[CUDA] CUTLASS | `CuTe DSL` 创新
链接:https://docs.nvidia.com/cutlass/media/docs/cpp/quickstart.html
docs:CUTLASS
CUTLASS是面向NVIDIA GPU的高性能线性代数库,专注于**通用矩阵乘法(GEMM)**及相关运算。
该库提供丰富的C++模板抽象实现硬件级细粒度控制,同时配备*Python原生领域特定语言(DSL)*简化核函数开发。
支持多种数据类型实现混合精度计算,并包含收尾操作实现高效结果后处理。
架构
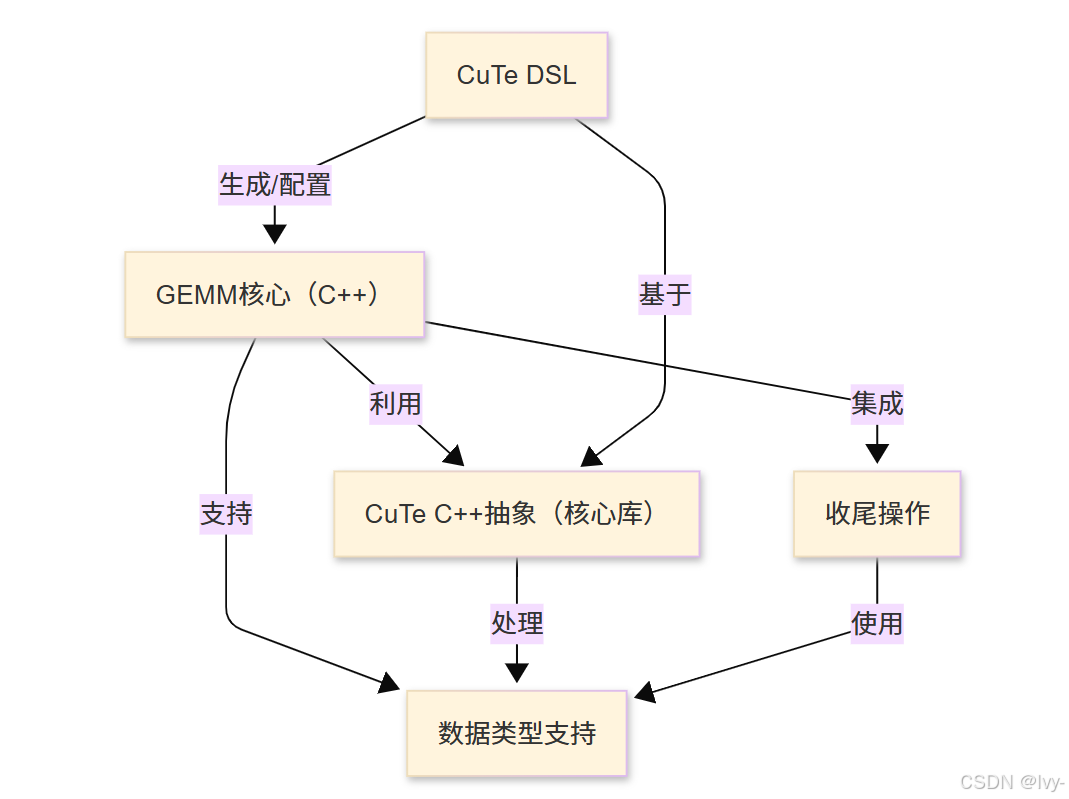
章节导航
- CuTe DSL
- GEMM核心(C++)
- CuTe C++抽象(核心库)
- 收尾操作
- 数据类型支持
CUTLASS 4.1.0
CUTLASS 面向CUDA的模块化抽象库集合,专注于实现高性能矩阵乘法(GEMM)及相关计算的全层次优化。该库通过层次化分解策略和智能数据移动机制,将复杂计算流程解耦为可复用的软件组件。
核心特性:
- 可定制计算原语:通过自定义分块尺寸、数据类型和算法策略,支持从线程级到设备级的并行化层次调优
- 跨架构支持:全面支持Volta/Turing/Ampere/Ada/Hopper/Blackwell架构的混合精度计算,涵盖:
- FP64/FP32/TF32/FP16/BF16等浮点格式
- 8位浮点类型(e5m2/e4m3)
- 块缩放数据类型(NVFP4/MXFP4/MXFP6/MXFP8)
- 窄位整数(4/8位有符号/无符号)
- 二进制1位数据类型(需硬件支持)
- 异步数据流:集成专用数据移动操作(异步拷贝)与乘累加原语
CUTLASS 4 更新
CuTe DSL 创新
新增Python原生编程接口,实现三大突破:
# CuTe DSL示例:Blackwell架构GEMM核函数
import cutlass_dsl as cdswith cds.BlockScope(threadblock_shape=(128, 128, 32)):A = cds.Tensor(shape=(M, K), dtype=cds.float16, layout=cds.RowMajor)B = cds.Tensor(shape=(K, N), dtype=cds.float16, layout=cds.ColumnMajor)C = cds.Tensor(shape=(M, N), dtype=cds.float32)cds.gemm(A, B, C, mma_instruction=cds.HopperTensorCore)cds.epilogue_add(beta=0.5, activation=cds.ReLU)
优势对比:
| 特性 | C++模板方案 | CuTe DSL方案 |
|---|---|---|
| 编译时间 | 小时级 | 分钟级 |
| 学习曲线 | 需C++17高级特性掌握 | Python基础即可 |
| 框架集成 | 需胶水代码 | 原生对接深度学习框架 |
| 元编程复杂度 | 复杂模板元编程 | 声明式编程 |
4.1版本新特性
-
架构支持扩展:
- 新增aarch64架构支持(GB200系统可用
pip install nvidia-cutlass-dsl) - Blackwell SM100持久化块缩放GEMM静态调度
- 新增aarch64架构支持(GB200系统可用
-
核心功能增强:
# 编译参数示例(Blackwell SM100a架构) cmake .. -DCUTLASS_NVCC_ARCHS="100a" -DCUTLASS_LIBRARY_KERNELS=cutlass_tensorop_blackwell_* -
重要更新:
- 优化Blackwell SM100注意力核函数(示例77)
- 支持FMHA反向核函数变长序列
- 重构CuTe底层架构(ArithTuple/ScaledBasis)
性能表现
在NVIDIA Blackwell SM100架构GPU上的基准测试:
| 数据类型组合 | 理论峰值利用率 |
|---|---|
| FP16输入/FP32累加 | 98.7% |
| BF16输入/FP32累加 | 97.2% |
| FP8输入/FP32累加 | 95.8% |
| MXFP6输入/FP32累加 | 93.4% |
CuTe核心库
CuTe作为CUTLASS 3.0+的核心基础架构,通过多维布局描述实现高效张量操作:
// CuTe布局组合示例(混合行优先+列优先)
auto layoutA = make_layout(make_shape(128,64), make_stride(64,1)); // 行主序
auto layoutB = make_layout(make_shape(64,256),make_stride(1,64)); // 列主序
auto composed_layout = product_layout(layoutA, layoutB);
关键组件:
- Layout代数:支持布局的数学运算(乘积/拼接/转置)
- Tensor抽象:统一管理数据类型/形状/内存空间
- 硬件原子操作:封装MMA/Copy等底层指令
兼容性
基础环境
| 组件 | 最低要求 | 推荐配置 |
|---|---|---|
| GPU架构 | Volta (SM7.0) | Blackwell (SM10.0) |
| CUDA工具包 | 11.4 | 12.8 |
| 主机编译器 | C++17兼容 | GCC ≥9.3 |
操作系统支持
| 系统版本 | 已验证编译器 |
|---|---|
| Ubuntu 18.04 | GCC 7.5 |
| Ubuntu 20.04 | GCC 10.3 |
| Ubuntu 22.04 | GCC 11.2 |
构建指南
基础编译流程
# 环境配置
export CUDACXX=/usr/local/cuda-12.8/bin/nvcc# 创建构建目录
mkdir build && cd build# 配置编译参数(Ampere架构示例)
cmake .. -DCUTLASS_NVCC_ARCHS=80 \-DCUTLASS_ENABLE_CUBLAS=ON \-DCUTLASS_ENABLE_CUDNN=OFF# 并行编译(16线程)
make cutlass_profiler -j16
环境变量CUDACXX指定NVIDIA CUDA编译器路径,确保系统能找到正确的nvcc编译器。创建独立构建目录build是标准做法,避免污染源码。
cmake配置阶段的关键参数:
-DCUTLASS_NVCC_ARCHS=80指定针对Ampere架构(如A100显卡)生成代码-DCUTLASS_ENABLE_CUBLAS=ON启用cuBLAS集成-DCUTLASS_ENABLE_CUDNN=OFF禁用cuDNN支持
make命令使用-j16参数启动16个线程并行编译,显著加速构建过程,重点构建cutlass_profiler性能分析工具。
高级优化策略
高级编译:
# 选择性编译GEMM核函数(Tensor Core)
cmake .. -DCUTLASS_LIBRARY_KERNELS=cutlass_tensorop_s*gemm_f16* # 编译卷积核函数子集
cmake .. -DCUTLASS_LIBRARY_KERNELS=cutlass_tensorop_s*fprop_optimized_f16
核函数选择编译
通过-DCUTLASS_LIBRARY_KERNELS参数实现精准控制:
cutlass_tensorop_s*gemm_f16*仅编译FP16精度的Tensor Core矩阵乘法核函数cutlass_tensorop_s*fprop_optimized_f16专门编译FP16精度的前向卷积优化核函数
这种选择性编译能大幅减少编译时间,特别适用于需要特定计算模式的场景。
星号*是通配符,匹配符合模式的所有核函数实现。
性能分析
Profiler关键参数示例:
# GEMM性能分析(FP16 Tensor Core)
./cutlass_profiler --operation=gemm \--m=4096 --n=4096 --k=4096 \--A=f16:row --B=f16:column \--accumulator-type=f32# 卷积性能分析(NHWC格式)
./cutlass_profiler --operation=conv2d \--n=8 --h=224 --w=224 --c=128 \--k=128 --r=3 --s=3
文档体系
https://docs.nvidia.com/cutlass/CHANGELOG.html
- 快速入门指南:基础构建与示例运行
- 功能白皮书:支持特性全景说明
- CUDA高效GEMM:CUDA GEMM优化方法论
- 架构设计文档:CUTLASS 3.x+设计哲学
- API参考手册:完整模板接口说明
提示:
- SM90a架构核函数需显式指定
-DCUTLASS_NVCC_ARCHS=90a - RTX 50系列(SM12x)与数据中心Blackwell(SM10x)二进制不兼容
第一章:CuTe DSL
欢迎来到cutlass的世界~
在本章,我们将通过探索CuTe DSL开启技术旅程,这个强大的工具旨在让高性能GPU代码编写变得更加简单直观。
高性能GPU编程的挑战
想象我们需要手工打造一辆超级跑车。
我们需要从原始金属开始锻造每个螺丝、螺栓和引擎部件。这种方式虽然能实现极致控制,但过程极其复杂耗时,且需要深厚的冶金学和机械工程知识。
用传统CUDA C++编写高性能GPU内核也面临类似挑战。
尽管能对硬件实现精细控制,但其复杂的语法、缓慢的编译速度,以及对底层GPU架构和C++元编程的深度要求,使得原型设计和迭代过程异常缓慢。
CuTe DSL的革新
CuTe DSL应运而生!基于强大的CuTe C++核心库
CuTe DSL(领域特定语言)提供了Python原生接口来编写高性能CUDA内核。这如同为赛车设计配备可视化工具——无需手工锻造每个部件,只需选择预优化组件进行组合,工具即可自动生成精细化蓝图。
CuTe DSL带来的革命性变化:
快速原型设计:无需冗长的C++编译周期即可验证想法直观开发体验:利用Python的简洁语法处理复杂GPU逻辑无损性能表现:生成与手工C++代码同等优化的GPU指令
本章目标是通过实际案例理解CuTe DSL的核心价值。
CuTe DSL技术基石
-
CuTe C++核心库:作为底层支撑,提供
Layout和Tensor等核心抽象,描述GPU数据的组织与操作方式。CuTe DSL本质上是这些C++能力的Python"遥控器"。 -
Python原生接口:直接使用Python语法编写GPU内核逻辑,支持标准控制流(if/for/while),自动转换为GPU可执行指令。
-
高阶抽象层:
- 布局系统:支持行列主序、分块模式等内存组织方式
- 张量操作:以
Pythonic方式处理多维数据结构 - 硬件级原语:调用
Tensor Core等专用计算单元实现峰值性能
首个CuTe DSL核函数:逐元素加法
import cutlass.cute as cute
import torch # 使用PyTorch管理GPU内存@cute.kernel
def add_kernel(a, b, c, N):# 计算全局线程索引idx = cute.block_idx_x() * cute.block_dim_x() + cute.thread_idx_x()# 边界检查if idx < N:c[idx] = a[idx] + b[idx] # 逐元素相加# 数据准备
N = 1000
a_torch = torch.rand(N, dtype=torch.float32, device='cuda')
b_torch = torch.rand(N, dtype=torch.float32, device='cuda')
c_torch = torch.zeros(N, dtype=torch.float32, device='cuda')# 内存视图转换
a_cute = cute.as_ptr(a_torch)
b_cute = cute.as_ptr(b_torch)
c_cute = cute.as_ptr(c_torch)# 计算执行配置
threads_per_block = 256
blocks_per_grid = (N + threads_per_block - 1) // threads_per_block# 内核启动
add_kernel[blocks_per_grid, threads_per_block](a_cute, b_cute, c_cute, N)# 结果验证
expected = a_torch + b_torch
assert torch.allclose(c_torch, expected), "结果验证失败"
print("计算验证通过!")
技术解析:
- 内核定义:
@cute.kernel装饰器将Python函数标记为GPU核函数 - 索引计算:通过
block_idx_x等函数实现CUDA线程网格映射 - 内存视图:
as_ptr将PyTorch张量转换为底层内存指针 - 执行配置:256线程/块的经典配置,自动计算所需块数量
- 启动语法:
kernel[grid,block](args)形式保持Python简洁性
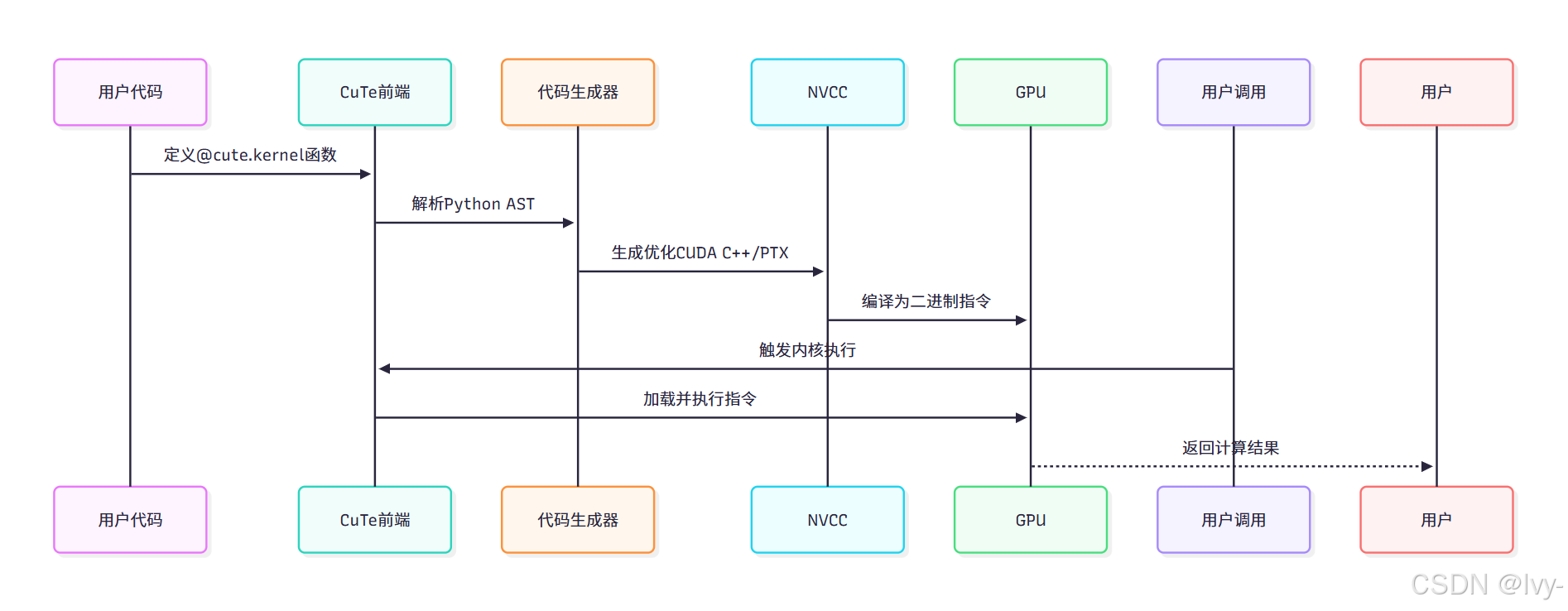
底层编译原理
CuTe DSL作为编译器前端实现自动化代码生成
⭕优势对比
| 特性 | 传统CUDA C++开发 | CuTe DSL方案 |
|---|---|---|
| 语法复杂度 | 需掌握C++模板元编程 | Python原生语法 |
| 编译速度 | 分钟级等待 | 秒级JIT即时编译 |
| 调试体验 | 需熟悉CUDA-GDB | 支持标准Python调试器 |
| 框架集成 | 需编写绑定代码 | 原生对接PyTorch生态 |
🎢深度学习框架 PyTorch vs TensorFlow
PyTorch 是一个灵活易用的深度学习框架,适合研究和快速实验,动态计算图让调试更直观。
TensorFlow 是一个功能强大的工业级深度学习框架,支持大规模部署和跨平台运行,静态计算图优化性能。
应用场景
- 快速算法原型:研究人员可
快速验证新并行算法设计 - 教学演示工具:直观展示
GPU线程模型与内存层次 - 生产级优化:性能工程师可基于DSL快速迭代优化方案
- 跨框架兼容:
无缝集成PyTorch/TensorFlow等生态
下一章将深入GEMM核函数(C++),解析传统实现方式为后续理解DSL优化奠定基础。