(Arxiv-2025) CINEMA:通过基于MLLM的引导实现多主体一致性视频生成
CINEMA:通过基于MLLM的引导实现多主体一致性视频生成
paper是字节发布在Arxiv 2025的工作
paper title:CINEMA: Coherent Multi-Subject Video Generation via
MLLM-Based Guidance
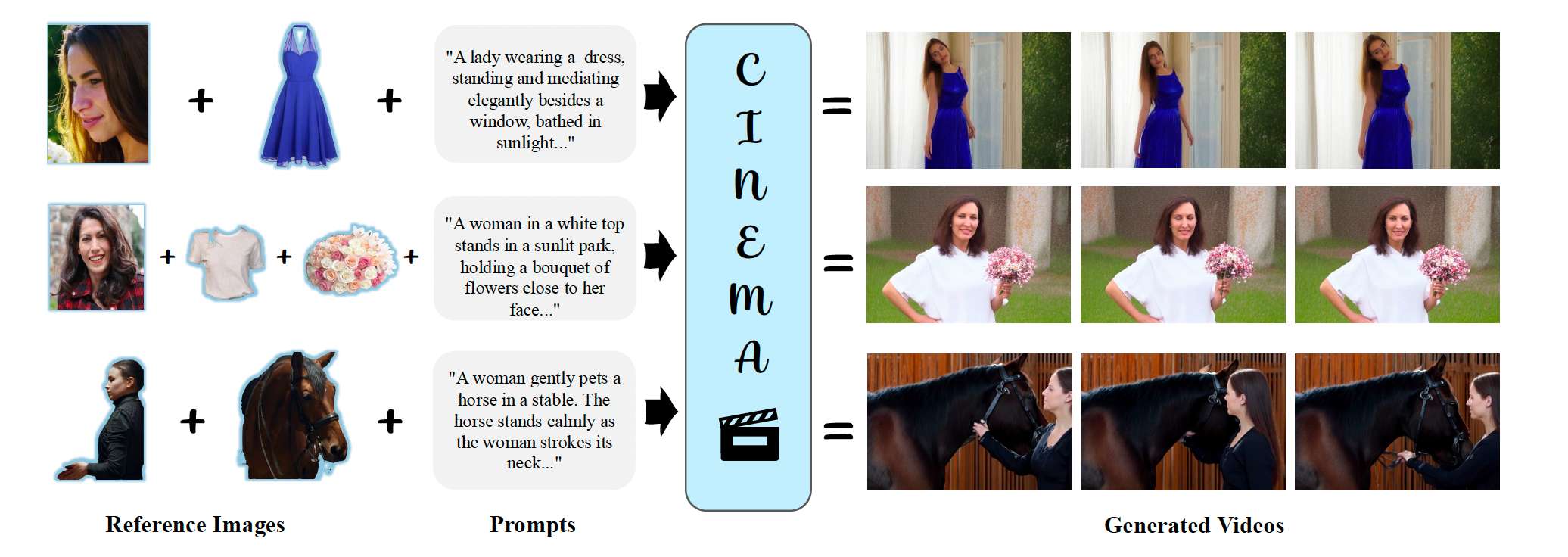
图1. 我们提出了CINEMA,一种基于一组参考图像和文本提示进行条件生成的视频生成框架。CINEMA能够在来自不同场景的多个主体之间生成视觉上一致的视频,提供了更高的灵活性和对视频合成过程的精确控制。
Abstract
随着深度生成模型,特别是扩散模型的出现,视频生成取得了显著进展。现有方法在根据文本提示或单张图像生成高质量视频方面表现出色,但个性化的多主体视频生成仍然是一个尚未充分探索的挑战。该任务涉及合成包含多个不同主体的视频,每个主体由单独的参考图像定义,同时确保时间和空间上的一致性。当前的方法主要依赖于将主体图像映射到文本提示中的关键词,这会引入歧义,并限制其有效建模主体关系的能力。本文中,我们提出了CINEMA,一种利用多模态大语言模型(MLLM)实现一致性多主体视频生成的新颖框架。我们的方法消除了主体图像与文本实体之间需要显式对应的需求,从而减轻了歧义并降低了标注成本。通过利用MLLM解释主体之间的关系,我们的方法提升了可扩展性,使得可以使用大型和多样化的数据集进行训练。此外,我们的框架可以基于可变数量的主体进行条件生成,在个性化内容创作方面提供了更大的灵活性。通过大量评估,我们证明了我们的方法显著提升了主体一致性和整体视频连贯性,为故事讲述、交互式媒体以及个性化视频生成等高级应用铺平了道路。
1. Introduction
深度生成模型的进步,特别是扩散模型的发展 [16, 28, 41],显著提升了从文本提示或图像生成逼真且连贯视频的能力,受到了学术界和工业界的广泛关注。开创性模型如Stable Video Diffusion [2]、Runway Gen [40]、Pika [29] 和 Sora [27] 展示了在生成高质量视频方面的卓越能力,不断拓展视觉内容创作的边界。这些模型利用大规模数据集、先进的扩散技术以及模型规模的扩展,生成在视觉上引人注目且时间上保持一致的结果,确立了视频生成作为现代生成式人工智能核心技术的地位。
通常,视频生成由用户提供的提示驱动(文本生成视频,Text-to-Video),或以单张图像作为起始帧(图像生成视频,Image-to-Video)。此外,个性化视频生成旨在在遵循提示指令的同时保持给定主体的视觉一致性。单主体视频生成已被广泛研究。例如,近期的工作如CustomCrafter [51] 使用LoRA [17] 来适配给定主体,而DreamVideo-2 [50] 和 SUGAR [64] 分别通过在输入图像中使用遮罩机制或注意力操作来增强身份保持能力。
相比之下,个性化多主体视频生成仍然是一个具有显著挑战性且尚未被充分探索的任务。它要求生成包含多个主体的视频,每个主体由不同的参考图像定义,同时可选地通过文本提示引导,以控制场景的背景或动态。尽管现有模型在从单一输入模态生成视频方面表现优异,但它们常常难以以连贯且视觉一致的方式无缝整合多个主体。这一局限凸显了一个关键挑战:如何有效理解多个主体之间的关系、它们的交互以及它们在统一场景中的融合,同时保持时间和空间上的一致性。
近期的研究 [8, 18, 25, 49] 试图解决这一挑战。VideoAlchemy [8] 利用冻结的图像编码器将多个主体图像编码为token,将其与文本提示中的对应词语token绑定,并通过独立的交叉注意力层将这些组合的嵌入输入到Diffusion Transformer [28] 中。然而,将视觉概念与实体词语进行绑定是具有挑战性的 [37],并且在大规模模型时代并不实用。例如,在一个“two persons are talking”的视频中,两个视觉主体都映射为“two persons”,从而引入歧义。此外,这些方法难以在提示语上下文中建立主体视觉特征之间的有意义关联,导致对主体关系的理解有限。例如在 [8] 中,视觉token在与词语token连接后仅仅被拼接在一起,缺乏更深入的语义理解或推理,从而在生成中导致空间布局混乱以及主体交互不清晰。
在本文中,我们提出了一个新颖的多主体视频生成框架,利用多模态大语言模型(MLLM)的引导以确保一致性与主体连贯性。我们主张利用MLLM的理解能力来解析并协调多个主体之间的关系,从而生成既具有视觉连贯性又具备上下文意义的个性化多主体视频。我们的方法是模型无关的,我们在一个预训练的开源视频生成模型 [53] 基础上无缝构建了CINEMA,突出了其通用性与适应性。由于大多数现有的开源视频生成模型 [44, 53, 62, 63] 依赖于类似 [33] 的LLM,且本身并不兼容MLLM,我们提出了AlignerNet模块,用于将MLLM输出对齐到原生文本特征,从而弥合这一差距。此外,为确保每个主体的视觉外观得以保留,我们还将参考图像的变分自编码器(VAE)特征注入训练中,作为辅助的条件信号,实践证明这对于在帧间保持一致性至关重要。
总结我们的贡献:
- 我们提出了CINEMA,这是首个在多主体视频生成任务中利用MLLM的视频生成模型。
- 我们证明了该方法无需显式地将主体图像与文本实体词进行对应,具备良好的可扩展性,可支持使用大型、多样化的数据集进行训练。
- 借助MLLM的理解能力,我们展示了CINEMA在多主体一致性和整体视频连贯性方面均有显著提升。
2. Related Work
视频基础模型。近期在视频生成方面的进展通常依赖于变分自编码器(VAE)[20, 23, 45],将原始视频数据压缩到一个低维潜空间。在这个压缩的潜空间中,使用基于扩散的方法 [15, 42] 或自回归方法 [7, 36, 55] 进行大规模生成式预训练。利用Transformer模型的可扩展性 [28, 46],这些方法已展现出稳定的性能提升 [3, 4, 13, 53]。
早期的文本生成视频(T2V)方法如MagicTime [58, 59] 和 AnimateDiff [14] 通过在二维U-Net架构 [38] 中引入时间模块奠定了基础。这些方法通常需要重新设计并大量训练U-Net模型,以学习时间动态性,从而应对视频内容的动态特性所带来的挑战。近期的研究如CogVideoX [53] 和 HunyuanVideo [21] 采用了更先进的架构设计。首先,它们利用三维因果VAE [56] 对原始视频数据进行编码与解码,显著提高了原始数据的压缩比。其次,它们使用了以扩展能力著称的DiT架构 [28],并引入了三维全注意力机制,增强了模型对视频数据中时间动态性的建模能力,从而在T2V生成方面取得了显著进展。
图像生成视频(I2V)任务则侧重于以静态输入图像为条件生成视频。一种广泛采用的策略是将输入图像的CLIP [30] 嵌入引入扩散过程中。例如,VideoCrafter1 [6] 和 I2V-Adapter [13] 受IP-Adapter [54] 启发,利用双重交叉注意力层有效融合这些嵌入。另一种显著策略是扩展扩散模型的输入通道,将静态图像与带噪声的视频帧拼接。方法如SEINE [9] 和 PixelDance [60] 通过更有效地整合图像信息,在视频生成过程中取得了优越的结果。此外,混合方法将通道拼接与注意力机制结合以注入图像特征,典型代表包括DynamiCrafter [52]、I2VGen-XL [61] 和 Stable Video Diffusion(SVD)[3]。这些方法旨在同时保持全局语义和细粒度细节的一致性。通过这种双重策略,它们确保生成的视频既忠于输入图像,又展现出逼真且连贯的运动动态。
主体驱动的图像与视频生成。根据给定的参考图像生成身份一致的图像与视频,需要模型能够准确捕捉身份特征。已有方法大致可分为两类:基于微调的方法与无微调的方法。
基于微调的方法 [8, 50, 51, 64] 通常采用高效的微调技术,如LoRA [17] 或 DreamBooth [39],以适配预训练模型。这些方法在保留基础模型生成能力的同时,嵌入了特定身份的信息。然而,这些方法需要为每一个新身份进行微调,限制了其在实际应用中的实用性。
相比之下,无微调方法采用前向推理方式,省去了对新身份进行微调的需求。StoryDiffusion [65] 使用一致的自注意力机制与语义运动预测器,以确保平滑的过渡与一致的身份。MS-Diffusion [48] 引入了基于参考主体的resampler与多主体交叉注意力机制,用于提取参考图像的细节特征。ConsisID [57] 则通过频率分解在视频中保持面部身份一致性。具体而言,它将身份特征分解为低频与高频信号,并将这些信号注入到DiT模型 [28] 的特定层中。最后,ConceptMaster [18] 使用CLIP图像编码器 [31] 和Q-Former [22] 提取视觉嵌入特征,并通过解耦注意力模块(DAM)融合视觉与文本嵌入。该方法进一步通过多概念注入器将嵌入信息引入扩散模型,从而实现多概念的视频定制生成。
3. Method
给定一组参考图像及其对应的文本提示,我们的目标是生成一个在各帧中保持主体外观一致性的视频。该任务面临多个挑战,因为它不仅要求保留参考图像中描绘的身份特征,还需忠实遵循文本提示中的指令,并在整个视频序列中确保时间上的连贯性。
3.1. Preliminaries
多模态大语言模型。多模态大语言模型(MLLMs)[1, 22, 24, 43, 47] 在传统大语言模型的基础上扩展了跨模态的理解与生成能力,支持文本、图像、视频和音频等多种模态。基于像GPT [5] 和 PaLM [10] 等单模态LLM的成功,MLLMs 引入了模态特定的编码器,例如用于视觉输入的CLIP [31] 和用于音频的Whisper [32],以将异构输入投射到统一的嵌入空间中。这些嵌入与跨模态融合模块(如基于注意力机制的Perceiver Resamplers [19])高度对齐,并通过专为多模态任务适配的仅解码式Transformer骨干网络进行处理,同时采用参数高效的微调方法 [17, 39]。
多模态扩散Transformer。Multimodal Diffusion Transformer(MM-DiT)是一种由 [12] 提出的先进的基于Transformer的扩散骨干网络,旨在提升生成任务中的多模态对齐性与生成一致性。具体而言,MM-DiT采用多模态联合注意力机制,促进了高效的视觉-文本跨模态交互。研究表明,该方法在生成质量、文本对齐以及计算效率方面显著优于基于交叉注意力的模型。
3.2. Data Curation
我们提出了一种高效处理训练视频的数据处理流程,能够生成文本标签,并提取诸如人类、面部和物体等参考信息,从而促进全面的视频相关任务。
为了确保干净且高质量的训练数据集,我们执行严格的数据预处理和筛选。对于一组训练视频,我们首先执行场景变化检测,将每个视频划分为多个片段,即 V1,V2,…,VnV_1, V_2, \dots, V_nV1,V2,…,Vn。参考之前的视频生成方法 [53, 62],我们评估每个视频片段 ViV_iVi 的美学质量和运动幅度,剔除那些美感差或运动极小的片段。
对于每个筛选后的视频片段 ViV_iVi,我们利用 Qwen2-VL [47] 生成一个描述其整体内容 CCC 的文本,侧重于运动方面。然后,我们提示 MLLM 识别并列出文本中提到的对象(实体词),作为片段级别的标签,如 “cat”、“hat” 和 “t-shirt”。对于每个对象标签,我们在视频片段的第一帧中使用 GroundingDINO [26] 计算其边界框,然后通过 SAM2 [34] 继续对该对象进行分割。这些分割出的主体图像作为参考图像 Ii,kObjI^{\text{Obj}}_{i,k}Ii,kObj。
在图像/视频生成任务中,保持人的外观一致性极具挑战。为了确保人类主体的清晰表示,我们首先使用 YOLO [35] 在初始帧中检测人和面部,再用 SAM2 对人体区域进行分割,并对面部应用稍宽松的边界框,以避免包含无关元素。这些分割图像分别存储为 IiHumanI^{\text{Human}}_iIiHuman 和 IiFaceI^{\text{Face}}_iIiFace。
因此,每个训练输入包含一组物体分割图、人类分割图和裁剪后的人脸图像,以及它们的文本标签。我们将训练数据定义为:
Ri={Ci,IiHuman,IiFace,Ii,1Obj,Ii,2Obj,…,Ii,kObj} \mathcal{R}_i = \{ C_i, I^{\text{Human}}_i, I^{\text{Face}}_i, I^{\text{Obj}}_{i,1}, I^{\text{Obj}}_{i,2}, \dots, I^{\text{Obj}}_{i,k} \} Ri={Ci,IiHuman,IiFace,Ii,1Obj,Ii,2Obj,…,Ii,kObj}
对于每个训练样本,我们将该集合与对应的视频片段 ViV_iVi 进行配对。
3.3. Video Generation via MLLM-Based Guidance
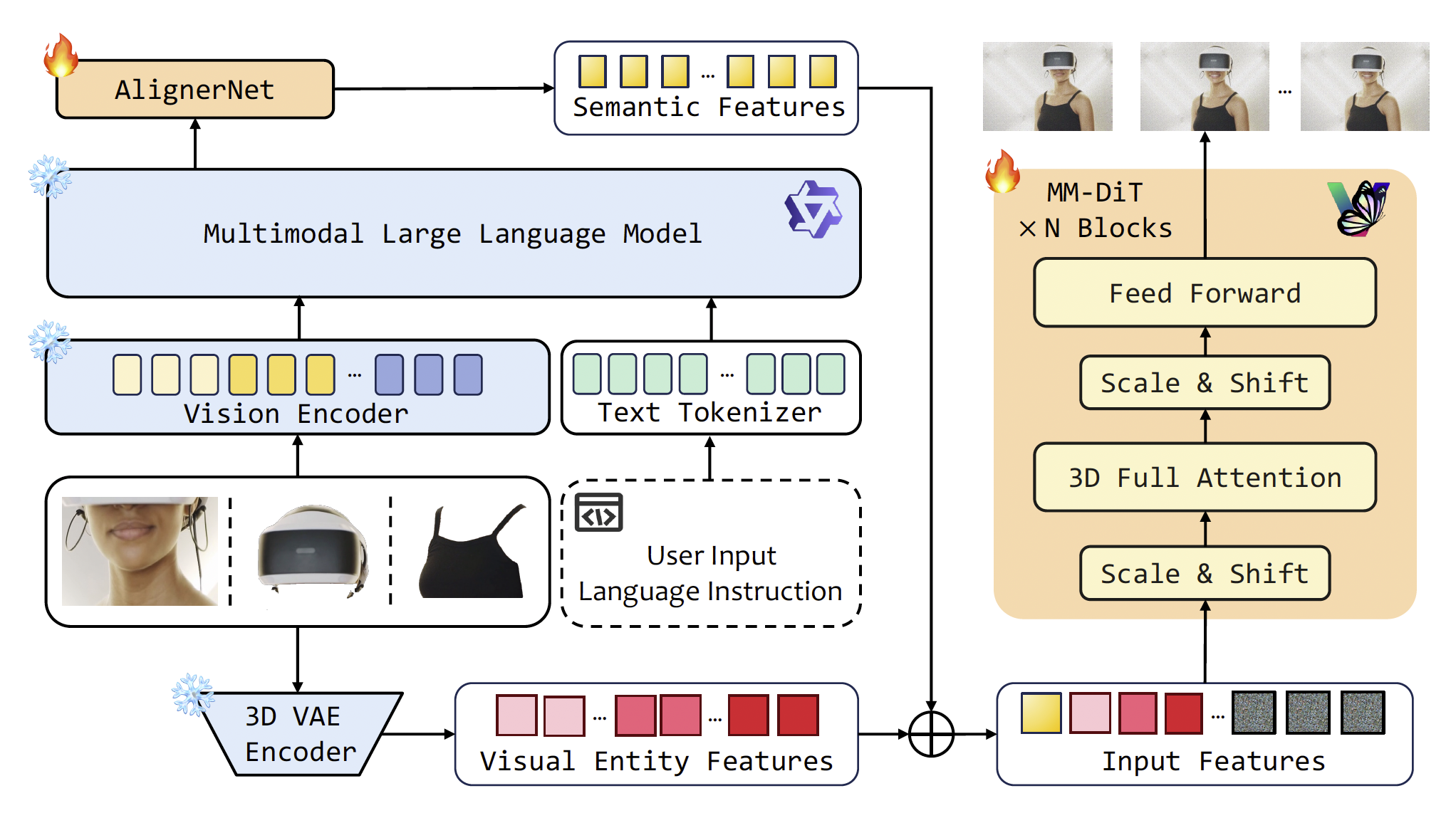
图2. 我们的整体流程包括一个多模态大语言模型、一个语义对齐网络(AlignerNet)、一个视觉实体编码网络,以及一个将前两个模块编码的嵌入整合的扩散Transformer。符号 ⊕ 表示拼接操作。
我们提出了一个新颖的框架——CINEMA,用于一致性的多主体视频生成,利用MLLMs强大的理解能力。CINEMA采用MM-DiT进行视频生成,并通过三个关键模块融合多模态条件信息,即多模态大语言模型、语义对齐网络和视觉实体编码。图2展示了我们框架的概览。MLLM用于将多模态条件(例如图像和文本)编码为统一的特征表示。此外,我们引入了语义对齐网络AlignerNet,用于弥合统一表示空间与原始DiT条件特征空间之间的差距。最后,视觉实体编码模块被设计用于捕捉细粒度的实体级视觉属性。下一个小节将详细介绍各个模块的架构和功能。
多模态大语言模型。CINEMA的核心在于对MLLM的利用。具体而言,我们采用Qwen2-VL [47] 从任意参考图像和文本提示中生成统一的表示。这些统一表示随后被输入到MM-DiT主干网络中,在其中多模态联合注意力机制用于促进编码token之间的交互式融合。此外,我们还采用了指令微调的方法,引入专门的指令模板,引导MLLM生成更准确且具有上下文相关性的编码结果。具体的指令如图3所示。
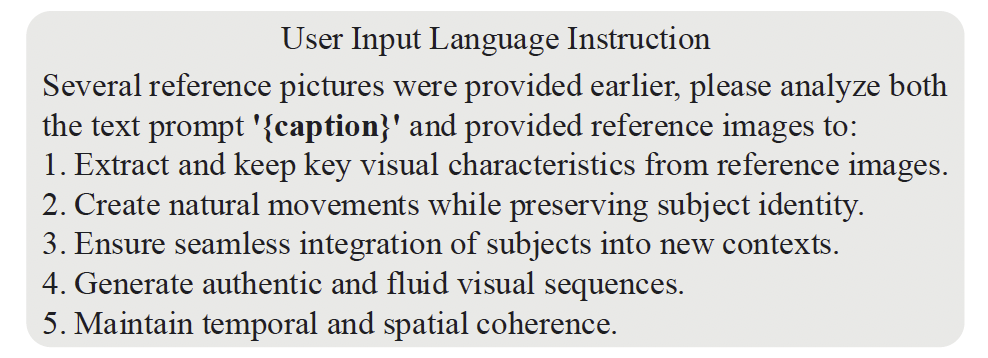
图3. 我们用于MLLM的语言指令模板。
语义对齐网络。我们在预训练的开源视频生成模型CogVideoX [53] 的基础上构建CINEMA,该模型主要在文本/图像到视频任务上进行预训练,并通过大语言模型 [33] 编码文本提示。为了解决LLM与MLLM之间的语义表示差异,我们提出引入AlignerNet模块,用MLLM替代T5编码器。
我们的AlignerNet是一个基于Transformer的网络。具体而言,AlignerNet将MLLM生成的隐藏状态映射到T5文本编码器的特征空间中,从而确保最终的多模态语义特征(包含视觉与文本信息)能够与T5编码器的特征空间良好对齐。我们使用均方误差(Mean Squared Error, MSE)和余弦相似度损失(Cosine Similarity loss)的组合来优化AlignerNet。设 FT5∈RK×d\mathbf{F}_{\text{T5}} \in \mathbb{R}^{K \times d}FT5∈RK×d 表示T5编码器生成的特征向量,FMLLM∈RK×d\mathbf{F}_{\text{MLLM}} \in \mathbb{R}^{K \times d}FMLLM∈RK×d 表示通过AlignerNet映射后的MLLM隐藏状态。MSE损失用于最小化 FT5\mathbf{F}_{\text{T5}}FT5 与 FMLLM\mathbf{F}_{\text{MLLM}}FMLLM 之间的欧几里得距离,其公式如下:
Lmse=1N∑i=1N∥FMLLM(i)−FT5(i)∥22(1) \mathcal{L}_{\text{mse}} = \frac{1}{N} \sum_{i=1}^{N} \left\| \mathbf{F}_{\text{MLLM}}^{(i)} - \mathbf{F}_{\text{T5}}^{(i)} \right\|_2^2 \tag{1} Lmse=N1i=1∑NFMLLM(i)−FT5(i)22(1)
余弦相似度损失旨在对齐 FT5\mathbf{F}_{\text{T5}}FT5 和 FMLLM\mathbf{F}_{\text{MLLM}}FMLLM 的方向,其公式如下:
Lcos=1N∑i=1N(1−⟨FMLLM(i),FT5(i)⟩∥FMLLM(i)∥2⋅∥FT5(i)∥2)(2) \mathcal{L}_{\text{cos}} = \frac{1}{N} \sum_{i=1}^{N} \left( 1 - \frac{ \left\langle \mathbf{F}_{\text{MLLM}}^{(i)}, \mathbf{F}_{\text{T5}}^{(i)} \right\rangle }{ \left\| \mathbf{F}_{\text{MLLM}}^{(i)} \right\|_2 \cdot \left\| \mathbf{F}_{\text{T5}}^{(i)} \right\|_2 } \right) \tag{2} Lcos=N1i=1∑N1−FMLLM(i)2⋅FT5(i)2⟨FMLLM(i),FT5(i)⟩(2)
最终,整体的损失函数如公式(3)所示,其中 λmse\lambda_{\text{mse}}λmse 和 λcos\lambda_{\text{cos}}λcos 是用于调节两个损失项权重的系数:
LAlignerNet=λmse⋅Lmse+λcos⋅Lcos(3) \mathcal{L}_{\text{AlignerNet}} = \lambda_{\text{mse}} \cdot \mathcal{L}_{\text{mse}} + \lambda_{\text{cos}} \cdot \mathcal{L}_{\text{cos}} \tag{3} LAlignerNet=λmse⋅Lmse+λcos⋅Lcos(3)
视觉实体编码。我们观察到,预训练的MLLM [47] 所编码的视觉特征是粗粒度的,因为其训练目标是最小化视觉与文本表示之间的相似性损失,主要捕捉的是语义级图像特征。然而,我们的任务需要细粒度的视觉身份(ID)特征,以应对任意参考图像作为条件的情况。为弥合这一差距,我们使用一种对每张参考图像进行实体级编码的VAE编码器,以增强视觉ID一致性。具体而言,如图2所示,给定可变数量的参考图像,VAE首先对每张图像进行编码以生成潜在特征。然后,这些特征被展平为一系列嵌入,并填充为固定长度(记作 Fvisual∈RM×d\mathbf{F}_{\text{visual}} \in \mathbb{R}^{M \times d}Fvisual∈RM×d),再输入到MM-DiT中。
多模态特征条件去噪。在获得多模态特征 FMLLM\mathbf{F}_{\text{MLLM}}FMLLM 和视觉特征 Fvisual\mathbf{F}_{\text{visual}}Fvisual 后,我们将这些token拼接形成统一的多模态特征 Funified\mathbf{F}_{\text{unified}}Funified,如下所示:
Funified=Concat(FMLLM,Fvisual)∈R(K+M)×d(4) \mathbf{F}_{\text{unified}} = \text{Concat}(\mathbf{F}_{\text{MLLM}}, \mathbf{F}_{\text{visual}}) \in \mathbb{R}^{(K+M) \times d} \tag{4} Funified=Concat(FMLLM,Fvisual)∈R(K+M)×d(4)
接下来,将统一的多模态特征 Funified\mathbf{F}_{\text{unified}}Funified 与在时间步 ttt 上的噪声token Fnoiset\mathbf{F}_{\text{noise}}^tFnoiset 拼接,形成MM-DiT主干网络的最终输入序列:
Finput=Concat(Funified,Fnoiset)∈R(K+M+T)×d(5) \mathbf{F}_{\text{input}} = \text{Concat}(\mathbf{F}_{\text{unified}}, \mathbf{F}_{\text{noise}}^t) \in \mathbb{R}^{(K+M+T) \times d} \tag{5} Finput=Concat(Funified,Fnoiset)∈R(K+M+T)×d(5)
接着,采用双分支Transformer模型 [53],其中 Funified\mathbf{F}_{\text{unified}}Funified 输入文本分支,Fnoiset\mathbf{F}_{\text{noise}}^tFnoiset 输入视觉分支。该模型具有联合注意力机制,能够动态融合增强的多模态特征token,如下所示:
Attention(Q,K,V)=softmax(Qi(K)Td)V(6) \text{Attention}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \text{softmax}\left( \frac{\mathbf{Q}^i (\mathbf{K})^T}{\sqrt{d}} \right) \mathbf{V} \tag{6} Attention(Q,K,V)=softmax(dQi(K)T)V(6)
其中:
- Q=FinputWQ\mathbf{Q} = \mathbf{F}_{\text{input}} \mathbf{W}_QQ=FinputWQ
- K=FinputWK\mathbf{K} = \mathbf{F}_{\text{input}} \mathbf{W}_KK=FinputWK
- V=FinputWV\mathbf{V} = \mathbf{F}_{\text{input}} \mathbf{W}_VV=FinputWV
WQ\mathbf{W}_QWQ、WK\mathbf{W}_KWK 和 WV\mathbf{W}_VWV 是用于编码输入特征映射的可训练权重矩阵。在注意力操作中,两个模态的序列被拼接,并计算联合注意力权重以实现互补信息的交互。
最后,MM-DiT在扩散模型 [15] 的训练目标上进行完全微调,其目标函数如下:
L=Et,x0,ϵ∥ϵ−ϵθ(αˉtx0+1−αˉtϵ,t)∥2(7) \mathcal{L} = \mathbb{E}_{t, x_0, \epsilon} \left\| \epsilon - \epsilon_\theta \left( \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon, t \right) \right\|^2 \tag{7} L=Et,x0,ϵϵ−ϵθ(αˉtx0+1−αˉtϵ,t)2(7)
其中,ttt 通过显式均匀采样得到。
4. Experiments
4.1. Experimental Setup
数据集。我们在一个自构建的高质量视频数据集上训练模型(见图4中的示例)。具体来说,原始训练集包含约510万个视频。经过筛选后,我们获得了约146万个视频片段,每个片段配有1到6个人类或物体参考。每个视频片段由96帧组成,所有参考图像以RGBA格式存储。

图4. 来自我们训练集的一个示例,展示了参考图像、对应的视频以及描述文本。
网络组件。对于视频扩散模型,我们使用一个开源版本的图像到视频的预训练DiT模型,以CogVideoX [53] 作为基础模型。由于训练不足,原始的I2V模型无法有效收敛。因此,我们首先在I2V任务上持续训练该模型 [53]。对于MLLM,我们采用Qwen2-VL-7B-Instruct [47],并在整个框架的训练过程中冻结其参数。我们为AlignerNet采用了一种基于注意力的架构,由六层注意力层组成,每层具有768的隐藏宽度、8个注意力头,以及226个潜在token,以对齐原始T5的序列长度。输入维度为2048,输出维度与DiT对齐。
训练策略。我们使用AdamW优化器训练模型,参数设置为 β1=0.9\beta_1 = 0.9β1=0.9,β2=0.95\beta_2 = 0.95β2=0.95,权重衰减为0.001。初始学习率设为 1×10−51 \times 10^{-5}1×10−5,并采用带重启的余弦退火调度。在训练初期的前100步中,我们采用线性预热阶段以稳定训练过程。批次大小设为1。我们应用最大范数为1.0的梯度裁剪,以防止梯度爆炸。条件参考以0.05的概率随机丢弃。我们的模型使用128块NVIDIA H100 GPU训练两天。输入视频的处理分辨率为448P,序列长度为45帧,时间步长为2。AlignerNet使用MSE损失和余弦相似度损失进行预训练,以匹配T5模型的特征分布,其中 λmse\lambda_{\text{mse}}λmse 和 λcos\lambda_{\text{cos}}λcos 在公式3中均设为1。随后我们对AlignerNet与DiT进行联合训练。