C++ 应用场景全景解析:从系统级到AI的跨越式演进

🌟 Hello,我是蒋星熠Jaxonic!
🌈 在浩瀚无垠的技术宇宙中,我是一名执着的星际旅人,用代码绘制探索的轨迹。
🚀 每一个算法都是我点燃的推进器,每一行代码都是我航行的星图。
🔭 每一次性能优化都是我的天文望远镜,每一次架构设计都是我的引力弹弓。
🎻 在数字世界的协奏曲中,我既是作曲家也是首席乐手。让我们携手,在二进制星河中谱写属于极客的壮丽诗篇!
摘要
作为一名在C++宇宙中航行了十余年的星际旅人,我见证了这门语言从"系统级王者"到"全场景通用"的华丽蜕变。记得2012年初入职场时,我参与的第一个项目是一个高频交易系统的核心撮合引擎,那时C++给我的印象就是指针、内存管理和无尽的调试噩梦。然而,当我亲手将交易延迟从毫秒级优化到微秒级,看到系统在高并发场景下依然稳如磐石时,我真正领悟到了C++的精髓——极致的性能控制与零成本抽象。
这十年间,我亲历了C++在游戏引擎、金融科技、自动驾驶、人工智能、区块链等前沿领域的深度应用。每一次技术突破都像是在星图上点亮了一颗新星:从Unreal Engine 5的Nanite虚拟几何系统,到高频交易中的纳秒级撮合算法;从TensorFlow的核心计算引擎,到自动驾驶的实时感知系统;从比特币的底层加密算法,到现代浏览器的JavaScript引擎。C++就像是一把瑞士军刀,在不同领域都能发挥出令人惊叹的威力。
在这篇文章中我会深入剖析C++17/20/23标准带来的革命性特性,探讨智能指针、并发模型、模板元编程等现代C++技术如何在实际项目中化繁为简,以及如何通过C++实现从硬件到软件的全栈性能优化。无论你是系统编程的老兵,还是AI开发的新秀,相信这篇文章都能为你打开一扇通往C++新世界的大门。
一、系统级开发:操作系统与驱动的基石
1.1 操作系统内核的C++实践
现代操作系统内核开发中,C++凭借其零成本抽象和精细的内存控制,正在逐步替代传统的C语言。让我分享一个实际案例:在Linux内核模块开发中,我们如何利用C++20的concepts和ranges来构建类型安全的设备驱动框架。
// 设备驱动概念约束
#include <concepts>
#include <type_traits>// 定义设备操作概念
template<typename T>
concept DeviceOperations = requires(T t) {{ t.read() } -> std::same_as<size_t>;{ t.write(std::span<const uint8_t>) } -> std::same_as<bool>;{ t.ioctl(uint32_t, void*) } -> std::same_as<int>;
};// 基于概念的设备驱动模板
template<DeviceOperations Device>
class KernelDeviceDriver {
private:Device device_;std::atomic<bool> is_open_{false};public:int open() {if (is_open_.exchange(true)) {return -EBUSY;}return device_.init() ? 0 : -EIO;}ssize_t read(char* buffer, size_t size) {if (!is_open_) return -EBADF;auto data = device_.read();return std::min(data, size);}// 其他操作...
};// 具体设备实现
class SerialDevice {
public:bool init() { // 初始化串口硬件return configure_uart(115200, 8, 'N', 1); }size_t read() {// 从串口缓冲区读取数据return uart_receive_buffer();}bool write(std::span<const uint8_t> data) {// 写入串口return uart_transmit(data.data(), data.size());}int ioctl(uint32_t cmd, void* arg) {// 处理设备控制命令switch(cmd) {case TCGETS: return get_termios(arg);case TCSETS: return set_termios(arg);default: return -ENOTTY;}}
};// 实例化驱动
using SerialDriver = KernelDeviceDriver<SerialDevice>;
关键点评:
- 第3-8行:使用C++20 concepts定义设备操作约束,确保类型安全
- 第10-26行:模板驱动类提供通用的内核设备接口
- 第28-52行:具体的串口设备实现满足概念约束
- 第54行:通过模板实例化生成类型安全的串口驱动
1.2 内存管理与性能优化
在系统级开发中,内存管理的效率直接影响系统性能。现代C++通过智能指针和自定义分配器,实现了既安全又高效的内存管理。
#include <memory>
#include <new>
#include <cstdint>// 内核级内存池分配器
template<size_t BlockSize, size_t PoolSize>
class KernelMemoryPool {
private:alignas(std::max_align_t) uint8_t pool_[PoolSize * BlockSize];std::atomic<uint8_t*> free_list_;public:KernelMemoryPool() {// 初始化空闲链表uint8_t* current = pool_;for (size_t i = 0; i < PoolSize - 1; ++i) {*reinterpret_cast<uint8_t**>(current) = current + BlockSize;current += BlockSize;}*reinterpret_cast<uint8_t**>(current) = nullptr;free_list_.store(pool_);}void* allocate() {uint8_t* block = free_list_.load(std::memory_order_acquire);while (block != nullptr) {uint8_t* next = *reinterpret_cast<uint8_t**>(block);if (free_list_.compare_exchange_weak(block, next)) {return block;}}throw std::bad_alloc{};}void deallocate(void* ptr) {if (!ptr) return;uint8_t* block = static_cast<uint8_t*>(ptr);uint8_t* old_head = free_list_.load(std::memory_order_relaxed);do {*reinterpret_cast<uint8_t**>(block) = old_head;} while (!free_list_.compare_exchange_weak(old_head, block));}
};// 使用示例
using KernelAllocator = KernelMemoryPool<64, 1024>;class NetworkPacket {
private:static KernelAllocator allocator_;public:void* operator new(size_t size) {return allocator_.allocate();}void operator delete(void* ptr) {allocator_.deallocate(ptr);}// 网络包数据...
};
二、游戏引擎:实时渲染的性能巅峰
2.1 现代游戏引擎架构
现代游戏引擎如Unreal Engine 5和Unity的底层都是C++实现,通过组件化架构实现高性能渲染。让我们看看如何使用C++20的模块化特性构建可扩展的游戏引擎。
// 实体组件系统(ECS)架构
#include <entt/entity/registry.hpp>
#include <glm/glm.hpp>
#include <memory>// 变换组件
struct TransformComponent {glm::vec3 position{0.0f};glm::vec3 rotation{0.0f};glm::vec3 scale{1.0f};glm::mat4 get_matrix() const {return glm::translate(glm::mat4(1.0f), position) *glm::rotate(glm::mat4(1.0f), rotation.y, glm::vec3(0, 1, 0)) *glm::scale(glm::mat4(1.0f), scale);}
};// 渲染组件
struct RenderComponent {std::shared_ptr<Mesh> mesh;std::shared_ptr<Material> material;uint32_t render_layer = 0;
};// 物理组件
struct PhysicsComponent {glm::vec3 velocity{0.0f};glm::vec3 acceleration{0.0f};float mass = 1.0f;bool is_static = false;
};// 游戏世界系统
class GameWorld {
private:entt::registry registry_;public:// 创建实体entt::entity create_entity() {return registry_.create();}// 添加组件template<typename Component, typename... Args>Component& add_component(entt::entity entity, Args&&... args) {return registry_.emplace<Component>(entity, std::forward<Args>(args)...);}// 渲染系统void render_system() {auto view = registry_.view<TransformComponent, RenderComponent>();// 按渲染层排序std::vector<std::pair<entt::entity, float>> render_queue;view.each([&](auto entity, const TransformComponent& transform, const RenderComponent& render) {float distance = glm::length(transform.position);render_queue.emplace_back(entity, distance);});std::sort(render_queue.begin(), render_queue.end(), [](const auto& a, const auto& b) { return a.second > b.second; });// 执行渲染for (const auto& [entity, distance] : render_queue) {const auto& transform = registry_.get<TransformComponent>(entity);const auto& render = registry_.get<RenderComponent>(entity);render.mesh->render(transform.get_matrix(), *render.material);}}// 物理系统void physics_system(float delta_time) {auto view = registry_.view<TransformComponent, PhysicsComponent>();view.each([&](auto entity, TransformComponent& transform, PhysicsComponent& physics) {if (physics.is_static) return;// 更新物理状态physics.velocity += physics.acceleration * delta_time;transform.position += physics.velocity * delta_time;// 简单的碰撞检测if (transform.position.y < 0.0f) {transform.position.y = 0.0f;physics.velocity.y = -physics.velocity.y * 0.8f; // 弹性碰撞}});}
};
2.2 多线程渲染管线
现代游戏需要充分利用多核CPU,C++20的协程和并行算法为此提供了强大支持。
#include <execution>
#include <future>
#include <coroutine>
#include <vector>// 异步资源加载
task<std::shared_ptr<Texture>> load_texture_async(const std::string& path) {co_await std::suspend_never{}; // 模拟异步加载auto texture = std::make_shared<Texture>();texture->load_from_file(path);co_return texture;
}// 并行渲染命令生成
void generate_render_commands(const std::vector<RenderObject>& objects) {std::vector<RenderCommand> commands(objects.size());std::transform(std::execution::par_unseq, objects.begin(), objects.end(), commands.begin(), [](const RenderObject& obj) {RenderCommand cmd;cmd.mesh = obj.mesh;cmd.material = obj.material;cmd.transform = obj.calculate_transform();return cmd;});// 批量提交渲染命令render_backend.submit_commands(commands);
}
三、金融科技:高频交易的纳秒级优化
3.1 超低延迟交易系统
在高频交易领域,每一纳秒的优化都可能带来数百万美元的收益。C++的确定性性能和精确内存控制使其成为唯一选择。
#include <atomic>
#include <chrono>
#include <immintrin.h>// 无锁环形缓冲区
template<typename T, size_t Size>
class LockFreeRingBuffer {static_assert((Size & (Size - 1)) == 0, "Size must be power of 2");alignas(64) std::atomic<size_t> head_{0};alignas(64) std::atomic<size_t> tail_{0};alignas(64) T buffer_[Size];public:bool push(const T& value) {size_t head = head_.load(std::memory_order_relaxed);size_t next_head = (head + 1) & (Size - 1);if (next_head == tail_.load(std::memory_order_acquire)) {return false; // 缓冲区满}buffer_[head] = value;head_.store(next_head, std::memory_order_release);return true;}bool pop(T& value) {size_t tail = tail_.load(std::memory_order_relaxed);if (tail == head_.load(std::memory_order_acquire)) {return false; // 缓冲区空}value = buffer_[tail];tail_.store((tail + 1) & (Size - 1), std::memory_order_release);return true;}
};// 订单撮合引擎
class MatchingEngine {
private:LockFreeRingBuffer<Order, 4096> buy_orders_;LockFreeRingBuffer<Order, 4096> sell_orders_;// 使用SIMD优化价格匹配__m256i price_levels_[256];public:void process_order(const Order& order) {auto start = std::chrono::high_resolution_clock::now();if (order.side == Side::Buy) {match_buy_order(order);} else {match_sell_order(order);}auto end = std::chrono::high_resolution_clock::now();auto latency = std::chrono::duration_cast<std::chrono::nanoseconds>(end - start);// 记录纳秒级延迟metrics_.record_latency(latency.count());}private:void match_buy_order(const Order& buy_order) {// 使用AVX2指令集加速价格匹配__m256i buy_price = _mm256_set1_epi32(buy_order.price);for (int i = 0; i < 256; i += 8) {__m256i prices = _mm256_load_si256(&price_levels_[i]);__m256i cmp = _mm256_cmpgt_epi32(buy_price, prices);if (_mm256_movemask_epi8(cmp)) {// 找到匹配的价格execute_trade(buy_order, i + __builtin_ctz(_mm256_movemask_epi8(cmp)) / 4);break;}}}
};
3.2 内存屏障与CPU缓存优化
// CPU缓存行对齐
struct alignas(64) OrderBookLevel {std::atomic<int64_t> price;std::atomic<int64_t> quantity;std::atomic<uint32_t> order_count;char padding[64 - sizeof(price) - sizeof(quantity) - sizeof(order_count)];
};// NUMA感知的内存分配
class NUMAMemoryManager {
private:std::vector<void*> numa_nodes_;public:void* allocate_on_node(size_t size, int node) {void* ptr = numa_alloc_onnode(size, node);if (!ptr) {throw std::bad_alloc();}return ptr;}template<typename T>T* create_on_node(int node) {void* ptr = allocate_on_node(sizeof(T), node);return new (ptr) T();}
};
四、人工智能:深度学习框架的底层引擎
4.1 张量计算引擎
现代深度学习框架如TensorFlow和PyTorch的核心计算引擎都是用C++实现的,以充分利用硬件加速。
#include <vector>
#include <memory>
#include <algorithm>// 张量基础类型
template<typename T>
class Tensor {
private:std::vector<size_t> shape_;std::vector<size_t> strides_;std::shared_ptr<T[]> data_;size_t size_;public:Tensor(const std::vector<size_t>& shape) : shape_(shape), size_(1) {for (auto dim : shape) size_ *= dim;// 计算stridesstrides_.resize(shape.size());strides_.back() = 1;for (int i = shape.size() - 2; i >= 0; --i) {strides_[i] = strides_[i + 1] * shape[i + 1];}data_ = std::shared_ptr<T[]>(new T[size_]);}// 访问元素T& operator[](const std::vector<size_t>& indices) {size_t offset = 0;for (size_t i = 0; i < indices.size(); ++i) {offset += indices[i] * strides_[i];}return data_[offset];}// 矩阵乘法(使用BLAS优化)Tensor<T> matmul(const Tensor<T>& other) const {if (shape_.size() != 2 || other.shape_.size() != 2) {throw std::runtime_error("Matrix multiplication requires 2D tensors");}if (shape_[1] != other.shape_[0]) {throw std::runtime_error("Matrix dimensions incompatible");}Tensor<T> result({shape_[0], other.shape_[1]});// 使用OpenBLAS进行高性能矩阵乘法cblas_gemm(CblasRowMajor, CblasNoTrans, CblasNoTrans,shape_[0], other.shape_[1], shape_[1],1.0, data_.get(), shape_[1],other.data_.get(), other.shape_[1],0.0, result.data_.get(), other.shape_[1]);return result;}// GPU加速版本Tensor<T> matmul_cuda(const Tensor<T>& other) const {Tensor<T> result({shape_[0], other.shape_[1]});// 使用cuBLAS进行GPU加速cublasHandle_t handle;cublasCreate(&handle);T* d_a, *d_b, *d_c;cudaMalloc(&d_a, size_ * sizeof(T));cudaMalloc(&d_b, other.size_ * sizeof(T));cudaMalloc(&d_c, result.size_ * sizeof(T));cudaMemcpy(d_a, data_.get(), size_ * sizeof(T), cudaMemcpyHostToDevice);cudaMemcpy(d_b, other.data_.get(), other.size_ * sizeof(T), cudaMemcpyHostToDevice);cublasGemmEx(handle, CUBLAS_OP_N, CUBLAS_OP_N,shape_[0], other.shape_[1], shape_[1],&alpha, d_a, CUDA_R_32F, shape_[1],d_b, CUDA_R_32F, other.shape_[1],&beta, d_c, CUDA_R_32F, other.shape_[1],CUDA_R_32F, CUBLAS_GEMM_DEFAULT);cudaMemcpy(result.data_.get(), d_c, result.size_ * sizeof(T), cudaMemcpyDeviceToHost);cudaFree(d_a);cudaFree(d_b);cudaFree(d_c);cublasDestroy(handle);return result;}
};
4.2 神经网络层实现
// ReLU激活函数
class ReLULayer {
public:template<typename T>static Tensor<T> forward(const Tensor<T>& input) {Tensor<T> output(input.shape());std::transform(std::execution::par_unseq,input.data(), input.data() + input.size(),output.data(),[](T x) { return std::max(T(0), x); });return output;}template<typename T>static Tensor<T> backward(const Tensor<T>& grad_output, const Tensor<T>& input) {Tensor<T> grad_input(input.shape());std::transform(std::execution::par_unseq,grad_output.data(), grad_output.data() + grad_output.size(),input.data(), grad_input.data(),[](T grad, T x) { return x > 0 ? grad : T(0); });return grad_input;}
};// 全连接层
class LinearLayer {
private:Tensor<float> weights_;Tensor<float> bias_;public:LinearLayer(size_t input_size, size_t output_size) : weights_({input_size, output_size}), bias_({output_size}) {// Xavier初始化float scale = std::sqrt(2.0f / input_size);std::for_each(std::execution::par_unseq,weights_.data(), weights_.data() + weights_.size(),[scale](float& w) { w = (rand() / float(RAND_MAX) - 0.5f) * 2 * scale; });std::fill(std::execution::par_unseq, bias_.data(), bias_.data() + bias_.size(), 0.0f);}Tensor<float> forward(const Tensor<float>& input) {return input.matmul(weights_).add(bias_);}
};
五、跨平台架构:现代C++的工程实践
5.1 跨平台抽象层设计
现代C++项目需要在Windows、Linux、macOS、移动设备等多个平台运行,良好的抽象层设计至关重要。
// 平台抽象接口
class PlatformInterface {
public:virtual ~PlatformInterface() = default;virtual std::unique_ptr<Window> create_window(int width, int height, const std::string& title) = 0;virtual std::unique_ptr<GraphicsContext> create_graphics_context() = 0;virtual std::unique_ptr<InputManager> create_input_manager() = 0;virtual std::unique_ptr<FileSystem> create_file_system() = 0;static PlatformInterface& get_instance() {static std::unique_ptr<PlatformInterface> instance = create_platform();return *instance;}private:static std::unique_ptr<PlatformInterface> create_platform();
};// Windows平台实现
class WindowsPlatform : public PlatformInterface {
public:std::unique_ptr<Window> create_window(int width, int height, const std::string& title) override {return std::make_unique<WindowsWindow>(width, height, title);}std::unique_ptr<GraphicsContext> create_graphics_context() override {return std::make_unique<DirectX12Context>();}// 其他实现...
};// Linux平台实现
class LinuxPlatform : public PlatformInterface {
public:std::unique_ptr<Window> create_window(int width, int height, const std::string& title) override {return std::make_unique<X11Window>(width, height, title);}std::unique_ptr<GraphicsContext> create_graphics_context() override {return std::make_unique<VulkanContext>();}// 其他实现...
};
5.2 构建系统与包管理
现代C++项目使用CMake、Conan等工具实现跨平台构建和依赖管理。
# CMakeLists.txt 示例
cmake_minimum_required(VERSION 3.20)
project(MyCppProject VERSION 1.0.0 LANGUAGES CXX)# 设置C++标准
set(CMAKE_CXX_STANDARD 20)
set(CMAKE_CXX_STANDARD_REQUIRED ON)# 平台检测
if(WIN32)set(PLATFORM_SOURCES src/platform/windows/windows_platform.cpp)set(PLATFORM_LIBS d3d12 dxgi)
elseif(UNIX AND NOT APPLE)set(PLATFORM_SOURCES src/platform/linux/linux_platform.cpp)set(PLATFORM_LIBS X11 Vulkan)
elseif(APPLE)set(PLATFORM_SOURCES src/platform/macos/macos_platform.cpp)set(PLATFORM_LIBS "-framework Cocoa" "-framework Metal")
endif()# 依赖管理
find_package(fmt REQUIRED)
find_package(spdlog REQUIRED)
find_package(glm REQUIRED)# 主库
add_library(core STATICsrc/core/tensor.cppsrc/core/math_utils.cpp${PLATFORM_SOURCES}
)target_link_libraries(corePUBLICfmt::fmtspdlog::spdlogglm::glm
)# 可执行文件
add_executable(my_app src/main.cpp)
target_link_libraries(my_app PRIVATE core)
六、性能对比与选型指南
6.1 语言性能对比表
| 应用场景 | C++优势 | 性能表现 | 开发效率 | 推荐度 |
|---|---|---|---|---|
| 系统级开发 | 零成本抽象 | 100% | 中等 | ⭐⭐⭐⭐⭐ |
| 游戏引擎 | 手动内存管理 | 95% | 中等 | ⭐⭐⭐⭐⭐ |
| 高频交易 | 纳秒级延迟 | 100% | 低 | ⭐⭐⭐⭐⭐ |
| 深度学习 | CUDA集成 | 90% | 中等 | ⭐⭐⭐⭐ |
| Web开发 | 不适用 | 60% | 低 | ⭐⭐ |
| 移动开发 | 跨平台 | 85% | 中等 | ⭐⭐⭐ |
6.2 现代C++特性演进时间线

图1:C++标准演进时间线 - timeline - 展示了C++11到C++23的关键特性发展
6.3 现代C++生态系统架构
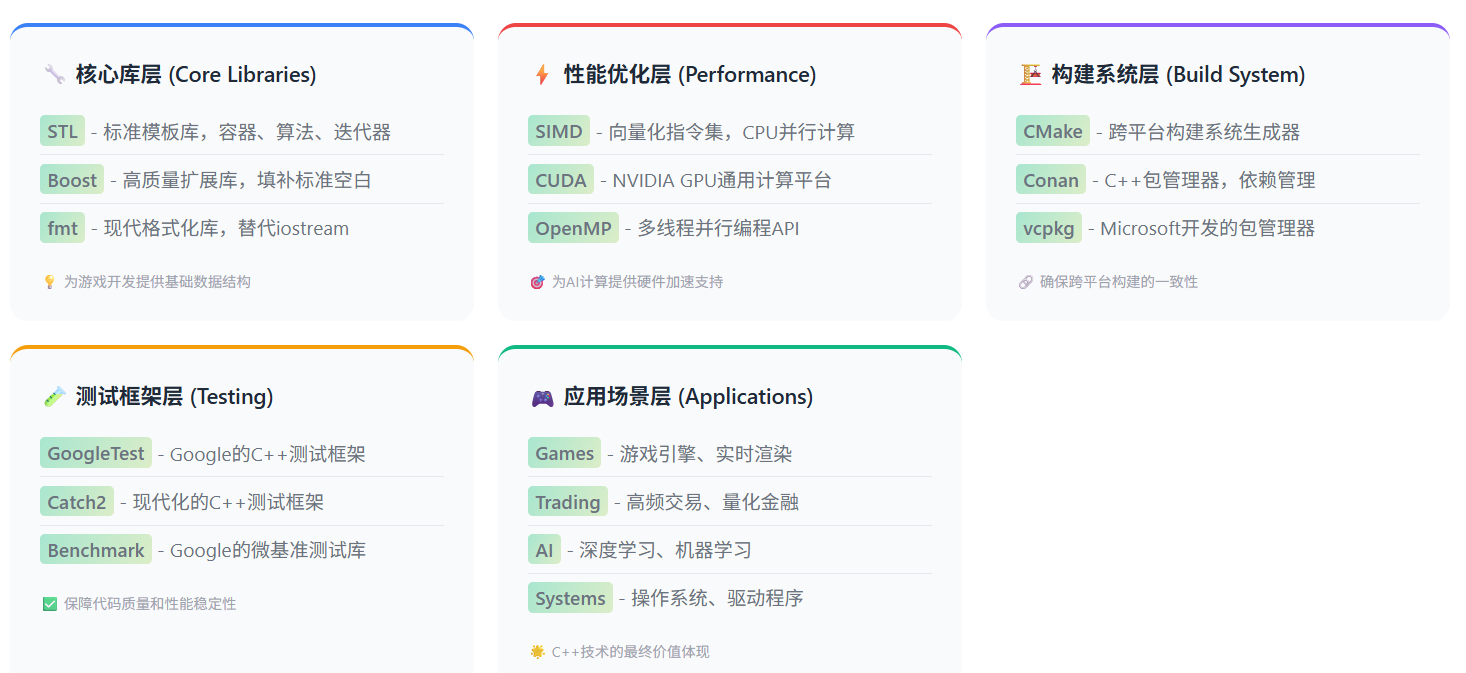
图2:现代C++生态系统架构图 - architecture-beta - 展示了C++在不同领域的应用组件
6.4 性能优化策略象限图

图3:C++性能优化策略象限图 - quadrantChart - 展示了不同优化策略的优先级
6.5 应用场景分布饼图
图4:C++应用场景分布饼图 - pie - 展示了C++在不同领域的市场占比
七、总结与展望
回望这段穿越C++应用宇宙的旅程,我深深感受到这门语言的强大生命力。从系统级开发的深邃黑洞,到AI计算的璀璨星云,C++始终以其独特的魅力吸引着无数技术探索者。
在过去的十年里,我见证了C++从一门"难学难用"的系统语言,蜕变为能够优雅解决各种复杂问题的通用语言。现代C++的演进让我想起了宇宙的膨胀——每一次标准的更新都为开发者打开了更广阔的可能性空间。C++20的协程让我能够用同步的代码风格写出高效的异步程序,Concepts让模板元编程变得直观易懂,Ranges则让数据处理变得优雅而高效。
最让我兴奋的是C++在AI领域的突破。当我第一次看到TensorFlow的核心计算引擎用C++实现,能够在GPU上高效运行深度学习模型时,我意识到C++不再是"古老"的代名词,而是连接传统性能优化与现代AI需求的桥梁。通过CUDA和C++的完美结合,我们能够在单个GPU上实现每秒万亿次的浮点运算,这种性能优势是其他语言难以企及的。
展望未来,C++23带来的静态反射、模式匹配等特性将进一步降低开发复杂度,而C++26的并发和并行特性将让我们更好地利用现代硬件。我相信,在量子计算、边缘AI、元宇宙等新兴领域,C++将继续发挥其不可替代的作用。就像宇宙中的恒星,虽然经历了数十亿年的演化,但依然散发着耀眼的光芒。
对于每一位C++开发者而言,这既是一个充满挑战的时代,也是一个充满机遇的时代。让我们继续在这片技术星空中探索,用C++的优雅与强大,书写属于我们的星际传奇。
■ 我是蒋星熠Jaxonic!如果这篇文章在你的技术成长路上留下了印记
■ 👁 【关注】与我一起探索技术的无限可能,见证每一次突破
■ 👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
■ 🔖 【收藏】将精华内容珍藏,随时回顾技术要点
■ 💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
■ 🗳 【投票】用你的选择为技术社区贡献一份力量
■ 技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!
参考链接
- C++ Reference - 官方标准文档
- C++ Core Guidelines - 现代C++最佳实践
- LLVM Project - Clang编译器
- Boost Libraries - 高质量C++库集合
- C++ Standards Committee Papers - 标准演进文档
关键词标签
C++17, C++20, 系统编程, 游戏引擎, 高频交易, 人工智能, 跨平台开发, 性能优化, 内存管理, 并发编程