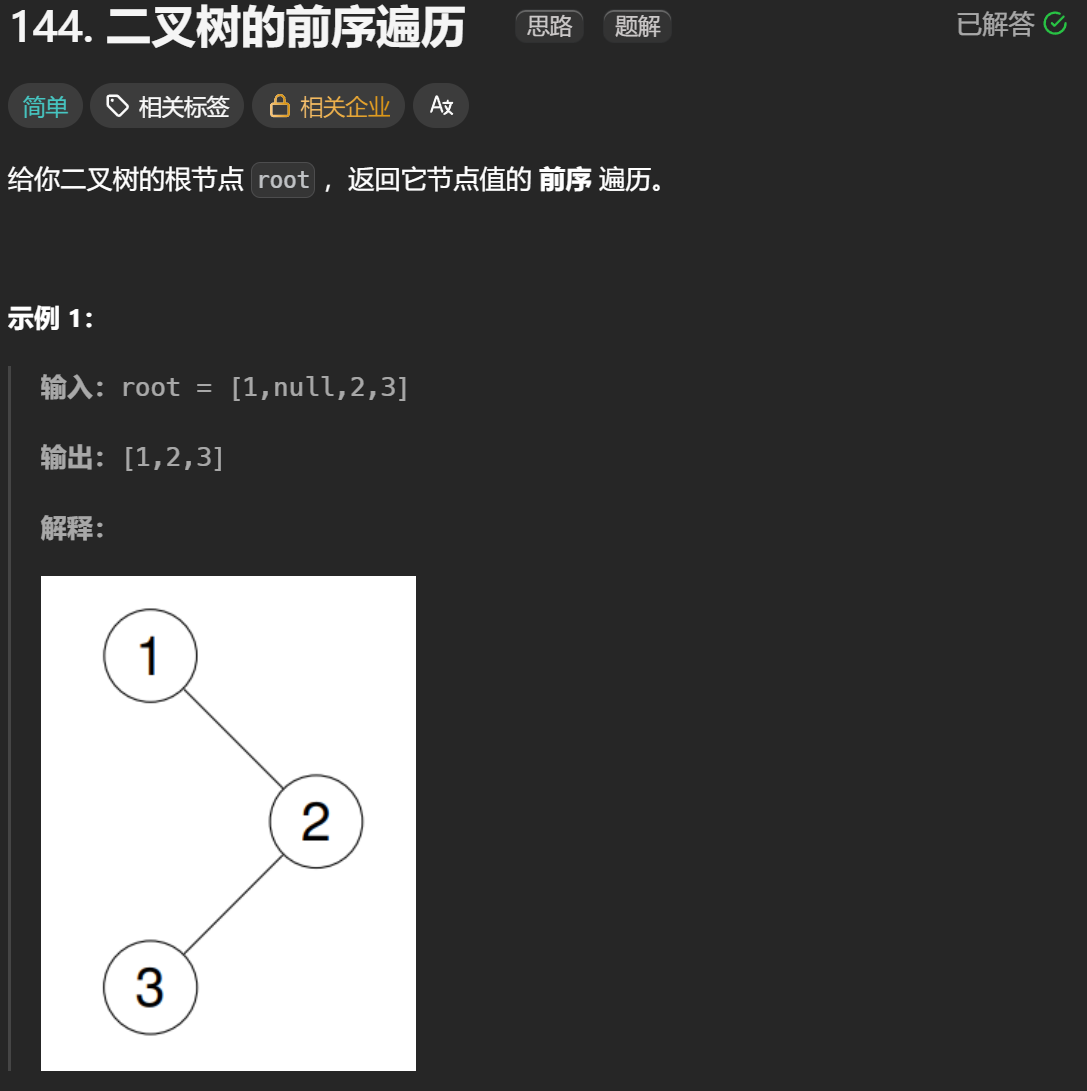
144.二叉树的前序遍历
思路解析
二叉树的遍历可以用递归法来实现,前序遍历要求先访问根节点,再递归访问左子树,最后访问右子树。
这道题的核心思路就是利用递归遍历的性质来依次收集节点值。
方法一:递归 + 利用返回值拼接
思路
- 定义
preorderTraversal(root)返回以root为根的二叉树的前序遍历结果。 - 先把
root->val加入结果数组。 - 递归调用
preorderTraversal(root->left)获取左子树结果,并拼接到结果数组末尾。 - 递归调用
preorderTraversal(root->right)获取右子树结果,并拼接到结果数组末尾。 - 最终返回拼接好的数组。
代码
class Solution {
public:vector<int> preorderTraversal(TreeNode* root) {vector<int> res;if (root == nullptr) {return res; // 空树直接返回}// 1. 访问根节点res.push_back(root->val);// 2. 拼接左子树前序遍历结果vector<int> left = preorderTraversal(root->left);res.insert(res.end(), left.begin(), left.end());// 3. 拼接右子树前序遍历结果vector<int> right = preorderTraversal(root->right);res.insert(res.end(), right.begin(), right.end());return res;}
};
优点:逻辑直观,直接利用递归函数的返回值构建结果。
缺点:每次拼接 vector 会有额外的时间和空间开销。
方法二:递归 + 全局结果数组
思路
-
定义一个全局(或成员变量)
res用来保存遍历结果。 -
定义辅助函数
traverse(TreeNode* root):- 若当前节点为空,直接返回。
- 将当前节点的值加入
res。 - 递归遍历左子树。
- 递归遍历右子树。
-
主函数中调用
traverse(root)完成遍历。
代码
class Solution {
public:vector<int> res; // 存储遍历结果vector<int> preorderTraversal(TreeNode* root) {traverse(root);return res;}// 前序遍历递归函数void traverse(TreeNode* root) {if (root == nullptr) {return;}// 1. 访问当前节点res.push_back(root->val);// 2. 遍历左子树traverse(root->left);// 3. 遍历右子树traverse(root->right);}
};
优点:只维护一个数组,避免频繁拼接,效率更高。
缺点:需要借助额外的成员变量(全局变量)保存状态,函数的“纯粹性”降低。
复杂度分析
对于两种方法:
-
时间复杂度:
O(n),n为节点数,所有节点访问一次。 -
空间复杂度:
- 方法一:
O(n + h),其中h是递归栈高度,n是结果数组存储节点值,额外还可能有vector拼接的开销。 - 方法二:
O(n + h),只维护一个结果数组,递归栈深度h。
- 方法一: