直接插入排序算法:可视化讲解与C语言实现
目录
介绍
算法思想
算法流程图
算法可视化演示
编辑算法步骤详解
算法特点
时间复杂度分析
空间复杂度分析
稳定性分析
关键特性总结
C语言实现
介绍
直接插入排序(Straight Insertion Sort)是一种简单直观的排序算法。它的工作原理类似于我们打扑克牌时对手中的牌进行排序。
算法思想
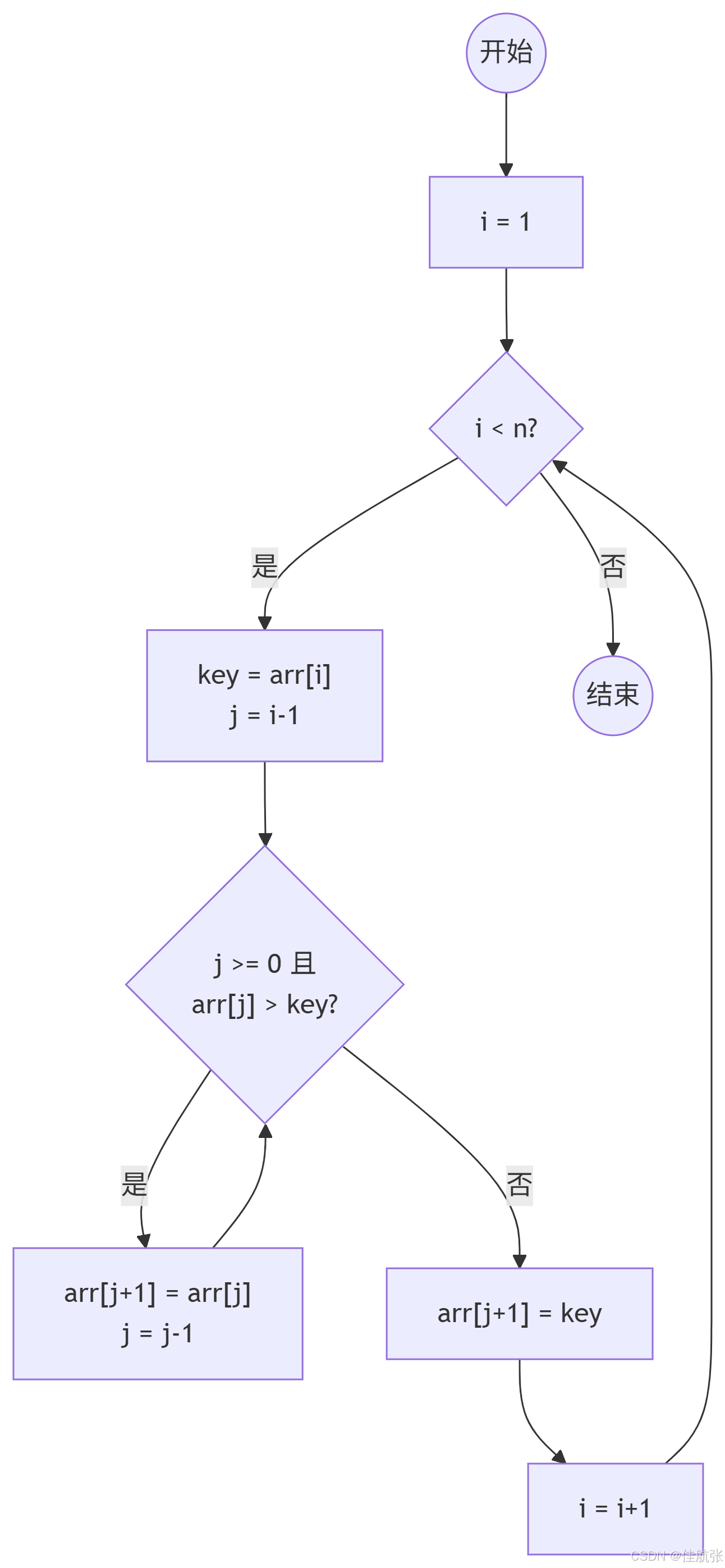
直接插入排序是一种简单直观的排序算法,核心思想是:将待排序元素插入到已排序序列的适当位置。类似于整理扑克牌的过程:
- 从第一个元素开始,该元素可以认为已经被排序。
- 取出下一个元素,在已经排序的元素序列中从后向前扫描。
- 如果该元素(已排序)大于新元素,将该元素移到下一位置。
- 重复步骤3,直到找到已排序的元素小于等于新元素的位置。
- 将新元素插入到该位置后。
- 重复步骤2~5,直到所有元素都排序完毕。
算法流程图
算法可视化演示
接下来将根据算法流程图来讲解,以数组arr={2,0,6,8,6,7,7,9,1,3}共10个元素,进行直接插入排序的算法可视化演示。其中数组arr;数组长度n=10;下标i=0,1,...,8,9;key用来存储当前未排序元素的原始值;j=i-1,...,0用来表示已排序区的元素的下标。
 算法步骤详解
算法步骤详解
数组arr={2,0,6,8,6,7,7,9,1,3},共10个元素,下图展示了其未排序前的状态。
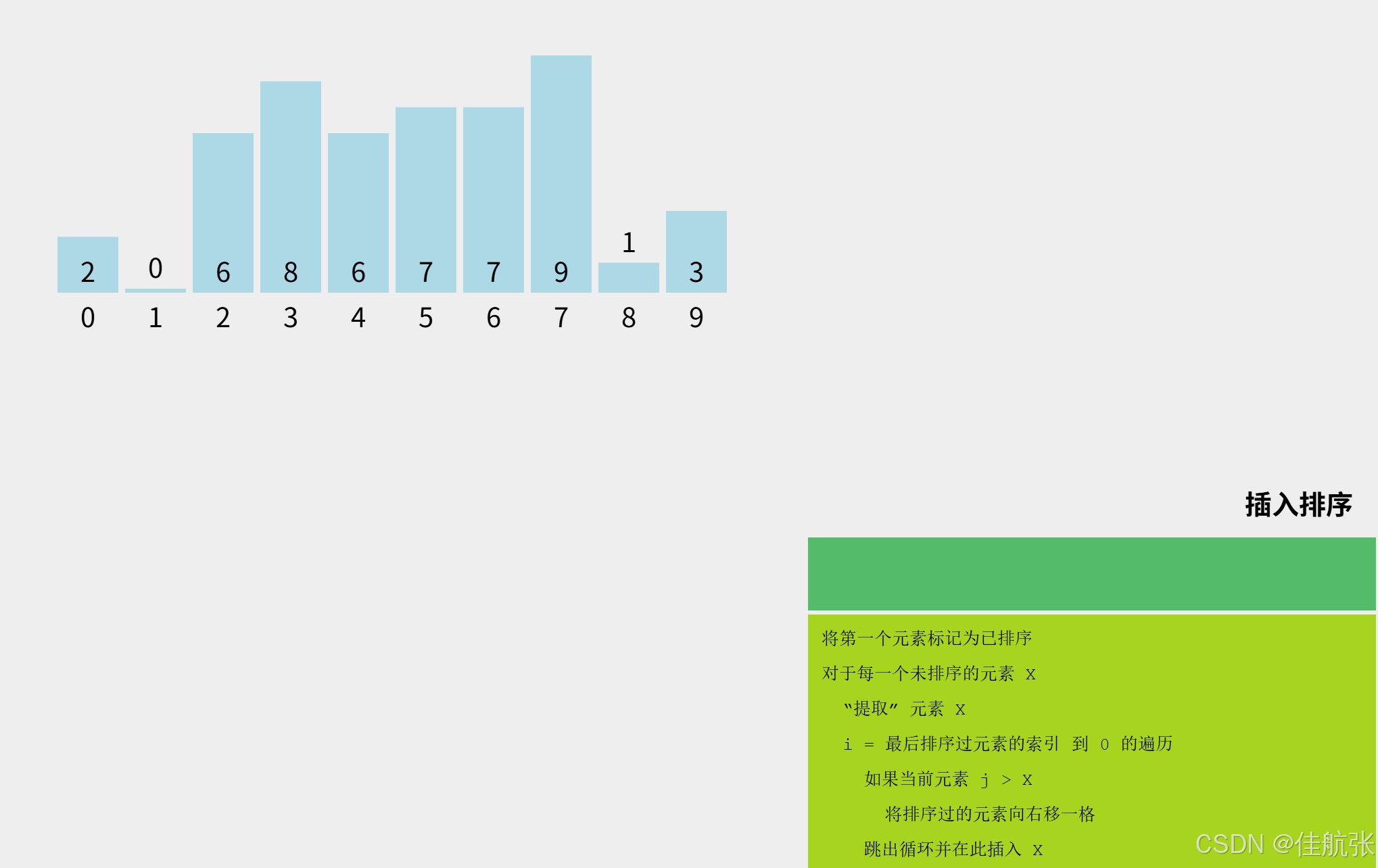
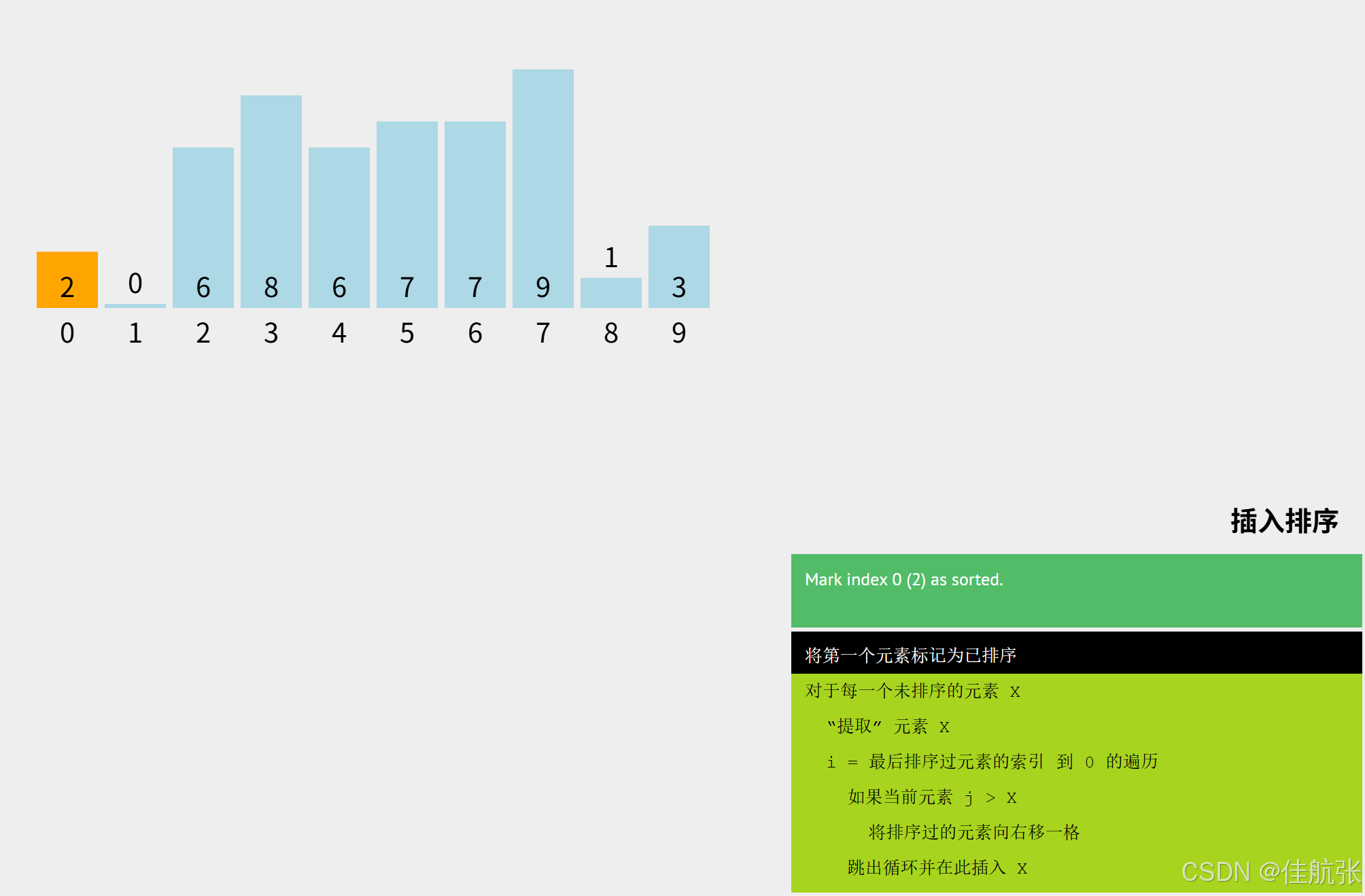
对于arr[0] = 2,因为其是第一个元素,直接标记成已排序,第一个不用排序,这也是流程图中从i=1开始,而不是i=0开始的原因。区分已排序区和未排序区两个概念有利于我们理解排序的过程。做个类比:已排序区相当于我们手中已经抓到的牌,未排序区指还未摸的牌。(注:这里假设摸到手里的牌都会按顺序插入排列,不会随意放置)。接下来就是遍历未排序区的元素,即arr[1]、arr[2]、,...,arr[9]进行排序。
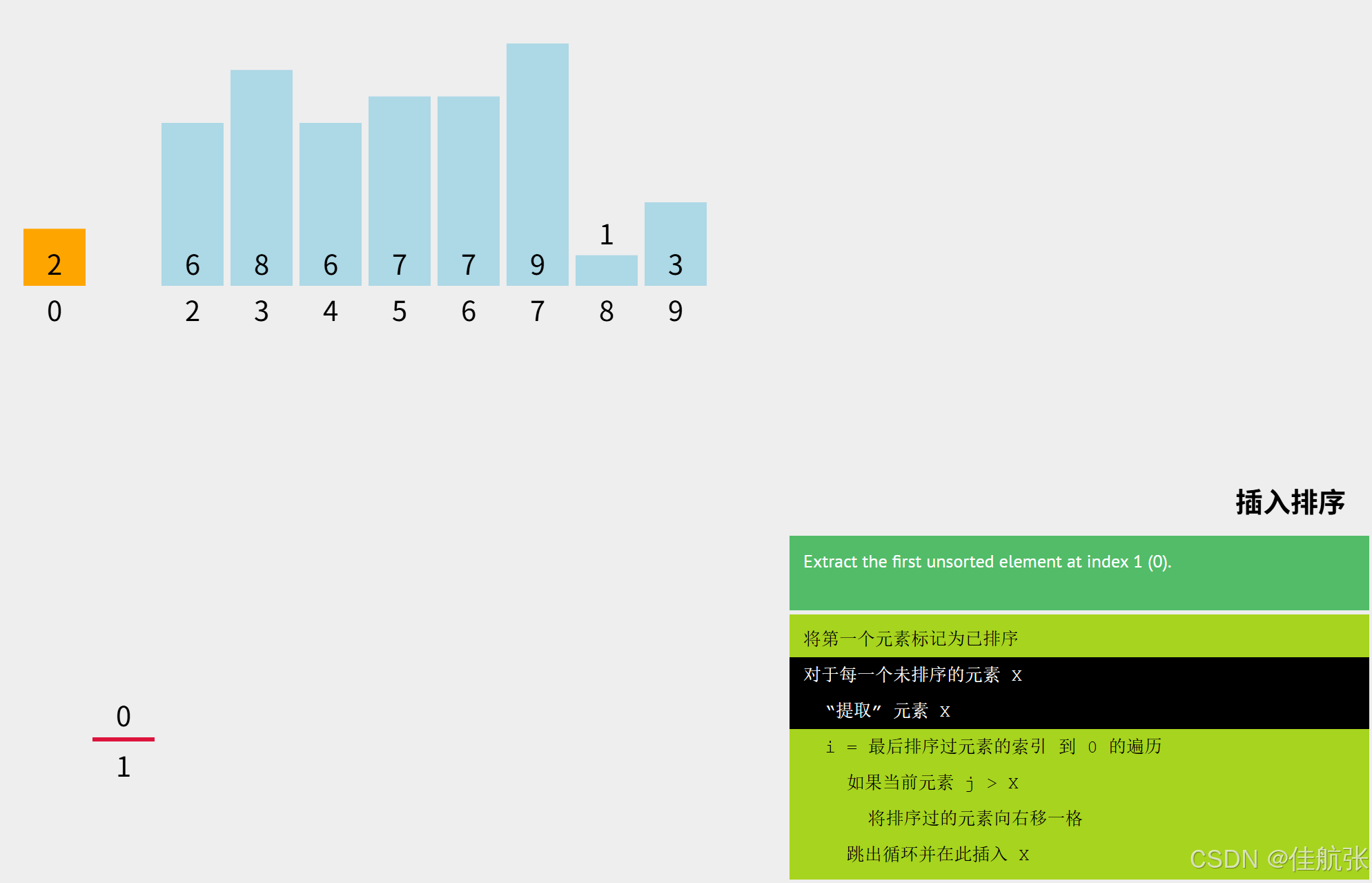
对于arr[1] = 0,首先令key = arr[1],将arr[1]位置原本的值保存下来。因为排序中可能涉及到元素移动,原位置的元素就有可能被覆盖,从而丢失。
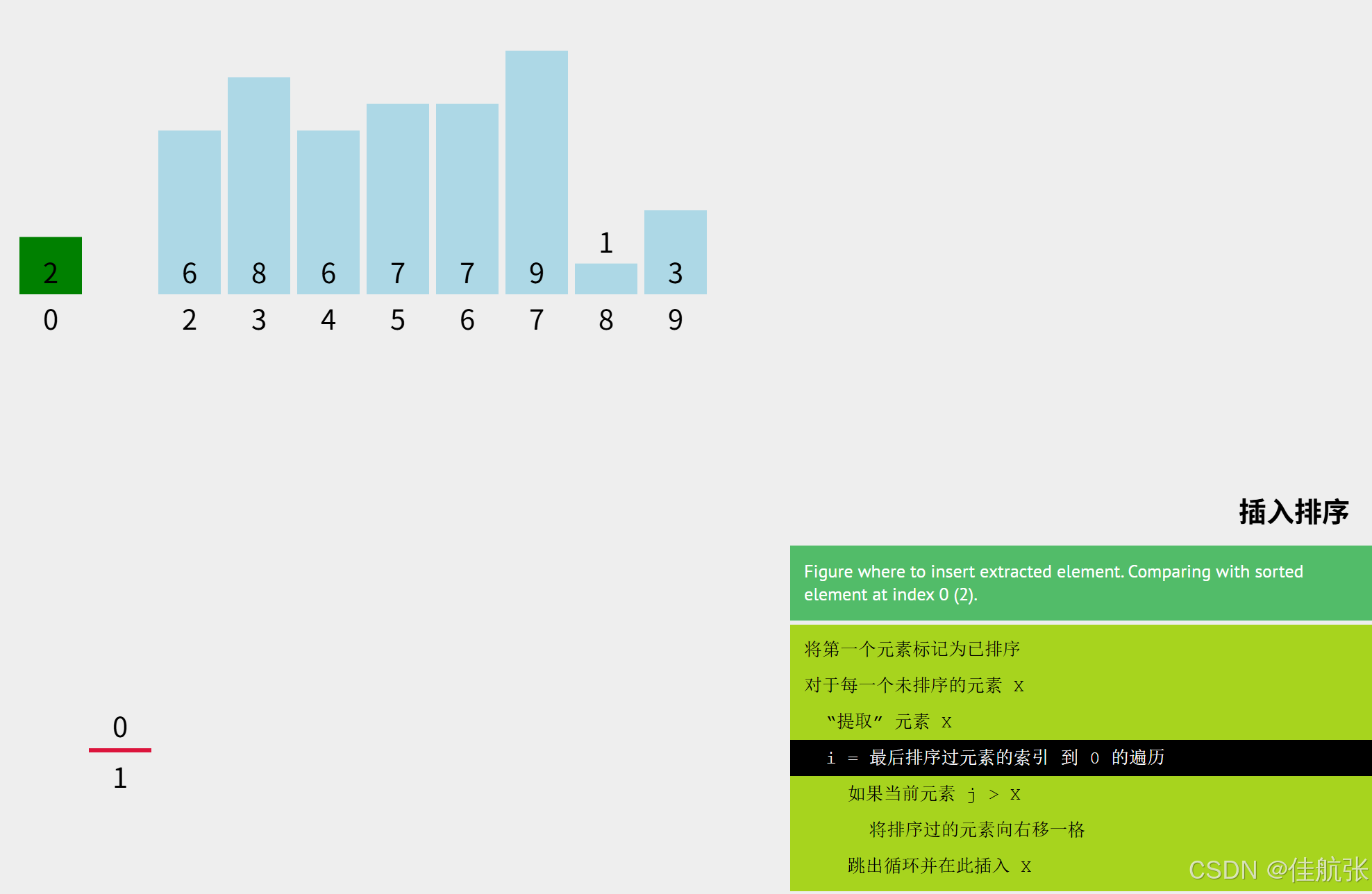
接下来就是要确定key插入的位置,可以想象的是,如果数组排序完之后按照升序排列(即小的数在下标小的位置,大的数在下标大的位置),那么key插入的位置应该满足以下条件:
左边的数<= key <= 右边的数。至于这个"==",就涉及到数组中存在相同的元素时的处理情况。直接插入排序算法,不改变原始数组中相同元素的相对位置。即若排序前 a==a‘ ,a在a'左侧,则排序后a还在a'左侧,下面示例中会有涉及。
根据流程图,此时i=1, j = i - 1 = 0 key只需要跟已排序区中的arr[0]对应的2比较即可
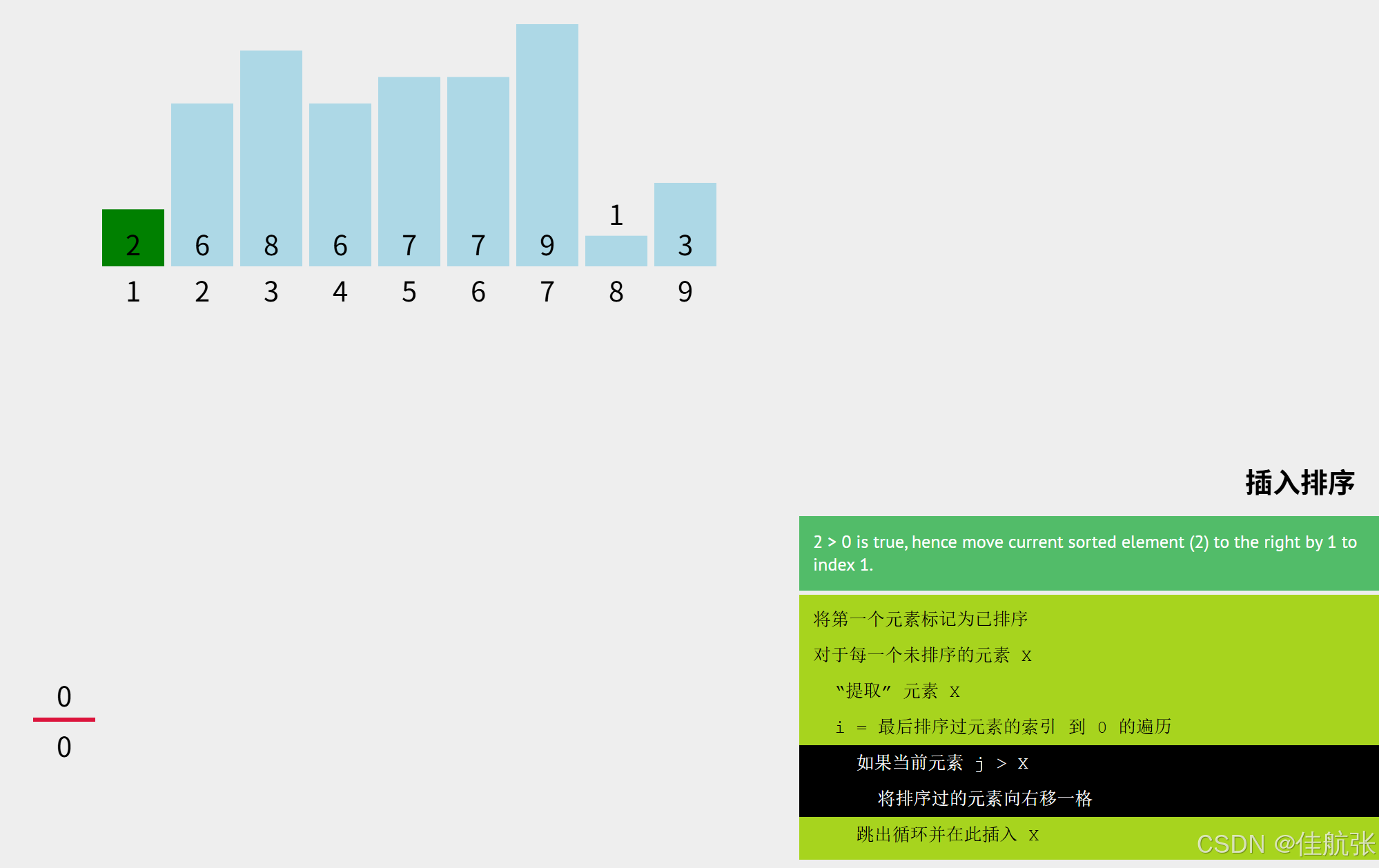
2 > 0,所以2右移,就是流程图中的arr[j+1] = arr[j]这行代码实现的右移。
j = j - 1 = 0 -1 = -1 < 0 所以针对当前未排序元素key的排序结束了
给key放到合适的位置,即代码arr[j+1] = key.此时j=-1,j+1 = 0,即arr[0] = key.
i = 1 即下标1的插入结束,i = i + 1 = 2 < n(10),继续下标2的插入处理。
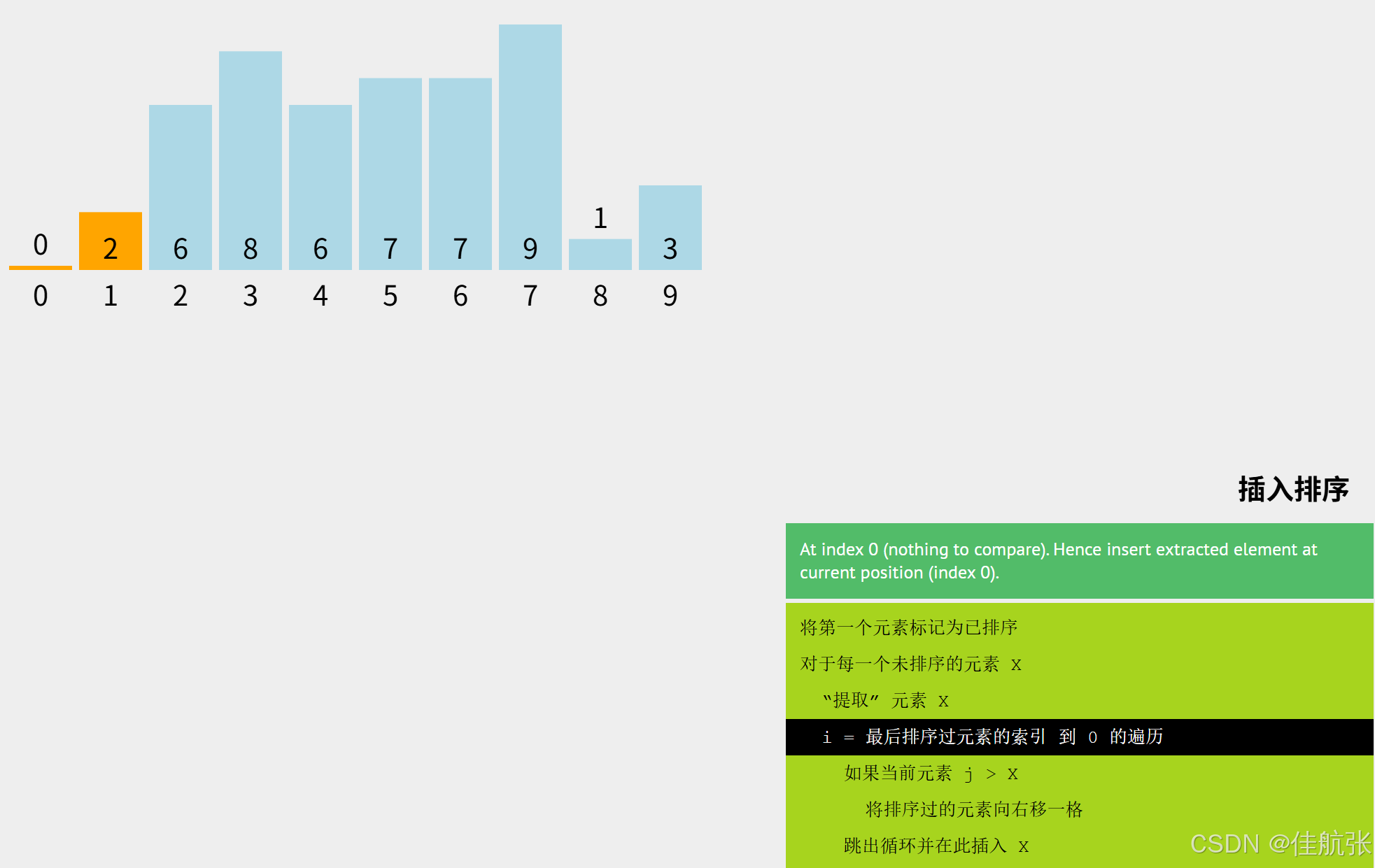
同理,把key = arr[i] (i=2),即key =6;
j = i -1 (i=2),即j = 1;可见此时已排序区有两个元素(下标1和下标0),即6可能要依次跟下标1对应的2,下标0对应的0进行比较。6需要先跟2比,视结果,再决定是否还要与0比较。
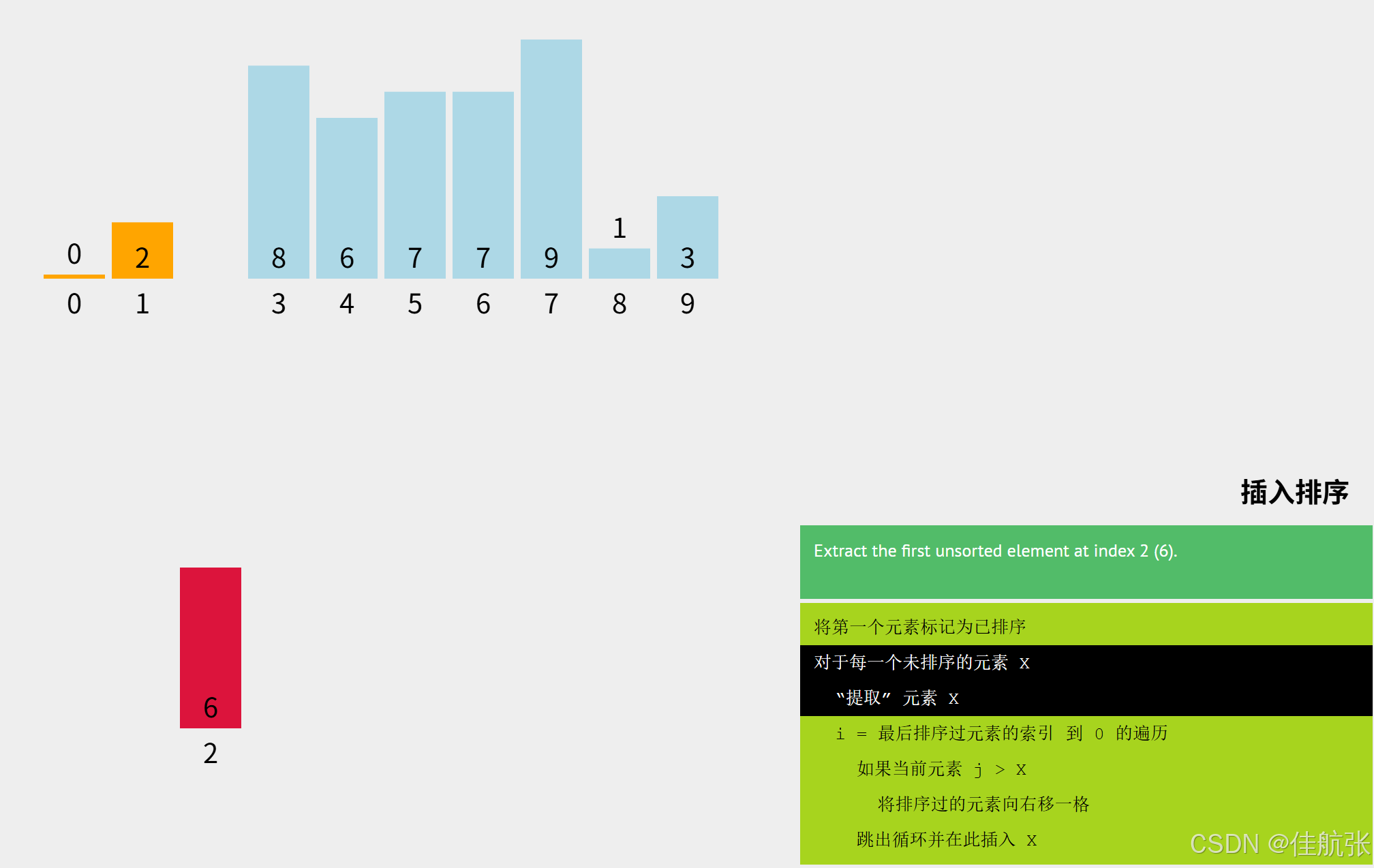
6先与2比较,2 < 6,所以6的位置已经确定了,不用再与下标0对应的0比了。因为有前面的插入排序,可以确定已排序区是升序的。6不小于下标1对应的元素,则一定不小于下标0对应的元素。
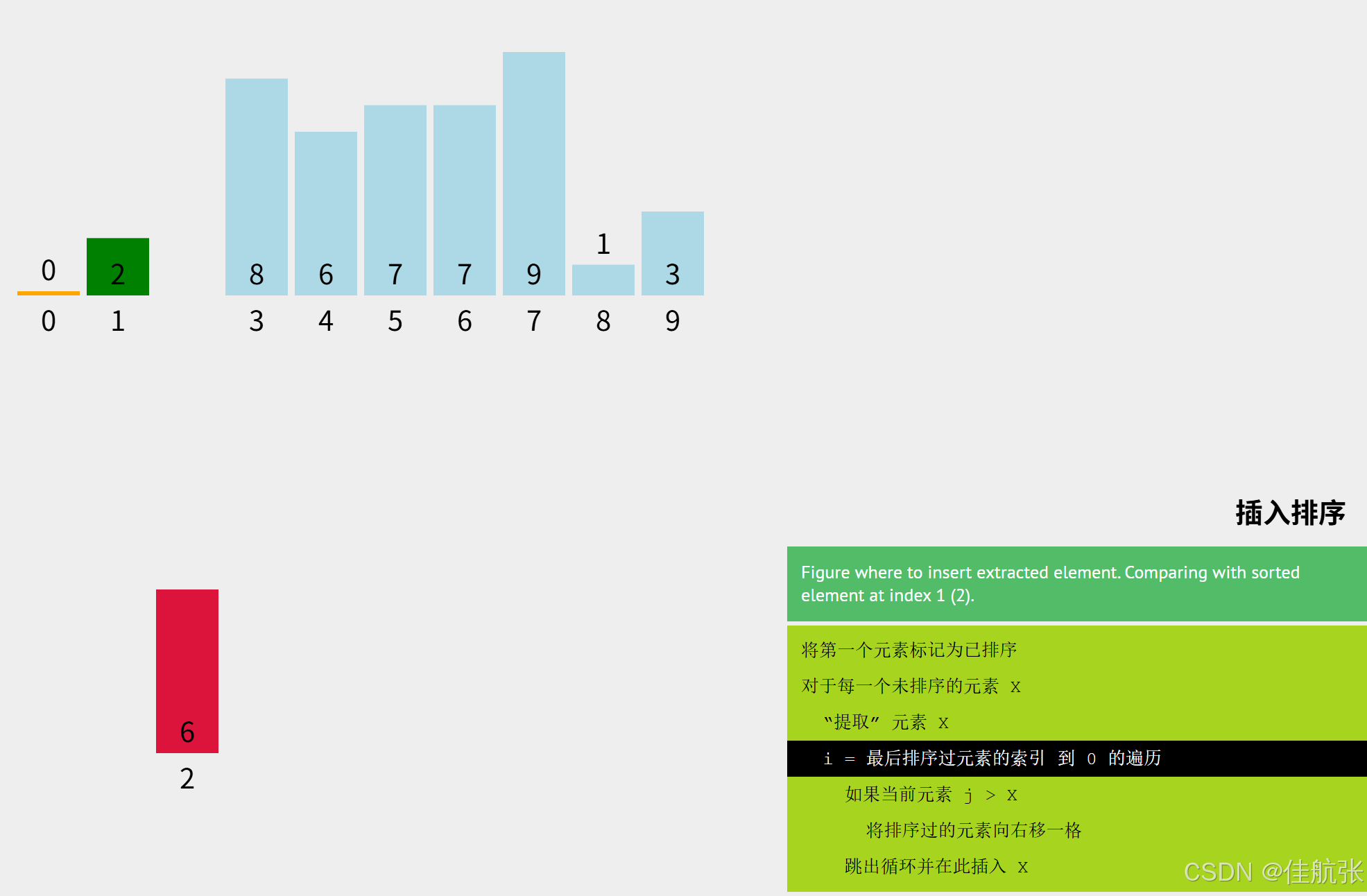
直接将6插入即可 i = i + 1 = 2 + 1 = 3 < n(10),所以未排序区还没遍历完,继续。
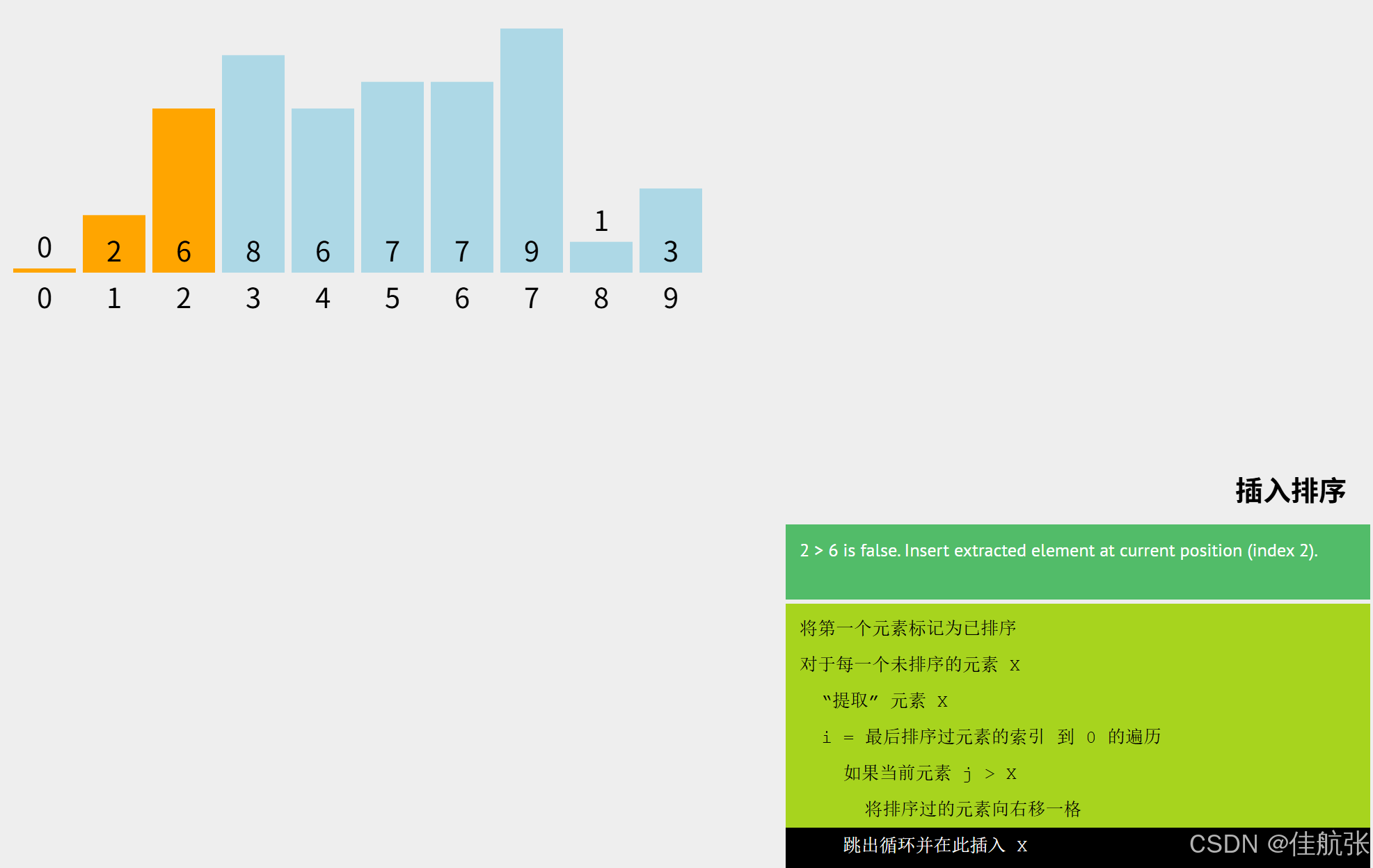
同理,把key = arr[i] (i=3),即key =8;
j = i -1 (i=3),即j = 2;可见此时已排序区有3个元素(下标2、1、0),即8可能要依次跟下标2对应的6、下标1对应的2,下标0对应的0进行比较。8需要先跟6比,视结果,再决定是否还要与2比较。
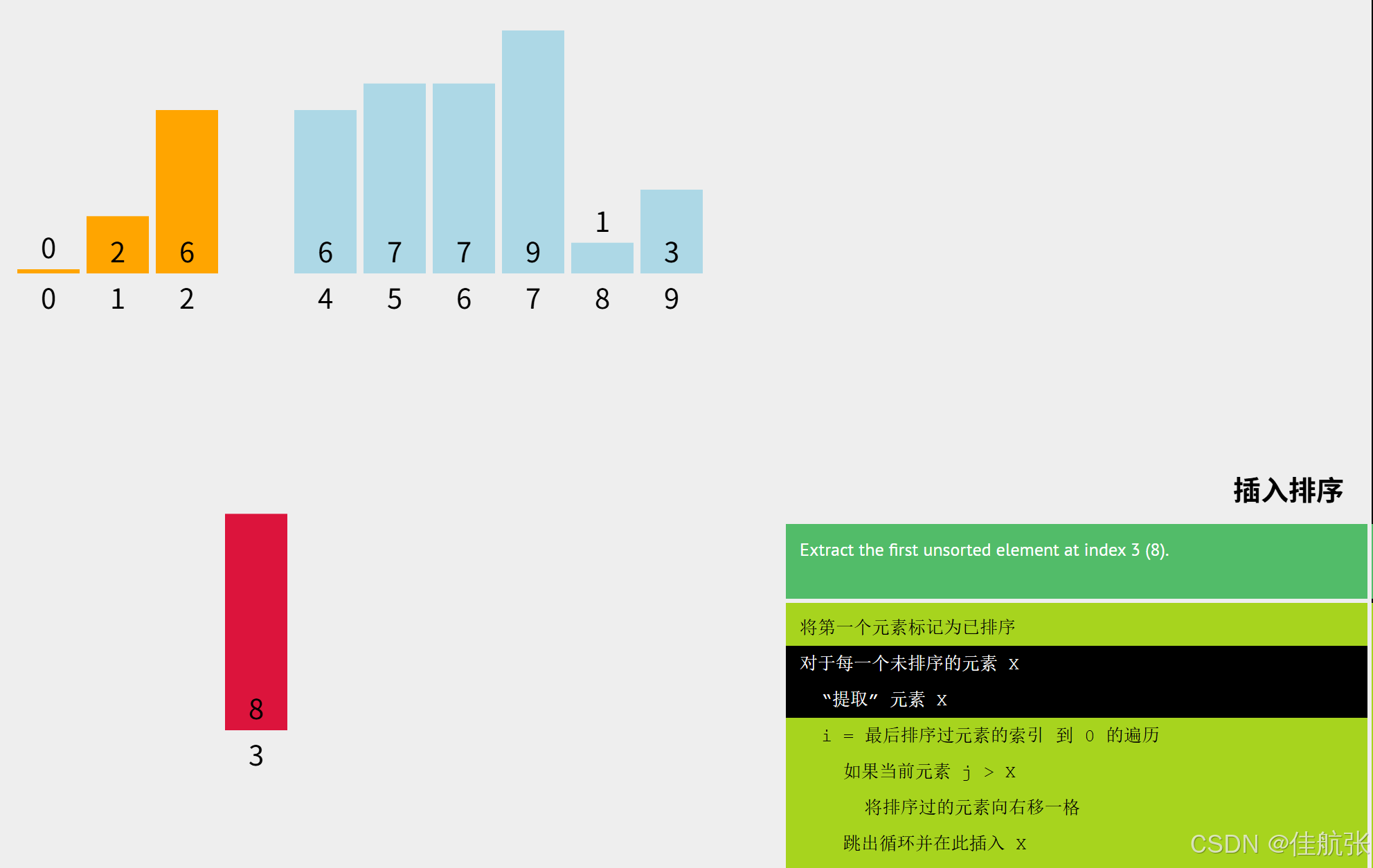
8先与6比较,6 < 8,所以8的位置已经确定了,不用再与下标1和下标0比了。因为有前面的插入排序,可以确定已排序区是升序的。8不小于下标2对应的元素,则一定不小于下标1和0对应的元素。
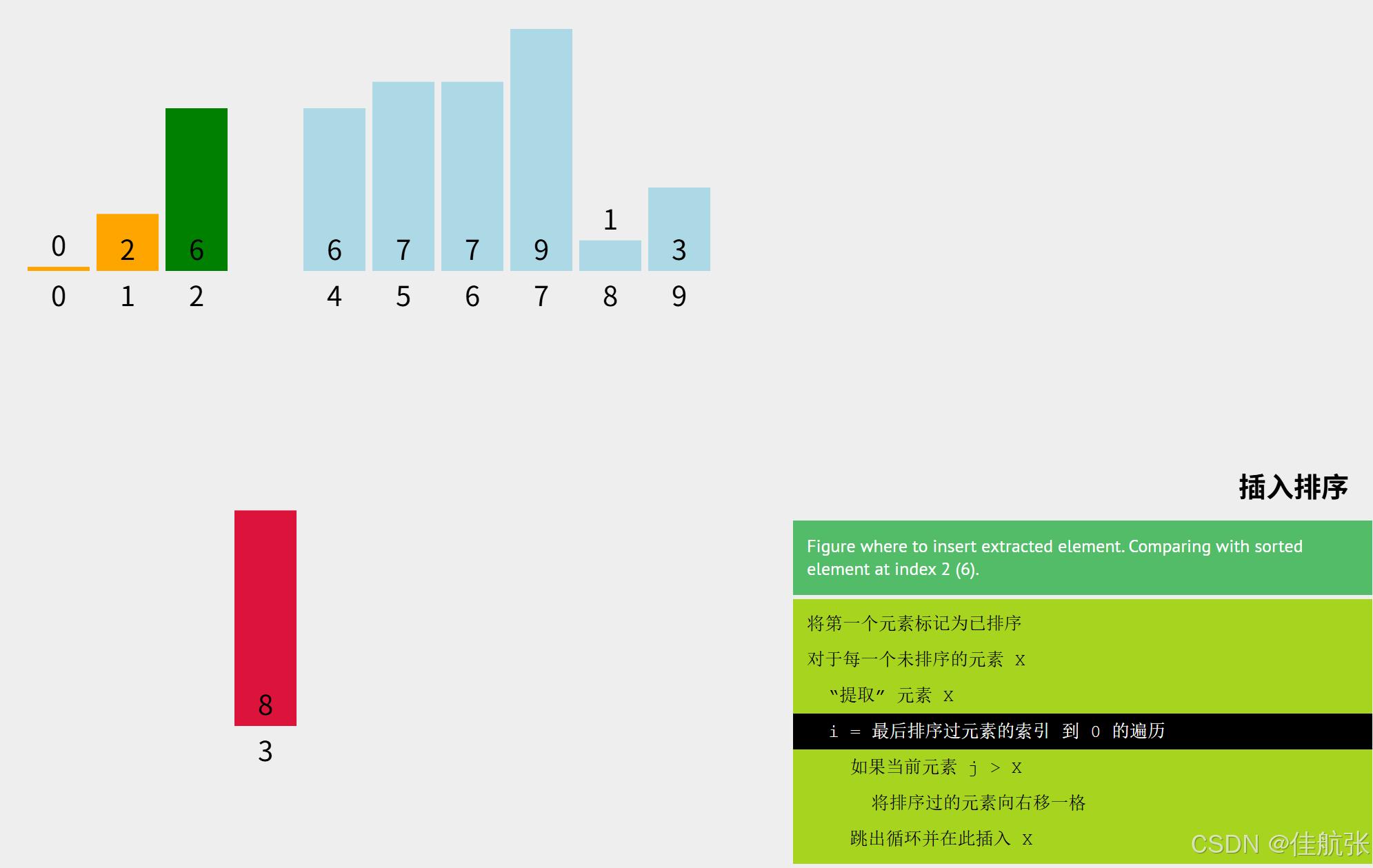
直接将8插入即可 i = i + 1 = 3 + 1 = 4 < n(10),所以未排序区还没遍历完,继续。
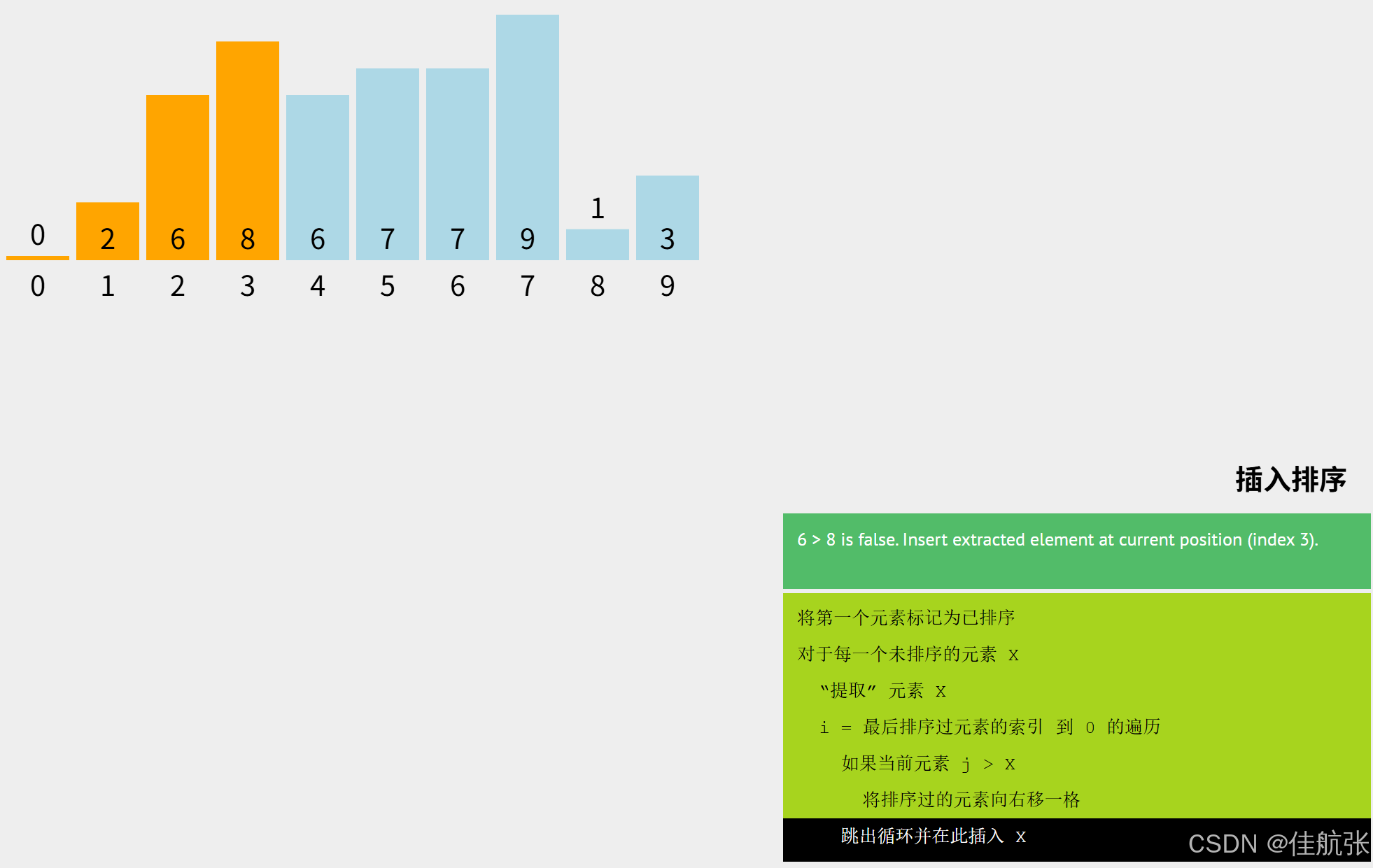
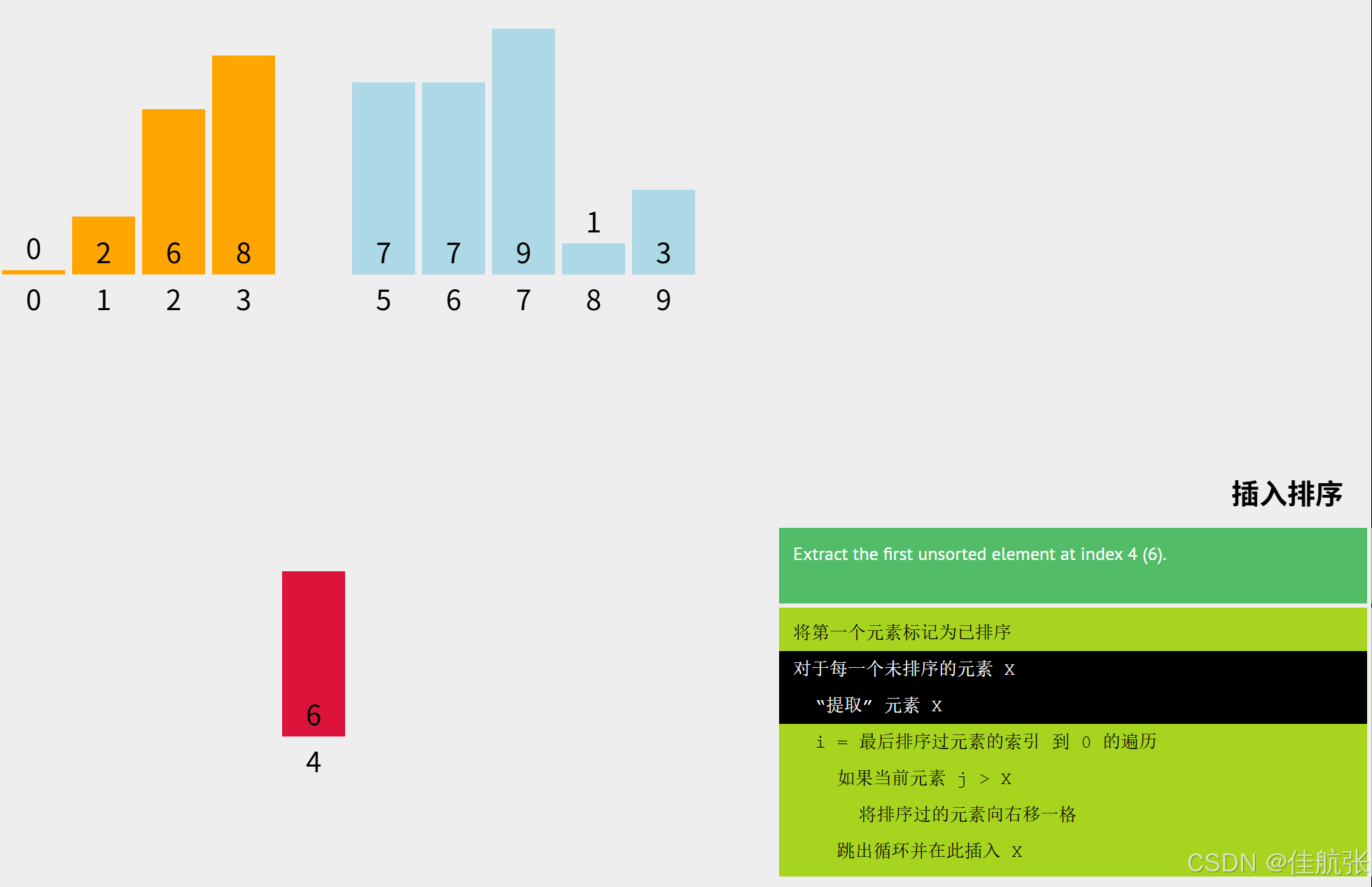
同理,把key = arr[i] (i=4),即key =6;
j = i -1 (i=4),即j = 3;可见此时已排序区有4个元素(下标3、2、1、0),即6可能要依次跟下标3、2、1、0对应的元素进行比较。6需要先跟下标3对应的元素比,视结果,再决定是否还要继续比较。
6先与8比较,8 > 6,所以6的位置还不确定,将8先右移1位,6继续和下标2对应的元素比较。
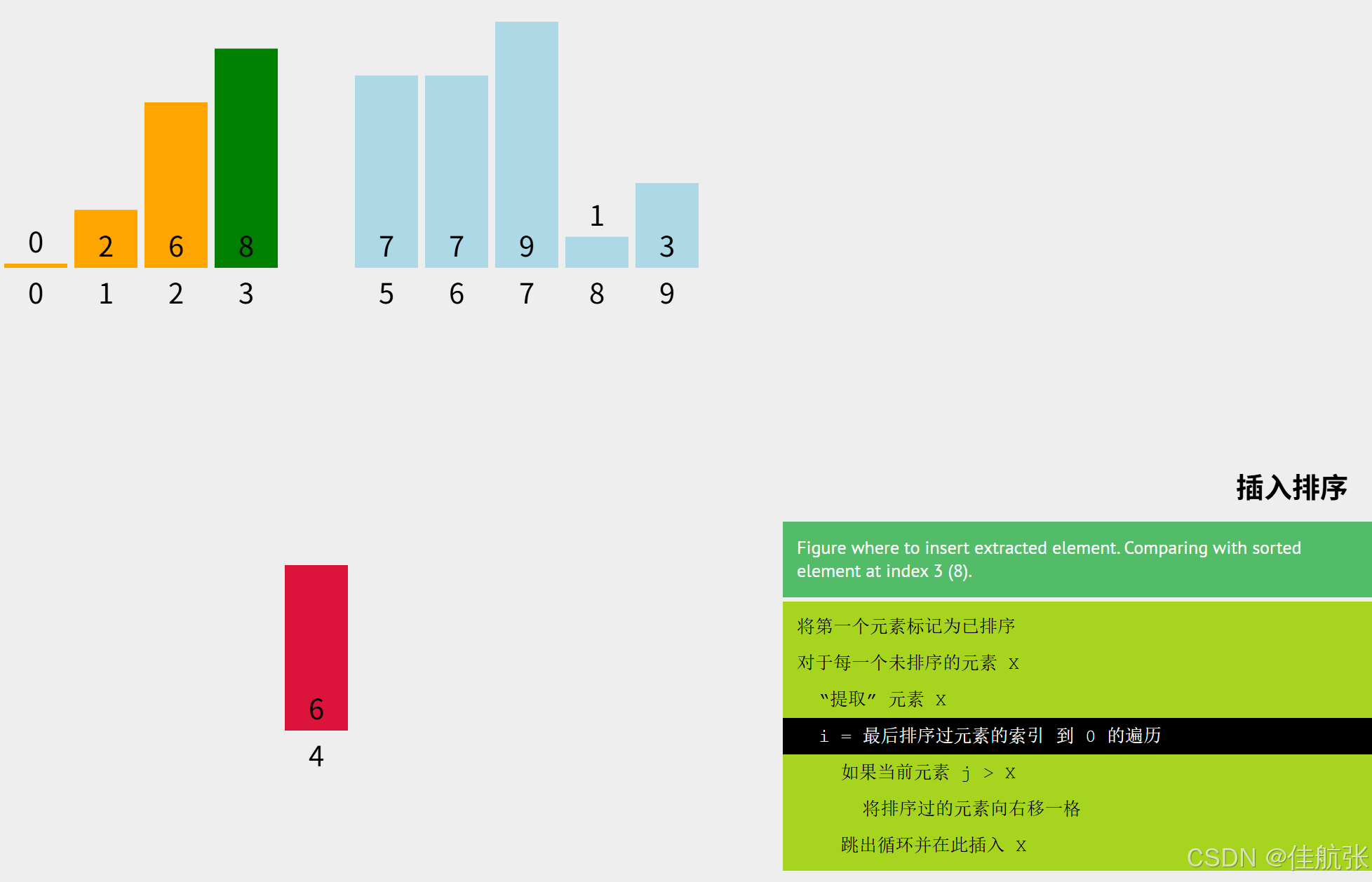
6先再与下标2对应的6比较,arr[2] = 6, 不大于6,所以当前要排序的这个6的位置已经确定了,不用再与下标1和下标0比了。因为有前面的插入排序,可以确定已排序区是升序的。6不小于下标2对应的元素,则一定不小于下标1和0对应的元素。此次插入,体现了直接插入排序算法对相同元素情况时的处理。即,直接插入排序不会改变数组中相同元素的相对位置。
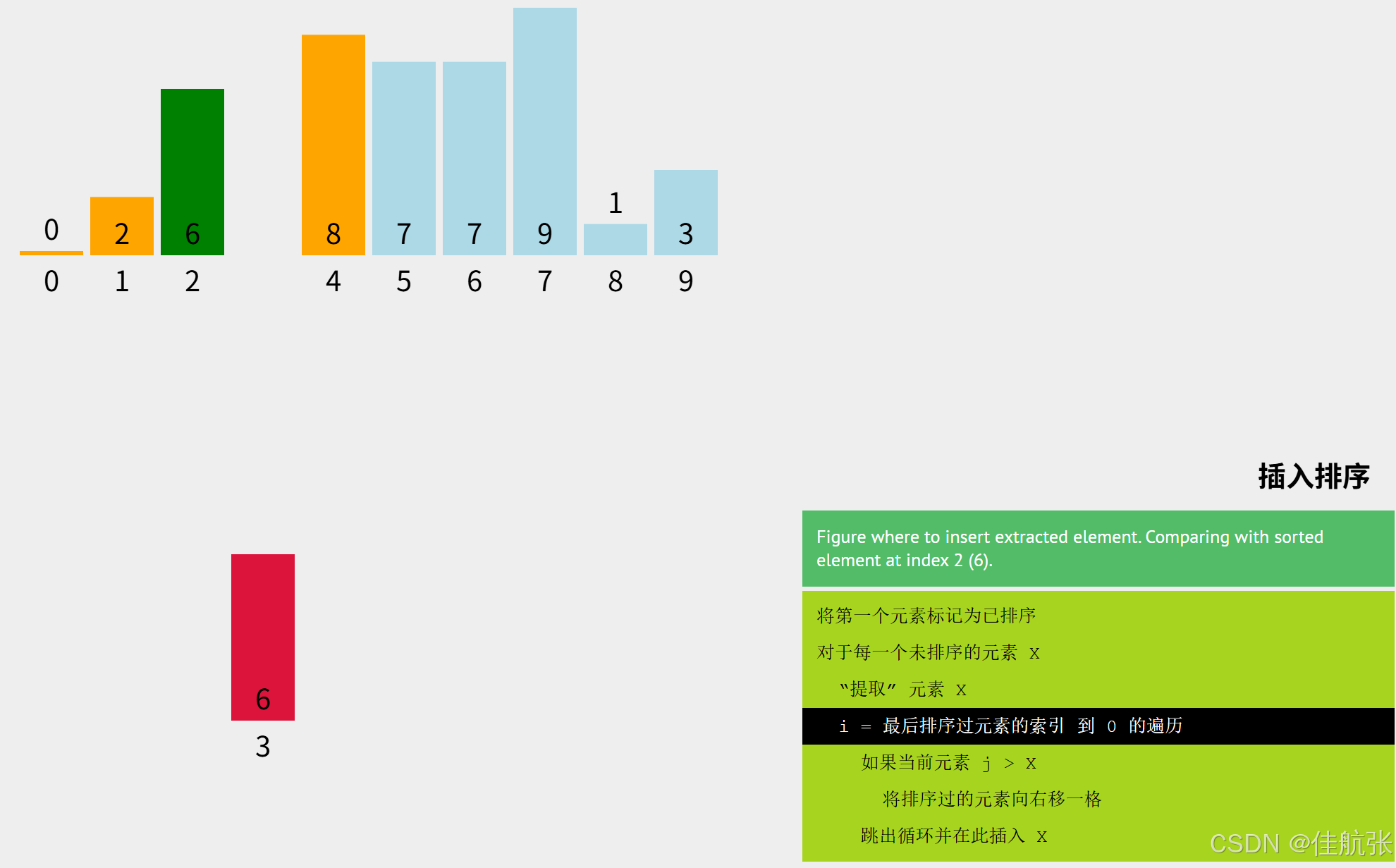
将6插入,然后继续下面的排序。
接下来的排序就比较相似了,都遵循流程图。最终排序完成后的数组如下:
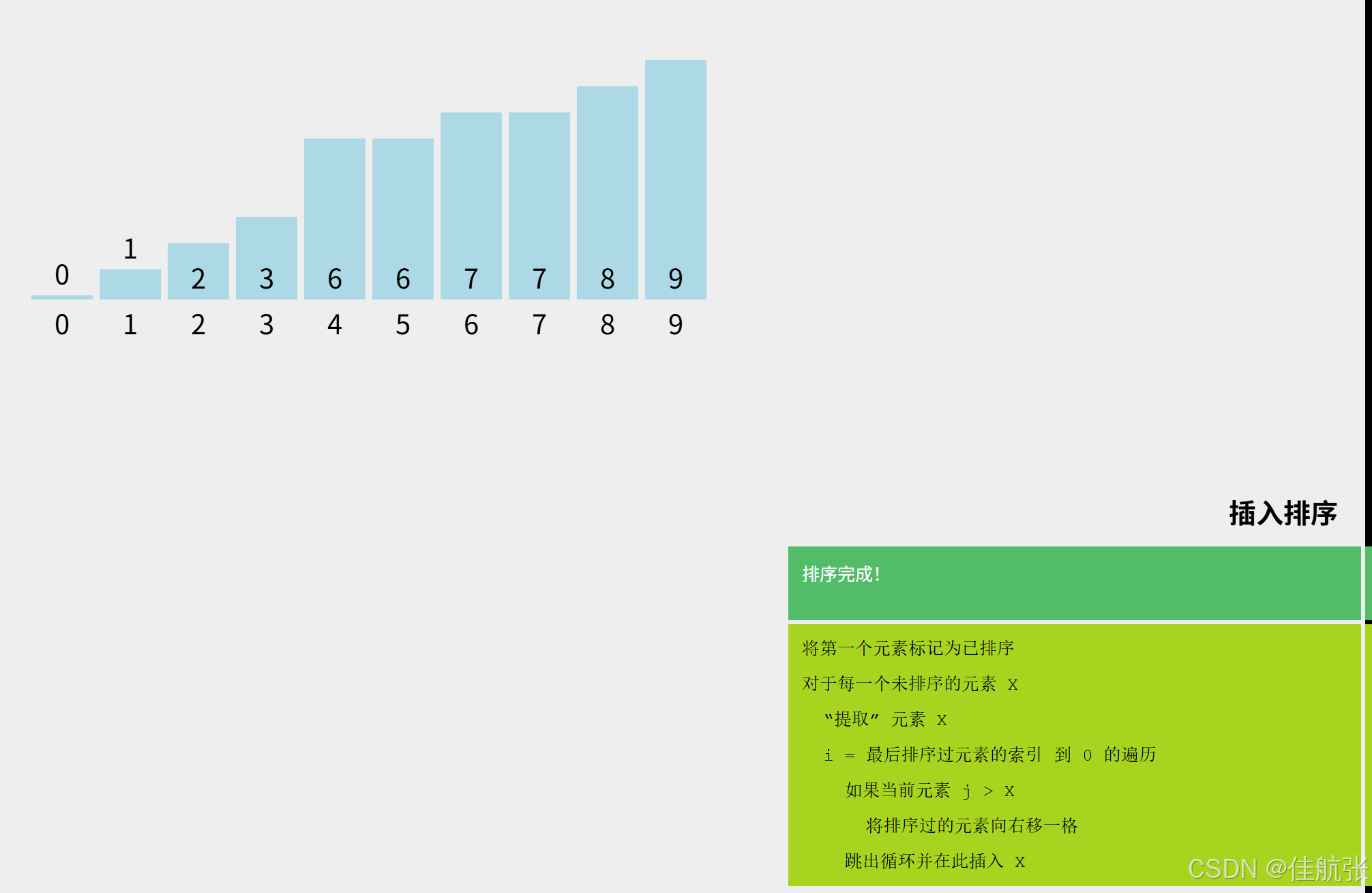
算法特点
时间复杂度分析
| 情况 | 时间复杂度 | 说明 |
|---|---|---|
| 最好情况 | O(n) | 当输入数组已经有序时,每次插入只需比较一次(因为新元素大于已排序序列的最后一个元素),不需要移动。总共需要比较n-1次,因此时间复杂度为O(n)。 |
| 最坏情况 | O(n²) | 当输入数组完全逆序时,每次插入都需要将新元素与已排序序列中的所有元素比较并移动。对于第i个元素(从1开始),需要比较和移动i次(即从i-1到0)。总比较和移动次数为:1 + 2 + ... + (n-1) = n(n-1)/2,因此时间复杂度为O(n²)。 |
| 平均情况 | O(n²) | 考虑到随机排列的数组,每个元素平均需要比较和移动的次数约为i/2(i为当前插入的位置),所以总次数约为n²/4,因此时间复杂度为O(n²)。 |
空间复杂度分析
| 复杂度 | 说明 |
|---|---|
| O(1) | 仅需常数级别额外空间(用于key和索引变量i,j),是原地排序算法 |
稳定性分析
| 特性 | 说明 |
|---|---|
| 稳定排序 | 当遇到相等元素时(arr[j] == key),由于条件arr[j] > key不成立,循环停止,新元素插入在相等元素之后,保持了原有顺序 |
关键特性总结
| 维度 | 特性 |
|---|---|
| 时间复杂度 | 依赖输入数据的有序程度 |
| 空间效率 | 最优的原地排序算法之一 |
| 稳定性 | 保持相等元素相对位置 |
| 适用场景 | 小数据集/部分有序数据 |
C语言实现
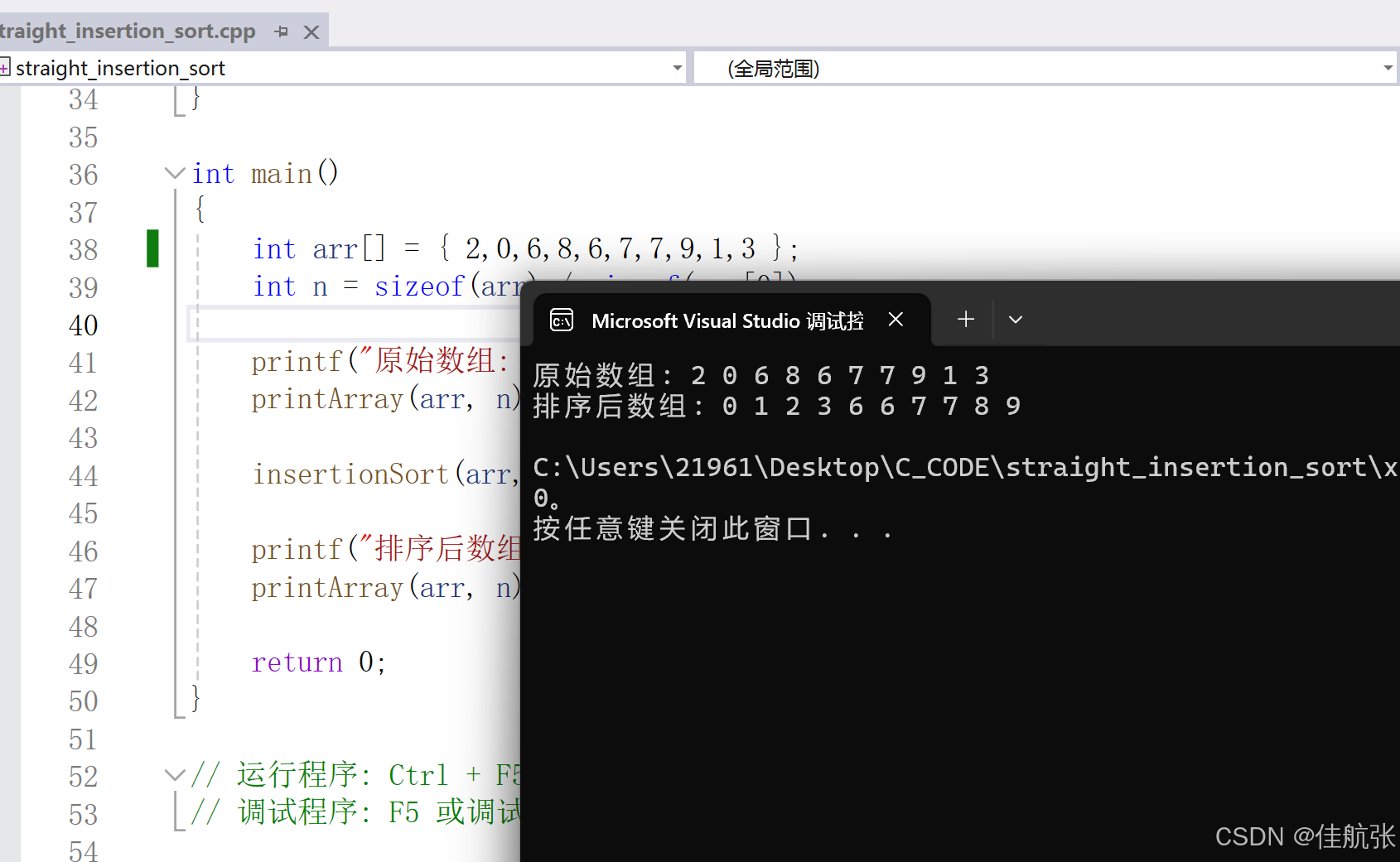
#include <stdio.h>// 直接插入排序函数
void insertionSort(int arr[], int n)
{for (int i = 1; i < n; i++) { // 从第二个元素开始int key = arr[i]; // 当前待插入元素int j = i - 1;// 将大于key的元素后移while (j >= 0 && arr[j] > key) {arr[j + 1] = arr[j]; // 元素后移j--;}arr[j + 1] = key; // 插入到正确位置}
}// 打印数组
void printArray(int arr[], int size)
{for (int i = 0; i < size; i++) {printf("%d ", arr[i]);}printf("\n");
}int main()
{int arr[] = {2,0,6,8,6,7,7,9,1,3};int n = sizeof(arr) / sizeof(arr[0]);printf("原始数组: ");printArray(arr, n);insertionSort(arr, n);printf("排序后数组: ");printArray(arr, n);return 0;
}程序输出