Ethereum: L1 与 L2 的安全纽带, Rollups 技术下的协作与区别全解析
引言:一个常见的困惑
“等一下,如果 Arbitrum 和 Optimism 这些 L2 (Layer 2) 网络有自己的原生代币,甚至还有负责排序交易的节点,那它们不就和以太坊、Solana 这些 L1 (Layer 1) 公链一样了吗?它们之间到底是怎么协作的?L2 的数据是独立的吗?”
如果你曾有过这样的疑问,恭喜你,你已经触及到了 L1 与 L2 关系的核心。从表面上看,一个活跃的 L2 生态确实很像一个独立的区块链。但实际上,它们的底层逻辑和安全保障与 L1 紧密相连,形成了一种巧妙的共生关系。
今天,我们就来彻底讲清楚 L1 和 L2 究竟是如何集成的,以及 L2 的“原生代币”和“验证节点”到底扮演了什么角色。
L1 与 L2:老板与得力助手的关系
我们可以用一个简单的比喻来理解 L1 和 L2 的关系:
- L1 (以太坊主网):就像一位能力超群但分身乏术的大老板。他负责最终的决策和安全保障,确保公司的每一笔账目(交易)都绝对安全、不可篡改。但由于他太受欢迎,所有事情都找他审批,导致他的办公桌前排起了长队,处理每件事的成本(Gas 费)也水涨船高。
- L2 (扩展层):就像大老板雇佣的一位或多位得力助手。助手们在自己的办公室里,批量处理各种日常事务(执行交易),然后把处理好的一大堆文件(交易批次)整理成一份简洁的报告,交给老板最终签字确认。
通过这种方式,公司(整个以太坊生态)的运行效率大大提升,而最终的安全性和权威性依然由大老板(L1)来保障。L2 的核心目标就是:在不牺牲 L1 安全性的前提下,为用户提供更快、更便宜的交易体验。
集成核心:Rollups 技术如何“打报告”
L2 与 L1 之间的集成,主要通过一种名为 Rollups 的技术实现。 Rollups 的核心思想正如其名,就是把成百上千笔在 L2 上发生的交易“卷”起来,压缩成一笔交易,然后提交到 L1 的以太坊主网上。
这种“打报告”的方式主要分为两种:
1. Optimistic Rollups (乐观汇总)
- 工作原理:这种方案持“乐观”态度,默认相信 L2 提交的所有交易都是有效的。它将一批交易数据发布到 L1,然后设定一个“挑战期”(通常为 7 天)。
- 安全保障:在挑战期内,任何人都可以检查这批交易。如果发现有人作恶(例如,凭空给自己增发资产),可以提交“欺诈证明”(Fraud Proof)。一旦证明有效,作恶交易将被回滚,作恶者会受到惩罚。
- 代表项目:Arbitrum, Optimism。
2. Zero-Knowledge Rollups (ZK Rollups / 零知识汇总)
- 工作原理:这种方案更加“严谨”。它在将交易批次提交到 L1 的同时,会附上一份“有效性证明”(Validity Proof)。 这份证明通过复杂的密码学算法,能够向 L1 证明这批交易中的每一步计算都是真实有效的,但又不会泄露交易的具体细节(零知识)。
- 安全保障:L1 上的智能合约只需要验证这份证明的真伪即可,无需重新执行所有交易。只要证明有效,交易就立刻被确认。
- 代表项目:zkSync, StarkNet。
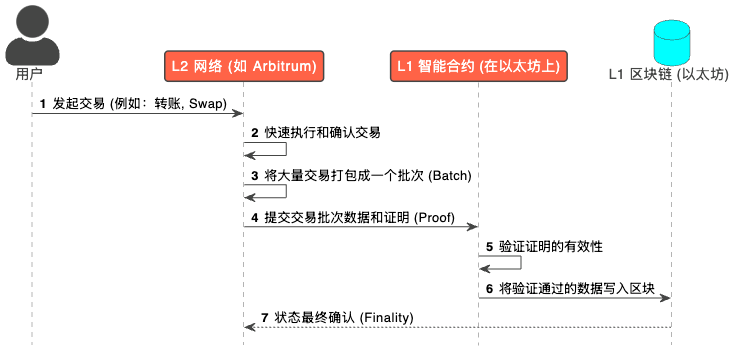
下面是一个简化的 L1 与 L2 交互流程图,可以帮助我们更清晰地理解这个过程:
L2 的原生代币和验证节点是做什么的?
现在我们来解答最初的困惑:既然安全由 L1 保证,那 L2 自己的代币和节点有什么用?
L2 原生代币:治理与激励
很多 L2 网络确实发行了自己的原生代币,例如 OP、ARB 等。这些代币通常不用于支付 Gas 费(L2 上的 Gas 费通常仍用 ETH 支付),其核心作用在于:
- 去中心化治理:代币持有者可以对 L2 网络的发展方向、技术升级、资金使用等重要事项进行投票,实现社区驱动的治理。
- 生态激励:用于激励开发者在 L2 上构建应用,或奖励为生态做出贡献的用户。
- 特殊功能:在某些设计中,代币也可能用于质押,以参与到 L2 的某些特定角色中,例如排序器选举等。例如,Linea 就计划推出一种双重销毁机制,同时销毁 ETH 和其原生代币 LINEA,以连接 L1 和 L2 的经济利益。
L2 验证节点:排序器 (Sequencer)
L2 上的节点通常不叫“验证者”(Validator),而被称为“排序器”(Sequencer)。 它们的职责不是像 L1 验证者那样通过共识算法(如 PoW 或 PoS)来确保网络安全,而是:
- 接收用户交易:收集用户在 L2 上提交的交易。
- 排序和打包:将这些交易按一定顺序排列并打包成批次。
- 提交到 L1:将打包好的数据和相关证明提交给 L1 的智能合约。
关键在于,L2 排序器的诚实性最终是由 L1 来保障的。 即使用户不信任排序器,他们仍然可以依赖 L1 上的数据来验证自己的资产和交易,甚至在极端情况下通过 L1 强制提款。 这就是 L2 与一个完全独立的 L1 公链最根本的区别:L2 的安全根基在 L1。
L2 的数据是独立的吗?关键看“数据可用性”
这是一个非常好的问题,答案是:不完全独立,并且这恰恰是 L2 安全性的关键所在。
这个问题的核心是“数据可用性”(Data Availability, DA)。 它指的是确保验证交易所需的数据对所有人都公开可得。
- 对于真正的 Rollups:它们会将交易数据(或其压缩形式)发布回 L1。 这意味着,即使 L2 的排序器全体下线或作恶,任何人都可以根据 L1 上存储的数据,独立地计算出 L2 的准确状态,并安全地取回自己的资产。数据不独立,反而更安全。
- 对于其他方案 (如 Validiums):为了追求极致的低成本,有些方案会将数据存放在链下,由一个“数据可用性委员会”来保管。 这种方案成本更低,但引入了额外的信任假设,因为数据没有被 L1 直接保护。
因此,当我们讨论 L2 时,大部分主流的 Rollups (如 Arbitrum, Optimism, zkSync) 都将数据锚定在以太坊主网,它们的数据并非完全独立,而是与 L1 共享状态根和数据可用性。
结论
希望通过这篇文章,我们对 L1 和 L2 的关系有了更清晰的认识。我们来总结一下核心要点:
- 关系定位:L2 是以太坊 L1 的扩展层,像助手一样分担 L1 的工作量,以实现扩容。
- 集成方式:主要通过 Rollups 技术,将大量 L2 交易打包后,以一份简洁的证明和数据提交到 L1 进行最终确认。
- 原生代币:L2 的原生代币主要用于治理和生态激励,而非像 L1 的 ETH 那样作为核心的安全资产。
- 验证节点:L2 的节点(排序器)负责交易排序和打包,其安全性最终由 L1 监督和保障,用户无需完全信任它们。
- 数据独立性:安全的 L2 (Rollups) 会将交易数据发布回 L1,确保数据可用性,因此其数据并非孤立存在,而是深深植根于 L1。
下次当我们看到一个 L2 项目时,可以从这几个角度去审视它,我们会发现它与 L1 之间那条无形但坚韧的安全纽带,正是整个以太坊生态能够蓬勃发展的基石。