。
- 核心公式:
- 优化目标:Ccvd=wflowCflow+wtempCtemp+wpriorCprior\mathcal{C}_{\text{cvd}} = w_{\text{flow}} \mathcal{C}_{\text{flow}} + w_{\text{temp}} \mathcal{C}_{\text{temp}} + w_{\text{prior}} \mathcal{C}_{\text{prior}}Ccvd=wflowCflow+wtempCtemp+wpriorCprior
- 深度先验损失:Cprior=Csi+wgradCgrad+wnormalCnormal\mathcal{C}_{\text{prior}} = \mathcal{C}_{\text{si}} + w_{\text{grad}} \mathcal{C}_{\text{grad}} + w_{\text{normal}} \mathcal{C}_{\text{normal}}Cprior=Csi+wgradCgrad+wnormalCnormal
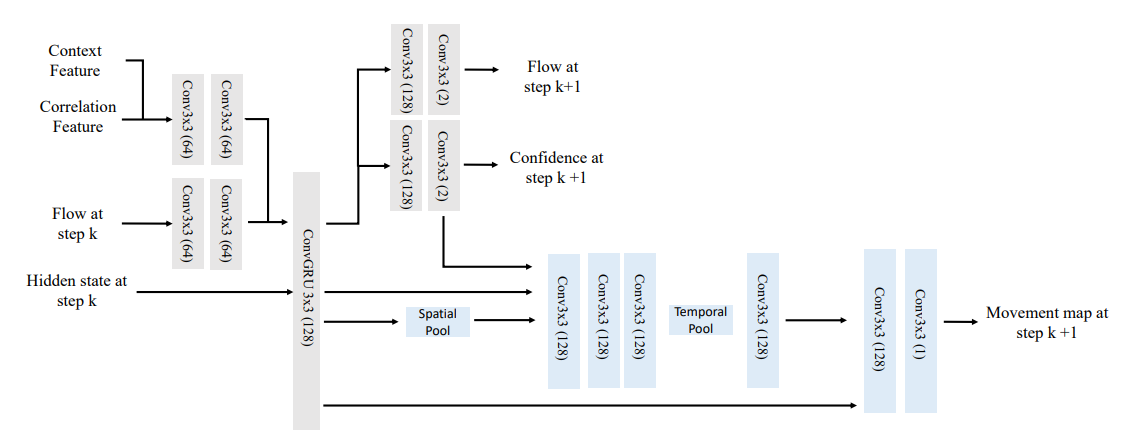
4.3 模块配置
- 深度视觉SLAM模块:使用Adam优化器,在静态合成数据上预训练时学习ego-motion诱导的流动及置信度,动态微调阶段冻结预训练参数。
- 不确定性感知BA模块:设置γd=1×10−4\gamma_d = 1 \times 10^{-4}γd=1×10−4,βd=0.05\beta_d = 0.05βd=0.05,τf=50\tau_f = 50τf=50,根据参数可观测性动态调整正则化与焦距优化。
- 一致深度优化模块:采用一阶优化,迭代500步(含100步warm-up),设置wflow=1.0w_{\text{flow}} = 1.0wflow=1.0,wtemp=0.2w_{\text{temp}} = 0.2wtemp=0.2,wprior=1.0w_{\text{prior}} = 1.0wprior=1.0。
➔➔➔➔点击查看原文模块,以及获取更多即插即用模块合集
5.【适用任务】
5.1 动态场景下的相机参数估计
- 适用场景:适用于从手持设备拍摄的动态场景单目视频中估计相机姿态、焦距等参数,尤其在场景存在复杂运动物体且相机视差有限的情况下。
- 核心作用:通过整合单目深度先验和两阶段训练方案,提升相机参数估计的准确性和稳健性,解决传统方法在有限视差和动态场景中跟踪精度不足的问题。
5.2 动态场景的视频深度估计
- 适用场景:适用于在已知相机参数时,从单目动态视频中获取高分辨率且时间一致的深度信息,可应用于机器人导航、增强现实等需精确深度感知的领域。
- 核心作用:通过一阶优化及特定损失函数,快速得到准确的深度估计,无需耗时的网络微调,提升深度估计效率与精度。
5.3 复杂动态场景的SLAM系统构建
- 适用场景:适用于构建在相机参数受输入视频约束较弱时仍能保持稳健性的SLAM系统,如在室内动态环境、相机移动范围有限的场景中。
- 核心作用:借助不确定性感知的全局BA方案,动态调整正则化和优化策略,增强系统在参数约束较弱时的稳定性,提升SLAM系统整体性能。
5.4 动态场景的3D重建任务
- 适用场景:适用于从单目动态视频中重建动态场景的3D结构,可用于文物数字化、场景还原等领域。
- 核心作用:结合相机跟踪与深度估计结果,构建场景的3D结构,利用多模块协同工作提升重建精度和效率,准确还原动态场景的空间结构。
➔➔➔➔点击查看原文模块,以及获取更多即插即用模块合集
6.【实验结果与可视化分析】
6.1 实验设置与基准方法
-
实现细节:训练采用两阶段方案,先在静态场景的合成数据(163个TartanAir场景和5K个静态Kubric视频)上预训练模型,再在11K个Kubric动态视频上微调运动模块(F_m)。训练示例为7帧视频序列,设置了相应的权重参数,训练耗时约4天(使用8个Nvidia 80G A100)。推理阶段在不同模块也有对应的参数设置,平均运行速度在特定分辨率下为1.3 FPS。
-
基准方法:比较了多种相机姿态估计方法,如ACE-Zero、CasualSAM、RoDynRF、Particle-SfM、LEAP-VO、MonST3R等;深度估计方面,对比了CasualSAM、MonST3R、VideoCrafter以及DepthAnything-V2的原始单目深度。所有基准方法均使用其开源实现,在同一台配备单个Nvidia A100 GPU的机器上运行。
-
数据集与指标:使用了MPI Sintel、DyCheck、In-the-Wild等数据集。评估相机姿态估计采用绝对平移误差(ATE)、相对平移误差(RTE)、相对旋转误差(RRE);评估深度估计采用绝对相对误差(abs-rel)、对数均方根误差(log-rmse)、Delta准确率(delta1.25)(delta_{1.25})(delta1.25)等指标,并遵循相应的评估协议。
6.2 定量比较结果
-
相机姿态估计:在Sintel、DyCheck、In-the-Wild三个数据集上,无论是校准(已知焦距)还是未校准(未知焦距)设置,MegaSaM在ATE、RTE、RRE等所有误差指标上均显著优于其他基准方法,同时运行时间具有竞争力。例如在Sintel数据集未校准情况下,MegaSaM的ATE为0.023,远低于CasualSAM的0.067;在DyCheck数据集校准情况下,其ATE为0.020,优于ACE-Zero的0.062等。
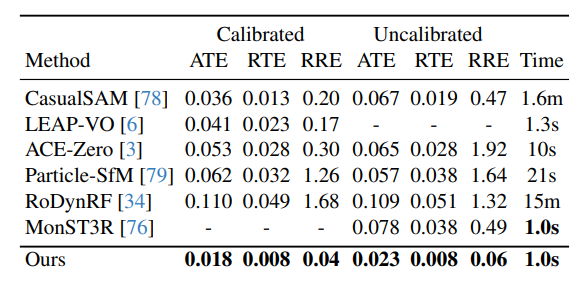
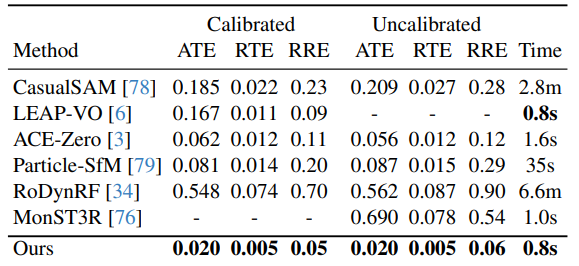
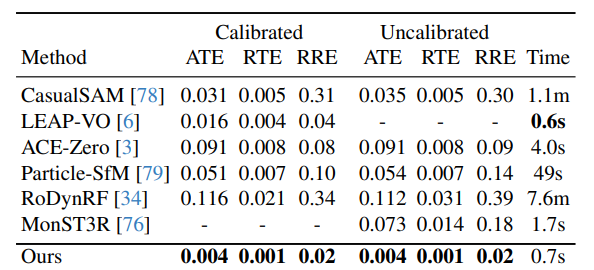
-
深度估计:在Sintel和Dycheck数据集上,MegaSaM的深度估计结果在abs-rel、log-rmse、(delta1.25)(delta_{1.25})(delta1.25)等指标上也大幅领先于其他方法。如在Sintel数据集上,其abs-rel为0.21,低于DA-v2的0.37、CasualSAM的0.31等;在Dycheck数据集上,(delta1.25)(delta_{1.25})(delta1.25)达到94.1,远高于其他方法。
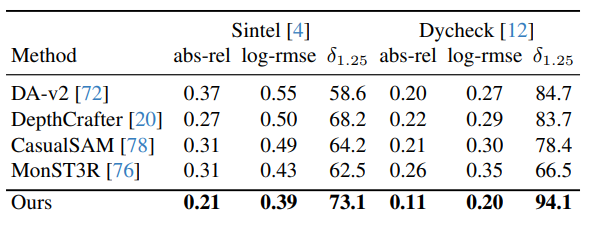
6.3 消融研究结果
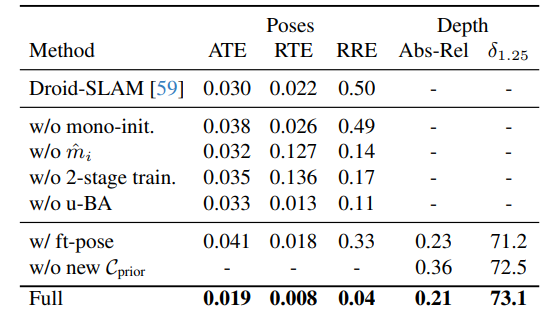
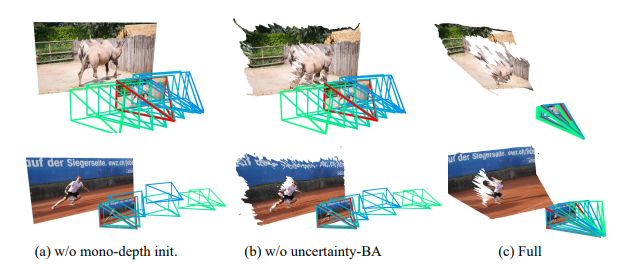
- 对相机跟踪和深度估计模块的主要设计选择进行了验证,评估了不同配置下的性能。结果显示,完整系统(Full)在相机姿态估计的ATE、RTE、RRE以及深度估计的Abs-Rel、(delta1.25)(delta_{1.25})(delta1.25)等指标上均优于其他替代配置,如没有单目深度初始化(w/o mono-init.)、没有物体运动图预测(w/o (hatmihat{m}_ihatmi))等情况。
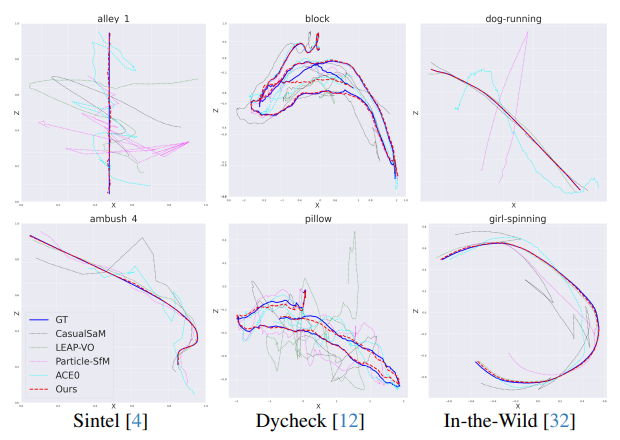
6.4 定性比较结果
-
相机轨迹:在三个基准数据集上的2D相机轨迹估计 qualitative 比较显示,MegaSaM的相机估计值最接近地面真值。
-
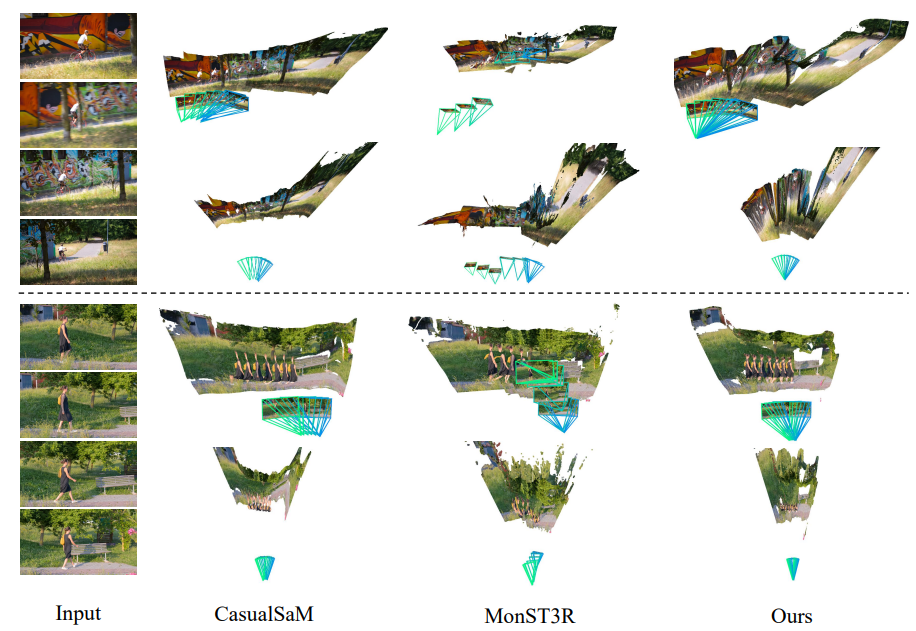
视频深度:与CasualSAM和MonST3R相比,MegaSaM生成的视频深度图更准确、详细且在时间上更一致,通过参考帧的深度图和相应的x-t切片可视化得到验证。

-
具有挑战性的示例:在DAVIS的具有旋转主导相机运动和窄视场的示例中,CasualSaM倾向于产生扭曲的3D点云,MonST3R会错误地将旋转相机运动视为平移运动,而MegaSaM能产生更准确的相机和更一致的几何结构估计。
➔➔➔➔点击查看原文模块,以及获取更多即插即用模块合集
7.【即插即用模块代码】
7.1 DropPath模块模块
功能:实现随机深度(Stochastic Depth)功能,在训练时随机丢弃部分残差路径,以减少过拟合,提高模型泛化能力。支持对不同维度的张量进行处理,适用于残差块结构中。
核心代码段(即插即用关键):
def drop_path(x, drop_prob: float = 0.0, training: bool = False):if drop_prob == 0.0 or not training:return xkeep_prob = 1 - drop_probshape = (x.shape[0],) + (1,) * (x.ndim - 1) # 适配不同维度张量random_tensor = x.new_empty(shape).bernoulli_(keep_prob)if keep_prob > 0.0:random_tensor.div_(keep_prob)output = x * random_tensorreturn outputclass DropPath(nn.Module):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""def __init__(self, drop_prob=None):super(DropPath, self).__init__()self.drop_prob = drop_probdef forward(self, x):return drop_path(x, self.drop_prob, self.training)
即插即用优势:
- 轻量级实现,代码简洁,仅通过张量乘法实现路径丢弃,计算开销小。
- 适配任意维度的输入张量,不仅限于2D卷积网络,可广泛应用于Transformer等不同结构。
- 作为独立模块,可直接插入到残差连接中,无需修改其他网络结构,使用灵活。
7.2 SwiGLU激活函数模块
功能:实现SwiGLU(Swish-Gated Linear Unit)激活函数,结合Swish激活函数和门控机制,增强模型的非线性表达能力,常用于Transformer的前馈网络中。
核心代码段(即插即用关键):
class SwiGLUFFN(nn.Module):def __init__(self,in_features: int,hidden_features: Optional[int] = None,out_features: Optional[int] = None,act_layer: Callable[..., nn.Module] = None,drop: float = 0.0,bias: bool = True,) -> None:super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.w12 = nn.Linear(in_features, 2 * hidden_features, bias=bias)self.w3 = nn.Linear(hidden_features, out_features, bias=bias)def forward(self, x: Tensor) -> Tensor:x12 = self.w12(x)x1, x2 = x12.chunk(2, dim=-1)hidden = F.silu(x1) * x2return self.w3(hidden)class SwiGLUFFNFused(SwiGLU): # 当xformers可用时的融合实现def __init__(self,in_features: int,hidden_features: Optional[int] = None,out_features: Optional[int] = None,act_layer: Callable[..., nn.Module] = None,drop: float = 0.0,bias: bool = True,) -> None:out_features = out_features or in_featureshidden_features = hidden_features or in_featureshidden_features = (int(hidden_features * 2 / 3) + 7) // 8 * 8super().__init__(in_features=in_features,hidden_features=hidden_features,out_features=out_features,bias=bias,)
即插即用优势:
- 提供基础实现和基于xformers的融合加速实现,可根据环境自动选择,兼顾兼容性和性能。
- 无需依赖复杂外部库(基础版本),直接继承nn.Module,可无缝替换传统MLP中的激活函数模块。
- 结构紧凑,仅通过两个线性层和简单的张量操作实现,易于嵌入到各类网络结构中。
7.3 注意力机制模块
功能:实现多头自注意力机制,包括标准注意力(Attention)和内存高效注意力(MemEffAttention),用于捕获输入序列中的长距离依赖关系,是Transformer架构的核心组件。
核心代码段(即插即用关键):
class Attention(nn.Module):def __init__(self,dim: int,num_heads: int = 8,qkv_bias: bool = False,proj_bias: bool = True,attn_drop: float = 0.0,proj_drop: float = 0.0,) -> None:super().__init__()self.num_heads = num_headshead_dim = dim // num_headsself.scale = head_dim **-0.5self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim, bias=proj_bias)self.proj_drop = nn.Dropout(proj_drop)def forward(self, x: Tensor) -> Tensor:B, N, C = x.shapeqkv = (self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4))q, k, v = qkv[0] * self.scale, qkv[1], qkv[2]attn = q @ k.transpose(-2, -1)attn = attn.softmax(dim=-1)attn = self.attn_drop(attn)x = (attn @ v).transpose(1, 2).reshape(B, N, C)x = self.proj(x)x = self.proj_drop(x)return xclass MemEffAttention(Attention):def forward(self, x: Tensor, attn_bias=None) -> Tensor:if not XFORMERS_AVAILABLE:assert attn_bias is None, "xFormers is required for nested tensors usage"return super().forward(x)B, N, C = x.shapeqkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads)q, k, v = unbind(qkv, 2)x = memory_efficient_attention(q, k, v, attn_bias=attn_bias)x = x.reshape([B, N, C])x = self.proj(x)x = self.proj_drop(x)return x
即插即用优势:
- 提供两种实现方式,标准注意力保证兼容性,内存高效注意力(依赖xformers)可优化显存占用和计算速度。
- 参数配置灵活,支持自定义头数、偏置设置、dropout概率等,适配不同场景需求。
- 作为独立模块,可直接替换其他注意力实现,或嵌入到Transformer块、卷积网络等结构中,增强模型对长距离依赖的捕捉能力。
7.4 图像分块嵌入模块
功能:将2D图像分割为非重叠的补丁(patch),并通过线性投影将每个补丁转换为特征向量,实现图像到序列的转换,是视觉Transformer(ViT)的基础组件。
核心代码段(即插即用关键):
class PatchEmbed(nn.Module):"""2D image to patch embedding: (B,C,H,W) -> (B,N,D)"""def __init__(self,img_size: Union[int, Tuple[int, int]] = 224,patch_size: Union[int, Tuple[int, int]] = 16,in_chans: int = 3,embed_dim: int = 768,norm_layer: Optional[Callable] = None,flatten_embedding: bool = True,) -> None:super().__init__()image_HW = make_2tuple(img_size)patch_HW = make_2tuple(patch_size)patch_grid_size = (image_HW[0] // patch_HW[0], image_HW[1] // patch_HW[1])self.img_size = image_HWself.patch_size = patch_HWself.patches_resolution = patch_grid_sizeself.num_patches = patch_grid_size[0] * patch_grid_size[1]self.in_chans = in_chansself.embed_dim = embed_dimself.flatten_embedding = flatten_embeddingself.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_HW, stride=patch_HW)self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()def forward(self, x: Tensor) -> Tensor:_, _, H, W = x.shapepatch_H, patch_W = self.patch_sizeassert H % patch_H == 0 and W % patch_W == 0, "Image size must be multiple of patch size"x = self.proj(x) # B C H WH, W = x.size(2), x.size(3)x = x.flatten(2).transpose(1, 2) # B HW Cx = self.norm(x)if not self.flatten_embedding:x = x.reshape(-1, H, W, self.embed_dim) # B H W Creturn x
即插即用优势:
- 支持任意图像尺寸和补丁尺寸(需满足图像尺寸是补丁尺寸的整数倍),通过
make_2tuple函数适配整数或元组输入。 - 提供是否展平嵌入结果的选项,可根据后续网络需求输出序列形式(B, N, D)或空间网格形式(B, H, W, D)。
- 核心逻辑通过卷积层实现,计算高效,且包含可选的归一化层,可直接作为视觉Transformer的输入层,或用于其他需要图像分块处理的场景。
7.5 层缩放模块
功能:对输入张量进行逐通道缩放,通过学习的缩放因子增强或减弱特定通道的特征,有助于稳定训练过程,尤其在深层网络中效果明显。
核心代码段(即插即用关键):
class LayerScale(nn.Module):def __init__(self,dim: int,init_values: Union[float, Tensor] = 1e-5,inplace: bool = False,) -> None:super().__init__()self.inplace = inplaceself.gamma = nn.Parameter(init_values * torch.ones(dim))def forward(self, x: Tensor) -> Tensor:return x.mul_(self.gamma) if self.inplace else x * self.gamma
即插即用优势:
- 实现极简,仅包含一个可学习的参数向量,计算成本可忽略不计。
- 支持原地操作(inplace),可节省显存,且不改变输入张量的形状和维度,易于插入到网络的任意层之后。
- 初始化缩放因子较小(默认1e-5),对初始训练影响小,随着训练自动调整各通道权重,有助于深层网络的收敛。
➔➔➔➔点击查看原文模块,以及获取更多即插即用模块合集