2025-08-09 李沐深度学习14——经典卷积神经网络 (2)
文章目录
- 1 NiN (2013)
- 1.1 动机:解决全连接层的“三大罪状”
- 1.2 两大核心创新
- 1.2.1 NiN 块 (NiN Block)
- 1.2.2 全局平均池化 (Global Average Pooling, GAP)
- 1.3 NiN 整体架构
- 1.4 代码实现
- 2 GoogLeNet (2014)
- 2.1 Inception 模块
- 2.1.1 Inception 模块的结构
- 2.1.2 1×1 卷积作用
- 2.2 GoogLeNet 整体架构
- 2.3 演进:V1、V2、V3、V4
- 2.4 优缺点
- 2.5 代码实现
- 3 ResNet (2015)
- 3.1 批量归一化
- 3.1.1 工作原理
- 3.1.2 应用位置
- 3.1.3 理论争论
- 3.2 为什么需要 ResNet
- 3.3 核心思想:残差连接
- 3.4 ResNet 结构
- 3.5 ResNet 的主要版本
- 3.6 梯度计算
- 3.6.1 普通的深度网络
- 3.6.2 带有残差连接的 ResNet
- 3.6.3 小结
- 3.7 代码实现
1 NiN (2013)
1.1 动机:解决全连接层的“三大罪状”
在 AlexNet 和 VGG 等早期成功的模型中,一个巨大的痛点来自于网络末端的全连接层 (Fully Connected Layers)。NiN 的设计初衷就是为了解决这些全连接层带来的严重问题。
问题一:惊人的参数数量
全连接层的参数量与输入和输出的维度直接相关,在卷积网络末端,这会导致参数量的爆炸。
-
LeNet: 最后一个卷积层到第一个全连接层约
4.8万参数 (16×5×5×120)。 -
AlexNet: 激增至约
2600万参数 (256×5×5×4096)。 -
VGG: 更是达到了恐怖的 1亿 级别参数 (512×7×7×4096)。
网络的绝大部分参数都集中在这一两层中。
问题二:巨大的资源开销
- 内存占用: 巨大的参数量意味着巨大的内存消耗。VGG 模型的大小可达约 700MB,其中大部分被全连接层占据。
- 计算/带宽瓶颈: 大规模的矩阵乘法运算不仅消耗计算资源,更受限于内存带宽,即CPU/GPU需要花费大量时间来回读取权重参数。
问题三:严重的过拟合风险
-
单单一层就拥有上亿个参数,模型极易在训练集上发生过拟合,完全“背下”训练数据,导致其在未见过的数据上表现很差。这需要研究者使用大量的正则化技巧来对抗。
NiN 的激进思想:既然全连接层有这么多问题,那我们干脆完全不要全连接层。

1.2 两大核心创新
为了取代全连接层,NiN 提出了两个非常重要的概念,这两个概念深刻影响了后来的网络设计。
1.2.1 NiN 块 (NiN Block)
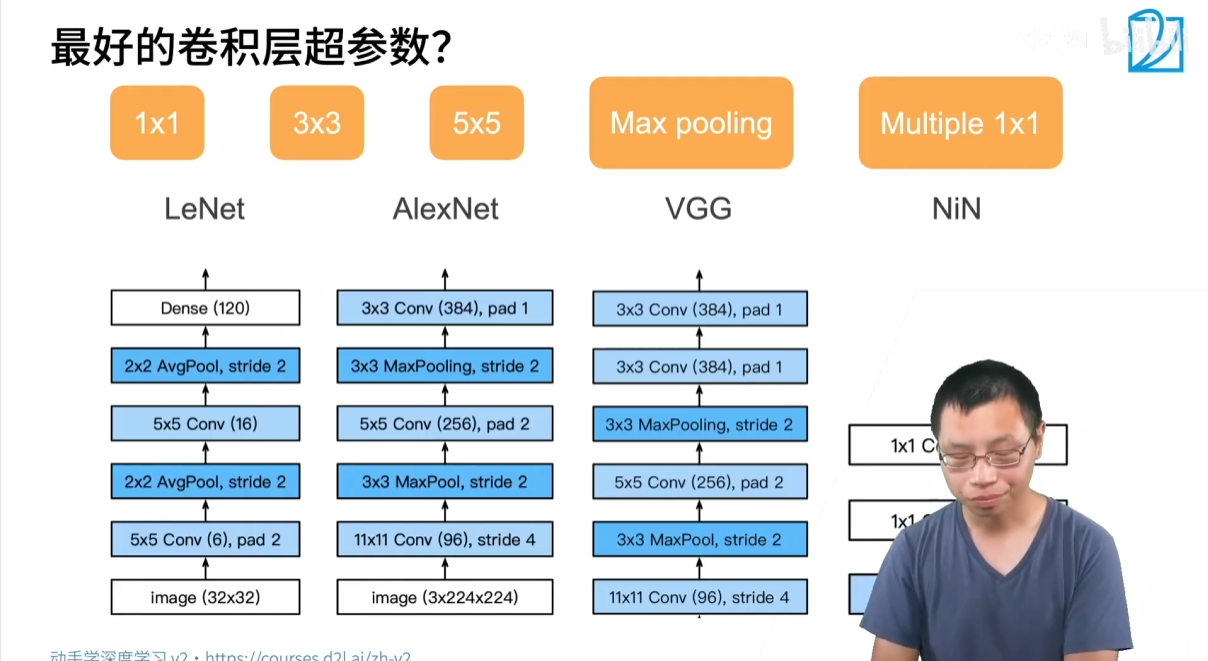
NiN 同样采用了模块化的设计思想,其核心组件是 NiN 块。它并非简单地堆叠卷积层,而是在一个常规卷积层后,增加了两个特殊的 1×1 卷积层。
- 结构: 一个常规卷积层 + 两个 1×1 卷积层。
- 1×1 卷积层的作用:
- 一个 1×1 卷积,在不改变特征图高宽的情况下,等价于一个作用于每个像素上的全连接层。它对每个像素点上的所有通道(channels)进行一次线性的融合计算。
- 在 NiN 块中,连续使用两个带有激活函数的 1×1 卷积层,就相当于为每个像素位置都引入了一个小型的、非线性的多层感知机 (MLP)。
- 核心目的: 极大地增强了模型在像素级别上的非线性表达能力,让网络能学习到通道间更复杂的关系,这被称为“网络中的网络 (Network in Network)”。

1.2.2 全局平均池化 (Global Average Pooling, GAP)
为了替换掉网络末端用于分类的庞大全连接层,NiN 引入了全局平均池化层。
- 工作原理:
- 在网络的最后一层,将输出的通道数设置为与最终的类别数相等(例如,ImageNet 分类任务中设为 1000)。
- 全局平均池化层的池化窗口大小与整个特征图的高宽完全相同。
- 它将**每一个通道(Feature Map)**的所有像素值求平均,从而将一个
高 x 宽 x 通道数的三维张量,直接压缩成一个1 x 1 x 通道数的向量。 - 这个长度为类别数的向量,可以直接送入 Softmax 层进行分类。
- 优势:
- 无参数: 全局平均池化层没有任何需要学习的参数,极大地减少了模型的总参数量。
- 强效正则化: 由于没有海量参数,它天然地具有防止过拟合的能力。

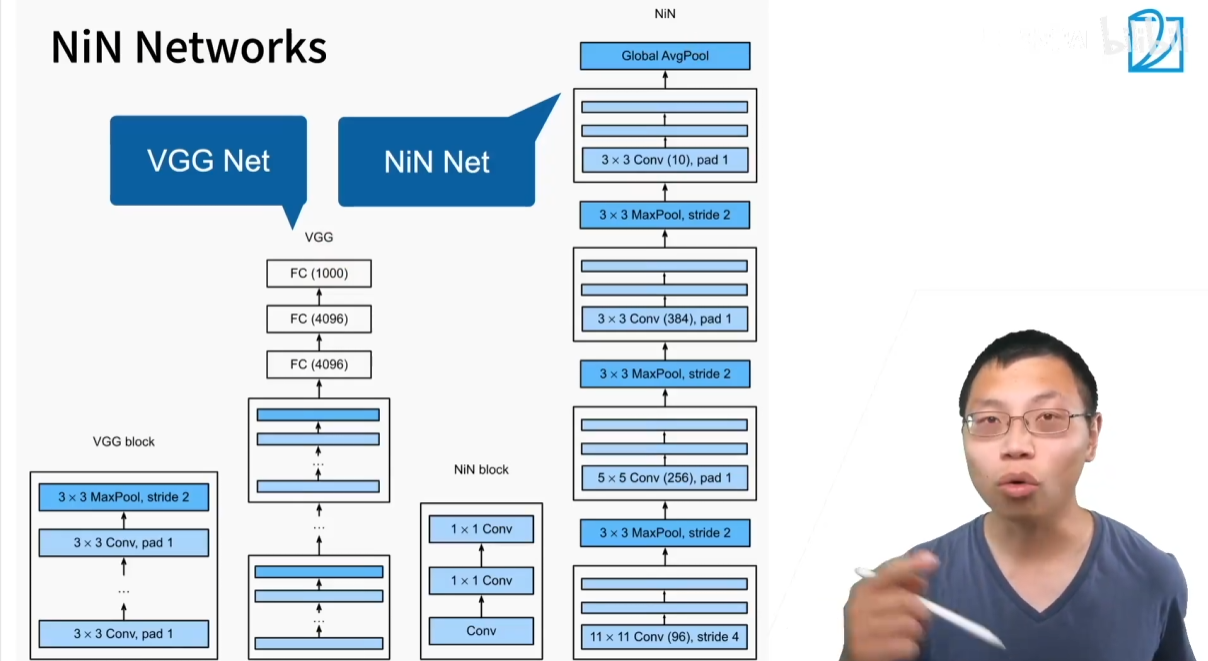
1.3 NiN 整体架构
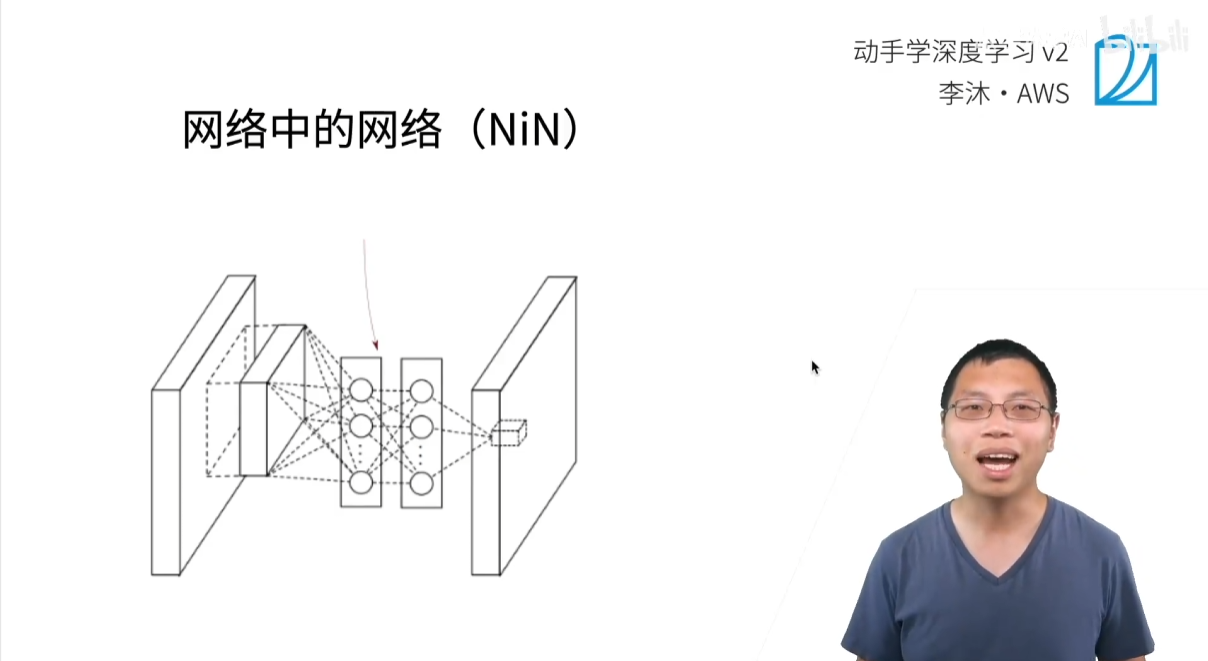
NiN 的整体架构比 VGG 更为简洁和极端。
- VGG 架构:
(VGG 块 + 池化) x N->庞大全连接层->庞大全连接层->输出 - NiN 架构:
(NiN 块 + 最大池化) x N->最终 NiN 块 (通道=类别数)->全局平均池化->输出
通过交替使用 NiN 块和步幅为2的最大池化层来构建网络的主体,逐步减小特征图的空间尺寸,同时增加其通道深度。最终,用一个轻量级的全局平均池化层优雅地完成了从特征提取到分类的转换。
尽管 NiN 模型本身现在已较少被直接使用,但它提出的思想是革命性的,并被后续的许多主流网络(如 GoogLeNet, ResNet)所吸收和发扬。
1.4 代码实现
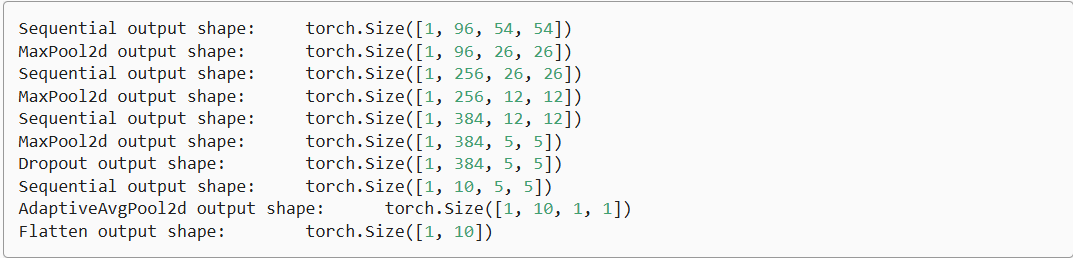
import torch
from torch import nndef nin_block(in_channels, out_channels, kernel_size, strides, padding):return nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),nn.ReLU(),nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(),nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())net = nn.Sequential(nin_block(1, 96, kernel_size=11, strides=4, padding=0),nn.MaxPool2d(3, stride=2),nin_block(96, 256, kernel_size=5, strides=1, padding=2),nn.MaxPool2d(3, stride=2),nin_block(256, 384, kernel_size=3, strides=1, padding=1),nn.MaxPool2d(3, stride=2),nn.Dropout(0.5),# 标签类别数是10nin_block(384, 10, kernel_size=3, strides=1, padding=1),nn.AdaptiveAvgPool2d((1, 1)),# 将四维的输出转成二维的输出,其形状为(批量大小,10)nn.Flatten())X = torch.rand(size=(1, 1, 224, 224))
for layer in net:X = layer(X)print(layer.__class__.__name__,'output shape:\t', X.shape)
2 GoogLeNet (2014)
GoogLeNet 是一个在卷积神经网络发展史上具有里程碑意义的网络。尽管它的前身 NIN(Network In Network)如今很少被单独使用,但 GoogLeNet 的核心思想——Inception 模块——对后续网络设计产生了深远影响,至今仍在被广泛使用。
GoogLeNet 的一大创举是首次实现了深度接近 100 层的卷积神经网络。虽然它不是简单地堆叠 100 层,但其内部的卷积层总数确实超过了 100,通过并行而非串行的方式增加了网络深度。
该网络的名字 GoogLeNet 中的 “Le” 大写,是为了致敬经典的 LeNet 网络。
2.1 Inception 模块
在设计卷积神经网络时,我们总是面临多种选择:应该使用 1×1、3×3、5×5 还是 7×7 的卷积核?应该用 Max Pooling 还是 Average Pooling?Inception 模块的核心思想是:“我全都要!”
Inception 模块将所有这些可能的优秀操作并行地放在一个“块”中,让网络自己去学习和选择哪种操作最有效。
2.1.1 Inception 模块的结构
一个 Inception 模块有四条并行的路径:
- 第一条路径:直接通过一个 1×1 的卷积层。
- 第二条路径:先通过一个 1×1 的卷积层改变通道数,再接一个 3×3 的卷积层。
- 第三条路径:先通过一个 1×1 的卷积层改变通道数,再接一个 5×5 的卷积层。
- 第四条路径:先通过一个 3×3 的 Max Pooling 层,再接一个 1×1 的卷积层。
所有这四条路径的输出在保持 高宽不变 的前提下,在 通道维度上进行拼接(concatenate),形成模块的最终输出。
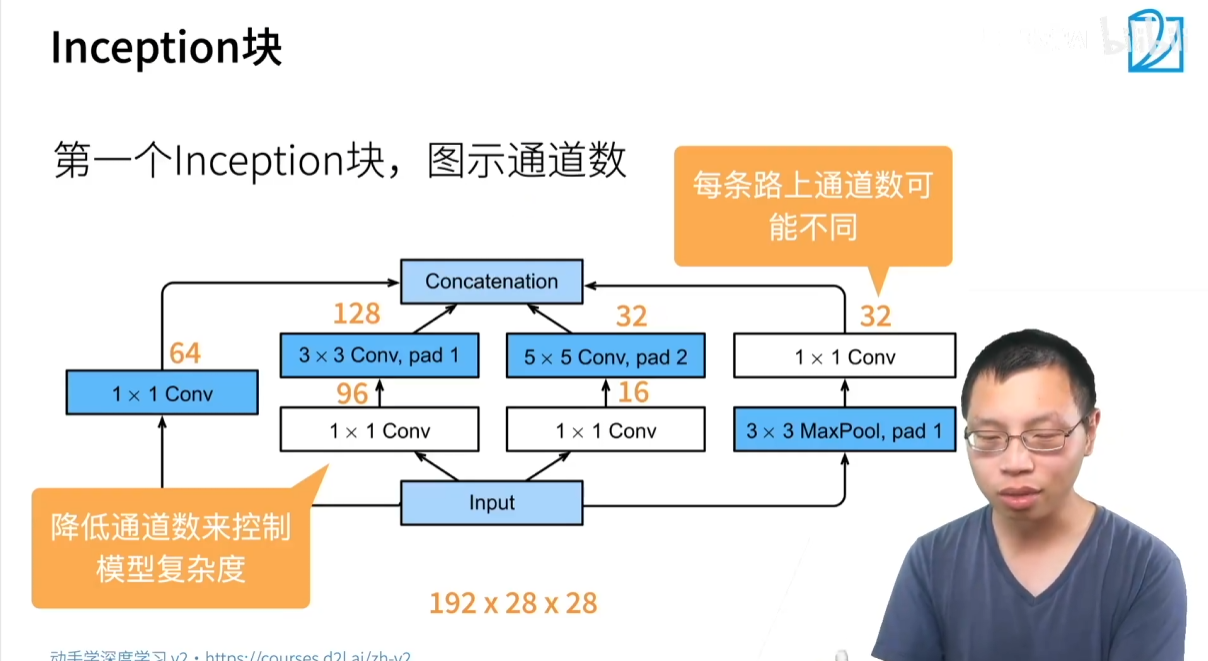
2.1.2 1×1 卷积作用
在 Inception 模块中,1×1 卷积层扮演了至关重要的角色,它主要用于:
- 降低通道数:在 3×3 和 5×5 卷积之前,通过 1×1 卷积来压缩通道数,从而显著 降低模型的参数量和计算复杂度。
- 融合通道信息:通过对通道维度的加权求和,实现不同通道特征的融合。
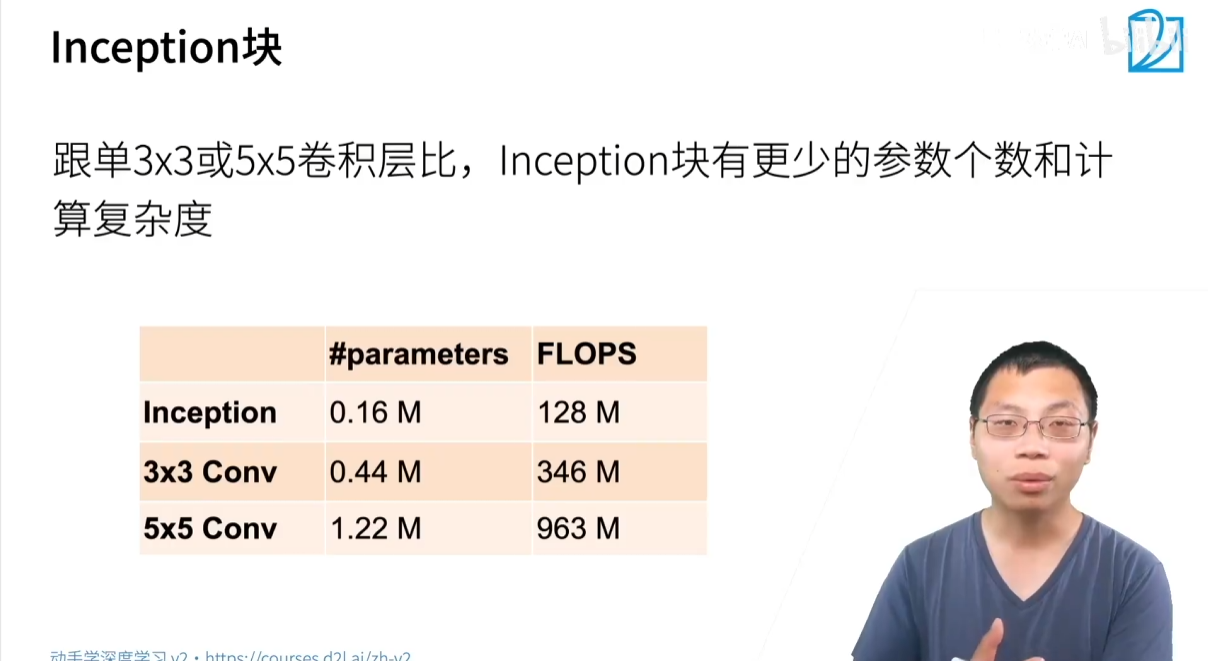
与直接使用一个 3×3 或 5×5 卷积相比,Inception 模块通过巧妙地利用 1×1 卷积,在保持甚至提升模型多样性的同时,将参数量和计算量大幅度减少。
2.2 GoogLeNet 整体架构
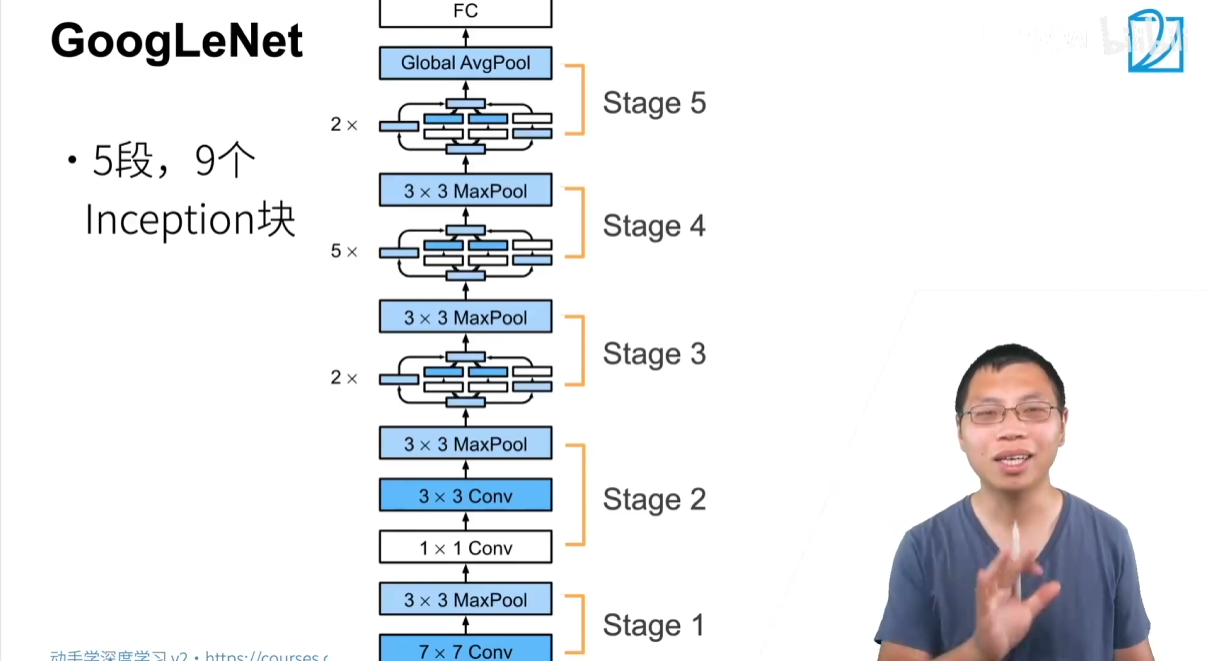
GoogLeNet 的整体架构类似于 VGG,由多个 “Stage” 组成,每个 Stage 负责在高宽减半的同时,增加通道数。
该网络总共包含 9 个 Inception 模块,分布在 5 个 Stage 中。
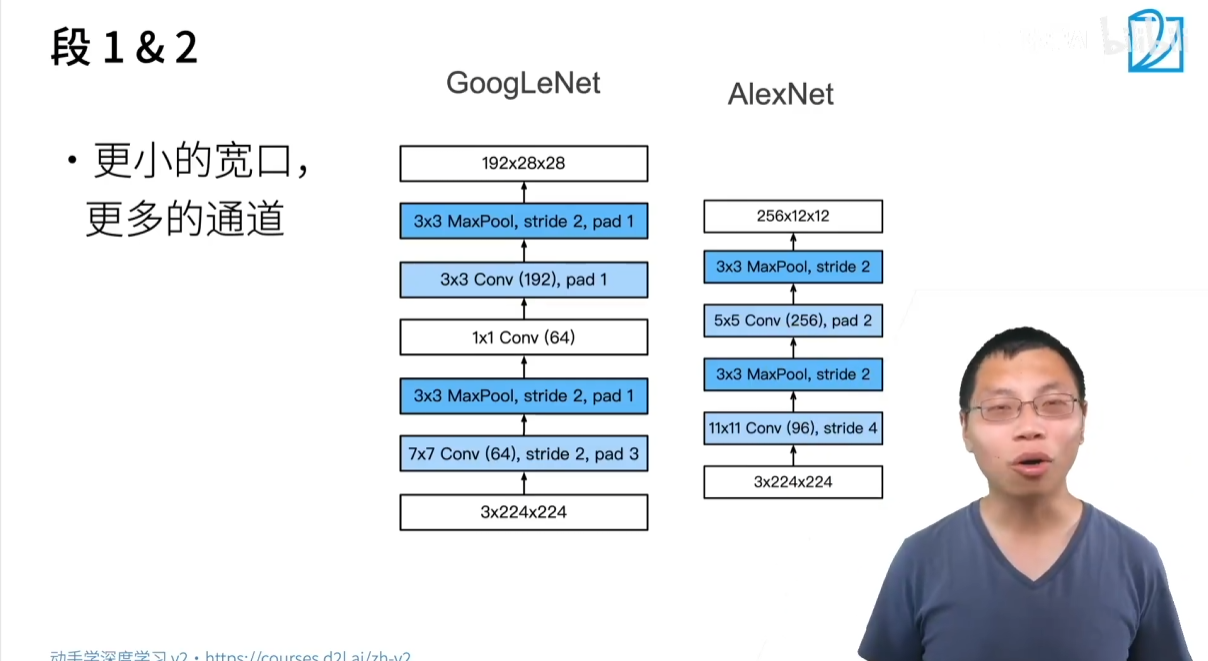
- Stage 1 & 2:
- 主要用于快速降低高宽、提升通道数,为后续的 Inception 模块做准备。
- 采用了 7×7 卷积和 3×3 的 Max Pooling。
- Stage 3:包含 2 个 Inception 模块,然后通过 Max Pooling 降低高宽。

- Stage 4:包含 5 个 Inception 模块,然后通过 Max Pooling 降低高宽。
- Stage 5:包含 2 个 Inception 模块。
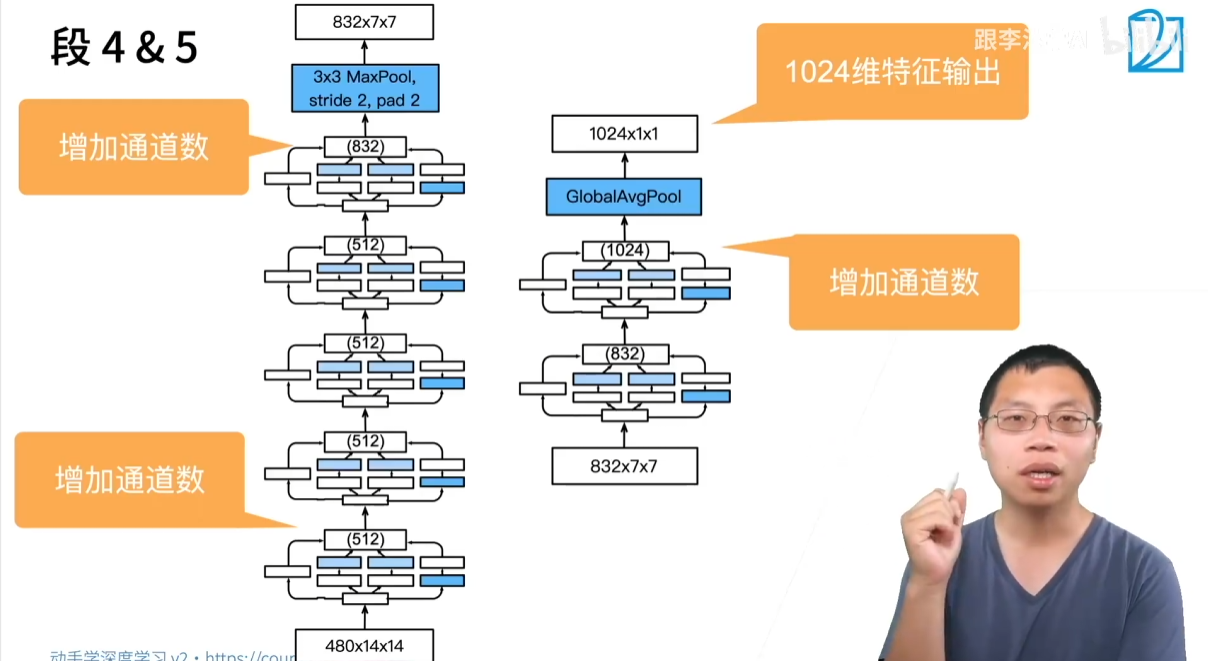
网络的最后不再使用传统的全连接层,而是采用 全局平均池化(Global Average Pooling)。这种设计受到 NIN 网络的启发,它将特征图的高宽平均化为一个单一的值,然后将这个长度为通道数的向量输入到最后一层全连接层,映射到类别数。这种做法大大减少了模型的参数量,并增强了模型的灵活性。
2.3 演进:V1、V2、V3、V4
GoogLeNet 的成功使其后续版本不断涌现,每个版本都加入了当时最新的研究成果:
-
Inception V1:即本笔记中主要介绍的原始 GoogLeNet 版本。
-
Inception V2:在 V1 的基础上引入了 Batch Normalization,显著加快了模型的收敛速度和训练稳定性。
-
Inception V3:对 Inception 模块本身进行了修改,用更小的卷积核替换了较大的卷积核。例如,用两个 3×3 卷积代替一个 5×5 卷积,或者用非对称的 1×7 和 7×1 卷积代替 3×3 卷积,进一步提升了参数效率和计算效率。同时,它将输入图像尺寸从 224×224 改为 299×299。
-
Inception V4:在 V3 的基础上,引入了 残差连接(Residual Connection),这个概念是 ResNet 的核心思想。
Inception V3 在速度和精度之间取得了很好的平衡,即使在今天仍然是一个非常优秀的网络。

2.4 优缺点
优点:
- 模型参数少,计算复杂度低:通过 Inception 模块中的 1×1 卷积来降低通道数,极大地减少了参数和计算量。
- 多样性强:Inception 模块集成了多种不同尺寸的卷积核和池化操作,能够更好地捕捉不同尺度的特征信息。
- 性能优越:在 ImageNet 等大型数据集上取得了出色的分类准确率,超越了 VGG 等经典网络。
- 深度更深:通过并行和串行相结合的方式,实现了超过 100 层的网络深度。
缺点:
- 设计复杂,难以复现:GoogLeNet 的网络结构,尤其是 Inception 模块中通道数的具体分配,是作者通过大量的实验和超参数搜索得到的,没有明确的规律,使得该网络难以复现和调整。
- 内存消耗大:由于并行路径的存在,中间特征图的内存占用较大。
2.5 代码实现
import torch
from torch import nn
from torch.nn import functional as Fclass Inception(nn.Module):# c1--c4是每条路径的输出通道数def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):super(Inception, self).__init__(**kwargs)# 线路1,单1x1卷积层self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)# 线路2,1x1卷积层后接3x3卷积层self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)# 线路3,1x1卷积层后接5x5卷积层self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)# 线路4,3x3最大汇聚层后接1x1卷积层self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)def forward(self, x):p1 = F.relu(self.p1_1(x))p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))p4 = F.relu(self.p4_2(self.p4_1(x)))# 在通道维度上连结输出return torch.cat((p1, p2, p3, p4), dim=1)b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),nn.ReLU(),nn.Conv2d(64, 192, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),Inception(256, 128, (128, 192), (32, 96), 64),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),Inception(512, 160, (112, 224), (24, 64), 64),Inception(512, 128, (128, 256), (24, 64), 64),Inception(512, 112, (144, 288), (32, 64), 64),Inception(528, 256, (160, 320), (32, 128), 128),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),Inception(832, 384, (192, 384), (48, 128), 128),nn.AdaptiveAvgPool2d((1,1)),nn.Flatten())net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))X = torch.rand(size=(1, 1, 96, 96))
for layer in net:X = layer(X)print(layer.__class__.__name__,'output shape:\t', X.shape)

3 ResNet (2015)
3.1 批量归一化
在深度神经网络中,当网络层数特别深时,会遇到一个常见问题:梯度消失(Vanishing Gradient)。梯度从顶层(靠近损失函数)反向传播到底层(靠近数据输入)时,由于多次链式法则的乘法,梯度会变得越来越小,导致底层参数更新非常缓慢。
这就造成了一个训练上的矛盾:
- 顶层:梯度大,更新快。
- 底层:梯度小,更新慢。
底层网络通常学习的是数据的底层特征(如边缘、纹理),而顶层学习的是高层语义特征。当底层网络在缓慢地更新参数时,其输出的特征分布会持续变化。这会导致顶层网络不得不不断地重新学习以适应这些新的底层特征分布,从而大大减慢了整个网络的收敛速度。

批量归一化的核心思想就是:在每一层都固定住数据的均值和方差,使其分布保持稳定,从而减少这种“内部协变量转移”的影响,让网络训练更快、更稳定。
3.1.1 工作原理
批量归一化(Batch Normalization)层的思想非常简单:对一个**小批量(mini-batch)**的数据,计算其均值和方差,然后用这两个统计量对数据进行归一化。

具体步骤:
-
计算均值和方差:对于一个大小为 ∣B∣|B|∣B∣ 的小批量数据 xi∈Bx_i\in Bxi∈B,计算其均值 μB\mu_BμB 和方差 σB2\sigma_B^2σB2:
μB=1∣B∣∑i∈BxiσB2=1∣B∣∑i∈B(xi−μB)2+ϵ\mu_B = \frac{1}{|B|}\sum_{i \in B} x_i\\ \sigma_B^2 = \frac{1}{|B|}\sum_{i \in B} (x_i - \mu_B)^2 + \epsilon μB=∣B∣1i∈B∑xiσB2=∣B∣1i∈B∑(xi−μB)2+ϵ- ϵ\epsilonϵ 是一个很小的常数,用于防止除以零。
-
进行归一化:用计算出的均值和方差对小批量中的每个样本进行归一化,使其均值为 0,方差为 1。
xi^=xi−μBσB2\hat{x_i}=\frac{x_i-\mu_B}{\sqrt{\sigma_B^2}} xi^=σB2xi−μB -
缩放和平移:为了让网络能够有选择地保留原始数据的分布信息,批量归一化层还引入了两个可学习的参数 γ\gammaγ(缩放因子)和 β\betaβ(平移因子)。
yi=γxi^+βy_i=\gamma\hat{x_i}+\beta yi=γxi^+β- γ\gammaγ 和 β\betaβ 是网络在训练过程中学习的参数。它们允许网络调整归一化后的数据分布,使其更适合后续层的处理。例如,当 γ=σB2\gamma=\sqrt{\sigma_{B}^{2}}γ=σB2 且 β=μB\beta=\mu_{B}β=μB 时,批量归一化层会恢复到原始数据分布,让网络可以自由选择是否进行归一化。
3.1.2 应用位置
批量归一化层通常被放置在全连接层或卷积层之后,激活函数之前。
- 全连接层:作用在特征维度上。每个特征(即矩阵的每一列)都有独立的均值、方差、γ\gammaγ 和 β\betaβ。它将所有样本的同一特征进行归一化。
- 卷积层:作用在通道维度上。它将一个 mini-batch 中所有图片、所有像素点的同一通道上的值视为一个整体,计算其均值和方差。换句话说,批量归一化层对每个通道计算一个均值和方差,并对该通道的所有像素点进行归一化。

3.1.3 理论争论
批量归一化刚被提出时,作者认为它之所以有效是因为减少了**“内部协变量转移”(Internal Covariate Shift)**。然而,后续的研究表明,批量归一化实际上并没有显著减少这种转移,其成功的真正原因可能在于:
- 平滑损失函数:批量归一化使得网络的损失函数更加平滑,从而允许使用更大的学习率,加速收敛。
- 正则化作用:批量归一化对每个小批量计算均值和方差,引入了随机性。这可以被视为一种噪声,对模型有正则化作用,类似于 Dropout,从而控制模型复杂度,避免过拟合。

3.2 为什么需要 ResNet
在深度学习的发展早期,人们普遍认为网络越深,性能应该越好。然而,当网络层数达到一定程度后,继续增加层数反而会导致网络性能下降。这并非过拟合问题,而是**梯度消失(Vanishing Gradient)或梯度爆炸(Exploding Gradient)**问题导致的训练困难。
GoogLeNet 和 VGG 这类网络通过巧妙的设计来增加深度,但都无法从根本上解决深层网络训练困难的问题。**批量归一化(Batch Normalization)**虽然能缓解梯度问题并加速收敛,但仍无法保证在网络深度极大时性能不会退化。
ResNet 的出现,通过引入一个颠覆性的概念——残差连接(Residual Connection),从根本上解决了深层网络的退化问题,使得训练数百甚至上千层的神经网络成为可能。

3.3 核心思想:残差连接
ResNet 的核心是其独特的残差块(Residual Block)。在一个普通的神经网络块中,我们希望学习一个映射 H(x)H(x)H(x),将输入 xxx 转换为输出。ResNet 的思想是:与其直接学习这个复杂的 H(x)H(x)H(x),不如让网络去学习一个“残差” F(x)F(x)F(x)。
残差块的输出不再是 H(x)H(x)H(x),而是 F(x)+xF(x)+xF(x)+x。这个 xxx 被称为残差连接,也叫捷径(Shortcut)。
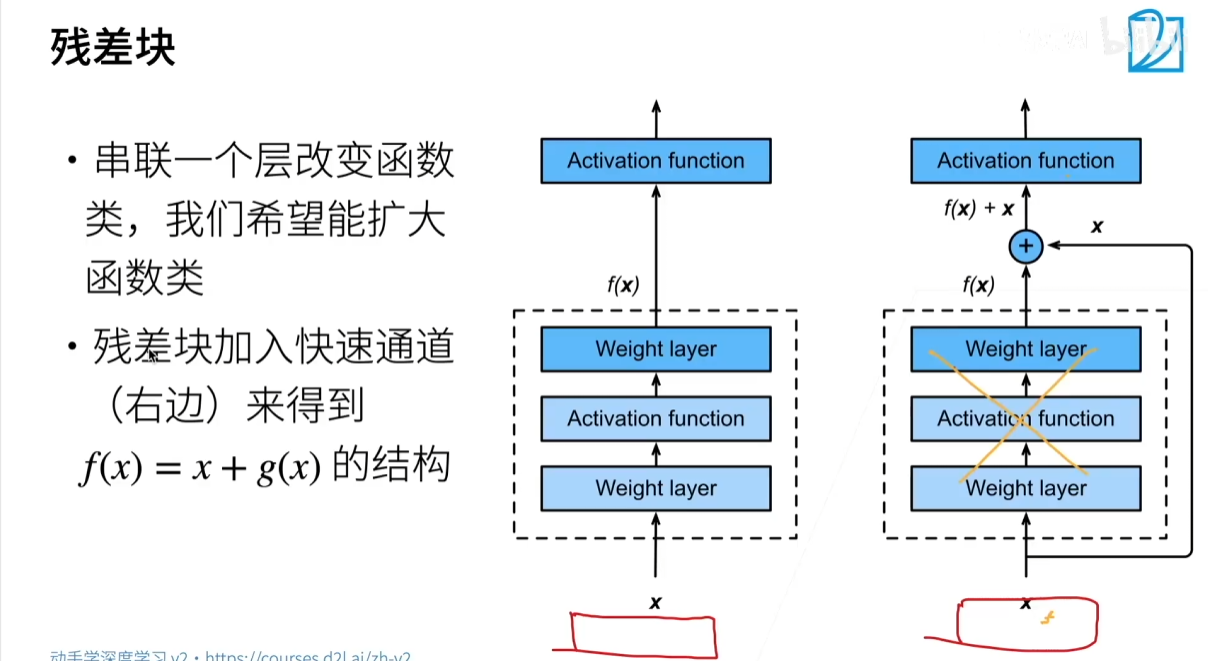
为什么残差连接是有效的?
- 易于学习恒等映射:当网络层数很深时,如果某些层不需要进行任何特征转换,理想的状况是这些层能直接输出输入。但在没有残差连接的普通网络中,将 H(x)H(x)H(x) 学习成恒等映射(即 H(x)=xH(x)=xH(x)=x)是一个非常困难的任务。
- 残差块的优势:在残差块中,要学习恒等映射,只需要将残差 F(x)F(x)F(x) 学习成 0 即可。这相比于直接学习复杂的恒等映射要容易得多。因此,即使网络很深,ResNet 也能保证至少不会比浅层网络差(因为多余的层可以被学习成恒等映射)。
- 缓解梯度消失:残差连接为梯度反向传播提供了一条直接的路径。梯度可以直接通过捷径从深层流向浅层,有效避免了梯度在深层网络中因多次相乘而消失,从而让底层网络也能得到有效的训练。
3.4 ResNet 结构
ResNet 的整体结构通常由多个残差块堆叠而成。根据不同的网络深度,残差块的设计也有所不同。
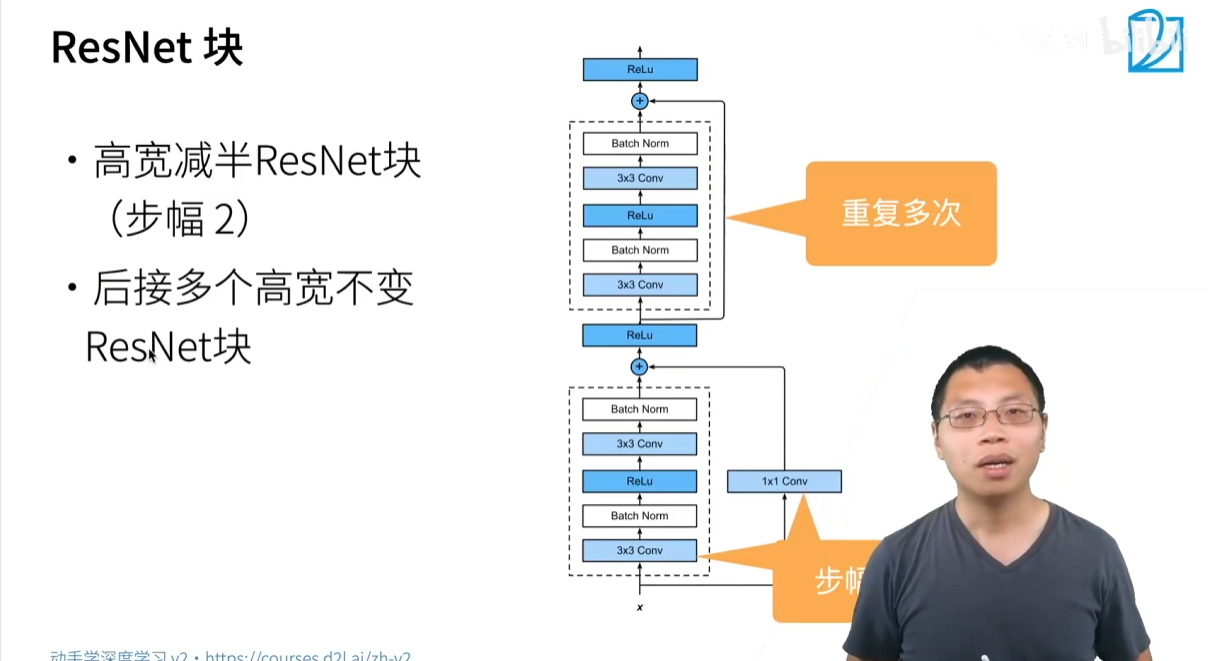
- 基本残差块(Basic Block):适用于较浅的 ResNet(如 ResNet-18,ResNet-34)。它包含两层 3×3 卷积,并在卷积后加入了批量归一化(Batch Normalization)层和 ReLU 激活函数。
y=F(x)+xy=F(x)+x y=F(x)+x
其中,F(x)F(x)F(x) 通常代表两层卷积和激活函数的复合操作。
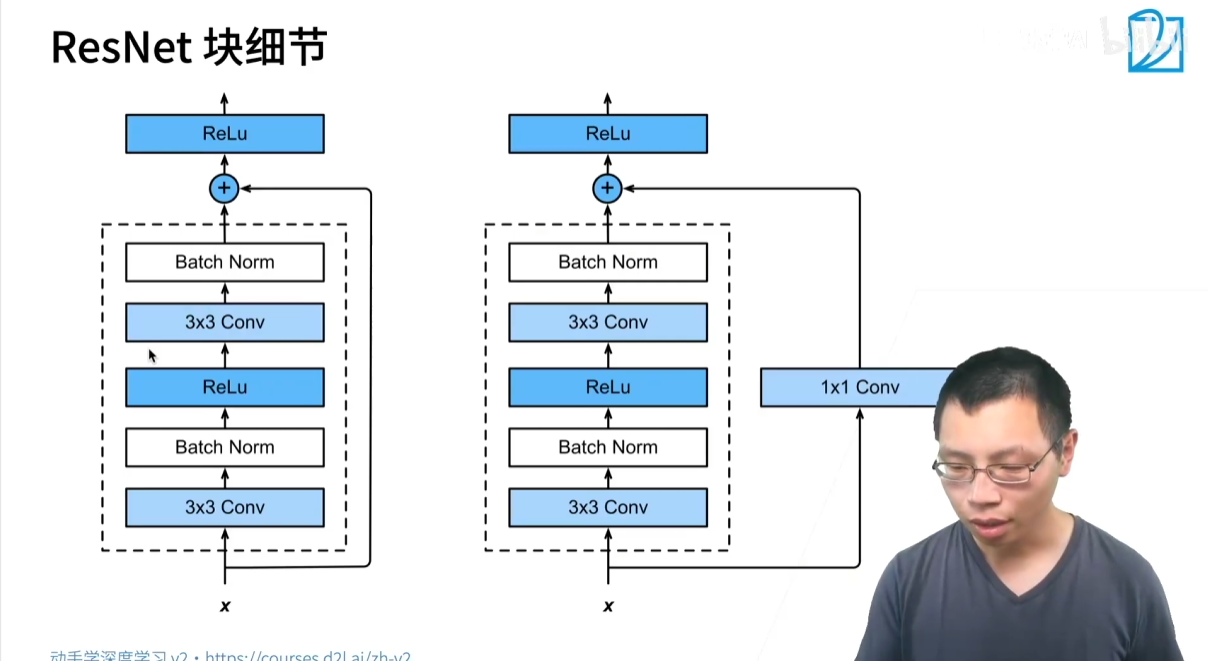
-
瓶颈残差块(Bottleneck Block):适用于更深的 ResNet(如 ResNet-50,ResNet-101,ResNet-152)。为了减少参数量和计算量,它使用了 1×1 卷积来先降维再升维(类似于 GoogLeNet 中的 1×1 卷积作用),从而形成一个“瓶颈”。
-
1×1 卷积:将通道数从 256 降至 64。
-
3×3 卷积:通道数保持 64 不变。
-
1×1 卷积:将通道数从 64 升回 256。
这种设计在保持网络深度的同时,极大地降低了计算复杂度。
-
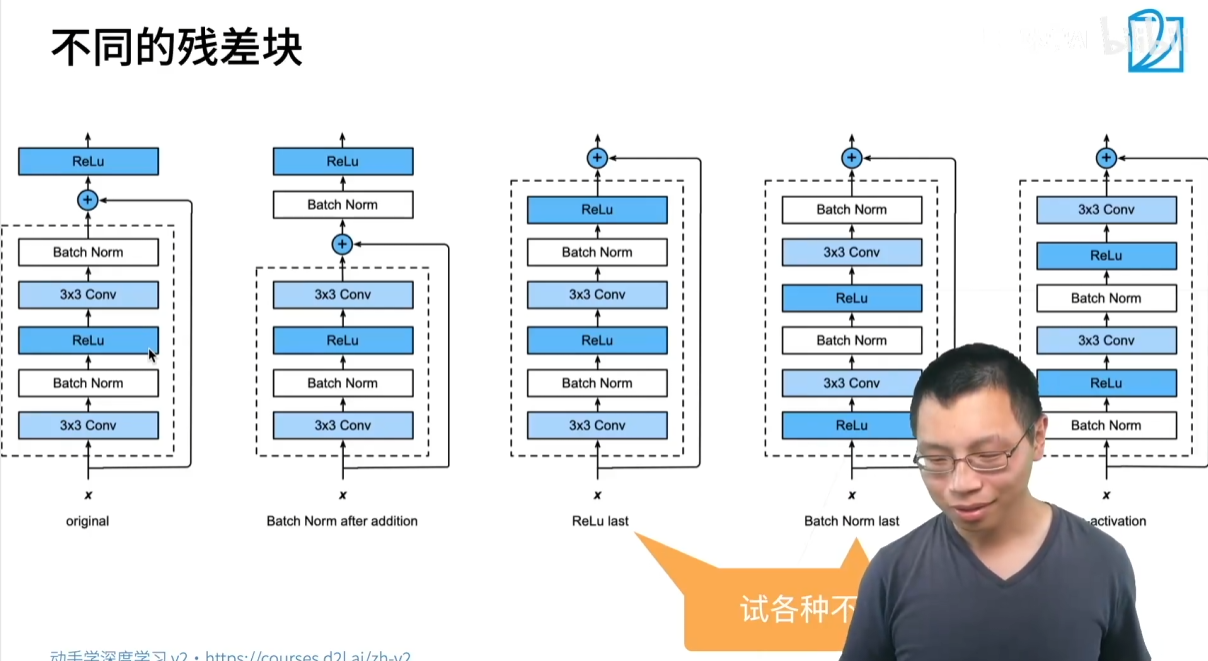
批量归一化(Batch Normalization)在 ResNet 中的作用:
ResNet 的每个卷积层后都会紧跟一个批量归一化层,这不仅能够加速网络收敛,还能稳定训练。由于 ResNet 能够构建数百层的网络,批量归一化在这里显得尤为重要,它确保了深层网络中每一层的输入分布都相对稳定,从而让训练变得可行。
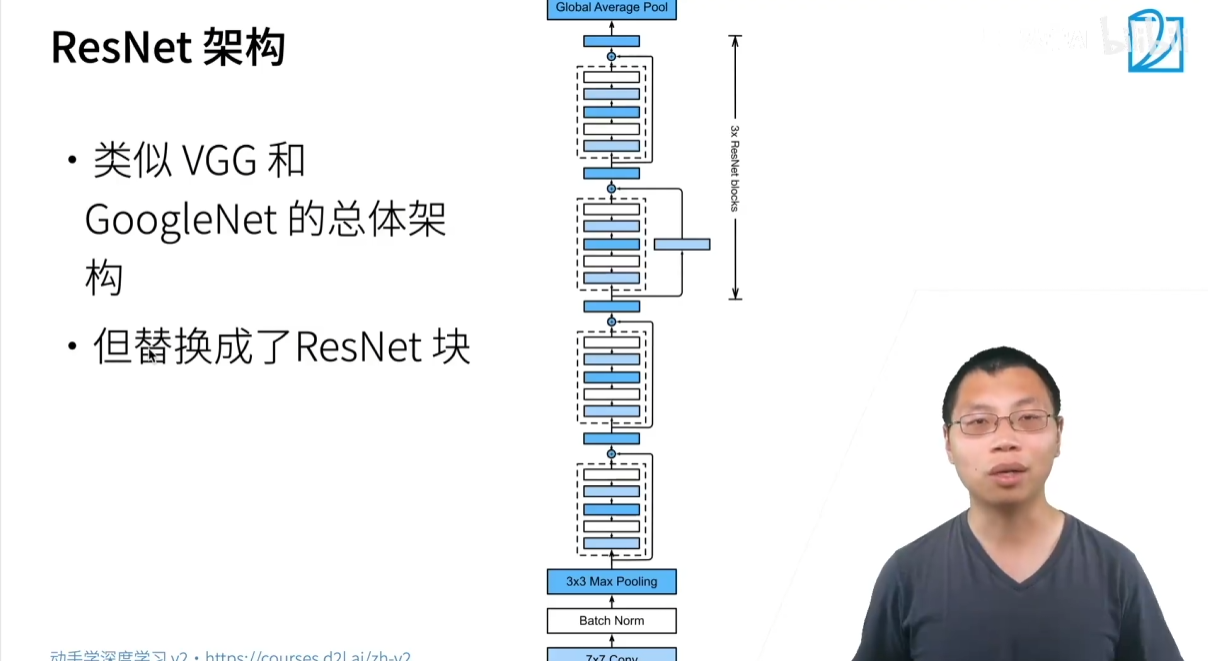
3.5 ResNet 的主要版本
- ResNet-18 / ResNet-34:使用基本残差块。
- ResNet-50 / ResNet-101 / ResNet-152:使用瓶颈残差块,是目前最常用的 ResNet 版本。
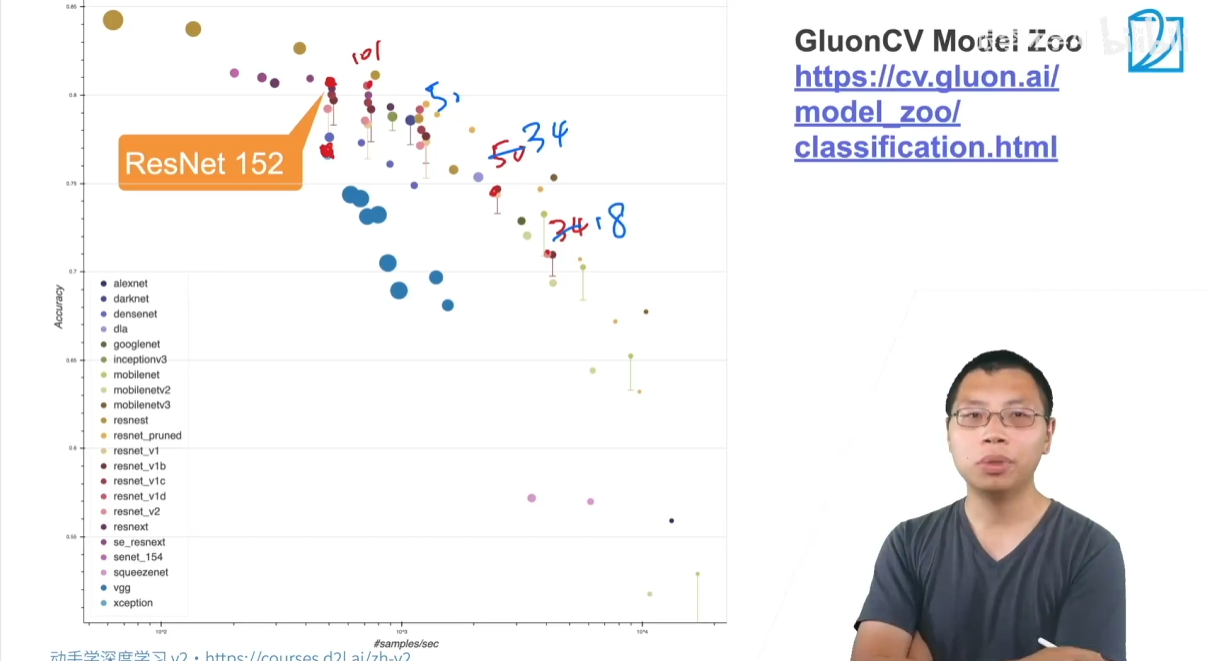
核心贡献
- 残差连接:通过引入捷径连接,让网络学习残差映射,从根本上解决了深层网络中的梯度消失和网络退化问题,使得训练超深网络成为可能。
- 批量归一化:在每个卷积层后都使用批量归一化,进一步稳定了训练过程,并允许使用更大的学习率,加速收敛。
- 模块化设计:网络由一系列可堆叠的残差块组成,这使得构建不同深度的 ResNet 变得非常灵活和方便。
ResNet 的出现,标志着深度学习进入了“超深网络”时代,它的思想被广泛应用于后续的各种网络架构中,包括 GoogLeNet 的后续版本(Inception-ResNet)。
3.6 梯度计算
我们可以通过比较有无残差连接的网络来直观地理解 ResNet 的原理。
3.6.1 普通的深度网络
假设我们有一个网络 F(x)F(x)F(x),其输出为 Y=F(x)Y=F(x)Y=F(x)。现在,我们在它上面再堆叠一层,形成一个新的网络 G(Y)=G(F(x))G(Y)=G(F(x))G(Y)=G(F(x))。
为了更新底层参数 WWW(位于 F(x)F(x)F(x) 中),我们需要计算梯度 $ \displaystyle\frac{\partial L}{\partial W} $。根据链式法则,这个梯度可以表示为:
∂L∂W=∂L∂Ynew⋅∂Ynew∂Y⋅∂Y∂W\frac{\partial L}{\partial W}=\frac{\partial L}{\partial Y_{new}}\cdot\frac{\partial Y_{new}}{\partial Y}\cdot\frac{\partial Y}{\partial W} ∂W∂L=∂Ynew∂L⋅∂Y∂Ynew⋅∂W∂Y
其中,Ynew=G(Y)Y_{new}=G(Y)Ynew=G(Y)。这里的关键是中间的乘法项
∂Ynew∂Y=∂G(Y)∂Y\frac{\partial Y_{new}}{\partial Y} = \frac{\partial G(Y)}{\partial Y} ∂Y∂Ynew=∂Y∂G(Y)
- 如果新添加的层 GGG 是一个非线性层(如全连接层),并且已经学习得不错(即输出接近最优解),那么它的导数 ∂G(Y)∂Y\displaystyle\frac{\partial G(Y)}{\partial Y}∂Y∂G(Y) 的值通常会非常小。
- 这个小数值会与前面层的梯度 ∂Y∂W\displaystyle\frac{\partial Y}{\partial W}∂W∂Y 相乘,导致最终的梯度 ∂L∂W\displaystyle\frac{\partial L}{\partial W}∂W∂L 变得更小。
- 随着网络层数的增加,这种乘法效应会不断累积,使得越靠近数据输入的底层,其梯度就越接近于零,从而发生梯度消失。
3.6.2 带有残差连接的 ResNet
ResNet 的残差连接将网络的映射关系从 Y=F(x)Y=F(x)Y=F(x) 变成了 Y=F(x)+xY=F(x)+xY=F(x)+x。
同样,我们在一个网络 F(x)F(x)F(x) 上再添加一层 GGG。但这一次,新层的输出 YnewY_{new}Ynew 不再仅仅是 G(Y)G(Y)G(Y),而是 Ynew=G(Y)+YY_{new}=G(Y)+YYnew=G(Y)+Y。
我们再次使用链式法则计算梯度 $ \displaystyle\frac{\partial L}{\partial W} $:
∂L∂W=∂L∂Ynew⋅∂Ynew∂Y⋅∂Y∂W\frac{\partial L}{\partial W}=\frac{\partial L}{\partial Y_{new}}\cdot\frac{\partial Y_{new}}{\partial Y}\cdot\frac{\partial Y}{\partial W} ∂W∂L=∂Ynew∂L⋅∂Y∂Ynew⋅∂W∂Y
现在,我们来看中间的乘法项 $ \displaystyle\frac{\partial Y_{new}}{\partial Y} $。由于残差连接的存在,这个导数变成了:
∂Ynew∂Y=∂(G(Y)+Y)∂Y=∂G(Y)∂Y+∂Y∂Y=∂G(Y)∂Y+1\frac{\partial Y_{new}}{\partial Y}=\frac{\partial(G(Y)+Y)}{\partial Y}=\frac{\partial G(Y)}{\partial Y}+\frac{\partial Y}{\partial Y}=\frac{\partial G(Y)}{\partial Y}+1 ∂Y∂Ynew=∂Y∂(G(Y)+Y)=∂Y∂G(Y)+∂Y∂Y=∂Y∂G(Y)+1
这个结果是一个加法,而不是简单的乘法!
- 即使新层的导数 ∂G(Y)∂Y\displaystyle\frac{\partial G(Y)}{\partial Y}∂Y∂G(Y) 变得非常小,由于有 +1 的存在,整个项 ∂G(Y)∂Y+1\displaystyle\frac{\partial G(Y)}{\partial Y}+1∂Y∂G(Y)+1 仍然会保持一个相对较大的值(至少不小于 1)。
- 这意味着,当梯度反向传播时,它总是能通过“捷径”直接传递下去,而不会被中间层的乘法项削弱。
- 这就像为梯度提供了一条高速公路,让它能够绕过复杂的网络层,直接到达底层,确保底层参数也能获得足够大的梯度来进行有效的更新。
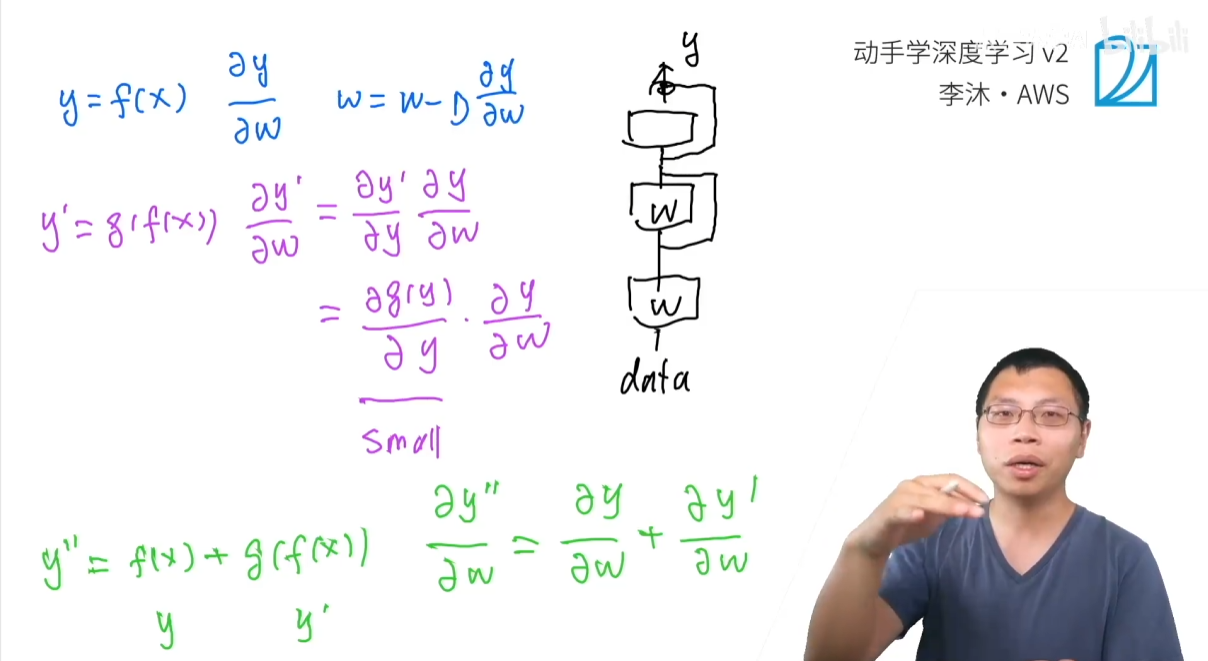
3.6.3 小结
- 本质区别:ResNet 的残差连接将梯度的连乘(multiplication)变成了连加(addition)。
- 深层网络中的作用:即使网络层数很深,残差连接也能为梯度提供一个直接的、无衰减的路径,避免了梯度在反向传播过程中因多次相乘而消失。
- 训练效果:这使得网络底层参数能够持续获得较大的梯度,从而可以被有效地训练,从根本上解决了深层网络中的梯度消失问题,使得训练上千层的网络成为可能。
3.7 代码实现
import torch
from torch import nn
from torch.nn import functional as F# 实现残差块
class Residual(nn.Module): #@savedef __init__(self, input_channels, num_channels,use_1x1conv=False, strides=1):super().__init__()self.conv1 = nn.Conv2d(input_channels, num_channels,kernel_size=3, padding=1, stride=strides)self.conv2 = nn.Conv2d(num_channels, num_channels,kernel_size=3, padding=1)if use_1x1conv:self.conv3 = nn.Conv2d(input_channels, num_channels,kernel_size=1, stride=strides)else:self.conv3 = Noneself.bn1 = nn.BatchNorm2d(num_channels)self.bn2 = nn.BatchNorm2d(num_channels)def forward(self, X):Y = F.relu(self.bn1(self.conv1(X)))Y = self.bn2(self.conv2(Y))if self.conv3:X = self.conv3(X)Y += Xreturn F.relu(Y)def resnet_block(input_channels, num_channels, num_residuals,first_block=False):blk = []for i in range(num_residuals):if i == 0 and not first_block:blk.append(Residual(input_channels, num_channels,use_1x1conv=True, strides=2))else:blk.append(Residual(num_channels, num_channels))return blk# 查看输入和输出形状一致的情况。
blk = Residual(3,3)
X = torch.rand(4, 3, 6, 6)
Y = blk(X)
print(Y.shape)# 也可以在增加输出通道数的同时,减半输出的高和宽。
blk = Residual(3,6, use_1x1conv=True, strides=2)
print(blk(X).shape)b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),nn.BatchNorm2d(64), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))net = nn.Sequential(b1, b2, b3, b4, b5,nn.AdaptiveAvgPool2d((1,1)),nn.Flatten(), nn.Linear(512, 10))X = torch.rand(size=(1, 1, 224, 224))
for layer in net:X = layer(X)print(layer.__class__.__name__,'output shape:\t', X.shape)
