PyTorch RNN 名字分类器
PyTorch RNN 名字分类器详解
使用PyTorch实现的字符级RNN(循环神经网络)项目,用于根据人名预测其所属的语言/国家。该模型通过学习不同语言名字的字符模式,够识别名字的语言起源。
环境设置
import torch
import string
import unicodedata
import glob
import os
import time
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np
1. 数据预处理
1.1 字符编码处理
# 定义允许的字符集(ASCII字母 + 标点符号 + 占位符)
allowed_characters = string.ascii_letters + " .,;'" + "_"
n_letters = len(allowed_characters) # 58个字符def unicodeToAscii(s):"""将Unicode字符串转换为ASCII"""return ''.join(c for c in unicodedata.normalize('NFD', s)if unicodedata.category(c) != 'Mn' and c in allowed_characters)
关键点:
- 使用One-hot编码表示每个字符
- 将非ASCII字符规范化(如 ‘Ślusàrski’ → ‘Slusarski’)
- 未知字符用 “_” 表示
1.2 张量转换
def letterToIndex(letter):"""将字母转换为索引"""if letter not in allowed_characters:return allowed_characters.find("_")return allowed_characters.find(letter)def lineToTensor(line):"""将名字转换为张量 <line_length x 1 x n_letters>"""tensor = torch.zeros(len(line), 1, n_letters)for li, letter in enumerate(line):tensor[li][0][letterToIndex(letter)] = 1return tensor
张量维度说明:
- 每个名字表示为3D张量:
[序列长度, 批次大小=1, 字符数=58] - 使用One-hot编码:每个字符位置只有一个1,其余为0
2. 数据集构建
2.1 自定义Dataset类
class NamesDataset(Dataset):def __init__(self, data_dir):self.data = [] # 原始名字self.data_tensors = [] # 名字的张量表示self.labels = [] # 语言标签self.labels_tensors = [] # 标签的张量表示# 读取所有.txt文件(每个文件代表一种语言)text_files = glob.glob(os.path.join(data_dir, '*.txt'))for filename in text_files:label = os.path.splitext(os.path.basename(filename))[0]lines = open(filename, encoding='utf-8').read().strip().split('\n')for name in lines:self.data.append(name)self.data_tensors.append(lineToTensor(name))self.labels.append(label)
2.2 数据集划分
# 85/15 训练/测试集划分
train_set, test_set = torch.utils.data.random_split(alldata, [.85, .15], generator=torch.Generator(device=device).manual_seed(2024)
)
3. RNN模型架构
3.1 模型定义
class CharRNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(CharRNN, self).__init__()# RNN层:输入大小 → 隐藏层大小self.rnn = nn.RNN(input_size, hidden_size)# 输出层:隐藏层 → 输出类别self.h2o = nn.Linear(hidden_size, output_size)# LogSoftmax用于分类self.softmax = nn.LogSoftmax(dim=1)def forward(self, line_tensor):rnn_out, hidden = self.rnn(line_tensor)output = self.h2o(hidden[0])output = self.softmax(output)return output
模型参数:
- 输入大小:58(字符数)
- 隐藏层大小:128
- 输出大小:18(语言类别数)
4. 训练过程
4.1 训练函数
def train(rnn, training_data, n_epoch=10, n_batch_size=64, learning_rate=0.2, criterion=nn.NLLLoss()):rnn.train()optimizer = torch.optim.SGD(rnn.parameters(), lr=learning_rate)for iter in range(1, n_epoch + 1):# 创建小批量batches = list(range(len(training_data)))random.shuffle(batches)batches = np.array_split(batches, len(batches)//n_batch_size)for batch in batches:batch_loss = 0for i in batch:label_tensor, text_tensor, label, text = training_data[i]output = rnn.forward(text_tensor)loss = criterion(output, label_tensor)batch_loss += loss# 反向传播和优化batch_loss.backward()nn.utils.clip_grad_norm_(rnn.parameters(), 3) # 梯度裁剪optimizer.step()optimizer.zero_grad()
训练技巧:
- 使用SGD优化器,学习率0.15
- 梯度裁剪防止梯度爆炸
- 批量大小:64
5. 模型评估
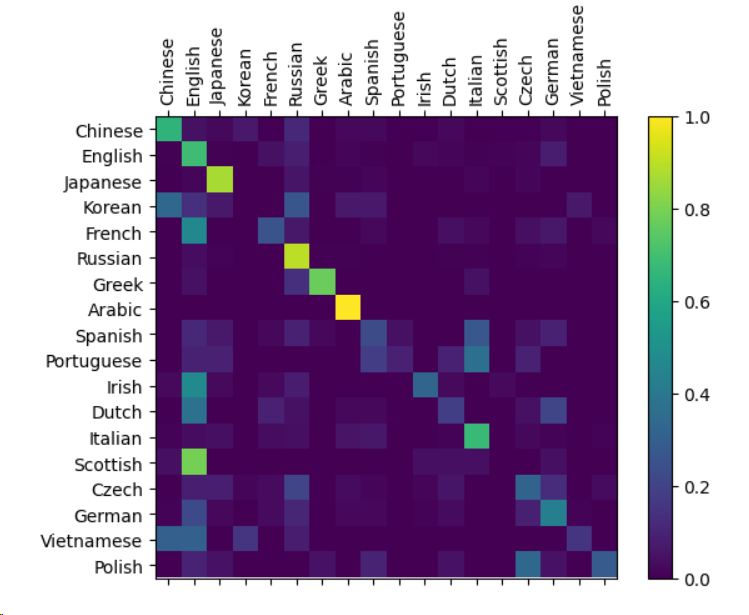
5.1 混淆矩阵可视化
def evaluate(rnn, testing_data, classes):confusion = torch.zeros(len(classes), len(classes))rnn.eval()with torch.no_grad():for i in range(len(testing_data)):label_tensor, text_tensor, label, text = testing_data[i]output = rnn(text_tensor)guess, guess_i = label_from_output(output, classes)label_i = classes.index(label)confusion[label_i][guess_i] += 1# 归一化并可视化# ...
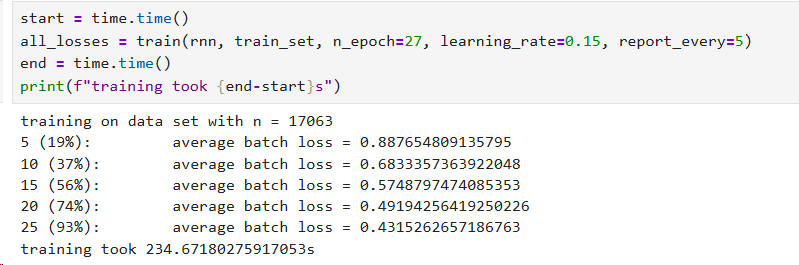
6. 训练结果
- 训练样本数:17,063
- 测试样本数:3,011
- 训练轮数:27
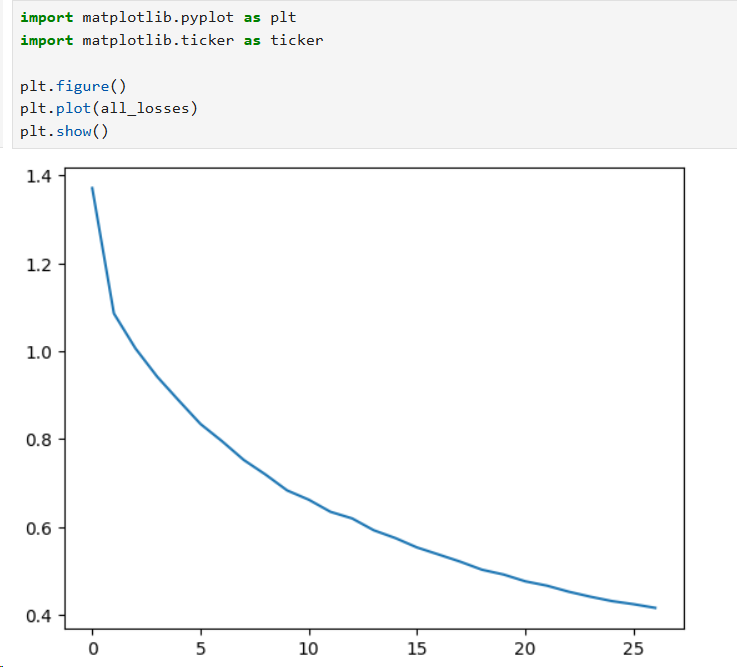
- 最终损失:约0.43
损失曲线显示模型收敛良好,从初始的0.88降至0.43。