对线面试官之幂等和去重
面试官:能谈谈你对「去重」和「幂等」这两个概念的理解吗?
候选人:
「去重」是对相同请求或者相同消息在「一定时间内」进行去掉重复,只保留一条。
「幂等」则是保证重复的请求或消息在「任意时间内」进行处理,都需要保证它的结果是一致的,不会因重复处理导致副作用。
- 去重是 “短期过滤”,解决 “重复操作的资源浪费”,适用于允许 “过了时间窗口后可重复” 的场景。
- 幂等是 “永久保障”,解决 “重复操作的结果错乱”,适用于必须保证结果唯一的核心业务(如支付、订单)。
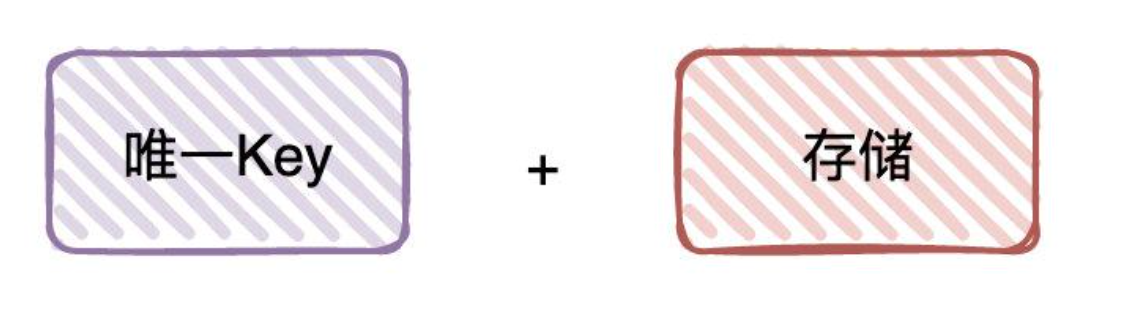
不论是「去重」还是「幂等」,都需要对有一个「唯一 Key」,并且有地方对唯一Key进行「存储」
面试官:假设我有个需求:“1 小时内同一用户通过同一渠道发送的消息,最多推送 3 次,超过则去重”。如何实现?
候选人:使用用户ID+渠道ID为唯一key;使用Redis存储推送记录次数,key=用户ID+渠道ID,value=推送次数,并设置过期时间为1小时;主要逻辑就是每次请求时,先检查Redis中对应的次数,大于等于3直接返回;否则推送并且计数+1。
- 唯一 Key:
用户ID+渠道ID。- 存储:Redis,Key 的过期时间设为 1 小时,Value 记录推送次数。
- 逻辑:每次请求时检查 Redis 中次数,若≥3 则过滤,否则计数 + 1 并推送。
面试官:嗯,回答不错。假设我有另一个需求:同一订单的支付请求,无论调用多少次,只扣一次钱。
候选人:使用订单号作为唯一key,在MySQL中,订单表用订单号作为唯一索引。当支付请求来时,通过唯一索引判断订单是否已支付,若未支付则扣钱并标记 “已支付”;若已支付则直接返回 “成功”。
- 唯一 Key:
订单号。- 存储:MySQL,订单表中用
订单号作为唯一索引。- 逻辑:支付请求时,通过唯一索引判断订单是否已支付,若未支付则扣钱并标记 “已支付”;若已支付则直接返回 “成功”(不重复扣钱)。
面试官:既然提到了「去重」了,你听过布隆过滤器吗?
候选者:有了解的
面试官:来讲讲布隆过滤器吧
候选者:布隆过滤器的底层数据结构可以理解为bitmap,bitmap也可以简单理解为是一个数组,元素只存储0和1,所以它占用的空间相对较小
候选者:当一个元素要存入bitmap时,其实是要去看存储到bitmap的哪个位置,这时一般用的就是哈希算法,存进去的位置标记为1
候选者:标记为1的位置表示存在,标记为0的位置标示不存在
候选者:布隆过滤器是可以以较低的空间占用来判断元素是否存在进而用于去重,但是它也有对应的缺点。
候选者:只要使用哈希算法就离不开「哈希冲突」,导致有存在「误判」的情况。在布隆过滤器中,如果元素判定为存在,那该元素「未必」真实存在。如果元素判定为不存在,那就肯定是不存在。(结合「哈希冲突」和「标记为1的位置表示存在,标记为0的位置标示不存在」这两者就能得出该结论。)
布隆过滤器也不能「删除」元素(也是哈希算法的局限性,在布隆过滤器中是不能准确定位一个元素的),Guava有布隆过滤器的实现。