网站服务器 英文高端网站建设深圳
本项目基于UCI的声呐目标识别数据集(Sonar, Mines vs. Rocks),通过10种机器学习算法比较,发现集成学习方法表现最优。研究首先对60个声呐能量特征进行可视化分析(分布直方图、相关性矩阵),对比了基础算法(如KNN、SVM)和集成算法(如随机森林、梯度提升)的10折交叉验证准确率。结果显示标准化后模型性能提升,其中额外树(ExtraTrees)表现最佳(准确率88.6%),并通过网格搜索优化超参数。最后利用SHAP值解释模型,揭示关键特征(如Feature 10)对预测的贡献度,为声呐目标分类提供了可解释的解决方案。完整代码已开源在个人GitHubhttps://github.com/KLWU07/Machine-learning-Project-practice。
一、数据集
onar.all-data 是 UCI 机器学习仓库中的经典二分类数据集,用于声呐信号处理与目标识别任务,区分声呐回波来自岩石(Rock)还是金属圆柱体(如地雷,Mine)。 原始数据通过主动声呐发射宽带声波,接收目标反射信号并进行数字化处理后得到。共 208 个样本,其中:岩石(R)97 个样本金属圆柱体(M)111 个样本;两类样本数量接近平衡,适合二分类算法测试。
数据集的 60 个特征均为连续型数值范围在 0.0 到 1.0 之间。每个数字代表特定频段内在一定时间内积分的能量。,本质上是声呐信号在不同处理阶段的能量响应值,反映目标对声波的反射特性。每个特征可能对应声呐信号在某个特定频率点的振幅值(通过傅里叶变换得到的频谱分量),部分特征可能对应信号在不同时间窗口的能量分布(短时傅里叶变换的结果),更多数据集信息来自于https://archive.ics.uci.edu/dataset/151,可在里面下载。
二、可视化
1.60个特征的分布情况(直方图和密度图)

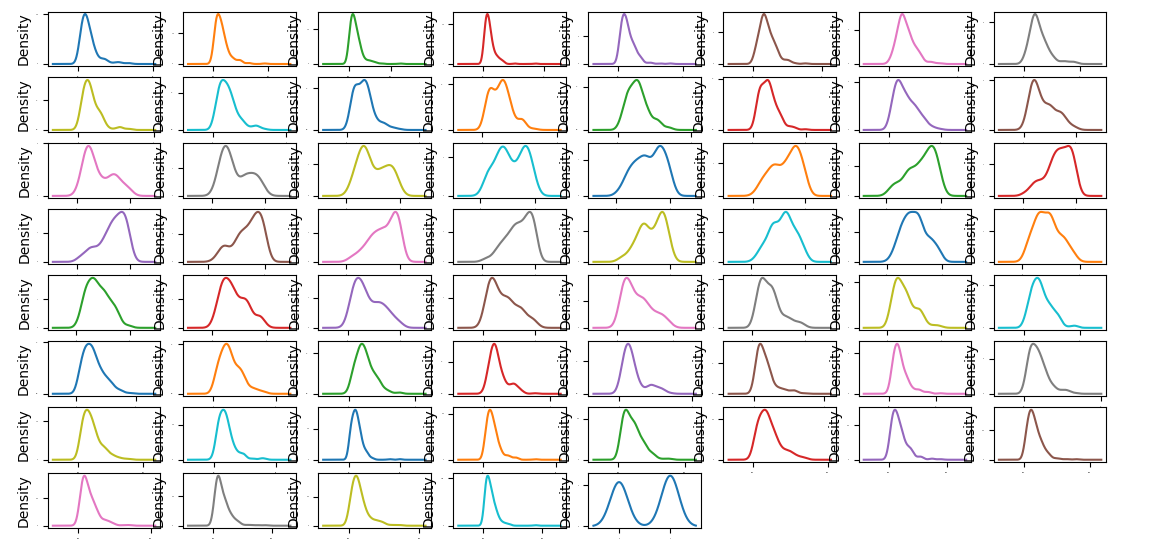
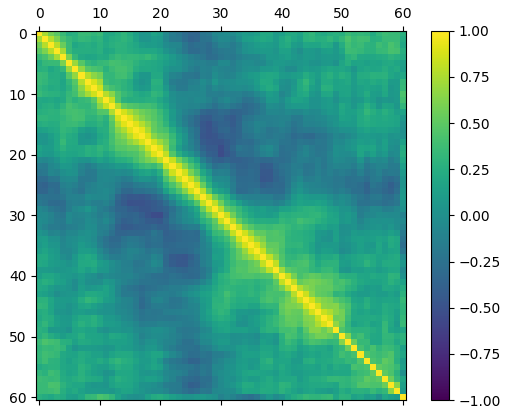
2.特征之间的相关性(矩阵图)
三、算法和评估
逻辑回归、线性判别分析、K近邻、决策树、朴素贝叶斯、支持向量机
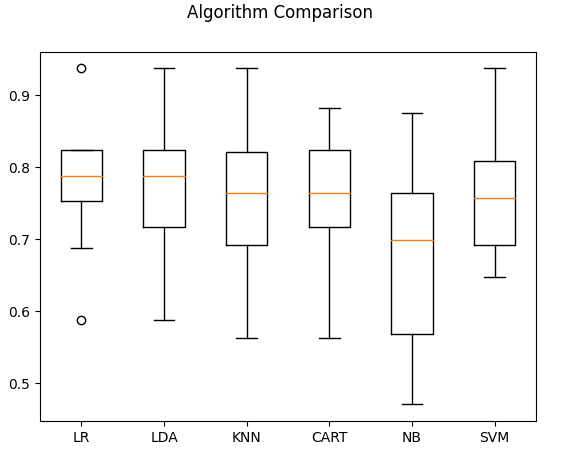
1.10折交叉验证准确率(箱线图)
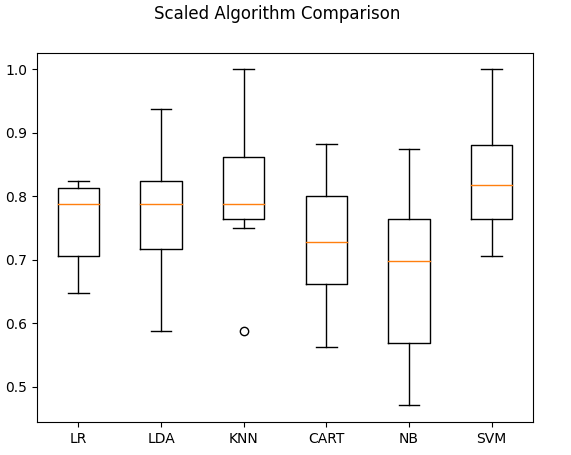
2.数据标准化和10折交叉验证准确率(箱线图)
数据标准化后准确率有提升。
四,改进算法和集合算法
- ** 网格搜索GridSearchCV寻找超参数,从上面挑出最好的:K近邻KNN和支持向量机SVR**
- 集成学习方法:AdaBoost、梯度提升、随机森林、额外树
1.数据标准化、10折交叉验证和网格搜索准确率(结果)
KNN最优:0.8360294117647058 使用{'n_neighbors': 1} SVR最优:0.85 使用{'C': 1.7, 'kernel': 'rbf'}
2.集成算法标准化和10折交叉验证(箱线图)

3.梯度提升、数据标准化、10折交叉验证和网格搜索
额外树ETR-ExtraTreesClassifier()
最优:0.8860294117647058 使用{'n_estimators': 400}
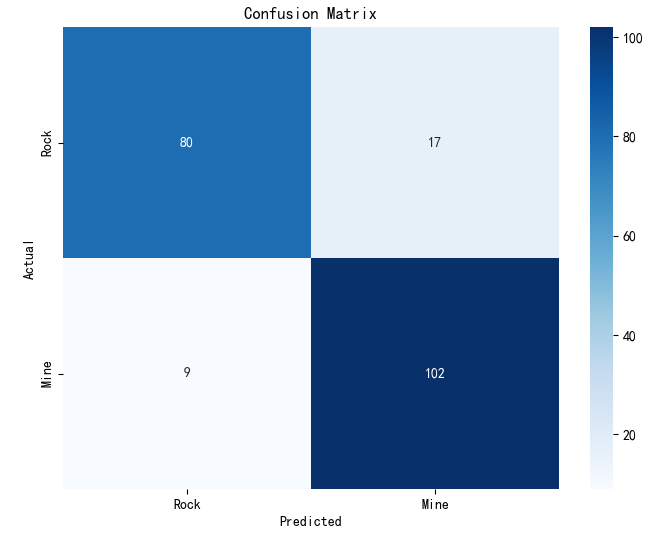
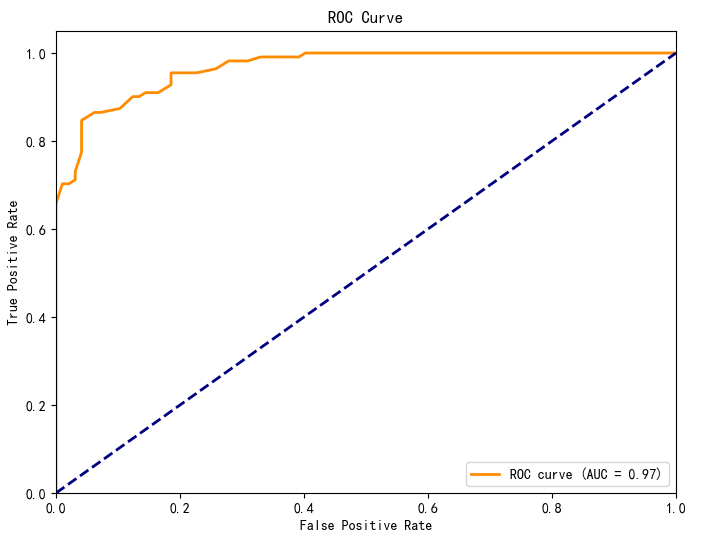
4.最终模型(分类报告)
额外树ETR-ExtraTreesClassifier(),使用10折交叉验证。混淆矩阵、ROC曲线
=== 交叉验证评估 ===
Accuracy: 0.874 (±0.080)
Precision: 0.846 (±0.140)
Recall: 0.910 (±0.101)
F1-score: 0.873 (±0.110)
ROC-AUC: 0.971 (±0.031)
=== 分类报告 ===precision recall f1-score supportRock 0.90 0.82 0.86 97Mine 0.86 0.92 0.89 111accuracy 0.88 208macro avg 0.88 0.87 0.87 208
weighted avg 0.88 0.88 0.87 208
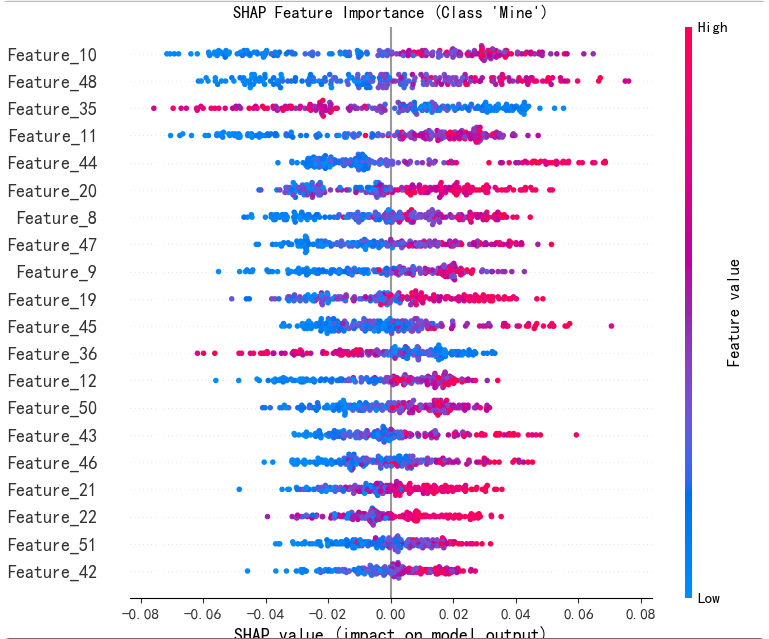
5. 解释模型计算特征重要性(SHAP 值的摘要图)
展示Mine类特征贡献度可视化(‘M’: 1)。
- 解释展现关系
- 单个特征对模型预测的影响方向(正相关/负相关)和影响程度(SHAP值绝对值大小)。
- 特征取值与SHAP值的分布关系(。
- 横轴为SHAP值,纵轴为特征名称,点的颜色表示特征取值(如颜色越深代表特征值越大)。
- 比如:特征x10的SHAP值多为正值,且随特征值增大而增大,表明x10与预测结果呈正相关;特征x2的SHAP值多为负值,表明其与预测结果呈负相关。很多都有正负相关。
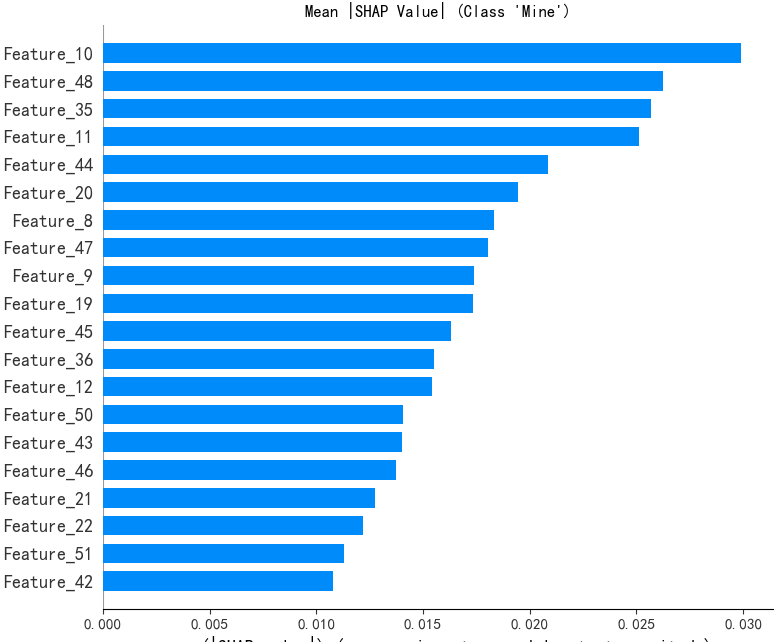
6.特征重要性排序
各特征的平均SHAP值绝对值排名,直观展示特征重要性排序。横轴为平均SHAP值绝对值,纵轴为特征名称,特征按重要性降序排列。特征Feature 10的平均SHAP值最大,对模型预测的贡献度最高。
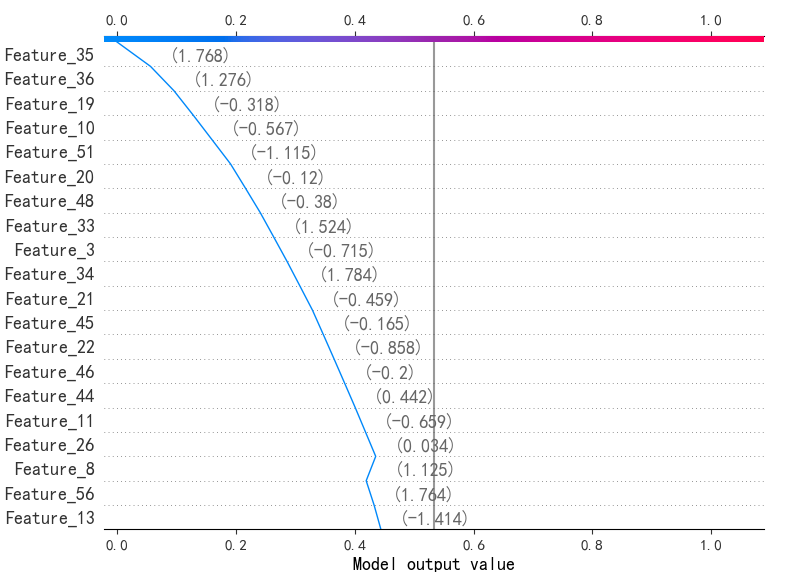
7.单个样本的SHAP决策图(第一个样本)
五、完整代码
# 导入类库
import numpy as np
import pandas as pd
from matplotlib import pyplot
from pandas.plotting import scatter_matrix
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier
import shap# 导入数据
filename = 'sonar.all-data.csv'
dataset = pd.read_csv(filename, header=None)# 将目标变量转换为数值类型
dataset[60] = dataset[60].map({'R': 0, 'M': 1})# 数据维度
print(dataset.shape)# 查看数据类型
print(dataset.dtypes)# 查看最初的20条记录
pd.set_option('display.width', 100)
print(dataset.head(20))# 描述性统计信息
pd.set_option('display.precision', 3)
print(dataset.describe())# 数据的分类分布
print(dataset.groupby(60).size())# 直方图
dataset.hist(sharex=False, sharey=False, xlabelsize=1, ylabelsize=1)
pyplot.show()# 密度图
dataset.plot(kind='density', subplots=True, layout=(8, 8), sharex=False, legend=False, fontsize=1)
pyplot.show()# 关系矩阵图
fig = pyplot.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(dataset.corr(), vmin=-1, vmax=1, interpolation='none')
fig.colorbar(cax)
pyplot.show()# 分离评估数据集
array = dataset.values
X = array[:, 0:60].astype(float)
Y = array[:, 60]
validation_size = 0.2
seed = 7
X_train, X_validation, Y_train, Y_validation = train_test_split(X, Y, test_size=validation_size, random_state=seed)# 评估算法的基准
num_folds = 10
seed = 7
scoring = 'accuracy'# 评估算法 - 原始数据
models = {}
models['LR'] = LogisticRegression()
models['LDA'] = LinearDiscriminantAnalysis()
models['KNN'] = KNeighborsClassifier()
models['CART'] = DecisionTreeClassifier()
models['NB'] = GaussianNB()
models['SVM'] = SVC()
results = []
for key in models:kfold = KFold(n_splits=num_folds, shuffle=True, random_state=seed)cv_results = cross_val_score(models[key], X_train, Y_train, cv=kfold, scoring=scoring)results.append(cv_results)print('%s : %f (%f)' % (key, cv_results.mean(), cv_results.std()))# 评估算法 - 箱线图
fig = pyplot.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
pyplot.boxplot(results)
ax.set_xticklabels(models.keys())
pyplot.show()# 评估算法 - 正态化数据
pipelines = {}
pipelines['ScalerLR'] = Pipeline([('Scaler', StandardScaler()), ('LR', LogisticRegression())])
pipelines['ScalerLDA'] = Pipeline([('Scaler', StandardScaler()), ('LDA', LinearDiscriminantAnalysis())])
pipelines['ScalerKNN'] = Pipeline([('Scaler', StandardScaler()), ('KNN', KNeighborsClassifier())])
pipelines['ScalerCART'] = Pipeline([('Scaler', StandardScaler()), ('CART', DecisionTreeClassifier())])
pipelines['ScalerNB'] = Pipeline([('Scaler', StandardScaler()), ('NB', GaussianNB())])
pipelines['ScalerSVM'] = Pipeline([('Scaler', StandardScaler()), ('SVM', SVC())])
results = []
for key in pipelines:kfold = KFold(n_splits=num_folds, shuffle=True, random_state=seed)cv_results = cross_val_score(pipelines[key], X_train, Y_train, cv=kfold, scoring=scoring)results.append(cv_results)print('%s : %f (%f)' % (key, cv_results.mean(), cv_results.std()))# 评估算法 - 箱线图
fig = pyplot.figure()
fig.suptitle('Scaled Algorithm Comparison')
ax = fig.add_subplot(111)
pyplot.boxplot(results)
ax.set_xticklabels(models.keys())
pyplot.show()# 调参改进算法 - KNN
scaler = StandardScaler().fit(X_train)
rescaledX = scaler.transform(X_train)
param_grid = {'n_neighbors': [1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21]}
model = KNeighborsClassifier()
kfold = KFold(n_splits=num_folds, shuffle=True, random_state=seed)
grid = GridSearchCV(estimator=model, param_grid=param_grid, scoring=scoring, cv=kfold)
grid_result = grid.fit(X=rescaledX, y=Y_train)print('最优:%s 使用%s' % (grid_result.best_score_, grid_result.best_params_))
cv_results = zip(grid_result.cv_results_['mean_test_score'],grid_result.cv_results_['std_test_score'],grid_result.cv_results_['params'])
for mean, std, param in cv_results:print('%f (%f) with %r' % (mean, std, param))# 调参改进算法 - SVM
scaler = StandardScaler().fit(X_train)
rescaledX = scaler.transform(X_train).astype(float)
param_grid = {}
param_grid['C'] = [0.1, 0.3, 0.5, 0.7, 0.9, 1.0, 1.3, 1.5, 1.7, 2.0]
param_grid['kernel'] = ['linear', 'poly', 'rbf', 'sigmoid']
model = SVC()
kfold = KFold(n_splits=num_folds, shuffle=True, random_state=seed)
grid = GridSearchCV(estimator=model, param_grid=param_grid, scoring=scoring, cv=kfold)
grid_result = grid.fit(X=rescaledX, y=Y_train)print('最优:%s 使用%s' % (grid_result.best_score_, grid_result.best_params_))
cv_results = zip(grid_result.cv_results_['mean_test_score'],grid_result.cv_results_['std_test_score'],grid_result.cv_results_['params'])
for mean, std, param in cv_results:print('%f (%f) with %r' % (mean, std, param))# 集成算法
ensembles = {}
ensembles['ScaledAB'] = Pipeline([('Scaler', StandardScaler()), ('AB', AdaBoostClassifier())])
ensembles['ScaledGBM'] = Pipeline([('Scaler', StandardScaler()), ('GBM', GradientBoostingClassifier())])
ensembles['ScaledRF'] = Pipeline([('Scaler', StandardScaler()), ('RFR', RandomForestClassifier())])
ensembles['ScaledET'] = Pipeline([('Scaler', StandardScaler()), ('ETR', ExtraTreesClassifier())])results = []
for key in ensembles:kfold = KFold(n_splits=num_folds, shuffle=True, random_state=seed)cv_result = cross_val_score(ensembles[key], X_train, Y_train, cv=kfold, scoring=scoring)results.append(cv_result)print('%s: %f (%f)' % (key, cv_result.mean(), cv_result.std()))# 集成算法 - 箱线图
fig = pyplot.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
pyplot.boxplot(results)
ax.set_xticklabels(ensembles.keys())
pyplot.show()# 集成算法ETR - 调参
scaler = StandardScaler().fit(X_train)
rescaledX = scaler.transform(X_train)
param_grid = {'n_estimators': [10, 50, 100, 200, 300, 400, 500, 600, 700, 800, 900]}
model = ExtraTreesClassifier()
kfold = KFold(n_splits=num_folds, shuffle=True, random_state=seed)
grid = GridSearchCV(estimator=model, param_grid=param_grid, scoring=scoring, cv=kfold)
grid_result = grid.fit(X=rescaledX, y=Y_train)
print('最优:%s 使用%s' % (grid_result.best_score_, grid_result.best_params_))# 模型最终化
scaler = StandardScaler().fit(X_train)
rescaledX = scaler.transform(X_train)
model = ExtraTreesClassifier()
model.fit(X=rescaledX, y=Y_train)
# 评估模型
rescaled_validationX = scaler.transform(X_validation)
predictions = model.predict(rescaled_validationX)
print(accuracy_score(Y_validation, predictions))
print(confusion_matrix(Y_validation, predictions))
print(classification_report(Y_validation, predictions))