爬虫与数据分析实战
中国大学排名数据爬取与可视化全流程
在数据科学领域,爬虫技术用于获取数据源,数据分析技术用于挖掘数据价值,二者结合能产生强大的业务驱动力。本文以 “中国大学排名” 为案例,完整展示从网页爬取数据到数据清洗、再到可视化分析的全流程,适合数据分析入门者参考学习。
一、案例背景与目标
本次案例旨在通过爬虫获取公开的中国大学排名数据,并通过数据分析技术处理数据、挖掘信息。具体目标如下:
- 爬取高三网(2021中国的大学排名一览表_高三网)的中国大学排名数据,包括学校名称、总分、全国排名、星级排名、办学层级;
- 对爬取的数据进行预处理,处理 “总分” 列的缺失值;
- 通过可视化图表(柱形图、饼图)分析不同星级学校的分布情况。
2.1 爬取思路解析
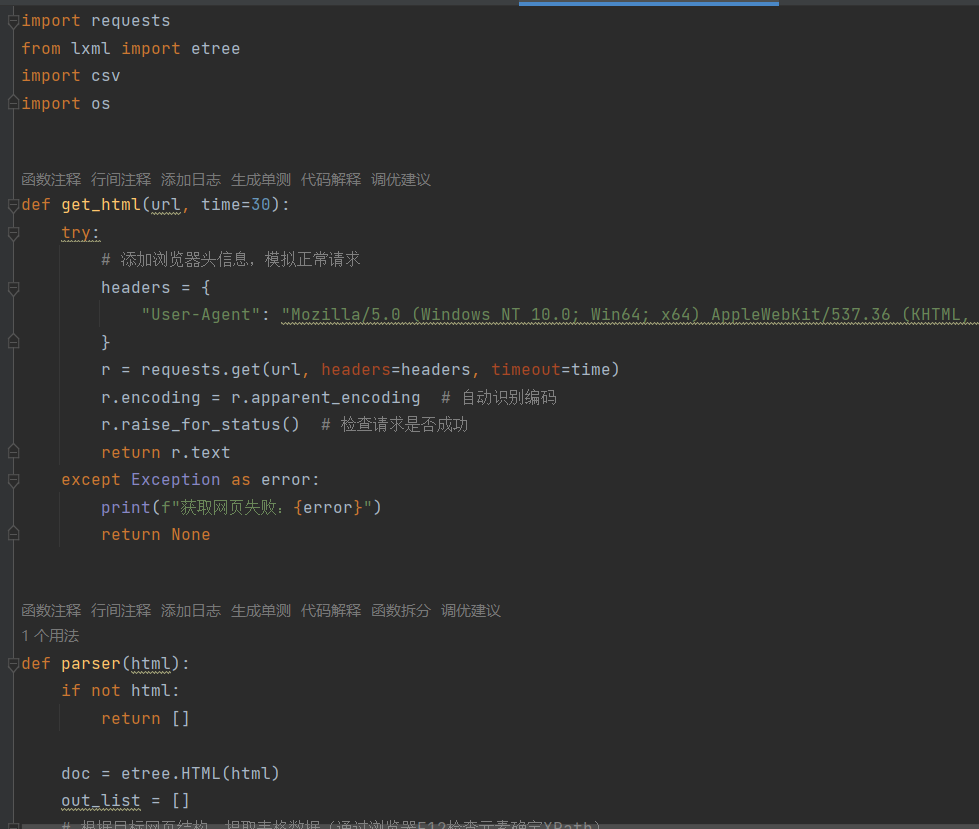
网页数据爬取的核心流程为:发送请求获取网页内容→解析网页提取目标数据→保存数据到本地文件。本次爬取使用requests库发送 HTTP 请求,BeautifulSoup库解析 HTML 结构,最终将数据保存为 CSV 格式。
2.2 完整代码实现
步骤 1:导入依赖库
步骤 2:获取网页内容
定义get_html函数发送 GET 请求,处理编码和异常:
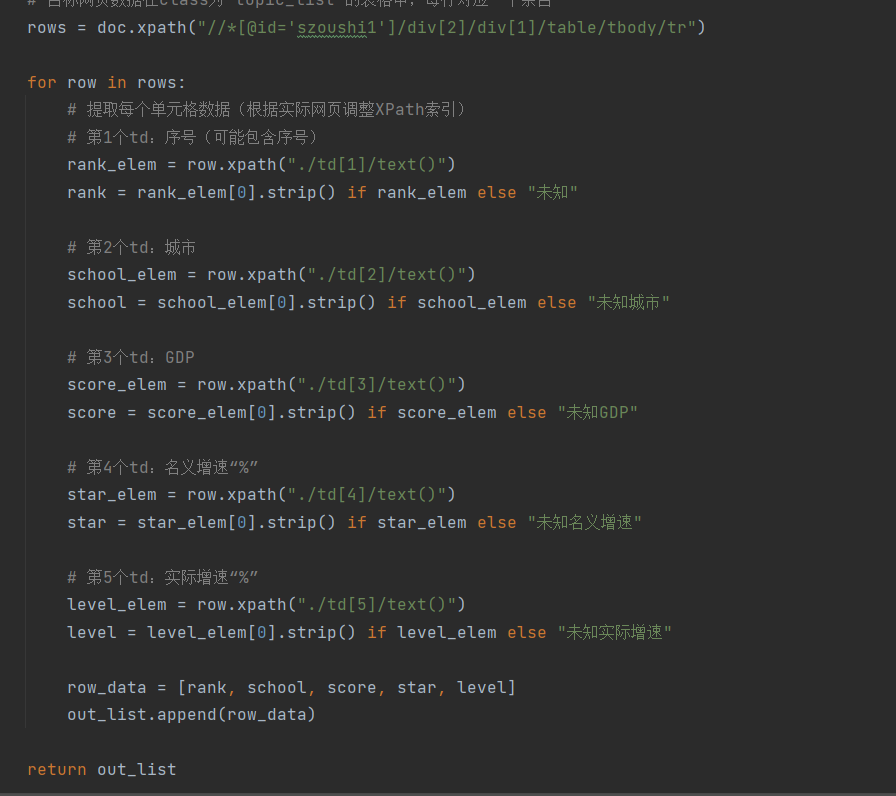
步骤 3:解析网页提取数据
通过BeautifulSoup定位表格标签,提取每行数据:
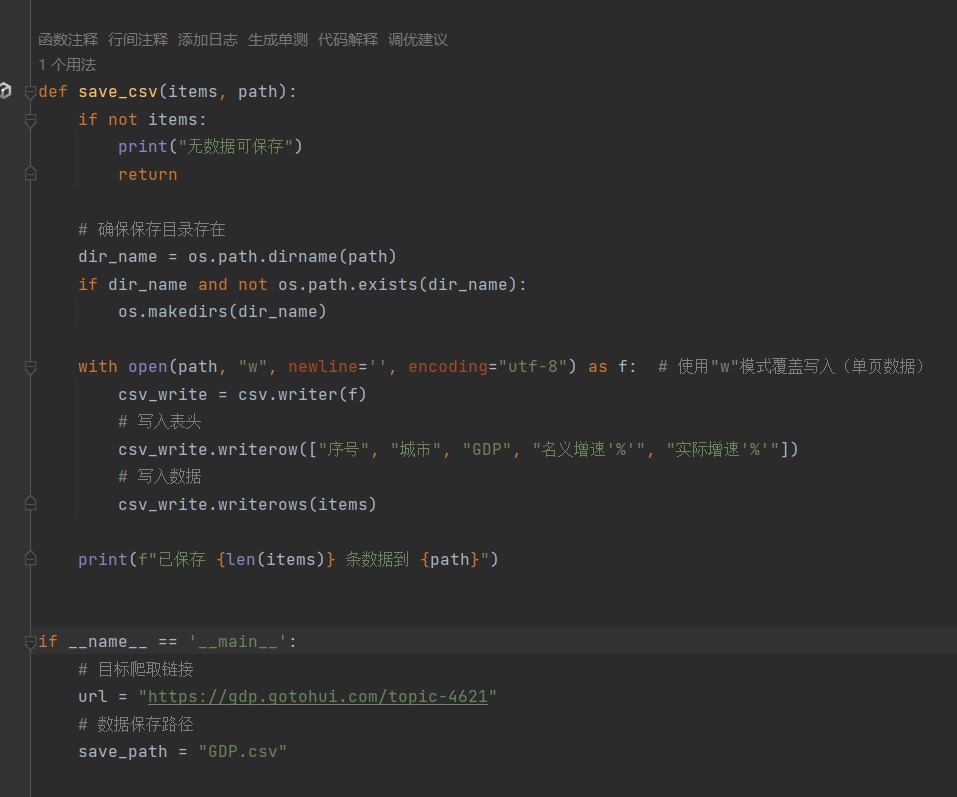
步骤 4:保存数据到 CSV
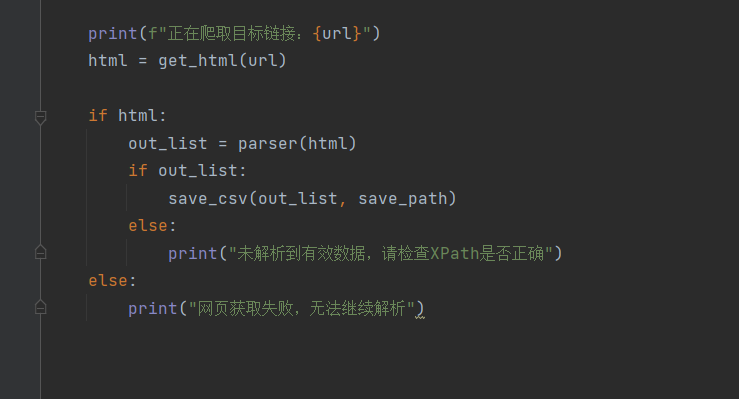
步骤 5:主函数执行流程
2.3 爬取结果
运行代码后,生成school.csv文件,
根据数据科学与计算,利用matplotlib库完成作图和信息查询
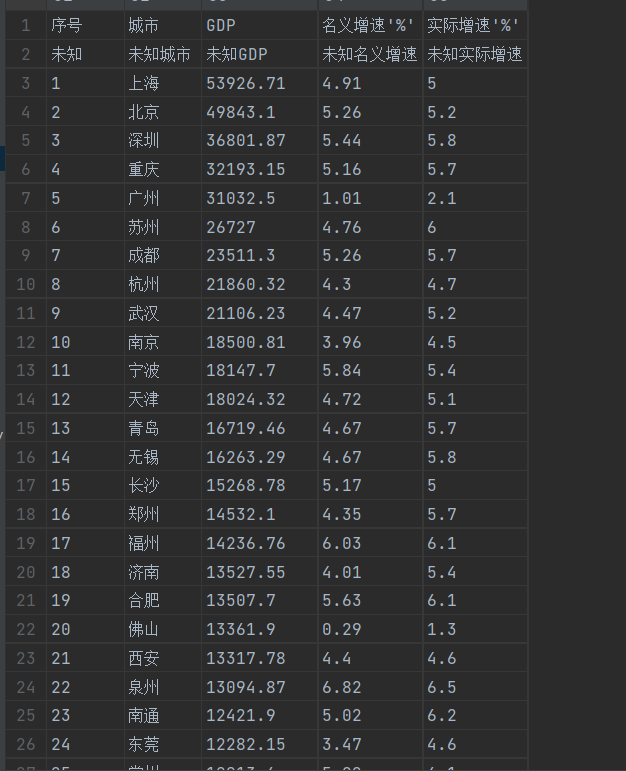
自主爬取2024度年GDP排名前五十的城市
网址: https://gdp.gotohui.com/topic-4621
运行结果:
本文通过 “中国大学排名” 案例,完整演示了从爬虫获取数据到数据分析的全流程。关键技术点包括:
- 爬虫:
requests+BeautifulSoup的网页数据提取; - 数据预处理:Pandas 处理缺失值的 4 种方法;
- 可视化:Matplotlib 绘制柱形图和饼图。