基于python的二手车价格预测及可视化系统,采用集成学习算法和diango框架
1引言
1.1研究背景
近年来,二手车市场已经进入到了一个快速发展的阶段。随着社会主义现代化建设进程的加快,我国国民经济的发展和市场的不断完善,使汽车的保有量迅速增加,汽车流通渠道和方式由过去的单一分配同事转向多元化。
1.2研究意义
开发一个基于集成学习+Django的二手车价格预测系统对于规范二手车市场、保障买卖双方权益、促进汽车市场的健康发展具有极其重要的意义。该系统可以为卖家提供一个合理的售卖方案,同时为买家提供详细的车辆信息和可靠的购车指导,极大地增强了市场的透明度。此外,系统还可以通过整合各种服务功能,简化交易流程,提高交易效率,从而激发二手车市场的活力。
1.3国内外研究现状
1.3.1国内研究现状
我国二手车评估技术体系以重置成本法为核心基础,通过量化车辆实体性贬值(车龄、里程等)与功能性贬值(技术迭代),在数据可获得性和评估公平性方面形成显著优势,成为金融机构抵押评估和企业资产清算的主流选择。
1.3.2国外研究现状
发达国家已构建多模态融合的智能评估体系,技术演进呈现三大特征:
- 大数据驱动成为核心范式,美国KBB、Edmunds等平台基于千万级实时交易数据,应用随机森林、梯度提升等算法实现特征权重自动标定,较之传统方法误差率降低42%;
- 物联网技术深度融入评估流程,德国TÜV通过车载传感器采集200余维工况数据,结合Gamma过程构建剩余寿命预测模型,使残值评估精度提升至93%。
- 计算机视觉技术取得突破性应用,Waymo团队研发的卷积神经网络可自动解析车辆外观损伤图像,实现贬值率毫秒级计算。
相较国内,国际研究已跨越单一估值阶段,向风险管理、资产证券化等衍生领域纵深发展,形成数据采集、智能估值、决策支持的技术流程,但在数据隐私保护、特殊车型评估等细分领域仍存在技术盲区。
1.4设计内容
搭建了一个二手车价格预测和可视化系统。数据来源于二手车之家爬取的数据,数据预处理后用清洗后的数据建立xgboost集成模型,并对数据进行图表可视化,最后使用Django框架设计系统,集成了数据可视化展示、系统设置、应用模型预测价格等功能,以实现系统和用户的交互,并为购车者提供决策支持。
其中数据采集与预处理模块采用request爬虫框架爬取二手车之家全量数据,集成IP代理池与随机延时机制突破反爬限制,可获取上万条结构化数据(车型、里程、车龄等12项核心字段)。
预测模型开发模块建立集成学习模型,通过融合XGBoost与LightGBM模型的预测结果,提升价格预测的稳定性和泛化能力。
数据可视化模块使用echart可视化框架,生成包括柱形图、饼图、词云图等可视化图表。
Django系统集成模块:采用MTV架构设计、模型层封装LightGBM/XGBoost双预测引擎,模板层实现ECharts图表动态渲染,视图层部署RESTful API接口。
2相关理论及技术
2.1XGBoost模型理论和公式
XGBoost,全称为eXtreme Gradient Boosting,是一种基于梯度提升决策树(GBDT)的集成学习算法。它由华盛顿大学的陈天奇和陈发祥开发,因其在速度和模型性能上的优势而广受欢迎。XGBoost的核心思想是通过构建一系列的决策树,每棵树都是对之前所有树的一个改进,以减少整体预测误差。
2.2LightGBM模型理论和公式
LightGBM是由微软开发的一种基于梯度提升决策树的算法,特别适用于处理大规模数据。与传统的GBDT相比,LightGBM在训练速度和内存效率上都有显著的提升。
LightGBM的主要创新点在于其采用了基于直方图的决策树算法和一种称为“按叶生长”(leaf-wise growth)的树生长策略。
2.3模型融合理论和公式
模型融合(Model Ensemble)是一种通过结合多个模型的预测结果来提高整体预测性能的技术。这种方法基于这样一个假设:不同的模型可能会从不同的角度捕捉数据的特征,因此它们的组合可能会比单一模型表现更好。
2.4K-means聚类理论和公式
K-means算法是一种广泛使用的聚类技术,用于将数据集分割成K个不同的簇(clusters),使得每个数据点属于最接近其均值的簇。这个算法特别适用于大数据集,因为它相对简单且计算效率高。
2.4相关技术
2.4.1Python技术
Python是一种广泛使用的高级编程语言,以其明确、简洁的语法著称,旨在提高开发效率。
2.4.2Django框架
Django是一个开源的Python Web框架,由Adrian Holovaty和Simon Willison于2005年发布。它遵循MTV(Model-Template-View)架构,旨在简化复杂网站的开发过程。
2.4.3Mysql技术
MySQL是一个关系型数据库管理系统(RDBMS),最初由Michael Widenius和David Axmark于1995年创建。它使用结构化查询语言(SQL)进行数据库访问和管理。
2.4.4Bootstrap框架
Bootstrap是一个开源的前端框架,由Twitter的Mark Otto和Jacob Thornton于2011年发布。它旨在简化Web开发中的用户界面设计和响应式布局的实现。
3需求分析
3.1业务流程
系统业务流程分为数据采集、数据处理、模型训练与优化、价格预测、可视化展示五个核心阶段。系统通过各种数据源采集相关数据,包括但不限于车辆基本信息、历史交易价格、市场趋势等。系统对采集的数据进行预处理,以保证数据的质量和完整性。系统业务流程图如下3.1所示:

3.2系统功能需求
3.2.1数据采集
数据来源二手车交易平台(易车网)的公开数据,包括车辆标题、品牌、车龄、里程、售价、上牌时间、配置信息等。通过Python爬虫设计反爬策略(动态IP代理、请求频率控制)爬取结构化数据。存储至MySQL数据库,建立“车辆信息表”和“历史价格表”。
3.2.2数据处理
数据处理包括两部分:第一部分数据清洗:去重,剔除重复车辆信息。缺失值处理,填充或删除缺失字段(如缺失里程数据)。第二部分特征工程,使用文本聚类(K-means),对车辆标题提取关键词(如“高配”“准新车”)并聚类,生成标签。最好数值标准化,归一化车龄、里程等数值特征。
3.2.3数据分析建模
数据分析方面通过基于K-means对车辆标题聚类,分析市场热门标签分布。价格预测方面,使用XGBoost和LightGBM训练回归模型,预测二手车售价。最后结合集成学习(Stacking),融合多个模型结果提升预测精度。
3.2.4数据可视化
前端功能包括车款分析可视化,展示各品牌/车系占比。售价可视化:统计不同价格区间的车辆数量。上牌趋势可视化,按年份/月份分析上牌车辆分布。可视化聚类后的车辆标题高频关键词。技术实现通过Django框架提供RESTful API。前端采用Boostrap框架结合 ECharts动态渲染图表。
3.3数据需求
3.3.1数据流图
系统数据流图如下图3.2、图3.3所示。用户通过输入查询条件触发系统预测功能,系统返回结果;同时,系统持续从外部平台爬取数据以更新模型和数据库。
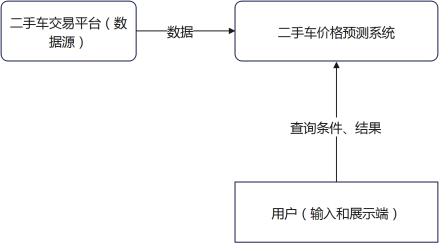
图3.2系统0层数据流图
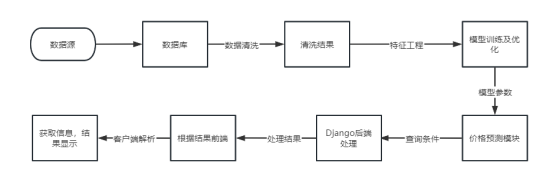
图3.3系统1层数据流图
3.3.2数据流说明
用户查询流:
输入:用户选择品牌、车龄范围等条件。
输出:预测价格结果和可视化图表。
模型训练流:
输入:清洗后的历史数据。
输出:模型参数文件(.pkl或.h5)。
3.4系统非功能需求
3.4.1兼容性
支持Chrome、Firefox、Safari等主流浏览器,适配PC端与移动端响应式布局。
3.4.2易用性
提供“一键预测”功能,用户仅需输入车辆基础信息即可获取价格。可视化图表支持交互式筛选(如点击柱形图查看详情)。
3.4.3安全性
用户分为“普通用户”和“管理员”:
普通用户:仅可查询数据和个人历史记录。
管理员:可管理模型版本、监控数据爬取状态。数据库定期备份。
4系统设计
4.1系统架构设计
本二手车市场价格预测与可视化系统从架构上分为三层:表现层、业务逻辑层以及数据层。
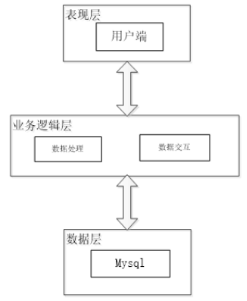
图4.1二手车价格预测与可视化系统系统架构设计图
4.2系统功能模块设计
二手车价格预测与可视化系统根据前面章节的需求分析得出,其总体设计模块图如下图所示。
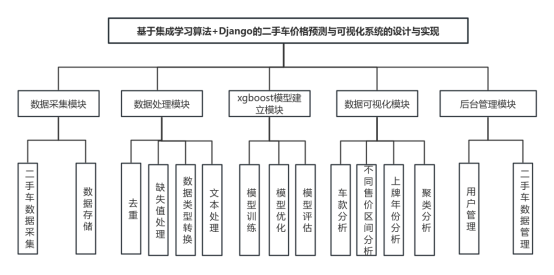
图4.2二手车价格预测与可视化系统功能模块图
4.3系统各功能设计
4.3.1登录操作流程
对于系统的安全性的第一关,就是用户想要进入系统,必须通过登录窗口,输入自己的登录信息才可以进行登录,用户输入的信息准确无误后才可以进入到操作系统界面,进行功能模块的相对应操作,如果用户输入的信息不正确,则窗囗出现提示框,用户登录失败,返回到第一步进行重新输入,如图3.3所示。
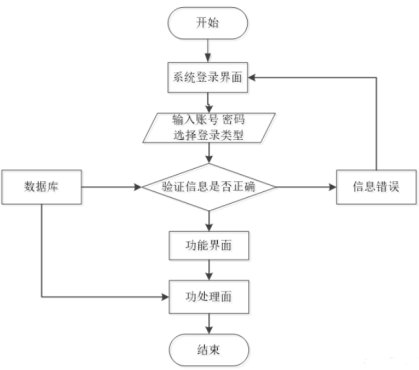
图4.3登录操作流程图
4.3.2信息添加流程
对于二手车市场数据分析与可视化系统,需要添加所需要的数据信息,对于添加信息,需要管理员进入添加界面,根据选框的内容进行填写所要添加的数据信息,信息输入完成后判断数据信息是否符合要求,符合要求则添加完成,管理员所添加的信息不符合要求,则需要返回到第一步,重新输入数据信息,再进行判断操作,如图4.4所示。
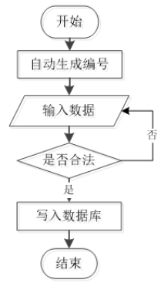
图4.4信息添加流程图
4.4.3信息删除流程
管理员进入到信息删除的系统操作界面,都可以进行不同的信息内容的操作功能,对用系统数据信息的删除,一旦将信息删除,那么该删除的数据信息将无法恢复,所以管理员在对数据删除事,一定判断删除的内容是否是确定要删除的,确定无误后选择确定删除操作,如图4.5所示。
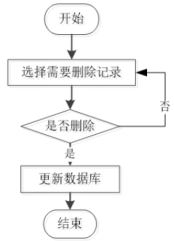
图4.5信息删除流程图
4.4.4数据采集功能设计
从主流二手车交易平台(易车网)获取车辆结构化数据与文本标题信息:采用request框架构建爬虫,支持多线程异步抓取。通过第三方代理服务(如快代理)轮换IP地址,规避平台IP封禁。采集流程如图4.6所示。

图4.6数据采集流程图
4.4.5数据处理功能设计
清洗原始数据并提取有效特征,为模型训练提供高质量输入。具体包括根据车ID剔除重复车辆记录。缺失值处理:数值型字段(如里程),使用同类车型的均值填充。数据处理流程如图4.7所示。

图4.7数据处理流程图
4.4.7可视化功能设计
可视化模块构建多维交互分析体系,围绕用户决策流程设计三层核心功能:建立动态数据映射机制,将预处理后的车辆特征数据转换为可交互图形元素,支持品牌占比、价格分布等维度分析。其次开发预测交互界面,设计结构化输入表单引导用户输入车辆关键参数(品牌、上牌年份、行驶里程等),系统即时生成价格预测结果。构建词云图动态解析车辆状况标签聚类特征,直观呈现"无事故""高配置"等关键卖点的市场关注度权重。所有可视化组件均采用响应式布局,确保跨终端设备的自适应展示效果。
4.3数据库设计
4.3.1概念设计
下面是整个二手车价格预测与可视化系统中主要的数据库表总E-R实体关系图。
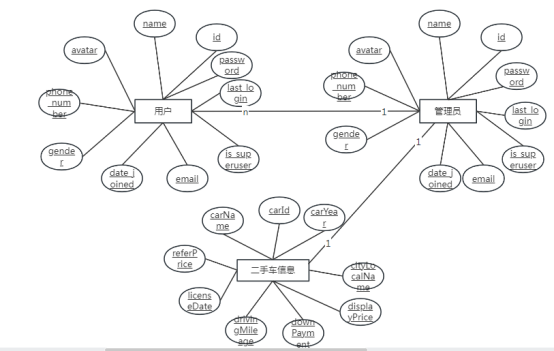
图4.3二手车价格预测与可视化系统总E-R关系图
4.3.2逻辑设计
通过上一小节中二手车市场数据分析与可视化系统中总E-R关系图上得出一共需要创建很多个数据表。在此主要罗列几个主要的数据库表结构设计。
表4.用户表
编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 |
1 | id | INTEGER | 0 | 0 | N | Y | |
2 | password | varchar | 128 | 0 | Y | N | |
3 | last_login | datetime | 0 | 0 | Y | N | |
4 | is_superuser | bool | 0 | 0 | N | N | |
5 | first_name | varchar | 150 | 0 | N | N | |
6 | last_name | varchar | 150 | 0 | N | N | |
7 | varchar | 254 | 0 | N | N | ||
8 | is_staff | bool | 0 | 0 | N | N | |
9 | is_active | bool | 0 | 0 | N | N | |
10 | date_joined | datetime | 0 | 0 | N | N | |
11 | username | varchar | 50 | 0 | N | N | |
12 | gender | varchar | 1 | 0 | N | N | |
13 | phone_number | varchar | 20 | 0 | N | N | |
14 | avatar | varchar | 100 | 0 | N | N |
表4.2二手车信息表
编号 | 名称 | 数据类型 | 长度 | 小数位 | 允许空值 | 主键 | 默认值 |
1 | carName | TEXT | 255 | 0 | N | Y | |
2 | carId | INTEGER | 255 | 0 | Y | N | |
3 | carYear | INTEGER | 255 | 0 | Y | N | |
4 | cityLocalName | TEXT | 255 | 0 | Y | N | |
5 | displayPrice | REAL | 255 | 0 | Y | N | |
6 | downPayment | REAL | 255 | 0 | Y | N | |
7 | drivingMileage | REAL | 255 | 0 | Y | N | |
8 | licenseDate | INTEGER | 255 | 0 | Y | N | |
9 | monthlyPayment | REAL | 255 | 0 | Y | N | |
10 | referPrice | REAL | 255 | 0 | Y | N | |
11 | vendorName | TEXT | 255 | 0 | Y | N | |
12 | labels | INTEGER | 255 | 0 | N | N |
5模型建立及集成
5.1数据准备
5.1.1数据来源
本文数据来源于易车网二手车网站(https://yiche.taocheche.com/cars?city=beijing)。登陆易车网二手车网站,可以在页面中选择地区、品牌、车系、价格等内容来筛选车辆,页面如下图2.1所示。
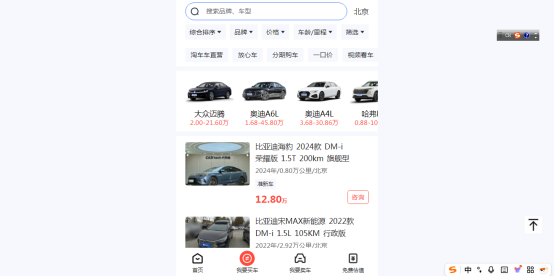
图5.1易车网二手车界面图
部分数据如下图2.2所示。
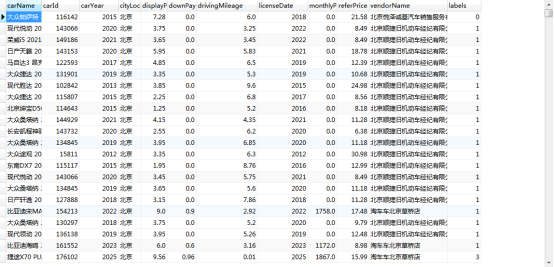
图5.2部分爬取数据展示图
5.2特征选择
5.2.1数据分布情况
(1)数据集中各列的分布情况存在较大的差异,且一些特征具有明显的偏斜。变量情况如下表5.2所示:
表5.2变量描述性统计表
描述统计参数 | carId | carYear | displayPrice | downPayment | drivingMileage | licenseDate | monthlyPayment | referPrice | labels |
count | 4000 | 4000 | 4000 | 4000 | 4000 | 4000 | 4000 | 4000 | 4000 |
mean | 1233807.928 | 2018.4805 | 19.4400975 | 2.577585 | 6.35883 | 2017.975 | 1208.3235 | 41.7109125 | 3.2305 |
std | 5239858.913 | 3.774941363 | 33.41845382 | 5.120642368 | 4.236662343 | 45.28766519 | 1992.102462 | 54.92855505 | 3.793740617 |
min | 77 | 2003 | 0.4 | 0 | 0.01 | 0 | 0 | 0 | 0 |
25% | 119077.75 | 2016 | 6.2225 | 0.3 | 2.9975 | 2017 | 0 | 15.18 | 1 |
50% | 136288.5 | 2019 | 10.76 | 0.945 | 5.815 | 2019 | 488 | 26.78 | 2 |
75% | 153597.25 | 2021 | 20.4 | 2.7925 | 9 | 2022 | 1734 | 44.9825 | 2 |
max | 50000787 | 2025 | 499.9 | 89.4 | 32 | 2025 | 22657 | 725 | 12 |
5.2样本划分
图5.8样本划分流程图
5.4模型调参
5.3.1XGBoost模型调参
(1)使用默认参数建立模型[21],其均方误差为2.55,决定系数为0.9819。
(2)XGBoost需要调节的重要参数与上述模型有所差别,它需要调节的重要参数如下表2.8所示:
表5.8XGBoost重要参数表
参数 | 解释 | 影响程度 |
n_estimators | 基模型的数量 | **** |
max_depth | 最大深度,调整模型的复杂度 | *** |
learning_rate | 学习率 | ** |
subsample | 每棵树随机取样比例 | * |
先对基模型个数和学习率进行调整,之后再调整其它参数得到最佳参数组合:n_estimators=745,learning_rate=0.08,max_depth=5,subsample=1。调参前和调参后的效果对比如下表5.9所示:
表5.9XGBoost调参前后预测结果对比表
状态 | MSE | R2 |
默认参数 | 2.55 | 0.9819 |
调参后 | 1.61 | 0.9885 |
5.4.5LightGBM模型调参
(1)使用默认参数建立模型,其均方误差为3.2,决定系数为0.9773。
(2)LightGBM需要调节的重要参数与XGBoost一致。同样地,得到最佳参数组合:n_estimators=825,learning_rate=0.08,max_depth=25,subsample=0.9。调参前和调参后的效果对比如下表2.10所示:
表2.10LightGBM调参前后预测结果对比表
状态 | MSE | R2 |
默认参数 | 3.2 | 0.9773 |
调参后 | 1.66 | 0.9882 |
5.4.6模型集成设计与实现
通过融合XGBoost与LightGBM模型的预测结果,提升价格预测的稳定性和泛化能力。
经过模型调参后得出各个模型的最佳预测情况,将它们进行对比,对比结果如下表5.11所示:
表5.11模型预测结果比较表
模型 | 均方误差(MSE) | 决定系数(R2) | 运行时长 |
XGBoost | 1.61 | 0.9885 | 24.6s |
LightGBM | 1.66 | 0.9882 | 3.9s |
集成模型 | 1.53 | 0.9901 | 28.5s |
6系统实现
6.1系统开发环境
本系统采用分层架构设计,开发环境配置如下:
1. 编程语言与框架
后端:基于Python 3.12,使用Django 4.0框架搭建RESTful API,提供数据处理与模型预测服务。
前端:采用Boostrap构建交互界面,通过ECharts 5.0实现动态图表渲染。
2. 数据存储与处理
数据库:MySQL 8.0存储车辆结构化数据。
数据处理:依赖Pandas、NumPy进行数据清洗,Scikit-learn实现K-means聚类,Jieba分词库处理车辆标题文本。
3. 机器学习与模型训练
核心算法:XGBoost 1.6与LightGBM 3.3构建价格预测模型,Scikit-learn实现Stacking集成学习。
训练环境:基于Jupyter Notebook进行特征分析与模型调优。
4. 开发工具:PyCharm与Xbuild编写代码。
6.2数据预处理功能模块
6.2.1数据预处理
(1)缺失值处理
缺失值在数据挖掘中会存在以下问题:(a)可能会使数据整体损失大量有用的信息;(b)加重系统的不确定性;(c)使模型容易输出不可靠的结果。对于缺失值的处理一般有删除、插补、不处理等处理方式。
由下图6.1所示,monthlyPayment的缺失值情况最为严重,共有1990条缺失值。
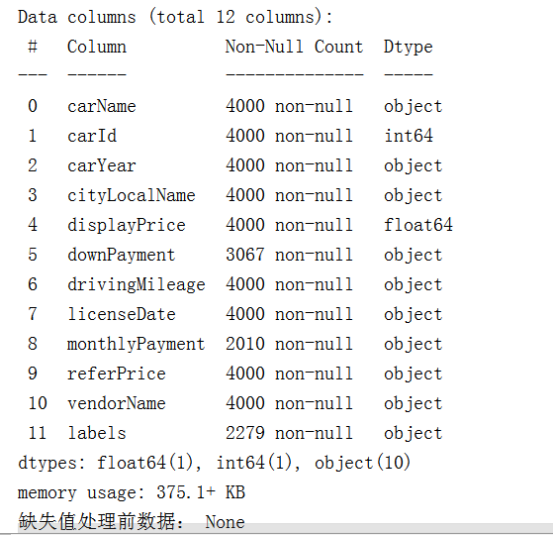
图6.1变量缺失值情况图
6.2.2数据特征转换
(1)labels转换
(2)数据替换
通过对数据中的字符串进行替换、转换和类型转换来实现。drivingMileage列标准化后的结果如下图6.2所示。

图6.2drivingMileage列标准化后的结果
6.3用户功能模块
6.3.1用户注册界面
用户注册功能由register.html实现,表单包含用户名、密码及确认密码字段。前端通过HTML5原生验证(required属性)确保非空输入,并通过pattern正则表达式限制密码复杂度(如至少8位含字母数字)。其用户注册界面展示如下图所示。
图5.1注册界面图
6.1.2用户登录界面
用户登录功能通过login.html前端表单提交用户名、密码及登录类型(普通用户或管理员),后端基于Django的AuthenticationForm实现验证逻辑。用户登录界面如下图所示。
图5.2用户登录界面图
6.1.3个人资料界面
个人信息管理通过user_info.html实现,包含基本信息修改与密码修改两个子模块。个人信息界面如下图所示。
图5.3个人资料界面图
6.1.4车款分析
系统可视化功能基于Django模板引擎与ECharts实现。车款分析界面如下图所示。
图5.4车款分析界面图
6.1.5不同售价区间界面
不同售价区间柱形图在后端通过SQL按价格区间(如5万以下、5-10万)分组统计车辆数量,结果以列表形式(横坐标区间名称、纵坐标数量)注入salary.html,前端通过bar图表配置xAxis.data和series.data动态展示,支持鼠标悬停显示数值。不同售价区间界面如下图所示。
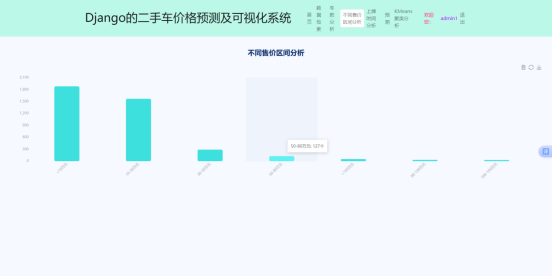
图5.5不同售价区间界面图
6.1.6上牌时间分析界面
上牌时间分析柱形图实现类似,数据源为按年份分组的licenseDate字段,视图层使用annotate聚合,前端通过option.xAxis.data绑定年份列表,series.data绑定对应数量。上牌时间分析界面如下图所示。
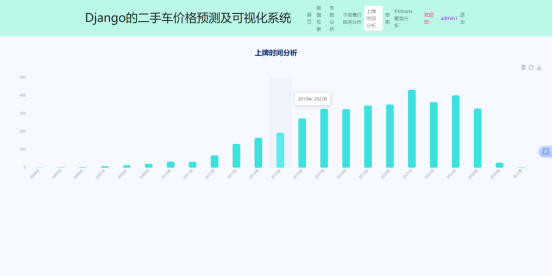
图5.7上牌时间分析界面图
6.1.7预测界面
价格预测功能在predict.html中实现,用户输入车辆参数(车龄、里程等)后,前端通过AJAX将数据POST至/predict接口。后端视图调用预训练的Stacking集成模型(XGBoost与LightGBM融合),加载joblib序列化的模型文件(.pkl),对输入特征进行标准化(复用训练时的MinMaxScaler),生成预测价格并返回JSON结果。前端接收后通过$("#val").html(res)动态显示预测值(如“12.5万元”)。预测界面如下图所示。
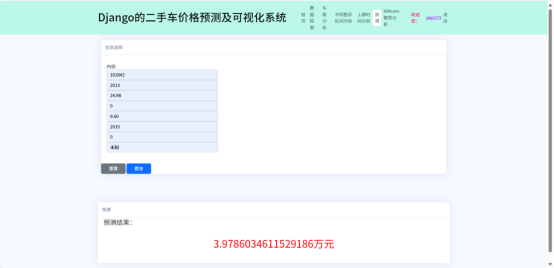
图6.7预测界面图
6.1.7聚类分析界面
K-means聚类词云图通过后端对车辆标题聚类生成高频词,使用jieba分词提取关键词并统计词频,支持下拉框选择聚类标签后通过AJAX异步更新数据。
6.2管理员功能模块
6.2.1管理员功能界面
管理员可以查看后台首页、用户管理、车辆管理等,并且可以根据需要进行相应的操作。管理员功能界面如下图所示。
图5.8管理员功能界面图
6.2.2系统用户数据管理界面
用户功能基于Django内置认证系统扩展实现。注册功能通过register.html表单提交用户名、密码及确认密码,后端视图register使用UserCreationForm验证输入合法性,检查用户名唯一性(User.objects.filter(username=username).exists()),密码一致性校验通过后调用create_user方法存储至数据库,密码经PBKDF2算法加密。系统用户管理数据界面如下图所示。
图5.9用户管理界面图
6.2.3车信息管理界面
数据管理功能主要面向管理员,基于Django Admin与自定义视图实现。车信息信息界面如下图所示。
图5.10车信息管理界面图