【数据结构】哈希扩展学习
目录
1. 位图
1.1 位图相关面试题
给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。(本题为腾讯/百度等公司出过的一个面试题)
1.2 位图的设计及实现
1.3 C++库中的位图 bitset
1.4 位图的优缺点
1.5 位图相关考察题目
• 给定100亿个整数,设计算法找到只出现一次的整数?
• 给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
• 一个文件有100亿个整数,1G内存,设计算法找到出现次数不超过2次的所有整数
2. 布隆过滤器
2.1 什么是布隆过滤器
2.2 布隆过滤器器误判率推导
2.3 布隆过滤器代码实现
2.4 布隆过滤器删除问题
2.5 布隆过滤器的应用
布隆过滤器在实际中的一些应用:
• 爬虫系统中URL去重:
• 垃圾邮件过滤:
• 预防缓存穿透
• 对数据库查询提效
3. 海量数据处理问题
3.1 10亿个整数里面求最大的前100个。
3.2 位图部分讲解的位图相关题目
3.3 给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?
3.4 给一个超过100G大小的log file, log中存着ip地址, 设计算法找到出现次数最多的ip地址?查找出现次数前10的ip地址
1. 位图
1.1 位图相关面试题
给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。(本题为腾讯/百度等公司出过的一个面试题)
解题思路1:暴力遍历,时间复杂度O(N),太慢
解题思路2:排序+二分查找。时间复杂度消耗 O(N*logN) + O(logN)
深入分析:解题思路2是否可行,思路二排序的消耗是O(N*logN),不过由于数据只需要排一次,平均下来时间上的消耗其实主要是O(logN)。思路二我们发现其实时间上的消耗合适了,本思路的问题关键在于空间上,我们先算算40亿个数据大概需要多少内存。1G = 1024MB = 1024*1024KB = 1024*1024*1024Byte 约等于10亿多Byte那么40亿个整数约等于16G,这说明40亿个数是无法直接放到内存中的,只能放到硬盘文件中。而二分查找只能对内存数组中的有序数据进行查找。所以思路二不合适。
解题思路3:数据是否在给定的整形数据中,结果是在或者不在,刚好是两种状态,那么可以使用一个二进制比特位来代表数据是否存在的信息,如果二进制比特位为1,代表存在,为0代表不存在。那么我们设计一个用二进制位表示数据是否存在的数据结构,这个数据结构就叫位图。
1.2 位图的设计及实现
位图本质是一个直接定址法的哈希表,每个整型值映射一个bit位,数位上为0,表示映射的整数不存在;数位上为1,表示映射的整数存在。位图提供控制这个bit的相关接口。
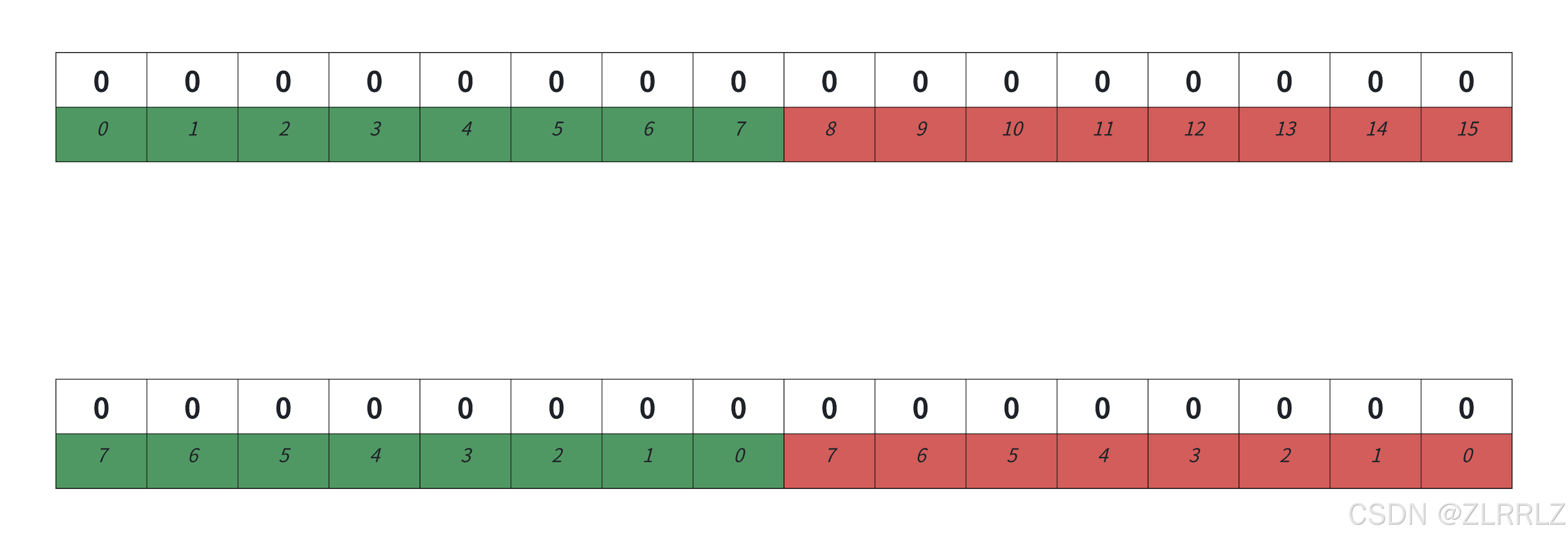
实现中需要注意的是,C/C++没有对应二进制位的类型,只能看int/char这样整形类型,我们再通过位运算去控制对应的比特位。
比如我们数据存到vector<int>中,相当于每个int值映射对应的32个值,比如第一个整形映射0-31对应的位,第二个整形映射32-63对应的位,后面的以此类推,那么来了一个整形值x,i = x / 32;j = x % 32;计算出x映射的值在vector的第i个整形数据的第j位。

这里需要特别说明的是,虽然底层数据存储上有大小端之分,但是这里我们可以忽略底层上的差异,在实现位图时所使用的位运算,如左移是指低位向高位移动,右移是指高位向低位移动,不是空间方位上的描述。所以这里大小端对于结果没有影响。
解决给40亿个不重复的无符号整数,查找一个数据的问题,我们要给位图开2^32个位,注意不能开40亿个位,因为映射是按大小映射的,我们要按数据大小范围开空间,范围是是0-2^32-1,所以需要开2^32个位。然后从文件中依次读取每个set到位图中,然后数据存在,映射位为1;数据不存在,映射位为0。就可以快速判断一个值是否在这40亿个数中了。



namespace zlr
{// N是需要多少比特位template<size_t N>class bitset{public:bitset(){//_bits.resize(N/32+1, 0);_bits.resize((N >> 5) + 1, 0);}// 把x映射的位标记成1void set(size_t x){size_t i = x / 32;size_t j = x % 32;_bits[i] |= (1 << j);}// 把x映射的位标记成0void reset(size_t x){size_t i = x / 32;size_t j = x % 32;_bits[i] &= ~(1 << j);}//用于测试,把对应数位结果返回。bool test(size_t x){size_t i = x / 32;size_t j = x % 32;return _bits[i] & (1 << j);}private:vector<int> _bits;};
}int main()
{zlr::bitset<100> bs1;bs1.set(50);bs1.set(30);bs1.set(90);for (size_t i = 0; i < 100; i++){if (bs1.test(i)){cout << i << "->" << "在" << endl;}else{cout << i << "->" << "不在" << endl;}}bs1.reset(90);bs1.set(91);cout << endl << endl;for (size_t i = 0; i < 100; i++){if (bs1.test(i)){cout << i << "->" << "在" << endl;}else{cout << i << "->" << "不在" << endl;}}// 开2^32个位的位图的不同表示方式。//zlr::bitset<-1> bs2;//这里模版我们给的参数是size_t,-1会自动转成一个非常大的值//zlr::bitset<UINT_MAX> bs3;//zlr::bitset<0xffffffff> bs4;return 0;
}1.3 C++库中的位图 bitset
bitset - C++ Reference
可以看到核心接口还是set/reset/和test,基本的实现与上位差不多,当然后面还实现了一些其他接口,如to_string将位图按位转成01字符串,再包括operator[]等支持像数组一样控制一个位的实现。
不过注意的是库中的bitset是开辟的空间是静态的,在栈桢上,如果一次性开辟数据过大会报错,如果我们要开辟大位图,要手动new开辟动态的位图。
1.4 位图的优缺点
优点:增删查改快,只需要进行位级的操作,节省空间
缺点:与直接定址法类似,因为是数据直接映射,因此只适用于整形
1.5 位图相关考察题目
• 给定100亿个整数,设计算法找到只出现一次的整数?
虽然是100亿个数,但是还是按范围开空间,所以还是开2^32个位,跟前面的题目是一样的
• 给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
把数据读出来,分别放到两个位图,依次遍历,同时在两个位图的值就是交集
• 一个文件有100亿个整数,1G内存,设计算法找到出现次数不超过2次的所有整数
之前我们是标记在不在,只需要一个位即可,这里要统计出现次数不超过2次的,可以每个值用两个位标记即可,00代表出现0次,01代表出现1次,10代表出现2次,11代表出现2次以上。最后统计出所有01和10标记的值即可。但是这里如果我们在原有的实现上取改动,改成两位为一组的设计,设计较为麻烦,这里我们封装两个位图为一个新位图。
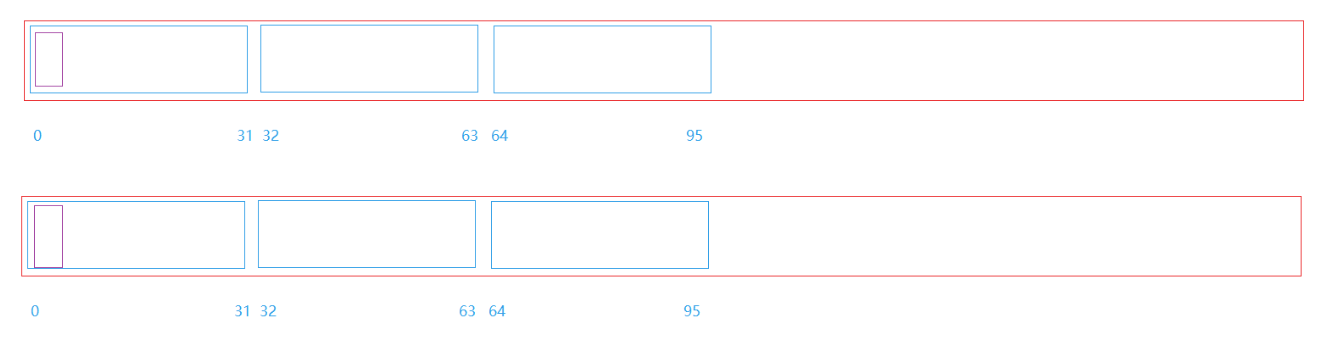
第一个位图对应位为0,第二个位图对应位为0,代表00;第一个位图对应位为0,第二个位图对应位为1,代表01;第一个位图对应位为1,第二个位图对应位为1,代表出现2次以上。
// 模拟位图找交集
void test_bitset1()
{int a1[] = { 5,7,9,2,5,99,5,5,7,5,3,9,2,55,1,5,6 };int a2[] = { 5,3,5,99,6,99,33,66 };bitset<100> bs1;bitset<100> bs2;for (auto e : a1){bs1.set(e);}for (auto e : a2){bs2.set(e);}for (size_t i = 0; i < 100; i++){if (bs1.test(i) && bs2.test(i)){cout << i << endl;}}
}//题二和题三本质都是统计数据出现的次数
//我们可以用两个位图封装成一个来解决。
template<size_t N>
class twobitset
{
public:void set(size_t x){bool bit1 = _bs1.test(x);bool bit2 = _bs2.test(x);if (!bit1 && !bit2) // 00->01{_bs2.set(x);}else if (!bit1 && bit2) // 01->10{_bs1.set(x);_bs2.reset(x);}else if (bit1 && !bit2) // 10->11{_bs1.set(x);_bs2.set(x);}}// 返回0 出现0次数// 返回1 出现1次数// 返回2 出现2次数// 返回3 出现2次及以上int get_count(size_t x){bool bit1 = _bs1.test(x);bool bit2 = _bs2.test(x);if (!bit1 && !bit2){return 0;}else if (!bit1 && bit2){return 1;}else if (bit1 && !bit2){return 2;}else{return 3;}}
private:bitset<N> _bs1;bitset<N> _bs2;
};void test_bitset2()
{bit::twobitset<100> tbs;int a[] = { 5,7,9,2,5,99,5,5,7,5,3,9,2,55,1,5,6,6,6,6,7,9 };for (auto e : a){tbs.set(e);}for (size_t i = 0; i < 100; ++i){//cout << i << "->" << tbs.get_count(i) << endl;if (tbs.get_count(i) == 1 || tbs.get_count(i) == 2){cout << i << endl;}}
}2. 布隆过滤器
2.1 什么是布隆过滤器
有一些场景下面,有大量数据需要判断是否存在,而这些数据不是整形,那么位图就不能使用了,使用红黑树/哈希表等内存空间可能不够。这些场景就需要布隆过滤器来解决。
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
与前面哈希文章的思路类似,针对位图无法处理非整形数据的问题,这里的解决思路就是通过哈希函数,将其他类型数据转成整形。
布隆过滤器这里跟哈希表不一样,它无法解决哈希冲突的,因为他压根就不存储这个值,布隆过滤器只标记映射的位。
布隆过滤器这我们根据一个数据确定它的映射位,在通过判断映射位是否为1来确定数据是否存在,但这里存在的问题是因为不存具体值,我们无法确定这个1是通过要查找的数据还是其他数据变成1的,所以诸如链地址法之类方法无法使用,冲突无法解决。
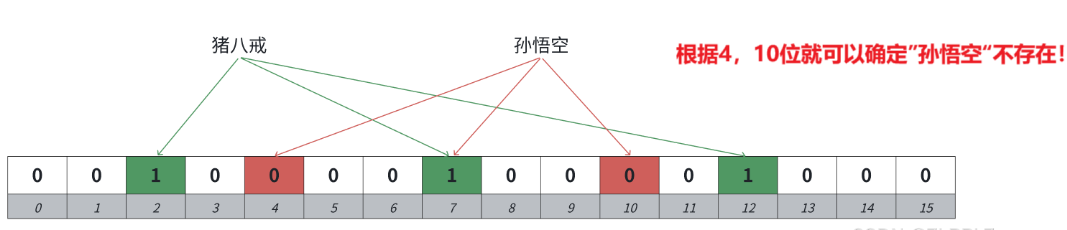
所以它的思路是尽可能降低哈希冲突来降低误判的可能。布隆过滤器的思路就是把一个key通过不同的哈希哈数同时映射到不同的位置上去。因为如果只映射一个位的话,冲突率会比较多,并且我们无法判断位上的1是怎么来的,但是如果key映射的几个位上不是1,那么该数一定不存在,即判断一个值key在是不准确的,判断一个值key不在是准确的。所以可以通过多个哈希函数映射多个位,降低冲突率。
2.2 布隆过滤器器误判率推导
说明:这个比较复杂,涉及概率论、极限、对数运算,求导函数等知识,有兴趣且数学功底比较好的可以看细看一下!
假设
m:布隆过滤器的bit长度。
n:插入过滤器的元素个数。
k:哈希函数的个数。布隆过滤器哈希函数等条件下某个位设置为1的概率:
布隆过滤器哈希函数等条件下某个位设置不为1的概率:
在经过k次哈希后,某个位置依旧不为1的概率:
根据极限公式:
添加n个元素某个位置不置为1的概率:
添加n个元素某个位置置为1的概率:
查询一个元素,k次hash后误判的概率为都命中1的概率:
结论:
布隆过滤器的误判率为:
由误判率公式可知,在k一定的情况下,当n增加时,误判率增加,m增加时,误判率减少。
在m和n一定,在对误判率公式求导,误判率尽可能小的情况下,可以得到hash函数个数:
时误判率最低。
期望的误判率p和插入数据个数n确定的情况下,再把上面的公式带入误判率公式可以得到,通过期望的误判率和插入数据个数n得到bit长度:
以上两个公式的推导过程尤其复杂,这里放两篇博客链接布隆过滤器(Bloom Filter)- 原理、实现和推导_布隆过滤器原理-CSDN博客和[布隆过滤器BloomFilter] 举例说明+证明推导_bloom filter 最佳hash函数数量 推导-CSDN博客
2.3 布隆过滤器代码实现
比起位图,布隆过滤器只是多了多个哈希表映射这一步,哈希表映射完后再设置对应数位即可,哈希函数从下方连接中选取较优的使用。
各种字符串Hash函数 - clq - 博客园
struct HashFuncBKDR
{/// @detail 本 算法由于在Brian Kernighan与Dennis Ritchie的《The CProgramming Language》// 一书被展示而得 名,是一种简单快捷的hash算法,也是Java目前采用的字符串的Hash算法累乘因子为31。size_t operator()(const string& s){size_t hash = 0;for (auto ch : s){hash *= 31;hash += ch;}return hash;}
};
struct HashFuncAP
{// 由Arash Partow发明的一种hash算法。size_t operator()(const string& s){size_t hash = 0;for (size_t i = 0; i < s.size(); i++){if ((i & 1) == 0) // 偶数位字符{hash ^= ((hash << 7) ^ (s[i]) ^ (hash >> 3));}else // 奇数位字符{hash ^= (~((hash << 11) ^ (s[i]) ^ (hash >>5)));}}return hash;}
};
struct HashFuncDJB
{// 由Daniel J. Bernstein教授发明的一种hash算法。size_t operator()(const string& s){size_t hash = 5381;for (auto ch : s){hash = hash * 33 ^ ch;}return hash;}
};template<size_t N,size_t X = 6,class K = string,class Hash1 = HashFuncBKDR,class Hash2 = HashFuncAP,class Hash3 = HashFuncDJB>
class BloomFilter
{
public:void Set(const K& key){size_t hash1 = Hash1()(key) % M;size_t hash2 = Hash2()(key) % M;size_t hash3 = Hash3()(key) % M;_bs.set(hash1);_bs.set(hash2);_bs.set(hash3);}bool Test(const K& key){size_t hash1 = Hash1()(key) % M;if (_bs.test(hash1) == false)return false;size_t hash2 = Hash2()(key) % M;if (_bs.test(hash2) == false)return false;size_t hash3 = Hash3()(key) % M;if (_bs.test(hash3) == false)return false;return true; // 存在误判(有可能3个位都是跟别人冲突的,所以误判)}// 获取公式计算出的误判率double getFalseProbability(){double p = pow((1.0 - pow(2.71, -3.0 / X)), 3.0);return p;}private:static const size_t M = X * N;// 我们实现位图是用vector,也就是堆上开的空间bit::bitset<M> _bs;//std::bitset<M> _bs;// vs下std的位图是开的静态数组,M太大会存在崩的问题// 解决方案就是bitset对象整体new一下,空间就开到堆上了//std::bitset<M>* _bs = new std::bitset<M>;
};//测试代码
void TestBloomFilter1()
{string strs[] = { "百度","字节","腾讯" };BloomFilter<10> bf;for (auto& s : strs){bf.Set(s);}for (auto& s : strs){cout << bf.Test(s) << endl;}for (auto& s : strs){cout << bf.Test(s + 'a') << endl;}cout << bf.Test("摆渡") << endl;cout << bf.Test("百渡") << endl;
}void TestBloomFilter2()
{srand(time(0));const size_t N = 10000000;BloomFilter<N> bf;//BloomFilter<N, 3> bf;//BloomFilter<N, 10> bf;std::vector<std::string> v1;std::string url = "https://www.cnblogs.com/-clq / archive / 2012 / 05 / 31 / 2528153.html";//std::string url = "https://www.baidu.com/s?ie=utf-8 & f = 8 & rsv_bp = 1 & rsv_idx = 1 & tn = 65081411_1_oem_dg & wd = ln2 & fenlei = 256 & rsv_pq = 0x8d9962630072789f & rsv_t = ceda1rulSdBxDLjBdX4484KaopD % 2BzBFgV1uZn4271RV0PonRFJm0i5xAJ % 2FDo & rqlang = en & rsv_enter = 1 & rsv_dl = ib & rsv_sug3 = 3 & rsv_sug1 = 2 & rsv_sug7 = 100 & rsv_sug2 =0 & rsv_btype = i & inputT = 330 & rsv_sug4 = 2535";//std::string url = "猪八戒";for (size_t i = 0; i < N; ++i){v1.push_back(url + std::to_string(i));}for (auto& str : v1){bf.Set(str);}// v2跟v1是相似字符串集(前缀一样),但是后缀不一样v1.clear();for (size_t i = 0; i < N; ++i){std::string urlstr = url;urlstr += std::to_string(9999999 + i);v1.push_back(urlstr);}size_t n2 = 0;for (auto& str : v1){if (bf.Test(str)) // 误判{++n2;}}cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;// 不相似字符串集 前缀后缀都不一样v1.clear();for (size_t i = 0; i < N; ++i){//string url = "zhihu.com";string url = "孙悟空";url += std::to_string(i + rand());v1.push_back(url);}size_t n3 = 0;for (auto& str : v1){if (bf.Test(str)){++n3;}}cout << "不相似字符串误判率:" << (double)n3 / (double)N << endl;cout << "公式计算出的误判率:" << bf.getFalseProbability() << endl;
}
int main()
{TestBloomFilter2();return 0;
}2.4 布隆过滤器删除问题
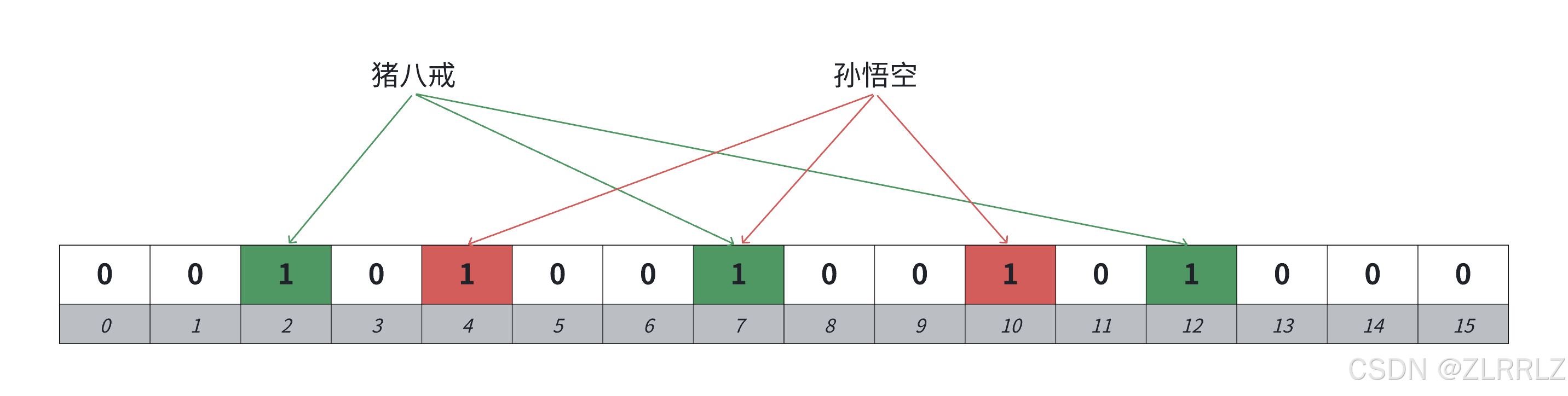
布隆过滤器默认是不支持删除的,因为比如"猪八戒“和”孙悟空“都映射在布隆过滤器中,他们映射的位有一个位是共同映射的(冲突的),如果我们把孙悟空删掉,那么再去查找“猪八戒”会查找不到,因为那么“猪八戒”间接被删掉了。
解决方案:可以考虑计数标记的方式,一个位置用多个位标记,记录映射这个位的计数值,删除时,仅仅减减计数,那么就可以某种程度支持删除。但是这个方案也有缺陷,如果一个值不在布隆过滤器中,我们去删除,减减了映射位的计数,那么会影响已存在的值,也就是说,一个确定存在的值,可能会变成不存在,这里就很坑。
当然也有人提出,我们可以考虑计数方式支持删除,但是定期重建一下布隆过滤器,这样也是一种思路。
2.5 布隆过滤器的应用
首先我们分析一下布隆过滤器的优缺点:
优点:效率高,节省空间,相比位图,可以适用于各种类型的标记过滤
缺点:存在误判(在是不准确的,不在是准确的),不好支持删除
布隆过滤器在实际中的一些应用:
• 爬虫系统中URL去重:
在爬虫系统中,因为网址间往往会出现互相嵌套的情况,为了避免重复爬取相同的URL,可以使用布隆过滤器来进行URL去重。爬取到的URL可以通过布隆过滤器进行判断,已经存在的URL则可以直接忽略,避免重复的网络请求和数据处理。
• 垃圾邮件过滤:
在垃圾邮件过滤系统中,布隆过滤器可以用来判断邮件是否是垃圾邮件。系统可以将已知的垃圾邮件的特征信息存储在布隆过滤器中,当新的邮件到达时,可以通过布隆过滤器快速判断是否为垃圾邮件,从而提高过滤的效率。
• 预防缓存穿透
在分布式缓存系统中,布隆过滤器可以用来解决缓存穿透的问题。缓存穿透是指恶意用户请求一个不存在的数据,导致请求直接访问数据库,造成数据库压力过大。布隆过滤器可以先判断请求的数据是否存在于布隆过滤器中,如果不存在,直接返回不存在,避免对数据库的无效查询。
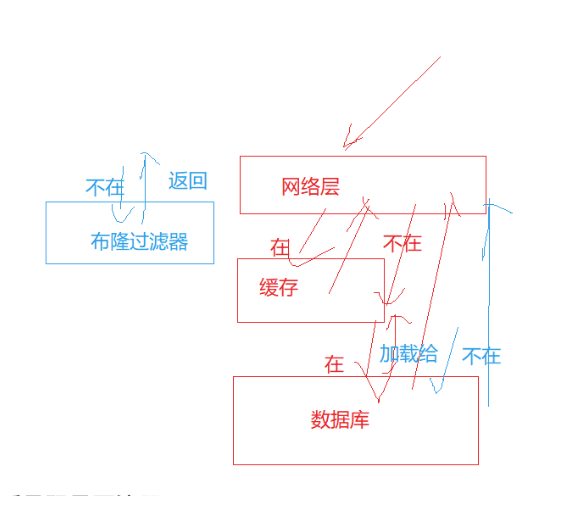
为了缓解数据库的压力,正常数据库会讲经常访问的热数据加载到缓存,方便下一次访问,如果下次查找的数据在缓存中,网络层直接从缓存中拿数据,不用再访问数据库,如果不在缓存,再访问数据库拿数据,拿到后再将数据加载到缓存中(方便下次拿数据),在这个过程中如果一个数据不在数据库中的消耗是最大的,因为会讲缓存、数据库都遍历,但是却不会加载数据,下次访问依然可能发生这种情况。
所以如果人为恶意的查找一系列注定不在数据库中的数据,就会给数据库造成非常大的压力,而布隆过滤器就能很好的应对,加入布隆过滤器,网络层会先根据布隆过滤器判断数据是否存在数据库,如果不在,则直接退出,较好避免恶意数据攻击。
• 对数据库查询提效
在数据库中,布隆过滤器可以用来加速查询操作。
例如:一个app要快速判断一个电话号码是否注册过,可以使用布隆过滤器来判断一个用户电话号码是否存在于表中,如果不存在,可以直接返回不存在,避免对数据库进行无用的查询操作。如果在,再去数据库查询进行二次确认。
3. 海量数据处理问题
3.1 10亿个整数里面求最大的前100个。
经典topk问题,用堆解决,这个我们数据结构初阶堆文章具体讲解过
3.2 位图部分讲解的位图相关题目
3.3 给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交
集?
分析:假设平均每个query字符串50byte,100亿个query就是5000亿byte,约等于500G(1G 约等于10亿多Byte)
哈希表/红黑树等数据结构肯定是无能为力的。
解决方案1:布隆过滤器这个首先可以用布隆过滤器解决,一个文件中的query放进布隆过滤器,另一个文件依次查找,在的就是交集,问题就是找到交集不够准确,因为在的值可能是误判的,但是交集一定被找到了。
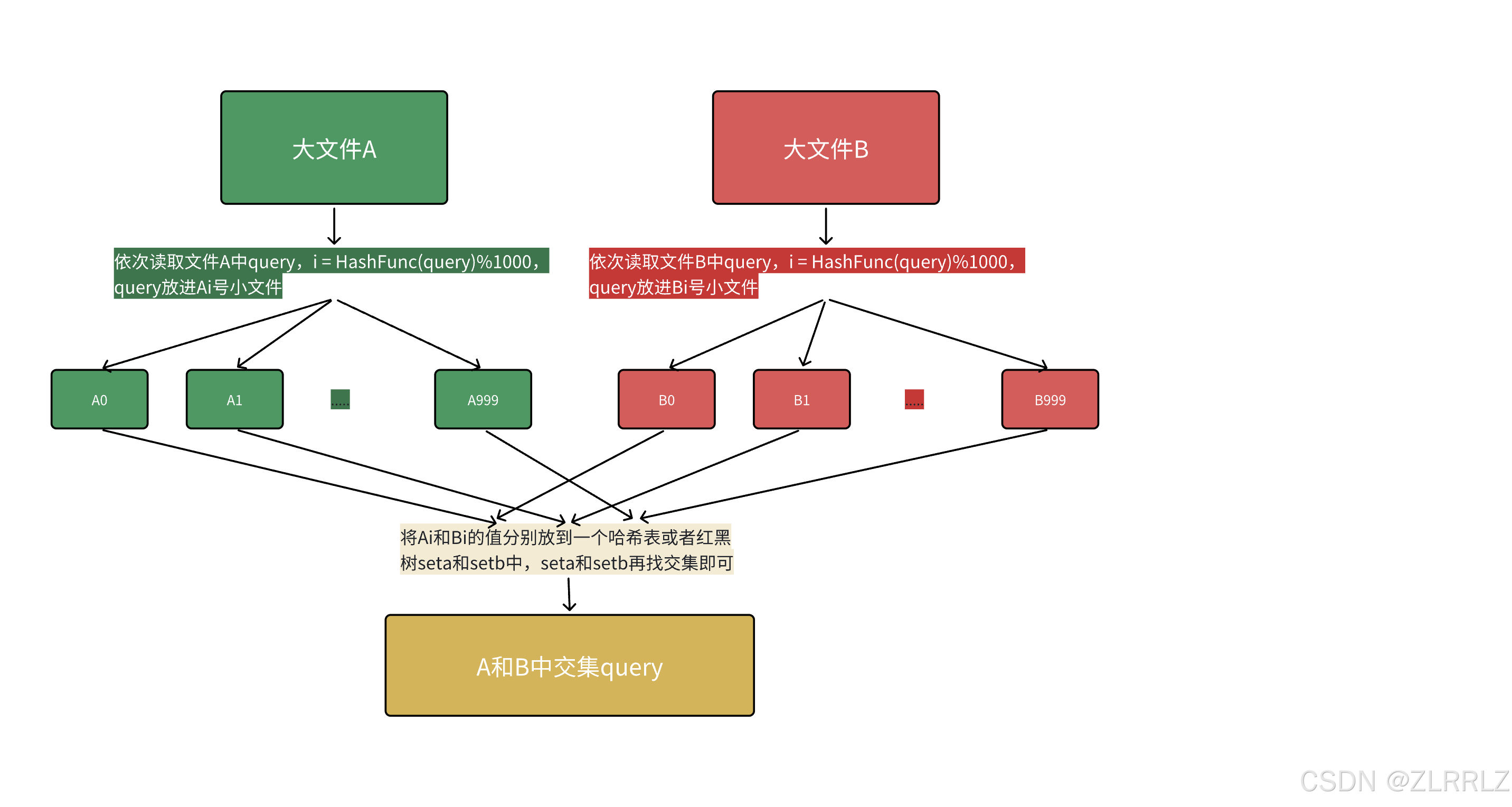
解决方案2:哈希切分
首先内存的访问速度远大于硬盘,大文件放到内存搞不定,那么我们可以考虑切分为小文件,再放进内存处理。但是不要平均切分,因为平均切分以后,大文件A和B相同的query存放的小文件编号可能不同,每个小文件都需要依次暴力遍历另一个大文件切分出来的小文件才可能找到相同的query,效率还是太低了。所以可以利用哈希切分,依次读取文件中query,i = HashFunc(query)%N,N为准备切分多少分小文件,N取决于切成多少份,内存能放下,query放进第i号小文件,这样A和B中相同的query算出的hash值i是一样的,相同的query就进入的编号相同的小文件就可以编号相同的文件直接找交集,不用交叉找,效率就提升了。
本质是相同的query在哈希切分过程中,一定进入的同一个小文件Ai和Bi,不可能出现A中的的query进入Ai,但是B中的相同query进入了和Bj的情况,所以对Ai和Bi进行求交集即可,不需要Ai和Bj求交集。(本段表述中i和j是不同的整数)
• 哈希切分的问题就是每个小文件不是均匀切分的,可能会导致某个小文件很大内存放不下。
我们细细分析一下某个小文件很大有两种情况:
1.这个小文件中大部分是同一个query,即大文件存在许多重复值。
2.这个小文件是有很多的不同query构成,本质是这些query冲突了。
针对情况1,其实放到内存的set中是可以放下的,因为set是去重的。
针对情况2,需要换个哈希函数继续二次哈希切分。所以本体我们遇到大于1G小文件,可以继续读到set中找交集,若set insert时抛出了异常(set插入数据抛异常只可能是申请内存失败了,不会有其他情况),那么就说明内存放不下是情况2,换个哈希函数进行二次哈希切分后再对应找交集。
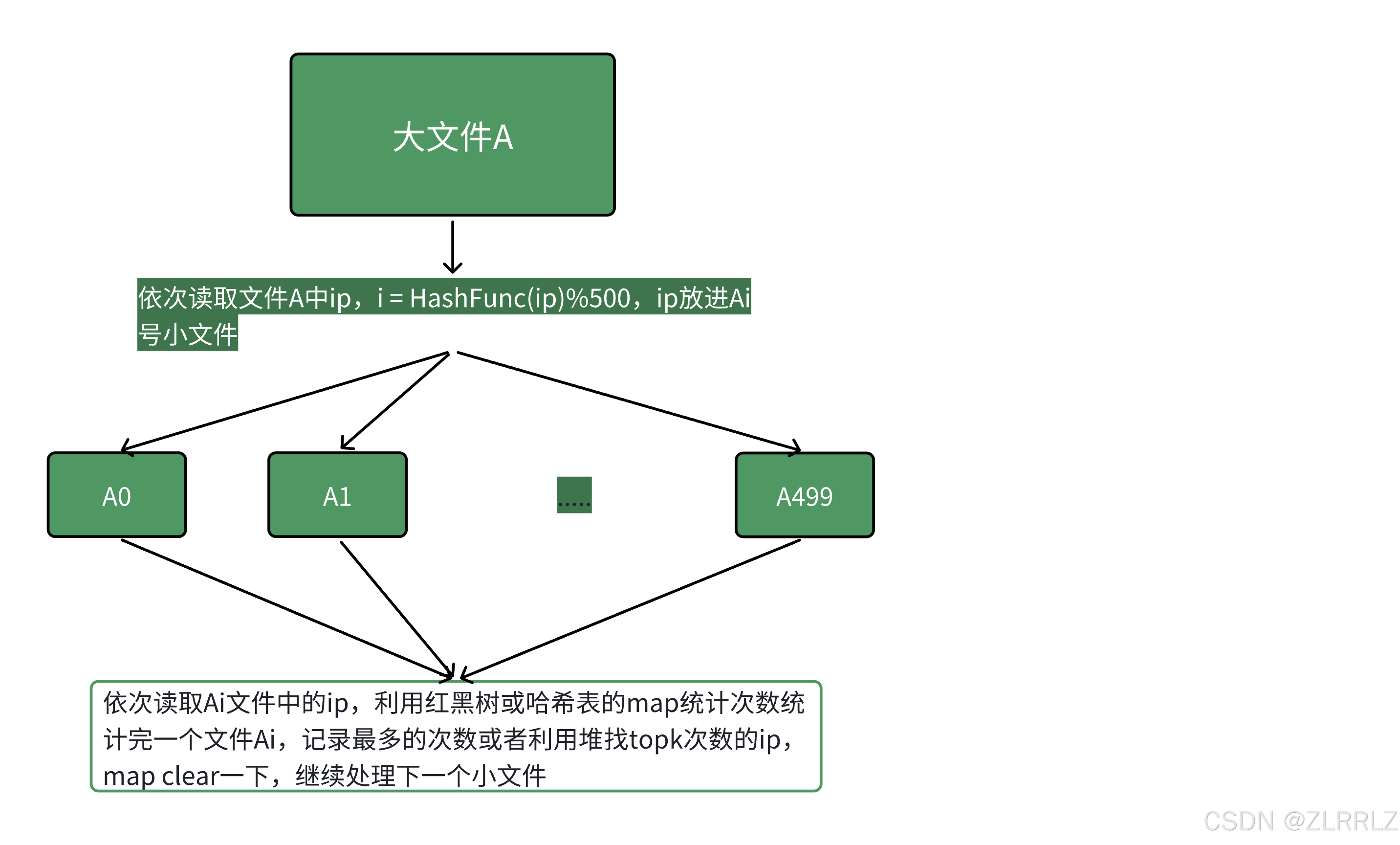
3.4 给一个超过100G大小的log file, log中存着ip地址, 设计算法找到出现次数最多的ip地址?查找出现次数前10的ip地址
本题的思路跟上题完全类似,依次读取文件A中query,i = HashFunc(query)%500,query放进Ai号小文件,然后依次用map<string, int>对每个Ai小文件统计ip次数,同时求出现次数最多的ip或者topkip。本质是相同的ip在哈希切分过程中,一定进入的同一个小文件Ai,不可能出现同一个ip进入Ai和Aj的情况,所以对Ai进行统计次数就是准确的ip次数。