Java学习进阶--集合体系结构
Java 集合框架 (java.util 包) 是 Java 中用于存储和操作数据集合的核心组件,其设计精良、功能强大且高度灵活。理解其体系结构是 Java 进阶的关键一步。
一.集合的核心思想
接口与实现分离
集合框架的核心在于接口定义了行为规范,而具体实现类提供了不同的底层数据结构和算法。应用程序应该面向0接口编程,这样可以在不改变代码逻辑的情况下更换实现,提高灵活性和可维护性。
集合框架的总体结构
Java 集合框架主要分为两大分支:Collection 和 Map。
Collection接口:是单列集合的根接口,用于存储单个元素。它有三个主要的子接口:List、Set和Queue。Map接口:是双列集合的根接口,用于存储键值对。
二.Collection接口 -- 单列集合
Collection是单列集合的祖宗接口,它的功能是全部的单列集合都可以继承使用的,下图是Collection接口下的继承和实现关系。
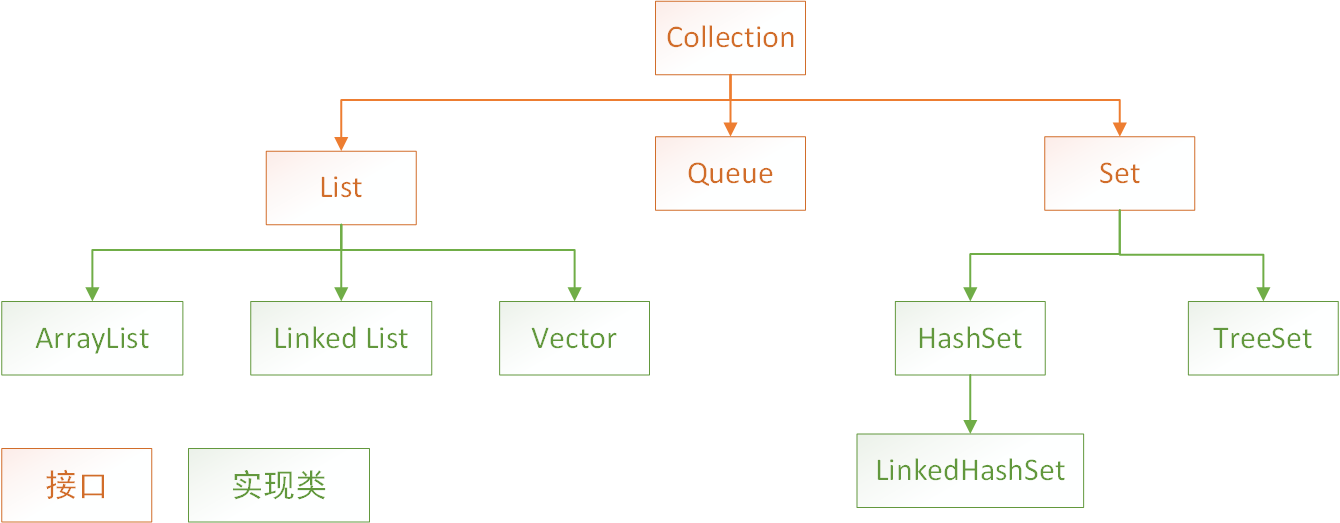
List系列集合:添加的元素是有序,可重复,有索引
Set系列集合:添加的元素是无序,不重复,无索引
Collection中的方法:
1. 基本操作方法
| 方法 | 描述 | 返回值 | 示例 |
|---|---|---|---|
boolean add(E e) | 添加元素 | 成功返回 true | list.add("Java") |
boolean remove(Object o) | 删除指定元素 | 存在并删除返回 true | set.remove("Python") |
int size() | 返回元素数量 | 集合大小 | queue.size() |
boolean isEmpty() | 检查是否为空 | 空集合返回 true | if (coll.isEmpty()) |
void clear() | 清空集合 | 无 | list.clear() |
2. 批量操作方法
| 方法 | 描述 | 示例 |
|---|---|---|
boolean addAll(Collection<? extends E> c) | 添加另一个集合的所有元素 | list1.addAll(list2) |
boolean removeAll(Collection<?> c) | 删除指定集合中存在的所有元素 | set.removeAll(subset) |
boolean retainAll(Collection<?> c) | 仅保留指定集合中的元素(求交集) | list.retainAll(subList) |
boolean containsAll(Collection<?> c) | 检查是否包含指定集合的所有元素 | if (set.containsAll(subset)) |
3. 查询方法
| 方法 | 描述 | 示例 |
|---|---|---|
boolean contains(Object o) | 检查是否包含指定元素 | if (list.contains("Java")) |
Object[] toArray() | 将集合转为数组 | Object[] arr = coll.toArray() |
<T> T[] toArray(T[] a) | 将集合转为指定类型数组 | String[] arr = list.toArray(new String[0]) |
4. 迭代方法
| 方法 | 描述 | 示例 |
|---|---|---|
Iterator<E> iterator() | 返回迭代器 | Iterator<String> it = coll.iterator() |
default void forEach(Consumer<? super T> action) | 使用函数式接口遍历 | list.forEach(System.out::println) |
5. Java 8 新增默认方法
| 方法 | 描述 | 示例 |
|---|---|---|
default boolean removeIf(Predicate<? super E> filter) | 删除满足条件的元素 | list.removeIf(s -> s.length() < 3) |
default Spliterator<E> spliterator() | 返回可分割迭代器 | Spliterator<String> sp = coll.spliterator() |
default Stream<E> stream() | 返回顺序流 | coll.stream().filter(...) |
default Stream<E> parallelStream() | 返回并行流 | coll.parallelStream(). |
import java.util.*;public class CollectionDemo {public static void main(String[] args) {// 1. 创建集合 (使用ArrayList实现)Collection<String> languages = new ArrayList<>();// 2. 添加元素languages.add("Java");languages.add("Python");languages.add("JavaScript");languages.add("C++");System.out.println("初始集合: " + languages); // [Java, Python, JavaScript, C++]// 3. 检查元素是否存在System.out.println("包含Java? " + languages.contains("Java")); // true// 4. 删除元素languages.remove("C++");System.out.println("删除C++后: " + languages); // [Java, Python, JavaScript]// 5. 批量操作 - 添加另一个集合Collection<String> frontend = new HashSet<>();frontend.add("HTML");frontend.add("CSS");frontend.add("JavaScript");languages.addAll(frontend);System.out.println("添加前端技术后: " + languages); // [Java, Python, JavaScript, HTML, CSS]// 6. 批量操作 - 删除另一个集合中的元素languages.removeAll(frontend);System.out.println("移除前端技术后: " + languages); // [Java, Python]// 7. 批量操作 - 保留交集Collection<String> popular = List.of("Java", "Python", "Go");languages.retainAll(popular);System.out.println("保留流行语言后: " + languages); // [Java, Python]// 8. 转换为数组Object[] array = languages.toArray();System.out.println("数组内容: " + Arrays.toString(array)); // [Java, Python]// 9. 遍历集合 - 迭代器System.out.print("迭代器遍历: ");Iterator<String> it = languages.iterator();while (it.hasNext()) {System.out.print(it.next() + " ");}System.out.println(); // 迭代器遍历: Java Python // 10. 遍历集合 - forEach (Java 8+)System.out.print("forEach遍历: ");languages.forEach(lang -> System.out.print(lang + " "));System.out.println(); // forEach遍历: Java Python // 11. Java 8 新特性 - removeIflanguages.removeIf(lang -> lang.startsWith("P"));System.out.println("移除P开头的语言后: " + languages); // [Java]// 12. Java 8 新特性 - streamlong count = languages.stream().filter(lang -> lang.length() > 3).count();System.out.println("长度大于3的元素数量: " + count); // 1 (Java)// 13. 清空集合languages.clear();System.out.println("清空后集合: " + languages); // []System.out.println("集合是否为空? " + languages.isEmpty()); // true}
}三.Map 接口 -- 双列集合
1. “双列集合”的含义
“双列”: 指的是 Map 存储的元素由两个部分组成:
- 键 (Key): 用于唯一标识元素的部分,相当于第一列。
- 值 (Value): 与键相关联的数据部分,相当于第二列。
“集合”: 指的是 Map 本身是一个容器,用于存储和管理这些键值对 (Key-Value Pair) 元素。
2. Map 接口的核心概念
键值对 (Key-Value Pair): 这是 Map 存储的基本单位。每个元素都是一个包含 Key 和 Value 的配对。
键 (Key) 的唯一性: Map 中 不允许有重复的键。每个键最多只能映射到一个值。这是 Map 最重要的特性之一。
值 (Value) 的可重复性: 不同的键可以映射到相同的值。值可以重复。
映射关系 (Mapping): Map 的核心功能就是建立 Key 到 Value 的映射关系。通过一个 Key,可以高效地查找到其对应的 Value。这就像一本字典(Dictionary)或电话簿,通过名字(Key)查找电话号码(Value)。
无序性 (通常): 大多数 Map 实现类(如 HashMap)不保证键值对的存储顺序(插入顺序或自然顺序)。但也有保证顺序的实现(如 LinkedHashMap 保证插入顺序,TreeMap 保证按键排序)。
不允许 null (视实现而定):
HashMap、LinkedHashMap允许一个null键和多个null值。TreeMap不允许null键(因为要排序),值可以为null。ConcurrentHashMap不允许null键和null值。Hashtable不允许null键和null值。
3. 为什么需要 Map?解决了什么问题?
Map 解决了需要根据 唯一标识符 快速查找、添加、删除或更新 关联数据 的场景。例如:
- 字典/电话簿: 根据单词查释义,根据姓名查电话。
- 数据库记录缓存: 用主键
ID作为Key,缓存整个记录对象作为Value。 - 配置信息: 配置项名称作为
Key,配置值作为Value。 - 对象属性映射: 属性名作为
Key,属性值作为Value。 - 计数/统计: 用物品名称作为
Key,物品数量作为Value。 - 图结构: 表示节点之间的连接关系(邻接表)。
| 实现类 | 描述 | 键有序性 | 允许 null 键/值 | 底层实现 |
|---|---|---|---|---|
HashMap | 最常用。 基于哈希表实现,提供最快的查找速度(平均 O(1))。 | 不保证 (通常无序) | 1个 null键, 多个 null值 | 数组 + 链表 / 红黑树 (JDK8+) |
LinkedHashMap | 继承 HashMap。额外维护一个双向链表,保证迭代顺序 == 插入顺序。 | 保证插入顺序 | 1个 null键, 多个 null值 | 哈希表 + 双向链表 |
TreeMap | 基于 红黑树 (Red-Black Tree) 实现。保证键值对按键的自然顺序或定制顺序排序。 | 保证键的排序顺序 | 键不能 null, 值可以 | 红黑树 |
Hashtable | 古老的线程安全实现 (JDK 1.0)。不推荐使用,优先选 ConcurrentHashMap。 | 不保证 | 键和值都不能 null | 哈希表 |
ConcurrentHashMap | 现代高效的线程安全实现 (JDK 5+)。支持高并发读写。 | 不保证 | 键和值都不能 null | 分段锁 / CAS (JDK8+) |
Properties | 继承 Hashtable。专门处理 属性配置文件 (key=value 格式如 .properties)。 | 通常按文件加载顺序 | 键和值都不能 null | 哈希表 |
4. Map 接口的常用方法
增 / 改:
V put(K key, V value): 添加键值对。如果键已存在,则替换旧值并返回旧值;如果键不存在,添加并返回null。void putAll(Map<? extends K, ? extends V> m): 将另一个Map的所有键值对添加到当前Map。
删:
V remove(Object key): 根据键删除键值对,返回被删除的值。键不存在返回null。void clear(): 清空所有键值对。
查:
V get(Object key): 根据键获取对应的值。键不存在返回null。boolean containsKey(Object key): 判断是否包含指定的键。boolean containsValue(Object value): 判断是否包含指定的值(效率通常低于containsKey)。
视图获取:
Set<K> keySet(): 返回此Map中所有键组成的Set集合(因为键唯一)。Collection<V> values(): 返回此Map中所有值组成的Collection集合(值可以重复)。Set<Map.Entry<K, V>> entrySet(): 返回此Map中所有键值对 (Map.Entry对象) 组成的Set集合。这是遍历Map最常用的方式。
其他:
int size(): 返回键值对的数量。boolean isEmpty(): 判断Map是否为空。default V getOrDefault(Object key, V defaultValue): (JDK8+) 获取指定键的值,如果键不存在则返回默认值。default V putIfAbsent(K key, V value): (JDK8+) 如果指定键尚未与值关联(或关联为null),则将其与给定值关联并返回null,否则返回当前值。default boolean remove(Object key, Object value): (JDK8+) 仅当指定键当前映射到指定值时删除该条目。default V replace(K key, V value): (JDK8+) 仅当指定键当前映射到某个值时,才替换该条目的值。default boolean replace(K key, V oldValue, V newValue): (JDK8+) 仅当指定键当前映射到指定值时,才替换该条目的值。
Map<String, Integer> phoneBook = new HashMap<>();
phoneBook.put("Alice", 123456);
phoneBook.put("Bob", 654321);
phoneBook.put("Charlie", 789012);// 方式1:使用 Map.Entry 遍历 (最推荐,效率高,一次获取key和value)
for (Map.Entry<String, Integer> entry : phoneBook.entrySet()) {String name = entry.getKey();int phoneNumber = entry.getValue();System.out.println(name + ": " + phoneNumber);
}// 方式2:遍历键 (KeySet),然后通过键找值 (效率稍低于entrySet,因为多了一次get操作)
for (String name : phoneBook.keySet()) {int phoneNumber = phoneBook.get(name);System.out.println(name + ": " + phoneNumber);
}// 方式3:仅遍历值 (Values) (如果只需要值)
for (int phoneNumber : phoneBook.values()) {System.out.println("Phone: " + phoneNumber);
}// 方式4:Java 8+ 使用 forEach + Lambda 表达式 (简洁)
phoneBook.forEach((name, phoneNumber) -> System.out.println(name + ": " + phoneNumber));