Java JDBC连接池深度解析与实战指南
Java JDBC连接池深度解析与实战指南
- Java JDBC连接池深度解析与实战指南
- 摘要
- 核心推荐如下:
- 表1:主流连接池高阶对比
- 第一章 连接池基础:JDBC连接池的基石
- 1.1 非托管连接的高昂代价
- 1.2 池化模式:连接的缓存机制
- 1.3 架构选择:应用侧池化 vs. 数据库侧池化
- 第二章 现代黄金标准:HikariCP深度解析
- 2.1 设计哲学:速度、简洁、可靠
- 2.2 架构优势
- 2.3 核心配置指南
- 2.4 高级调优与可靠性特性
- 2.5 实施蓝图
- 原生Java示例
- Spring Boot `application.yml` 示例
- 第三章 监控利器:阿里巴巴Druid深度剖析
- 3.1 设计哲学:可观测性与全面控制
- 3.2 杀手级特性:内置监控仪表盘
- 3.3 独特能力
- 3.4 全面配置指南
- 3.5 实施蓝图
- 原生Java示例
- Spring Boot集成
- 第四章 遗留技术:Apache Commons DBCP2与C3P0
- 4.1 历史背景与当前地位
- 4.2 关键缺陷与已知问题
- 4.3 何时还会遇到它们
- 第五章 正面交锋:全方位对比分析
- 5.1 性能基准测试解构
- 5.2 极端条件下的可靠性
- 5.3 功能与生态系统对决
- 第六章 战略建议
- 6.1 推荐矩阵
- 6.2 通用调优原则
- 6.3 生产就绪配置模板
- 模板1:优化后的HikariCP配置 (`application.yml`)
- 模板2:优化后的阿里巴巴Druid配置 (`application.yml`)
- 结论
Java JDBC连接池深度解析与实战指南
摘要
在现代Java应用开发中,数据库连接是一种昂贵且有限的资源。JDBC连接池作为管理这些资源的核心技术,对应用的性能、可伸缩性和稳定性起着决定性作用。本文旨在对当前主流的Java JDBC连接池技术进行全面、深入的分析。首先阐述连接池的基本原理,随后重点剖析当前市场的两大主角:以极致性能和可靠性著称的HikariCP,以及以强大监控和安全功能为特色的阿里巴巴Druid。同时,也将回顾曾经的主流选择Apache Commons DBCP2和C3P0,分析其历史地位与当下的局限性。
核心推荐如下:
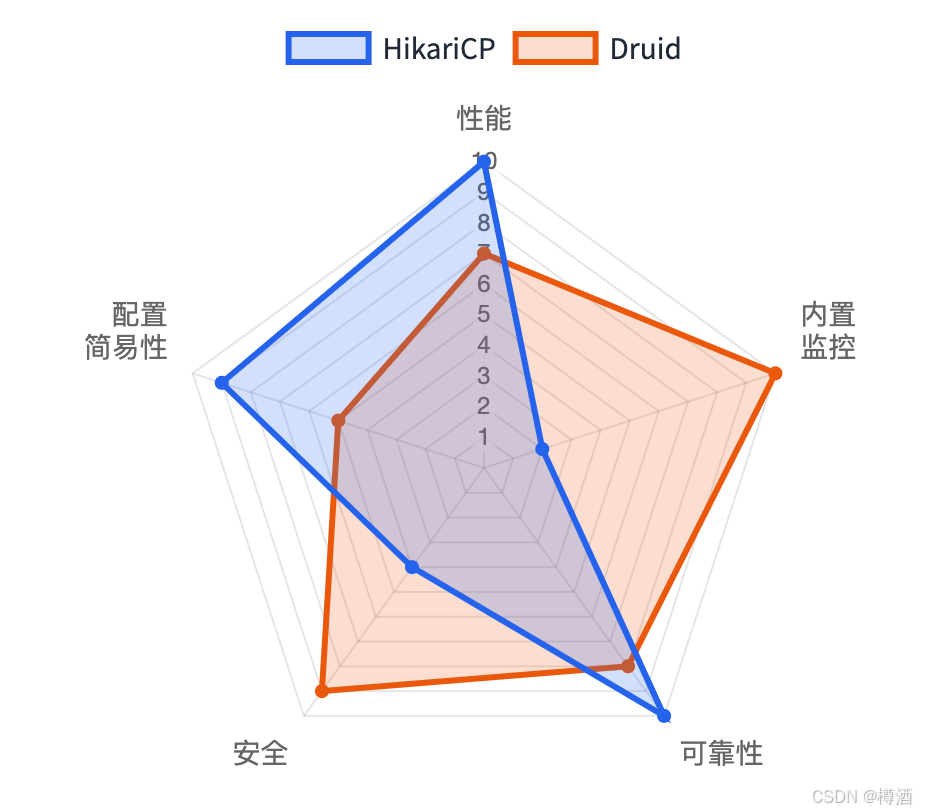
- 性能与通用场景首选:对于所有新项目,特别是基于Spring Boot的现代应用,HikariCP是无可争议的首选。其卓越的性能、极高的可靠性和轻量级设计,使其成为业界的黄金标准 。
- 高级监控与安全场景:在对系统有深度可观测性、SQL审计和应用层防火墙等有特殊需求的场景下,阿里巴巴Druid是强有力的竞争者。开发者应在接受其性能略逊于HikariCP的前提下,利用其强大的内置功能。
- 遗留系统:对于仍在维护的旧系统,虽然可能会遇到DBCP2和C3P0,但强烈建议在技术改造过程中,优先迁移至HikariCP以获得现代化的性能与稳定性。
当前连接池技术的选型,实质上是在极致性能的HikariCP与功能丰富的Druid之间做权衡。DBCP2和C3P0的时代已经过去,它们更多地存在于历史代码中。
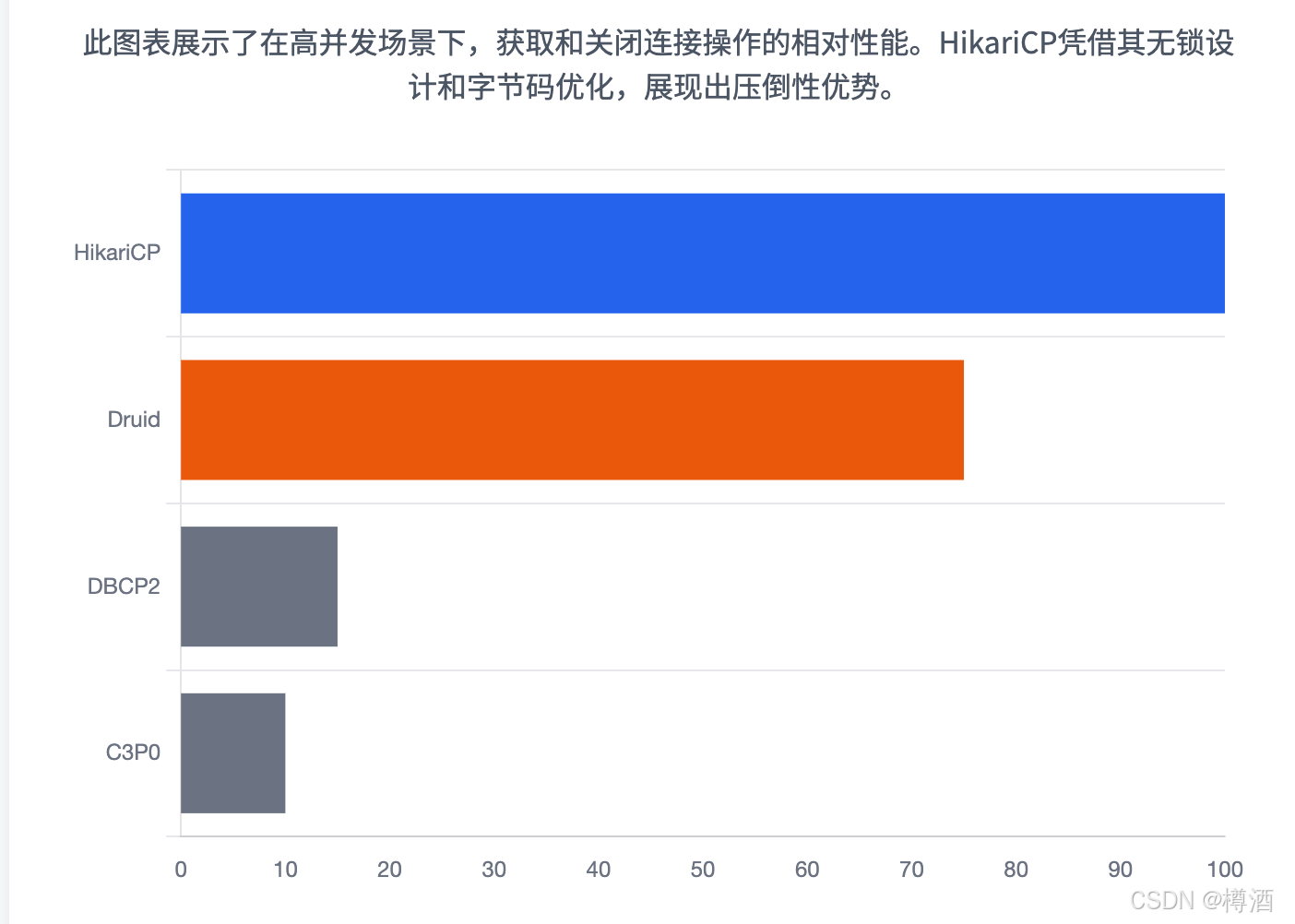
表1:主流连接池高阶对比
| 标准 | HikariCP | 阿里巴巴 Druid | Apache DBCP2 | C3P0 |
|---|---|---|---|---|
| 性能 | 卓越 通过字节码优化和无锁并发设计,实现最低的开销和最高的吞吐量 。 | 良好 性能优于传统连接池,但在高并发的连接获取/关闭操作上落后于HikariCP 。 | 较差/遗留 在高并发下因锁竞争导致性能瓶颈明显。 | 较差/遗留 性能通常低于DBCP2,配置复杂 。 |
| 可靠性 | 卓越 设计上强制执行可靠性策略(如连接测试),能快速从网络故障中恢复 。 | 良好 提供类似JBoss的ExceptionSorter机制,能处理致命数据库错误 。 | 一般 历史版本存在网络中断后无法恢复、返回失效连接的问题 。 | 良好 历史上比DBCP更健壮,但恢复机制不如现代连接池先进 。 |
| 配置简易性 | 卓越 配置项精简,拥有非常合理的默认值,上手快 。 | 一般 功能丰富导致配置项繁多,需要仔细阅读文档进行调优 。 | 一般 配置项较多,部分高级功能(如遗弃连接回收)易造成性能陷阱。 | 复杂 配置项非常多,调优难度大。 |
| 监控能力 | 良好 通过JMX/Metrics暴露核心池状态指标,专为集成外部监控系统(如Prometheus)设计 。 | 卓越 内置功能强大的Web监控后台(StatViewServlet),提供SQL监控、URL监控等深度洞察能力 。 | 基础 提供JMX支持,但监控维度和易用性远不及Druid。 | 基础 提供JMX支持,功能有限。 |
| 功能特性 | 精简核心 专注于连接池的核心功能,追求极致性能和可靠性。 | 功能丰富 内置SQL防火墙(WallFilter)、Oracle PSCache优化、强大的Filter扩展链 。 | 基础 提供连接池的基础功能和遗弃连接回收等。 | 较丰富 提供语句缓存(Statement Caching)等高级功能 。 |
| 社区与维护 | 非常活跃 Spring社区的默认标准,由专家积极维护 。 | 非常活跃 在中国技术社区极为流行,由阿里巴巴团队维护 。 | 活跃 作为Apache Commons项目的一部分,仍在维护,但已非主流选择 。 | 维护缓慢 开发活动远不如前,已显老旧 。 |
| Spring Boot集成 | 无缝(默认) 自Spring Boot 2.0起成为默认连接池,自动配置支持完善 。 | 良好 提供官方starter,但需手动配置监控组件 。 | 支持 Spring Boot支持,但需手动排除默认的HikariCP并添加依赖 。 | 需手动配置 Spring Boot不提供自动配置支持,需要开发者手动创建DataSource Bean 。 |
第一章 连接池基础:JDBC连接池的基石
1.1 非托管连接的高昂代价
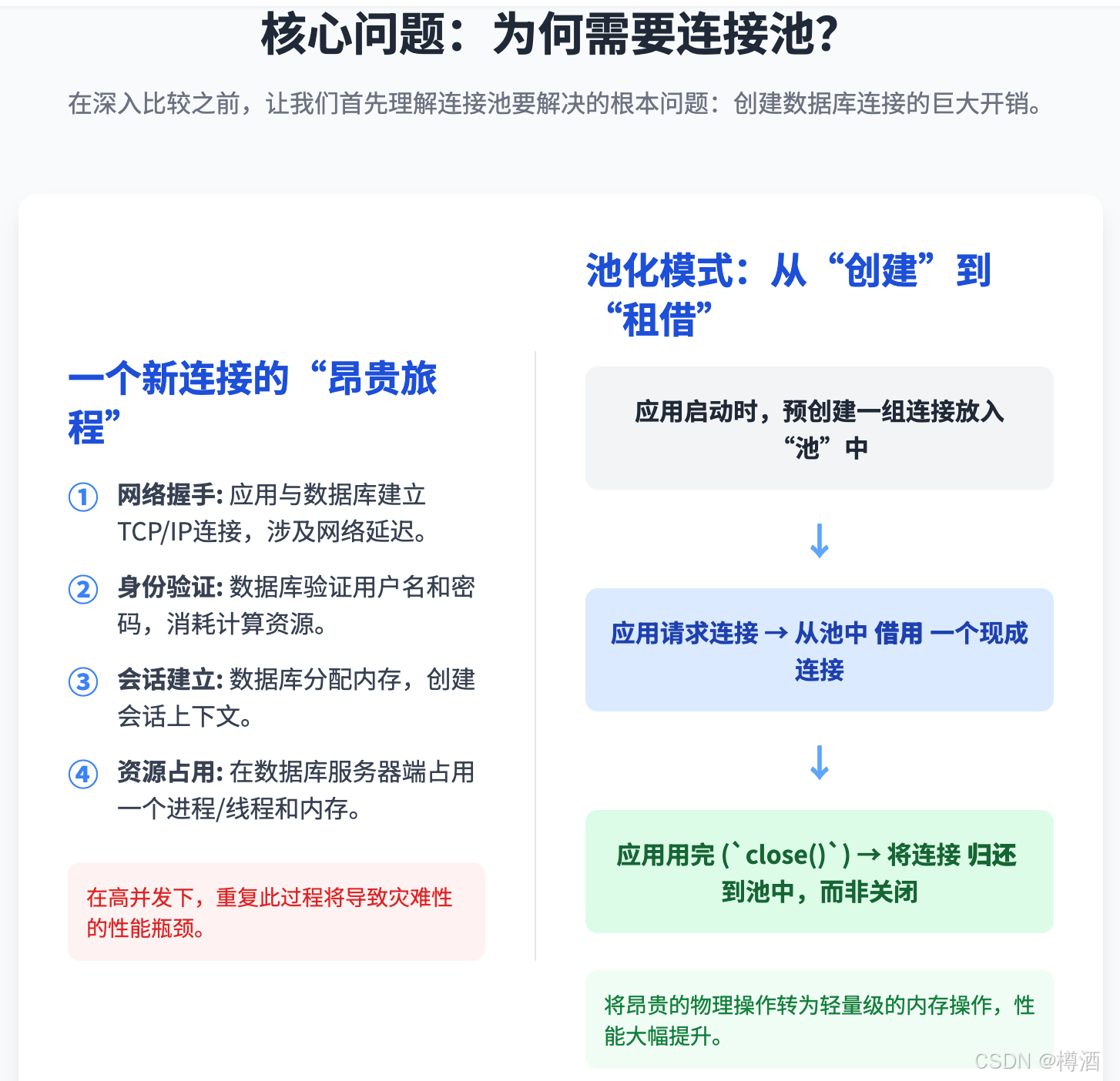
在讨论连接池的优势之前,必须理解创建一个新的数据库连接所涉及的开销。这个过程远不止是简单的对象实例化,它包含一系列耗时且消耗资源的操作 :
- 建立网络连接:应用通过JDBC驱动与数据库服务器建立一个TCP/IP套接字连接,这涉及到网络握手和延迟 。
- 数据库认证:数据库服务器需要验证应用的凭证(用户名和密码),这是一个安全敏感且计算密集的过程。
- 会话建立:认证通过后,数据库服务器需要为这个连接分配内存,创建会话上下文,并设置事务隔离级别等环境参数。
- 资源消耗:每个物理连接都会在数据库服务器端占用一个进程或线程以及相应的内存资源,这些资源是有限的。
对于单个请求,这些开销可能微不足道。然而,在现代高并发应用中,成百上千的请求同时涌入,如果每个请求都执行一次完整的连接创建和销毁流程,其累积的延迟和资源消耗将成为灾难性的性能瓶颈 。
1.2 池化模式:连接的缓存机制
连接池通过引入一个“缓存”机制来根本性地解决上述问题。其核心思想是,在应用启动时预先创建一组物理数据库连接,并将它们保存在内存中的一个“池”里 。
其工作流程如下:
- 当应用程序需要访问数据库时,它不再直接向JDBC驱动请求新连接,而是向连接池请求一个连接,即调用
dataSource.getConnection()方法 。 - 连接池从池中取出一个空闲的、已经建立好的物理连接,并将其“借”给应用程序。
- 应用程序使用这个连接执行SQL操作。
- 操作完成后,应用程序调用
connection.close()方法。此时,一个关键的机制发生了:这个调用并不会关闭真正的物理连接。连接池通过代理模式(Proxy Pattern)拦截了这个调用,将连接的状态重置(例如,回滚未提交的事务),然后将其“归还”到池中,使其可以被其他线程复用 。
这种模式的价值在于,它将昂贵的物理连接创建和销毁过程,转化为轻量级的从池中借用和归还操作,从而带来显著的收益:性能提升、延迟降低、数据库资源得到有效管理,并增强了应用的整体韧性 。
一个开发者必须理解的关键点是,在池化环境中,Connection.close()的语义发生了根本性变化。它不再是“关闭连接”,而是“归还连接”。忘记调用close()会导致“连接泄漏”(Connection Leak),即连接被永久占用,无法归还给池。这最终会导致池中无连接可用,新的请求将因超时而失败,这是连接池最常见的故障模式之一 。
1.3 架构选择:应用侧池化 vs. 数据库侧池化
连接池的实现位置可以在两个层面:
- 应用侧连接池 (Application-Side Pooling):连接池作为库(如HikariCP、Druid)嵌入在Java应用程序的内存中,由应用自身管理 。这种方式赋予了应用对自身连接使用的精细化控制权,例如可以为每个应用实例配置最大连接数、超时策略等。
- 数据库侧连接池 (Database-Side Pooling):这是一种外部中间件,如PgBouncer(针对PostgreSQL)或Oracle Connection Manager。它作为一个代理层,位于众多应用实例和数据库服务器之间 。它的主要作用是“多路复用”,将来自大量客户端(如微服务集群、无服务器函数)的连接请求,汇聚成少数几个与数据库的真实物理连接,从而保护数据库免受连接风暴的冲击。
这两种模式并非互相排斥,而是可以协同工作的。现代分布式系统的推荐架构通常是:在每个微服务实例内部署一个应用侧连接池(如HikariCP)来高效管理自身资源,同时在数据库前端部署一个数据库侧连接池(如PgBouncer)来统一管理和保护整个数据库集群的连接资源,形成双层防护体系 。
第二章 现代黄金标准:HikariCP深度解析
2.1 设计哲学:速度、简洁、可靠
HikariCP(日语“光”之意)是当今Java生态系统中性能最高、最可靠的JDBC连接池,自Spring Boot 2.0版本以来,它已成为默认的连接池选择,这标志着其在业界的主导地位 。它的设计哲学可以概括为三个词:极致性能、极简主义和绝对可靠。
HikariCP追求“零开销”的设计目标,通过精简的代码库(JAR包仅约165KB)和深入的优化,将连接池自身的性能损耗降至最低 。然而,其最根本和最值得称道的哲学是:可靠性不是一个可配置的选项。与那些允许用户为了追求性能而关闭安全校验的传统连接池不同,HikariCP默认强制执行了最可靠的行为,如连接借出时测试其有效性、归还时回滚未提交的事务等,并且这些核心的可靠性保障是无法被禁用的 。这种设计确保了应用在任何配置下都能获得最高的稳定性。
2.2 架构优势
HikariCP的卓越性能源于其先进的内部架构和微观优化:
- 字节码级优化:HikariCP的作者在开发过程中直接对生成的字节码进行分析和优化,以消除不必要的指令和开销,这是一种在库级别开发中不常见的深度优化手段。
- ConcurrentBag:这是HikariCP的核心创新之一。传统的连接池大多使用基于锁的
BlockingQueue来管理连接,在高并发下容易成为瓶颈。HikariCP则采用了自定义的无锁集合ConcurrentBag。它利用ThreadLocal缓存和高效的窃取机制,允许多个线程在几乎没有锁竞争的情况下借用和归还连接,极大地提升了并发性能。 - 智能状态追踪:HikariCP通过精巧的设计避免了与数据库之间不必要的网络通信。一个典型的例子是事务回滚处理。当一个连接被归还时,DBCP2等老式连接池会无条件地向数据库发送
rollback命令。而HikariCP会追踪连接的事务状态,只有当一个事务确实被开启且未被提交时,它才会执行回滚,否则将跳过此操作,从而减少了大量的网络开销。
2.3 核心配置指南
尽管HikariCP拥有合理的默认值,但为了在生产环境中获得最佳表现,精确调校其核心参数至关重要。
表2:HikariCP核心配置深度解析
| 属性名 | Spring Boot属性 (spring.datasource.hikari.*) | 默认值 | 描述与专家调优建议 |
|---|---|---|---|
jdbcUrl | url | 无 | [必需] JDBC连接字符串。 |
username | username | 无 | [必需] 数据库用户名。 |
password | password | 无 | [必需] 数据库密码。 |
dataSourceClassName | dataSourceClassName | 无 | [可选] 代替jdbcUrl,直接指定数据源类名。对于某些非标准JDBC驱动更优。 |
autoCommit | autoCommit | true | 控制连接的默认自动提交行为。现代框架(如Spring)通常自行管理事务,建议保持默认值true,由框架在事务边界控制提交与回滚 。 |
connectionTimeout | connectionTimeout | 30000 (30秒) | 客户端等待从池中获取连接的最大毫秒数。建议设置为一个合理的值(如30秒),以实现快速失败,避免线程长时间阻塞等待。 |
idleTimeout | idleTimeout | 600000 (10分钟) | 连接在池中保持空闲的最大毫秒数。当池中连接数超过minimumIdle时,空闲超时的连接将被移除。用于在应用低谷期释放不必要的连接资源。 |
maxLifetime | maxLifetime | 1800000 (30分钟) | [极其重要] 连接在池中的最大生命周期(毫秒)。必须将此值设置为小于任何网络基础设施(如防火墙、负载均衡器)或数据库本身的连接超时时间,以主动防止获取到已失效的“僵尸”连接。 |
minimumIdle | minimumIdle | 与maximumPoolSize相同 | 池中维护的最小空闲连接数。建议设置为与maximumPoolSize相同的值,以获得最佳性能并应对突发流量。这可以避免在高负载下频繁地创建和销毁连接。 |
maximumPoolSize | maximumPoolSize | 10 | [最关键的调优参数] 池中允许的最大连接数(包括空闲和在用)。此值的设定直接影响应用性能和数据库负载。应根据第6.2节的公式和负载测试来确定。 |
connectionTestQuery | connectionTestQuery | 无 | 用于验证连接是否有效的SQL查询。对于现代JDBC4驱动,此参数通常不需要设置,因为HikariCP默认使用效率更高的Connection.isValid()方法进行验证。 |
2.4 高级调优与可靠性特性
leakDetectionThreshold:连接泄漏检测阈值(毫秒)。当一个连接被借出超过此时间仍未归还,HikariCP会打印一条WARN日志,并附带堆栈信息,是调试连接泄漏问题的利器。建议在开发和测试环境中设置为一个较小的值(如2000ms),但在生产环境中需谨慎使用,因为合法的长耗时查询可能导致误报 。keepaliveTime:连接保活时间(毫秒)。此功能用于防止连接因长时间空闲而被数据库或网络防火墙单方面断开。HikariCP会定期(每keepaliveTime毫秒)对池中的空闲连接进行一次有效性检测(“ping”),从而保持连接活跃。这是一个在复杂网络环境中保障连接池稳定性的重要参数 。initializationFailTimeout:初始化失败超时时间(毫秒)。默认值为1,表示如果池无法成功初始化(例如,数据库在应用启动时宕机),应用将快速失败并退出。在某些场景下,如果希望应用即使在数据库暂时不可用时也能启动,可以将其设置为-1 。- 数据库故障处理:HikariCP在设计上对数据库宕机和恢复有很强的适应性。当数据库不可用时,它能有效地隔离故障;当数据库恢复后,它能迅速地重建连接池,恢复服务,其恢复速度和稳定性优于许多传统连接池。
2.5 实施蓝图
原生Java示例
以下代码展示了如何在原生Java应用中以编程方式配置和使用HikariCP。
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;public class HikariCPDemo {private static HikariDataSource ds;static {HikariConfig config = new HikariConfig();config.setJdbcUrl("jdbc:mysql://localhost:3306/mydatabase");config.setUsername("user");config.setPassword("password");config.addDataSourceProperty("cachePrepStmts", "true");config.addDataSourceProperty("prepStmtCacheSize", "250");config.addDataSourceProperty("prepStmtCacheSqlLimit", "2048");config.setMaximumPoolSize(20);config.setMinimumIdle(10);config.setMaxLifetime(1800000); // 30 minutesconfig.setConnectionTimeout(30000); // 30 secondsconfig.setIdleTimeout(600000); // 10 minutesds = new HikariDataSource(config);}public static Connection getConnection() throws SQLException {return ds.getConnection();}public static void main(String[] args) {// 使用 try-with-resources 确保连接被正确关闭(归还到池中)try (Connection conn = getConnection();Statement stmt = conn.createStatement();ResultSet rs = stmt.executeQuery("SELECT 1")) {if (rs.next()) {System.out.println("Connection test successful. Result: " + rs.getInt(1));}} catch (SQLException e) {e.printStackTrace();} finally {if (ds != null) {ds.close(); // 在应用关闭时关闭整个数据源}}}
}
Spring Boot application.yml 示例
在Spring Boot项目中,配置HikariCP极为简单,只需在application.yml(或.properties)文件中提供相关属性即可。
spring:datasource:url: jdbc:postgresql://db.example.com:5432/mydatabaseusername: myuserpassword: mypassworddriver-class-name: org.postgresql.Driver# HikariCP specific settingshikari:# 连接池名称,会显示在日志和JMX中pool-name: MyAppHikariPool# 最小空闲连接数。为了最佳性能和响应突发请求,建议设置为与maximum-pool-size相同minimum-idle: 20# 最大连接数。应根据基准测试和数据库能力设定maximum-pool-size: 20# 连接自动提交auto-commit: true# 空闲连接超时时间。连接在池中空闲超过此时间将被移除(当池中连接数大于minimum-idle时)idle-timeout: 600000 # 10分钟# 连接最大生存期。设置为略小于数据库或网络设施的超时时间,如30分钟max-lifetime: 1800000 # 30分钟# 获取连接的超时时间。建议30秒,避免线程无休止等待connection-timeout: 30000 # 30秒# 连接测试查询。对于现代JDBC驱动通常不需要,依赖于isValid()# connection-test-query: SELECT 1# 连接泄漏检测阈值。仅在开发或调试时开启leak-detection-threshold: 2000 # 2秒
第三章 监控利器:阿里巴巴Druid深度剖析
3.1 设计哲学:可观测性与全面控制
在深入探讨之前,必须做一个重要澄清:本报告讨论的阿里巴巴Druid是一个JDBC连接池,而Apache Druid是一个开源的实时分析数据库。两者除了名字相似外,是完全不同的项目,切勿混淆 。
阿里巴巴Druid(下文简称Druid)的设计哲学是“为监控而生” 。它的核心价值主张并非追求像HikariCP那样的极致性能,而是提供一个功能极其丰富、集监控、诊断和安全于一体的“全家桶”式解决方案 。选择Druid,意味着选择了一套内建的、强大的数据库访问治理工具。
3.2 杀手级特性:内置监控仪表盘
Druid最引人注目的特性是其内置的Web监控仪表盘,通过配置一个StatViewServlet即可启用。这个仪表盘提供了无与伦比的深度洞察能力,是其他连接池难以企及的:
- 数据源监控 (DataSource):实时展示连接池的详细状态,包括当前活动连接数、空闲连接数、峰值、创建和销毁次数、逻辑和物理SQL执行次数等 。
- SQL监控 (SQL):这是Druid最强大的功能。它能记录并分析应用执行的每一条SQL语句,提供包括执行次数、总耗时、最大耗时、错误次数、影响行数等在内的详尽统计。它会自动识别并聚合相似的SQL,并按执行时间、执行频率等维度排序,让开发者能轻易定位到慢查询和高频查询 。
- URL监控:监控Web应用中每个URL的请求次数、耗时等性能指标。
- Spring和Session监控:提供对Spring Bean方法和Web会话的监控。
- 连接泄漏诊断:可以清晰地看到哪些连接被借用后没有归还,并提供堆栈信息帮助定位问题代码 。
通过这个仪表盘,运维和开发人员无需依赖外部APM(应用性能监控)工具,就能对数据库的交互层进行细致入微的分析和诊断。
3.3 独特能力
- WallFilter SQL防火墙:Druid内置了一个名为
WallFilter的应用层SQL防火墙。它通过对SQL进行语法分析,能够识别和拦截常见的SQL注入攻击模式,为应用提供一道额外的安全防线。这是一个在连接池层面实现的独特安全功能 。 - Oracle PSCache 优化:Druid对
PreparedStatement的缓存(PSCache)进行了专门优化,特别是针对Oracle数据库。在Oracle环境中,不当的PSCache配置可能导致严重的内存占用问题,而Druid声称解决了这一痛点,能够显著提升性能 。 - Filter-Chain架构:Druid的功能都是通过可插拔的Filter链实现的。例如,
StatFilter负责收集监控数据,LogFilter负责日志记录,WallFilter负责安全。这种设计具有良好的扩展性,允许用户自定义Filter来满足特定需求 。
3.4 全面配置指南
Druid的配置项非常丰富,理解其核心参数是发挥其功能的前提。
表3:阿里巴巴Druid核心配置深度解析
| 属性名 | Spring Boot属性 (spring.datasource.druid.*) | 默认值 | 描述与专家调优建议 |
|---|---|---|---|
| 基础配置 | |||
url | url | 无 | [必需] JDBC连接URL。 |
username | username | 无 | [必需] 数据库用户名。 |
password | password | 无 | [必需] 数据库密码。 |
driverClassName | driver-class-name | 自动识别 | 通常无需配置,Druid会根据URL自动识别。 |
| 池大小配置 | |||
initialSize | initial-size | 0 | 初始化时建立的连接数。 |
minIdle | min-idle | 0 | 池中保持的最小空闲连接数。 |
maxActive | max-active | 8 | 池中最大连接数,等同于HikariCP的maximumPoolSize。 |
| 超时与驱逐 | |||
maxWait | max-wait | -1 (无限等待) | 获取连接时的最大等待时间(毫秒)。建议设置一个有限值,如60000。 |
timeBetweenEvictionRunsMillis | time-between-eviction-runs-millis | 60000 (1分钟) | 驱逐线程运行的间隔时间,用于检测和关闭空闲、失效的连接。 |
minEvictableIdleTimeMillis | min-evictable-idle-time-millis | 1800000 (30分钟) | 连接在池中最小的可驱逐空闲时间。 |
maxEvictableIdleTimeMillis | max-evictable-idle-time-millis | 25200000 (7小时) | 连接在池中最大的可驱逐空闲时间,类似HikariCP的maxLifetime。 |
| 验证与保活 | |||
validationQuery | validation-query | 自动选择 | 用于验证连接的SQL。Druid会为常见数据库自动选择,如MySQL的SELECT 1。 |
testOnBorrow | test-on-borrow | false | 借用连接时是否测试。会影响性能,通常不建议开启。 |
testWhileIdle | test-while-idle | true | 建议保持true。当连接空闲时间超过timeBetweenEvictionRunsMillis时,在借用时会进行测试,是一种高效的验证方式。 |
keepAlive | keep-alive | false | [推荐开启] 设为true后,驱逐线程会对空闲时间超过minEvictableIdleTimeMillis的连接进行保活操作,而不是直接关闭,能有效应对网络超时问题 [50]。 |
| 监控与安全 | |||
filters | filters | 无 | [核心功能开关] 以逗号分隔的Filter别名。配置stat开启监控,wall开启SQL防火墙,log4j开启日志。例如:stat,wall。 |
removeAbandoned | remove-abandoned | false | 是否开启遗弃连接回收。建议仅在开发环境用于定位问题,生产环境开启有性能风险。 |
| PSCache | |||
poolPreparedStatements | pool-prepared-statements | false | 是否开启PreparedStatement缓存。对Oracle等数据库性能提升明显。 |
maxPoolPreparedStatementPerConnectionSize | max-pool-prepared-statement-per-connection-size | 10 | 每个连接上缓存的PreparedStatement的最大数量。 |
3.5 实施蓝图
原生Java示例
通过DruidDataSourceFactory从属性文件创建数据源是原生Java中的常见做法。
druid.properties 文件:
driverClassName=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://localhost:3306/mydatabase
username=user
password=passwordinitialSize=5
minIdle=5
maxActive=20
maxWait=60000# 开启监控和防火墙
filters=stat,wall
Java 代码:
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.Properties;
import javax.sql.DataSource;public class DruidDemo {private static DataSource dataSource;static {Properties properties = new Properties();try (InputStream inputStream = DruidDemo.class.getClassLoader().getResourceAsStream("druid.properties")) {properties.load(inputStream);dataSource = DruidDataSourceFactory.createDataSource(properties);} catch (Exception e) {e.printStackTrace();}}public static Connection getConnection() throws SQLException {return dataSource.getConnection();}//... main method to use the connection
}
Spring Boot集成
集成Druid到Spring Boot项目需要引入starter并进行Java配置。
-
添加Maven依赖:
<dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.2.25</version> </dependency> -
application.yml配置:spring:datasource:# 指定数据源类型为Druidtype: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/testdb?useUnicode=true&characterEncoding=utf-8username: rootpassword: passworddruid:initial-size: 5min-idle: 5max-active: 20max-wait: 60000time-between-eviction-runs-millis: 60000min-evictable-idle-time-millis: 300000validation-query: SELECT 1test-while-idle: truetest-on-borrow: falsetest-on-return: falsepool-prepared-statements: truemax-pool-prepared-statement-per-connection-size: 20# 开启监控统计和SQL防火墙功能filters: stat,wall -
配置监控后台 (Java Config): 为了启用并保护Druid的监控后台,需要创建一个配置类。
import com.alibaba.druid.support.http.StatViewServlet; import com.alibaba.druid.support.http.WebStatFilter; import org.springframework.boot.web.servlet.FilterRegistrationBean; import org.springframework.boot.web.servlet.ServletRegistrationBean; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration;import java.util.HashMap; import java.util.Map;@Configuration public class DruidConfig {@Beanpublic ServletRegistrationBean<StatViewServlet> statViewServlet() {// 创建StatViewServlet,并将其映射到/druid/*路径ServletRegistrationBean<StatViewServlet> bean = new ServletRegistrationBean<>(new StatViewServlet(), "/druid/*");// 设置监控后台的登录参数Map<String, String> initParams = new HashMap<>();initParams.put("loginUsername", "admin"); // 登录用户名initParams.put("loginPassword", "123456"); // 登录密码initParams.put("allow", ""); // 允许所有IP访问,生产环境应配置为特定IP// initParams.put("deny", "192.168.1.100"); // 拒绝特定IP访问bean.setInitParameters(initParams);return bean;}@Beanpublic FilterRegistrationBean<WebStatFilter> webStatFilter() {FilterRegistrationBean<WebStatFilter> bean = new FilterRegistrationBean<>();bean.setFilter(new WebStatFilter());// 设置WebStatFilter的参数Map<String, String> initParams = new HashMap<>();initParams.put("exclusions", "*.js,*.css,/druid/*"); // 排除静态资源和Druid后台的监控bean.setInitParameters(initParams);// 设置拦截的URL模式bean.addUrlPatterns("/*");return bean;} }
第四章 遗留技术:Apache Commons DBCP2与C3P0
4.1 历史背景与当前地位
Apache Commons DBCP(及其后续版本DBCP2)和C3P0是Java连接池领域的先驱,它们在很长一段时间内都是企业级应用的事实标准 。许多经典的框架(如早期版本的Hibernate)和大量的遗留系统中,都能看到它们的身影 。
然而,随着技术的发展,它们的局限性也日益凸显。尽管Apache基金会仍在对DBCP2进行维护 ,C3P0也偶有更新 ,但它们的设计理念和实现方式已经难以适应现代高并发、多核、微服务化的应用场景。它们的创新步伐已远远落后于HikariCP和Druid 。
4.2 关键缺陷与已知问题
这些老旧的连接池之所以被现代技术所取代,是因为它们存在一些难以克服的根本性问题。
Apache Commons DBCP/DBCP2:
- 并发性能差:DBCP的早期版本甚至是单线程的,而DBCP2虽然支持多线程,但在高并发场景下,其内部过多的同步锁会导致严重的锁竞争,性能急剧下降 。
- 可靠性问题:历史上有大量报告指出,DBCP在遇到网络中断等问题时,无法正确地清理和恢复连接,甚至会将已经失效的连接返回给应用程序,导致应用报错 。
- 低效的默认行为:如前文所述,DBCP2默认会对归还的连接无条件执行
rollback,这在大多数情况下是不必要的,平白增加了大量的数据库网络开销 。 - 配置陷阱:其
removeAbandoned(遗弃连接回收)功能虽然意在解决连接泄漏,但其实现机制会在获取连接时增加额外检查,可能导致性能问题,因此不推荐在生产环境开启 。
C3P0:
- 性能不佳:尽管在健壮性上C3P0的口碑普遍优于DBCP,但其性能也一直为人诟病,通常比DBCP还要慢 。
- 配置极其复杂:C3P0提供了海量的配置参数,这虽然带来了灵活性,但也极大地增加了调优的难度。错误的配置,例如对
max_statements(语句缓存)的设置不当,很容易引发性能问题。 - 历史包袱:C3P0的早期版本存在严重的性能缺陷,虽然新版本有所改进,但其整体架构已显陈旧。
这些连接池的设计诞生于一个与今天截然不同的技术时代——一个由单体应用和较少CPU核心主导的时代。它们的锁定策略和复杂性反映了那个时代的局限。当高并发、多核处理器和微服务架构成为主流时,这些第一代连接池的性能瓶颈和可靠性短板便暴露无遗。HikariCP的诞生正是为了解决这些痛点,它通过采用无锁数据结构等现代并发编程技术,重新设计了连接池。而Druid则另辟蹊径,聚焦于解决运维和诊断中的“可观测性”黑洞问题。因此,这不仅仅是简单的技术迭代,而是连接池技术向着“高性能”和“强监控”两个不同方向的演化。
4.3 何时还会遇到它们
如今,开发者最可能在维护遗留项目或使用一些尚未更新其依赖的旧版第三方库时遇到DBCP2和C3P0。对于这些情况,最佳实践是在项目允许的情况下,尽快规划技术升级,将连接池迁移到HikariCP,以享受现代技术带来的性能和稳定性红利。
第五章 正面交锋:全方位对比分析
5.1 性能基准测试解构
性能是衡量连接池优劣的核心指标。根据HikariCP官方提供的、在真实数据库(MySQL)而非模拟驱动上进行的基准测试,结果差异惊人:
- 在默认配置下,仅执行
getConnection()和close()循环,HikariCP的吞吐量(ops/ms)是Tomcat JDBC Pool的近20倍,是DBCP2的超过2000倍。 - 性能与可靠性的倒置关系:这一巨大差异的背后,是一个深刻的现象。HikariCP之所以快,并不仅仅是算法高效,更是因为它在保证高可靠性的前提下实现了高效。当把DBCP2和Tomcat JDBC Pool的配置调整到与HikariCP具有同等级别的可靠性保障时(例如,开启
testOnBorrow和rollbackOnReturn),它们的性能会发生断崖式下跌,甚至低于DBCP2的默认值 。这证明了HikariCP的设计从根本上就优于这些传统连接池。 - HikariCP vs. Druid:在另一组对比测试中,HikariCP在获取和关闭连接的性能上同样显著优于Druid。而在语句处理方面,两者差距较小,HikariCP略占优势。
所有严谨的性能测试都应使用像JMH(Java Microbenchmark Harness)这样的专业工具,以避免JVM的即时编译(JIT)、死代码消除等优化对测试结果产生干扰,确保数据的有效性 。
5.2 极端条件下的可靠性
- 故障恢复:HikariCP被明确设计并经过严格测试,能够在数据库或网络发生故障后快速恢复。相比之下,DBCP和C3P0则有大量关于在类似情况下无法恢复或返回已损坏连接的历史记录。
- 错误处理:Druid提供了强大的
ExceptionSorter机制,能够识别数据库返回的致命错误代码,并据此将失效的连接从池中驱逐。这一功能与JBoss数据源中备受好评的同名功能类似,是其可靠性的重要保障 。
5.3 功能与生态系统对决
- 监控:这是HikariCP和Druid最显著的区别。Druid提供的是一个“开箱即用”的、功能丰富的Web UI,尤其擅长深度SQL分析 。而HikariCP则遵循“小而美”的哲学,仅提供核心的池状态指标(通过JMX或Metrics库),旨在与专业的外部监控系统(如Prometheus、Grafana)无缝集成 。这是一个“一体化解决方案”与“最佳单品组合”的路线选择。
- 安全:Druid的
WallFilter提供了一层应用级的SQL注入防护,这是其他连接池所不具备的独特安全特性 。 - 易用性:HikariCP以其极简的配置和明智的默认值而备受赞誉。相比之下,Druid和C3P0由于功能集庞大,配置相对复杂,需要用户投入更多学习成本。
- 社区与维护:HikariCP作为Spring Boot的钦定选择,拥有极其活跃的社区和顶级的维护支持。Druid同样在积极维护,尤其在广大的中国开发者社区中深受欢迎。DBCP2和C3P0的开发活跃度则明显偏低 。
第六章 战略建议
6.1 推荐矩阵
基于全面的分析,为不同应用场景提供明确的选型建议。
表4:最终选型推荐矩阵
| 应用场景 / 需求 | 推荐连接池 | 核心配置策略与理由 | 推荐系数 |
|---|---|---|---|
| 高吞吐量微服务/无服务器应用 | HikariCP | minimumIdle = maximumPoolSize。理由:追求最低的连接获取延迟和最小的运行时开销,HikariCP的性能和轻量级特性是最佳选择 。 | ★★★★★ |
| 标准企业级/Web应用 | HikariCP | 遵循HikariCP最佳实践配置。 理由:作为Spring Boot的默认选择,提供了性能、可靠性和易用性的完美平衡,是通用场景下的安全牌 。 | ★★★★★ |
| 需要深度SQL洞察的数据密集型应用 | 阿里巴巴 Druid | filters=stat,wall。理由:内置的SQL监控和防火墙功能对于调试复杂的数据访问层、定位慢查询和增强安全性具有不可替代的价值 。 | ★★★★☆ |
| 有Oracle数据库性能优化需求 | 阿里巴巴 Druid | poolPreparedStatements=true。理由:其专门为Oracle优化的PSCache能有效解决特定场景下的性能和内存问题。 | ★★★★☆ |
| 遗留应用现代化改造 | HikariCP | 制定迁移计划,逐步替换DBCP2/C3P0。 理由:迁移至HikariCP是技术升级的明确目标,能带来显著的性能和稳定性提升。 | ★★★★★ |
| 严格禁止外部APM工具的项目 | 阿里巴巴 Druid | 启用StatViewServlet。理由:在无法使用外部监控工具的情况下,Druid自带的监控仪表盘提供了一个足够好的、零依赖的内部监控方案。 | ★★★☆☆ |
6.2 通用调优原则
无论选择哪个连接池,以下原则都具有普遍指导意义。
- 连接池大小的设定:业界流传一个著名的公式作为起点:
pool_size = (core_count * 2) + 1。其背后的逻辑是,对于一个混合了CPU密集型和I/O密集型任务的应用,线程数略多于CPU核心数可以保证在某些线程等待I/O(如磁盘、网络)时,CPU核心不会闲置。然而,这仅仅是一个经验公式,绝非银弹。数据库的类型、存储介质(SSD的I/O等待远小于HDD )、查询的复杂度以及应用的并发模型都会影响最佳值。最终的、唯一可信的池大小必须通过压力测试来确定。 - 超时配置策略:
connectionTimeout(获取连接超时): 应设置得相对较短(如30秒),让应用在无法获取连接时快速失败,而不是无限期等待。idleTimeout(空闲连接超时): 平衡资源占用和连接池抖动。时间太短会导致连接被频繁关闭和创建;时间太长则在低峰期浪费资源。maxLifetime(连接最大生命周期): 这是保障系统稳定性的非协商性参数,必须设置为一个比任何中间网络设备(防火墙、负载均衡器)或数据库本身设置的空闲连接超时更短的值。
- 连接验证的重要性:在生产环境中,必须开启某种形式的连接验证(如HikariCP的
keepaliveTime或Druid的testWhileIdle和keepAlive),这是构建一个能够从网络抖动或数据库重启中自动恢复的弹性应用的基石。
6.3 生产就绪配置模板
模板1:优化后的HikariCP配置 (application.yml)
spring:datasource:url: jdbc:mysql://localhost:3306/prod_db?serverTimezone=UTC&useSSL=falseusername: prod_userpassword: ${DB_PASSWORD} # 从环境变量或配置中心获取driver-class-name: com.mysql.cj.jdbc.Driverhikari:pool-name: Prod-HikariPool# 关键性能配置:让池保持全速运行,避免收缩和扩张minimum-idle: 30maximum-pool-size: 30# 可靠性配置max-lifetime: 1740000 # 29分钟,小于常见的30分钟防火墙超时connection-timeout: 30000 # 30秒idle-timeout: 600000 # 10分钟keepalive-time: 60000 # 每分钟对空闲连接进行一次保活# 驱动特定优化data-source-properties:cachePrepStmts: trueprepStmtCacheSize: 250prepStmtCacheSqlLimit: 2048useServerPrepStmts: trueuseLocalSessionState: truerewriteBatchedStatements: truecacheResultSetMetadata: truecacheServerConfiguration: trueelideSetAutoCommits: truemaintainTimeStats: false
模板2:优化后的阿里巴巴Druid配置 (application.yml)
spring:datasource:type: com.alibaba.druid.pool.DruidDataSourceurl: jdbc:mysql://localhost:3306/prod_db?serverTimezone=UTC&useSSL=falseusername: prod_userpassword: ${DB_PASSWORD}driver-class-name: com.mysql.cj.jdbc.Driverdruid:# 基础池配置initial-size: 10min-idle: 10max-active: 30max-wait: 60000# 可靠性与驱逐配置time-between-eviction-runs-millis: 60000min-evictable-idle-time-millis: 300000max-evictable-idle-time-millis: 1800000 # 30分钟validation-query: SELECT 1test-while-idle: truetest-on-borrow: falsetest-on-return: false# 开启保活,非常重要!keep-alive: true# 开启监控和防火墙filters: stat,wall,slf4j# Filter特定属性filter:stat:log-slow-sql: trueslow-sql-millis: 5000wall:config:multi-statement-allow: true
结论
Java JDBC连接池技术已经走过了漫长的发展道路。分析表明,HikariCP凭借其在性能和可靠性上的压倒性优势,已经赢得了现代Java应用开发的头把交椅,成为几乎所有新项目的默认和最佳选择。与此同时,阿里巴巴Druid通过其无与伦比的内置监控和安全功能,成功地开辟了一个专注于深度可观测性和数据库访问治理的强大生态位。而曾经的王者,DBCP2和C3P0,则因其陈旧的架构和性能瓶颈,已步入遗留技术的行列。
最终的战略建议是清晰的:默认选择HikariCP,除非你的项目对Druid提供的内置监控和安全功能有不可替代的强需求。
然而,选择正确的工具只是第一步。更重要的是,要将其视为应用基础设施的关键组件,投入时间去理解其配置,并通过持续的监控和基准测试进行精细化调优,以确保应用在生产环境中能够发挥出最大的潜能和稳定性。