瑞芯微rk3588:yolov8-obb训练实战笔记
本文内容都是我自己的理解,如果有错误,欢迎指出。
一、数据集标注:
使用软件:roLabelImg
官网: https://github.com/cgvict/roLabelImg
常用的快捷键:
| w | 创建一个矩形框 |
| e | 创建一个旋转矩形框 |
| d | 下一张图像 |
| a | 上一张图像 |
| zxcv | 对矩形框进行顺时针和逆时针的旋转 |
更多快捷键可见上面官网的README.md文件,有详细介绍。
二、标签转换
1、roLabelImg软件生成的xml格式的标签文件
内容如下:

其中box的位置是边框的中心点坐标(cx,cy),图像的宽w,高h,框顺时针旋转的角度angle(范围为(0,))。
2、yolov8训练标签的格式:
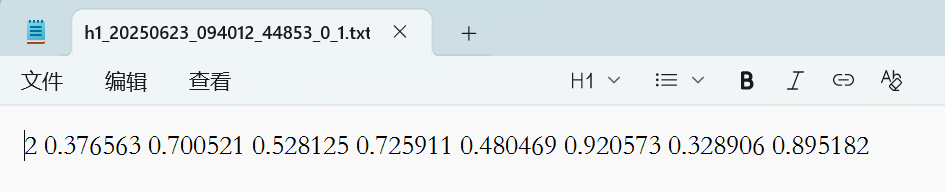
一共是九个数值,第一个是类别序号,后面八个是矩形框四个顶点的归一化之后的坐标位置x0,x1,x2,x3,x4,x5,x6,x7。
3、转换步骤:
将(cx,cy,angle)转换为(x0,x1),(x2,x3),(x4,x5),(x6,x7)的形式。
在二维坐标系中,(x,y)以原点为中心逆时针旋转 之后得到的
的转换公式为:
而roLabelImg软件的标签是以顺时针为正向,因此需要将公式调整如下:
相关代码实现可参考:【yolov8旋转框检测】微调yolov8-obb目标检测模型:数据集制作和训练_yolov8旋转目标检测-CSDN博客
下面是我整理过的代码:
import os
import xml.etree.ElementTree as ET
import mathcls_list = ['obj1', 'obj2', 'obj3'] # 修改为自己的类别名称def convert_dota_xml(xml_file, dotaxml_file):if os.path.basename(xml_file).endswith('xml') :tree = ET.parse(xml_file)objs = tree.findall('object')for ix, obj in enumerate(objs):x0 = ET.Element("x0") # 创建节点y0 = ET.Element("y0")x1 = ET.Element("x1")y1 = ET.Element("y1")x2 = ET.Element("x2")y2 = ET.Element("y2")x3 = ET.Element("x3")y3 = ET.Element("y3")if (obj.find('robndbox') == None):obj_bnd = obj.find('bndbox')obj_xmin = obj_bnd.find('xmin')obj_ymin = obj_bnd.find('ymin')obj_xmax = obj_bnd.find('xmax')obj_ymax = obj_bnd.find('ymax')# 以防有负值坐标xmin = max(float(obj_xmin.text), 0)ymin = max(float(obj_ymin.text), 0)xmax = max(float(obj_xmax.text), 0)ymax = max(float(obj_ymax.text), 0)obj_bnd.remove(obj_xmin) # 删除节点obj_bnd.remove(obj_ymin)obj_bnd.remove(obj_xmax)obj_bnd.remove(obj_ymax)x0.text = str(xmin)y0.text = str(ymax)x1.text = str(xmax)y1.text = str(ymax)x2.text = str(xmax)y2.text = str(ymin)x3.text = str(xmin)y3.text = str(ymin)else:obj_bnd = obj.find('robndbox')obj_bnd.tag = 'bndbox' # 修改节点名obj_cx = obj_bnd.find('cx')obj_cy = obj_bnd.find('cy')obj_w = obj_bnd.find('w')obj_h = obj_bnd.find('h')obj_angle = obj_bnd.find('angle')cx = float(obj_cx.text)cy = float(obj_cy.text)w = float(obj_w.text)h = float(obj_h.text)angle = float(obj_angle.text)obj_bnd.remove(obj_cx) # 删除节点obj_bnd.remove(obj_cy)obj_bnd.remove(obj_w)obj_bnd.remove(obj_h)obj_bnd.remove(obj_angle)x0.text, y0.text = rotatePoint(cx, cy, cx - w / 2, cy - h / 2, -angle)x1.text, y1.text = rotatePoint(cx, cy, cx + w / 2, cy - h / 2, -angle)x2.text, y2.text = rotatePoint(cx, cy, cx + w / 2, cy + h / 2, -angle)x3.text, y3.text = rotatePoint(cx, cy, cx - w / 2, cy + h / 2, -angle)# obj.remove(obj_type) # 删除节点obj_bnd.append(x0) # 新增节点obj_bnd.append(y0)obj_bnd.append(x1)obj_bnd.append(y1)obj_bnd.append(x2)obj_bnd.append(y2)obj_bnd.append(x3)obj_bnd.append(y3)tree.write(dotaxml_file, method='xml', encoding='utf-8') # 更新xml文件# 转换成四点坐标
def rotatePoint(xc, yc, xp, yp, theta):xoff = xp - xcyoff = yp - yccosTheta = math.cos(theta)sinTheta = math.sin(theta)pResx = cosTheta * xoff + sinTheta * yoffpResy = - sinTheta * xoff + cosTheta * yoffreturn str(int(xc + pResx)), str(int(yc + pResy))def totxt(xml_path, txt_save_dir_path, W, H):files = os.listdir(xml_path)i = 0for file in files:tree = ET.parse(xml_path + os.sep + file)name = file.split('.')[0]txt_save_path = txt_save_dir_path + '/' + name + '.txt'file = open(txt_save_path, 'w')i = i + 1objs = tree.findall('object')for obj in objs:cls = obj.find('name').textbox = obj.find('bndbox')# 直接将坐标归一化x0 = float(box.find('x0').text) / Wy0 = float(box.find('y0').text) / Hx1 = float(box.find('x1').text) / Wy1 = float(box.find('y1').text) / Hx2 = float(box.find('x2').text) / Wy2 = float(box.find('y2').text) / Hx3 = float(box.find('x3').text) / Wy3 = float(box.find('y3').text) / Hif x0 < 0:x0 = 0if x1 < 0:x1 = 0if x2 < 0:x2 = 0if x3 < 0:x3 = 0if y0 < 0:y0 = 0if y1 < 0:y1 = 0if y2 < 0:y2 = 0if y3 < 0:y3 = 0# 直接将数据以yolo训练的格式写到txt文档里面for cls_index, cls_name in enumerate(cls_list):if cls == cls_name:file.write("{} {} {} {} {} {} {} {} {}\n".format(cls_index, x0, y0, x1, y1, x2, y2, x3, y3))file.close()print(f'{txt_save_path}已保存')if __name__ == '__main__':roxml_path = './test/label_xml' # 存放 rolabelme 软件直接生成的 xml 标签的文件夹路径dotaxml_path = './test/label_xml_dota' # 存放原始 xml文件转换成的 dotaxml形式标签的文件夹路径txt_save_path = './test/labels_txt_new' # 存放最后生成的用于 yolo训练的 txt标签的文件夹路径W = 1280 # 原图的宽H = 1536 # 原图的高if not os.path.exists(dotaxml_path):os.makedirs(dotaxml_path)if not os.path.exists(txt_save_path):os.makedirs(txt_save_path)filelist = os.listdir(roxml_path)for file in filelist:convert_dota_xml(os.path.join(roxml_path, file), os.path.join(dotaxml_path, file))totxt(dotaxml_path, txt_save_path, W, H) 可以观察到,我们在上面的公式变换中,已经将取过负值了,代码实现的rotatePoint函数的输入值其实是-angel,那为什么这里带入的还是-angel?这个过程分两步走,第一步,我们想要的旋转后的坐标是顺时针旋转的,但是常规的二维坐标系的变换公式是逆时针旋转的,这个时候我们将-
带入到公式,得到的是我们想要的顺时针旋转之后的坐标,但是这个公式的输入还是逆时针旋转的角度,而obb输出的旋转角度依然是顺时针方向的,所以需要对它取负值。
然后使用下面代码对数据集划分成训练集和验证集:
import os
import shutil
import randomdef moveFile(img_train_dir, img_val_dir, label_train_dir, label_val_dir, rate):img_train_dir_list = os.listdir(img_train_dir) # 取图片的原始路径random.shuffle(img_train_dir_list)filenumber = len(img_train_dir_list)# rate = 0.3 # 自定义抽取图片的比例,比方说100张抽10张,那就是0.1picknumber = int(filenumber * rate) # 按照rate比例从文件夹中取一定数量图片sample = random.sample(img_train_dir_list, picknumber) # 随机选取picknumber数量的样本图片pathDir_label = os.listdir(label_train_dir)for name in sample:shutil.move(img_train_dir + name, img_val_dir + name)for name_label in pathDir_label:name_label_base = os.path.splitext(name_label)[0]name_base = os.path.splitext(name)[0]if (name_label_base == name_base):shutil.move(label_train_dir + name_label, label_val_dir + name_label)returnif __name__ == '__main__':path = './test/imgs' # 图像和txt标签都存放在这个文件夹里面img_train_dir = os.path.join(os.path.join(os.path.dirname(path), 'dataset'), 'images/train/')img_val_dir = os.path.join(os.path.join(os.path.dirname(path), 'dataset'), 'images/val/')label_train_dir = os.path.join(os.path.join(os.path.dirname(path), 'dataset'), 'labels/train/')label_val_dir = os.path.join(os.path.join(os.path.dirname(path), 'dataset'), 'labels/val/')for i in [img_train_dir, img_val_dir, label_train_dir, label_val_dir]:if not os.path.exists(i):os.makedirs(i)path_list = os.listdir(path)for name in path_list:if name.endswith('png'):shutil.copy(os.path.join(path, name), os.path.join(img_train_dir, name))if name.endswith('txt'):shutil.copy(os.path.join(path, name), os.path.join(label_train_dir, name))moveFile(img_train_dir, img_val_dir, label_train_dir, label_val_dir, 0.3)print('数据集划分完成')
划分完成后会在放图像和标签的文件夹的统计文件夹下生成一个dataset文件夹,里面是划分好的训练集和验证集,如下:

三、训练
数据处理好之后,即可开始训练。我是准备在瑞芯微rk3588上部署,因此直接下载了瑞芯微官网的训练代码:
https://github.com/airockchip/ultralytics_yolov8
1、新建数据集配置文件
可以在下面的文件夹中找到一些数据集的配置文件:
可以直接在DOTAv1.yaml的基础上修改成自己的数据集配置文件:
只需要修改里面的path以及names即可,存放位置如下:
2、创建train.py文件:
在ultralytics_yolov8_OBB文件夹下,创建train.py文件如下:
from ultralytics import YOLO
import warnings
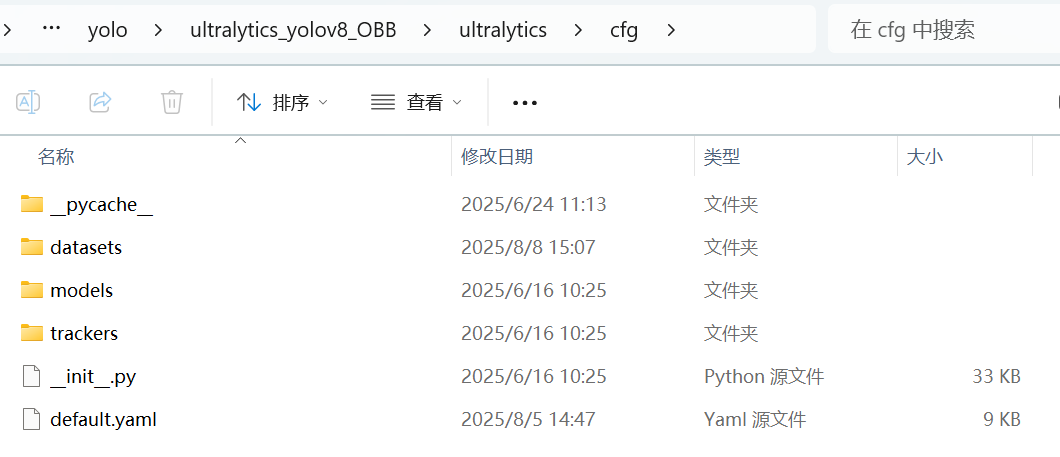
warnings.filterwarnings("ignore", category=UserWarning, module="albumentations")if __name__ == '__main__':# 加载模型# model = YOLO("yolov8n-obb.yaml") # 从 YAML 构建新模型model = YOLO("yolov8n-obb.pt") # 加载预训练模型(推荐用于训练)# model = YOLO("yolov8n-obb.yaml").load("yolov8n.pt") # 从 YAML 构建并转移权重# 训练模型results = model.train(data="train_test.yaml", epochs=100, imgsz=768)训练的相关参数可以看下图文件夹中的default.yaml文件,也可以直接在default.yaml文件中修改。
3、推理图片
新建一个detect.py文件,内容如下:
import osfrom ultralytics import YOLO# Load a model
model = YOLO("./runs/obb/train_2/weights/best.pt") # pretrained YOLO11n modelimg_dir_path= './detect_dir'
img_list = os.listdir(img_dir_path)for name in img_list:img_path = os.path.join(img_dir_path, name)if name.endswith('png'):results = model.predict(source=img_path, save=True, imgsz=768, conf=0.5)for result in results:xywhr = result.obb.xywhr # center-x, center-y, width, height, angle (radians)xyxyxyxy = result.obb.xyxyxyxy # polygon format with 4-pointsnames = [result.names[cls.item()] for cls in result.obb.cls.int()] # class name of each boxconfs = result.obb.conf # confidence score of each boxcls = result.obb.clsprint(f'cls:{cls}, conf:{confs}')4、适配rk3588的onnx模型导出:
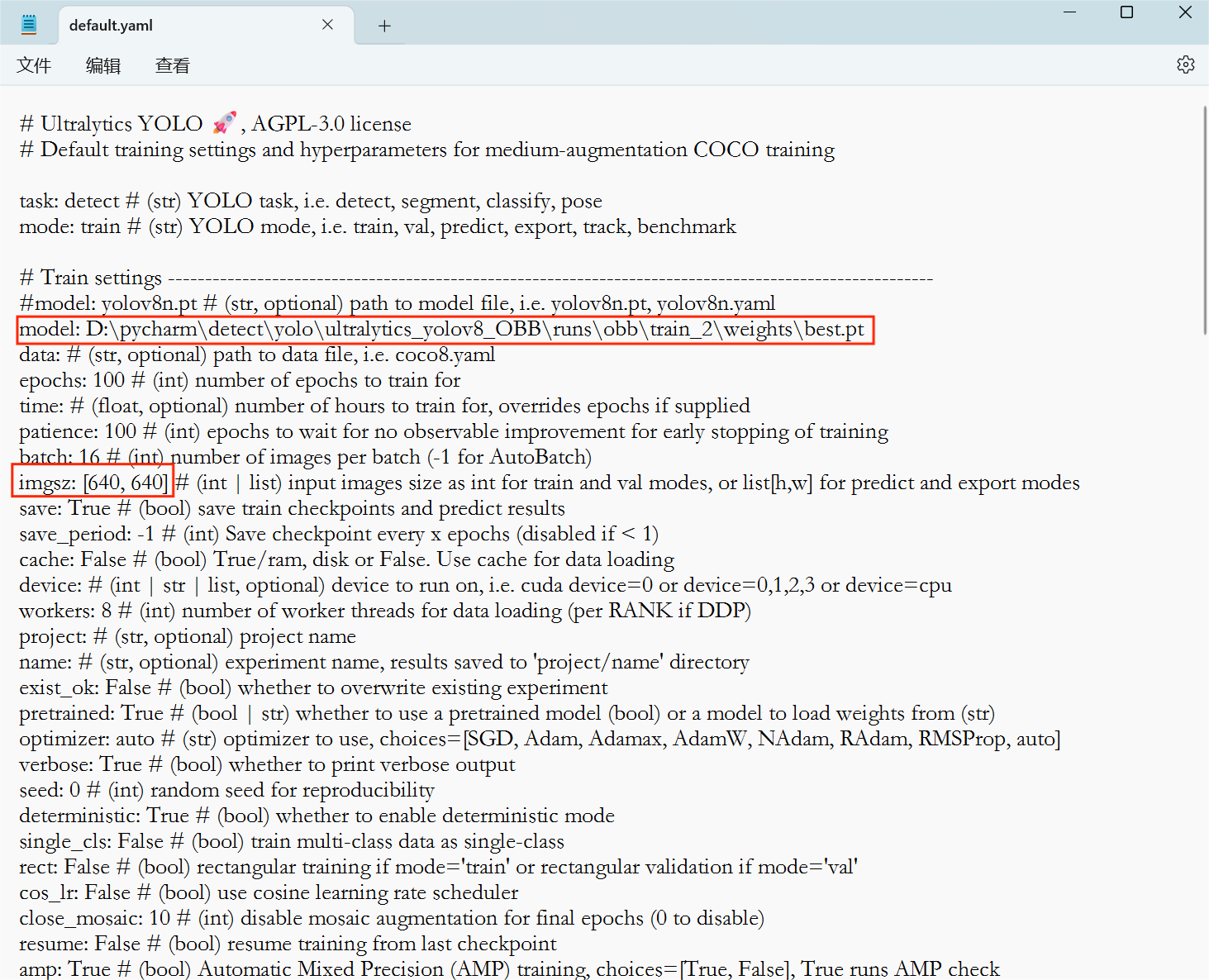
具体可以参考RKOPT_README.zh-CN.md文件,我是直接在default.yaml文件修改如下,model参数是训练好的pt模型的路径,imgsz是转换成onnx模型的输入尺寸大小,format是rknn表示适应rk3588的onnx模型。

然后直接运行exporter.py文件即可。
转换好的onnx模型如下:
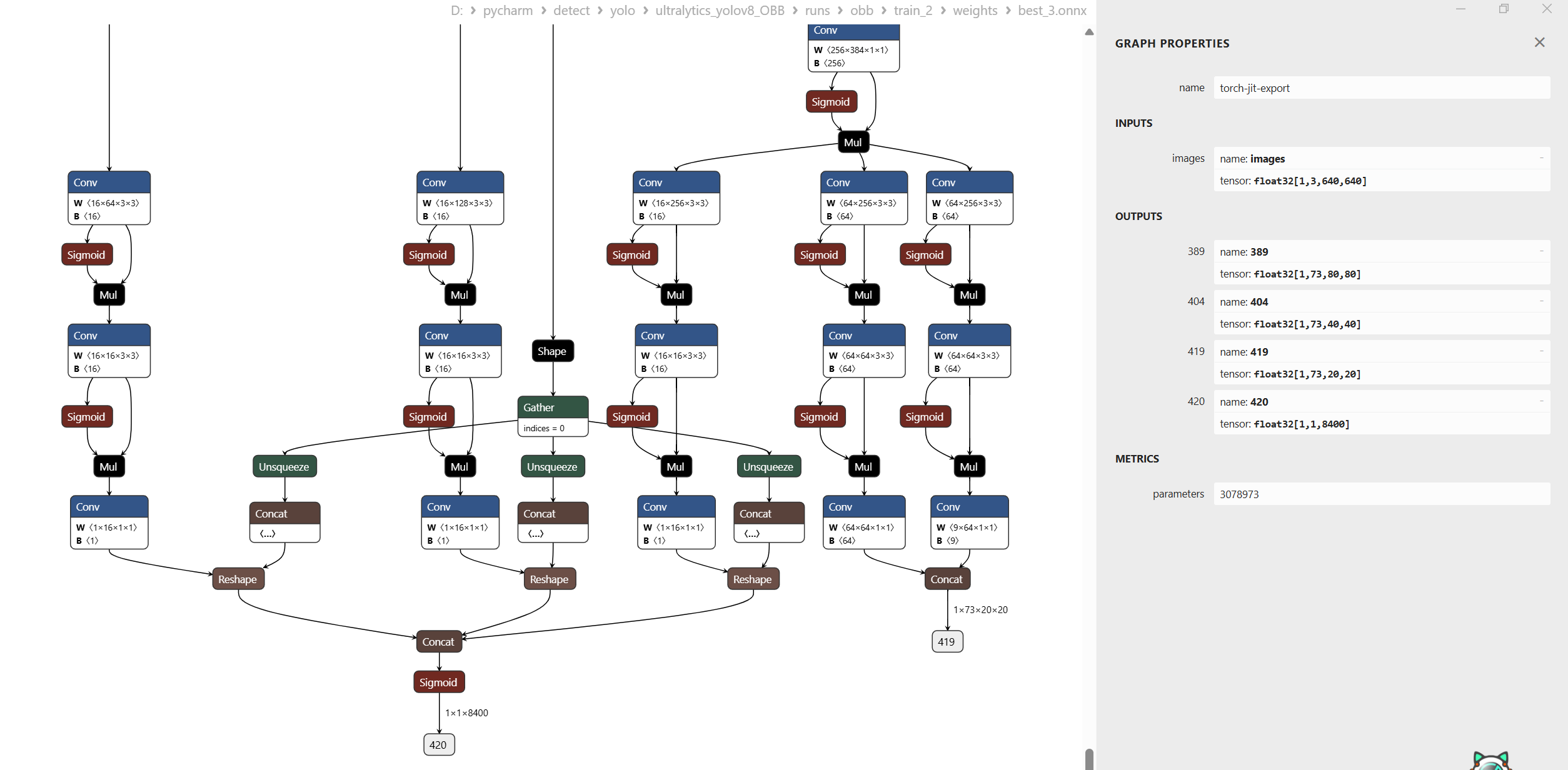
与传统的yolov8-obb的区别如下:

四、后处理
瑞芯微官方给的后处理代码在:
https://github.com/airockchip/rknn_model_zoo/tree/main/examples/yolov8_obb/python
这里我研究的是python的后处理代码,里面也有c++的的后处理代码的demo。下面的代码是我在官方的基础上修改了一些,用于在torch的环境下使用onnx模型推理,官方的代码只适合640*640的输入尺寸,onnx模型的输入尺寸发生变化之后,就会有点问题。
注:下面所有尺寸大小都是以模型输入尺寸为640*640来计算的。
import numpy as np
import argparse
import cv2, mathimport onnxruntime
from shapely.geometry import PolygonCLASSES = ['0', '1', '2', '3', '4', '5', '6', '7', '8']nmsThresh = 0.4
objectThresh = 0.5def letterbox_resize(image, size, bg_color):"""letterbox_resize the image according to the specified size:param image: input image, which can be a NumPy array or file path:param size: target size (width, height):param bg_color: background filling data:return: processed image"""if isinstance(image, str):image = cv2.imread(image)target_width, target_height = sizeimage_height, image_width, _ = image.shape# Calculate the adjusted image sizeaspect_ratio = min(target_width / image_width, target_height / image_height)new_width = int(image_width * aspect_ratio)new_height = int(image_height * aspect_ratio)# Use cv2.resize() for proportional scalingimage = cv2.resize(image, (new_width, new_height), interpolation=cv2.INTER_AREA)# Create a new canvas and fill itresult_image = np.ones((target_height, target_width, 3), dtype=np.uint8) * bg_coloroffset_x = (target_width - new_width) // 2offset_y = (target_height - new_height) // 2result_image[offset_y:offset_y + new_height, offset_x:offset_x + new_width] = imagereturn result_image, aspect_ratio, offset_x, offset_yclass DetectBox:def __init__(self, classId, score, xmin, ymin, xmax, ymax, angle):self.classId = classIdself.score = scoreself.xmin = xminself.ymin = yminself.xmax = xmaxself.ymax = ymaxself.angle = angledef rotate_rectangle(x1, y1, x2, y2, a):# 计算中心点坐标cx = (x1 + x2) / 2cy = (y1 + y2) / 2# 将角度转换为弧度# a = math.radians(a)# 对每个顶点进行旋转变换x1_new = int((x1 - cx) * math.cos(a) - (y1 - cy) * math.sin(a) + cx)y1_new = int((x1 - cx) * math.sin(a) + (y1 - cy) * math.cos(a) + cy)x2_new = int((x2 - cx) * math.cos(a) - (y2 - cy) * math.sin(a) + cx)y2_new = int((x2 - cx) * math.sin(a) + (y2 - cy) * math.cos(a) + cy)x3_new = int((x1 - cx) * math.cos(a) - (y2 - cy) * math.sin(a) + cx)y3_new = int((x1 - cx) * math.sin(a) + (y2 - cy) * math.cos(a) + cy)x4_new = int((x2 - cx) * math.cos(a) - (y1 - cy) * math.sin(a) + cx)y4_new = int((x2 - cx) * math.sin(a) + (y1 - cy) * math.cos(a) + cy)return [(x1_new, y1_new), (x3_new, y3_new), (x2_new, y2_new), (x4_new, y4_new)]def intersection(g, p):g = np.asarray(g)p = np.asarray(p)g = Polygon(g[:8].reshape((4, 2)))p = Polygon(p[:8].reshape((4, 2)))if not g.is_valid or not p.is_valid:return 0inter = Polygon(g).intersection(Polygon(p)).areaunion = g.area + p.area - interif union == 0:return 0else:return inter / uniondef NMS(detectResult):predBoxs = []# 按照置信度排序sort_detectboxs = sorted(detectResult, key=lambda x: x.score, reverse=True)for i in range(len(sort_detectboxs)):# 取出得分最高的一个框为基准,与其他的框做 nmsxmin1 = sort_detectboxs[i].xminymin1 = sort_detectboxs[i].yminxmax1 = sort_detectboxs[i].xmaxymax1 = sort_detectboxs[i].ymaxclassId = sort_detectboxs[i].classIdangle = sort_detectboxs[i].angle# 计算旋转之后的预测框左上角和右下角坐标p1 = rotate_rectangle(xmin1, ymin1, xmax1, ymax1, angle)p1 = np.array(p1).reshape(-1)if sort_detectboxs[i].classId != -1:predBoxs.append(sort_detectboxs[i])for j in range(i + 1, len(sort_detectboxs), 1):# 按类别分别进行 NMSif classId == sort_detectboxs[j].classId:xmin2 = sort_detectboxs[j].xminymin2 = sort_detectboxs[j].yminxmax2 = sort_detectboxs[j].xmaxymax2 = sort_detectboxs[j].ymaxangle2 = sort_detectboxs[j].anglep2 = rotate_rectangle(xmin2, ymin2, xmax2, ymax2, angle2)p2 = np.array(p2).reshape(-1)iou = intersection(p1, p2)if iou > nmsThresh:sort_detectboxs[j].classId = -1return predBoxsdef sigmoid(x):return 1 / (1 + np.exp(-x))def softmax(x, axis=-1):# 将输入向量减去最大值以提高数值稳定性exp_x = np.exp(x - np.max(x, axis=axis, keepdims=True))return exp_x / np.sum(exp_x, axis=axis, keepdims=True)def process(out, model_w, model_h, stride, angle_feature, index, scale_w=1, scale_h=1):class_num = len(CLASSES) # 9angle_feature = angle_feature.reshape(-1) # (1,8400)全部的 angle信息都在一起,单独的一个头xywh = out[:, :64, :] # (1, 64, 6400) 4*16,16个值代表一个数值conf = sigmoid(out[:, 64:, :]) # (1, 9, 6400)out = []conf = conf.reshape(-1)# 使用置信度阈值进行第一次筛选for ik in range(model_h * model_w * class_num):if conf[ik] > objectThresh:# w,h分别表示在feature map尺寸下,anchor_point的位置, c表示类别w = ik % model_wh = (ik % (model_w * model_h)) // model_wc = ik // (model_w * model_h)# 取出前 64 位数据用来解码(l,t,r,b), 64 = 4 * 16, 16位数据表示一个分量xywh_ = xywh[0, :, (h * model_w) + w] # [1,64,1]xywh_ = xywh_.reshape(1, 4, 16, 1)data = np.array([i for i in range(16)]).reshape(1, 1, 16, 1)xywh_ = softmax(xywh_, 2)xywh_ = np.multiply(data, xywh_)xywh_ = np.sum(xywh_, axis=2, keepdims=True).reshape(-1) # 解码之后的(l,t,r,b)数据xywh_add = xywh_[:2] + xywh_[2:] # (l+r, t+b) : box_w, box_hxywh_sub = (xywh_[2:] - xywh_[:2]) / 2 # (r-l, b-t)/2 : w/2, h/2angle_feature_ = (angle_feature[index + (h * model_w) + w] - 0.25) * 3.1415927410125732angle_feature_cos = math.cos(angle_feature_)angle_feature_sin = math.sin(angle_feature_)# 计算旋转之后的预测框中心在 featur map尺寸下,相对于 anchor_point的偏移量xy_mul1 = xywh_sub[0] * angle_feature_cosxy_mul2 = xywh_sub[1] * angle_feature_sinxy_mul3 = xywh_sub[0] * angle_feature_sinxy_mul4 = xywh_sub[1] * angle_feature_cosx, y = xy_mul1 - xy_mul2, xy_mul3 + xy_mul4 # 旋转之后的预测框中心以anchor_point为原点的局部偏移量# xywh_1 = np.array([(xy_mul1 - xy_mul2) + w + 0.5, (xy_mul3 + xy_mul4) + h + 0.5, xywh_add[0], xywh_add[1]])#[x,y,w,h] 将局部预测框中心映射到feature map的位置xywh_1 = np.array([x + w + 0.5, y + h + 0.5, xywh_add[0], xywh_add[1]])xywh_ = xywh_1 * stride # (x,y,w,h): 将feature map下的坐标映射到原图中的位置# 计算出预测框在原图的尺寸下,以(x,y)为中心的轴对齐预测框的左上角和右下角坐标xmin = (xywh_[0] - xywh_[2] / 2) * scale_wymin = (xywh_[1] - xywh_[3] / 2) * scale_hxmax = (xywh_[0] + xywh_[2] / 2) * scale_wymax = (xywh_[1] + xywh_[3] / 2) * scale_h# 最终的box信息为:类别,置信度,预测框的左上角和右下角的在原图尺寸下的坐标,旋转度数box = DetectBox(c, conf[ik], xmin, ymin, xmax, ymax, angle_feature_)out.append(box)print()return outdef model_load(args):weights = args.model_pathw = str(weights[0] if isinstance(weights, list) else weights)providers = ['CPUExecutionProvider']session = onnxruntime.InferenceSession(w, providers=providers)return sessionif __name__ == '__main__':parser = argparse.ArgumentParser(description='RetinaFace Python Demo', add_help=True)# basic paramsparser.add_argument('--model_path', type=str, default='./model/best_3.onnx', help='model path, could be .rknn file')parser.add_argument('--target', type=str,default='rk3588', help='target RKNPU platform')args = parser.parse_args()# 加载onnx模型session = model_load(args)input_shape = session.get_inputs()[0].shapeoutput_names = [x.name for x in session.get_outputs()]output_shape_list = [x.shape for x in session.get_outputs()]# 读取输入图像img_path = './ydj_img_test/q1_20250725_104429_7358.png'# Set inputsimg = cv2.imread(img_path)# 对图像进行预处理letterbox_img, aspect_ratio, offset_x, offset_y = letterbox_resize(img, (input_shape[3], input_shape[2]), 114) # letterbox缩放infer_img = letterbox_img[..., ::-1] # BGR2RGBinfer_img = infer_img.transpose((2, 0, 1)) # [640,640,3]->[3,640,640]infer_img = infer_img.reshape(1, *infer_img.shape).astype(np.float32) # [3,640,640]->[1,3,640,640],并转换成浮点数infer_img = infer_img / 255. # 归一化# Inferenceprint('--> Running model')# 模型推理if not isinstance(infer_img, np.ndarray):im = np.array(infer_img)# 四个输出头,前三个是位置信息+分类信息,第四个是旋转角度信息# 尺寸大小分别为:[1,64+cls,80,80], [1,64+cls,40,40], [1,64+cls,20,20], [1,1,8400]results = session.run(output_names, {session.get_inputs()[0].name: infer_img})# 模型输出结果后处理outputs = []i = 0# 对前三个输出的数据进行处理(包含解码位置坐标,NMS等)for x in results[:-1]:i += 1output_shape = x.shapeindex, stride = 0, 0if x.shape[2] == output_shape_list[2][2]:stride = 32index = output_shape_list[2][2] * 4 * output_shape_list[2][3] * 4 + output_shape_list[2][2] * 2 * output_shape_list[2][3] * 2if x.shape[2] == output_shape_list[1][2]:stride = 16index = output_shape_list[2][2] * 4 * output_shape_list[2][3] * 4if x.shape[2] == output_shape_list[0][2]:stride = 8index = 0feature = x.reshape(1, output_shape[1], -1)output = process(feature, x.shape[3], x.shape[2], stride, results[-1], index)outputs = outputs + outputprint('\n\n\n\n')# nms,返回的坐标还是轴对齐预测框的左上角和右下角坐标,cls,旋转角度predbox = NMS(outputs)for index in range(len(predbox)):# 计算letterbox上的预测框位置在原图上的位置xmin = int((predbox[index].xmin - offset_x) / aspect_ratio)ymin = int((predbox[index].ymin - offset_y) / aspect_ratio)xmax = int((predbox[index].xmax - offset_x) / aspect_ratio)ymax = int((predbox[index].ymax - offset_y) / aspect_ratio)classId = predbox[index].classIdscore = predbox[index].scoreangle = predbox[index].angle# 旋转预测框points = rotate_rectangle(xmin, ymin, xmax, ymax, angle)cv2.polylines(img, [np.asarray(points, dtype=int)], True, (0, 255, 0), 1)ptext = (xmin, ymin)title = CLASSES[classId] + " %.2f" % scorecv2.putText(img, title, ptext, cv2.FONT_HERSHEY_DUPLEX, 0.5, (0, 0, 255), 1)img_path = './result.jpg'cv2.imwrite(img_path, img)print("save image in", img_path)下面进行分块解析:
1、加载onnx模型:
def model_load(args):weights = args.model_pathw = str(weights[0] if isinstance(weights, list) else weights)providers = ['CPUExecutionProvider']session = onnxruntime.InferenceSession(w, providers=providers)return session使用onnxruntime来加载onnx模型,并返回session。瑞芯微给的demo里面是直接加载的rknn模型,需要对应的环境,不能直接使用,这里我写改为使用onnx模型进行推理。
然后调用model_load函数:
# 加载onnx模型session = model_load(args)input_shape = session.get_inputs()[0].shapeoutput_names = [x.name for x in session.get_outputs()]output_shape_list = [x.shape for x in session.get_outputs()]通过模型得到输入尺寸和输出尺寸。
2、数据预处理:
# 对图像进行预处理letterbox_img, aspect_ratio, offset_x, offset_y = letterbox_resize(img, (input_shape[3], input_shape[2]), 114) # letterbox缩放infer_img = letterbox_img[..., ::-1] # BGR2RGBinfer_img = infer_img.transpose((2, 0, 1)) # [640,640,3]->[3,640,640]infer_img = infer_img.reshape(1, *infer_img.shape).astype(np.float32) # [3,640,640]->[1,3,640,640],并转换成浮点数infer_img = infer_img / 255. # 归一化3、模型推理:
# 四个输出头,前三个是位置信息+分类信息,第四个是旋转角度信息# 尺寸大小分别为:[1,64+cls,80,80], [1,64+cls,40,40], [1,64+cls,20,20], [1,1,8400]results = session.run(output_names, {session.get_inputs()[0].name: infer_img})这里的onnx模型是已经经过裁剪之后,一共有四个输出头。其中中间的64+cls维度中的 64 代表的是预测框的位置信息(l, t, r, b),分别表示anchor point距离预测框左边框,上边框,右边框和下边框的距离,那么为什么是64位呢,而不是直接的四位?这里是基于DFL损失设计的,具体的细节可以参考:YOLO中的DFL损失函数的理论讲解与代码分析-CSDN博客。cls代表一共有多少类别。
4、模型结果处理:
# 用于存放三个输出头处理之后的结果outputs = []i = 0# 对前三个输出的数据进行处理(包含解码位置坐标,NMS等)for x in results[:-1]:i += 1output_shape = x.shapeindex, stride = 0, 0if x.shape[2] == output_shape_list[2][2]:stride = 32index = output_shape_list[2][2] * 4 * output_shape_list[2][3] * 4 + output_shape_list[2][2] * 2 * output_shape_list[2][3] * 2if x.shape[2] == output_shape_list[1][2]:stride = 16index = output_shape_list[2][2] * 4 * output_shape_list[2][3] * 4if x.shape[2] == output_shape_list[0][2]:stride = 8index = 0feature = x.reshape(1, output_shape[1], -1)output = process(feature, x.shape[3], x.shape[2], stride, results[-1], index)outputs = outputs + output依次取出模型的前三个输出头的结果,分别进行处理。output_shape_list是由三个输出头的输出尺寸构成的列表,其中:
output_shape_list[0]=(1, 64+cls, 80, 80)对应的stride=8
output_shape_list[1]=(1, 64+cls, 40, 40)对应的stride=16
output_shape_list[2]=(1, 64+cls, 20, 20)对应的stride=32
根据x的第三个通道(也就是图像的高度h)的大小来判断x是属于第几个输出头,从而来计算anchor-point的index,比如说第一个输出头空间大小为80*80,也就是说这一层一共有6400个anchor-point,那么第一个输出头的anchor-point的index就是从0开始计数的,范围为(0,6399),第二个输出头的尺寸为40*40,一共有1600个anchor-point,index从6400开始计数,范围为:(6400, 80*80+40*40-1),第三个输出头尺寸为20*20,一共有400个anchor-point,index从8000(6400+1600)开始,范围为(8000, 80*80+40*40+20*20-1)。也就是说为每一个anchor-point都设置一个序号index用来从第四个输出头中取出对应的旋转角度。
计算完index之后,开始使用process函数分别处理每一个输出头的特征,process函数处理过程见下一部分。
5、process函数部分
这里的数据以第一个输出头(1,64+cls, 80,80)为例。
def process(out, model_w, model_h, stride, angle_feature, index, scale_w=1, scale_h=1):class_num = len(CLASSES) # 9angle_feature = angle_feature.reshape(-1) # (1,8400)全部的 angle信息都在一起,单独的一个头xywh = out[:, :64, :] # (1, 64, 6400) 4*16,16个值代表一个数值conf = sigmoid(out[:, 64:, :]) # (1, 9, 6400)out = []conf = conf.reshape(-1)# 使用置信度阈值进行第一次筛选for ik in range(model_h * model_w * class_num):if conf[ik] > objectThresh:# w,h分别表示在feature map尺寸下,anchor_point的位置, c表示类别w = ik % model_wh = (ik % (model_w * model_h)) // model_wc = ik // (model_w * model_h)# 取出前 64 位数据用来解码(l,t,r,b), 64 = 4 * 16, 16位数据表示一个分量xywh_ = xywh[0, :, (h * model_w) + w] # [1,64,1]xywh_ = xywh_.reshape(1, 4, 16, 1)data = np.array([i for i in range(16)]).reshape(1, 1, 16, 1)xywh_ = softmax(xywh_, 2)xywh_ = np.multiply(data, xywh_)xywh_ = np.sum(xywh_, axis=2, keepdims=True).reshape(-1) # 解码之后的(l,t,r,b)数据xywh_add = xywh_[:2] + xywh_[2:] # (l+r, t+b) : box_w, box_hxywh_sub = (xywh_[2:] - xywh_[:2]) / 2 # (r-l, b-t)/2 : w/2, h/2angle_feature_ = (angle_feature[index + (h * model_w) + w] - 0.25) * 3.1415927410125732angle_feature_cos = math.cos(angle_feature_)angle_feature_sin = math.sin(angle_feature_)# 计算旋转之后的预测框中心在 featur map尺寸下,相对于 anchor_point的偏移量xy_mul1 = xywh_sub[0] * angle_feature_cosxy_mul2 = xywh_sub[1] * angle_feature_sinxy_mul3 = xywh_sub[0] * angle_feature_sinxy_mul4 = xywh_sub[1] * angle_feature_cosx, y = xy_mul1 - xy_mul2, xy_mul3 + xy_mul4 # 旋转之后的预测框中心以anchor_point为原点的局部偏移量# xywh_1 = np.array([(xy_mul1 - xy_mul2) + w + 0.5, (xy_mul3 + xy_mul4) + h + 0.5, xywh_add[0], xywh_add[1]])#[x,y,w,h] 将局部预测框中心映射到feature map的位置xywh_1 = np.array([x + w + 0.5, y + h + 0.5, xywh_add[0], xywh_add[1]])xywh_ = xywh_1 * stride # (x,y,w,h): 将feature map下的坐标映射到原图中的位置# 计算出预测框在原图的尺寸下,以(x,y)为中心的轴对齐预测框的左上角和右下角坐标xmin = (xywh_[0] - xywh_[2] / 2) * scale_wymin = (xywh_[1] - xywh_[3] / 2) * scale_hxmax = (xywh_[0] + xywh_[2] / 2) * scale_wymax = (xywh_[1] + xywh_[3] / 2) * scale_h# 最终的box信息为:类别,置信度,预测框的左上角和右下角的在原图尺寸下的坐标,旋转度数box = DetectBox(c, conf[ik], xmin, ymin, xmax, ymax, angle_feature_)out.append(box)return out输入的值为:
out:为模型输出特征,即前面的(1, 64+cls, 80, 80),(1, 64+cls, 40, 40),(1, 64+cls, 20, 20),这里以(1, 64+cls, 80, 80)为例解析代码
model_w:这一个输出头特征的宽度(80)
model_h:这一个输出头特征的高度(80)
stride:这一个输出头对应的下采样倍数(8)
angle_feature:第四个输出头的所有旋转角度信息
index:这一个输出头的anchor-point开始的index序号
整体的流程如下:
- 先将64+cls前64维提取出来解析位置信息,后面cls维是分类信息。
- 通过设置的阈值先将低于阈值的框筛除掉
- 使用DFL设计规则解析出(l, t, r, b),计算出预测框的宽高以及中心坐标位置
这里需要注意的是:直接通过DFL解析出来的预测框是轴对齐的预测框,还没有经过旋转,这里假设为box_AABB(Axis Aligned Bound Box),且第四个输出头给出的旋转角度,是box_AABB以anchor-point为中心点旋转的角度,因此需要先计算出box_AABB的中心点坐标(x_AABB, y_AABB),通过二维坐标旋转公式计算出box_AABB的中心点坐标(x_AABB, y_AABB)以anchor-point为原点旋转之后的中心点坐标才是最终预测框的中心点坐标(x,y)。
- 并根据中心点坐标与宽高计算出预测框的左上角以及右下角坐标,并将左上角和右下角坐标以及宽高映射到原图的尺寸上
这里需要注意的是,前面一步进行的旋转变换只是计算出旋转之后的中心点坐标,这一步中计算预测框的左上角和右下角坐标依旧是轴对齐的,没有经过旋转。
- 将类别,置信度,预测框的左上角和右下角的在原图尺寸下的坐标,旋转度数返回
回到main函数中,将前三个输出头的经过处理之后得到的数据拼接到一起,进行NMS操作。
6、NMS
def NMS(detectResult):predBoxs = []# 按照置信度排序sort_detectboxs = sorted(detectResult, key=lambda x: x.score, reverse=True)for i in range(len(sort_detectboxs)):# 取出得分最高的一个框为基准,与其他的框做 nmsxmin1 = sort_detectboxs[i].xminymin1 = sort_detectboxs[i].yminxmax1 = sort_detectboxs[i].xmaxymax1 = sort_detectboxs[i].ymaxclassId = sort_detectboxs[i].classIdangle = sort_detectboxs[i].angle# 计算旋转之后的预测框左上角和右下角坐标p1 = rotate_rectangle(xmin1, ymin1, xmax1, ymax1, angle)p1 = np.array(p1).reshape(-1)if sort_detectboxs[i].classId != -1:predBoxs.append(sort_detectboxs[i])for j in range(i + 1, len(sort_detectboxs), 1):# 按类别分别进行 NMSif classId == sort_detectboxs[j].classId:xmin2 = sort_detectboxs[j].xminymin2 = sort_detectboxs[j].yminxmax2 = sort_detectboxs[j].xmaxymax2 = sort_detectboxs[j].ymaxangle2 = sort_detectboxs[j].anglep2 = rotate_rectangle(xmin2, ymin2, xmax2, ymax2, angle2)p2 = np.array(p2).reshape(-1)iou = intersection(p1, p2)if iou > nmsThresh:sort_detectboxs[j].classId = -1return predBoxs输入数据:
detectResult:是模型前三个输出头经过第一批阈值过滤之后剩下的预测框拼接的结果
NMS具体步骤如下:
- 根据预测框的分类得分进行降序排序
- 从排序之后的列表中选出第一个预测框,也就是分类得分最高的一个预测框作为基准,记作box_max,并计算旋转之后的左上角和右下角坐标。然后判断该预测框的classId是否为-1,如果为-1说明前面已经遍历过了,如果不为-1,将其加入到predBoxs中,进行下一步
- 从上一步的基准box_max后面一个预测框开始遍历余下的预测框,判断预测框分类的类别与box_max是否一致,如果一致,则计算该预测框旋转之后左上角与右下角的坐标,并与box_max计算iou,如果iou大于设定的阈值,说明两个预测框重合度过高,认定为是一个目标,则将这个预测框的classId设置为-1,避免之后继续遍历到。
- 然后取出排序列表的第二个预测框,重复第二和第三步,知道将所有的预测框遍历完成。
7、最终处理
返回到main函数中,经过nms处理之后的所有预测框都对应着一个预测出来的目标。且nms返回的预测框的位置信息还是轴对齐的,需要进一步的进行旋转处理,然后再映射回原图中去。