Kafka服务端NIO操作原理解析(二)
Kafka系列文章
基于Kafka2.1解读Producer原理
基于Kafka2.1解读Consumer原理
Kafka服务端NIO操作原理解析(一)
文章目录
- Kafka系列文章
- 前言
- 一、基本认知
- 二、Acceptor的主体流程
- 2.1 run方法源码
- 2.2 acceptNewConnections方法源码
- 2.3 主体逻辑流程示意图
- 三、Processor的主体流程
- 3.1 run方法源码
- 3.2 主体逻辑流程示意图
- 3.2.1 configureNewConnections
- 3.2.2 processNewResponses
- 3.2.3 poll
- pollSelectionKeys
- 3.2.4 processCompletedReceives
- 3.2.5 processCompletedSends
- 四、问题
- 总结
前言
废话不多说,继续上一篇文章,我们继续基于Kafka3.7解读服务端的nio原理
一、基本认知
可以看到Acceptor和Processor都是线程,所以实际Kafka服务端在启动(执行startup)方法之后,会基于一个Acceptor多个Processor的模式启动,并把这多个线程执行起来。
二、Acceptor的主体流程
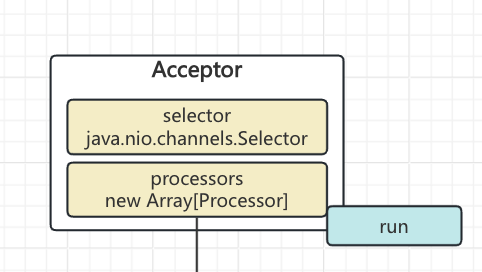
对于Acceptor来说,主要就是通过selector监听accept事件,然后选择一个processor来进行后续操作
2.1 run方法源码
/*** Accept loop that checks for new connection attempts*/override def run(): Unit = {serverChannel.register(nioSelector, SelectionKey.OP_ACCEPT)try {while (shouldRun.get()) {try {acceptNewConnections()closeThrottledConnections()}catch {// We catch all the throwables to prevent the acceptor thread from exiting on exceptions due// to a select operation on a specific channel or a bad request. We don't want// the broker to stop responding to requests from other clients in these scenarios.case e: ControlThrowable => throw ecase e: Throwable => error("Error occurred", e)}}} finally {debug("Closing server socket, selector, and any throttled sockets.")CoreUtils.swallow(serverChannel.close(), this, Level.ERROR)CoreUtils.swallow(nioSelector.close(), this, Level.ERROR)throttledSockets.foreach(throttledSocket => closeSocket(throttledSocket.socket, this))throttledSockets.clear()}}
可以看到主要流程在acceptNewConnections中,下面我们看看acceptNewConnections代码
2.2 acceptNewConnections方法源码
/*** Listen for new connections and assign accepted connections to processors using round-robin.*/private def acceptNewConnections(): Unit = {val ready = nioSelector.select(500)if (ready > 0) {val keys = nioSelector.selectedKeys()val iter = keys.iterator()while (iter.hasNext && shouldRun.get()) {try {val key = iter.nextiter.remove()if (key.isAcceptable) {accept(key).foreach { socketChannel =>// Assign the channel to the next processor (using round-robin) to which the// channel can be added without blocking. If newConnections queue is full on// all processors, block until the last one is able to accept a connection.var retriesLeft = synchronized(processors.length)var processor: Processor = nulldo {retriesLeft -= 1processor = synchronized {// adjust the index (if necessary) and retrieve the processor atomically for// correct behaviour in case the number of processors is reduced dynamicallycurrentProcessorIndex = currentProcessorIndex % processors.lengthprocessors(currentProcessorIndex)}currentProcessorIndex += 1} while (!assignNewConnection(socketChannel, processor, retriesLeft == 0))}} elsethrow new IllegalStateException("Unrecognized key state for acceptor thread.")} catch {case e: Throwable => error("Error while accepting connection", e)}}}}
2.3 主体逻辑流程示意图
注意看到Processor的accept操作做了两件事
1. 将socketChannel放到了自身的newConnections里
2. wakeup一下自身的selector
备注:newConnections是线程安全的ArrayBlockingQueue
三、Processor的主体流程
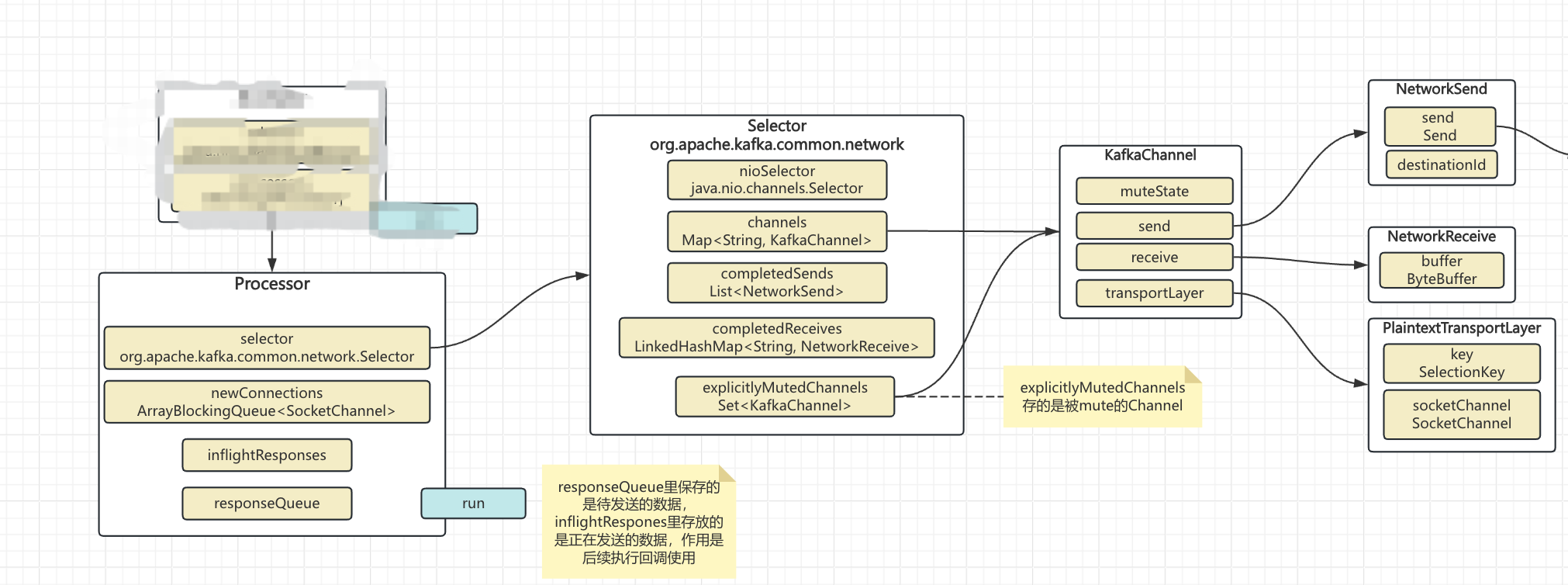
每个Processor是会处理多个socketChannel的:
channels变量维护多个KafkaChannel
explicitlyMutedChannels:维护的是被mute掉的channels
completedReceives:维护单次poll操作从每个channel读取到的数据
completedSends:维护的是单次poll操作已经通过nio写出去的数据
explicitly:强调 “主动、明确地”,即用户通过手动操作(而非系统默认或其他自动设置)进行的行为
注意:completedReceives和completedSends单次执行poll操作的数据
3.1 run方法源码
override def run(): Unit = {try {while (shouldRun.get()) {try {// setup any new connections that have been queued upconfigureNewConnections()// register any new responses for writingprocessNewResponses()poll()processCompletedReceives()processCompletedSends()processDisconnected()closeExcessConnections()} catch {// We catch all the throwables here to prevent the processor thread from exiting. We do this because// letting a processor exit might cause a bigger impact on the broker. This behavior might need to be// reviewed if we see an exception that needs the entire broker to stop. Usually the exceptions thrown would// be either associated with a specific socket channel or a bad request. These exceptions are caught and// processed by the individual methods above which close the failing channel and continue processing other// channels. So this catch block should only ever see ControlThrowables.case e: Throwable => processException("Processor got uncaught exception.", e)}}} finally {debug(s"Closing selector - processor $id")CoreUtils.swallow(closeAll(), this, Level.ERROR)}}
3.2 主体逻辑流程示意图
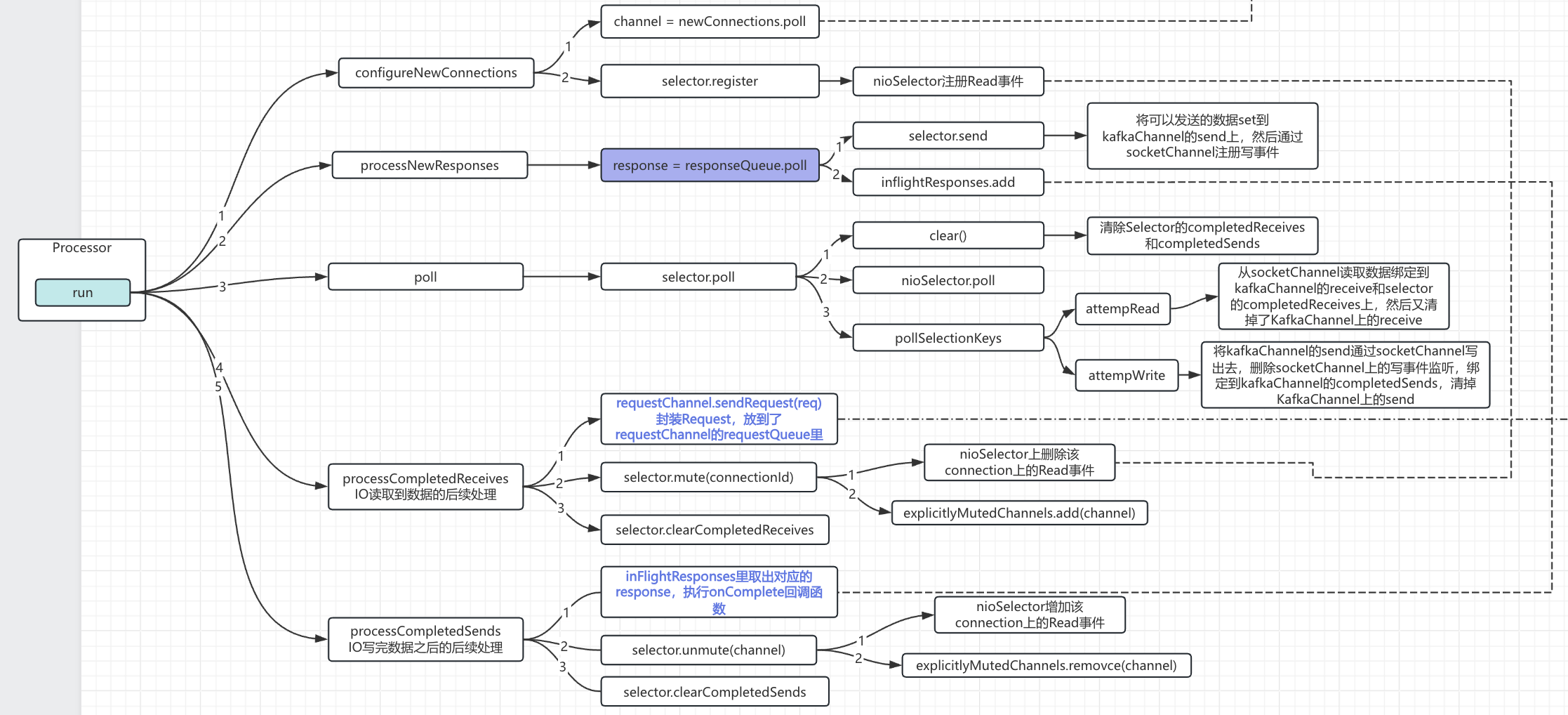
可以看到我这个主体流程示意图并没有把processDisconnected()和closeExcessConnections()方法放进来,因为这两个方法对于我们理解Kafka的nio不太重要,所以暂时忽略
3.2.1 configureNewConnections
1. 从自身的newConnections里获取socketChannel
2. 将socketChannel封装成KafkaChannel,并在selector上注册读事件
3.2.2 processNewResponses
一句话总结:将需要发送出去的数据拷贝到KafkaChannel上,也就是做真正发送的准备操作
1. 从自身responseQueue里poll一个可发送的response
2. 将response拷贝到对应KafkaChannel的send对象上
3. 在selector上注册写事件
4. 同时将response放到inflightRespones里:为后续执行回调函数使用
当然,responseQueue也是线程安全的,不过是LinkedBlockingDeque
3.2.3 poll
这个方法是服务端真正执行IO操作的逻辑,包括读和写
1. 清掉completedReceives和completedSends
2. 执行poll操作
3. 处理poll到的selectionKeys
pollSelectionKeys
attemptRead
1. 从socketChannel读取数据
2. 将读取到的数据存到selector的completedReceives里
3. 把当前KafkaChannel里的receive给清掉
attemptWrite
注意:此处KafkaChannel上的send数据来自于「3.2.2 processNewResponses」
4. 将KafkaChannel上send数据通过KafkaChannel写出去
5. 将该数据append到selector的completedSends上
6. 把当前KafkaChannel里的send给清掉
3.2.4 processCompletedReceives
一言以蔽之:对上一步「3.2.3 poll」读取到的数据进行处理
1. 将读取到数据封装成Request放到requestChannel的requestQueue里
2. 将该数据的Channel给禁言:mute
3. 清掉整个selector的completedReceives
mute操作主要两件事:①删除掉该channel在selector上注册的读事件②将该channel放到explicitlyMutedChannels里
3.2.5 processCompletedSends
一言以蔽之:对「3.2.3 poll」操作里发出去的response执行回调
1. 从inflightRespones里读取response,执行该response的回调方法
2. 如果该channel被禁言了,解除禁言
3. 清掉整个selector的completedSends
解除禁言操作主要两件事:①该channel在selector上注册读事件②将该channel从explicitlyMutedChannels里remove掉
四、问题
看完processor的主要操作,咱们就冒出两个问题:
- processor的responseQueue里的数据是谁写入的?
- 我们写到requestChannel#requestQueue里的数据谁去处理了?
这两个问题就是Kafka server的核心计算逻辑了,而本文着重讲了Kafka server的核心IO逻辑
总结
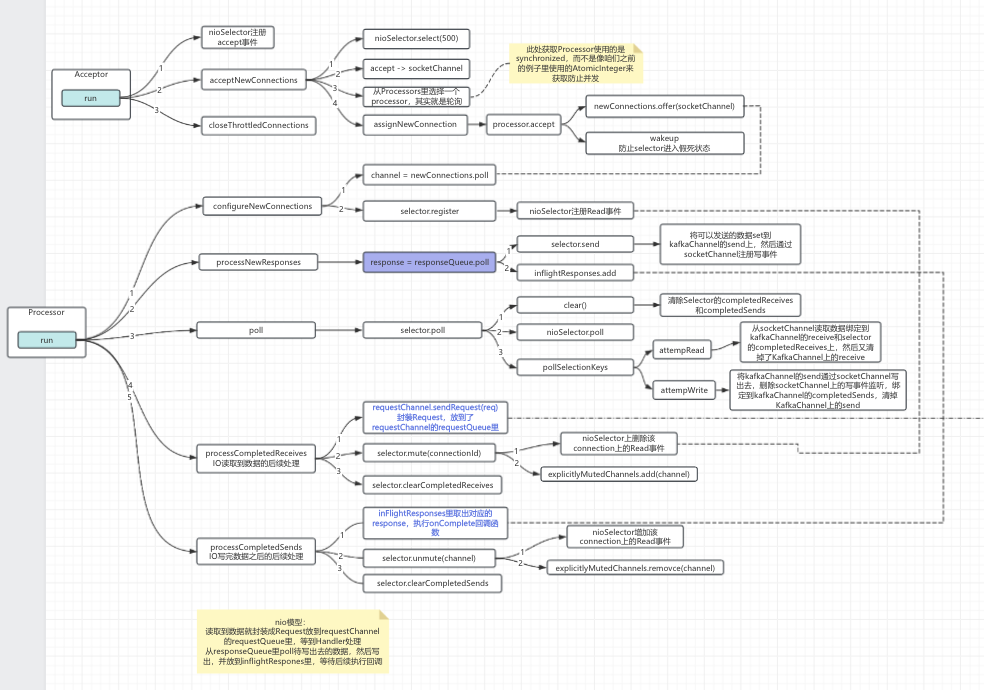
在上一篇简单概括加原生nio的引导之后,本文详细介绍了Kafka server端Acceptor和Processor是如何工作来处理读入和写出的逻辑。
后续咱们就要基于咱们的问题来介绍Kafka server的计算逻辑了:读进来的数据怎么处理,写出去的response是怎么来的~