人大地平线新国立单目具身导航新范式!MonoDream:基于全景想象的单目视觉语言导航
- 作者: Shuo Wang1,2^{1,2}1,2, Yongcai Wang1^{1}1, Wanting Li1^{1}1, Yucheng Wang2^{2}2, Maiyue Chen2^{2}2, Kaihui Wang2^{2}2, Zhizhong Su2^{2}2, Xudong Cai1^{1}1, Yeying Jin3^{3}3, Deying Li1^{1}1, Zhaoxin Fan1^{1}1
- 单位:1^{1}1中国人民大学,2^{2}2地平线机器人,3^{3}3新加坡国立大学
- 论文标题:MonoDream: Monocular Vision-Language Navigation with Panoramic Dreaming
- 论文链接:https://arxiv.org/pdf/2508.02549v1
主要贡献
- 提出轻量级的视觉语言导航框架MonoDream,能够使单目智能体学习统一导航表示(UNR),从而在仅使用单目输入的情况下,实现与使用全景RGB-D信息的方法相媲美的导航性能。
- 引入潜在全景想象任务,通过这些任务监督UNR的学习,使模型能够基于单目输入预测当前和未来步骤的全景RGB和深度观察的潜在特征,从而增强智能体对环境的整体空间理解。
- 在单目VLN-CE基准测试(包括R2R-CE和RxR-CE)中实现了SOTA性能,同时使用的模型更小且无需外部训练数据,验证了模型的泛化能力。
研究背景
- 视觉语言导航(VLN)任务要求智能体根据语言指令在三维环境中导航到指定目标。早期成功的方法通常依赖于全景RGB-D图像作为全局感知输入,这些输入能够提供广阔的视野和明确的视觉与几何信息,帮助智能体更好地理解环境并实现高成功率的导航。
- 然而,全景相机和深度传感器存在成本高、功耗大、重量增加以及硬件集成复杂等问题,限制了它们在现实世界部署中的实用性。因此,近期的研究开始关注仅使用单目RGB相机的轻量级设置。
- 尽管单目智能体更容易部署,但其导航性能仍显著落后于使用全景RGB-D输入的系统,主要原因是单目智能体的视野狭窄,难以推断出对导航有益的全局空间和几何线索。
方法
概览
- 研究目标:本文研究单目视觉语言导航(Monocular Vision-Language Navigation, VLN-CE)任务,目标是让智能体在连续的三维环境中,仅依赖自然语言指令和单目RGB图像进行导航。
- 挑战:单目智能体的视野有限,难以捕捉到全局场景信息(如全景RGB-D图像),这限制了其对环境的整体理解,导致导航性能不如使用全景RGB-D输入的方法。
- 核心思路:提出 MonoDream 框架,通过构建 统一导航表示(Unified Navigation Representation, UNR),将导航动作和智能体对全局场景的隐含理解(包括全景视觉、深度信息和未来动态)对齐到一个共享的潜在空间中。此外,引入 潜在全景想象(Latent Panoramic Dreaming, LPD) 任务作为辅助监督,让智能体在训练阶段预测当前和未来步骤的全景RGB-D特征,从而增强其全局感知能力。
- 框架组成:
- 输入:包括自然语言指令 III、当前单目RGB观测 oto_tot 和采样历史观测 OtO_tOt。
- 输出:预测下一步的导航动作 ata_tat。
- 核心模块:基于视觉语言模型(VLM),包括视觉编码器、文本编码器和解码器以及基于LLM的主干网络。通过多任务协同训练(动作预测、LPD任务和指令推理),让智能体在有限的单目输入下,做出更可靠、更具前瞻性的导航决策。
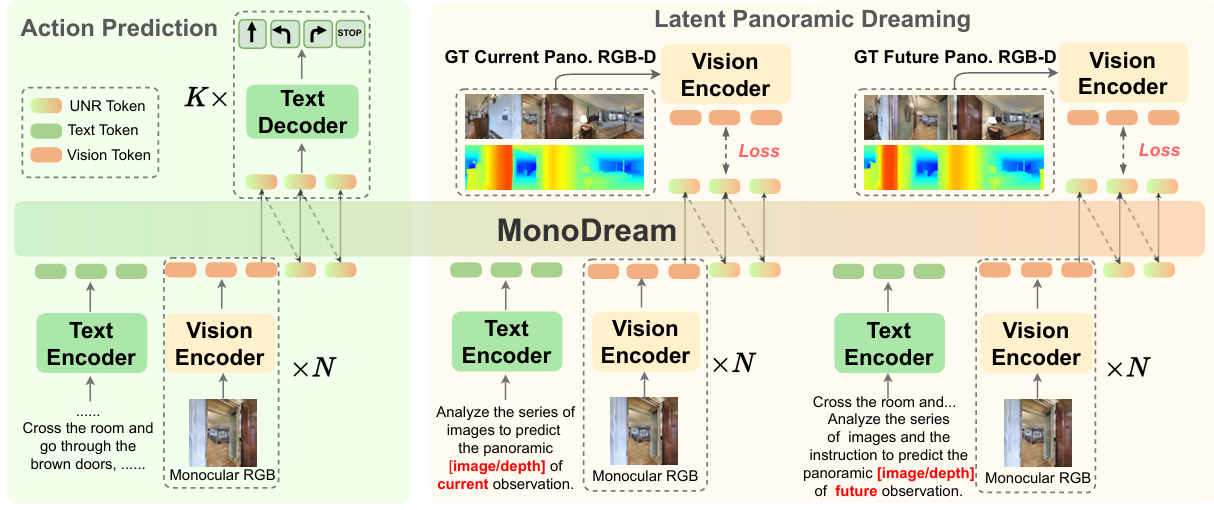
统一导航表示
提出统一导航表示(UNR),将导航相关的信息(包括动作的隐含特征、全景场景布局、全景深度感知和未来动态)对齐到一个紧凑的潜在空间中。UNR可以从视觉和文本输入中解码出导航动作、指令文本或直接作为导航相关特征。
-
文本输入处理:将文本指令 III 分词后通过文本编码器 Φtext(⋅)\Phi_{\text{text}}(\cdot)Φtext(⋅) 处理,生成文本特征 Etext∈RL×dE_{\text{text}} \in \mathbb{R}^{L \times d}Etext∈RL×d,其中 LLL 是文本序列长度,ddd 是隐藏维度。
Etext=Φtext(I) E_{\text{text}} = \Phi_{\text{text}}(I) Etext=Φtext(I) -
视觉输入处理:视觉输入包括当前视图 oto_tot 和采样的历史图像。为了保持计算效率,从完整的过去观测序列中均匀采样 NNN 帧,记为 Ot={op0,…,opN−1}\mathcal{O}_t = \{o_{p_0}, \ldots, o_{p_{N-1}}\}Ot={op0,…,opN−1}。每张图像通过视觉编码器 Φvis(⋅)\Phi_{\text{vis}}(\cdot)Φvis(⋅) 独立处理,生成 ddd 维特征,这些特征组合形成视觉输入序列 EvisE_{\text{vis}}Evis。
Evis={Φvis(op0),…,Φvis(opN−1),Φvis(ot)} E_{\text{vis}} = \{\Phi_{\text{vis}}(o_{p_0}), \ldots, \Phi_{\text{vis}}(o_{p_{N-1}}), \Phi_{\text{vis}}(o_t)\} Evis={Φvis(op0),…,Φvis(opN−1),Φvis(ot)} -
联合输入序列:将文本特征 EtextE_{\text{text}}Etext 和视觉特征 EvisE_{\text{vis}}Evis 组合为单个输入序列 StS_tSt,输入到基于LLM的MonoDream主干网络中。
St=[Etext,Evis] S_t = [E_{\text{text}}, E_{\text{vis}}] St=[Etext,Evis] -
输出UNR:主干网络输出隐藏状态 ht∈Rlseq×dh_t \in \mathbb{R}^{l_{\text{seq}} \times d}ht∈Rlseq×d,其中 lseql_{\text{seq}}lseq 是输出序列的长度。这个表示封装了智能体在步骤 ttt 的全面状态。
ht=MonoDream-Backbone(St) h_t = \text{MonoDream-Backbone}(S_t) ht=MonoDream-Backbone(St)
潜在全景想象
通过辅助任务监督UNR的学习,使智能体能够从有限的单目观测中内化全局场景、深度几何和未来信息。包括两个目标:(1)监督智能体将UNR hth_tht 与当前全景RGB和深度的潜在特征对齐,鼓励智能体捕捉超出单目观测范围的完整空间理解;(2)引导智能体预测下一步的全景RGB和深度的潜在特征,鼓励UNR hth_tht 纳入短期时间动态,提升智能体的提前规划能力。
-
潜在特征获取:通过与单目输入图像编码器共享权重的视觉编码器 Φvis\Phi_{\text{vis}}Φvis 对全景RGB和深度进行编码,确保监督特征和学习的UNR hth_tht 在同一特征空间中对齐并受益于联合训练。
-
训练目标:最小化UNR hth_tht 与上述潜在目标之间的均方误差(MSE)。
LFeat(θ)=∑m∈M∥ht−Hmt∥2+∑m∈M∥ht−Hmt+1∥2 L_{\text{Fea}}^t(\theta) = \sum_{m \in M} \|h_t - H_m^t\|^2 + \sum_{m \in M} \|h_t - H_m^{t+1}\|^2 LFeat(θ)=m∈M∑∥ht−Hmt∥2+m∈M∑∥ht−Hmt+1∥2
多任务协同训练
-
动作预测:在每个时间步 ttt,模型基于UNR hth_tht 预测接下来的三个导航动作 at,at+1,at+2a_t, a_{t+1}, a_{t+2}at,at+1,at+2,以鼓励短期动作预测并保持对新观测的反应性。
LActt(θ)=−∑k=0Klogπθ(at∗+k∣ht) L_{\text{Act}}^t(\theta) = -\sum_{k=0}^{K} \log \pi_\theta(a^*_t+k | h_t) LActt(θ)=−k=0∑Klogπθ(at∗+k∣ht)
其中 at∗+ka^*_t+kat∗+k 是步骤 t+kt+kt+k 的真实动作。 -
指令推理:通过从视觉轨迹上下文中推断出底层语言指令 III,增强智能体对指令的理解,促进从视觉到语言的多模态对齐。
LInst(θ)=−logπθ(Iτ∣hT) L_{\text{Ins}}^t(\theta) = -\log \pi_\theta(I_\tau | h_T) LInst(θ)=−logπθ(Iτ∣hT) -
最终损失函数:将动作预测、特征损失和指令推理损失结合起来进行优化。
L=∑τ∈D(∑t=1Tτ(LActt(θ)+λLFeat(θ))+LInst(θ)) L = \sum_{\tau \in D} \left( \sum_{t=1}^{T_\tau} (L_{\text{Act}}^t(\theta) + \lambda L_{\text{Fea}}^t(\theta)) + L_{\text{Ins}}^t(\theta) \right) L=τ∈D∑(t=1∑Tτ(LActt(θ)+λLFeat(θ))+LInst(θ))
其中 DDD 是训练轨迹集合,TτT_\tauTτ 是轨迹 τ\tauτ 的步数,λ\lambdaλ 是权重超参数。
实现细节
动作设计
- 动作空间:设计为四个类别:向前移动、向左转、向右转和停止。向前移动包括25cm、50cm和75cm的步长,转向动作由15°、30°和45°的旋转角度参数化。这种细粒度设计在复杂环境中至关重要。
训练数据集
-
数据来源:所有训练数据均来自模拟环境,包括R2R-CE和RxR-CE的训练分割,以及通过DAgger策略额外收集的数据。
-
数据构建:
- 基于R2R-CE和RxR-CE提供的动作注释构建逐步导航数据,分别得到320K和600K样本。
- 基于R2R-CE构建辅助监督数据,应用图像预处理和指令推理任务。
- 按照DAgger策略,从R2R-CE训练环境中生成的非Oracle轨迹中额外收集500K逐步样本。
-
全景图像处理:对于LPD任务中的训练全景图像,采用立方体贴图格式,将360度视图分解为四个90度视图(左、前、右、后)。对于深度图像,先对原始深度值进行对数缩放以压缩大尺度变化,然后通过基于colormap的RGB渲染。
Depthprocessed=colormap(log(Depthraw)) \text{Depth}_{\text{processed}} = \text{colormap}(\log(\text{Depth}_{\text{raw}})) Depthprocessed=colormap(log(Depthraw))
模型训练
- 基础模型:采用NVILA-lite-2B作为基础模型,包括SigLIP视觉编码器、投影模块和基于Qwen2的语言模型。
- 训练策略:从NVILA-lite-2B的预训练权重开始,进行监督微调(SFT)。所有模型组件在微调过程中均可训练。
- 训练参数:在8块NVIDIA H20 GPU上训练5个epoch,学习率为1e-5,预热比例为0.03,批量大小为80。在训练和推理过程中,预测未来动作的数量 KKK 设置为3,采样历史帧的数量 NNN 设置为8。
实验
实验设置
- 数据集:使用R2R-CE和RxR-CE基准测试中的模拟环境进行评估,这些环境提供了连续环境中导航动作的真实感室内场景。

- 评估指标:遵循标准的VLN评估协议,包括成功率(SR)、 oracle成功率(OSR)、按路径长度加权的成功率(SPL)以及从目标的导航误差(NE)。
结果
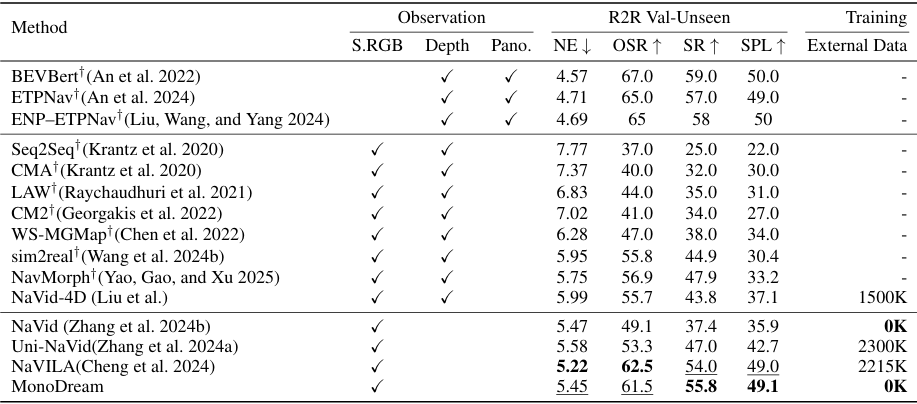
- R2R-CE基准测试:MonoDream在不依赖任何外部数据的情况下取得了55.8%的SR和49.1%的SPL,优于其他仅使用单目RGB输入的方法。
- RxR-CE基准测试:MonoDream在更复杂的RxR-CE环境中也取得了25.1%的SR和21.6%的SPL的最好性能,证明了其在长轨迹和多样化语言指令任务中的优势。
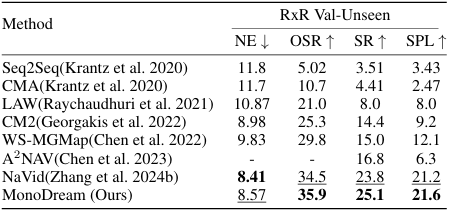
- 跨数据集评估:在未使用RxR-CE训练数据的情况下,MonoDream在RxR-CE的跨数据集评估中取得了最佳性能,展示了其强大的泛化能力。
消融研究
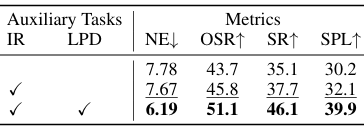
- 辅助任务的影响:引入LPD和指令推理(IR)任务可以显著提升模型性能,其中LPD对性能的提升最为显著,表明其在增强智能体全局空间理解方面的重要性。
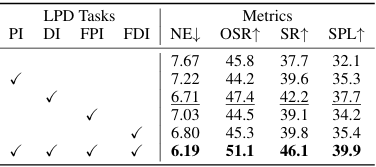
- LPD任务的分解:对LPD任务中的四个子任务(当前全景RGB图像、当前全景深度图像、未来全景RGB图像和未来全景深度图像)分别进行评估,结果表明每个子任务都能带来一致的性能提升,尤其是当前全景和深度图像对性能的提升最为关键。
模型效率
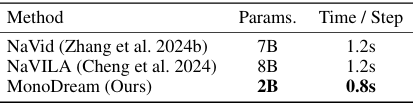
MonoDream在模型大小和推理速度方面都优于其他最新的VLN方法,其模型参数仅为2B,单步推理时间为0.8秒,这使得MonoDream成为实时具身导航应用的实用解决方案。
结论与未来工作
- 结论:
- MonoDream通过引入统一导航表示和潜在全景想象任务,成功地使单目智能体在仅使用单目输入的情况下实现了与使用全景RGB-D信息的方法相媲美的导航性能。
- 该方法在多个基准测试中取得了SOTA性能,同时具有高效的模型大小和推理速度,证明了其在实际应用中的潜力。
- 未来工作:
- 尽管MonoDream在单目VLN任务中取得了显著的进展,但其在想象当前场景和即时未来方面仍存在局限性,例如没有显式重建全景历史或预测长期未来。
- 未来的研究可以考虑引入更丰富的时序建模,如多步想象或基于记忆的推理,以进一步提高规划能力和鲁棒性。
