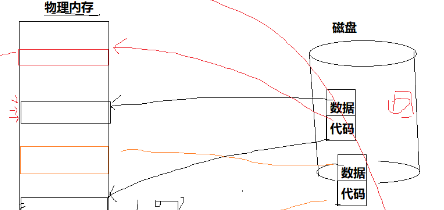
进程Linux
1.冯诺依曼体系
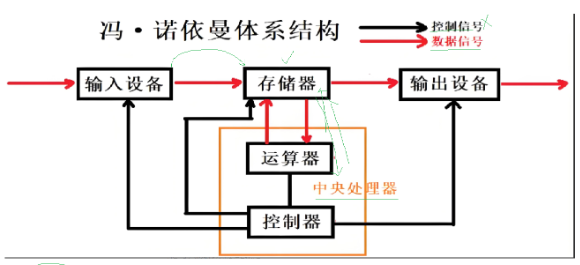
关于冯诺依曼,必须强调几点:
1.这里的存储器指的是内存
2.不考虑缓存情况,这里的CPU能且只能对内存进行读写,不能访问外设(输入或输出设备)
3.外设(输入或输出设备)要输入或者输出数据,也只能写入内存或者从内存中读取。
一句话,所有设备都只能直接和内存打交道。
冯诺依曼就是一个为了性价比而产生的体系
外设备和cpu的运行时间不是一个量级,所以就以一个中间(内存)为中间载体
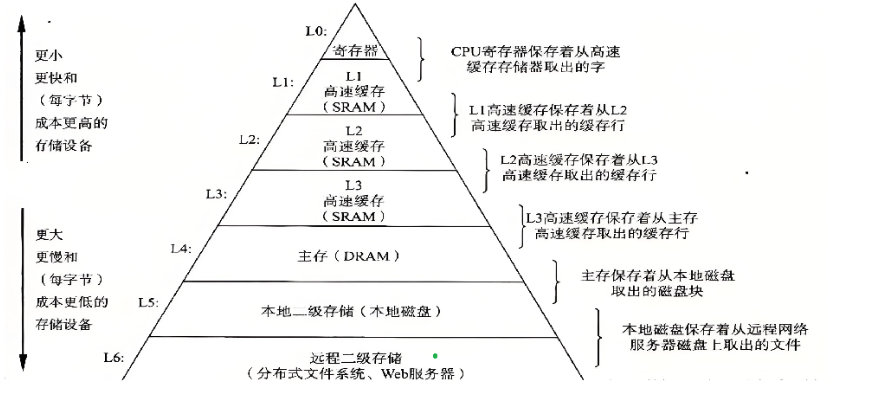
2.操作系统
操作系统包括两部分:
1.内核(进程管理,内存管理,文件管理,驱动管理)
2.其他程序(例如函数库,shell程序等等)
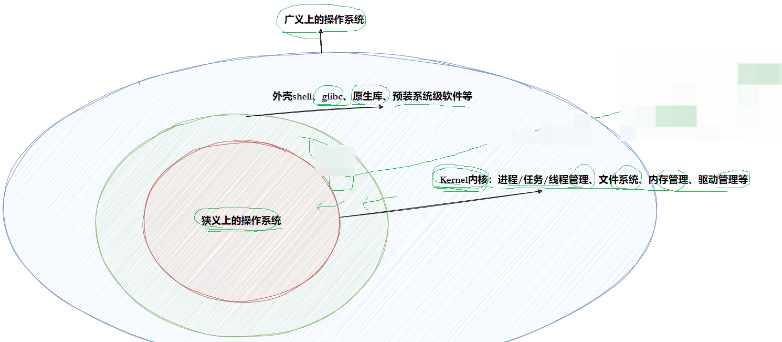
设计OS的目的:总的来说,操作系统就是软件层面和硬件层面交互的中间商
对下,与硬件交互,管理所有的软硬件资源
对上,为用户程序(应用程序)提供一个良好的执行环境

3.进程
3.1.进程的概念:
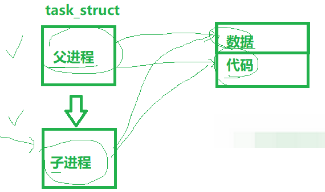
进程=PCB+自己的代码和数据
PCB里面有指向自己代码和数据的指针
基本概念:
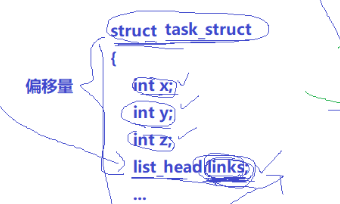
描述进程——PCB:
task_struct包含的数据:
3.2.在Linux对进程的操作
1.查看所有的进程: cd /proc
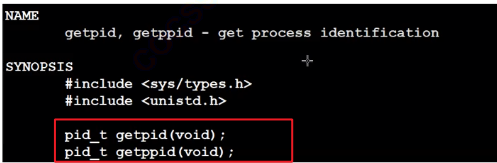
2.代码内部调用查看id
getpid:获取本身的进程(哪个进程调用这个函数,就返回哪个进程的id)
getppid:获取父亲的进程

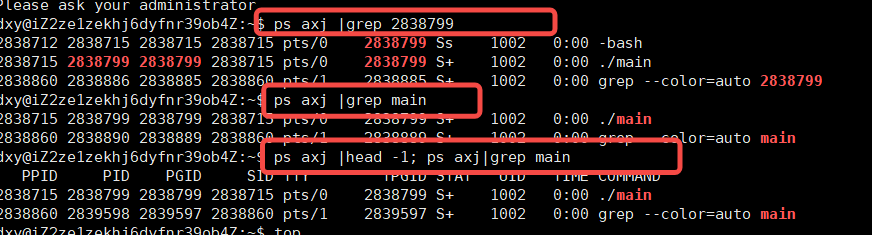
3.根据执行的文件,查看指定的进程
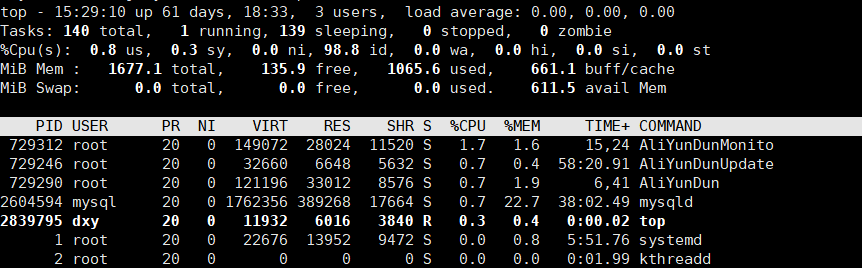
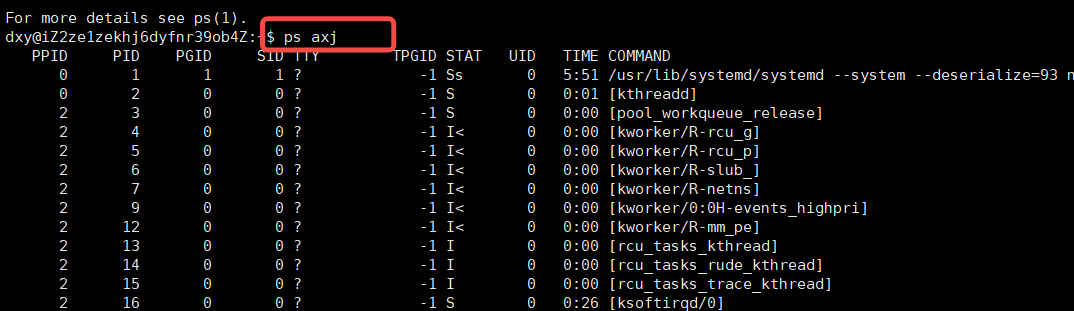
1.查看所有的进程: ps axj 或者是 top
top:
ps axj:
2.查看正在运行的指定进程
假设此时我设计一个程序是一直在进行运行:
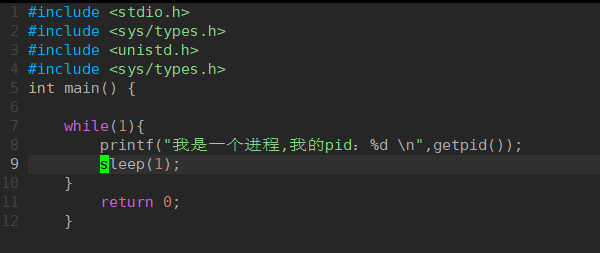
根据PID和程序名都是可以查到指定程序的状态
此时我们三种方式都是可以的:
3.在本身进程中创建一个子进程:fock()
fock():创建的子进程调用的是和父进程相同的一段代码,
fork()函数创建子进程后,子进程会从fork()调用后的下一行代码开始执行
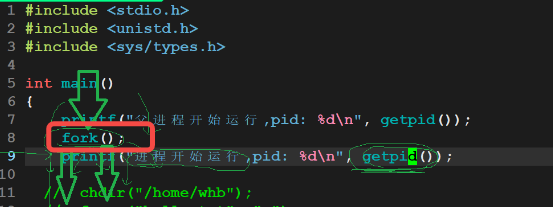
fork():创建失败返回-1,子进程调用返回0,父进程调用返回子进程的PID

fork()函数内部的大致执行逻辑:

3.3.进程的状态
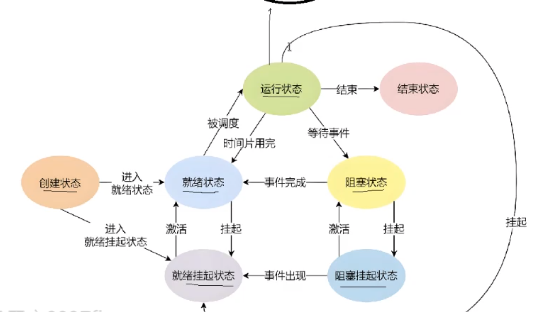
3.3.1.运行&&阻塞&&挂起
进程状态的变化,表现之一,就是要在不同的队列中进行流动。本质都是数据结构的增删查改!
每个进程的task_struct都指向自己的代码数据:
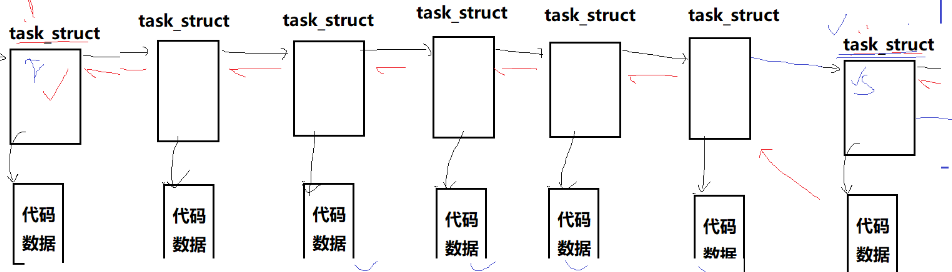
运行:如果此时是运行状态那么所有的运行状态的task_struct就形成一个运行状态的双向链表
阻塞:等待某种设备或者资源就绪键盘,显示器,中网卡,磁盘,摄像头,话筒..(阻塞状态那么所有的运行状态的task_struct就形成一个阻塞状态的双向链表)
挂起:此时因为cpu的内存严重不足,只能将一些进程暂时挂起,释放其内存(挂起状态那么所有的运行状态的task_struct就形成一个挂起状态的双向链表)
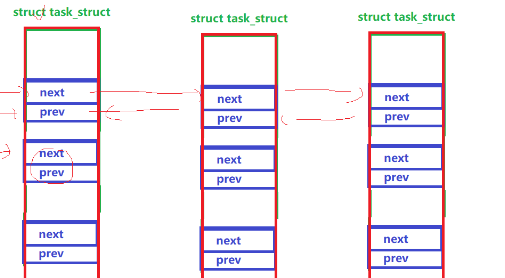
3.3.2.不同状态的双向链表
这么多状态的链表的形成:
其实是Node节点内部再有个head结果,不同状态的链表的形成,也只需要靠head进行连接即可
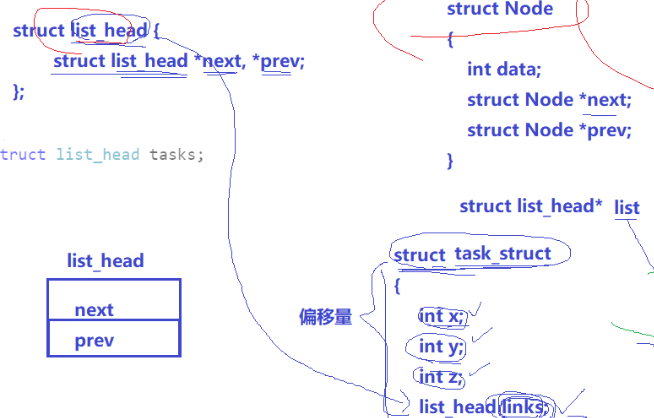
此时虽然我们只有每一个Node节点中的head的地址,但是我们可以靠偏移量来找到PCB的位置,从而访问到Node节点中其他变量的数值
cpu在对这些状态的调度,对其head链表进行增删查改即可
3.3.3.Linux中的进程状态
R运行状态(running):并不意味着进程一定在运行中,它表明进程要么是在运行中要么在运行队列里。
S睡眠状态(sleeping):意味着进程在等待事件完成(这里的睡眠有时候也叫做可中断睡眠(interruptible sleep))。
D磁盘休眠状态(Disk sleep)有时候也叫不可中断睡眠状态(uninterruptible sleep),在这个状态的进程通常会等待I0的结束。
T停止状态(stopped):可以通过发送 SIGSTOP 信号给进程来停止(T)进程。这个被暂停的进程可以通过发送 SIGCONT 信号让进程继续运行。
X死亡状态(dead):这个状态只是一个返回状态,你不会在任务列表里看到这个状态。

状态的查看指令:
![]()
每个字母代表的含义:

查看进程状态:

R运行状态(running):
下面的代码就是一直都在进行运行,所以是一个运行的状态

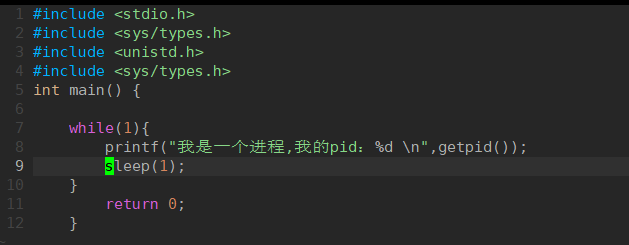
S睡眠状态(sleeping):
因为此时代码中有一个向屏幕输出的操作,所以此时的cpu就会对输出操作进行等待,所以此时大部分是睡眠状态
因为此时代码中有一个等待键盘输入的操作,所以此时的cpu就会对输入操作进行等待,所以此时是睡眠状态

D磁盘休眠状态(Disk sleep):
S对应的是浅睡眠,D对应的就是一个深度睡眠,S的进程在睡眠的状态下是可以被杀死的,
但是D多了一个特权,就是程序在休眠的状态下是不可以被杀死,内存不可以被cpu回收
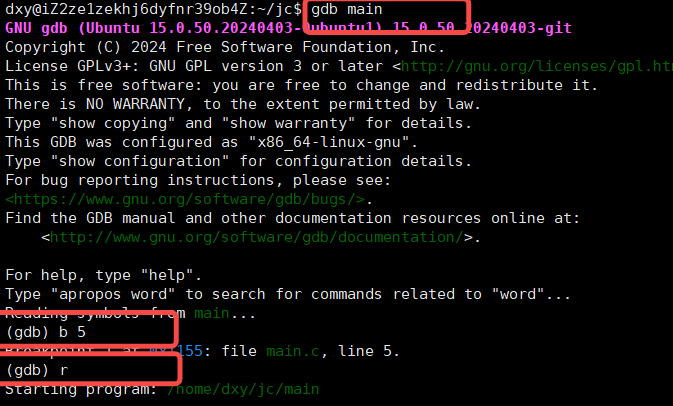
t 追踪状态(tracing stop):
此时我们个运行文件加上调试信息,并打上断点,运行的时候,就会在断点处停下
![]()

T停止状态(stopped):
此时我们的代码一直在向屏幕打印数据,但是此时我们 CTRL+z:由我们人自己进行暂停,在另一个终端显示的就是T状态

3.3.3.1.僵尸状态
在Linux中,所有的进程都是一个进程的子进程,我们创建子进程就是为了完成某种事情,但是子进程完成之后,父进程需要查看子进程完成的情况如何,所以子进程结束后不可以将自己的PCB
信息给释放,要等待父进程结束,此时子进程在等待父进程的这段区间就是被称为僵尸状态
终端的观察情况:

3.3.3.2.孤儿进程
父子进程关系中,如果父进程先退出,子进程要被1号进程领养,这个被领养的进程(子进程),叫做孤儿进程

![]()
3.4.进程优先级
首先我们要先理解下面四个概念:
1.竞争性:系统进程数目众多,而CPU资源只有少量,甚至1个,所以进程之间是具有竞争属性的。为了高效完成任务,更合理竞争相关资源,便具有了优先级
2.独立性: 多进程运行,需要独享各种资源,多进程运行期间互不干扰
3.并行:多个进程在多个CPU下分别,同时进行运行,这称之为并行
4.并发:多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为并发
cpu资源分配的先后顺序,就是指进程的优先权(priority)优先权高的进程有优先执行权利。配置进程优先权对多任务环境的linux很有用,可以改善系统性能。
总的来说就是谁先运行谁后运行
查看系统进程:

UID:代表执行者的身份
PID:代表这个进程的代号
PPID:代表这个进程是由哪个进程发展衍生而来的,亦即父进程的代号
PRI:代表这个进程可被执行的优先级,其值越小越早被执行(默认值为80)
N:代表这个进程的nice值
真实的的进程优先级=PRI(默认)+N;
改变进程的优先级:
1. 进入top 查看优先级
2.输入 r 要更改的进程PRI 回车

3.输入要改的 nice值即可
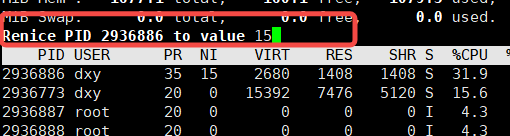
4.对更改的NI的文件进行查询的时候,就发现PRI变成了 95(默认是80) NI变成了15

优先级极值的问题:
nice范围:【-20,19】;
默认:80;
所以Linux优先级的取值范围是[60,99]
优先级设立不合理,会导致优先级低的进程,长时间得不到CPU资源,进而导致:进程饥饿
所以设置这种范围
3.5.进程的切换
进程的切换从下面三部分进行理解;
1.cpu的运行机制:
2.宏观上进程的切换
3.Linux真实调度算法:O(1)调度算法
3.5.1.cpu的运行机制
并发:多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为并发
问题:假设一个死循环进程运行,是否会一直占有cpu,导致后面的进程无法运行
不会,因为有一个时间片的东西,过来时间片,进程就会停止,这就是并发
3.5.2.宏观上进程的切换
现在我们有了cpu运行进程的时候是采用时间片的方式运行,在理解一下寄存器的工作原理
寄存器:寄存器是cpu内部的临时空间,存储的是进程的临时数据
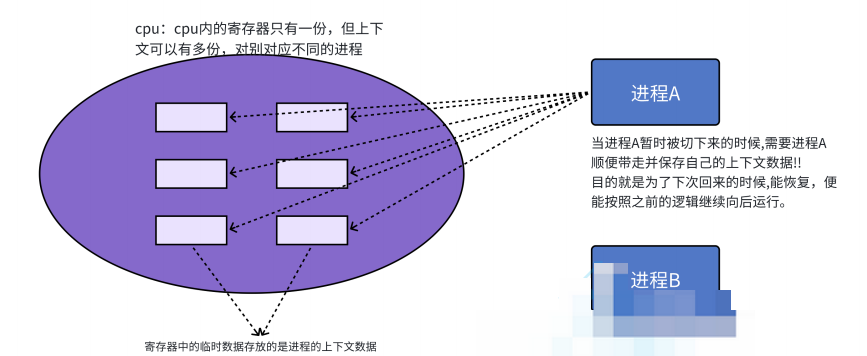
当进程超出了规定的时间片后,进程就会将寄存器中的临时数据取出,到下次的进程再次运行的时候,就可以找到对应的数据,后面的进程直接将自己的数据在寄存器进行覆盖即可
当前进程要把自己的进程硬件上下文数据,保存起来,保存到哪里了呢
保存到进程的task struct 里面==》》TSS:任务状态段

3.5.3.Linux真实调度算法:O(1)调度算法
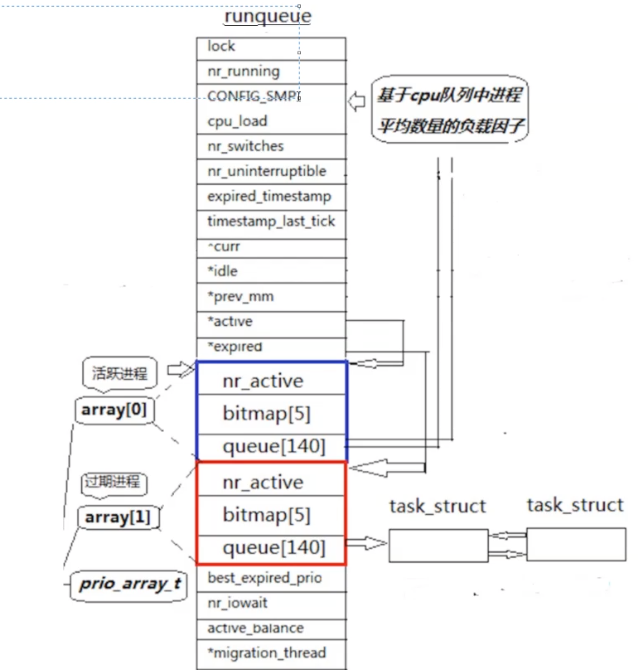
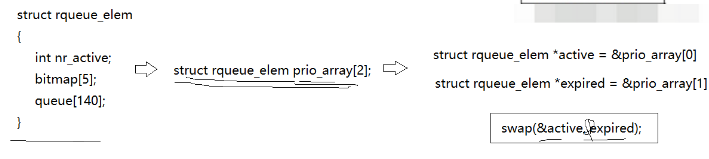
1.queue[140]
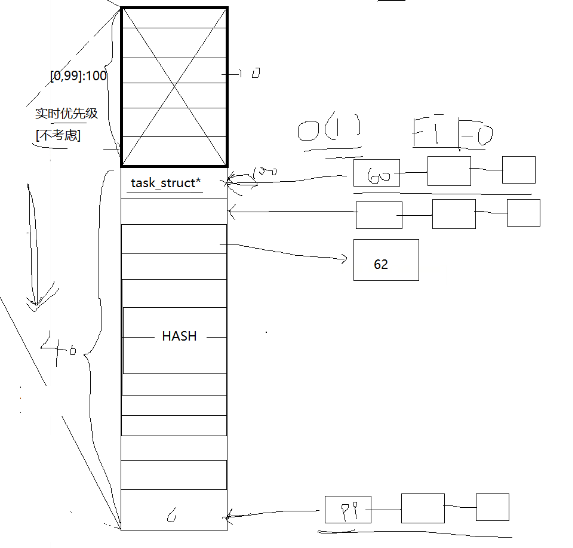
此时优先级分成下面两种:
实时优先级:就是加入实时优先级中的进程是必须完成(0~99(不关心))
普通优先级:100~139(我们都是普通的优先级,想想nice值的取值范围,可与之对应!)
x(PRI-NI)-60+(140-40):就是此时普通优先级储存的位置
其实这个queue就相当于一个hash表,先根据优先级确定存储的位置,每一个位置相当于这个位置优先级的头结点,过了时间片就将其舍弃,遵行先进先出的原则
2.bitmap[5]
bitmap的左右就是为了标记对应的queue数组是否有进程,如果没有bitmap数组,cpu运行的时候只能遍历queue数组一遍,但是此时引入了bitmap数组,我们只要O(1)的时间复杂度,就可以确定进程的位置
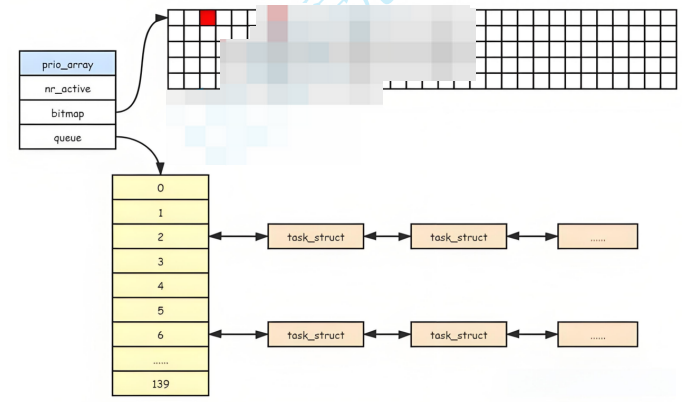
一共有32*5个二进制位,但是queue只有140位,所以最后的20位不要了舍弃
3.nr_active:表示queue数组中进程的个数
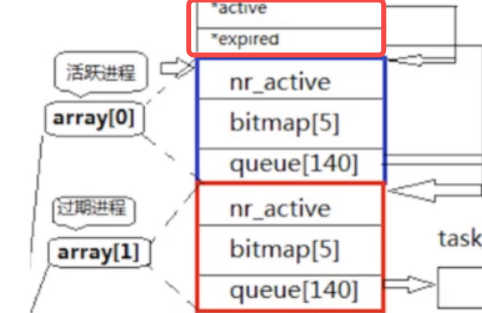
4.*active和*expired
elem的数组大小为2,第一个是活跃进程,一个是过期进程,他们的作用又是什么?
机制:
其实cpu运行进程只运行活跃进程中的进程,当这个进程过了设置的时间片,就把这个进程从活跃进程中删除,根据对应的优先级插入到过期进程中(这就是为什么 真实的优先级=PRI+NI 的原因),当活跃进程中的进程运行完后,将活跃进程和过期进程,进行交换,再次运行活跃进程即可

4.环境变量
基本概念:
环境变量(environment variables)一般是指在操作系统中用来指定操作系统运行环境的一些参数如:我们在编写C/C++代码的时候,在链接的时候,从来不知道我们的所链接的动态静态库在哪里,但是照样可以链接成功,生成可执行程序,原因就是有相关环境变量帮助编译器进行查找。
环境变量通常具有某些特殊用途,还有在系统当中通常具有全局特性
常见的环境变量:
PATH:指定命令的搜索路径
HOME:指定用户的主工作目录(即用户登陆到Linux系统中时,默认的目录)
SHELL:当前Shell,它的值通常是/bin/bash。
查看指定的环境变量:
![]()
测试PATH:
假设此时我的main.c文件
此时运行它有两种方式:
方式一:./main:指定路径
![]()
方式二:将main文件的路径加入到 PATH环境变量中,直接运行main,系统自动在环境变量中的路径下找到相对应的文件,并运行(这就是cd pwd,直接输入命令就可以运行的原因)

和环境变量相关的命令:
echo:显示某个环境变量值
export: 设置一个新的环境变量
env:显示所有环境变量
unset: 清除环境变量
set: 显示本地定义的shell变量和环境变量
环境变量的组织方式:
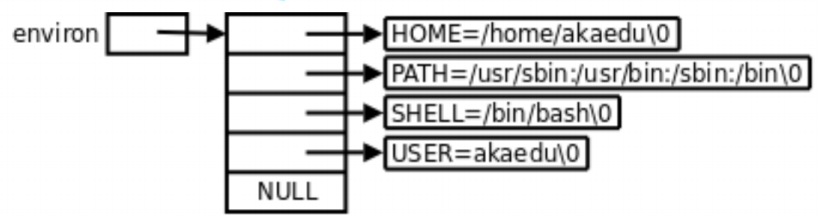
argc:表示命令行参数的数量,是一个整数。当程序从命令行启动时,argc的值会根据传入的参数个数确定,至少为 1(表示程序名本身)。argv:是一个字符指针数组,用于存储命令行参数。argv[0]通常是程序的名称,后续元素argv[1]、argv[2]等依次是传入的命令行参数。env:是一个字符指针数组,存储了系统的环境变量。每个元素都是一个以key=value形式表示的环境变量字符串。
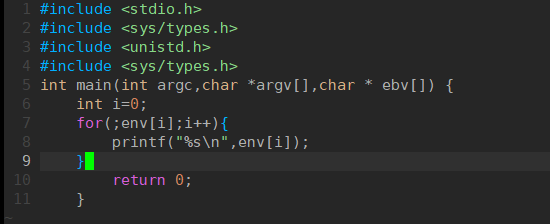
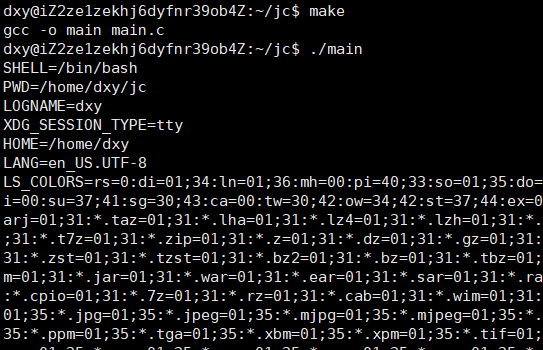



2.我们的环境变量都是继承于bash进程,bash中的变量分成环境变量和本地变量
5.程序地址空间
5.1.虚拟地址空间
观察一个现象:
子进程肯定先跑完,也就是子进程先修改,完成之后,父进程再读取
结果:

但地址值是一样的,说明,该地址绝对不是物理地址!
在Linux地址下,这种地址叫做 虚拟地址
我们在用C/C++语言所看到的地址,全部都是虚拟地址!物理地址,用户一概看不到,由OS统一管理OS必须负责将 虚拟地址 转化成 物理地址 。
结论:用户是拿不到真正的物理地址,我们拿到的是cpu给你的虚拟地址,如何要访问物理内存的话,cpu会管理一个页表,相当一个map一样,可以通过虚拟地址找到真正的地址
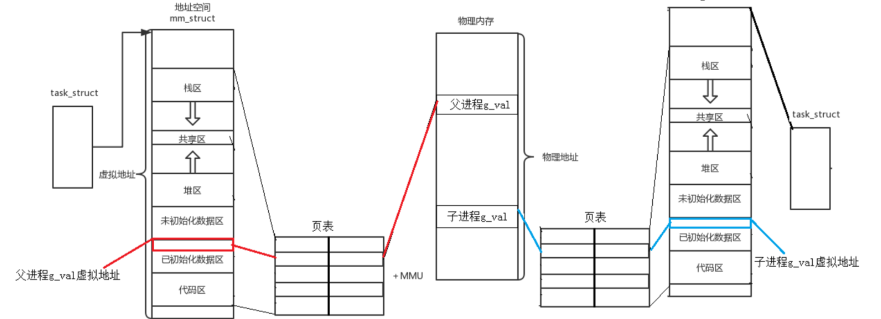
5.2.虚拟地址空间的划分

mm_struct里面存储的都是每一个区域的start位置和end位置
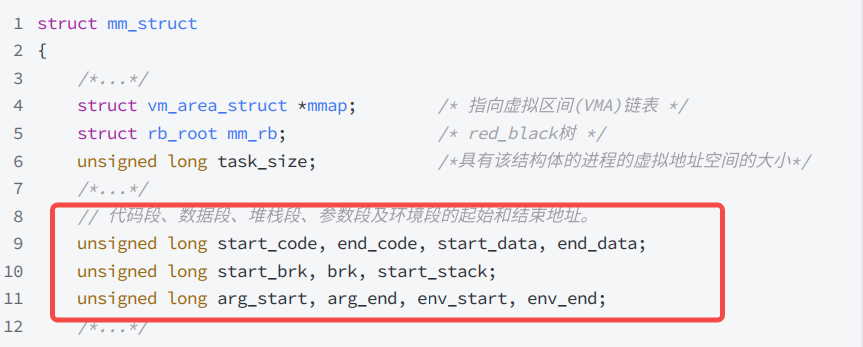
struct vm_area_struct {unsigned long vm_start; // 虚存区起始unsigned long vm_end; // 虚存区结束struct vm_area_struct *vm_next, *vm_prev; // 前后指针struct rb_node vm_rb; // 红黑树中的位置unsigned long rb_subtree_gap;struct mm_struct *vm_mm; // 所属的mm_structpgprot_t vm_page_prot;unsigned long vm_flags; // 标志位struct {struct rb_node rb;unsigned long rb_subtree_last;} shared;struct list_head anon_vma_chain;struct anon_vma *anon_vma;const struct vm_operations_struct *vm_ops; // vma对应的实际操作unsigned long vm_pgoff; // 文件映射偏移量struct file *vm_file; // 映射的文件void *vm_private_data; // 私有数据atomic_long_t swap_readahead_info;
#ifndef CONFIG_MMUstruct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMAstruct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endifstruct vm_userfaultfd_ctx vm_userfaultfd_ctx;
} __randomize_layout;
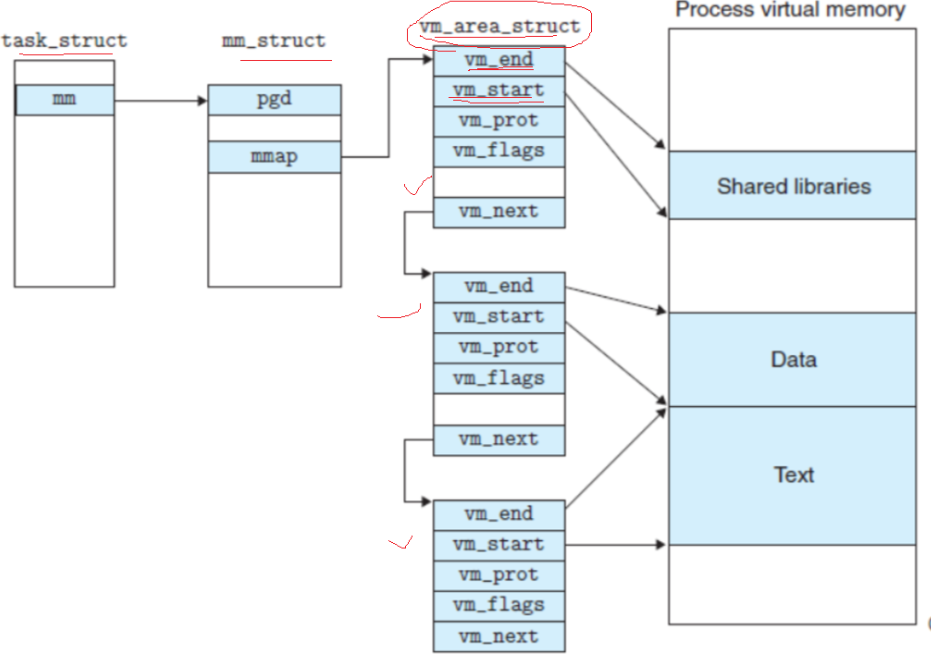
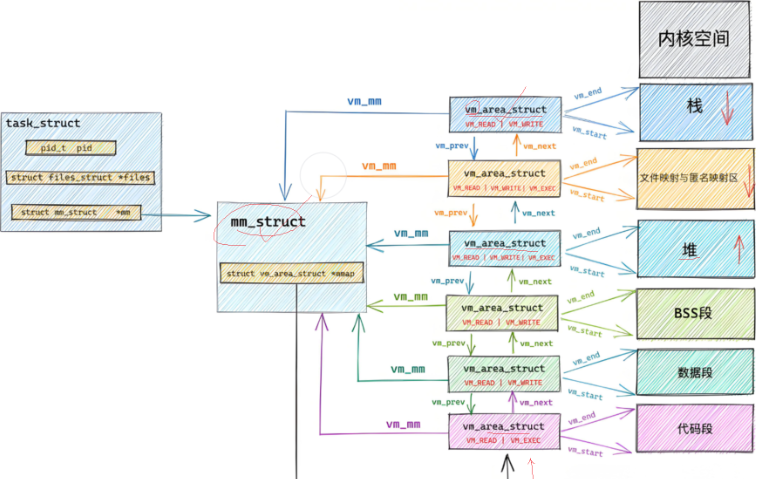
创建虚拟地址空间的意义:
1.此时代码和数据在物理空间上就可以随便存储,只有我们的虚拟空间是连续的就可以(无序==》》有序)
2.在地址转换的过程中,可以对你的地址的合法性和操作做出判断,从而保护了物理空间,
页表其实后面还有一列来标明,用户对这块地址的使用权限

3.让进程管理和内存管理进行一定程度的解耦合
像进行进行进程的调度的时候,我只需要改变虚拟地址即可,内存和磁盘进行内存管理的时候,也只是改变物理空间而已