爬虫和数据分析相结合案例
案例1 · 豆瓣电影
首先爬取并保存csv文件
import requests
from bs4 import BeautifulSoup
import csvdef get_html(url, time=3): # 保持原函数结构,仅添加User-Agent适配豆瓣try:headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36"}r = requests.get(url, headers=headers, timeout=time) # 发送请求r.encoding = r.apparent_encoding # 设置字符集编码r.raise_for_status() # 状态码非200则抛异常return r.text # 返回网页文本except Exception as error:print(error)def parser(html): # 解析函数,适配豆瓣电影列表结构soup = BeautifulSoup(html, "lxml") # 转换为soup对象out_list = [["电影名称", "评分", "评价人数", "上映年份", "国家/地区"]] # 存储解析数据的列表# 豆瓣电影Top250的每部电影在<li>标签中,循环遍历for item in soup.select("ol.grid_view > li"):# 提取电影核心信息(对应原代码的td解析逻辑)title_tag = item.select_one(".hd > a > span:nth-child(1)") # 电影名称rating_tag = item.select_one(".rating_num") # 评分comment_tag = item.select_one(".star > span:last-child") # 评价人数info_tag = item.select_one(".bd > p:first-child") # 导演/主演/年份等信息# 提取文本(处理可能的空值)title = title_tag.text.strip() if title_tag else ""rating = rating_tag.text.strip() if rating_tag else ""comment = comment_tag.text.strip() if comment_tag else ""info = info_tag.text.strip().replace("\n", "").replace(" ", "") if info_tag else ""# 拆分年份(从info中提取,适配原代码的字段数量逻辑)year = info.split("/")[0].strip()[-4:] if "/" in info else ""row_data = [title,rating,comment,year,info.split("/")[1].strip() if len(info.split("/")) > 1 else ""]out_list.append(row_data) # 插入列表return out_listdef save_csv(item, path): # 保持原存储函数完全不变with open(path, "wt", newline='', encoding="utf-8") as f:csv_write = csv.writer(f)csv_write.writerows(item)if __name__ == "__main__":# 豆瓣Top250分页爬取(共10页,每页25条)all_data = []for page in range(10):start = page * 25url = f"https://movie.douban.com/top250?start={start}&filter="html = get_html(url)if html:page_data = parser(html)all_data.extend(page_data) # 合并所有页数据save_csv(all_data, "douban_top250.csv") # 存储为CSV然后调用csv文件 进行数据预处理
数据可视化
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns# 中文支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 读取 & 清洗
df = pd.read_csv('douban_top250.csv')
df['评分'] = pd.to_numeric(df['评分'], errors='coerce') # 一步到位:非法变 NaN
df = df.dropna(subset=['评分'])# 分析
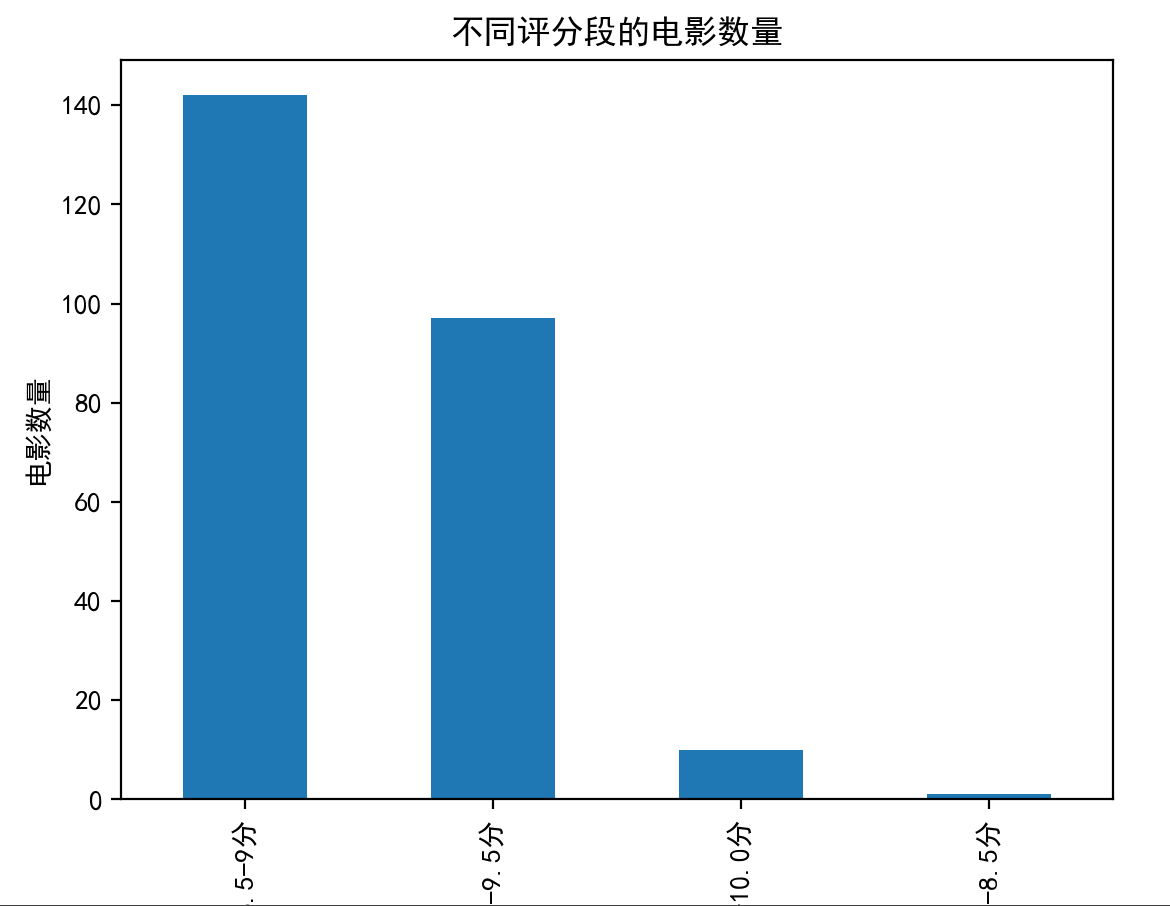
bins = [8, 8.5, 9, 9.5, 10]
labels = ['8.0-8.5分', '8.5-9分', '9.0-9.5分', '9.5-10.0分']
df['评分段'] = pd.cut(df['评分'], bins=bins, labels=labels, right=False)tongji = df['评分段'].value_counts()
print(tongji)print(f"平均评分:{df['评分'].mean()}")
print(f"最高评分:{df['评分'].max()}")
print(f"最低评分:{df['评分'].min()}")# 可视化\
tongji.plot(kind='bar')
plt.title('不同评分段的电影数量')
plt.xlabel('评分段')
plt.ylabel('电影数量')
plt.show()
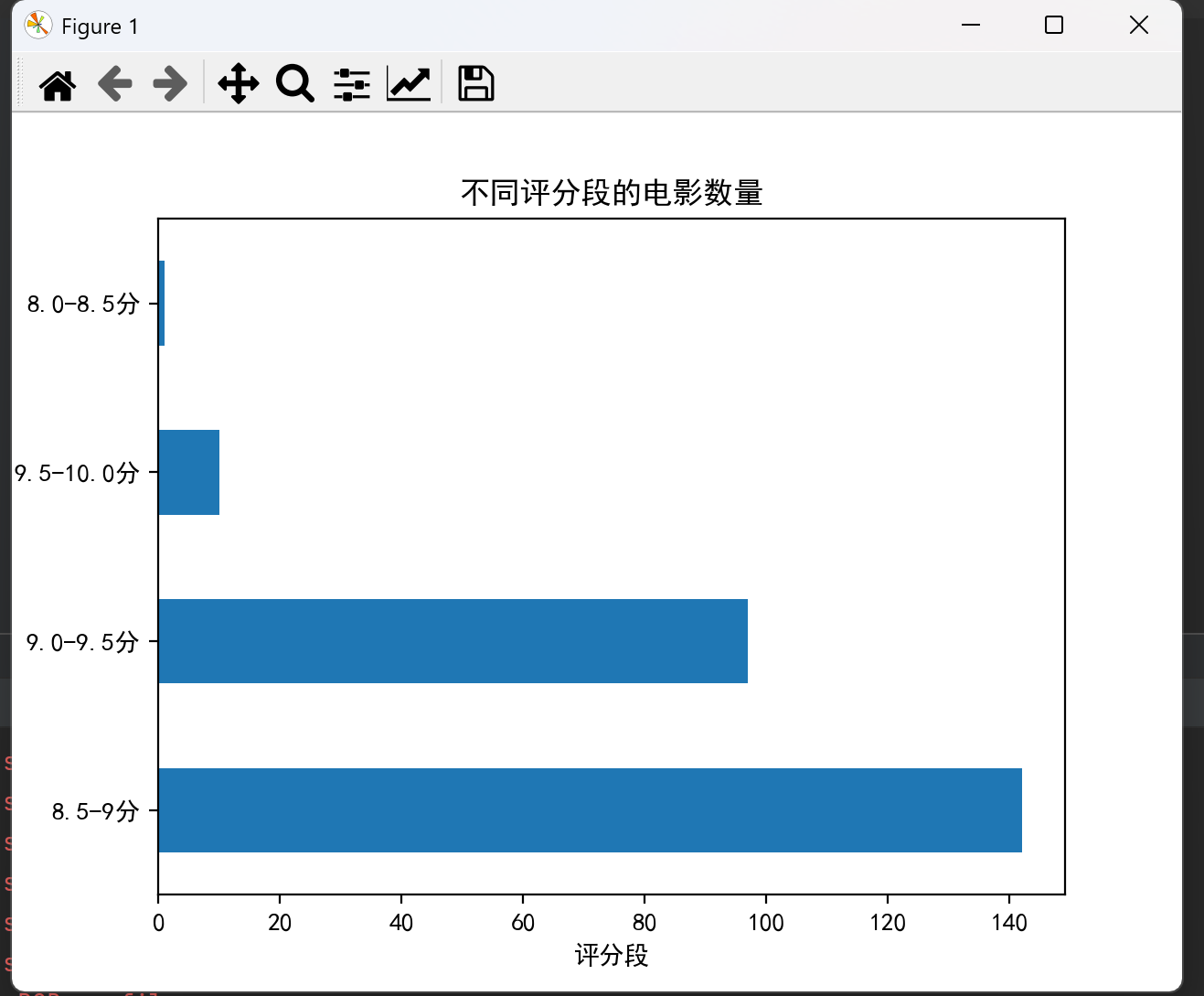
 tongji.plot(kind='barh')
plt.title('不同评分段的电影数量')
plt.xlabel('评分段')
plt.ylabel('电影数量')
plt.show()
tongji.plot(kind='barh')
plt.title('不同评分段的电影数量')
plt.xlabel('评分段')
plt.ylabel('电影数量')
plt.show()
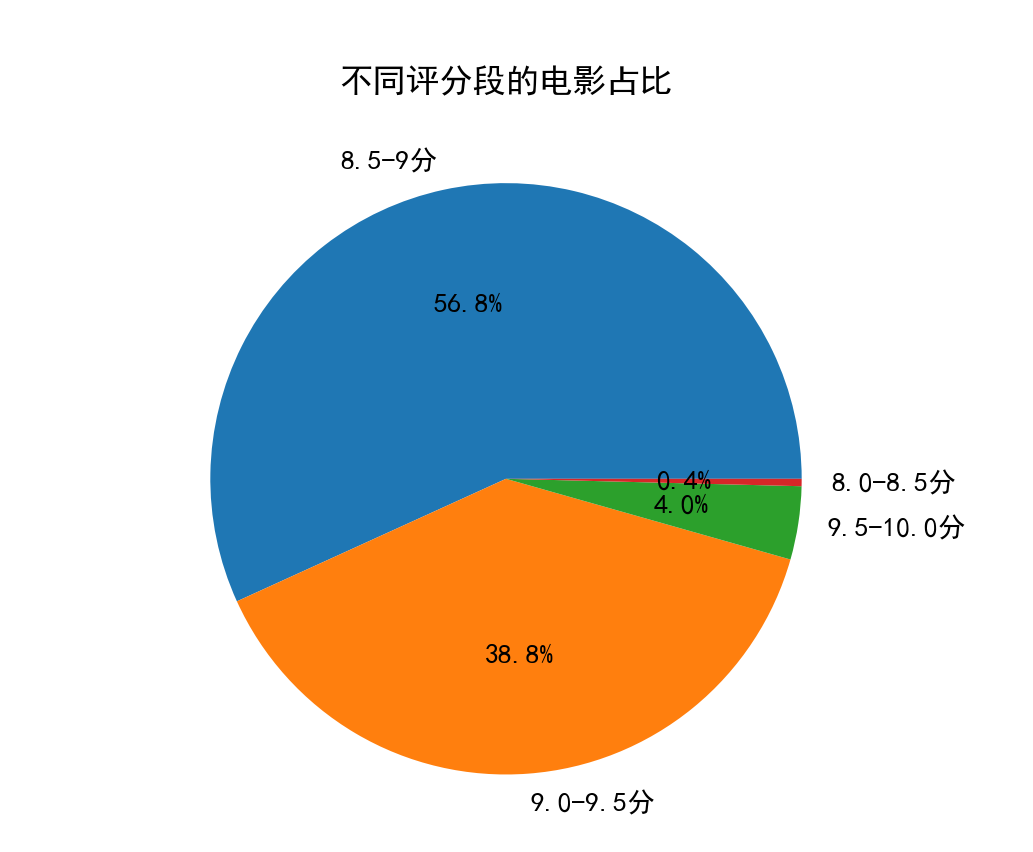
 plt.pie(tongji, labels=tongji.index, autopct='%1.1f%%')
plt.title('不同评分段的电影占比')
plt.show()
plt.pie(tongji, labels=tongji.index, autopct='%1.1f%%')
plt.title('不同评分段的电影占比')
plt.show()
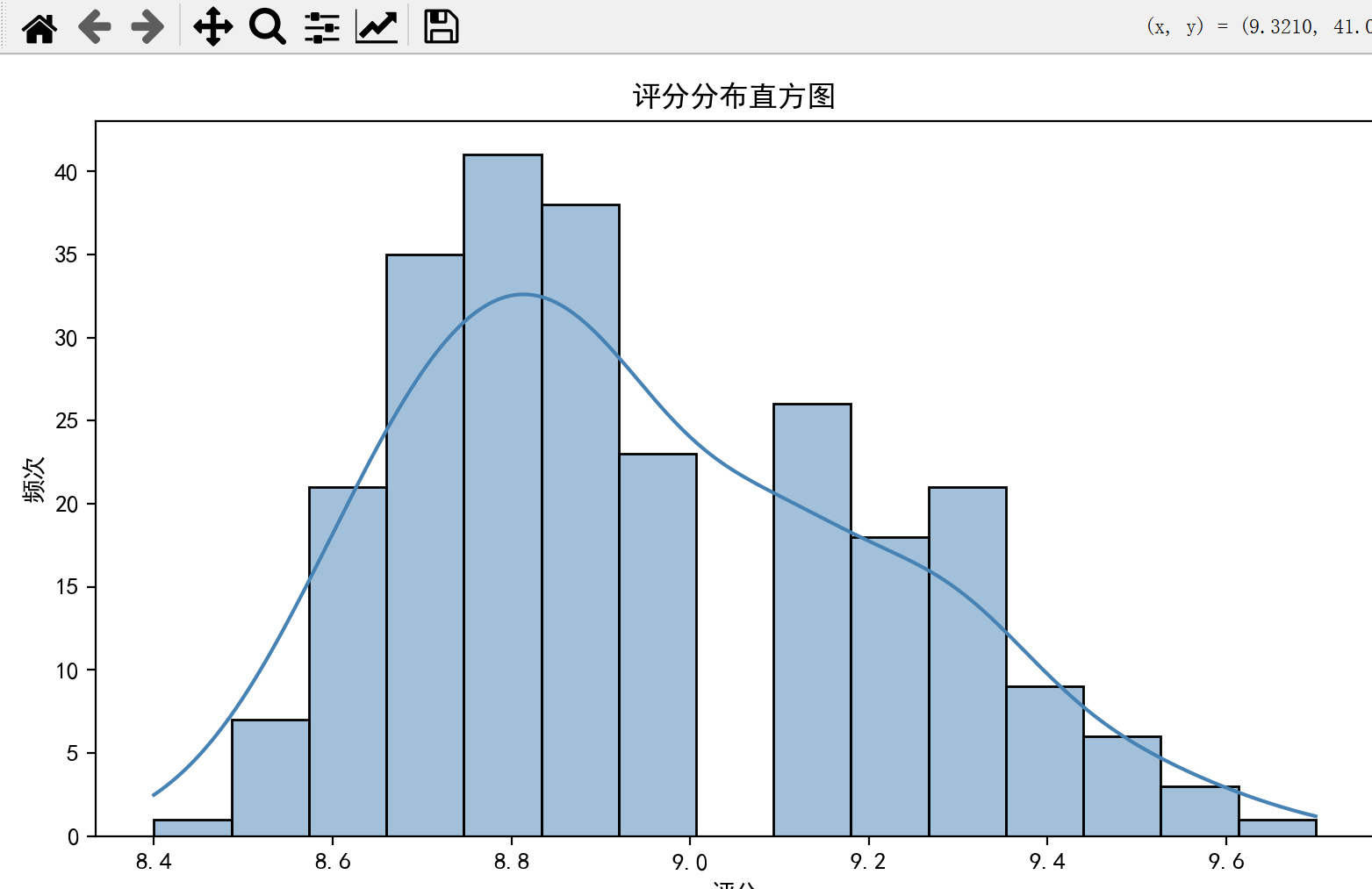
 plt.figure(figsize=(8, 5))
sns.histplot(df['评分'], bins=15, kde=True, color='steelblue')
plt.title('评分分布直方图')
plt.xlabel('评分')
plt.ylabel('频次')
plt.tight_layout()
plt.show()
plt.figure(figsize=(8, 5))
sns.histplot(df['评分'], bins=15, kde=True, color='steelblue')
plt.title('评分分布直方图')
plt.xlabel('评分')
plt.ylabel('频次')
plt.tight_layout()
plt.show()
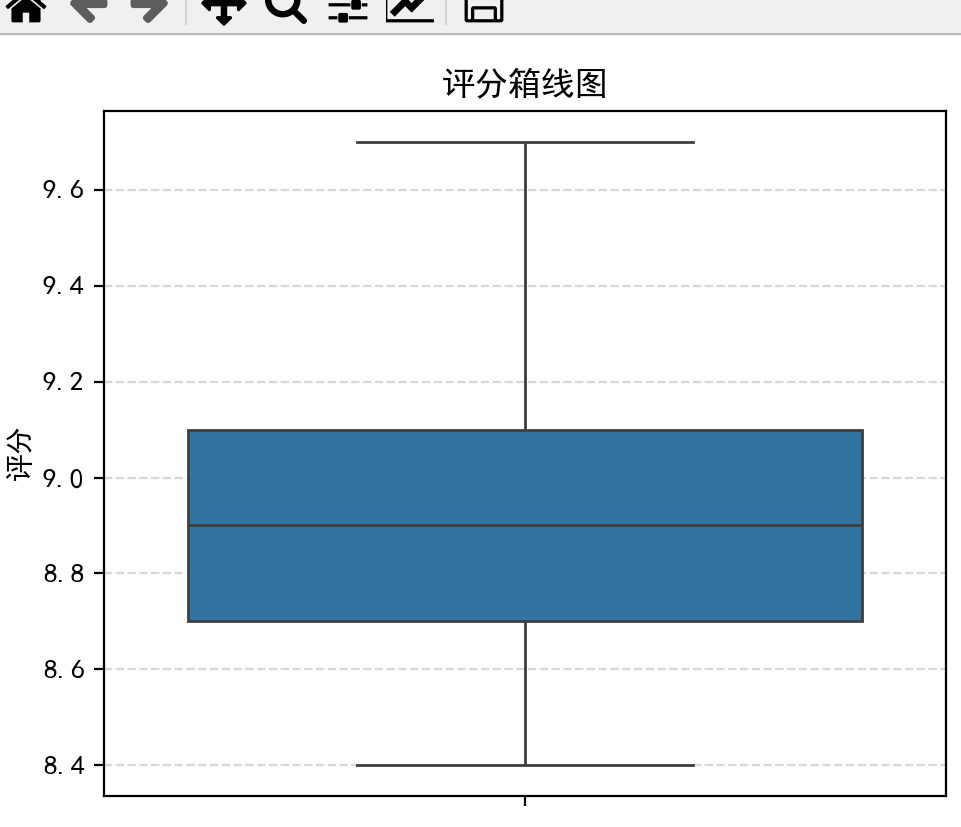
 plt.figure(figsize=(5, 4))
sns.boxplot(y=df['评分'])
plt.title('评分箱线图')
plt.ylabel('评分')
plt.grid(axis='y', linestyle='--', alpha=0.5)
plt.tight_layout()
plt.show()
plt.figure(figsize=(5, 4))
sns.boxplot(y=df['评分'])
plt.title('评分箱线图')
plt.ylabel('评分')
plt.grid(axis='y', linestyle='--', alpha=0.5)
plt.tight_layout()
plt.show()
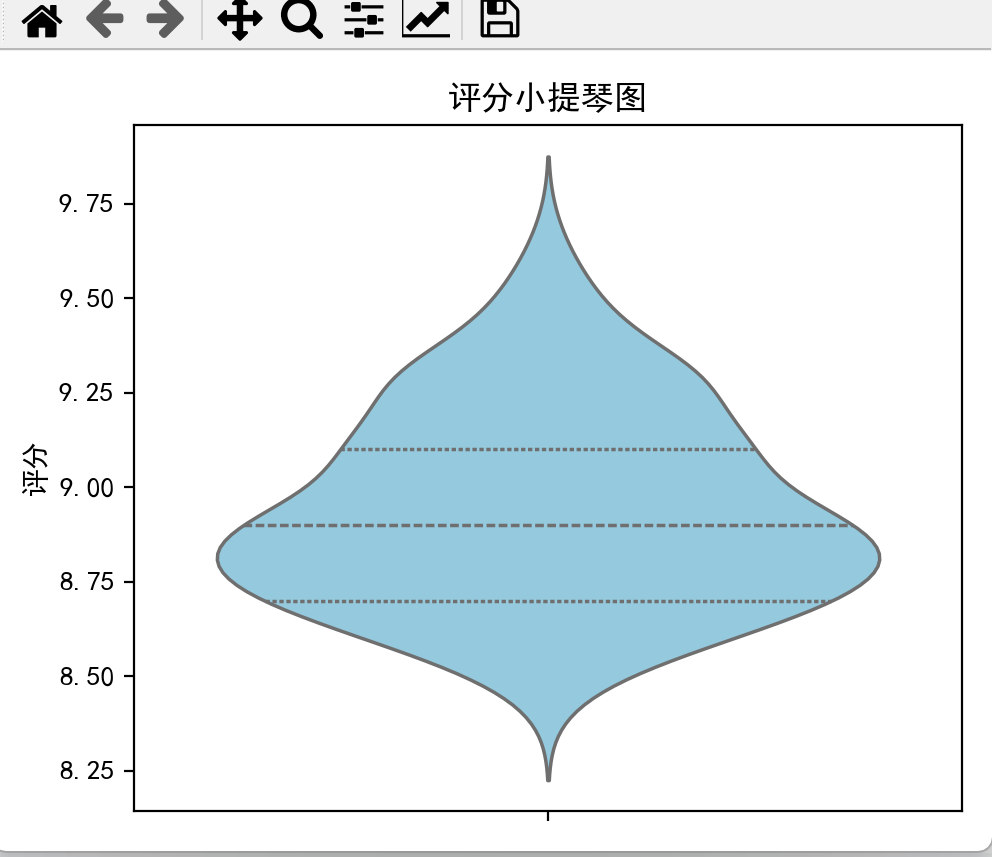
 plt.figure(figsize=(5, 4))
sns.violinplot(y=df['评分'], inner='quartile', color='skyblue')
plt.title('评分小提琴图')
plt.ylabel('评分')
plt.tight_layout()
plt.show()
plt.figure(figsize=(5, 4))
sns.violinplot(y=df['评分'], inner='quartile', color='skyblue')
plt.title('评分小提琴图')
plt.ylabel('评分')
plt.tight_layout()
plt.show()
案例2 · 中国大学排名爬取
首先爬取并保存csv文件
import requests
from bs4 import BeautifulSoup
import csvdef get_html(url, time=3): # get请求通用函数,去掉了user-agent简化代码try:r = requests.get(url, timeout=time) # 发送请求r.encoding = r.apparent_encoding # 设置返回内容的字符集编码r.raise_for_status() # 返回的状态码不等于200抛出异常return r.text # 返回网页的文本内容except Exception as error:print(error)def parser(html): # 解析函数soup = BeautifulSoup(html, "lxml") # html转换为soup对象out_list = [] # 解析函数输出数据的列表for row in soup.select("table>tbody>tr"): # 循环遍历trtd_html = row.select("td") # 获取tdrow_data = [td_html[1].text.strip(), # 学校名称td_html[2].text.strip(), # 总分td_html[3].text.strip(), # 全国排名td_html[4].text.strip(), # 星级td_html[5].text.strip(), # 办学层次]out_list.append(row_data) # 将解析的每行数据插入到输出列表中return out_listdef save_csv(item, path): # 数据存储, 将List数据写入文件 with open(path, "wt", newline='', encoding="utf-8") as f: # 创建utf8编码文件csv_write = csv.writer(f) # 创建写入对象csv_write.writerows(item) # 一次性写入多行if __name__ == "__main__":url = "http://www.bspider.top/gaosan/"html = get_html(url) # 获取网页数据out_list = parser(html) # 解析网页, 输出列表数据save_csv(out_list, "school.csv") # 数据存储
import pandas as pd
df = pd.read_csv("school.csv")
new_df = df.dropna()
print(new_df.to_string())
import pandas as pd
df = pd.read_csv("school.csv")
# 将“总分”列转换为字符串类型,解决数据类型不兼容问题
df["总分"] = df["总分"].astype(str)
# 填充空值
df.fillna("暂无分数信息", inplace=True)
print(df.to_string())
import pandas as pd
df = pd.read_csv("school.csv")
x = df["总分"].median()
print("总分的中位数为")
print(x)
# 改用直接赋值,避免 inplace=True 引发的链式操作警告
df["总分"] = df["总分"].fillna(x)
print(df.to_string())
import pandas as pd
df = pd.read_csv("school.csv")
x = df["总分"].mean()
print("总分的均值为")
print(x)
# 直接赋值替换inplace=True,避免链式操作警告
df["总分"] = df["总分"].fillna(x)
print(df.to_string())
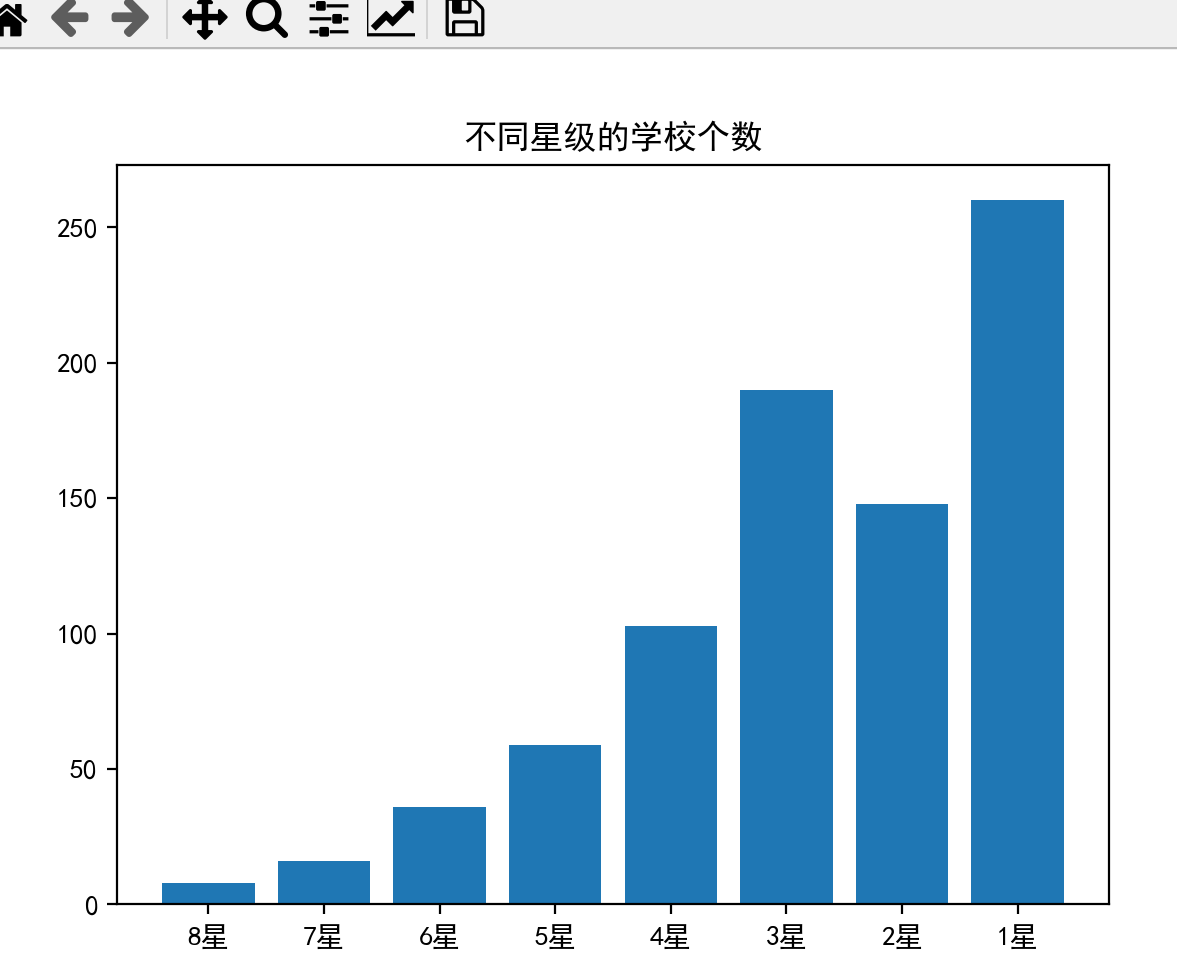
import matplotlib.pyplot as plt # 导入matplotlib库的pyplot模块,用于绘图,并简写为plt
import numpy as np # 导入numpy库,并简写为np,用于数值计算# 创建一个包含星级标签的numpy数组,用于x轴
x = np.array(["8星", "7星", "6星", "5星", "4星", "3星", "2星", "1星"])
# 创建一个包含各星级学校数量的numpy数组,用于y轴
y = np.array([8, 16, 36, 59, 103, 190, 148, 260])
# 设置图表的标题
plt.title("不同星级的学校个数")
# 设置字体为SimHei,以支持中文显示
plt.rcParams["font.sans-serif"] = ["SimHei"]
# 创建柱形图,x和y分别为x轴和y轴的数据
plt.bar(x, y)
# 显示图表
plt.show()
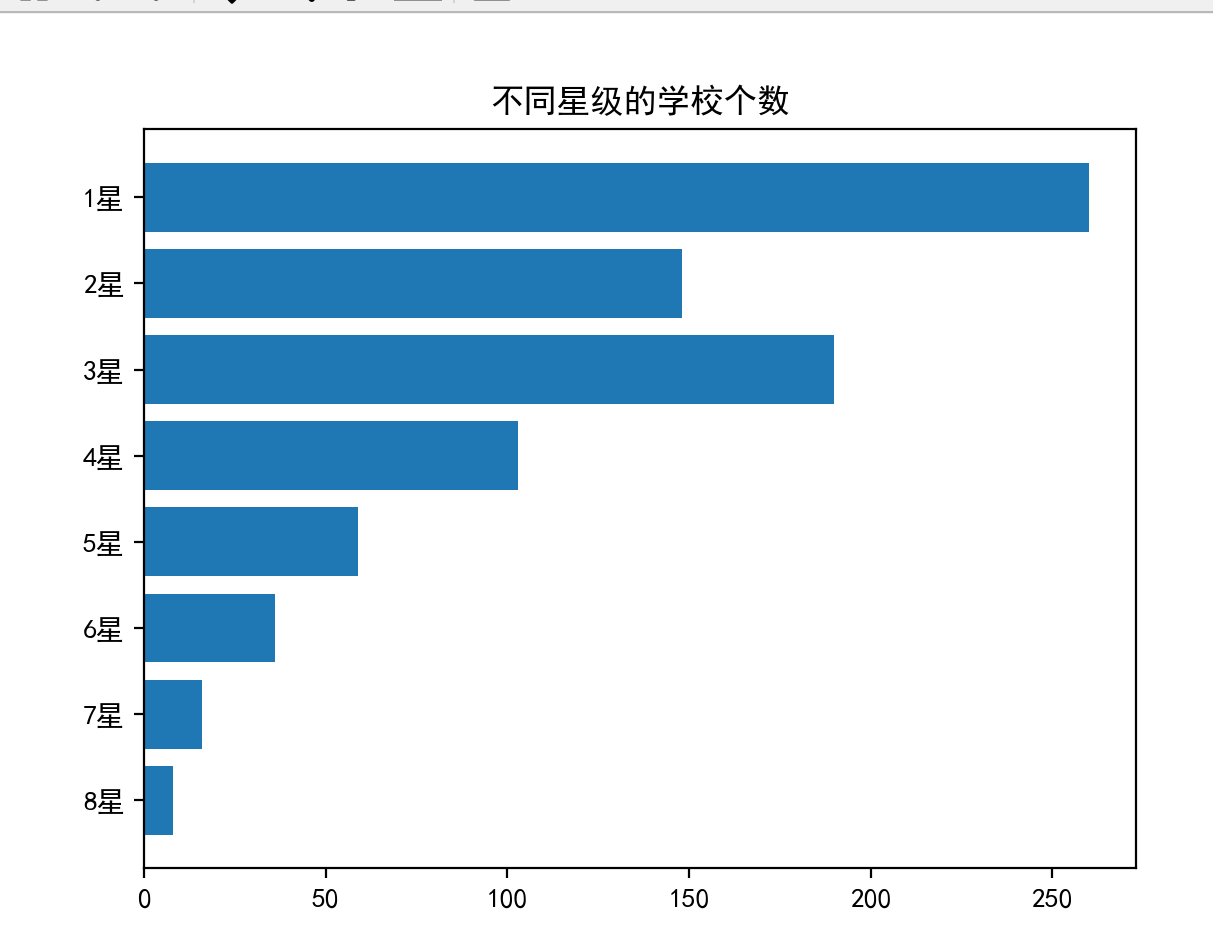
 # 创建一个包含星级标签的numpy数组,用于x轴
x = np.array(["8星", "7星", "6星", "5星", "4星", "3星", "2星", "1星"])
# 创建一个包含各星级学校数量的numpy数组,用于y轴
y = np.array([8, 16, 36, 59, 103, 190, 148, 260])
# 设置图表的标题
plt.title("不同星级的学校个数")
# 设置字体为SimHei,以支持中文显示
plt.rcParams["font.sans-serif"] = ["SimHei"]
# 创建水平柱形图,x和y分别为x轴和y轴的数据
plt.barh(x, y)
# 显示图表
plt.show()
# 创建一个包含星级标签的numpy数组,用于x轴
x = np.array(["8星", "7星", "6星", "5星", "4星", "3星", "2星", "1星"])
# 创建一个包含各星级学校数量的numpy数组,用于y轴
y = np.array([8, 16, 36, 59, 103, 190, 148, 260])
# 设置图表的标题
plt.title("不同星级的学校个数")
# 设置字体为SimHei,以支持中文显示
plt.rcParams["font.sans-serif"] = ["SimHei"]
# 创建水平柱形图,x和y分别为x轴和y轴的数据
plt.barh(x, y)
# 显示图表
plt.show()
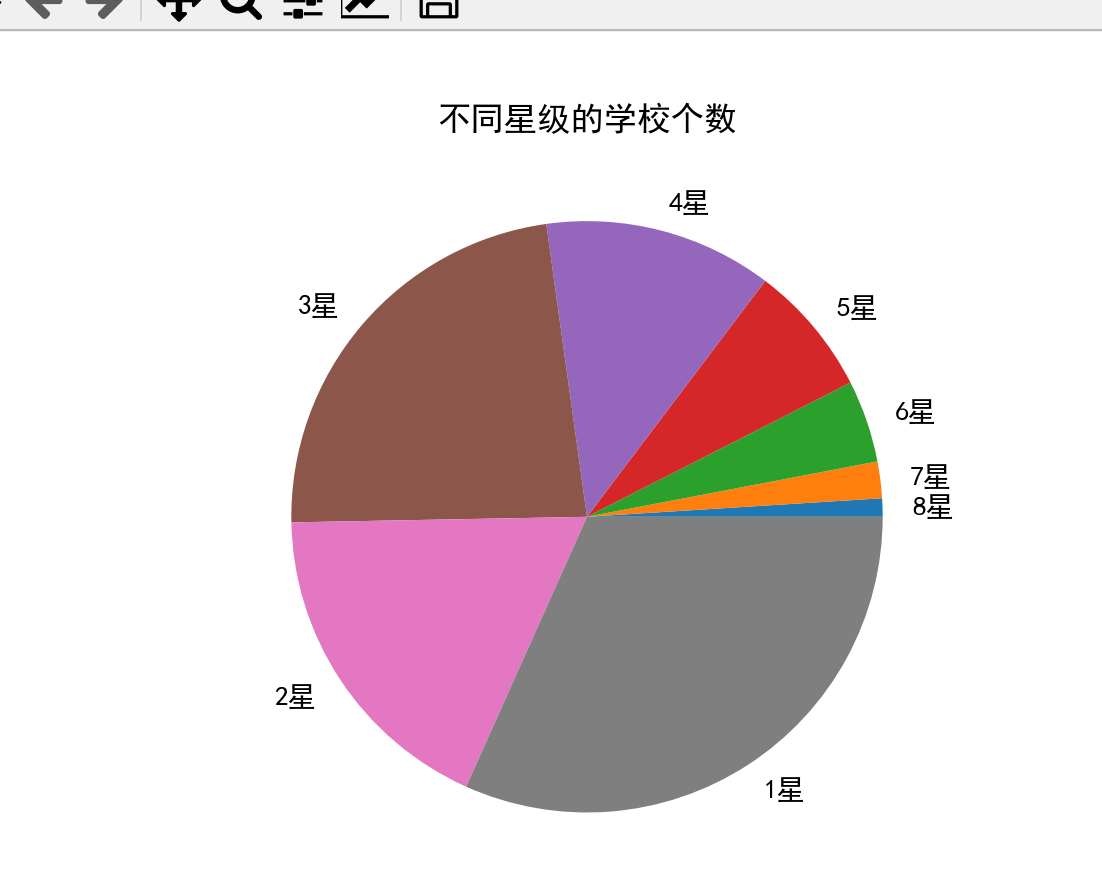
 # 创建一个包含各星级学校占比的numpy数组,用于饼图的数据
y = np.array([1, 2, 4.5, 7.2, 12.5, 23.1, 18, 31.7])
# 创建饼图,y为饼图的数据,labels为饼图每个部分的标签
plt.pie(y, labels=["8星", "7星", "6星", "5星", "4星", "3星", "2星", "1星"])
# 设置图表的标题
plt.title("不同星级的学校个数")
# 设置字体为SimHei,以支持中文显示
plt.rcParams["font.sans-serif"] = ["SimHei"]
# 显示图表
plt.show()
# 创建一个包含各星级学校占比的numpy数组,用于饼图的数据
y = np.array([1, 2, 4.5, 7.2, 12.5, 23.1, 18, 31.7])
# 创建饼图,y为饼图的数据,labels为饼图每个部分的标签
plt.pie(y, labels=["8星", "7星", "6星", "5星", "4星", "3星", "2星", "1星"])
# 设置图表的标题
plt.title("不同星级的学校个数")
# 设置字体为SimHei,以支持中文显示
plt.rcParams["font.sans-serif"] = ["SimHei"]
# 显示图表
plt.show()