【大模型】强化学习算法总结
角色和术语定义
- State:状态
- Action:动作
- Policy/actor model:策略模型,用于决策行动的主要模型
- Critic/value model:价值模型,用于评判某个行动的价值大小
- Reward model:奖励模型,用于给行动打分
- Reference model:参考模型,是初始的策略模型,用于计算更新后策略模型和初始的偏差
一个简单的小故事
首先,举个最简单的例子:在考试中,学生是policy/actor model,努力获得高分;老师是reward model,通过阅卷得到成绩;根据成绩发放零花钱的家长是critic/value model;第一次模拟考试的学生是reference model。
为什么根据成绩发放零花钱的家长需要使用model呢?因为家长发放零花钱时,定的分数线不能是静态不变的,也需要动态考虑到孩子成绩的变化,比如第一次考试70分,那分数线可以定在80,第二次考了81分,分数线可以调整到85,并且对于不同的人,这个分数线也应该是差异化定制的。所以发放零花钱的家长是critic/value model,根据model去动态预测合适分数线,因此也是需要训练更新的。
【至此,已经介绍完了PPO的故事场景】
但是家长觉得这种动态调整太费时费力了,需要一直观察孩子的情况。所以提出在每次考试前,先给孩子做几套模拟试卷,取平均分作为分数线。正式考完试之后计算成绩和分数线的差距,决定零花钱怎么发。
【至此,已经介绍完了GRPO的优化】
有一次,家长突然发现孩子拿了100分,非常惊讶,调查后发现是作弊了。所以家长决定给孩子一些限制,要求孩子能力不能和初始时偏差太远!也就是要循序渐进地进步,而不是通过作弊的方式拿到100分。
【以上,是PPO和GRPO中引入reference model的KL散度的原因】
可以看到,PPO和GRPO的不同点在于怎么去计算这个动态的分数线(也称作优势),其他部分几乎一致。
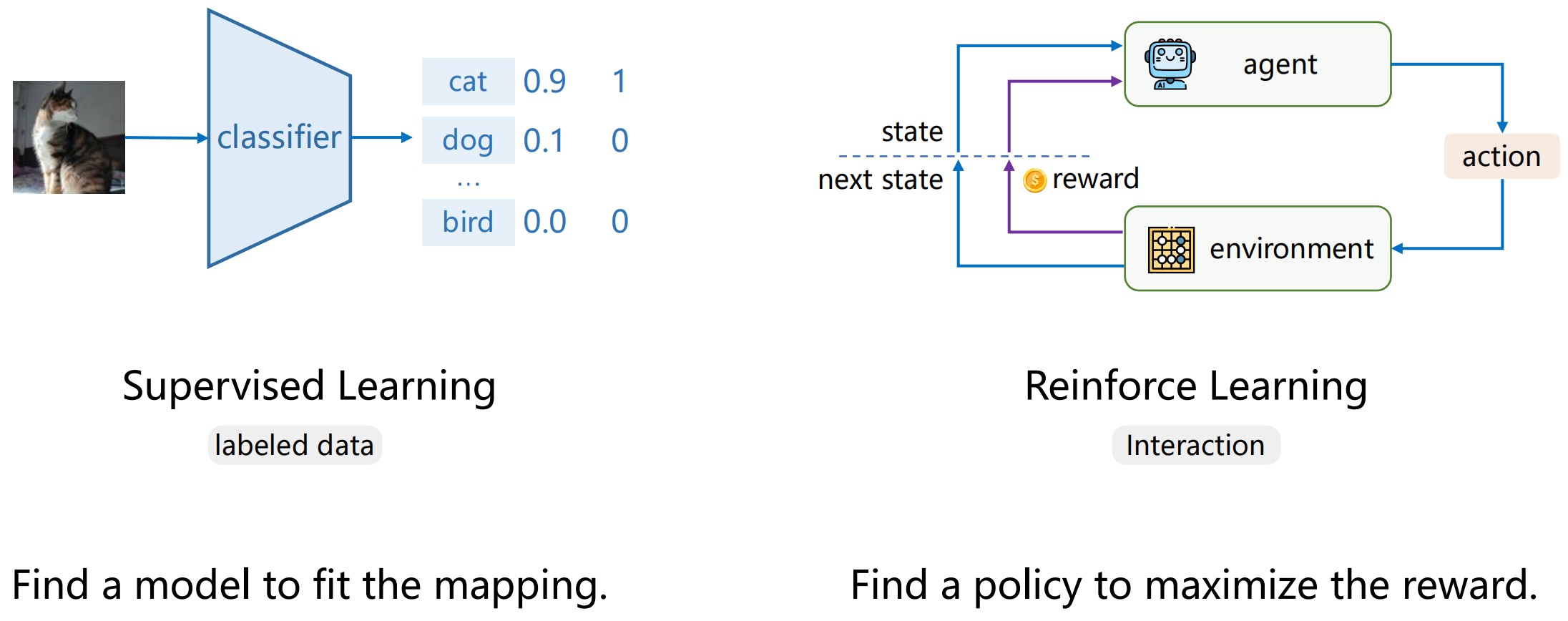
对比监督学习和强化学习
强化学习分类
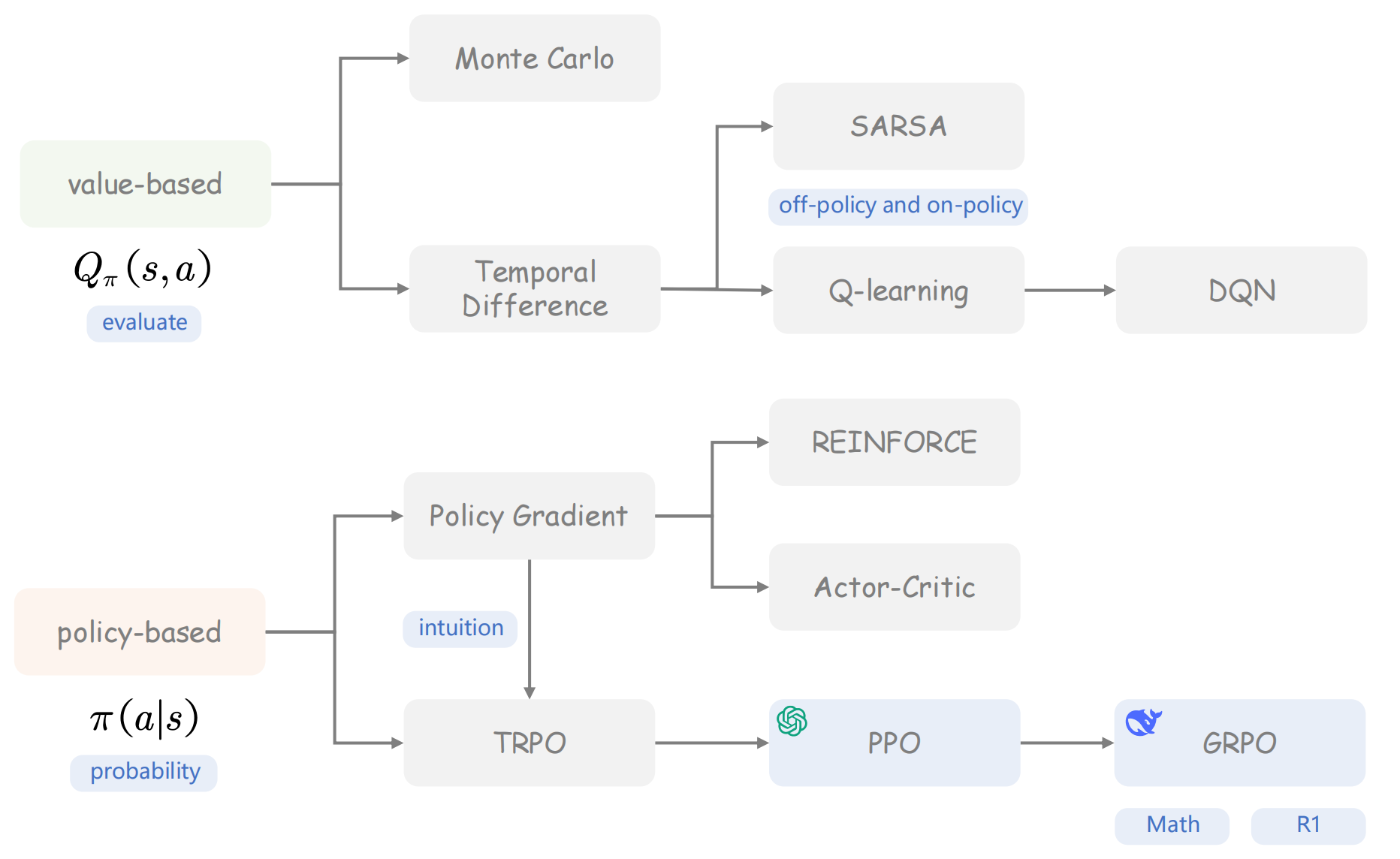
- Value-based方法:相对早期的算法,比如DQN只能用于离散的动作空间,而输出需要是连续值时,DQN则无法实现。
- Policy-based方法:现在比较流行的算法,比如PPO、GRPO,也是这篇博客的重点。这种方法直接学习一个策略函数(actor model),在给定的状态下,输出动作的概率分布π(a∣s)\pi(a|s)π(a∣s)。
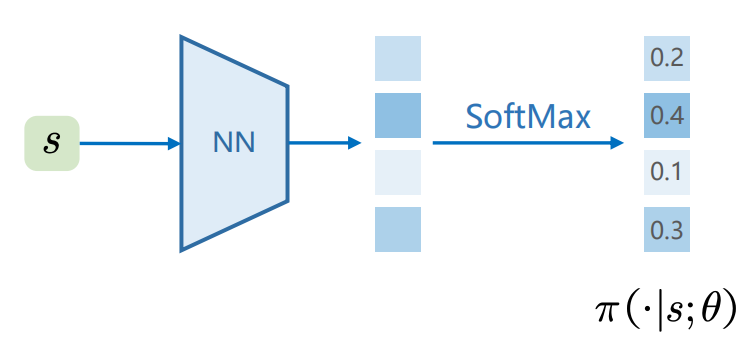
基于Policy的强化学习
Actor-Critic架构
- Actor(策略模型):在给定的状态sss下,输出动作的概率分布π(a∣s)\pi(a|s)π(a∣s)。
- Critic(价值函数):在状态sss下,预测长期累积奖励的期望值V(s)V(s)V(s)。这里很容易疑惑,critic model那reward model的区别是什么?简单来说,reward model通常是环境或人工设计的单步即时奖励信号,无法衡量长期收益。所以critic model的目标就是学习这个V(s)V(s)V(s),以更好地指导actor优化方向。
- Advantage(优势函数):在给定的状态sss下,动作aaa比平均水平好多少,计算方式是A(s,a)=Q(s,a)−V(s)A(s,a)= Q(s,a)-V(s)A(s,a)=Q(s,a)−V(s)。优势函数可以给actor带来精确的反馈信号。
这里再举一个直观的例子:actor是运动员,只负责行动,不知道自己做的好不好;critic是教练员,通过当前局势状态,计算价值,用于评估当前这个局面怎么样,critic会去预测从当前状态出发,按照当前策略一直玩下去,最终大概能得多少分,所以critic不决定动作,只负责评价。那教练员如何给运动员提供精确的反馈呢?不能只说“好”或“坏”,而要说“比我预想的要好/坏多少”,这个值就是上面说的advantage。
下面介绍PPO和GRPO算法,首先强烈推荐大家先看博主给的关于强化学习的story:一个故事秒懂强化学习与GRPO!
PPO算法
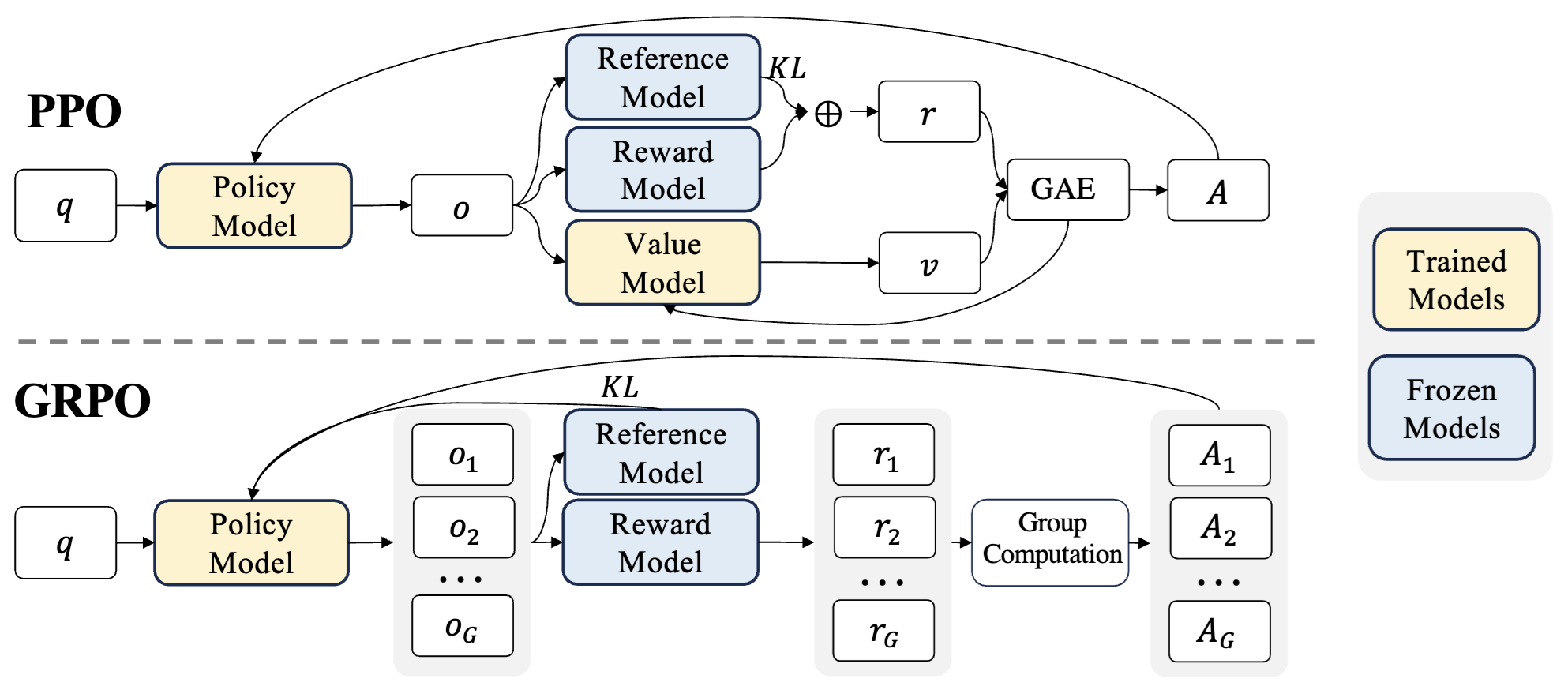
PPO则是基于上面的actor-critic架构,其中critic/value model是一个可训练的模型,一般用actor+linear层或reward model进行初始化(所以通常参数规模和actor一致)。
为了避免actor的更新过程不稳定(更新程度太大),PPO引入了 clipping机制:
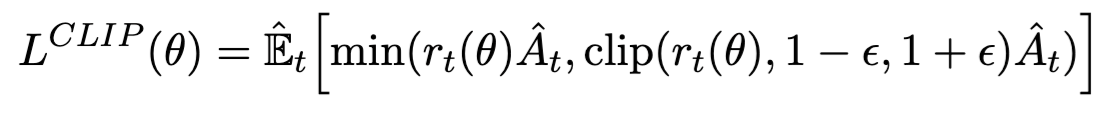
一般来说,ϵ=0.2\epsilon=0.2ϵ=0.2。
其中rt(θ)=πθ(at∣st)πθold(at∣st)r_t(\theta)=\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}rt(θ)=πθold(at∣st)πθ(at∣st),用于衡量新旧策略选择动作ata_tat的概率比,比如rt(θ)>1r_t(\theta)>1rt(θ)>1,说明新策略更倾向于选择ata_tat。
rt(θ)r_t(\theta)rt(θ)是其实是重要性采样,目标是复用旧策略收集的数据,通过新旧策略的概率比修正旧数据的权重,以提高效率。
在PPO中,advantage是由GAE算法得到的【TODO:涉及到时序差分算法】,需要输入critic/value model的输出vvv以及reward rrr。注意这里的reward中包含了KL散度项,目的是保证actor和reference model不要偏离太远:
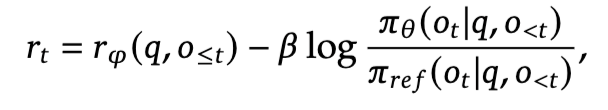
PPO总体优化目标如下(最大化):
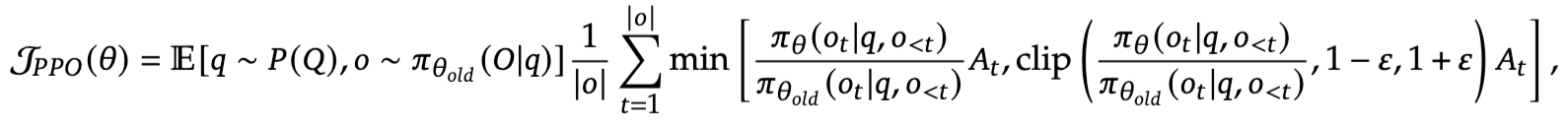
GRPO算法
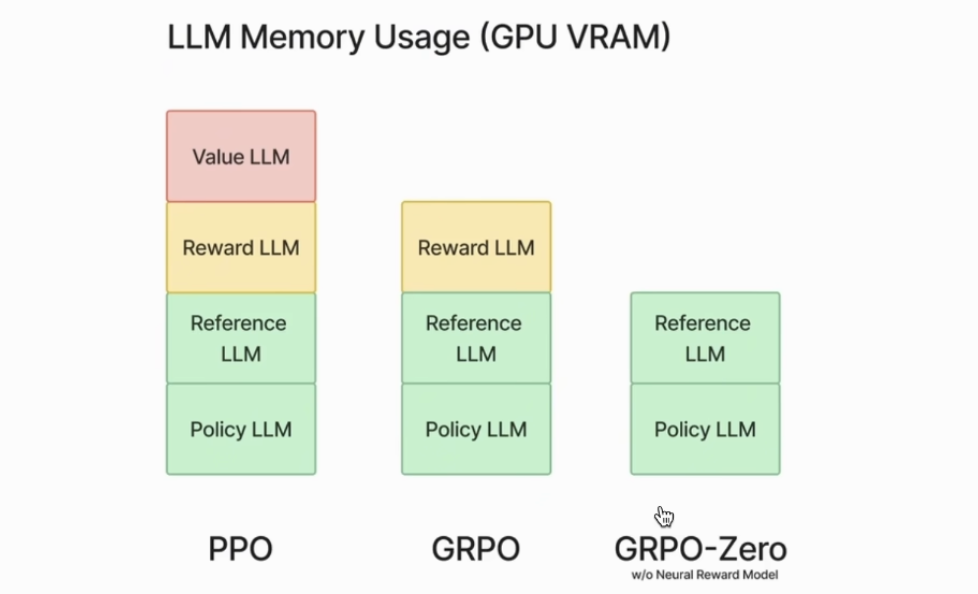
GRPO相比于PPO,去掉了critic/value model,并且通常reward model可以是自定义的规则(比如DeepSeek-R1-Zero中直接判断数学题答案对错),因此也不需要用单独的模型了。这对于强化学习训练来说,省下了可观的显存。
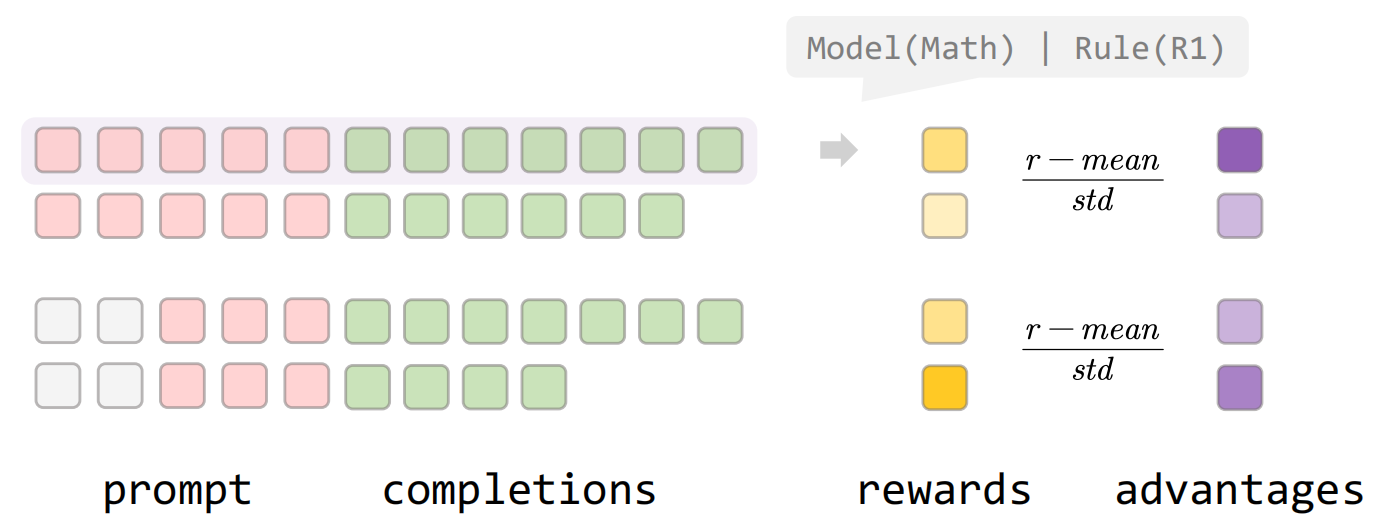
GRPO的核心是引入了一个 “组相对策略” 的概念,对于每一个输入的prompt,会复制多份,并且分别采样生成多个completion,得到reward,把它们看作一组。在组内,将每个输出句子的normalized reward当作每个句子(所有token)的advantage。
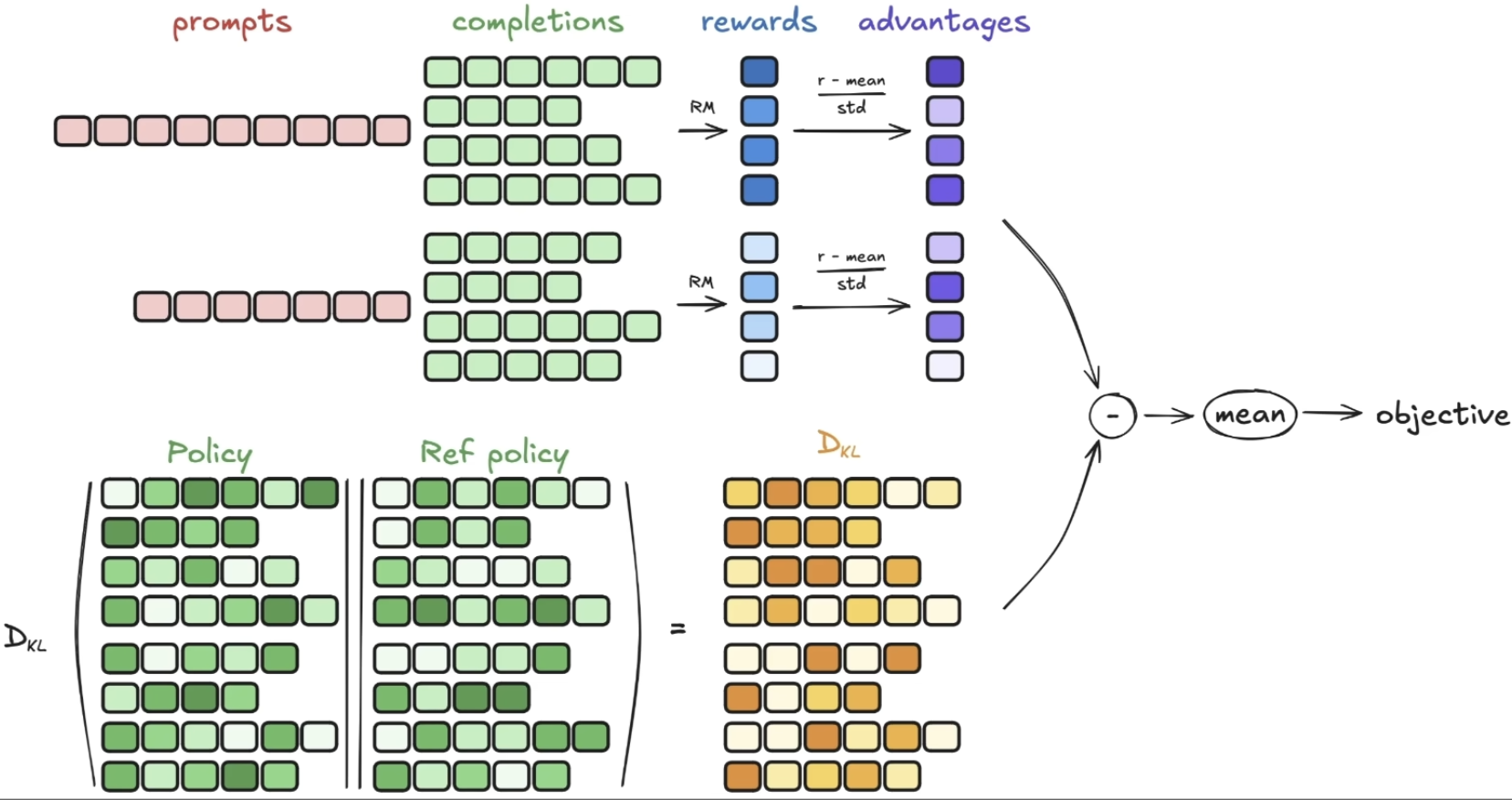
GRPO总体优化目标如下(最大化):
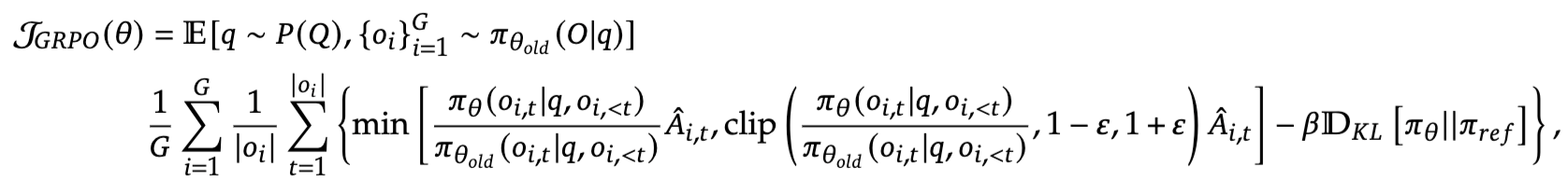
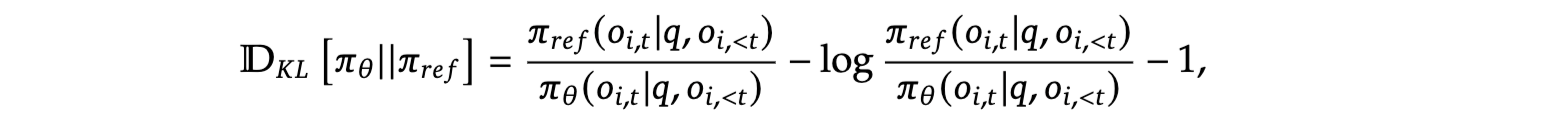
不同于PPO,GRPO中的KL散度项不是在reward的计算中,而是直接写在优化目标中用于actor的更新。
PPO与GRPO结构图
参考资料
- 无需RL基础理解 PPO 和 GRPO
- https://github.com/yogyan6/cartpole-DQN
- PPO基础介绍
- 【大白话03】一文理清强化学习RL基本原理 | 原理图解+公式推导
- 【大白话04】一文理清强化学习PPO和GRPO算法流程 | 原理图解
- PPO已经有了reward model 为何还要有critic model?
- 从原理到代码,带你掌握DeepSeek GRPO!