Conditional Modeling Based Automatic Video Summarization
Conditional Modeling Based Automatic Video Summarization
Authors: Jia-Hong Huang, Chao-Han Huck Yang, Pin-Yu Chen, Min-Hung Chen, Marcel Worring
Deep-Dive Summary:
条件建模自动视频摘要
作者:Jia-Hong Huang, Member, IEEE, Chao-Han Huck Yang, Member, IEEE, Pin-Yu Chen, Member, IEEE, Min-Hung Chen, Member, IEEE, 和 Marcel Worring, Senior Member, IEEE
摘要:视频摘要的目标是自动缩短视频,同时保留传递整体故事所必需的关键信息。视频摘要方法主要依赖视觉因素,例如视觉连续性和多样性,但这些因素可能不足以完全理解视频内容。还需要考虑其他非视觉因素,如趣味性、代表性和故事情节一致性,以生成高质量的视频摘要。目前的方法未能充分考虑这些非视觉因素,导致性能不佳。在这项工作中,我们提出了一种基于人类创建真实视频摘要的见解的新型视频摘要方法。该方法采用条件建模视角,引入了多个有意义的随机变量和联合分布,并设计了一个条件注意力模块,以减轻多模态输入可能导致的性能下降。所提出的视频摘要方法融入了上述创新设计选择,旨在缩小人类生成和机器生成视频摘要之间的差距。大量实验表明,该方法优于现有方法,并在常用的视频摘要数据集上实现了最先进的性能。
索引词:视频摘要,条件建模,视觉因素,潜在因素,条件图
1 引言
视频摘要在提升视频浏览、可搜索性和理解能力方面扮演着关键角色,它使用户能够高效地浏览视频集合并提取相关信息。一个好的摘要是一个简短的视频片段,能够传达原始视频的关键信息和叙事。为了实现这一目标,近年来开发自动视频摘要算法的兴趣激增,相关研究包括 [1], [2], [3], [4], [5], [6], [7], [8], [9], [10]。
通过将自动算法与人类专家进行比较,如 [11], [12], [13], [14], [15], [16] 所建议,可以明显看出人类专家在创建视频摘要时会考虑多种因素。这些因素包括具体的/视觉因素,如视觉连续性和视觉多样性,以及抽象的/非视觉因素,如趣味性、代表性和故事情节一致性。这些因素对视频摘要的最终结果有显著影响,必须加以考虑以确保摘要的质量。然而,当前的视频摘要方法主要依赖于视觉因素,如图1所示,并且往往不考虑或仅以非常有限的方式考虑非视觉因素。不考虑非视觉因素会导致自动视频摘要的性能不佳 [16], [17]。
在本研究中,我们从人类驱动的非视觉因素与最终摘要之间的关系复杂且非确定性的前提出发。因此,我们从条件建模的角度研究这一问题。为了创建模型,我们结合了 [12], [15] 中关于人类如何评估视频摘要质量的见解,如图2所示。我们方法的基础在于数据干预 [19]。研究人员从干预建模技术 [20], [21] 中汲取灵感,并引入代理变量来探索条件学习的条件,以增强模型通过引入额外信息到学习过程中学习关系的能力。我们提出的视频摘要方法纳入了四个重要的随机变量,分别表征视频摘要中的数据干预行为、模型预测、观察因素和未观察因素。为了建模人类摘要评估的见解,提出的方法涉及构建先验联合分布及其后验近似,基于上述四个随机变量。
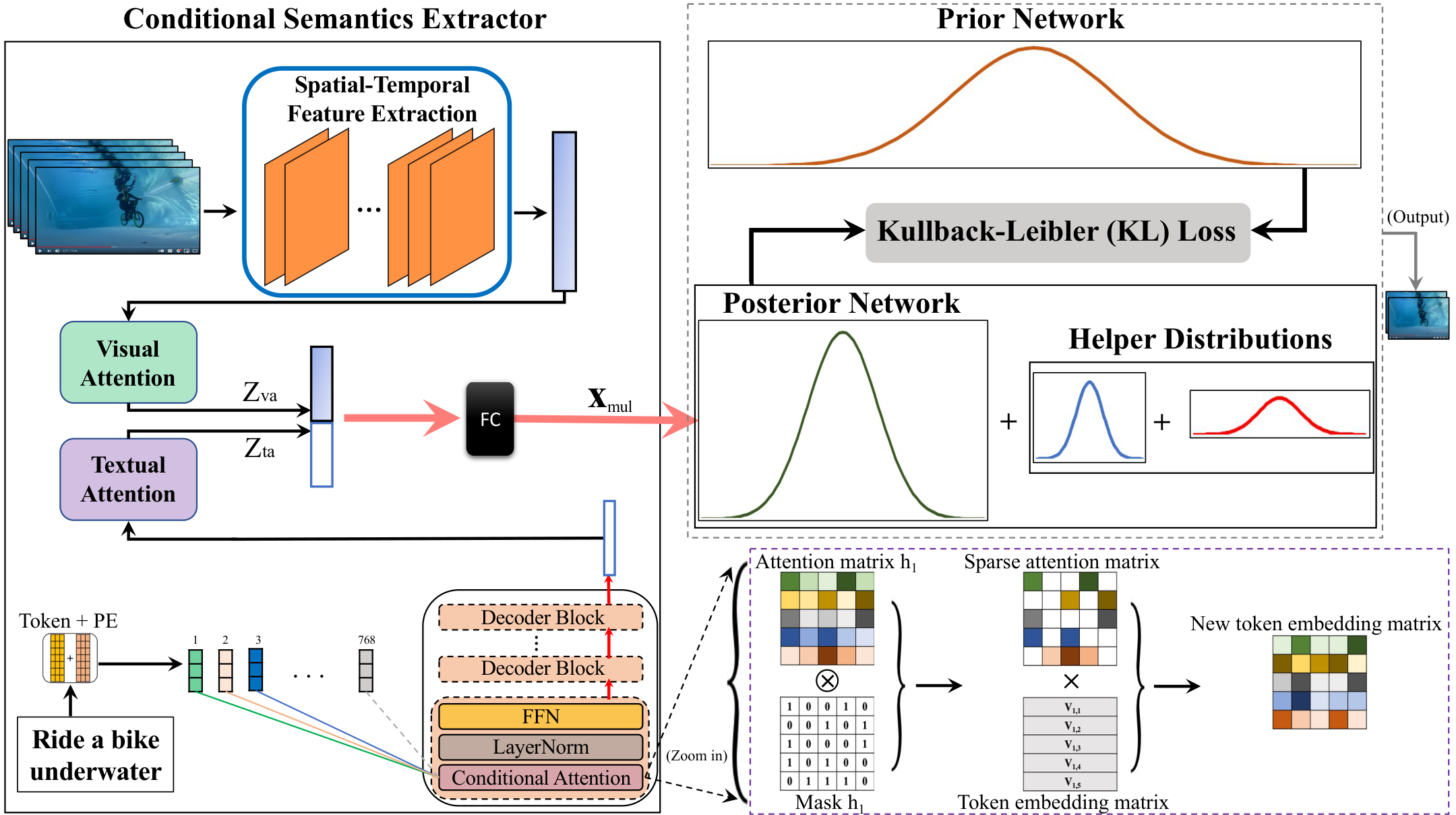
该方法通过最小化先验分布和后验近似之间的距离进行训练。然而,由于视频噪声或运动/镜头模糊等多种因素,预测数据干预和模型结果的行为在实践中可能具有挑战性。为解决这一问题,引入了辅助分布,并创建了一个新的损失项来指导模型学习。当视觉数据伴随文本信息时,额外的输入有时会由于不同模态之间的无效交互而损害模型性能。为了克服这一挑战,引入了条件注意力模块,以有效提炼多模态输入之间的互信息。图3展示了所提出方法的流程图。提出的视频摘要方法结合了上述创新设计选择,即条件建模、辅助分布和条件注意力模块,旨在最小化人类生成和机器生成的视频摘要之间的差距。在常用的视频摘要数据集上进行的大量实验表明,所提出的方法优于现有方法,并实现了最先进的性能。
贡献:
- 提出了一种受人类处理任务方式启发的新方法来建模视频摘要问题。
- 为了有效提取多模态输入之间的交互信息,在存在多种输入模式的情况下引入了条件注意力模块。
- 通过在广泛使用的视频摘要基准数据集上的大量实验验证了所提出方法的有效性。实验结果表明,该方法非常成功,超越了其他方法,在 F1 分数方面达到了最先进的性能。
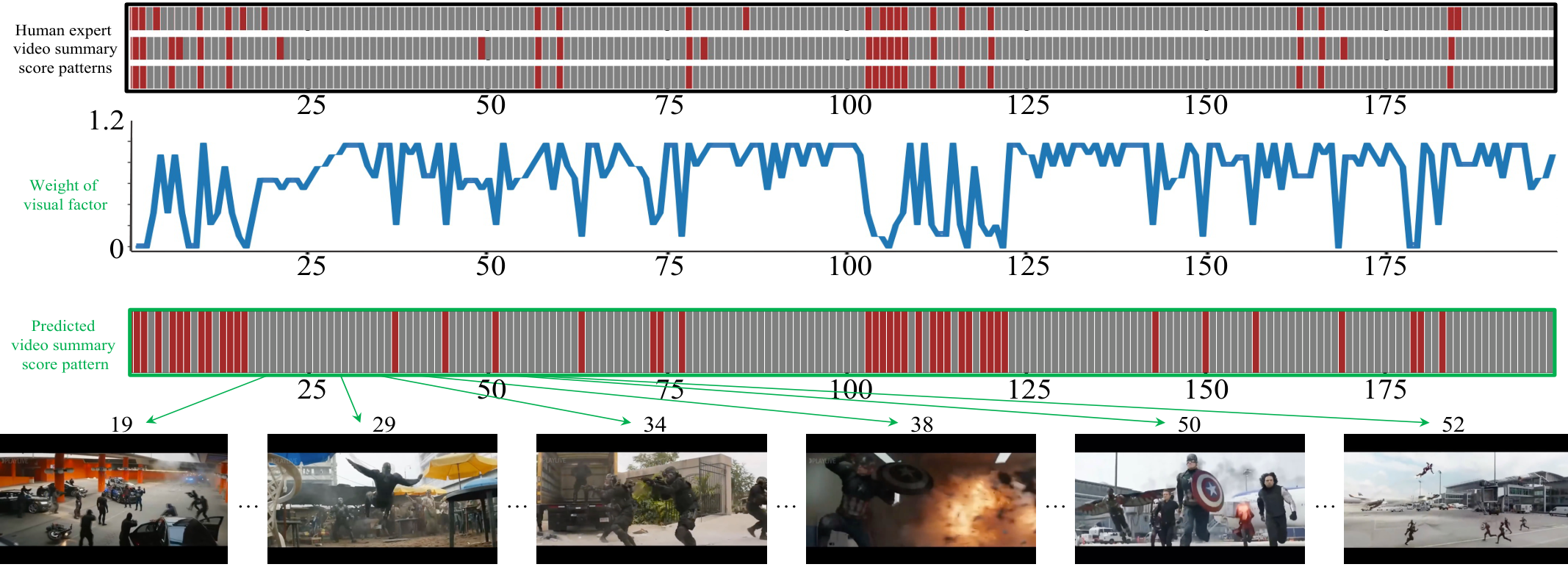
本文的其余部分结构如下:在第2节中,我们回顾了相关工作。第3节介绍了我们提出的方法的细节,包括其设计选择和实现。第4节中,我们评估了我们方法的性能,并将其与现有的最先进方法进行了比较。最后,在第5节和第6节中,我们讨论了我们的发现并指出了未来的研究方向。
与我们先前工作的关系
本文是对我们在2022年国际多媒体与博览会议(ICME)上发表的会议论文[25]的进一步改进。首先,我们引入了一个条件注意力模块(见图3),该模块能够有效地提取多模态输入之间的交互作用。其次,我们使用TVSum [12]、SumMe [15] 和 QueryVS [16] 数据集进行了全面且扩展的实验。第三,我们展示了如何在视频摘要的条件建模方法中将视觉和文本扰动作为数据干预加以整合。
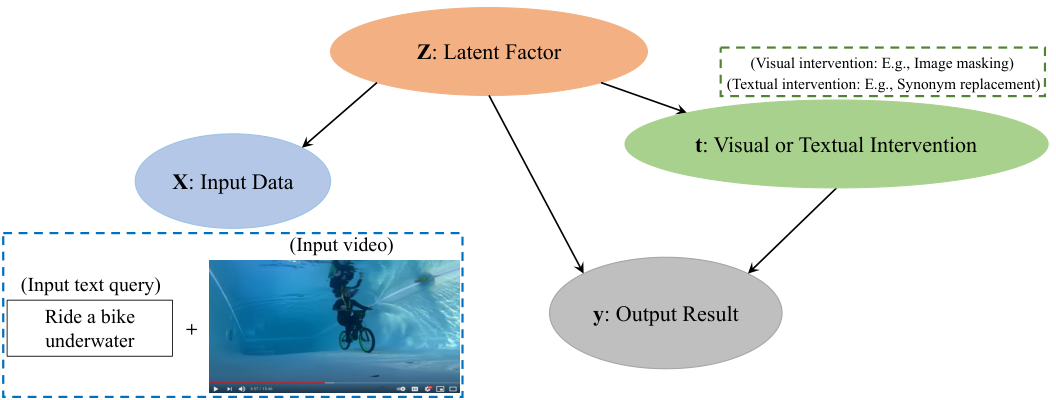
图2:视频摘要中的条件图示例。ttt 是一个干预,例如视觉或文本扰动;yyy 是一个结果,例如视频帧的重要性分数或输入文本查询与视频之间的相关性分数;ZZZ 是一个未观察到的因素,例如代表性、趣味性或故事情节流畅性;XXX 包含对隐藏因素 ZZZ 的噪声视图,例如输入文本查询和视频。视频摘要的条件图有助于构建更具解释性的模型。
此外,本文是对先前工作的全面重组和重写版本。
相关工作
在接下来的部分中,我们将简要回顾与所提议方法相关的研究工作。视频摘要是一项机器学习挑战,可以通过不同的监督方案来解决,例如全监督、弱监督或无监督方法。后续章节将对每个类别中的相关方法进行简要总结。
2.1 仅使用视觉输入的全监督方法
视频摘要通常涉及全监督学习 [14], [15], [26], [27], [28], [29], [30], [31],其中使用人类定义的标签来监督训练阶段。这些方法可以分为三大类:第一类涉及循环神经网络(RNN)/长短期记忆网络(LSTM)方法 [27], [28], [29], [30], [32]。在 [27], [28] 中,采用分层方式使用 RNN 架构来建模视频数据中的时间结构,并选择用于摘要的镜头/片段。在 [29] 中,引入了一种扩张时间关系生成对抗网络,通过 LSTM 和扩张时间关系单元捕获时间依赖性,以解决基于帧的视频摘要问题。[30] 将视频摘要视为序列到序列的学习问题,提出了一个基于 LSTM 的编码器-解码器模型,并带有中间注意力层。随后通过整合语义保持嵌入网络进一步扩展了这种方法 [31]。第二类方法涉及使用确定点过程(DPP)[26], [33]。在 [26] 中,视频摘要被视为结构化预测问题,提出了一种基于深度学习的方法来估计视频帧的重要性。使用 LSTM 建模时间依赖性,并采用 DPP 增加内容多样性。第三类包括不涉及 RNN/LSTM 和 DPP 的方法 [14], [15]。在 [14] 中,引入了一种称为顺序 DPP 的概率模型,用于捕获视频数据的顺序结构并选择多样化的子集。顺序 DPP 承认视频数据中固有的顺序结构,从而解决了标准 DPP 将视频帧视为可随机排列实体的局限性。[15] 提出了一种针对用户视频中有趣事件的自动摘要方法,利用特征预测视觉趣味性,并为摘要选择一组最佳的超帧。
上述全监督方法依赖于完整的人类专家标注来训练模型,这确实带来了出色的性能。然而,获取此类标注可能成本高昂。因此,需要一种更具成本效益的视频摘要解决方案。在这项工作中,我们提出了一种基于条件建模的更具成本效益的替代方法。与现有方法相比,这种方法提供了更好的可解释性、更强的泛化能力、更高的灵活性和增强的决策能力。
2.2 全监督多模态输入方法
许多方法被提出以通过利用视觉输入之外的额外模态来增强视频摘要的效果。这些模态包括观众的评论、视频字幕或其他上下文数据[13]、[16]、[18]、[25]、[34]、[35]、[36]、[37]、[38]、[39]、[40]、[41]、[42]、[43]、[44]、[45]、[46]、[47]、[48]、[49]。例如,[35]提出了一种基于深度学习的方法,利用多模态来总结足球比赛视频。[36]引入了一个类别驱动的视频摘要模型,保留了同一类别摘要中的核心部分。[37]和[38]分别提出了基于强化学习的方法,利用视频级别的标签训练动作分类器,进行动作驱动的视频分段和标记,随后进行类别驱动的视频摘要。[39]和[40]通过最大化视频摘要与视频可用元数据的相关性来生成摘要,将视觉和文本信息投影到一个共同的潜在特征空间。[41]则应用了视觉到文本的映射以及基于语义的视频片段选择,通过自动生成的视频描述与原始描述的匹配来实现,使用语义注意力网络。
上述多模态视频摘要方法利用额外模态来提升模型性能。这些模态的有效融合对于方法成功至关重要。如[13]、[16]、[41]所述,不适当的融合方法可能限制模型充分利用不同模态提供的互补信息的能力。
2.3 弱监督方法
一些视频摘要方法,例如[50]、[51]、[52]、[53]、[54]、[55],采用弱监督学习来克服对大量人工专家标注数据的需求。这些方法利用成本较低的弱标签,例如来自人工专家的视频级别标注来训练模型。尽管弱标签的准确性低于完整的人工专家标注,但它们仍能有效训练视频摘要模型并实现可接受的性能。例如,[50]引入了一种介于全监督学习和无监督学习之间的弱监督方法,利用视频级元数据对视频进行分类,提取3D-CNN特征,并学习一个视频摘要模型用于新视频的分类。[52]提出了一种弱监督方法,结合编码器-解码器架构与软注意力机制以及变分自编码器(VAE),从网络视频中学习潜在语义,通过弱监督语义匹配损失训练视频摘要模型。[51]提出了一种模型,利用第三人称视频的完整标注高光分数和一小部分标注的第一人称视频进行训练,其中仅一小部分第一人称视频带有真实标注。[53]使用强化学习训练视频摘要模型,依赖有限的人工标注和手工设计的奖励,通过分层关键片段选择过程生成最终视频摘要,奖励基于多样性和代表性。
上述弱监督视频摘要方法相较于全监督方法更具成本效益,尽管在性能上可能略逊于后者。
2.4 无监督方法
无监督的视频摘要方法依赖于一个核心理念,即一个好的摘要应当传达视频的精髓,而这种精髓的证据应存在于数据中。因此,我们只需要找到捕捉这些信息的方法 [2], [3], [5], [56], [57], [58], [59], [60], [61], [62], [63]。在 [56] 中,通过群稀疏编码从视频数据中学习一个字典,并通过组合那些无法基于字典稀疏重建的片段来创建摘要。[2] 引入了一种最大二部图寻找算法来识别频繁共现的视觉模式,并通过选择最常共现的镜头来生成摘要。[3] 提出了一种同时捕捉特定和一般特征的视频摘要模型。[57] 提出了一种结合基于 LSTM 的关键帧选择器、可训练的判别器以及变分自编码器(VAE)的模型,通过对抗学习创建摘要。在 [60] 中,提出了一种 VAE-GAN 架构,而在 [61] 中,使用了一种循环一致的对抗学习目标,以最大化摘要和视频之间的互信息。[59] 的一个变体在 [62] 中用确定性注意力自编码器替换了 VAE,从而实现更有效的关键片段选择。[5] 提出了一种新的视频数据摘要公式,通过对抗训练对摘要映射施加多样性约束。
现有的无监督方法在训练阶段不依赖于人类专家标注或伪标签进行监督。因此,它们的性能往往落后于全监督方法。相比之下,我们提出的方法同时利用人类专家标注和伪标签监督来获得优势。我们的方法旨在推断输入数据与期望摘要之间的因果关系,这在当前的基于机器学习的视频摘要方法中往往被忽视。我们的方法具有通用性,可根据不同的实验设置应用于全监督和弱监督方案。
3 方法论
视频摘要是自动创建视频的浓缩表示的过程,旨在捕捉原始视频中最重要的信息内容。给定一个输入视频 x=(c0,c1,...,cn)x = (c_0, c_1, ..., c_n)x=(c0,c1,...,cn),包含 nnn 帧,我们将视频摘要视为寻找一个分类函数 f:yi=f(ci)f : y_i = f(c_i)f:yi=f(ci) 的问题,该函数用于确定帧 cic_ici 是否与摘要相关(yi=1y_i = 1yi=1)或无关(yi=0y_i = 0yi=0)。分类问题受到用户定义的摘要预算 NyN_yNy 的约束,满足 ∑i=0nyi≤Ny\sum_{i=0}^n y_i \leq N_y∑i=0nyi≤Ny。需要注意的是,摘要预算被视为用户定义的超参数 [16]。在本研究中,我们的目标是将视频摘要建模为条件学习问题。我们提出的方法利用条件建模来增强基于机器学习的视频摘要模型的条件推理能力。接下来,我们将深入探讨所涉及的组成部分。我们引入了代理变量 XXX 和隐藏因子变量 ZZZ。在从噪声干预中吸收信息的过程中 [19], [22], [23], [64], [65], [66], [67], [68],模型的首要任务是提升其对联合分布 p(X,Z)p(X, Z)p(X,Z) 的推理能力,该分布涵盖了代理变量和隐藏变量。随后,模型利用这种增强的理解,巧妙地运用这些知识来微调和调整隐藏因子变量。我们首先介绍条件建模的假设。然后,我们引入了四个随机变量:yyy、ttt、XXX 和 ZZZ,它们分别表征模型的预测行为、数据干预以及观察到的和未观察到的因子。具体来说,从视频摘要的建模角度看,随机变量 XXX 表示带有或不带有文本查询的输入视频。变量 ttt 表示视觉或文本干预分配,yyy 表示输入基于文本的查询与视频帧之间的相关性评分,或者视频帧的重要性评分。视频摘要基于 yyy 创建。之后,我们将推导训练目标,结合辅助分布和提出的条件注意力模块。所提出的方法主要由两个概率网络组成:先验网络和后验网络。有关概述,请参阅图 3。
3.1 假设
通常情况下,现实世界观察研究的条件建模是复杂的 [19], [69], [70], [71]。在噪声干预下条件建模的既有努力 [19], [72], [73] 的基础上,在建模视频摘要问题时提出了两个假设。首先,是否具有视觉/文本干预 ttt 的信息是二元的。其次,来自深度神经网络(DNN)的观察数据 (X,t,y)(X, t, y)(X,t,y) 足以近似恢复未观察因子变量 ZZZ、观察因子变量 XXX、干预 ttt 以及结果 yyy 的联合分布 p(Z,X,t,y)p(Z, X, t, y)p(Z,X,t,y)。所提出的方法建立在多个概率分布之上,具体将在接下来的小节中描述。
3.2 视频摘要的条件建模
在训练我们的模型时,我们假设拥有一组视频数据集。令 xix_ixi 表示输入视频以及一个可选的基于文本的查询,iii 是该集合中的索引,zzz 表示潜在因子,t∈{0,1}t \in \{0, 1\}t∈{0,1} 表示干预分配,yiy_iyi 表示结果。为了训练模型,我们假设拥有一组视频数据集,其中 xix_ixi 表示输入视频及可选文本查询,zzz 为潜在因子,t∈{0,1}t \in \{0, 1\}t∈{0,1} 为干预分配,yiy_iyi 为结果。
先验概率分布:先验网络以潜在变量 zzz 为条件,主要包含以下组成部分:
(i) 潜在因子分布:
P(Zi)⟶←∏z∈ZiN(z∣μ≠∅,O2⟶→1),\mathcal{P}(Z_{i})\stackrel{\leftarrow}{\longrightarrow}\prod_{z\in\mathbf{Z}_{i}}\mathcal{N}(\mathcal{z}|\mu\not=\emptyset,\mathcal{O}^{2}\stackrel{\rightarrow}{\longrightarrow}\atop1\Big), 1),P(Zi)⟶←∏z∈ZiN(z∣μ=∅,O2⟶→
其中 N(⋅∣μ,σ2)\mathcal{N}(\cdot|\mu, \sigma^2)N(⋅∣μ,σ2) 表示高斯分布,zzz 是潜在变量,属于 ZiZ_iZi 的元素,均值 μ\muμ 和方差 σ2\sigma^2σ2 遵循文献 [74] 的设置,即 μ=0\mu=0μ=0,σ2=1\sigma^2=1σ2=1。
(ii) 条件数据分布:
p(xi∣zi)=∏x∈μxip(x∣zi),p(\mathbf{x}_{i}|\mathbf{z}_{i})=\prod_{x\in{\mathbf{\mu}}\mathbf{x}_{i}}p(x|\mathbf{z}_{i}), p(xi∣zi)=x∈μxi∏p(x∣zi),
其中 p(x∣zi)p(x|z_i)p(x∣zi) 是一个合适的概率分布,条件为 zzz,且 xxx 是 xix_ixi 的元素。
(iii) 条件干预分布:
p(ti∣zi)⟶BerrOU∣1∣(σ(fθ1(zi))),p(t_{i}|{\bf z}_{i})\stackrel{\bf}{\longrightarrow}{\bf Ber}{\bf r}_{\bf O U}|1|(\sigma(f_{\theta_{1}}(z_{i}))), p(ti∣zi)⟶BerrOU∣1∣(σ(fθ1(zi))),
其中 σ()\sigma()σ() 是 logistic 函数,Bernoulli()\text{Bernoulli}()Bernoulli() 表示离散结果的伯努利分布,fθ1()f_{\theta_1}()fθ1() 是由参数 θ1\theta_1θ1 参数化的神经网络。
(iv) 条件结果分布:
p(yi∣zi,ti)=σ(tifθ2(zi)+(1−ti)fθ3(zi)),p(y_{i}|\mathbf{z}_{i},t_{i})=\sigma(t_{i}f_{\theta_{2}}(\mathbf{z}_{i})+(1-t_{i})f_{\theta_{3}}(\mathbf{z}_{i})), p(yi∣zi,ti)=σ(tifθ2(zi)+(1−ti)fθ3(zi)),
其中 fθ2()f_{\theta_2}()fθ2() 和 fθ3()f_{\theta_3}()fθ3() 是分别由参数向量 θ2\theta_2θ2 和 θ3\theta_3θ3 参数化的神经网络。在本研究中,yyy 被定制用于分类问题。
后验概率分布:由于缺乏对潜在因子的先验知识,我们需要在学习模型参数 θ1\theta_1θ1、θ2\theta_2θ2 和 θ3\theta_3θ3 时对其进行边缘化(参见公式 (3) 和 (4))。非线性神经网络函数使得推断变得棘手。因此,采用变分推断 [74] 以及后验网络。这些神经网络输出给定观测变量下潜在变量 zzz 的固定形式后验近似的参数。类似于 [19]、[75],在本研究中,提出的后验网络以观测为条件。同时,zzz 的真实后验依赖于 xxx、ttt 和 yyy。因此,采用以下定义的后验近似来构建后验网络:
KaTeX parse error: Expected 'EOF', got '}' at position 195: …d{array}\right|}̲}\\ {{\left|\ph…
其中 gΦ()g_\Phi()gΦ() 表示具有可学习参数 Φk\Phi_kΦk 的神经网络,k=0,1,2,3,4k=0,1,2,3,4k=0,1,2,3,4,且 gΦ0(xi,yi)g_{\Phi_0}(x_i, y_i)gΦ0(xi,yi) 是一个共享表示。
3.4 条件注意力模块
在文本输入并不总能提升模型性能的情况下,由于从视觉和文本输入中提取互信息的效率不高(参考文献[12]、[16]),本文提出了一种基于自注意力的条件注意力模块。该模块建立在Transformer块(参考文献[76])之上。传统的Transformer在每一层中利用所有token进行注意力计算,而本文提出的条件注意力模块的设计理念是有效利用较少但信息量较大的token来计算注意力图。传统注意力矩阵 A∈Rn×n\mathcal{A} \in \mathbb{R}^{n \times n}A∈Rn×n 的计算基于点积(参考文献[76]):
A=softmax(QKTd);Q=TWq,K=TWk,\mathcal{A}=\mathrm{softmax}\left(\frac{\mathbf{Q}\mathbf{K}^{\mathsf{T}}}{\sqrt{d}}\right);\mathbf{Q}=\mathbf{T}\mathbf{W}_{q},\mathbf{K}=\mathbf{T}\mathbf{W}_{k}, A=softmax(dQKT);Q=TWq,K=TWk,
其中查询矩阵 Q∈Rn×d\mathbf{Q} \in \mathbb{R}^{n \times d}Q∈Rn×d 和键矩阵 K∈Rn×d\mathbf{K} \in \mathbb{R}^{n \times d}K∈Rn×d 通过输入token的线性投影生成,nnn 表示输入token的总数,ddd 表示嵌入维度,dmd_mdm 表示输入token的维度。新的值矩阵 Vnew∈Rn×d\mathbf{V}_{\mathrm{new}} \in \mathbb{R}^{n \times d}Vnew∈Rn×d 可通过以下公式得到:
KaTeX parse error: Undefined control sequence: \slash at position 106: …mathbb{R}^{n}\!\̲s̲l̲a̲s̲h̲{\mathrm{M}}_{v…
在传统注意力机制中(参考文献[76]),注意力矩阵基于所有查询-键对的计算。然而,为了提高计算效率,本文提出的条件注意力模块仅对每个查询使用前 kkk 个最相似的键和值来计算条件注意力矩阵。类似于参考文献[76],所有查询和键通过点积计算,然后按行选取前 kkk 个元素进行softmax计算。在条件注意力模块中,值矩阵 Vk∈Rn×d\mathbf{V}_k \in \mathbb{R}^{n \times d}Vk∈Rn×d 定义为:
Ψκ=softmax(Tκ(AV))Ψnewdˉ\begin{array}{c}{{\displaystyle\Psi_{\kappa}\ =\,\mathrm{softmax}\left(\mathcal{T}_{\kappa}(\mathcal{A}\mathcal{V})\right)\Psi_{\mathrm{new}}}}\\ {{\displaystyle\bar{\sqrt{d}}}}\end{array} Ψκ =softmax(Tκ(AV))Ψnewdˉ
其中 Tk()\mathcal{T}_k()Tk() 表示按行选取前 kkk 个元素的操作符,T()\mathcal{T}()T() 定义为:
KaTeX parse error: Double subscript at position 132: …ystyle-\infty}}_̲{\begin{array}{…
随后,V\mathbf{V}V 可进一步用于生成条件注意力模块的输出 Xmul\mathbf{X}_{\mathrm{mul}}Xmul,其计算过程定义如下:
Zta=Textatten(FFN(LayerNorm(Vs)),{\cal Z}_{\mathrm{ta}}=\,\mathrm{Textatten}(\mathrm{FFN}(\mathrm{LayerNorm}(\mathrm{V}_{\mathrm{s}})), Zta=Textatten(FFN(LayerNorm(Vs)),

图4:一个数据集示例,展示了“椒盐噪声”的视觉干预。

其中 LayerNorm()\mathrm{LayerNorm}()LayerNorm() 表示层归一化,FFN()\mathrm{FFN}()FFN() 表示前馈网络,TextAtten()\mathrm{TextAtten}()TextAtten() 表示基于元素级乘法的文本注意力机制。
Zva=Visualatten(C3D(x)),{\cal Z}_{\mathrm{va}}=\mathrm{Visualatten}(C3D({\bf x})), Zva=Visualatten(C3D(x)),
其中 x\mathbf{x}x 表示输入视频,C3D()C3D()C3D() 表示时空特征提取操作,例如输入视频的3D版本ResNet-34(参考文献[77]、[78]),VisualAtten()\mathrm{VisualAtten}()VisualAtten() 表示基于元素级乘法的视觉注意力机制。
Xmul=FC(Zta(x^)Zva),{\bf X}_{\mathrm{mul}}=\mathrm{FC}(Z_{\mathrm{ta}}\ (\hat{\bf x})\;Z_{\mathrm{va}}), Xmul=FC(Zta (x^)Zva),
其中 x^\hat{\bf x}x^ 表示特征拼接,FC()\mathrm{FC}()FC() 表示全连接层。需要注意的是,条件注意力模块的输出 Xmul\mathbf{X}_{\mathrm{mul}}Xmul 是基于多模态输入方案的后验网络的输入。
与参考文献[16]中视频摘要生成的最后步骤类似,在提出的条件视频摘要模型端到端训练完成后,根据生成的评分标签,从原始输入视频中选择一组视频帧,形成最终的视频摘要。
4 实验
在本节中,首先详细描述了实验设置和使用的数据集。然后,评估、分析并比较了所提出的视频摘要方法的有效性,与现有的最先进方法进行了对比。最后,如图2所示,展示了用于视频摘要的条件图,以证明建模可解释性的改进。

4.1 实验设置与数据集准备
实验设置
本文考虑了以下三种场景。首先,在完全监督学习方案中,使用一整套带有专家标注的数据(即帧级标签)来训练所提出的模型。其次,在具有多模态输入的完全监督场景中,将基于文本的查询作为额外的输入。第三,根据[12]的作者实证发现,两秒的视频片段长度适合捕捉视频的局部上下文,并具有良好的视觉连贯性。因此,基于给定的帧级评分,每两秒生成一个视频片段级评分。片段级标签可以被视为弱监督学习方案中的一种弱标签[52]、[53]、[79]。
视频摘要数据集
为了确保与现有视频摘要方法的公平比较,我们主要在广泛使用的数据集上评估所提出的方法,包括TVSum [12]、QueryVS [16] 和 SumMe [15]。TVSum 数据集由[12]提出,包含来自不同类型的50个视频,包括纪录片、教程视频、新闻、第一人称视频和视频博客。每个视频有一个对应的标题,可作为基于文本的查询输入。该数据集由每视频20名众包工作者进行标注。TVSum 中视频长度范围为2到10分钟,专家标注的帧级重要性评分范围为1到5。QueryVS 由[16]引入,是一个更大的数据集,包含190个视频。QueryVS 中每个视频基于每秒一帧(fps)的帧率进行帧级标注,视频长度范围为2到3分钟,专家标注的帧级重要性评分范围为0到3。每个视频基于给定的文本查询进行检索。SumMe 由[15]提出,是一个包含25个视频的基准数据集。每个视频至少有15个人类摘要(总共390个),通过受控的心理学实验获取,为视频摘要模型的评估提供了一种客观方式,并为视频摘要研究提供了新见解。SumMe 中视频时长范围为1到6分钟,专家标注的重要性评分范围为0到1。需要注意的是,SumMe 不用于多模态视频摘要,因此在该数据集上评估模型时没有文本输入。这些数据集中的视频以1 fps 采样,输入图像大小为 224×224,具有 RGB 通道。每个通道通过标准差 =(0.2737,0.2631,0.2601)=(0.2737, 0.2631, 0.2601)=(0.2737,0.2631,0.2601) 和均值 =(0.4280,0.4106,0.3589)=(0.4280, 0.4106, 0.3589)=(0.4280,0.4106,0.3589) 进行归一化。使用 PyTorch 和 NVIDIA TITAN Xp GPU 实现并训练模型,训练60个 epoch,学习率为 1e−61e-61e−6。采用 Adam 优化器[80],超参数设置为 e=1e−8e=1e-8e=1e−8,β1=0.9\beta_1=0.9β1=0.9,β2=0.999\beta_2=0.999β2=0.999。大规模基于查询的视频摘要数据集由于创建成本高昂,因此常用数据集如 TVSum、QueryVS 和 SumMe 规模相对较小。为了验证我们提出的条件建模方法,我们基于 TVSum、QueryVS 和 SumMe 分别引入了三个新的视频摘要数据集。
条件学习数据集
研究人员在观察人们的写作行为时,注意到一些常见现象,例如同义词替换、句子中意外遗漏某些单词等[81]、[82]。受此启发,我们随机选择其中一种行为,例如句子中意外遗漏某些单词,并编写一个文本干预函数来模拟这种行为。同样,我们知道人们在日常生活中制作视频时,可能会存在一些视觉干扰,例如椒盐噪声、图像遮罩、模糊等。我们也选择了其中一些,例如模糊和椒盐噪声,并制作一个视觉干预函数进行模拟。基于可控的视觉和文本干预模拟函数,我们可以创建带有视觉和文本干预的条件视频摘要数据集。数据集的制作步骤如下:首先,从原始训练、验证和测试集中随机选择50%的(视频,查询)数据对;其次,对于每个选定的视频,随机为30%的视频帧和对应的查询分配0或1个干预标签。图4和图5分别是带有视觉干预和文本干预的数据集示例。需要注意的是,在现实世界中存在各种可能的干扰,上述随机选择的视觉和文本干预只是其中的几种,其他干预也可以用于所提出的方法。
4.2 评估与分析
评估协议:根据现有研究[12]、[15]、[16]、[17]、[18]的设置,我们在相同条件下对所提出的方法进行评估。TVSum、QueryVS 和 SumMe 数据集分别被随机分为五份。其中,80% 的数据集用于训练,剩余部分用于评估。我们运行模型五次,并报告平均结果[16]、[17]、[18]。采用 F1 分数[12]、[15]、[17]、[92] 来衡量生成的视频摘要 S:S:S: 与真实视频摘要 SSS 对于视频 xxx 的匹配程度。F1 分数基于精确率和召回率定义。基于 S:S:S: 和 SSS 之间时间重叠的精确率 PPP 和召回率 RRR 计算如下:
P=∣si∩s^i∣∣si∣,R=∣si∩s^i∣∣si∣,F1=2PRP+R.P=\frac{|{\sf s}_{i}\cap\hat{\mathfrak{s}}_{i}|}{|{\sf s}_{i}|}, \quad R=\frac{|{\sf s}_{i}\cap\hat{\mathfrak{s}}_{i}|}{|{\sf s}_{i}|}, \quad F_{1}=\frac{2{\cal P}R}{P+R}. P=∣si∣∣si∩s^i∣,R=∣si∣∣si∩s^i∣,F1=P+R2PR.
对于具有多个人工标注视频摘要的视频,指标的计算遵循[17]、[18]的方法。
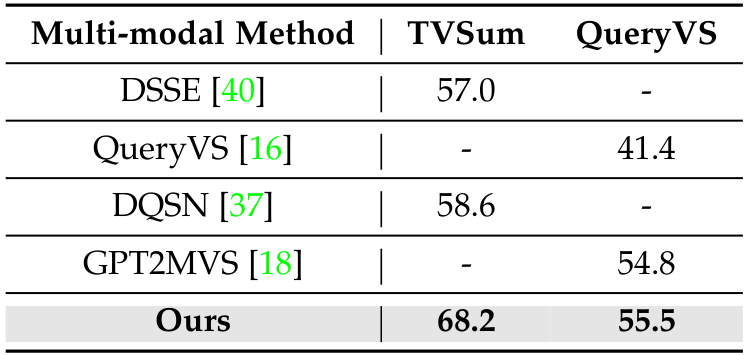

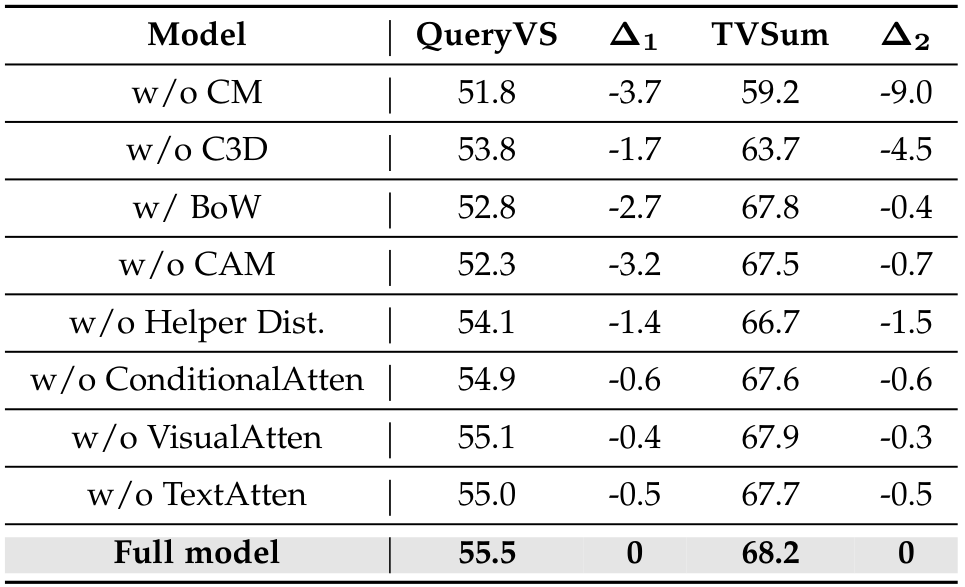
TABLE 4: Ablation study of the proposed method for video summarization. “w/o” indicates a model without using that specific component. “w/o CM” indicates conditional modeling is used. “w/o C3D” denotes 2D CNN is used for video encoding. “w/ BoW” indicates bag-of-word is used for query embedding instead of the Conditional Attention Module (CAM). “w/o CAM” means the input textual query contributions are not introduced. △1 and △2 show the F1-score difference, compared with the full model.
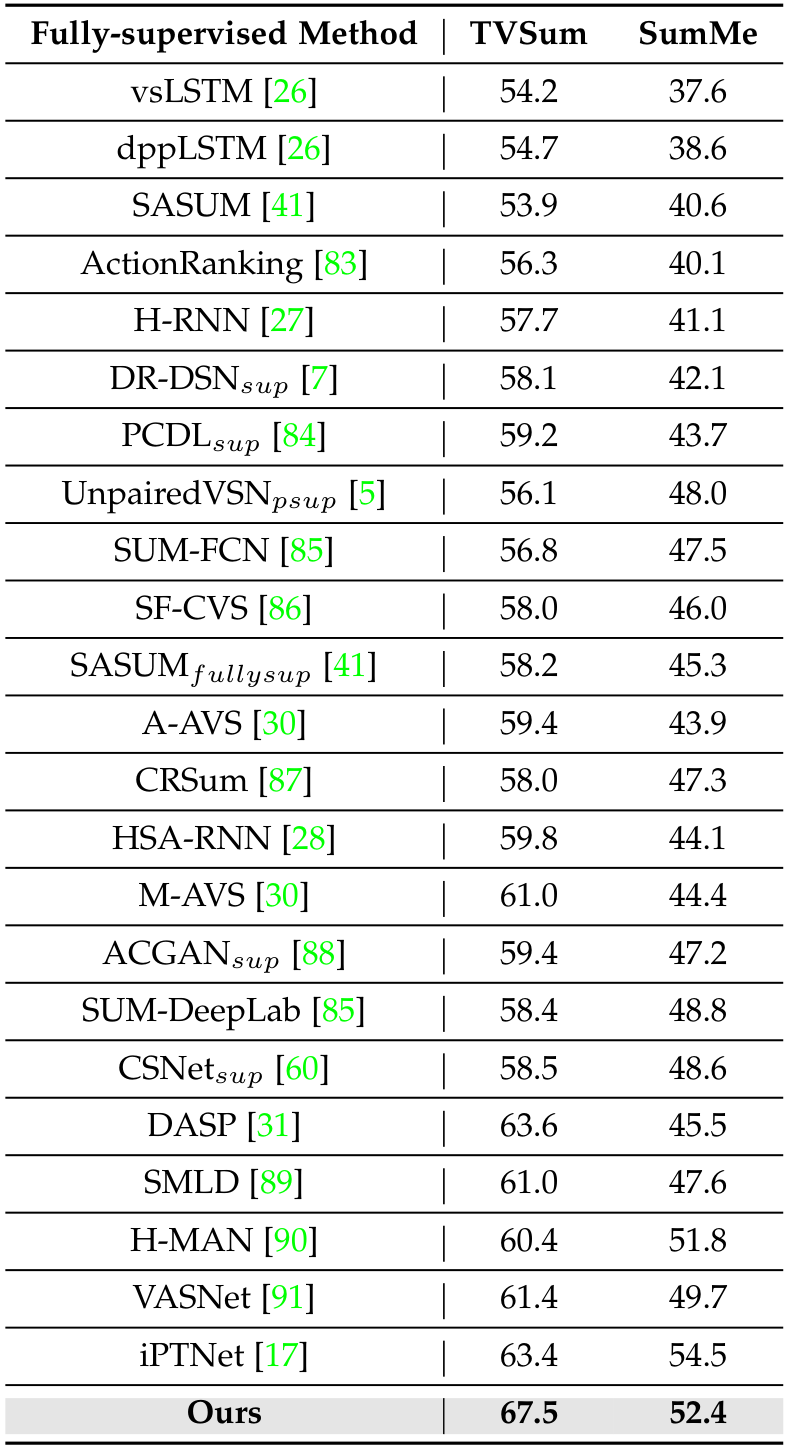
与最先进方法的比较:在表1、表2、表3 和图6中,所提出的方法与基于不同监督方案的现有最先进(SOTA)模型进行了比较。结果表明,所提出的模型优于现有的 SOTA 方法。原因是引入的条件建模增强了视频摘要模型的条件推理能力,即帮助揭示引导过程并导致结果的因果关系。
消融研究:为了验证所提出方法的有效性,消融研究结果显示在表4中。结果表明,引入的组件有效提升了模型性能。原因如下:(i) 所提出的条件注意力模块有效捕捉了所提出方法中各组件的交互;(ii) 存在显式/隐式因素会影响视频摘要模型的条件推理,条件注意力有效利用了这些因素的因果贡献;(iii) 基于条件注意力的上下文化查询表示在文本查询嵌入方面比 BoW[93]、[94]更有效;(iv) 文本查询对模型性能有帮助;(v) 在视频编码方面,3D CNN 比 2D CNN 更有效;(vi) 辅助分布改善了数据干预的行为预测和模型的结果。
所提出条件建模的有效性分析:由于所提出方法与现有方法的主要区别在于条件建模,表1、表2 和表3 中的结果可以视为基于不同监督方案的条件学习的消融研究。结果表明,引入的条件建模是有效的。所提出方法的关键组件之一是辅助任务/分布。引入辅助任务的目的是帮助模型学习诊断输入,以便在存在无关干预的情况下仍能正确推断主任务(即视频摘要推断)。在训练阶段,提供真实的二元因果标签以教导模型输入是否受到干扰。如果模型无论是否存在干预都能表现良好,意味着模型有能力分析输入以在主任务中表现良好,换句话说,表明模型具有条件推理能力。在某种意义上,也可以认为所提出的条件建模使模型变得更加鲁棒。然而,鲁棒性分析的目的是对输入施加非常小的干预以分析系统[95-105],而所提出条件建模中的输入干预旨在帮助模型学习系统中元素之间的关系。因此,条件建模中干预的强度不一定是小的,因为目标是增强模型对因果关系的理解。
5 讨论
为什么视频摘要可以从条件建模中受益?以下是几个主要原因:
- 提高可解释性:条件建模提供了一个理解系统中不同变量之间关系的框架,使得构建更具可解释性的视频摘要模型成为可能。通过明确建模视频中不同元素(如对象、事件或场景)之间的关系,我们可以更好地洞察影响视频摘要整体内容和结构的因素。
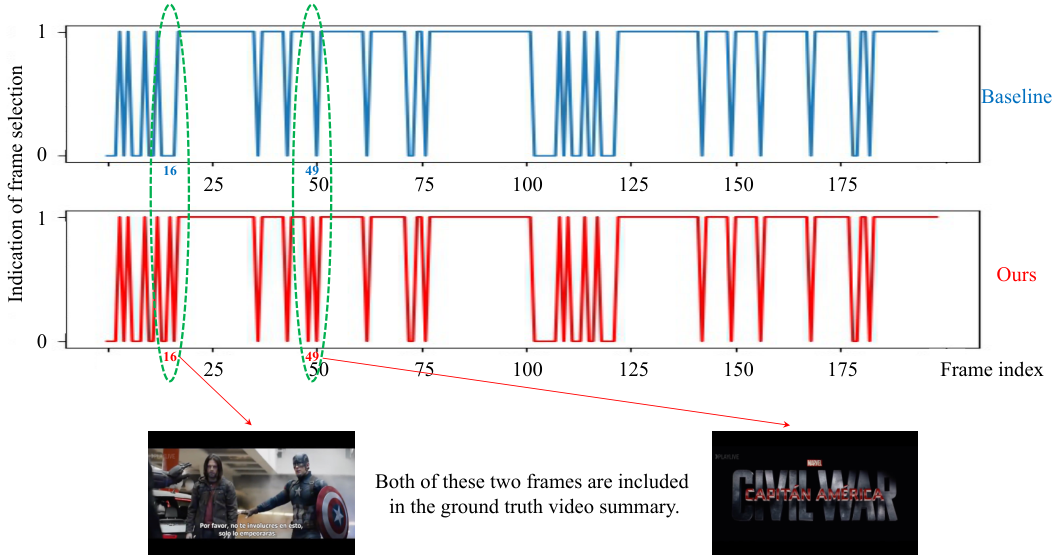
由于所提出的方法与视频摘要的条件图相关联,建模的可解释性可以从图中受益。在引入的条件视频摘要模型中,我们考虑了影响生成良好视频摘要的潜在因素,将其视为因果效应。具体来说,我们利用条件/因果图形模型来解决视频摘要问题。视频摘要中的建模可解释性在图2中有所展示。
-
更好的泛化能力:条件建模有助于构建更具泛化能力的视频摘要模型,这些模型可以在不同的视频领域和情境中表现良好。通过建模不同变量之间的因果关系,我们可以捕捉到支配系统行为的潜在机制,并利用这些知识设计更有效、更鲁棒的视频摘要模型。
-
更高的灵活性:条件建模为构建视频摘要模型提供了一个灵活的框架,可以轻松适应不同的场景和情境。通过明确建模不同变量之间的关系,我们可以根据新的观察或底层数据的变化来修改和优化模型,而无需从头开始重新训练整个模型。
-
更好的决策能力:条件建模有助于构建能够做出更明智、更准确决策的视频摘要模型,决定摘要中应包含哪些内容。通过建模视频不同元素之间的因果关系,我们可以更好地理解不同因素(如视觉因素、语义信息或时间动态)如何影响摘要的整体内容和结构,并利用这些知识做出更明智的决策,确定包含和排除的内容。
所提出方法的主要局限性:一般来说,训练所提出的条件模型需要标注数据。因此,所提出的方法不能被视为无监督的视频摘要方法。虽然该方法表现良好,但在现实世界中部署时,标注数据的成本不容忽视。在实践中,弱监督模型是平衡性能和部署成本的一个好方法。参见表3。
6 结论
总之,视频摘要旨在自动缩短视频,同时保留传达视频整体故事所需的基本信息。虽然现有方法主要依赖于视觉因素,如连续性和多样性,但它们可能忽略了重要的非视觉因素,如趣味性、代表性和故事情节的一致性。这种局限性可能导致在生成高质量视频摘要时的性能不佳。为了解决这些问题,本文提出了一种新的视频摘要方法。借鉴人类创建真实视频摘要的洞察,该方法采用条件建模视角,并引入有意义的随机变量和联合分布来捕捉视频摘要的关键组成部分。使用辅助分布来增强模型训练,并设计了一个条件注意力模块来有效处理多模态输入。这些创新设计选择旨在缩小人类生成和机器生成视频摘要之间的差距。所提出的视频摘要方法优于现有技术,并在常用的视频摘要数据集上实现了最先进的性能。此外,由于条件图改善了模型决策过程的理解,该方法增强了可解释性。这种增加的可解释性对于建立对自动化机器学习决策系统的信任至关重要。随着视频内容的快速增长,所提出的视频摘要方法有潜力显著提高视频探索效率。通过生成简洁而信息丰富的视频摘要,它使用户能够高效处理和理解大量视频数据,促进在各种应用中更好的决策和探索。
致谢
该项目获得了欧盟“地平线2020”研究与创新计划的资助,资助协议号为玛丽·斯克沃多夫斯卡-居里奖学金协议No765140。
Original Abstract: The aim of video summarization is to shorten videos automatically while
retaining the key information necessary to convey the overall story. Video
summarization methods mainly rely on visual factors, such as visual
consecutiveness and diversity, which may not be sufficient to fully understand
the content of the video. There are other non-visual factors, such as
interestingness, representativeness, and storyline consistency that should also
be considered for generating high-quality video summaries. Current methods do
not adequately take into account these non-visual factors, resulting in
suboptimal performance. In this work, a new approach to video summarization is
proposed based on insights gained from how humans create ground truth video
summaries. The method utilizes a conditional modeling perspective and
introduces multiple meaningful random variables and joint distributions to
characterize the key components of video summarization. Helper distributions
are employed to improve the training of the model. A conditional attention
module is designed to mitigate potential performance degradation in the
presence of multi-modal input. The proposed video summarization method
incorporates the above innovative design choices that aim to narrow the gap
between human-generated and machine-generated video summaries. Extensive
experiments show that the proposed approach outperforms existing methods and
achieves state-of-the-art performance on commonly used video summarization
datasets.
PDF Link: 2311.12159v1
部分平台可能图片显示异常,请以我的博客内容为准
