C++ - 基于多设计模式下的同步异步日志系统(11w字)
1.前言
日志:程序运行过程中所记录的程序运行状态信息
作用:记录程序运行状态信息,以便于程序员能够随时根据状态信息,对系统的运行状态,进行分析
功能:能够让用户非常简便的进行日志的输出,以及控制
2.项目介绍
本项目主要实现一个日志系统,其主要支持以下功能:
- 支持多级别日志消息
- 支持同步日志和异步日志
- 支持可靠写入日志到控制台、文件以及滚动文件中
- 支持多线程程序并发写文件
- 支持拓展不同的日志落地目标地
3.开发环境
- CentOS 7
- vscode/vim
- g++/gdb
- Makefile
4.核心技术
- 类层次设计(继承和多态的应用)
- C++11(多线程、auto、智能指针、右值引用)
- 双缓冲区
- 生产消费模型
- 设计模式(单例、工厂、代理、建造者)
5.日志系统介绍
5.1为什么需要日志系统
-
⽣产环境的产品为了保证其稳定性及安全性是不允许开发⼈员附加调试器去排查问题, 可以借助⽇志系统来打印⼀些⽇志帮助开发⼈员解决问题
-
上线客⼾端的产品出现bug⽆法复现并解决, 可以借助⽇志系统打印⽇志并上传到服务端帮助开发⼈员进⾏分析
-
对于⼀些⾼频操作(如定时器、⼼跳包)在少量调试次数下可能⽆法触发我们想要的⾏为,通过断点的暂停⽅式,我们不得不重复操作⼏⼗次、上百次甚⾄更多,导致排查问题效率是⾮常低下, 可以借助打印⽇志的⽅式查问题
-
在分布式、多线程/多进程代码中, 出现bug⽐较难以定位, 可以借助⽇志系统打印log帮助定位bug
-
帮助⾸次接触项⽬代码的新开发⼈员理解代码的运⾏流程
5.2日志系统技术实现
⽇志系统的技术实现主要包括三种类型:
-
利⽤printf、std::cout等输出函数将⽇志信息打印到控制台
-
对于⼤型商业化项⽬, 为了⽅便排查问题,我们⼀般会将⽇志输出到⽂件或者是数据库系统⽅便查询和分析⽇志, 主要分为同步⽇志和异步⽇志⽅式
- 同步写⽇志
- 异步写⽇志
5.2.1同步写日志
同步⽇志是指==当输出⽇志时,必须等待⽇志输出语句执⾏完毕后,才能执⾏后⾯的业务逻辑语句,==⽇志输出语句与程序的业务逻辑语句将在同⼀个线程运⾏。每次调⽤⼀次打印⽇志API就对应⼀次系统调⽤write写⽇志⽂件。

在⾼并发场景下,随着⽇志数量不断增加,同步⽇志系统容易产⽣系统瓶颈:
- ⼀⽅⾯,⼤量的⽇志打印陷⼊等量的write系统调⽤,有⼀定系统开销.
- 另⼀⽅⾯,使得打印⽇志的进程附带了⼤量同步的磁盘IO,影响程序性能
同步写日志就是直接写磁盘
5.2.2异步写日志
异步⽇志是指在进⾏⽇志输出时,⽇志输出语句与业务逻辑语句并不是在同⼀个线程中运⾏,⽽是有专⻔的线程⽤于进⾏⽇志输出操作。业务线程只需要将⽇志放到⼀个内存缓冲区中不⽤等待即可继续执⾏后续业务逻辑(作为⽇志的⽣产者),⽽⽇志的落地操作交给单独的⽇志线程去完成(作为⽇志的消费者), 这是⼀个典型的⽣产-消费模型。
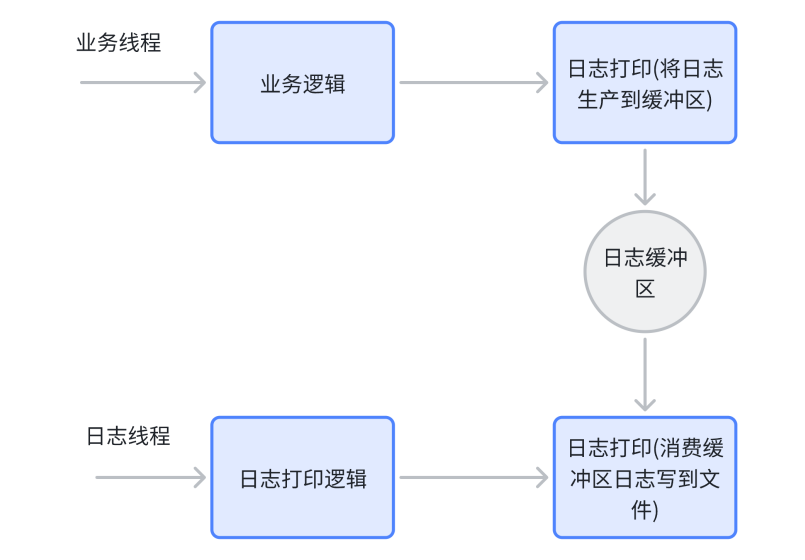
这样做的好处是即使⽇志没有真的地完成输出也不会影响程序的主业务,可以提⾼程序的性能:
- 主线程调⽤⽇志打印接⼝成为⾮阻塞操作
- 同步的磁盘IO从主线程中剥离出来交给单独的线程完成
6.相关技术知识补充
在初学C语⾔的时候,我们都⽤过printf函数进⾏打印。其中printf函数就是⼀个不定参函数,在函数内部可以根据格式化字符串中格式化字符分别获取不同的参数进⾏数据的格式化。⽽这种不定参函数在实际的使⽤中也⾮常多⻅,在这⾥简单做⼀介绍:
6.1不定参函数
一个函数中有多少个参数是不确定的或者是不固定的
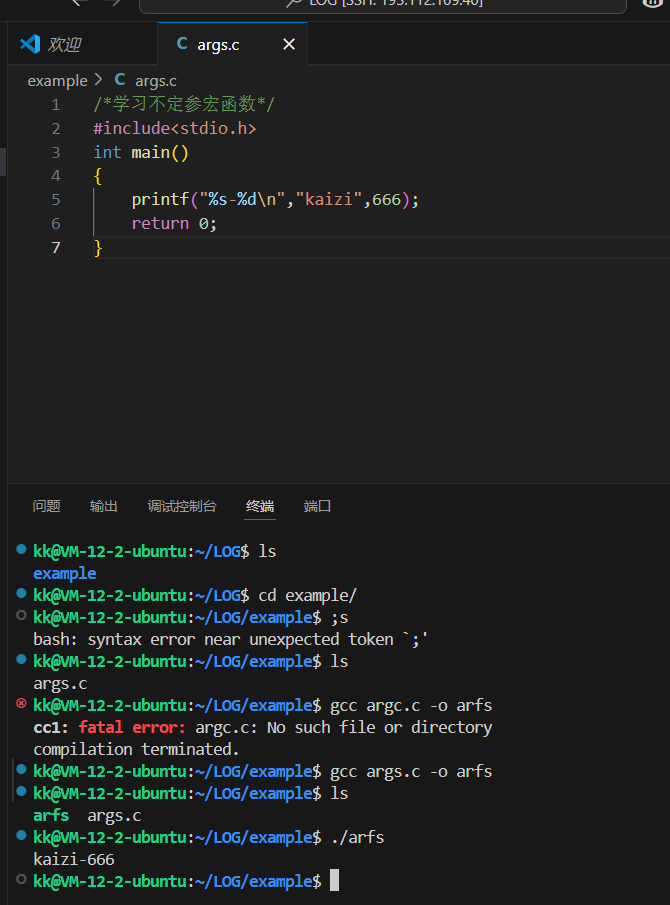
6.1.1C语言风格
/*学习不定参宏函数*/#include<stdio.h>int main(){printf("%s-%d\n","kaizi",666);return 0;}
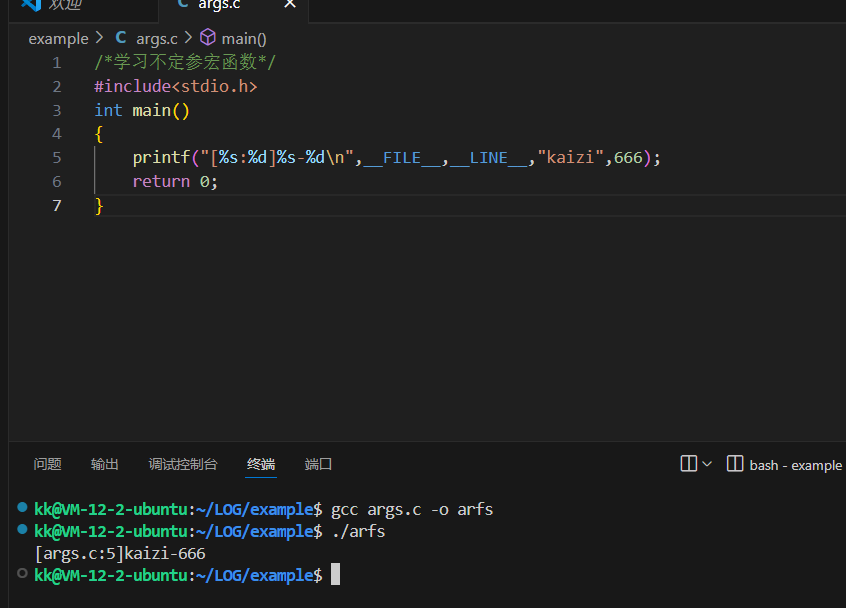
如果我们想在当前的基础上加上我们的文件名和行号
编译器提供了两个宏
__FILE__和__LINE__
代码如下:
/*学习不定参宏函数*/#include<stdio.h>int main(){printf("[%s:%d]%s-%d\n",__FILE__,__LINE__,"kaizi",666);return 0;}
效果如下:
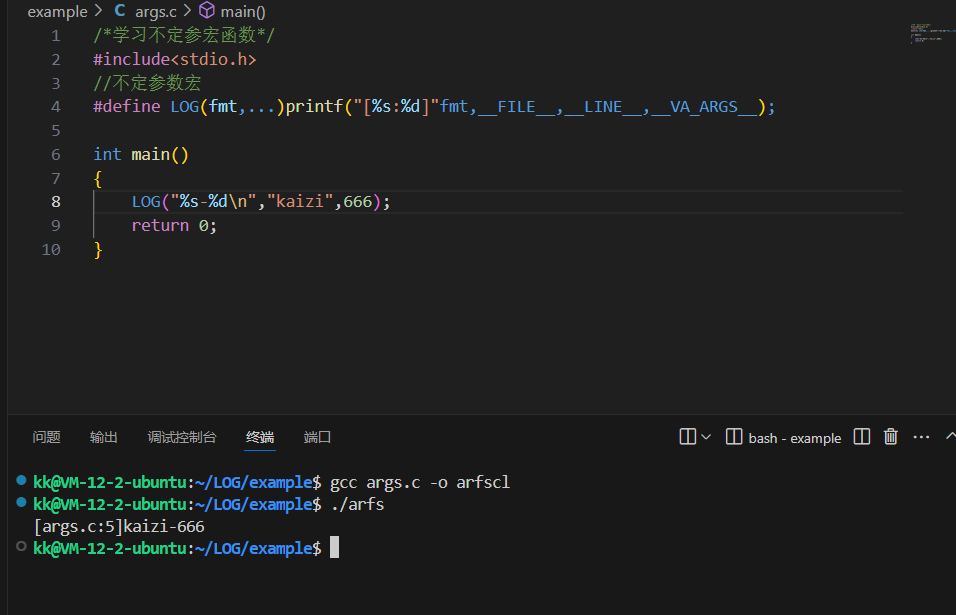
 但是这样还是很麻烦,所以我们直接定义一个宏
但是这样还是很麻烦,所以我们直接定义一个宏
代码如下:
/*学习不定参宏函数*/#include<stdio.h>//不定参数宏#define LOG(fmt,...)printf("[%s:%d]"fmt,__FILE__,__LINE__,__VA_ARGS__);/*LOG(fmt, ...):宏名称是 LOG,它接受一个固定参数 fmt(格式字符串),后面是 ... 表示可以传入任意数量的额外参数(不定参)。printf("[%s:%d]"fmt, __FILE__, __LINE__, __VA_ARGS__);宏体中调用了 printf。"[%s:%d]"fmt:格式化字符串,将会被拼接成如 "[main.c:10]%s-%d\n"。__FILE__:这是一个预定义宏,表示当前源文件的名称(如 main.c)。__LINE__:当前所在的行号。__VA_ARGS__:表示传入的不定参数部分。使用举例LOG("%s-%d\n", "kaizi", 666);预处理展开后会变成类似这样:printf("[%s:%d]%s-%d\n", __FILE__, __LINE__, "kaizi", 666);我们的[%s:%d]这个是固定的文件名和行号的输出操作然后我们的fmt输出的就是%s-%d\n,kaizi和666就是不定参数部分*/int main(){LOG("%s-%d\n","kaizi",666);return 0;}
效果如下:
但是如果这个不定参为空的话,那么我们这里就是会出问题的,就是后面没有任何的参数
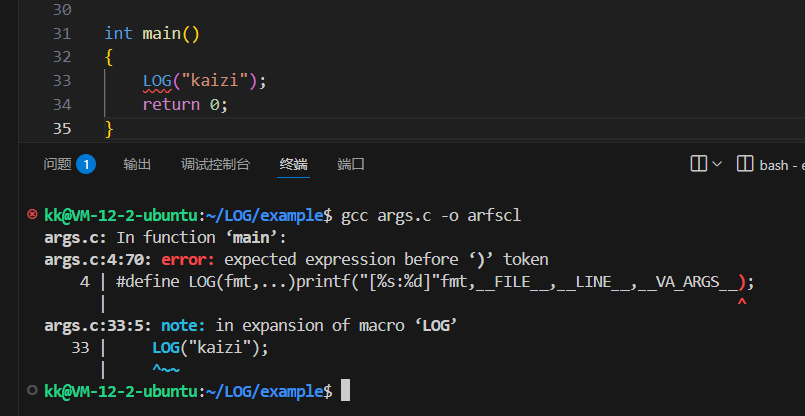
为了避免这种情况的话,我们直接在宏定义__VA_ARGS__这个位置前面加上两个#就行了
代码如下:
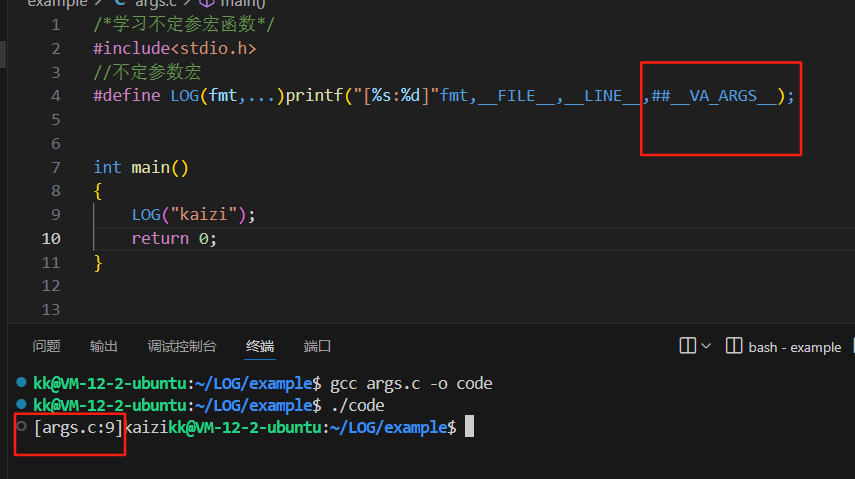
/*学习不定参宏函数*/#include<stdio.h>//不定参数宏#define LOG(fmt,...)printf("[%s:%d]"fmt,__FILE__,__LINE__,##__VA_ARGS__);//## 其作用是处理可变参数为空的情况,避免编译错误int main(){LOG("kaizi");return 0;}
6.1.2C语言函数中的不定参
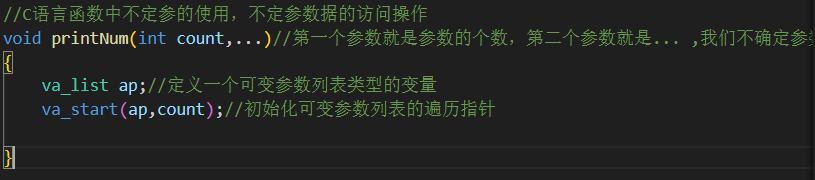
我们这里介绍一个函数va_start,利用va_start进行我们不定参地址的获取操作
我们先利用va_list进行定义一个可变参数列表类型的变量
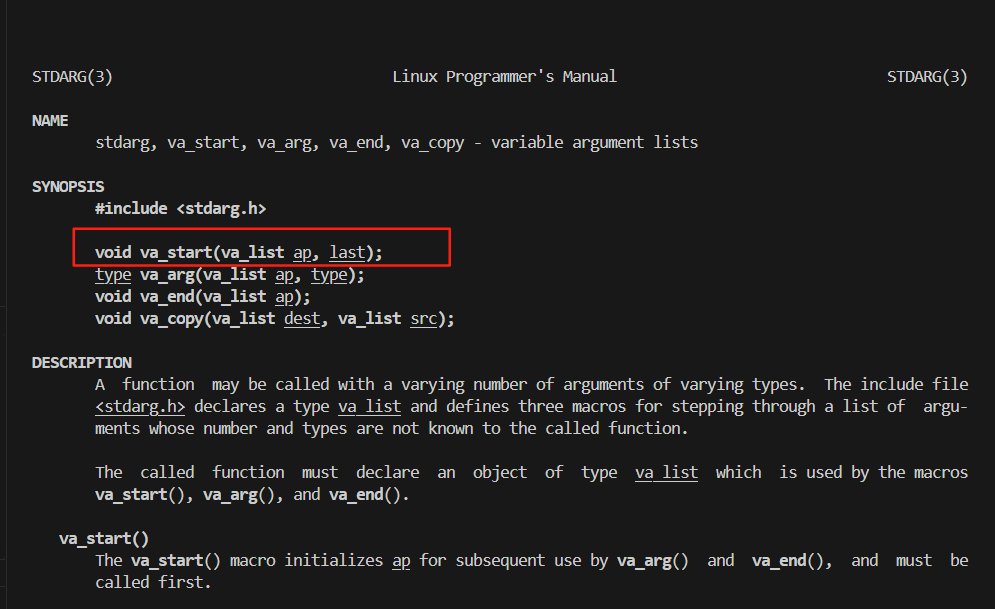
这里的va_start有两个参数,第二个参数last就是我们需要获取函数的哪个参数后面第一个不定参参数的地址,我们这里的话就是直接将count传进去,因为我们要获取last后面的不定参参数的地址
从我们参数列表开始,我们要获取什么类型的参数,我们利用va_arg获取可变参数列表中获取下一个对应类型的参数
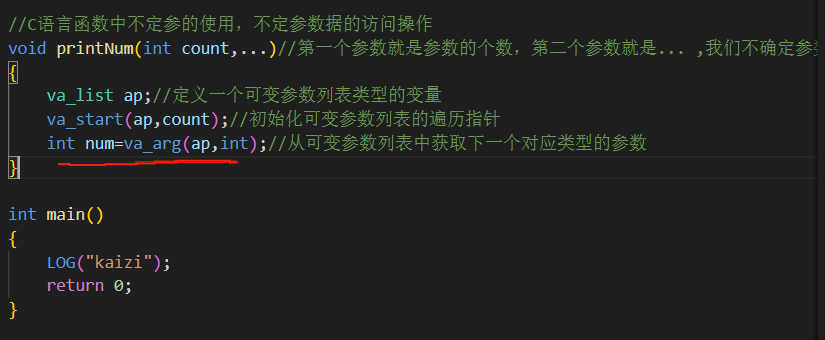
然后我们将这个获取列表中对应类型的参数这个代码放到一个循环中
在循环结束之后,我们需要将可变参数列表的指针进行置空操作
使用va_end(ap)
效果如下:
代码如下:
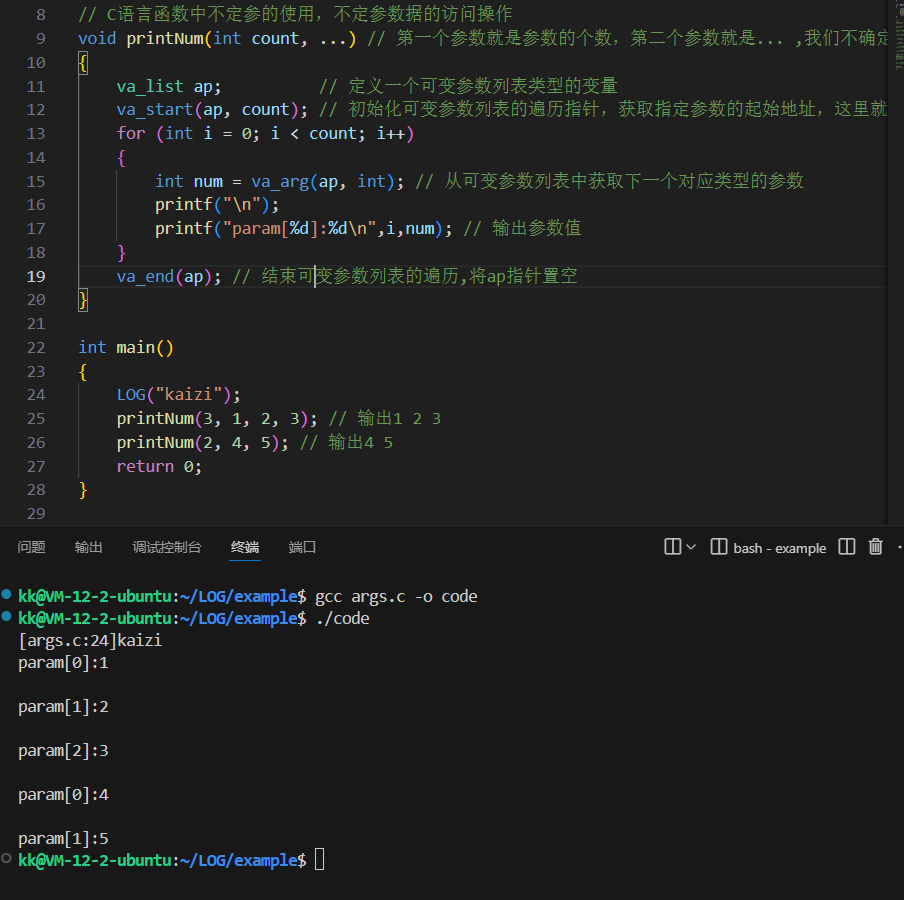
#include <stdio.h>#include <stdarg.h>void printNum(int count, ...) // 第一个参数就是参数的个数,第二个参数就是... ,我们不确定参数的个数{va_list ap; // 定义一个可变参数列表类型的变量va_start(ap, count); // 初始化可变参数列表的遍历指针,获取指定参数的起始地址,这里就是获取count参数后第一个参数的起始地址for (int i = 0; i < count; i++){int num = va_arg(ap, int); // 从可变参数列表中获取下一个对应类型的参数printf("\n");printf("param[%d]:%d\n",i,num); // 输出参数值}va_end(ap); // 结束可变参数列表的遍历,将ap指针置空}int main(){LOG("kaizi");printNum(3, 1, 2, 3); // 输出1 2 3printNum(2, 4, 5); // 输出4 5return 0;}
你们可以会疑惑,为什么这个循环里面的num在变化呢?难道是这个ap指针会变化么,解释如下:
代码的 for 循环里,ap 指针会随着 va_arg(ap, int) 的调用不断变化,逐步移动指向可变参数列表里的下一个参数
va_arg(ap, int) 的工作分两步:
- 取值:从
ap当前指向的地址,按int类型读出数据(比如第一次读1)。 - 移动指针:根据
int类型的大小(通常是 4 字节),把ap往后移动,指向下一个可变参数的地址
循环里每执行一次va_arg,ap就会 “跳” 到下一个参数,所以这个num每次循环都是会变化的,随着我们类型的字节大小变化,所以我们这里的参数里面得加上int类型
这里我们了解了四个函数,但是其实不是函数,其实是宏
va_list
va_start
va_arg
va_end
我们这里写一个printf函数,针对与不定参来说
那么这里我们就介绍到一个接口vasprintf,这个函数就是对不定参函数的基本使用
第一个参数我们给一个空的一级指针的地址进去,然后编译器会对这个地址进行内部字符串的组织,然后根据fmt内部的格式化字符,来从参数列表中取出一个一个的参数放到地址空间中进行组织
用完了记得进行释放操作,不然的话是会出现内存泄漏的
如果vasprintf的返回值是-1的话,那么就说明错误了,如果成功了的话,返回的就是组织好的字符串的长度
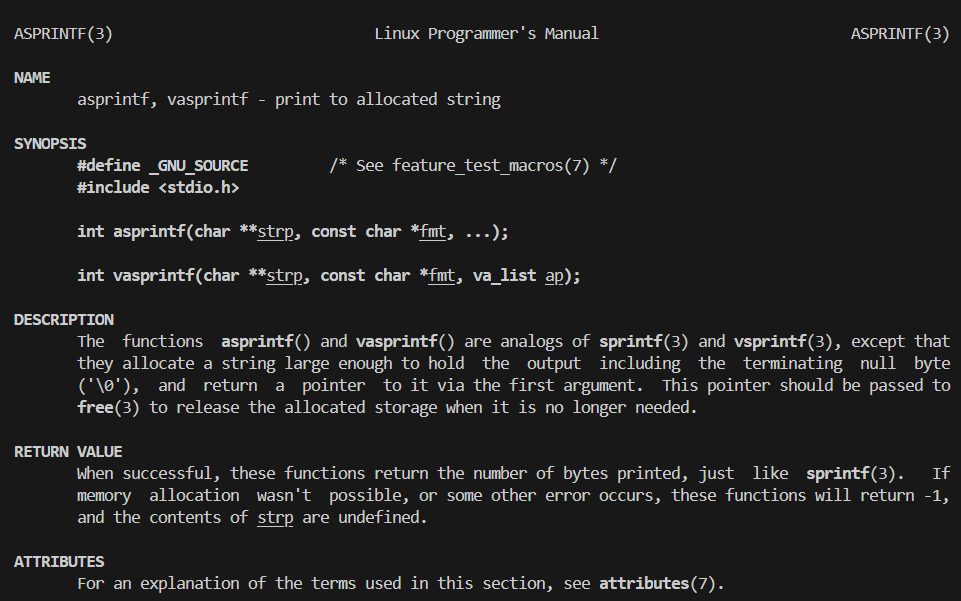
如果要使用vasprintf的话我们得加上头文件stdio.h和一个宏:
#define _GNU_SOURCE
具体效果如下:
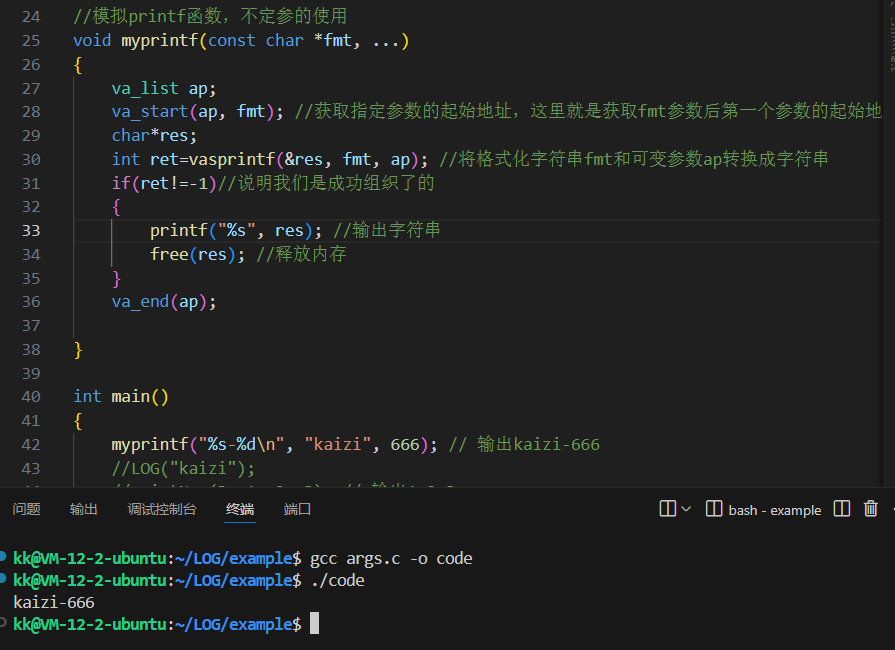
具体代码如下:
//模拟printf函数,不定参的使用void myprintf(const char *fmt, ...){va_list ap; //定义一个可变参数列表变量 `ap` va_start(ap, fmt); //获取指定参数的起始地址,这里就是获取fmt参数后第一个参数的起始地址char*res;//定义一个存储结果的指针int ret=vasprintf(&res, fmt, ap); //将格式化字符串fmt和可变参数ap转换成字符串if(ret!=-1)//说明我们是成功组织了的{printf("%s", res); //输出字符串free(res); //释放内存}va_end(ap);}int main(){myprintf("%s-%d\n", "kaizi", 666); // 输出kaizi-666//LOG("kaizi");//printNum(3, 1, 2, 3); // 输出1 2 3//printNum(2, 4, 5); // 输出4 5return 0;}
myprintf 函数的作用是接收一个格式化字符串 fmt 和若干个可变参数,然后将它们组合成一个完整的字符串并输出
vasprintf(&res, fmt, ap);
- 根据格式化字符串
fmt和可变参数列表ap,生成最终的格式化字符串,将分配的内存地址赋给res指针
这个就是我们C语言中不定参数函数的基本使用方式
同样使用…对不定参进行表示
6.1.3C++风格不定参数
这里我们的代码如下
#include <iostream>using namespace std;/*C++风格的补丁参函数使用*///这行声明了一个模板,它能接收至少 1 个类型(T),后面还能跟着任意数量类型(Args 包 )。template<typename T,typename ...Args>//不定参的参数包类型,Args 是一个 “包”,可以包含零个或多个类型void xprintf(T&v,Args&&... args){cout<<v;//先将V打印了if(sizeof ...(args)>0)//;利用sizeof算出参数包中的参数的个数,这里的args得括起来,不然会报错{xprintf(forward<Args>(args)...);//进行一个完美转发,将参数包中的参数转发给xprintf,递归调用//这个完美转发的话就是说,你原先传过来的是一个左值那就是左值,右值就是右值,通过完美转发不会改变性质的//因为我们要是传递多个参数的,而不是一个参数包,所以我们需要对这个参数包进行一个展开操作,直接在后面加上...就行了}else//如果参数没有了的话{cout<<endl;//换行}}//上面的写法可能会出问题,因为到最后的话是没有参数的,所以会报错,所以我们需要改一下:int main(){xprintf("kaizi");xprintf("kaizi","666");return 0;}
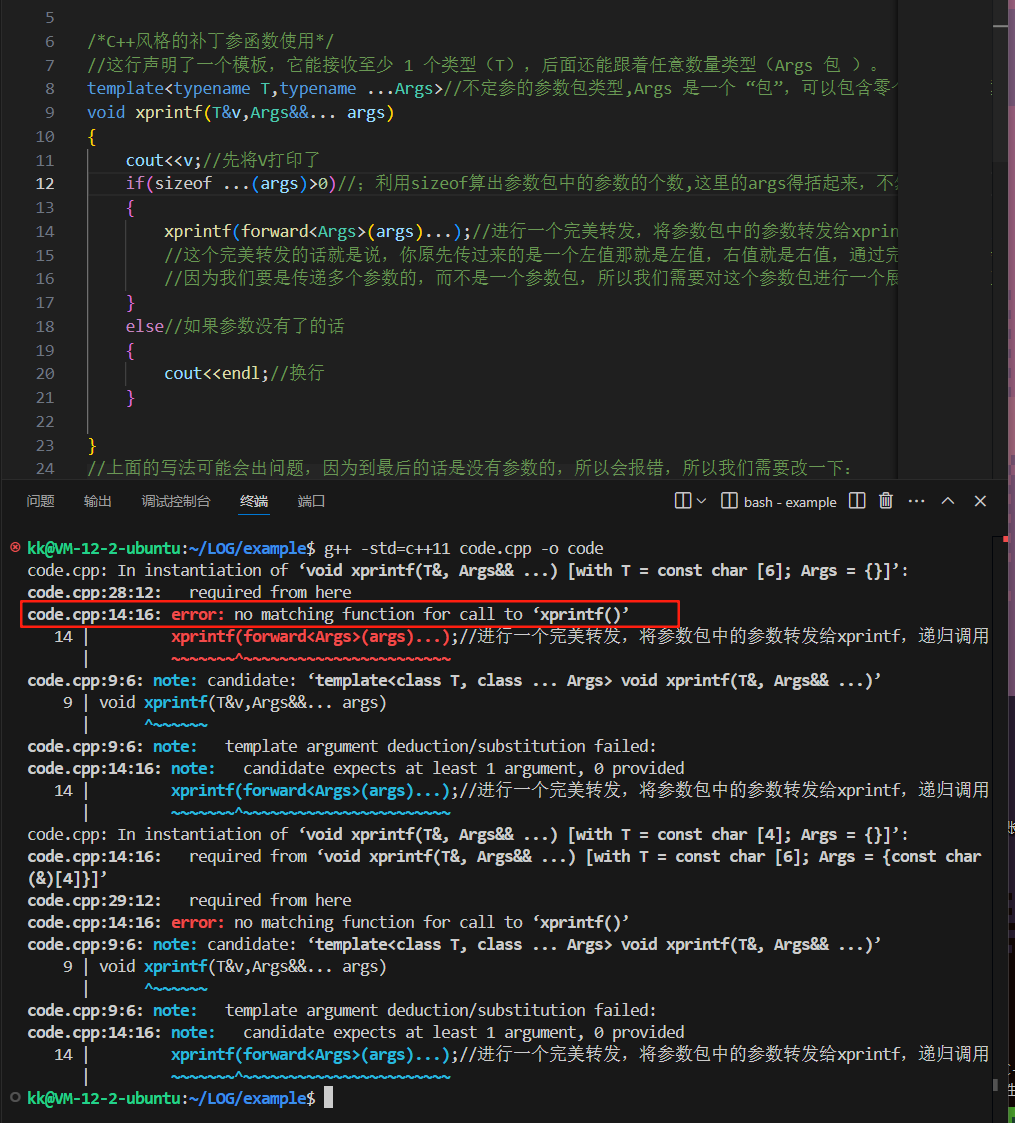
这里显示报错了,因为我们递归到最后,我们是没有参数了,最后的时候是一个0参,所以是会出现报错情况的
所以我们需要进行特例下
我们将这里的else中的代码改成无参形式的换行
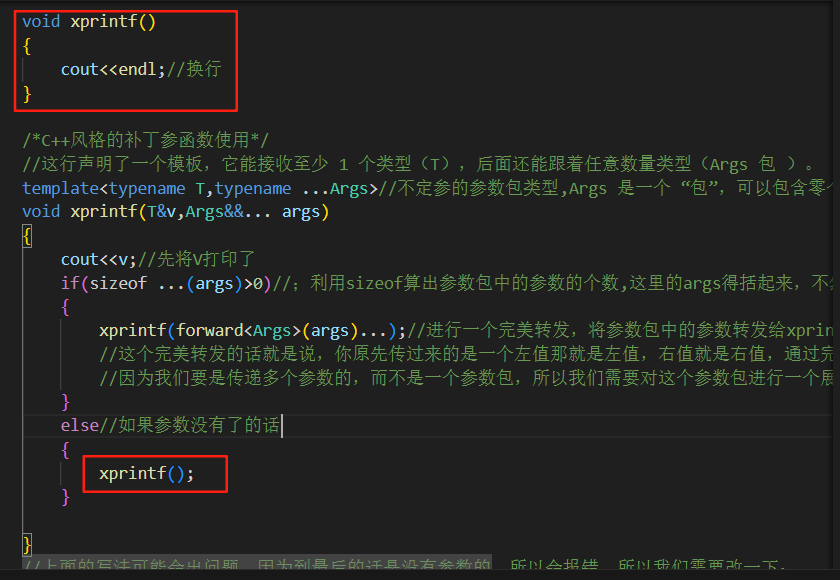
#include <iostream>using namespace std;void xprintf(){cout<<endl;//换行}/*C++风格的补丁参函数使用*///这行声明了一个模板,它能接收至少 1 个类型(T),后面还能跟着任意数量类型(Args 包 )。template<typename T,typename ...Args>//不定参的参数包类型,Args 是一个 “包”,可以包含零个或多个类型void xprintf(const T&v,Args&&... args){cout<<v;//先将V打印了if(sizeof ...(args)>0)//;利用sizeof算出参数包中的参数的个数,这里的args得括起来,不然会报错{xprintf(forward<Args>(args)...);//进行一个完美转发,将参数包中的参数转发给xprintf,递归调用//这个完美转发的话就是说,你原先传过来的是一个左值那就是左值,右值就是右值,通过完美转发不会改变性质的//因为我们要是传递多个参数的,而不是一个参数包,所以我们需要对这个参数包进行一个展开操作,直接在后面加上...就行了}else//如果参数没有了的话{xprintf();}}//上面的写法可能会出问题,因为到最后的话是没有参数的,所以会报错,所以我们需要改一下:int main(){xprintf("kaizi");xprintf("kaizi","666");return 0;}
就这样就可以解决问题了
因为我们在main函数中传的都是const char * 类型的数据,所以我们在xprintf的第一个模版参数前面得加上const进行限制下,不然会报错的,类型不能进行正常的转换操作
这样子我们就成功将数据打印下来了
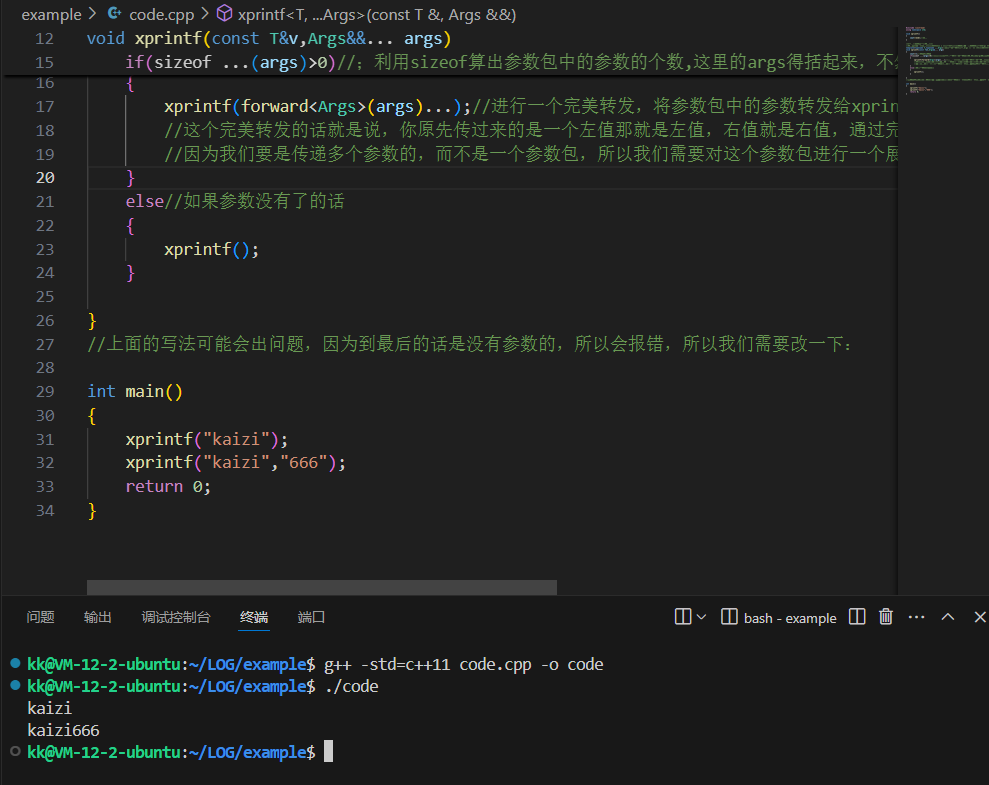
通过递归和完美转发来处理任意数量、任意类型的参数
-
当递归到最后一个参数时,参数包
args为空,会调用这个void xprintf版本的函数,- 它的作用是输出换行符,结束整个打印过程 -
Args&&... args:万能引用(转发引用),接收剩余参数包 -
forward<Args>(args)...是关键:forward保持参数的左值 / 右值属性(完美转发)(args)...将参数包展开为多个独立参数
-
例如,若
args包包含(a, b, c),展开后变为forward(a), forward(b), forward(c)
关键点 -
必须有一个无参版本作为终止条件,通过每次处理一个参数并递归剩余参数包来展开
-
使用
Args&&...(转发引用)和forward确保参数的左值 / 右值属性不丢失
6.2设计模式
设计模式是前辈们对代码开发经验的总结,是解决特定问题的⼀系列套路。它不是语法规定,⽽是⼀套⽤来提⾼代码可复⽤性、可维护性、可读性、稳健性以及安全性的解决⽅案。
6.2.1六大原则
- 单⼀职责原则(Single Responsibility Principle);
- 类的职责应该单⼀,⼀个⽅法只做⼀件事。职责划分清晰了,每次改动到最⼩单位的⽅法或类。
- 使⽤建议:两个完全不⼀样的功能不应该放⼀个类中,⼀个类中应该是⼀组相关性很⾼的函数、数据的封装
- ⽤例:⽹络聊天:⽹络通信 & 聊天,应该分割成为⽹络通信类 & 聊天类
- 开闭原则(Open Closed Principle);
- 对扩展开放,对修改封闭
- 使⽤建议:对软件实体的改动,最好⽤扩展⽽⾮修改的⽅式。
- ⽤例:超时卖货:商品价格—不是修改商品的原来价格,⽽是新增促销价格。
- ⾥⽒替换原则(Liskov Substitution Principle);
- 通俗点讲,就是只要⽗类能出现的地⽅,⼦类就可以出现,⽽且替换为⼦类也不会产⽣任何错误或异常。
- 在继承类时,务必重写⽗类中所有的⽅法,尤其需要注意⽗类的protected⽅法,⼦类尽量不要暴露⾃⼰的public⽅法供外界调⽤。
- 使⽤建议:⼦类必须完全实现⽗类的⽅法,孩⼦类可以有⾃⼰的个性。覆盖或实现⽗类的⽅法时,输⼊参数可以被放⼤,输出可以缩⼩
- ⽤例:跑步运动员类-会跑步,⼦类⻓跑运动员-会跑步且擅⻓ 跑, ⼦类短跑运动员-会跑步且擅⻓短跑
- 依赖倒置原则(Dependence Inversion Principle)。
- ⾼层模块不应该依赖低层模块,两者都应该依赖其抽象. 不可分割的原⼦逻辑就是低层模式,原⼦逻辑组装成的就是⾼层模块。
- 模块间依赖通过抽象(接⼝)发⽣,具体类之间不直接依赖
- 使⽤建议:每个类都尽量有抽象类,任何类都不应该从具体类派⽣。尽量不要重写基类的⽅法。结合⾥⽒替换原则使⽤。
- ⽤例:奔驰⻋司机类–只能开奔驰; 司机类 – 给什么⻋,就开什么⻋; 开⻋的⼈:司机–依赖于抽象
- 迪⽶特法则(Law of Demeter),⼜叫“最少知道法则”;
- 尽量减少对象之间的交互,从⽽减⼩类之间的耦合。⼀个对象应该对其他对象有最少的了解。对类的低耦合提出了明确的要求:
- 只和直接的朋友交流, 朋友之间也是有距离的。⾃⼰的就是⾃⼰的(如果⼀个⽅法放在本类中,既不增加类间关系,也对本类不产⽣负⾯影响,那就放置在本类中)。
- ⽤例:⽼师让班⻓点名–⽼师给班⻓⼀个名单,班⻓完成点名勾选,返回结果,⽽不是班⻓点名,⽼师勾选
- 尽量减少对象之间的交互,从⽽减⼩类之间的耦合。⼀个对象应该对其他对象有最少的了解。对类的低耦合提出了明确的要求:
- 接⼝隔离原则(Interface Segregation Principle);
- 客⼾端不应该依赖它不需要的接⼝,类间的依赖关系应该建⽴在最⼩的接⼝上
- 使⽤建议:接⼝设计尽量精简单⼀,但是不要对外暴露没有实际意义的接⼝。
- ⽤例:修改密码,不应该提供修改⽤⼾信息接⼝,⽽就是单⼀的最⼩修改密码接⼝,更不要暴露数据库操作
从整体上来理解六⼤设计原则,可以简要的概括为⼀句话,⽤抽象构建框架,⽤实现扩展细节,具体
到每⼀条设计原则,则对应⼀条注意事项:
- 单⼀职责原则告诉我们实现类要职责单⼀;
- ⾥⽒替换原则告诉我们不要破坏继承体系;
- 依赖倒置原则告诉我们要⾯向接⼝编程;
- 接⼝隔离原则告诉我们在设计接⼝的时候要精简单⼀;
- 迪⽶特法则告诉我们要降低耦合;
- 开闭原则是总纲,告诉我们要对扩展开放,对修改关闭。
6.2.2单例模式
⼀个类只能创建⼀个对象,即单例模式,该设计模式可以保证系统中该类只有⼀个实例,并提供⼀个访问它的全局访问点,该实例被所有程序模块共享。⽐如在某个服务器程序中,该服务器的配置信息存放在⼀个⽂件中,这些配置数据由⼀个单例对象统⼀读取,然后服务进程中的其他对象再通过这个单例对象获取这些配置信息,这种⽅式简化了在复杂环境下的配置管理。
单例模式有两种实现模式:饿汉模式和懒汉模式
6.2.3饿汉模式
- 饿汉模式: 程序启动时就会创建⼀个唯⼀的实例对象。 因为单例对象已经确定, 所以⽐较适⽤于多线程环境中, 多线程获取单例对象不需要加锁, 可以有效的避免资源竞争, 提⾼性能。
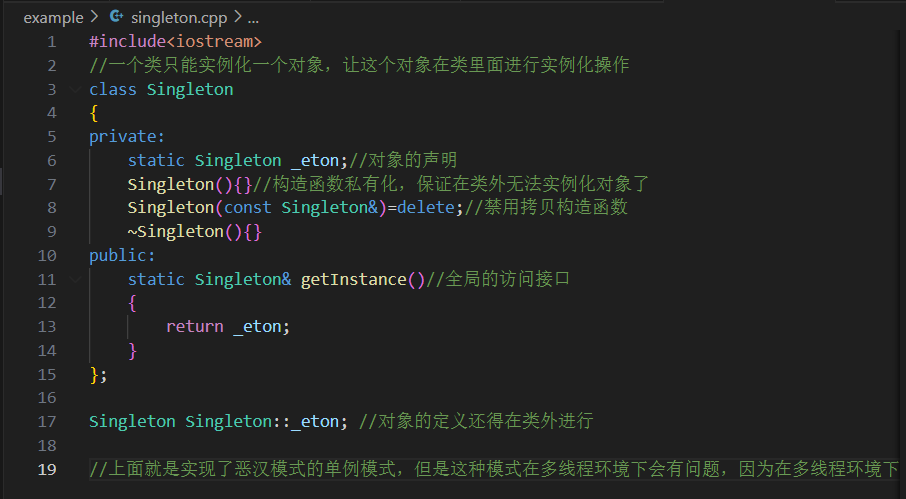
代码示例如下:
#include<iostream>//一个类只能实例化一个对象,让这个对象在类里面进行实例化操作class Singleton{private:static Singleton _eton;//对象的声明Singleton(){}//构造函数私有化,保证在类外无法实例化对象了Singleton(const Singleton&)=delete;//禁用拷贝构造函数~Singleton(){}public:static Singleton& getInstance()//全局的访问接口{return _eton;}};Singleton Singleton::_eton; //对象的定义还得在类外进行//上面就是实现了恶汉模式的单例模式,但是这种模式在多线程环境下会有问题,因为在多线程环境下,如果多个线程同时调用getInstance()函数,就会造成多个对象被创建,这就违背了单例模式的原则。
然后我们在在类中添加了一个变量进行一个对象的数据打印
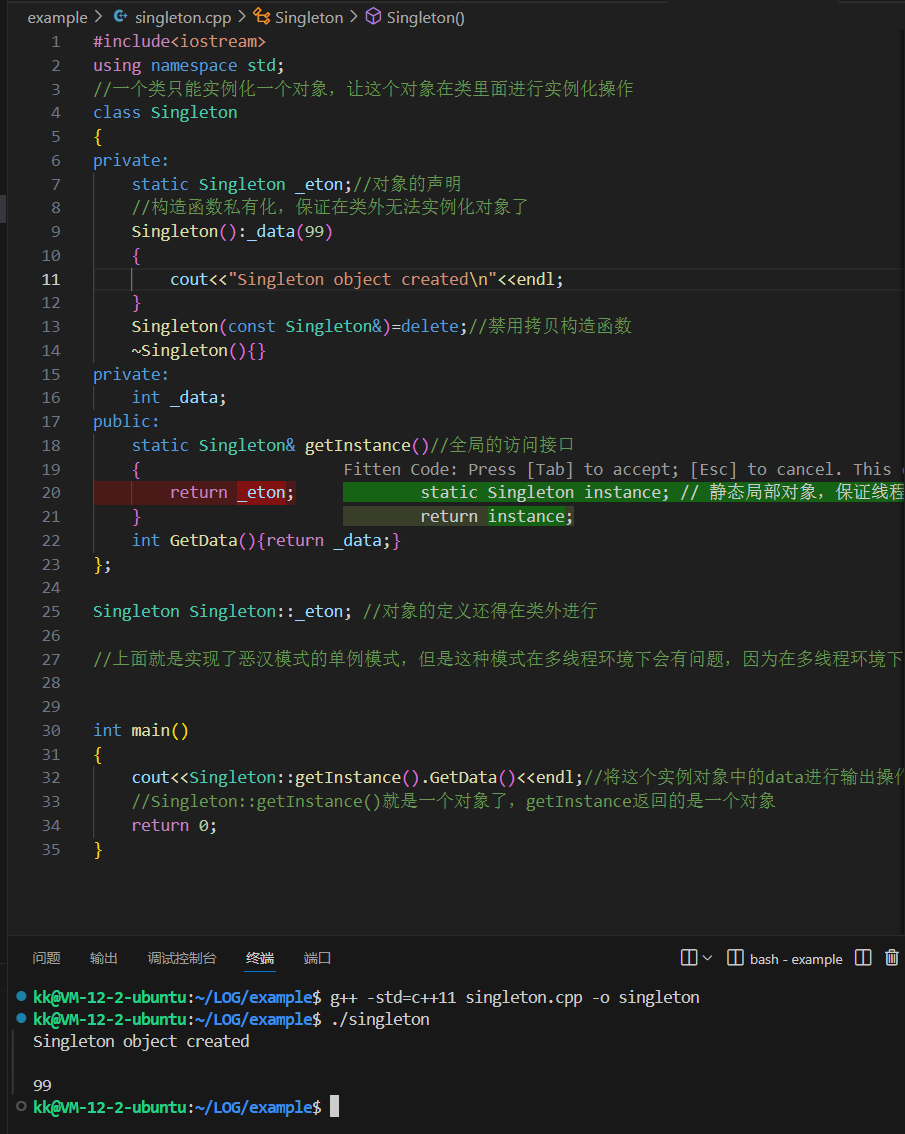
#include<iostream>using namespace std;//一个类只能实例化一个对象,让这个对象在类里面进行实例化操作class Singleton{private:static Singleton _eton;//对象的声明//构造函数私有化,保证在类外无法实例化对象了Singleton():_data(99){cout<<"Singleton object created"<<endl;}Singleton(const Singleton&)=delete;//禁用拷贝构造函数~Singleton(){}private:int _data;public:static Singleton& getInstance()//全局的访问接口{return _eton;}int GetData(){return _data;}};Singleton Singleton::_eton; //对象的定义还得在类外进行//上面就是实现了恶汉模式的单例模式,但是这种模式在多线程环境下会有问题,因为在多线程环境下,如果多个线程同时调用getInstance()函数,就会造成多个对象被创建,这就违背了单例模式的原则。int main(){cout<<Singleton::getInstance().GetData()<<endl;//将这个实例对象中的data进行输出操作了//Singleton::getInstance()就是一个对象了,getInstance返回的是一个对象return 0;}
在整个代码中,我们就算没有main函数中的这个打印操作,我们单例对象依旧能正常进行构造操作
因为我们这个对象是静态的对象,他的生命周期是随着整个程序的,在程序初始化的时候就已经构造好了这个对象了
懒汉模式:第⼀次使⽤要使⽤单例对象的时候创建实例对象。如果单例对象构造特别耗时或者耗费济源(加载插件、加载⽹络资源等), 可以选择懒汉模式, 在第⼀次使⽤的时候才创建对象。

class Singleton{private:// 构造函数私有化,保证在类外无法实例化对象了Singleton() : _data(99){cout << "Singleton object created" << endl;}Singleton(const Singleton &) = delete; // 禁用拷贝构造函数~Singleton() {}private:int _data;public://调用这个函数的时候就进行创建了一个对象static Singleton& getInstance(){static Singleton _eton; // 直接定义一个静态局部对象,只会在第一次调用getInstance()的时候实例化//以确保C++11起,静态变量将能够在满⾜ thread-safe 的前提下唯⼀地被构造和析构//如果多个线程同时舒适化同一个静态局部变量的话,则初始化只会发生一次return _eton;}int GetData(){return _data;}};
6.2.4工厂模式
⼯⼚模式是⼀种创建型设计模式, 它提供了⼀种创建对象的最佳⽅式。在⼯⼚模式中,我们创建对象时不会对上层暴露创建逻辑,⽽是通过使⽤⼀个共同结构来指向新创建的对象,以此实现创建-使⽤的分离。
⼯⼚模式可以分为:
6.2.4.1简单工厂模式
- 简单⼯⼚模式: 简单⼯⼚模式实现由⼀个⼯⼚对象通过类型决定创建出来指定产品类的实例。假设有个⼯⼚能⽣产出⽔果,当客⼾需要产品的时候明确告知⼯⼚⽣产哪类⽔果,⼯⼚需要接收用户提供的类别信息,当新增产品的时候,⼯⼚内部去添加新产品的⽣产⽅式。
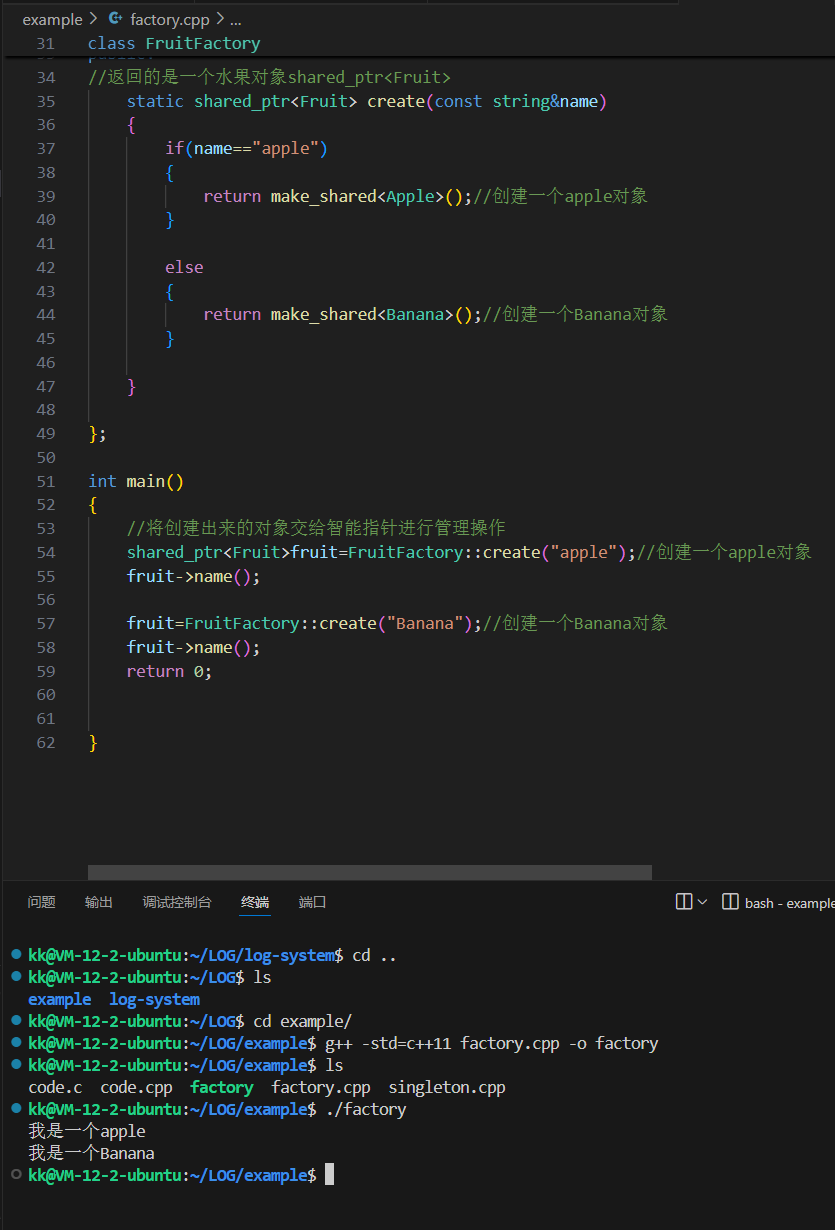
#include<iostream>#include<memory>using namespace std;class Fruit{public:virtual void name()=0;//纯虚函数private:};class Apple:public Fruit//继承水果类{public:void name() override//override表示对父类虚函数的重写操作{cout<<"我是一个apple\n";}};class Banana:public Fruit//继承水果类{public:void name() override//override表示对父类虚函数的重写操作{cout<<"我是一个Banana\n";}};class FruitFactory{public://返回的是一个水果对象shared_ptr<Fruit>static shared_ptr<Fruit> create(const string&name){if(name=="apple"){return make_shared<Apple>();//创建一个apple对象}else{return make_shared<Banana>();//创建一个Banana对象}}};int main(){//将创建出来的对象交给智能指针进行管理操作shared_ptr<Fruit>fruit=FruitFactory::create("apple");//创建一个apple对象fruit->name();fruit=FruitFactory::create("Banana");//创建一个Banana对象fruit->name();return 0;}
简单⼯⼚模式:通过参数控制可以⽣产任何产品
优点:简单粗暴,直观易懂。使⽤⼀个⼯⼚⽣产同⼀等级结构下的任意产品
缺点:
-
- 所有东西⽣产在⼀起,产品太多会导致代码量庞⼤
-
- 开闭原则遵循(开放拓展,关闭修改)的不是太好,要新增产品就必须修改⼯⼚⽅法。
对于这个代码进行解决操作
抽象基类 Fruit
- 定义纯虚函数
name(),强制派生类实现该方法。 - 使
Fruit成为抽象类,无法直接实例化,只能通过派生类实现
具体实现类Apple和Banana - 继承自
Fruit,并使用override进行重写name()方法,输出各自的名称。 - 使用
override关键字显式声明重写基类虚函数,提高代码安全性。
-
工厂类
FruitFactory- 静态方法
create()根据传入的名称创建对应的水果对象。 - 返回
shared_ptr<Fruit>智能指针,自动管理对象生命周期,避免内存泄漏。
让一个产品的生成和表示进行分离开来,以便于我们代码的后期维护
- 静态方法
这个模式的结构和管理产品对象的⽅式⼗分简单, 但是它的扩展性⾮常差,当我们需要新增产品的时候,就需要去修改⼯⼚类新增⼀个类型的产品创建逻辑,违背了开闭原则。
6.2.4.2工厂方法模式
⼯⼚⽅法模式: 在简单⼯⼚模式下新增多个⼯⼚,多个产品,每个产品对应⼀个⼯⼚。假设现在有A、B 两种产品,则开两个⼯⼚,⼯⼚ A 负责⽣产产品 A,⼯⼚ B 负责⽣产产品 B,⽤⼾只知道产品的⼯⼚名,⽽不知道具体的产品信息,⼯⼚不需要再接收客⼾的产品类别,⽽只负责⽣产产品。
各自的产品有各自的工厂进行负责生产操作,这样的话如果我们现在多了一种水果的话,那么我们直接多一个对应的水果工厂就行了
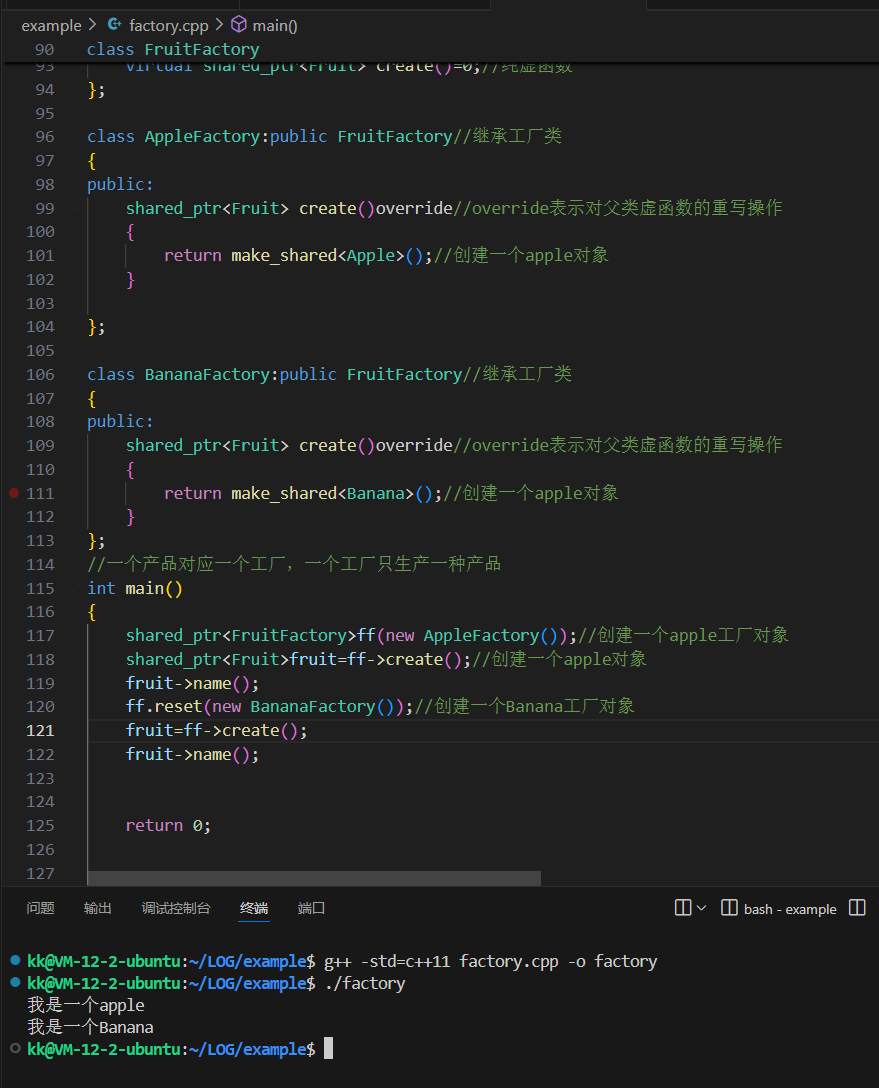
/*工厂方法模式*/class Fruit{public:virtual void name()=0;//纯虚函数private:};class Apple:public Fruit//继承水果类{public:void name() override//override表示对父类虚函数的重写操作{cout<<"我是一个apple\n";}};class Banana:public Fruit//继承水果类{public:void name() override//override表示对父类虚函数的重写操作{cout<<"我是一个Banana\n";}};class FruitFactory{public:virtual shared_ptr<Fruit> create()=0;//纯虚函数};class AppleFactory:public FruitFactory//继承工厂类{public: shared_ptr<Fruit> create()override//override表示对父类虚函数的重写操作{return make_shared<Apple>();//创建一个apple对象}};class BananaFactory:public FruitFactory//继承工厂类{public: shared_ptr<Fruit> create()override//override表示对父类虚函数的重写操作{return make_shared<Banana>();//创建一个apple对象}};//一个产品对应一个工厂,一个工厂只生产一种产品int main(){shared_ptr<FruitFactory>ff(new AppleFactory());//创建一个apple工厂对象shared_ptr<Fruit>fruit=ff->create();//创建一个apple对象fruit->name();ff.reset(new BananaFactory());//创建一个Banana工厂对象fruit=ff->create();fruit->name();return 0;}
new AppleFactory()就是进行苹果工厂的构造操作
然后让智能指针管理这个对象ff
shared_ptr<FruitFactory> 表示这个智能指针指向的是抽象工厂 FruitFactory,但实际对象是具体工厂 AppleFactory。这是多态的关键:基类指针指向派生类对象。
-
客户端(
main函数)只需要知道抽象接口FruitFactory,不需要关心具体是哪个工厂。 -
后续可以通过这个基类指针调用
create()方法,实际执行的是AppleFactory重写的逻辑。 -
由于
ff实际指向AppleFactory对象,根据动态绑定(运行时多态),会调用AppleFactory::create()方法。
shared_ptr<Fruit>fruit=ff->create();
ff先调用工厂类创建一个apple对象
然后利用智能指针将这个对象进行托管,用水果类对象进行托管
⼯⼚⽅法模式每次增加⼀个产品时,都需要增加⼀个具体产品类和⼯⼚类,这会使得系统中类的个数成倍增加,在⼀定程度上增加了系统的耦合度。
6.2.4.3抽象工厂模式
抽象⼯⼚模式: ⼯⼚⽅法模式通过引⼊⼯⼚等级结构,解决了简单⼯⼚模式中⼯⼚类职责太重的问题,但由于⼯⼚⽅法模式中的每个⼯⼚只⽣产⼀类产品,可能会导致系统中存在⼤量的⼯⼚类,势必会增加系统的开销。此时,我们可以考虑将⼀些相关的产品组成⼀个产品族(位于不同产品等级结构中功能相关联的产品组成的家族),由同⼀个⼯⼚来统⼀⽣产,这就是抽象⼯⼚模式的基本思想。
/*抽象⼯⼚模式*/class Fruit{public:virtual void name() = 0; // 纯虚函数private:};class Apple : public Fruit // 继承水果类{public:void name() override // override表示对父类虚函数的重写操作{cout << "我是一个apple\n";}};class Banana : public Fruit // 继承水果类{public:void name() override // override表示对父类虚函数的重写操作{cout << "我是一个Banana\n";}};class Animal{public:virtual void name() = 0; // 纯虚函数};class Lamp : public Animal // 继承动物类{public:void name() override // override表示对父类虚函数的重写操作{cout << "我是一只山羊!!\n";}};class Dog : public Animal // 继承动物类{public:void name() override // override表示对父类虚函数的重写操作{cout << "我是一只小狗!!\n";}};// 超级工厂class Factory // 通过这个工厂类派生出对应类型的产品类{public:virtual shared_ptr<Fruit> getFruit(const string &name) = 0; // 水果类的纯虚函数virtual shared_ptr<Animal> getAnimal(const string &name) = 0; // 水果类的纯虚函数};// 水果工厂class FruitFactory : public Factory // 继承工厂类{public:shared_ptr<Fruit> getFruit(const string &name) override // override表示对父类虚函数的重写操作{// 根据不同的水果来产生水果对象if (name == "apple"){return make_shared<Apple>(); // 创建一个apple对象}else{return make_shared<Banana>(); // 创建一个Banana对象}}shared_ptr<Animal> getAnimal(const string &name) override // 水果类的纯虚函数{return shared_ptr<Animal>(); // 因为这个是水果工厂,所以没有动物,所以我们返回一个空的智能指针}};// 动物工厂class AnimalFactory : public Factory // 继承工厂类{public:shared_ptr<Fruit> getFruit(const string &name) override // override表示对父类虚函数的重写操作{return shared_ptr<Fruit>(); // 因为这个是动物工厂,所以没有水果,所以我们返回一个空的智能指针}shared_ptr<Animal> getAnimal(const string &name) override // 水果类的纯虚函数{if (name == "小狗"){return make_shared<Dog>(); // 创建一个Dog对象}else{return make_shared<Lamp>(); // 创建一个Lamp对象}}};//工厂生产者class FactoryProducer{public:static shared_ptr<Factory> create(const string &name) // 根据不同的类型来产生不同的工厂对象{if(name=="水果工厂"){return make_shared<FruitFactory>(); // 创建一个水果工厂对象}else{return make_shared<AnimalFactory>(); // 创建一个动物工厂对象}}};// 一个产品对应一个工厂,一个工厂只生产一种产品int main(){shared_ptr<Factory> ff = FactoryProducer::create("水果工厂"); // 创建一个水果工厂对象shared_ptr<Fruit> fruit = ff->getFruit("apple"); // 创建一个apple对象fruit->name();fruit=ff->getFruit("Banana"); // 创建一个Banana对象fruit->name();shared_ptr<Factory> factory = FactoryProducer::create("动物"); // 创建一个水果工厂对象shared_ptr<Fruit> animal = factory->getFruit("小狗"); // 创建一个apple对象animal->name();animal=factory->getFruit("山羊"); // 创建一个Banana对象animal->name();return 0;}
抽象⼯⼚模式适⽤于⽣产多个⼯⼚系列产品衍⽣的设计模式,增加新的产品等级结构复杂,需要对原有系统进⾏较⼤的修改,甚⾄需要修改抽象层代码,违背了“开闭原则”。
6.2.5建造者模式
建造者模式是⼀种创建型设计模式, 使⽤多个简单的对象⼀步⼀步构建成⼀个复杂的对象,能够将⼀个复杂的对象的构建与它的表⽰分离,提供⼀种创建对象的最佳⽅式。主要⽤于解决对象的构建过于复杂的问题。
建造者模式主要基于四个核⼼类实现:
- 抽象产品类:
- 具体产品类:⼀个具体的产品对象类
- 抽象Builder类:创建⼀个产品对象所需的各个部件的抽象接⼝
- 具体产品的Builder类:实现抽象接⼝,构建各个部件
- 指挥者Director类:统⼀组建过程,提供给调⽤者使⽤,通过指挥者来构造产品
/*通过苹果笔记本的构造理解建造者模式*/#include<memory>#include<iostream>#include<string>using namespace std;class Computer{public:Computer()//电脑类{}void setBoard(const string &board)//设置主板{_board=board;}void setDisplay(const string &display)//设置显示器{_display=display;}void showParamaters()//显示电脑参数{string param="Computer Parameters:\n";param+="\tBoard:"+_board+"\n";param+="\tDisplay:"+_display+"\n";param+="\tOs:"+_os+"\n";cout<<param<<endl;}virtual void setOS()=0;protected:string _board;//主板string _display;//显示器string _os;//操作系统};class MacBook :public Computer//苹果电脑类{public:void setOS()override{_os="Mac OS x12";//不能访问父类的私有成员}};class Builder//创造者类{public:virtual void buildBoard(const string &board)=0;virtual void builddisplay(const string &display)=0;virtual void buildOs()=0;virtual shared_ptr<Computer> build()=0;};class MacBookBuilder :public Builder//基于创造者的苹果笔记本创建者类{public:MacBookBuilder():_computer(new MacBook()){}void buildBoard(const string &board)//对这个电脑类对象的主板进行设置{_computer->setBoard(board);}void builddisplay(const string &display)//对这个电脑类对象的显示器进行设置{_computer->setDisplay(display);}void buildOs()//对这个电脑类对象的操作系统进行设置{_computer->setOS();//这里我们setOs里面已经设置好了笔记本的型号了}shared_ptr<Computer> build()//返回一个笔记本类对象{return _computer;}private:shared_ptr<Computer>_computer;//构建一个电脑类};//上面这个类就是创建零部件然后返回最终的电脑对象//下面我们还需要一个指挥家类的对象,因为可能零部件配置的顺序是不一样的class Director{public:Director(Builder *builder)//传进来一个builder对象:_builder(builder){}void construct(string board,string display)//指挥家类对象来配置零部件,需要传入一个显示器和主板的对象{_builder->buildBoard(board);//设置主板_builder->builddisplay(display);//设置显示器_builder->buildOs();//设置操作系统}private:shared_ptr<Builder>_builder;//一个Builder对象};int main(){Builder *builder=new MacBookBuilder();//创建一个苹果笔记本电脑unique_ptr<Director>director(new Director(builder));//创建一个指挥家类对象director->construct("华硕主板","苹果显示器");//指挥家类对象来配置零部件shared_ptr<Computer>computer=builder->build();//返回一个笔记本类对象computer->showParamaters();return 0;}
. 产品类:Computer 与 MacBook
- Computer 类:作为抽象基类,它定义了电脑的基本属性(像主板、显示器、操作系统)以及设置和展示这些参数的方法。其中,
setOS()被声明为纯虚函数,目的是让子类去具体实现。 - MacBook 类:继承自 Computer 类,它实现了
setOS()方法,将操作系统固定设为 “Mac OS x12”。
- 建造者类:Builder 与 MacBookBuilder
- Builder 接口:定义了构建电脑各个部件的抽象方法,包括
buildBoard()、buildDisplay()、buildOs(),还有返回最终产品的build()方法。 - MacBookBuilder 类:实现了 Builder 接口,在内部维护着一个 MacBook 对象。它的作用是按照要求配置 MacBook 的各个部件,最后返回配置好的电脑。
- 指挥者类:Director
-
Director 类:负责控制产品的构建流程。它接收一个 Builder 对象,然后按照特定顺序调用 Builder 的方法来构建产品。在这个例子中,
construct()方法会依次设置主板、显示器和操作系统 -
先创建一个
MacBookBuilder对象,专门用于构建苹果笔记本。 -
接着创建一个
Director对象,并把MacBookBuilder传递给它。 -
调用
Director的construct()方法,传入主板和显示器的参数,从而完成电脑的构建。 -
最后通过
build()方法获取构建好的电脑,并展示其参数。
6.2.6代理模式
代理模式指代理控制对其他对象的访问, 也就是代理对象控制对原对象的引⽤。在某些情况下,⼀个对象不适合或者不能直接被引⽤访问,⽽代理对象可以在客⼾端和⽬标对象之间起到中介的作⽤。
代理模式的结构包括⼀个是真正的你要访问的对象(⽬标类)、⼀个是代理对象。⽬标对象与代理对象实现同⼀个接⼝,先访问代理类再通过代理类访问⽬标对象。代理模式分为静态代理、动态代理:
-
静态代理指的是,在编译时就已经确定好了代理类和被代理类的关系。也就是说,在编译时就已经确定了代理类要代理的是哪个被代理类。
-
动态代理指的是,在运⾏时才动态⽣成代理类,并将其与被代理类绑定。这意味着,在运⾏时才能确定代理类要代理的是哪个被代理类。
以租房为例,房东将房⼦租出去,但是要租房⼦出去,需要发布招租启⽰, 带⼈看房,负责维修,这些⼯作中有些操作并⾮房东能完成,因此房东为了图省事,将房⼦委托给中介进⾏租赁。 代理模式实现:
/*房东要将房子通过中介租出去,理解代理模式*/#include <iostream>#include<string>using namespace std;class RentHouse{public:virtual void rentHouse()=0;};//房东类class Landlord : public RentHouse{public:void rentHouse() override{cout << "房东正在出租房子\n" << endl;}};//中介class Intermediary : public RentHouse{public:void rentHouse(){cout<<"发布招租启示\n";cout<<"带人看房\n";_lanlord.rentHouse();//房东将房子租出去cout<<"负责租后维修\n";}private:Landlord _lanlord;//定义一个房东对象};int main(){//直接通过中介进行租房操作Intermediary intermediary;intermediary.rentHouse();return 0;}
不直接针对房东进行租房子,而是直接针对中介进行租房子的
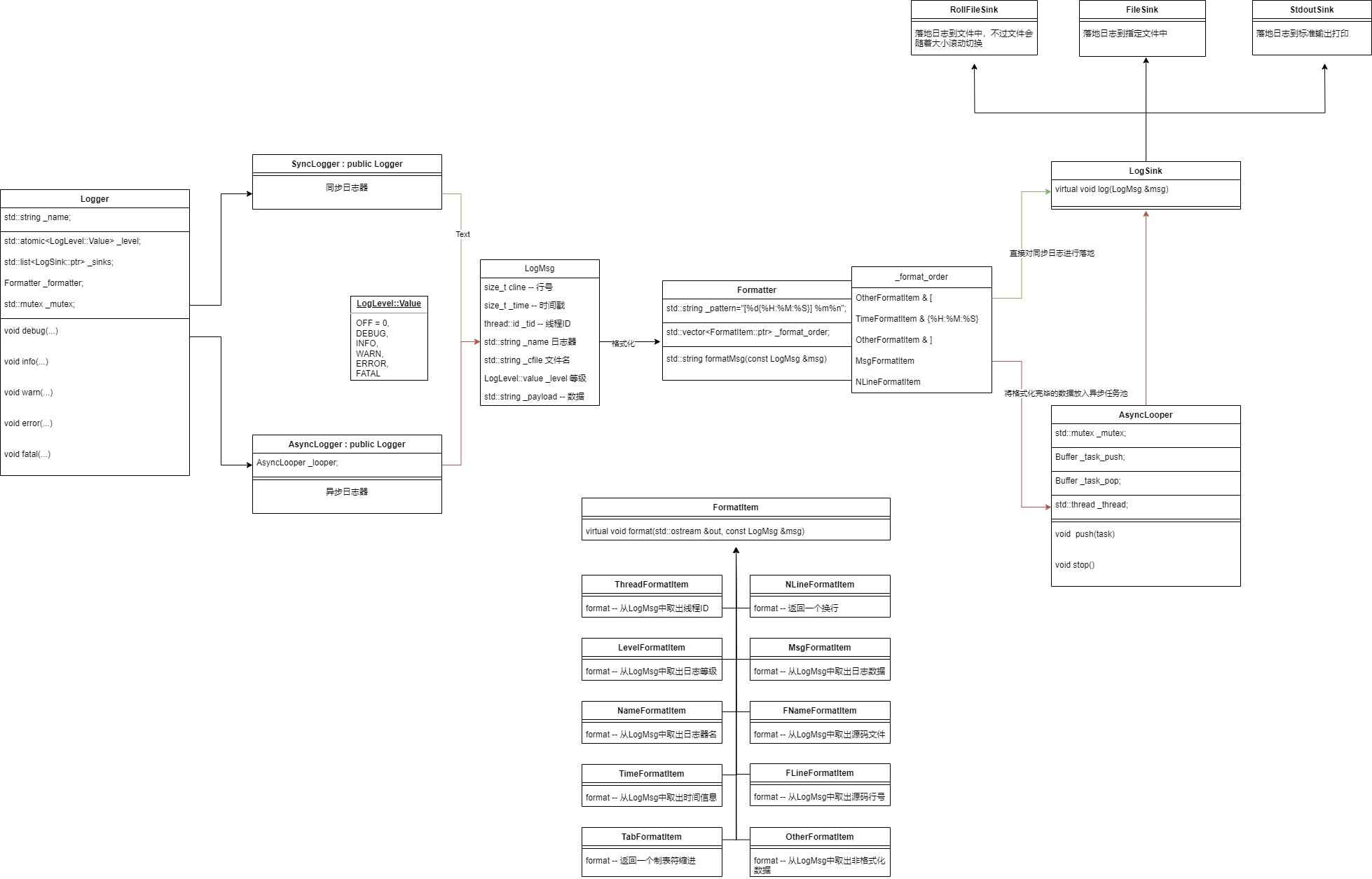
7.日志系统框架设计
本项⽬实现的是⼀个多⽇志器⽇志系统,主要实现的功能是让程序员能够轻松的将程序运⾏⽇志信息落地到指定的位置,且⽀持同步与异步两种⽅式的⽇志落地⽅式。
日志系统:将一条消息,进行格式化成为指定格式的字符串后,写入到指定位置
1.日志要写入指定位置(标准输出,指定文件,滚动文件,。。。)
,日志系统需要支持将日志消息落地到不同的位置—多落地方向
2.日志写入指定位置,支持不同的写入方式(同步,异步)
同步:业务线程自己负责日志的写入(流程简单,但是可能会因为阻塞导致效率降低)
异步:业务线程将日志放入缓冲区内存,让其他异步线程负责将日志写入到指定位置(不会阻塞,效率高)
3.日志输出以日志器为单位,支持多日志器(让不同的项目组有不同的输出策略)
日志系统的管理
7.1模块划分
项⽬的框架设计将项⽬分为以下⼏个模块来实现。
日志等级模块—枚举出日志氛围多少个等级 ,对不同的日志有不同的等级标志—以便于控制输出,那些等级能输入,哪些等级不能输入,比如低于指定输出等级就不能进行输出操作
- OFF:关闭
- DEBUG:调试,调试时的关键信息输出。
- INFO:提⽰,普通的提⽰型⽇志信息。
- WARN:警告,不影响运⾏,但是需要注意⼀下的⽇志。
- ERROR:错误,程序运⾏出现错误的⽇志
- FATAL:致命,⼀般是代码异常导致程序⽆法继续推进运⾏的⽇志
日志消息模块:封装一条日志所需的各种要素(时间,线程ID,文件名,行号,日志等级,消息主体…)
- 时间:描述本条⽇志的输出时间。
- 线程ID:描述本条⽇志是哪个线程输出的。
- ⽇志等级:描述本条⽇志的等级。
- ⽇志数据:本条⽇志的有效载荷数据。
- ⽇志⽂件名:描述本条⽇志在哪个源码⽂件中输出的。
- ⽇志⾏号:描述本条⽇志在源码⽂件的哪⼀⾏输出的。
日志消息格式化模块:按照指定的格式,对于日志消息关键要素进行组织,最终得到一个指定格式的字符串
- 系统的默认⽇志输出格式:%d{%H:%M:%S}%T[%t]%T[%p]%T[%c]%T%f:%l%T%m%n
- -> 13:26:32 [2343223321] [FATAL] [root] main.c:76 套接字创建失败\n
- %d{%H:%M:%S}:表⽰⽇期时间,花括号中的内容表⽰⽇期时间的格式。
- %T:表⽰制表符缩进。
- %t:表⽰线程ID
- %p:表⽰⽇志级别
- %c:表⽰⽇志器名称,不同的开发组可以创建⾃⼰的⽇志器进⾏⽇志输出,⼩组之间互不影响。
- %f:表⽰⽇志输出时的源代码⽂件名。
- %l:表⽰⽇志输出时的源代码⾏号。
- %m:表⽰给与的⽇志有效载荷数据
- %n:表⽰换⾏
- 设计思想:设计不同的⼦类,不同的⼦类从⽇志消息中取出不同的数据进⾏处理。
日志落地模块:负责对日志消息进行指定方向的写入输出
- 标准输出:表⽰将⽇志进⾏标准输出的打印。
- ⽇志⽂件输出:表⽰将⽇志写⼊指定的⽂件末尾。
- 滚动⽂件输出:当前以⽂件⼤⼩进⾏控制,当⼀个⽇志⽂件⼤⼩达到指定⼤⼩,则切换下⼀个⽂件进⾏输出
- 后期,也可以扩展远程⽇志输出,创建客⼾端,将⽇志消息发送给远程的⽇志分析服务器。
- 设计思想:设计不同的⼦类,不同的⼦类控制不同的⽇志落地⽅向。
日志器模块:对上面几个模块的整合
日志限制输出等级,消息格式化模块对象,日志落地模块对象
同步日志器模块—完成日志的同步输出功能
异步日志器模块—完成日志的异步输出功能
异步线程模块:负责异步日志的实际落地输出功能
实现对⽇志的异步输出功能,⽤⼾只需要将输出⽇志任务放⼊任务池,异步线程负责⽇志的落地输出功能,以此提供更加⾼效的⾮阻塞⽇志输出。
单例的日志器管理模块:对全局进行全局的管理,以便于能够在项目的任何位置获取指定的日志器进行日志输出
8.代码设计
8.1实用类设计
提前完成⼀些零碎的功能接⼝,以便于项⽬中会⽤到。
- 获取系统时间
- 判断⽂件是否存在
- 获取⽂件的所在⽬录路径
- 创建⽬录(如果指定存放日志的文件目录不存在的话,那么我们就得进行目录的创建了)
8.1.1构建简单框架
我们先简单的构建了下框架
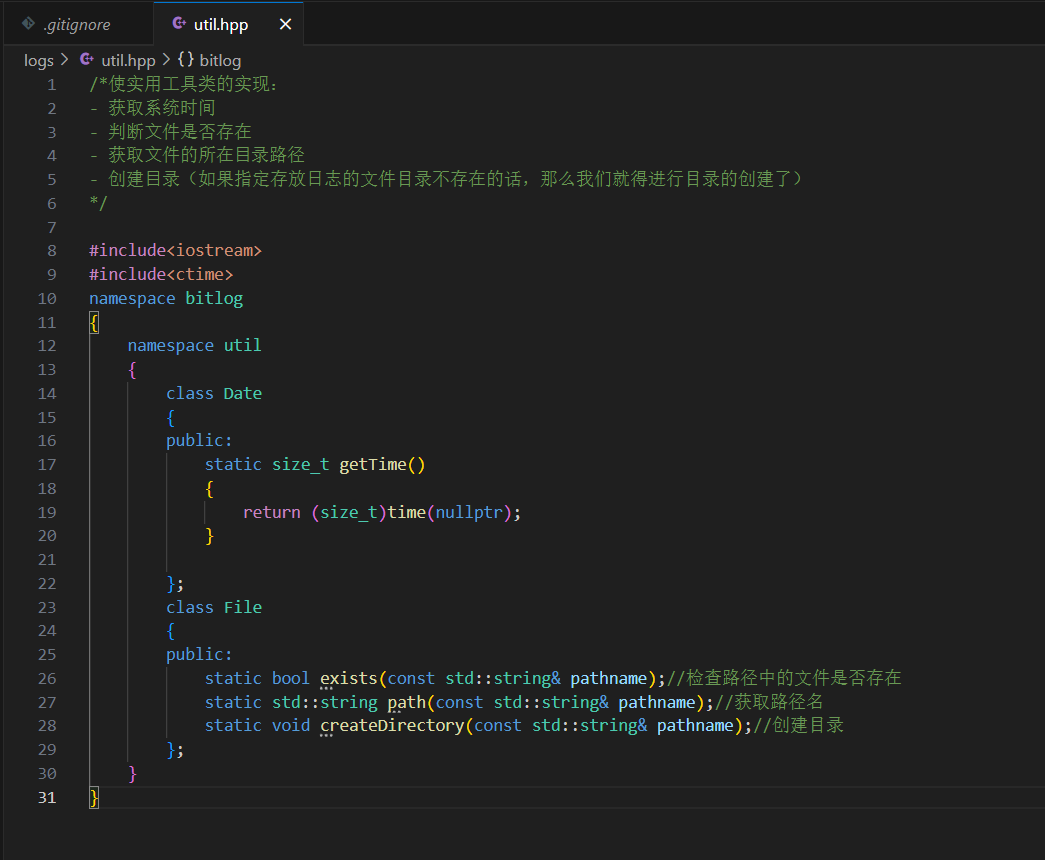
/*使实用工具类的实现:- 获取系统时间- 判断⽂件是否存在- 获取⽂件的所在⽬录路径- 创建⽬录(如果指定存放日志的文件目录不存在的话,那么我们就得进行目录的创建了)*/#include<iostream>#include<ctime>namespace kaizi{namespace util{class Date{public:static size_t now(){return (size_t)time(nullptr);}};class File{public:static bool exists(const std::string& pathname);//检查路径中的文件是否存在static std::string path(const std::string& pathname);//获取路径名static void createDirectory(const std::string& pathname);//创建目录};}}
8.1.1.1判断文件是否存在(stat)
接下来我们开始进行代码编写,我们先开始进行判断文件是否存在
如何判断系统中我们给到的文件是否存在呢?系统中给到了一个函数接口access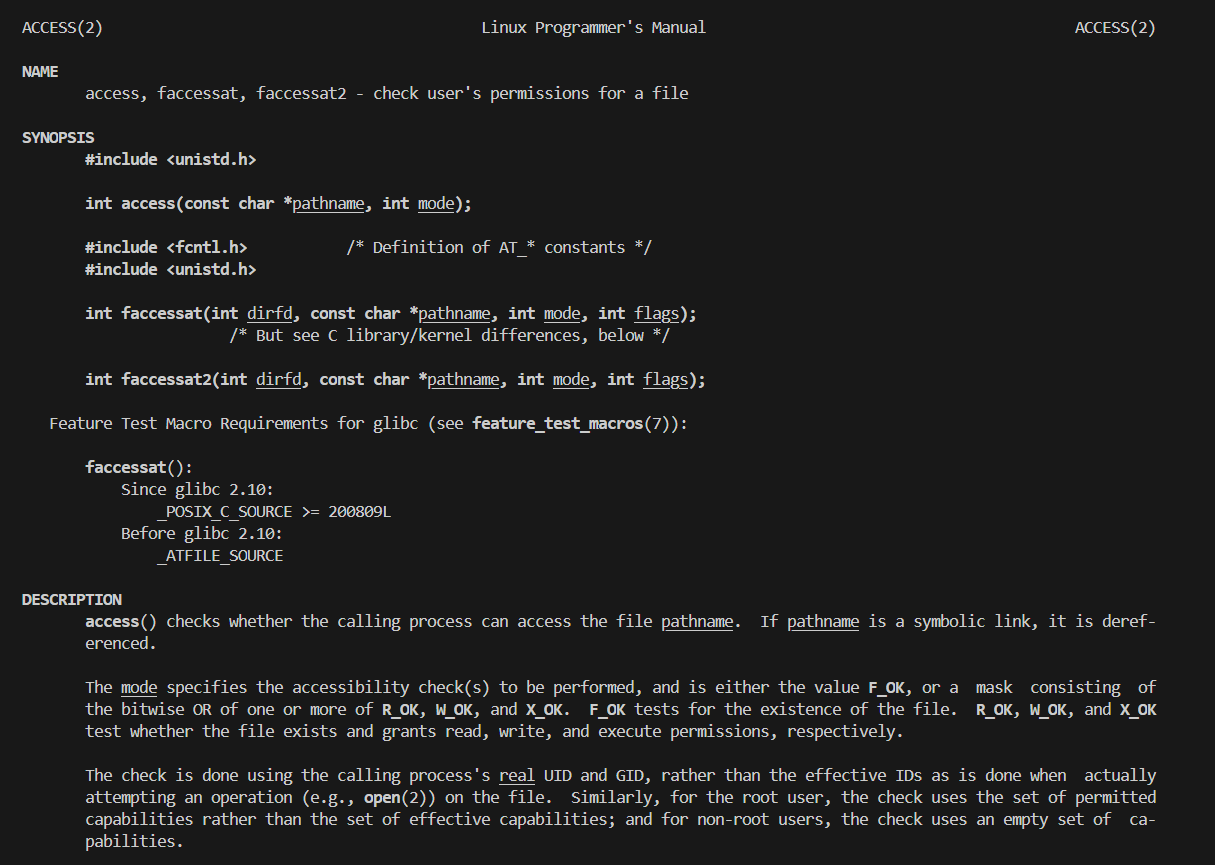
第一个参数的话就是一个路径名,第二参数就是我们使用这个接口进行的操作
操作中有一个选项叫做F_OK测试下这个文件是否存在
如果文件存在的话就是返回的是一个0,如果文件错误或者是不存在的话那么就是返回的是-1了
 但是我们的这个
但是我们的这个access这个系统调用接口只能在Linux平台上生效
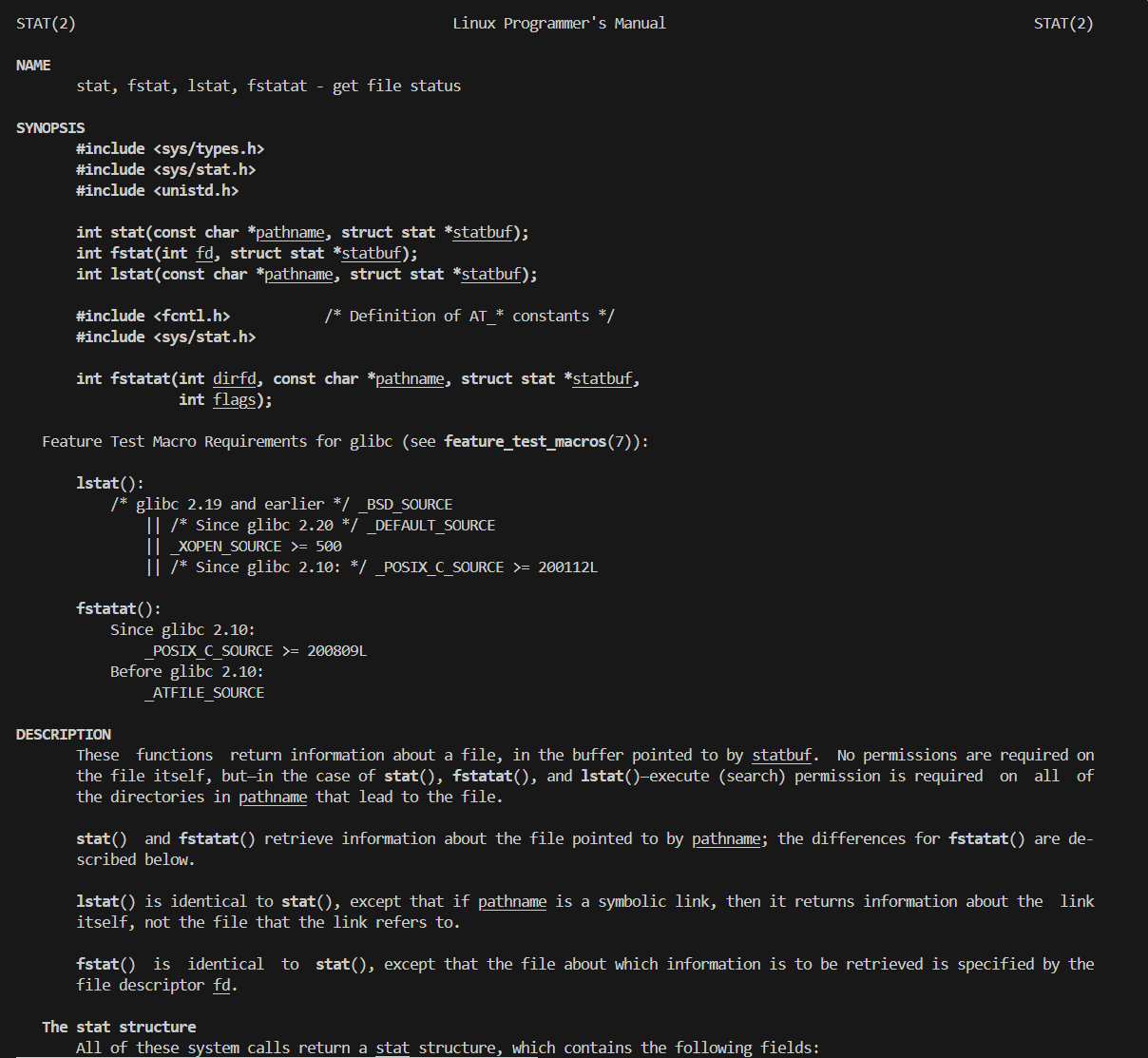
我们这里有一些通用的接口,跨平台性比较强
比如说fstat 获取文件属性状态,如果成功获取了文件属性的话,那么就说明这个文件是存在的
代码如下:
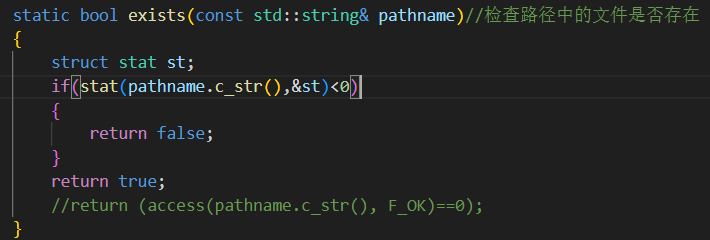
static bool exists(const std::string& pathname)//检查路径中的文件是否存在{struct stat st;if(stat(pathname.c_str(),&st)<0){return false;}return true;//return (access(pathname.c_str(), F_OK)==0);}
在代码中,通过调用 stat(pathname.c_str(), &st),将 pathname 所指定路径的文件或目录的信息填充到 st 结构体中,然后根据 stat 函数的返回值来判断操作是否成功,进而确定文件或目录是否存在。
8.1.1.2获取文件所在路径(查找pathname中最后一个/)
./abc/def.txt 这里我们只需要从一开始获取到def前面的/那里就行了,我们直接查找最后一个/
利用find_last_of查找指定的字符,查找到我们的pathname中最后一个/就行了


static std::string path(const std::string& pathname)//获取路径名{// ./abc/def.txt 这里我们只需要从一开始获取到def前面的/那里就行了,我们直接查找最后一个/size_t pos=pathname.find_last_of("/");// '/\\' 是为了适配不同操作系统的路径分隔符if(pos==std::string::npos)return ".";//说明没找到,我们直接返回一个点return pathname.substr(0,pos+1);//加上1是为了包含'/'在内的整个路径名,利用substr进行长度的截取操作}
8.1.1.3创建目录
./abc/bcd/a.txt 目录得一层一层的进行创建,要创建a.txt的话就得存在bcd,要创建bcd的话就得存在abc了
创建目录我们使用到了mkdir了
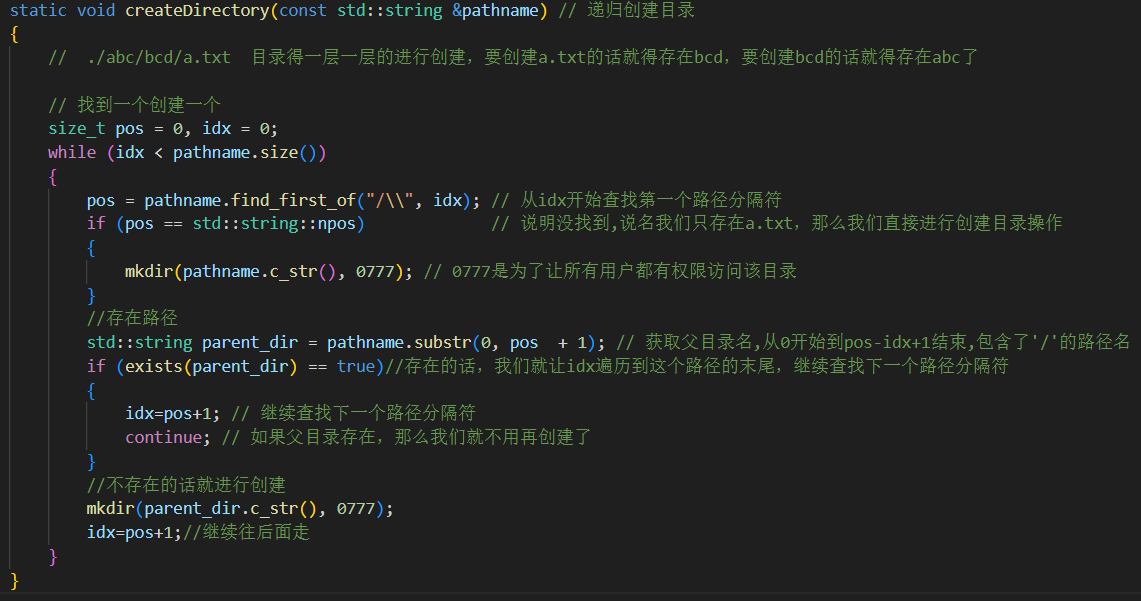
static void createDirectory(const std::string &pathname) // 递归创建目录{// ./abc/bcd/a.txt 目录得一层一层的进行创建,要创建a.txt的话就得存在bcd,要创建bcd的话就得存在abc了// 找到一个创建一个size_t pos = 0, idx = 0;while (idx < pathname.size()){pos = pathname.find_first_of("/\\", idx); // 从idx开始查找第一个路径分隔符if (pos == std::string::npos) // 说明没找到,说名我们只存在a.txt,那么我们直接进行创建目录操作{mkdir(pathname.c_str(), 0777); // 0777是为了让所有用户都有权限访问该目录}//存在路径std::string parent_dir = pathname.substr(0, pos + 1); // 获取父目录名,从0开始到pos-idx+1结束,包含了'/'的路径名if (exists(parent_dir) == true)//存在的话,我们就让idx遍历到这个路径的末尾,继续查找下一个路径分隔符{idx=pos+1; // 继续查找下一个路径分隔符continue; // 如果父目录存在,那么我们就不用再创建了}//不存在的话就进行创建mkdir(parent_dir.c_str(), 0777);idx=pos+1;//继续往后面走}}
核心逻辑是从路径中按分隔符拆分出各级父目录,逐级检查并创建不存在的目录,类似 mkdir -p 命令
- 输入路径(如
./abc/bcd/a.txt)。 - 循环拆分路径,每次找分隔符
/或\。 - 截取当前父目录片段(如
./→./abc/→./abc/bcd/)。 - 检查目录是否已存在,不存在则用
mkdir创建。 - 路径处理完后,创建 “最终路径”(但需注意是否是文件路径的问题 )。
8.1.1.4该框架整体代码
/*使实用工具类的实现:- 获取系统时间- 判断⽂件是否存在- 获取⽂件的所在⽬录路径- 创建⽬录(如果指定存放日志的文件目录不存在的话,那么我们就得进行目录的创建了)*/#include <iostream>#include <ctime>#include <sys/stat.h>namespace bitlog{namespace util{class Date{public:static size_t getTime(){return (size_t)time(nullptr);}};class File{public:static bool exists(const std::string &pathname) // 检查路径中的文件是否存在{struct stat st;if (stat(pathname.c_str(), &st) < 0){return false;}return true;// return (access(pathname.c_str(), F_OK)==0);}static std::string path(const std::string &pathname) // 获取路径名{// ./abc/def.txt 这里我们只需要从一开始获取到def前面的/那里就行了,我们直接查找最后一个/size_t pos = pathname.find_last_of("/\\"); // '/\\' 是为了适配不同操作系统的路径分隔符if (pos == std::string::npos)return "."; // 说明没找到,我们直接返回一个点return pathname.substr(0, pos + 1); // 加上1是为了包含'/'在内的整个路径名,利用substr进行长度的截取操作}static void createDirectory(const std::string &pathname) // 递归创建目录{// ./abc/bcd/a.txt 目录得一层一层的进行创建,要创建a.txt的话就得存在bcd,要创建bcd的话就得存在abc了// 找到一个创建一个size_t pos = 0, idx = 0;while (idx < pathname.size()){pos = pathname.find_first_of("/\\", idx); // 从idx开始查找第一个路径分隔符if (pos == std::string::npos) // 说明没找到,说名我们只存在a.txt,那么我们直接进行创建目录操作{mkdir(pathname.c_str(), 0777); // 0777是为了让所有用户都有权限访问该目录}//存在路径std::string parent_dir = pathname.substr(0, pos + 1); // 获取父目录名,从0开始到pos-idx+1结束,包含了'/'的路径名if (exists(parent_dir) == true)//存在的话,我们就让idx遍历到这个路径的末尾,继续查找下一个路径分隔符{idx=pos+1; // 继续查找下一个路径分隔符continue; // 如果父目录存在,那么我们就不用再创建了}//不存在的话就进行创建mkdir(parent_dir.c_str(), 0777);idx=pos+1;//继续往后面走}}};}}
8.1.2单元测试
这里我们写了一个Makefile文件
test::test.cc util.hppg++ -std=c++11 $^ -o $@
一个test.cc
#include"util.hpp"int main(){std::cout<<kaizi::util::Date::now()<<std::endl;std::string pathname="./abc/bcd/a.txt";//获取文件所在路径并且进行目录的创建kaizi::util::File::createDirectory(kaizi::util::File::path(pathname));return 0;}
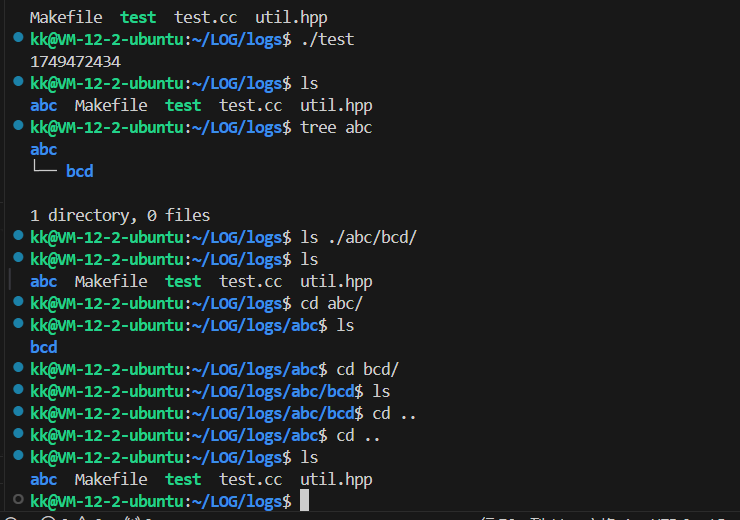
可以看见我们能创建目录
8.2日志等级模块
⽇志等级总共分为7个等级,分别为:
- DRBUG 进⾏debug时候打印⽇志的等级
- INFO 打印⼀些⽤⼾提⽰信息
- WARN 打印警告信息
- ERROR 打印错误信息
- FATAL 打印致命信息- 导致程序崩溃的信息
- OFF 关闭所有⽇志输出
每一个项目中都会设置一个默认的日志输出等级,只有输出的日志等级大于默认限制等级的时候才可以进行输出
这里的等级中OFF是最高等级的,所以当我们此时的等级是OFF的时候,所有的日志都不能进行输出操作
提供一个接口,将对应等级的枚举,转换为一个对应的字符串
/*1.定义枚举类,枚举出日志等级2,提供转换接口:将枚举转换为对应字符串*/#ifndef __M_LEVEL_H__#define __M_LEVEL_H__namespace kaizi{class LogLevel{public:enum class value{UNKONW=0,DEBUG,INFO,WARN,ERROR,FATAL,OFF};static const char*toString(LogLevel::value level)//传入一个具体日志等级的值,根据level进行转换{switch(level){case LogLevel::value::DEBUG:return "DEBUG";case LogLevel::value::INFO:return "INFO";case LogLevel::value::WARN:return "WARN";case LogLevel::value::ERROR:return "ERROR";case LogLevel::value::FATAL:return "FATAL";case LogLevel::value::OFF:return "OFF";}//如果里面都不是的话,那么直接返回一个UNKONW就行了return "UNKONW";}};}#endif
测试结果如下:
test.hpp
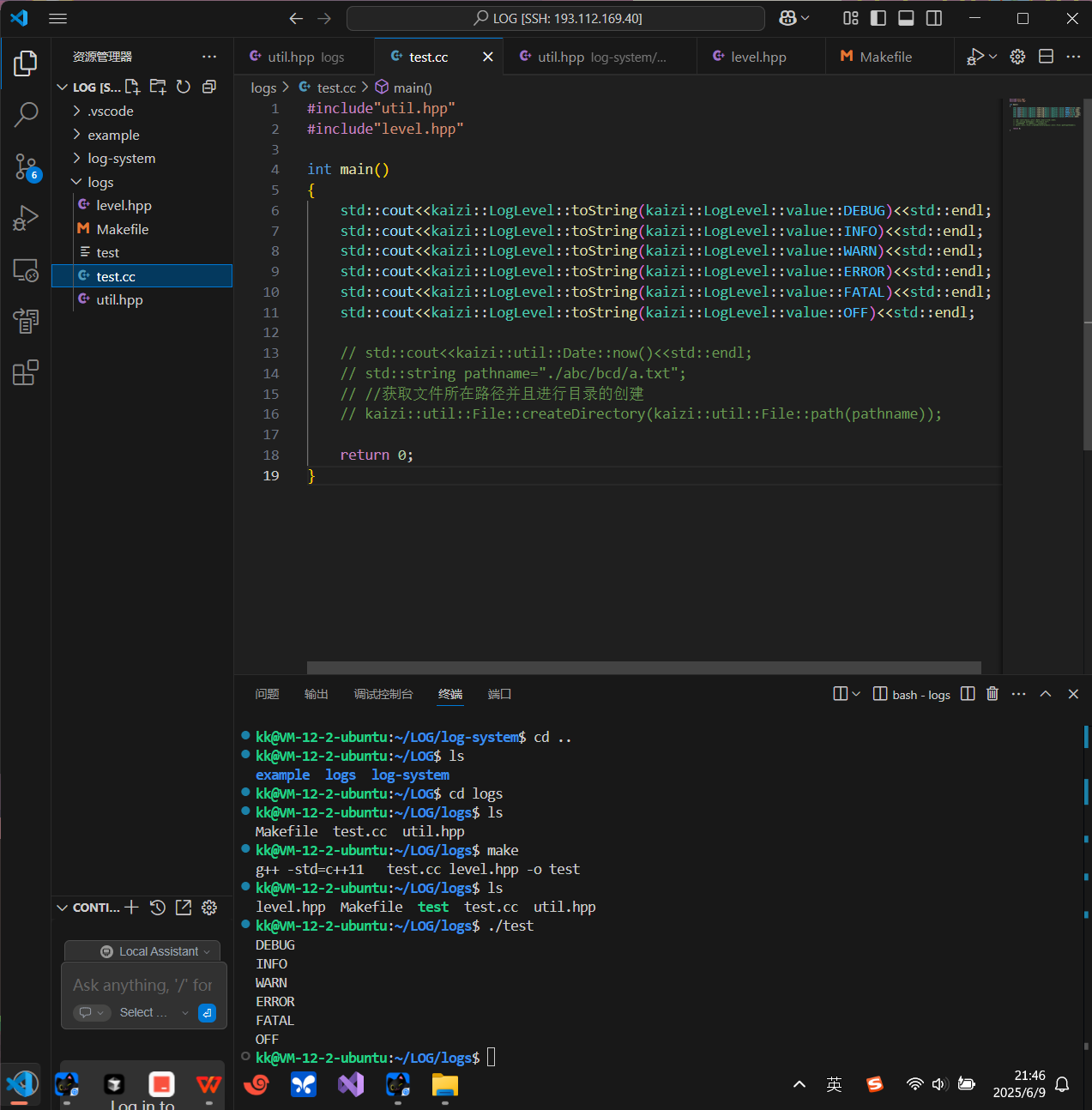
#include"util.hpp"#include"level.hpp"int main(){std::cout<<kaizi::LogLevel::toString(kaizi::LogLevel::value::DEBUG)<<std::endl;std::cout<<kaizi::LogLevel::toString(kaizi::LogLevel::value::INFO)<<std::endl;std::cout<<kaizi::LogLevel::toString(kaizi::LogLevel::value::WARN)<<std::endl;std::cout<<kaizi::LogLevel::toString(kaizi::LogLevel::value::ERROR)<<std::endl;std::cout<<kaizi::LogLevel::toString(kaizi::LogLevel::value::FATAL)<<std::endl;std::cout<<kaizi::LogLevel::toString(kaizi::LogLevel::value::OFF)<<std::endl;return 0;}
8.3日志消息类的构建
意义:中间存储一条日志消息所需的各项要素
1.日志输出时间 —用于过滤日志输出的时间
2.日志等级 —用于进行日志过滤分析
3.源文件名称
4.源代码行号 —用于定位出现错误的代码位置
5.线程ID —用于过滤程序出错的线程
6.日志主体消息
7.日志器名称(当前支持多日志器的同时使用)
我们这里直接定义一个结构体,在结构体中进行构造操作
/*定义日志消息类,进行日志中间信息的存储1.日志输出时间 ---用于过滤日志输出的时间2.日志等级 ---用于进行日志过滤分析3.源文件名称4.源代码行号 ---用于定位出现错误的代码位置5.线程ID ---用于过滤程序出错的线程6.日志主体消息7.日志器名称(当前支持多日志器的同时使用)*/#ifndef __M_MESSAGE_H__#define __M_MESSAGE_H__#include <iostream>#include <thread>#include <string>#include "level.hpp"#include "util.hpp"namespace kaizi{struct LogMsg // 定义一个结构体,默认就是公有的{time_t _ctime; // 日志的时间戳LogLevel::value _level; // 日志等级size_t _line; // 源代码行号std::thread::id _tid; // 线程IDstd::string _file; // 源文件名称std::string _logger; // 日志器名称std::string _payload; // 日志主体消息---有效载荷数据LogMsg(LogLevel::value level,size_t line,const std::string file,const std::string logger,const std::string msg): _ctime(util::Date::now()),_level(level),_line(line),_tid(std::this_thread::get_id()),_file(file),_logger(logger),_payload(msg){}};}#endif
里面的_ctime初始化使用的就是我们之前在应用类中设计的时间戳获取函数now()
8.4日志输出格式化类设计
作用:对日志消息进行格式化操作,组织成为指定格式的字符串
我们需要定义一个pattern成员:保存日志输出的格式字符串
- %d ⽇期
- %T 缩进
- %t 线程id
- %p ⽇志级别
- %c ⽇志器名称
- %f ⽂件名
- %l ⾏号
- %m ⽇志消息
- %n 换⾏
格式化字符串控制了日志的输出格式
定义格式化字符,是为了让日志系统进行格式化更加的灵活方便
成员:
1、格式化字符串
2、格式化子项数组:对格式化字符串进行解析,保存了日志消息要素的排序
不同的格式化子项,会从日志消息中取出指定的元素,转换为字符串

- std::vectorFormatItem::ptr items成员:⽤于按序保存格式化字符串对应的⼦格式化对象。
FormatItem类主要负责⽇志消息⼦项的获取及格式化。其包含以下⼦类 - MsgFormatItem :表⽰要从LogMsg中取出有效⽇志数据
- LevelFormatItem :表⽰要从LogMsg中取出⽇志等级
- NameFormatItem :表⽰要从LogMsg中取出⽇志器名称
- ThreadFormatItem :表⽰要从LogMsg中取出线程ID
- TimeFormatItem :表⽰要从LogMsg中取出时间戳并按照指定格式进⾏格式化
- CFileFormatItem :表⽰要从LogMsg中取出源码所在⽂件名
- CLineFormatItem :表⽰要从LogMsg中取出源码所在⾏号
- TabFormatItem :表⽰⼀个制表符缩进
- NLineFormatItem :表⽰⼀个换⾏
- OtherFormatItem :表⽰⾮格式化的原始字符串
⽰例:“[%d{%H:%M:%S}] %m%n”
需要完成的:格式化子项类的定义与实现
格式化子项的实现思想:
作用:从日志消息中取出指定的元素,追加到一块内存空间中
父类指针指向子类对象,来调用子类对象的成员函数
设计思想:
1.抽象一个格式化子项基类
2.基于基类,派生出不同的格式化项子类
主体消息,日志等级,时间子项,文件名,行号, 日志器名称,现成ID,制表符,缩进,换行,其他
3.这样就可以在父类中定义父类指针的数组,指向不同的格式化子项子类对象的
8.4.1格式化子项类的设计与实现
通过下面的代码我们实现了格式化子类
通过多态设计让日志能以不同格式输出
- 消息内容:
MsgFormatItem输出日志的核心内容msg._payload。 - 日志等级:
LevelFormatItem把日志等级从枚举值转为可读字符串(像DEBUG、INFO等)。 - 时间戳:
TimeFormatItem按照指定格式(例如%H:%M:%S)格式化时间。 - 文件与行号:
FileFormatItem和LineFormatItem分别输出日志所在的文件名和行号。 - 线程信息:
ThreadFormatItem输出日志产生的线程 ID。 - 日志器名称:
LoggerFormatItem输出当前使用的日志器名称。 - 分隔符:
TabFormatItem和NLineFormatItem分别输出制表符\t和换行符\n,用于日志排版。 - 自定义内容:
OtherFormatItem输出任意自定义字符串(比如前缀、后缀)。
#ifndef __M_FMT_H__#define __M_FMT_H__#include "level.hpp"#include "message.hpp"#include <memory>#include <ctime>//格式化子项类namespace kaizi{// 1、抽象格式化子项基类class FormatItem{public:using ptr = std::shared_ptr<FormatItem>; // 对FormatItem进行智能管理virtual void format(std::ostream &out, LogMsg &msg) = 0; // 纯虚函数};// 2、派生格式化子项子类---消息、等级、时间、文件名、行号、线程ID、日志器名称、制表符、换行、其他class MsgFormatItem : public FormatItem // 消息主体{public:void format(std::ostream &out, LogMsg &msg) override{out << msg._payload;}};class levelFormatItem : public FormatItem // 日志等级{public:void format(std::ostream &out, LogMsg &msg) override{out << LogLevel::toString(msg._level); // 利用之前写的日志等级代码进行日志等级的转换然后将转换后的结果输出进去}};class TimeFormatItem : public FormatItem // 格式化日志中的时间{public:TimeFormatItem(const std::string &fmt = "%H:%M:%S") // 构造函数,把传入的格式化字符串赋值给私有成员变量 _time_fmt: _time_fmt(fmt){}void format(std::ostream &out, LogMsg &msg) override{// tm 是 C/C++ 标准库的时间结构体// 先定义一个 tm 结构体变量 t ,tm 结构体用于存储分解后的时间信息struct tm t;// 把 msg._ctime 里的时间戳转换成本地时间,并填充到 tm 结构体 t 中。localtime_r(&msg._ctime, &t);// 定义一个字符数组 tmp,用来存储最终格式化的时间字符串char tmp[32] = {0};// strftime 是时间格式化核心函数,按规则把 tm 结构体的时间转成字符串strftime(tmp, 31, _time_fmt.c_str(), &t);// 把格式化好的时间字符串(存在 tmp),输出到日志流 ouout << tmp; // 输出日志的时间}private:std::string _time_fmt; //%H:%M:%S};class FileFormatItem : public FormatItem // 文件名{public:void format(std::ostream &out, LogMsg &msg) override{out << msg._file; // 直接取出文件名添加进去就行了}};class LineFormatItem : public FormatItem // 行号{public:void format(std::ostream &out, LogMsg &msg) override{out << msg._line; // 直接取出一个数字就行了}};class ThreadFormatItem : public FormatItem // 线程ID{public:void format(std::ostream &out, LogMsg &msg) override{out << msg._tid; // 直接取出线程ID就行了}};class LoggerFormatItem : public FormatItem // 日志器名称{public:void format(std::ostream &out, LogMsg &msg) override{out << msg._logger; // 直接取出日志器名称就行了}};class TabFormatItem : public FormatItem // 制表符{public:void format(std::ostream &out, LogMsg &msg) override{out << "\t";}};class NLineFormatItem : public FormatItem // 换行{public:void format(std::ostream &out, LogMsg &msg) override{out << "\n";}};// abcdefg[%d{%H}] 这里的话abcdefg[就属于其他字符串了class OtherFormatItem : public FormatItem // 其他{public:OtherFormatItem(const std::string &str) // 构造函数,把传入的字符串赋值给私有成员变量 _str: _str(str){}void format(std::ostream &out, LogMsg &msg) override{out << _str;}private:std::string _str; // 原始字符串};}#endif
8.4.2格式化类的定义
/*%d表示日期,包含子格式{%H:%M:%S}%t表示线程ID%c表示日志器名称%f表示文件名%l表示行号%p表示日志级别%T是制表符缩进%m表示消息主体%n表示换行符*/class Formatter{public:Formatter(const std::string &pattren = "[%d{%H:%M:%S}][%t][%c][%f:%l][%p]%T%m%n"): _pattern(pattren){}//下面两行代码是对msg进行格式化void format(std::ostream &out, LogMsg &msg);//format重载,将消息放到io流中,我们对IO流进行处理操作std::string format(LogMsg &msg); // 对这条消息进行格式化操作,返回格式化后的字符串//对格式化规则字符串进行解析bool parsePattern(); // 解析格式化规则字符串,将其解析成格式化子项数组private://根据不同的格式化字符创建不同的格式化子项对象FormatItem::ptr createItem(const std::string &key,const std::string &value); // 根据格式化子项的类型字符串,创建对应的格式化子项对象,并返回智能指针private:std::string _pattern; // 格式化规则字符串std::vector<FormatItem::ptr> _items; // 这个容器中的类型是智能指针 ,存储的是格式化子项的智能指针/*对这个子项数组按顺序的从我们的消息中取出对应的内容逐个遍历_items,从消息中取出内容进行一个format。得到一个数据就放到ostream中*/};
Formatter 类负责:
-
解析格式模式:将用户提供的格式字符串(如
[%d{%H:%M:%S}][%t][%c]...)解析为一系列FormatItem对象。 -
格式化日志消息:根据解析结果,将
LogMsg对象中的各字段(时间、线程 ID、日志级别等)按指定格式输出。 -
_pattern:用户传入的格式模板,使用特殊占位符(如%d、%p)表示不同日志字段。 -
_items:解析后的格式化子项列表,每个子项对应一个FormatItem派生类的实例(如TimeFormatItem、LevelFormatItem)
**parsePattern()**将_pattern解析为_items列表。 -
遍历
_pattern,识别特殊占位符(如%d、%p)和普通文本。 -
对每个占位符:
- 提取类型(如
%d表示日期)和参数(如{%H:%M:%S})。 - 调用
createItem()创建对应的FormatItem对象。
- 提取类型(如
-
对普通文本:创建
OtherFormatItem对象存储。
createItem()根据占位符类型(key)和参数(value)创建对应的 FormatItem。
Formatter 类通过策略模式和解析器模式,实现了日志格式的灵活配置和高效输出。它将格式字符串解析为多个独立的格式化器,然后按顺序组合输出,使日志格式可配置且易于扩展。
8.4.3日志格式化类的实现-1
补充好之前类中的简单接口
//将用户提供的格式字符串(如 [%d{%H:%M:%S}][%t][%c]...)解析为一系列 FormatItem 对象。class Formatter{public:Formatter(const std::string &pattren = "[%d{%H:%M:%S}][%t][%c][%f:%l][%p]%T%m%n"): _pattern(pattren){assert(parsePattern());//断言格式化必须成功}//下面两行代码是对msg进行格式化void format(std::ostream &out, LogMsg &msg)//format重载,将消息放到io流中,我们对IO流进行处理操作{//逐个遍历_items,从消息中取出内容进行一个format。得到一个数据就放到ostream中for(auto &item:_items)//遍历 _items 容器,_items 里存的是各种 FormatItem 子类的智能指针{//调用每个 FormatItem 子类重写的 format 方法,把 msg 里的对应数据//按照该子类的规则格式化后,输出到 out 流里item->format(out,msg);//这个format是基类的虚函数,我们在派生类中实现,这里我们直接调用基类的实现}}std::string format(LogMsg &msg) // 对这条消息进行格式化操作,返回格式化后的字符串{//创建一个 stringstream,它是内存中的流,用来临时存储格式化后的日志内容。std::stringstream ss;format(ss,msg);//调用上面的接口,将日志内容格式化后输出到ss这个内存流中return ss.str(); // 返回格式化后的字符串}//对格式化规则字符串进行解析bool parsePattern() // 解析格式化规则字符串,将其解析成格式化子项数组{return ;}private://根据不同的格式化字符创建不同的格式化子项对象FormatItem::ptr createItem(const std::string &key,const std::string &val) // 根据格式化子项的类型字符串,创建对应的格式化子项对象,并返回智能指针{/*%d表示日期,包含子格式{%H:%M:%S}%t表示线程ID%c表示日志器名称%f表示文件名%l表示行号%p表示日志级别%T是制表符缩进%m表示消息主体%n表示换行符*/if(key == "d") return std::make_shared<TimeFormatItem>(val);// 如果是日期格式化子项if(key == "t") return std::make_shared<ThreadFormatItem>();// 如果是线程ID格式化子项if(key == "c") return std::make_shared<LoggerFormatItem>();// 如果是日志器名称格式化子项if(key == "f") return std::make_shared<FileFormatItem>();// 如果是文件名格式化子项if(key == "l") return std::make_shared<LineFormatItem>();// 如果是行号格式化子项if(key == "p") return std::make_shared<levelFormatItem>();// 如果是日志级别格式化子项if(key == "T") return std::make_shared<TabFormatItem>();// 如果是制表符格式化子项if(key == "m") return std::make_shared<MsgFormatItem>();// 如果是消息主体格式化子项if(key == "n") return std::make_shared<NLineFormatItem>();// 如果是换行符格式化子项return std::make_shared<OtherFormatItem>(val);// 如果是其他格式化子项}private:std::string _pattern; // 格式化规则字符串std::vector<FormatItem::ptr> _items; // 这个容器中的类型是智能指针 ,存储的是格式化子项的智能指针/*对这个子项数组按顺序的从我们的消息中取出对应的内容逐个遍历_items,从消息中取出内容进行一个format。得到一个数据就放到ostream中*/};
8.4.4日志格式化字符串解析思想

abcde[%d{%H:%M:%S}][%p]%T%m%n
如果我们在遍历的时候遇到了%的话,说明这个%往后的是格式化字符了
没有以%起始的字符串都是原始字符串,直到遇到了%就是遇到了原始字符串的结束位置
不是%,则一直向后走,直到遇到%,则是原始字符串的结束
如果遇到了%的话,看看紧随其后的这个字符是不是%,如果是的话,就是%字符,相当于转义
如果不是,则代表紧随其后的这个字符是格式化字符
紧随格式化字符之后的话,如果是{,则说明是子格式化字符,则继续往后解析子格式化字符
直到遇到},则代表子格式化字符的结束
规则字符串的处理过程是一个循环过程
在处理过程中,需要将处理得到的信息保存下来
到了数组后,根据数组内容创建对应的格式化子项对象,添加到items成员数组中

我们就根据上面的要求进行代码的编写
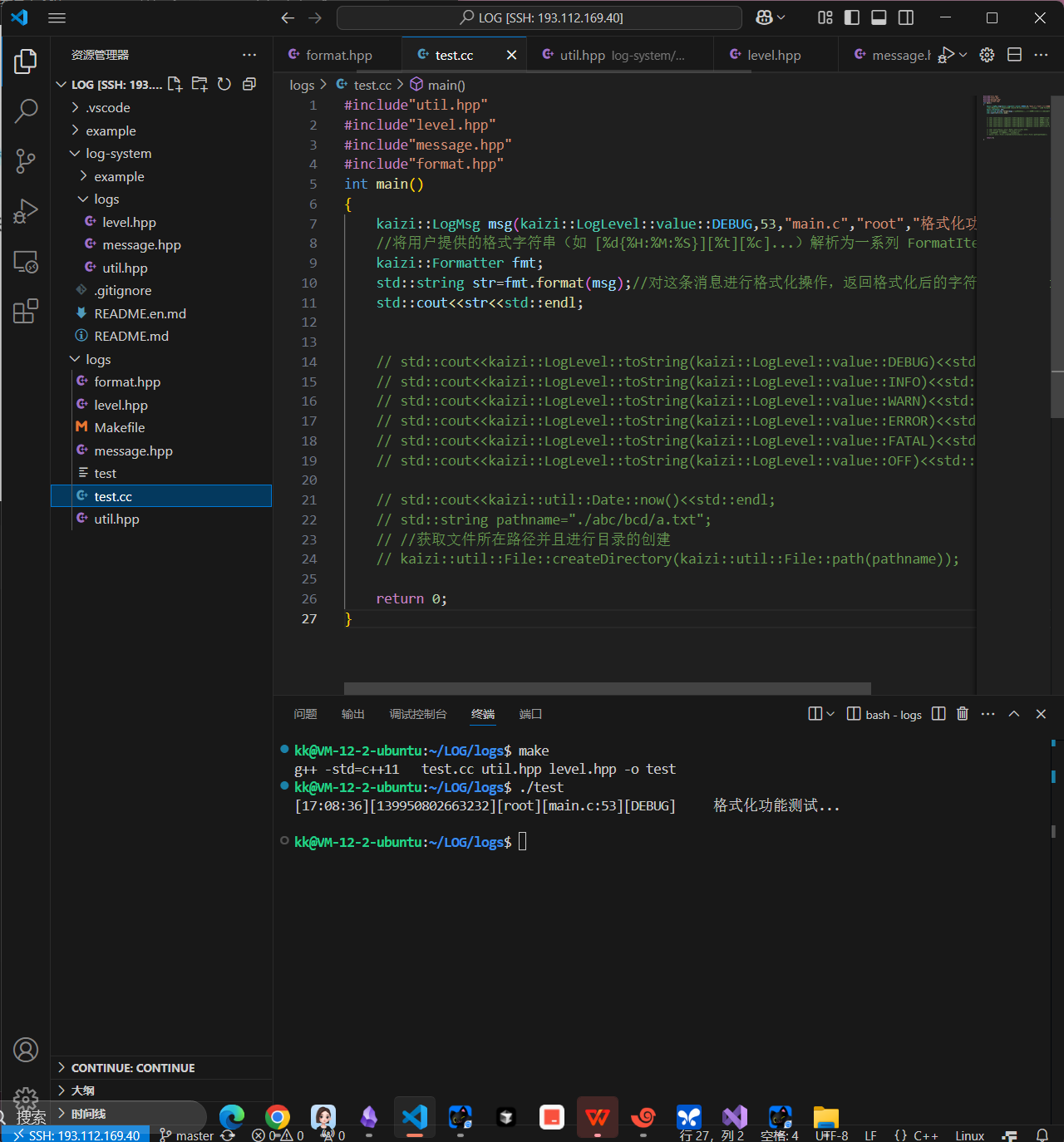
class Formatter{public:Formatter(const std::string &pattren = "[%d{%H:%M:%S}][%t][%c][%f:%l][%p]%T%m%n"): _pattern(pattren){assert(parsePattern());//断言格式化必须成功}//下面两行代码是对msg进行格式化void format(std::ostream &out, const LogMsg &msg)//format重载,将消息放到io流中,我们对IO流进行处理操作{//逐个遍历_items,从消息中取出内容进行一个format。得到一个数据就放到ostream中for(auto &item:_items)//遍历 _items 容器,_items 里存的是各种 FormatItem 子类的智能指针{//调用每个 FormatItem 子类重写的 format 方法,把 msg 里的对应数据//按照该子类的规则格式化后,输出到 out 流里item->format(out,msg);//这个format是基类的虚函数,我们在派生类中实现,这里我们直接调用基类的实现}}std::string format(const LogMsg &msg) // 对这条消息进行格式化操作,返回格式化后的字符串{//创建一个 stringstream,它是内存中的流,用来临时存储格式化后的日志内容。std::stringstream ss;format(ss,msg);//调用上面的接口,将日志内容格式化后输出到ss这个内存流中return ss.str(); // 返回格式化后的字符串}private://对格式化规则字符串进行解析bool parsePattern() // 解析格式化规则字符串,将其解析成格式化子项数组{//1.对格式化规则字符串进行解析std::vector<std::pair<std::string,std::string>> fmt_order; // 定义一个字符串数组,用来存储解析后的格式化子项size_t pos=0;std::string key,val;while(pos<_pattern.size()){//1. 处理原始字符串---判断是不是%,不是就是原始字符if(_pattern[pos]!='%'){// 不是%,直接输出原始字符val.push_back(_pattern[pos++]);//然后就是pos++继续往后面走了continue;}//能到这里说明pos位置就是%的,那么我们就得判断pos后面是不是%了,%%处理成为一个原始%字符if(pos+1<_pattern.size() && _pattern[pos+1]=='%')//说明是两个%{val.push_back('%');pos+=2;//往后面走两步,越过这两个%continue;}//这个时候代表我们原始字符串处理完毕if(val.empty()==false)//不为空的情况下{fmt_order.push_back(std::make_pair("",val)); // 加入到格式化子项数组中val.clear(); // 清空val}//这个时候是格式化字符的处理pos+=1;//往后面走一步,跳过%//走到了这里说明不是一个原始字符,说明后面是格式化字符了if(pos==_pattern.size())//如果pos已经到末尾了,说明格式化字符串格式不对{std::cout<<"%之后没有格式化字符"<<std::endl;return false;}key=_pattern[pos];//取出%pos+=1;//往后面走一步,跳过%//这个时候,pos指向格式化字符后的位置,//如果这个位置是{,说明后面还有子格式化字符串if(pos<_pattern.size()&&_pattern[pos]=='{'){pos+=1;//这个时候pos指向子格式化字符串的开始位置while(pos<_pattern.size()&&_pattern[pos]!='}'){val.push_back(_pattern[pos++]);}//走到了末尾跳出循环,没有遇到},说明格式化字符串格式不对if(pos==_pattern.size())//走到末尾了,都没找到},说明格式化字符串格式不对{std::cout<<"子规则花括号匹配错误"<<std::endl;return false;}pos+=1;//因为这个时候pos指向了},所以pos+1,跳过}//向后走一步,走到下次处理的新位置}fmt_order.push_back(std::make_pair(key,val)); // 加入到格式化子项数组中key.clear(); // 清空keyval.clear(); // 清空val//两个内容都进行清空操作,进行下一轮循环操作}//到这里我们就得到了处理结果了,我们就得进行解析了结果了//2.根据解析得到的数据初始化子项数组成员for(auto &it:fmt_order)//fmt_order是上面while循环的处理结果。我们进行遍历操作{//fmt_order是一个pair类型的,我们上面结束函数结束的时候是将(key,val)插入到里面了//我们这里遍历了fmt_order中的每一个pair类型进行子项对象的创建,并且插入到items数组中//并且我们在创建子项对象的时候,都返回了对应的数据了,然后将数据存储在items中,最后就是我们的日志了//往这个指针数组中加入对应的格式化子项对象_items.push_back(createItem(it.first,it.second)); // 根据格式化子项的类型字符串,创建对应的格式化子项对象,并加入到 _items 容器中}return true;}//根据不同的格式化字符创建不同的格式化子项对象FormatItem::ptr createItem(const std::string &key,const std::string &val) // 根据格式化子项的类型字符串,创建对应的格式化子项对象,并返回智能指针{/*%d表示日期,包含子格式{%H:%M:%S}%t表示线程ID%c表示日志器名称%f表示文件名%l表示行号%p表示日志级别%T是制表符缩进%m表示消息主体%n表示换行符*/if(key == "d") return std::make_shared<TimeFormatItem>(val);// 如果是日期格式化子项if(key == "t") return std::make_shared<ThreadFormatItem>();// 如果是线程ID格式化子项if(key == "c") return std::make_shared<LoggerFormatItem>();// 如果是日志器名称格式化子项if(key == "f") return std::make_shared<FileFormatItem>();// 如果是文件名格式化子项if(key == "l") return std::make_shared<LineFormatItem>();// 如果是行号格式化子项if(key == "p") return std::make_shared<levelFormatItem>();// 如果是日志级别格式化子项if(key == "T") return std::make_shared<TabFormatItem>();// 如果是制表符格式化子项if(key == "m") return std::make_shared<MsgFormatItem>();// 如果是消息主体格式化子项if(key == "n") return std::make_shared<NLineFormatItem>();// 如果是换行符格式化子项if(key=="")// 如果是空字符串,说明是其他格式化子项{return std::make_shared<OtherFormatItem>(val);// 如果是其他格式化子项}std::cout<<"没有对应的格式化字符:%"<<key<<std::endl;abort();//程序异常退出处理return FormatItem::ptr();//空对象指针}private:std::string _pattern; // 格式化规则字符串std::vector<FormatItem::ptr> _items; // 这个容器中的类型是智能指针 ,存储的是格式化子项的智能指针/*对这个子项数组按顺序的从我们的消息中取出对应的内容逐个遍历_items,从消息中取出内容进行一个format。得到一个数据就放到ostream中*/};
测试了下,效果还是不错的
8.5日志落地模块(简单工厂)
功能:将格式化完成后的日志消息字符串,输出到指定的位置
拓展:支持同时将日志落地到不同的位置
位置分类
1、标准输出
2、指定文件(事后进行日志分析)
3、滚动文件(文件按照时间/大小进行滚动切换)
扩展:支持落地方向的扩展
用户可以自己编写一个新的落地模块,将日志进行其他方向的落地
实现思想:
1、抽象出落地模块类
2、不同落地方向从基类进行派生
3、使用工厂模式进行创建与表示的分离
抽象的基类
class LogSink{public:using ptr=std::shared_ptr<LogSink>;//对LogSink进行智能管理LogSink(){};virtual~LogSink(){};//对析构进行抽象(用户在拓展的时候可能有一些释放的操作)virtual void log(const char*data,size_t len)=0;//起始地址和长度进行日志落地private:};
然后我们根据不同的方向进行拓展操作
8.5.1日志落地的框架介绍
三个方向:
标准输出
// 落地方向:标准输出class StdoutSink : public LogSink{public:// 将日志消息写入到标准输出void log(const char *data, size_t len);};
指定文件
// 落地方向:指定文件 class FileSink : public LogSink{public://传入文件名,并打开文件,将操作句柄管理起来FileSink(const std::string &pathname){}// 将日志消息写入到指定文件void log(const char *data, size_t len);private:std::string _pathname; // 指定的文件名std::ofstream _ofs; // 文件输出流};
滚动文件(以大小进行滚动)
// 落地方向:滚动文件(以大小进行滚动)class RollBySizeSink : public LogSink{public:RollBySizeSink(const std::string &basename,size_t max_fsize);// 将日志消息写入到指定文件,写入前判断文件大小,超过了最大大小就要切换文件了void log(const char *data, size_t len);private:void createNewFile();//进行大小判断,超过指定大小则创建新文件private://通过基础文件名+扩展文件名组成一个实际的当前输出文件名// ./log/test.log-2021-08-01std::string _basename; // 基础文件名,最终的文件名后面会有时间std::ofstream _ofs; // 文件输出流size_t _max_fsize; // 单个文件的最大大小,超过文件大小就得进行文件的切换了size_t _cur_fsize; // 记录当前文件已经写入的数据大小};
8.5.2三种方向版块的实际构建
标准输出
class LogSink{public:using ptr = std::shared_ptr<LogSink>; // 对LogSink进行智能管理LogSink() {};virtual ~LogSink() {}; // 对析构进行抽象(用户在拓展的时候可能有一些释放的操作)virtual void log(const char *data, size_t len) = 0; // 起始地址和长度进行日志落地};// 落地方向:标准输出class StdoutSink : public LogSink{public:// 将日志消息写入到标准输出void log(const char *data, size_t len){std::cout.write(data, len); // 直接使用重载函数write,可以进行限制写入的长度}};
指定文件
// 落地方向:指定文件class FileSink : public LogSink{public:// 传入文件名,并打开文件,将操作句柄管理起来FileSink(const std::string &pathname): _pathname(pathname){// 1、创建日志文件所在的目录util::File::createDirectory(util::File::path(_pathname));// 2、创建并打开日志文件_ofs.open(_pathname, std::ios::binary | std::ios::app); // 二进制的形式进行打开,并且进行数据的追加操作assert(_ofs.is_open());}// 将日志消息写入到指定文件void log(const char *data, size_t len){_ofs.write(data, len); // 写入数据到文件assert(_ofs.good()); // 断言写入是否成功了}private:std::string _pathname; // 指定的文件名std::ofstream _ofs; // 文件输出流};
滚动文件(以大小进行滚动)
// 落地方向:滚动文件(以大小进行滚动)class RollBySizeSink : public LogSink{public:RollBySizeSink(const std::string &basename, size_t max_fsize): _basename(basename), _max_fsize(max_fsize), _cur_fsize(0),_name_count(0){std::string pathname = createNewFile(); // 利用下面的创建文件名函数,创建第一个文件// 1、创建日志文件所在的目录util::File::createDirectory(util::File::path(pathname));// 2、创建并打开日志文件_ofs.open(pathname, std::ios::binary | std::ios::app); // 二进制的形式进行打开,并且进行数据的追加操作assert(_ofs.is_open());}// 将日志消息写入到指定文件,写入前判断文件大小,超过了最大大小就要切换文件了void log(const char *data, size_t len){if (_cur_fsize >= _max_fsize){//先将原来的文件给关闭掉,如果不关闭的话就会造成资源泄露的情况出现了_ofs.close();// 创建一个新的文件名std::string pathname = createNewFile();// 2、创建并打开日志文件_ofs.open(pathname, std::ios::binary | std::ios::app); // 二进制的形式进行打开,并且进行数据的追加操作assert(_ofs.is_open());_cur_fsize=0;//进行清零操作,因为我们换文件了}_ofs.write(data, len); // 写入数据到文件assert(_ofs.good()); // 断言写入是否成功了_cur_fsize+=len;//进程当前内存的更新}private:std::string createNewFile() // 创建一个新的文件名{// 获取系统时间,以时间来构建文件拓展名time_t t = util::Date::now(); // 获取时间struct tm lt; // 接受转换后的时间结构的localtime_r(&t, <); // 将结构化的时间信息放到lt中,就是将时间戳转换为时间结构std::stringstream filename;filename << _basename;// 下面的lt.tm_year都是结构体里面的相关信息filename << lt.tm_year + 1900;filename << lt.tm_mon + 1;filename << lt.tm_mday;filename << lt.tm_hour;filename << lt.tm_min;filename << lt.tm_sec;filename<<"-";filename<<_name_count++;filename << ".log"; // 文件的后缀名return filename.str(); // 我们需要通过str()获取字符串形式的filename}private:// 通过基础文件名+扩展文件名组成一个实际的当前输出文件名// ./log/test.log-2021-08-01size_t _name_count=0;std::string _basename; // 基础文件名,最终的文件名后面会有时间std::ofstream _ofs; // 文件输出流size_t _max_fsize; // 单个文件的最大大小,超过文件大小就得进行文件的切换了size_t _cur_fsize; // 记录当前文件已经写入的数据大小};
8.5.3落地模块工厂
//我们可以通过模版参数进行控制,作为类型来控制我们的输出//因为上面的三种方向的参数个数都是不一样的,所以这里我们使用不定参函数class SinkFactory{public://直接就是模版函数template<typename SinkType,typename ...Args>//传递一个具体的日志落地的方向类型static LogSink::ptr create(Args... args){//将参数包展开进行一个完美转发return std::make_shared<SinkType>(std::forward<Args>(args)...); // 通过make_shared来创建具体的日志落地对象}};
这段 C++ 代码实现了一个日志接收器(Sink)的工厂类,使用了模板元编程和可变参数模板技术,其主要目的是根据不同的日志输出目标(如文件、控制台、网络等)动态创建相应的日志接收器对象
SinkType:某种自定义的日志落地方向
Args...:可变参数包,用于传递给SinkType的构造函数。
创建SinkType类型的对象,并返回其基类指针(LogSink::ptr)
std::forward<Args>(args)...:完美转发参数包,保留参数的左值 / 右值属性,避免不必要的拷贝。- 适用于不同接收器的构造函数参数不同的场景(如
FileSink需要文件名,ConsoleSink可能不需要参数)。
std::make_shared<SinkType>(std::forward<Args>(args)...)
是 C++ 中一个非常精妙的表达式,结合了智能指针、完美转发和可变参数模板的特性。我来拆解它的工作原理和意义:
构造一个类型为 SinkType 的对象,使用传入的参数 args...。
将对象放入 std::shared_ptr 智能指针中,自动管理生命周期。
通过一次内存分配同时创建对象和智能指针的控制块(相比分开调用 new 和 shared_ptr 构造函数更高效)。
(args...) 将可变参数 args... 展开为参数列表,传递给 SinkType 的构造函数。
std::forward<Args>(args)... 完美转发:
- 保持参数值类别:确保参数以原始的左值 / 右值属性传递给构造函数。
- 左值参数(如变量名)会被转发为左值。
- 右值参数(如临时对象)会被转发为右值,触发移动构造 / 赋值。
- 避免拷贝:对于右值参数,直接调用移动语义,提高性能。
我们测试了下,效果还是很不错的
测试代码如下:
#include"util.hpp"#include"level.hpp"#include"message.hpp"#include"format.hpp"#include"sink.hpp"int main(){kaizi::LogMsg msg(kaizi::LogLevel::value::DEBUG,53,"main.c","root","格式化功能测试...");//将用户提供的格式字符串(如 [%d{%H:%M:%S}][%t][%c]...)解析为一系列 FormatItem 对象。kaizi::Formatter fmt;std::string str=fmt.format(msg);//对这条消息进行格式化操作,返回格式化后的字符串存储在str中kaizi::LogSink::ptr stdout_lsp=kaizi::SinkFactory::create<kaizi::StdoutSink>();//创建StdoutSink对象kaizi::LogSink::ptr file_lsp=kaizi::SinkFactory::create<kaizi::FileSink>("./logfile/test.log");//创建StdoutSink对象kaizi::LogSink::ptr roll_lsp=kaizi::SinkFactory::create<kaizi::RollBySizeSink>("./logfile/roll-",1024*1024);//创建StdoutSink对象stdout_lsp->log(str.c_str(),str.size());//将消息输出到StdoutSinkfile_lsp->log(str.c_str(),str.size());//将消息输出到FileSinksize_t cursize=0;//当前内存大小size_t count=0;//计数while(cursize<1024*1024*10)//如果小于10MB的话就不断的进行写入操作{//每一条日志后面都追加了我们的计数器std::string tmp=str+std::to_string(count++);roll_lsp->log(str.c_str(),str.size());//将消息输出到RollBySizeSinkcursize+=str.size();}return 0;
我们这里使用了三种方式进行落地,标准输出,文件输出,以及滚动文件方向
8.5.4日志落地模块的拓展测试
我们现在拓展一个以时间作为日志文件滚动切换的日志落地模块
/*拓展一个以时间作为日志文件滚动切换的日志落地模块1、以时间进行文件滚动,实际上是以时间段进行滚动的,多少秒切换一次文件实现思想:以当前系统时间取模时间段大小,可以得到当前时间段时第几个时间段每次以当前系统时间取模,判断与当前文件的时间是否一致,不一致的话代表不是同一个时间段time(nullptr)%gap;time(nullptr)%60 当前就是第n个60s*/// 落地方向:指定文件enum class TimeGap // 以多长时间进行切换的{GAP_SECOND,GAP_MINUTE,GAP_HOUR,GAP_DAY,};class RollByTimeSink : public kaizi::LogSink{public:// 传入文件名,并打开文件,将操作句柄管理起来RollByTimeSink(const std::string &basename, TimeGap gap_type) // 这里用户就可以传入一个间隔时间类型,然后我们在构造中进行分辨: _basename(basename){switch (gap_type){case TimeGap::GAP_SECOND:_gap_size = 1;break;case TimeGap::GAP_MINUTE:_gap_size = 60;break;case TimeGap::GAP_HOUR:_gap_size = 3600;break;case TimeGap::GAP_DAY:_gap_size = 3600 * 24;break;}cur_gap=_gap_size==1?kaizi::util::Date::now() :kaizi::util::Date::now()%_gap_size;//获取当前时间的余数,代表当前是第几个时间段std::string filename = createNewFile();//创建一个新的文件kaizi::util::File::createDirectory(kaizi::util::File::path(filename)); // 给到一个文件名然后进行目录的创建_ofs.open(filename, std::ios::binary | std::ios::app); // 二进制的形式进行打开,并且进行数据的追加操作assert(_ofs.is_open());//断言下是否打开成功}// 将日志消息写入到指定文件,判断当前时间是否是当前文件的时间段,不是切换文件void log(const char *data, size_t len){time_t cur = kaizi::util::Date::now(); // 获取时间if ((cur % _gap_size) != cur_gap) // 如果当前时间与当前文件的时间段不一致,那么切换文件{_ofs.close();//先将当前文件进行关闭,然后创建一个新的文件进行操作//满足上面的条件我们就进行新文件的创建操作std::string filename = createNewFile();//创建一个新的文件_ofs.open(filename, std::ios::binary | std::ios::app); // 二进制的形式进行打开,并且进行数据的追加操作assert(_ofs.is_open());}_ofs.write(data, len); // 写入数据到文件assert(_ofs.good()); // 断言写入是否成功了}private:std::string createNewFile() // 利用下面的创建文件名函数,创建第一个文件{time_t t = kaizi::util::Date::now(); // 获取时间struct tm lt; // 接受转换后的时间结构的localtime_r(&t, <); // 将结构化的时间信息放到lt中,就是将时间戳转换为时间结构std::stringstream filename;filename << _basename;// 下面的lt.tm_year都是结构体里面的相关信息filename << lt.tm_year + 1900; // 得加上1900才是真正的年份filename << lt.tm_mon + 1; // 默认是从0月开始的,我们是从1月开始的filename << lt.tm_mday;filename << lt.tm_hour;filename << lt.tm_min;filename << lt.tm_sec;filename << ".log"; // 文件的后缀名return filename.str(); // 我们需要通过str()获取字符串形式的filename}private:std::string _basename; // 指定的文件名std::ofstream _ofs; // 文件输出流size_t cur_gap; // 当前是第几个时间段size_t _gap_size; // 时间段的大小};
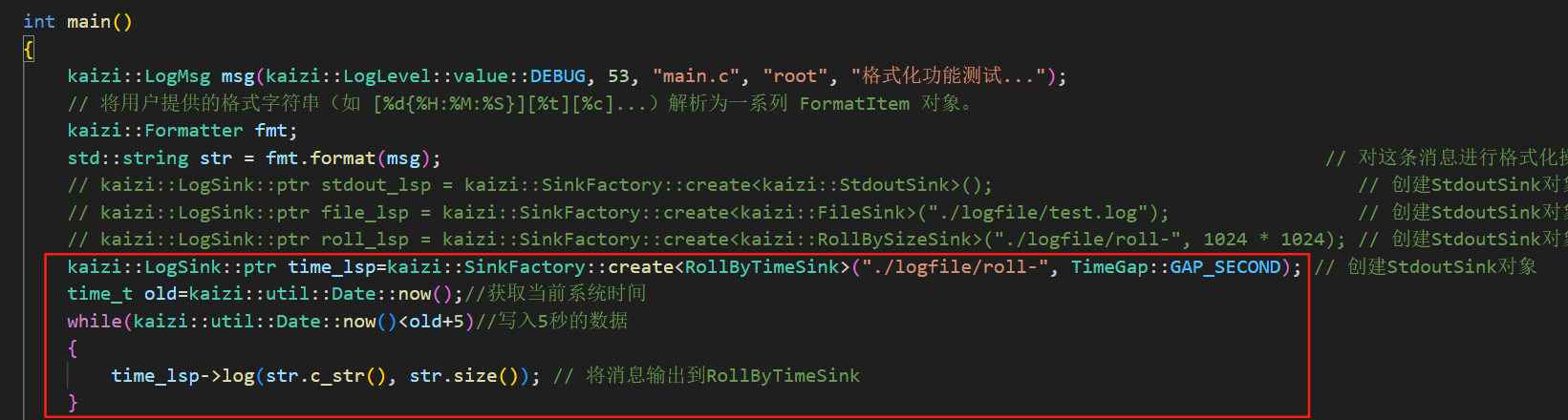
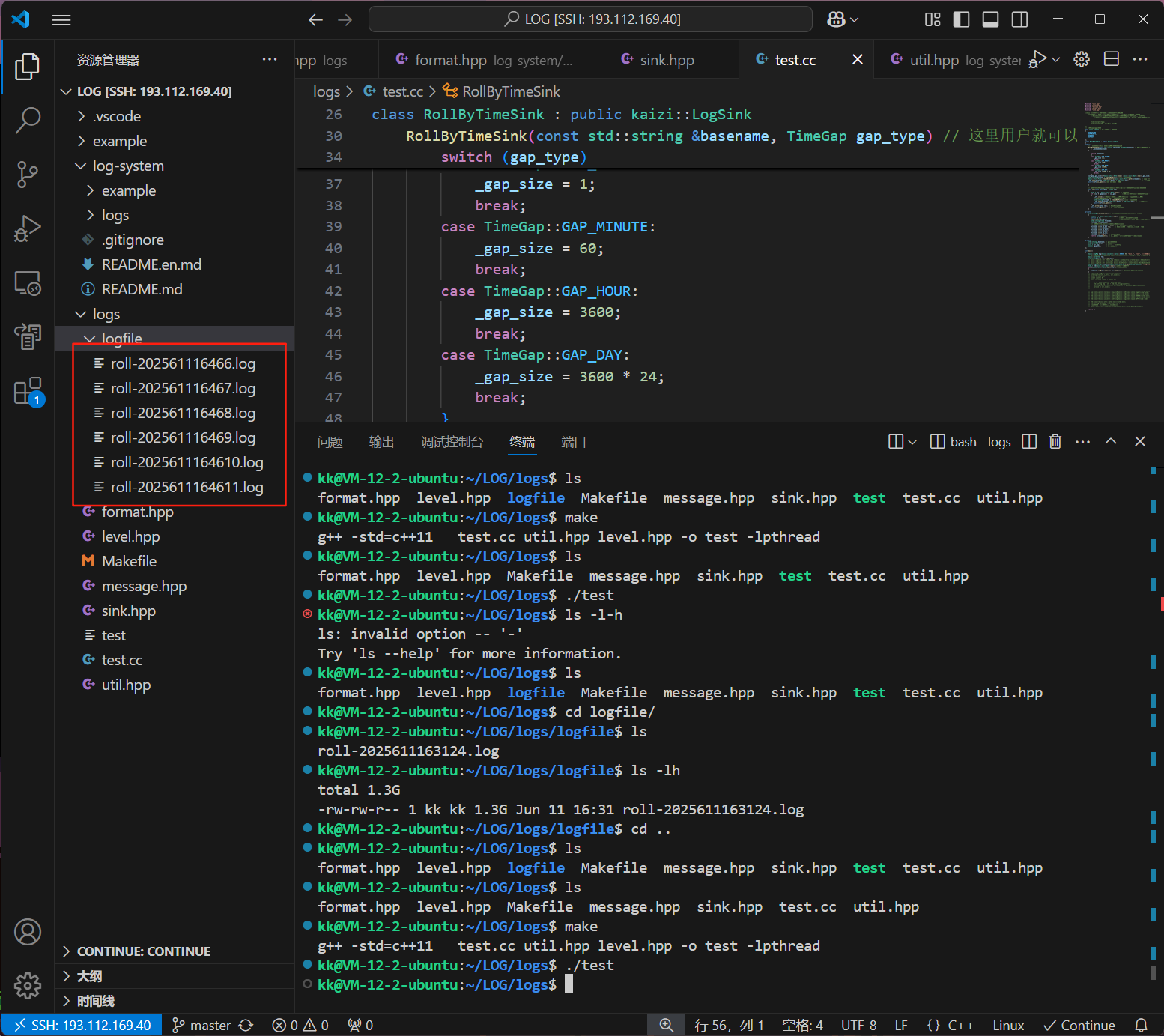
上面就是我们写的以时间作为日志文件滚动切换的日志落地模块类了
我们直接在测试里面加上这么几条代码进行测试操作
kaizi::LogSink::ptr time_lsp=kaizi::SinkFactory::create<RollByTimeSink>("./logfile/roll-", TimeGap::GAP_SECOND); // 创建StdoutSink对象time_t old=kaizi::util::Date::now();//获取当前系统时间while(kaizi::util::Date::now()<old+5)//写入5秒的数据{time_lsp->log(str.c_str(), str.size()); // 将消息输出到RollByTimeSink}
8.6日志器类设计(建造者模式)
8.6.1日志器模块的设计思想
功能:对前面所有模块进行整合,向外提供接口完成不同等级日志的输出操作
管理的成员:
1、格式化模块对象
2、落地模块对象数组(一个日志器可能会向多个位置进行日志输出)
3、默认的日志输出限制等级(大于等于限制等级的日志才能输出)
4、互斥锁(保证输出过程的安全性,不能让两个线程同时往一个文件里写数据)
5、日志器名称(日志器的唯一表示,以便于随机查找)
debug等级日志的输出操作(分别封装日志消息LogMsg----各个接口日志等级不同)
info等级日志的输出操作
warn等级日志的输出操作
error等级日志的输出操作
fatal等级日志的输出操作
实现:
1、抽象Logger基类(派生出同步日志器类&异步日志器类)
2、因为两种不同的日志器,只有落地方向不同,因此将落地操作给抽象出来
不同的日志器调用各自的落地操作进行日志落地
模块关联中使用基类指针对子类日志器对像进行日志管理和操作
⽇志器主要是⽤来和前端交互, 当我们需要使⽤⽇志系统打印log的时候, 只需要创建Logger对象,调⽤该对象debug、info、warn、error、fatal等⽅法输出⾃⼰想打印的⽇志即可,⽀持解析可变参数列表和输出格式, 即可以做到像使⽤printf函数⼀样打印⽇志。
当前⽇志系统⽀持同步⽇志 & 异步⽇志两种模式,两个不同的⽇志器唯⼀不同的地⽅在于他们在⽇志的落地⽅式上有所不同:
同步⽇志器:直接对⽇志消息进⾏输出。
异步⽇志器:将⽇志消息放⼊缓冲区,由异步线程进⾏输出。
因此⽇志器类在设计的时候先设计出⼀个Logger基类,在Logger基类的基础上,继承出SyncLogger同步⽇志器和AsyncLogger异步⽇志器。
且因为⽇志器模块是对前边多个模块的整合,想要创建⼀个⽇志器,需要设置⽇志器名称,设置⽇志输出等级,设置⽇志器类型,设置⽇志输出格式,设置落地⽅向,且落地⽅向有可能存在多个,整个⽇志器的创建过程较为复杂,为了保持良好的代码⻛格,编写出优雅的代码,因此⽇志器的创建这⾥采⽤了建造者模式来进⾏创建。
8.6.2日志器模块的代码设计
class Logger{public:using ptr=std::shared_ptr<Logger>;//智能指针进行类对象的管理//完成构造日志消息对象过程并进行格式化,得到格式化后的日志消息字符串,然后进行落地输出void debug(const std::string &file,size_t line,const std::string &fmt,...);//根据fmt取出后面的不定参数据,组成一个LogMsg对象,然后调用_log接口进行日志记录void info(const std::string &file,size_t line,const std::string &fmt,...);//根据fmt取出后面的不定参数据,组成一个LogMsg对象,然后调用_log接口进行日志记录void warn(const std::string &file,size_t line,const std::string &fmt,...);//根据fmt取出后面的不定参数据,组成一个LogMsg对象,然后调用_log接口进行日志记录void error(const std::string &file,size_t line,const std::string &fmt,...);//根据fmt取出后面的不定参数据,组成一个LogMsg对象,然后调用_log接口进行日志记录void fatal(const std::string &file,size_t line,const std::string &fmt,...);//根据fmt取出后面的不定参数据,组成一个LogMsg对象,然后调用_log接口进行日志记录protected://抽象的接口完成实际的落地输出---不同的日志器会有不同的实际落地方式virtual void log(const char*data,size_t len)=0;protected:std::mutex _mutex; // 日志器的互斥锁std::string _logger_name; // 日志器名称//如果下面的等级进行加锁保护的话锁冲突比较多,因为这个日志等级调用的比较频繁std::atomic<LogLevel::value> _limit_level;// 日志等级,定义为原子类型的成员,就能保证在多线程里面的原子访问了Formatter::ptr _formatter; // 日志格式化对象std::vector<LogSink::ptr> _sinks; // 日志落地对象,可能存在多个落地方向,所以使用vector+智能指针进行管理};
这段代码定义了一个 C++ 日志系统的核心类 Logger,它是一个抽象基类,提供了日志记录的基本框架和接口。
Logger 类实现了以下核心功能:
- 日志级别接口:提供了不同级别的日志记录方法(debug、info、warn、error、fatal)
- 日志格式化:使用格式化字符串和可变参数生成日志消息
- 日志落地:通过抽象接口
log将日志消息输出到目标位置 - 线程安全:使用互斥锁和原子操作确保多线程环境下的安全操作
8.6.3 日志器模块同步日志器的实现
这段 C++ 代码实现了一个日志器框架,包含抽象基类 Logger 和同步日志器子类 SyncLogger ,核心是规范日志的格式化、输出流程,并支持多线程安全
Logger:抽象基类,定义日志器的通用流程(等级判断、可变参数处理、日志格式化),并通过纯虚函数log把具体落地逻辑(同步 / 异步写文件、控制台等)留给子类实现。SyncLogger:继承Logger的子类,实现同步日志落地(调用sink直接输出,当前线程等待输出完成)。std::atomic:让_limit_level的读写原子化,多线程下无需额外加锁,高效且安全。Formatter/LogSink:都是通过智能指针管理的 “策略类”,Formatter负责日志格式(比如[时间] [等级] 内容),LogSink负责最终输出(比如写文件、打印到控制台 )。
Logger构造函数- 把外部传入的日志器名称、等级、格式化器、落地目标,初始化到成员变量,让日志器具备 “身份、规则、输出目标”。
以 debug 为例,其他 info/warn 逻辑类似,仅日志等级判断不同
- 等级过滤:确保日志等级满足输出条件(比如
DEBUG等级需 ≤_limit_level才输出 )。 - 参数拼接:通过
va_list+vasprintf处理可变参数(类似printf),生成完整日志文本。 - 序列化与落地:调用
serialize构造LogMsg、格式化、最终输出(交给log函数 )。
serialize:日志格式化与落地准备
LogMsg:封装日志的元数据(等级、位置、内容等 ),让格式化更灵活。_formatter->format:按配置的格式(比如"%Y-%m-%d %H:%M:%S [%level] %content"),把LogMsg转成最终日志字符串。
纯虛函数 log:子类实现落地逻辑
- 这是抽象接口,强制子类(如
SyncLogger)实现具体的 “日志落地” 逻辑(同步写文件 / 控制台,或异步入队列 )。
同步日志器:直接落地实现SyncLogger
- 加锁(
unique_lock)保证多线程下同一时间只有一个线程执行落地操作,避免冲突。 - 遍历
_sinks(落地目标),调用每个sink的log方法,把日志输出到不同目标(比如同时写文件和控制台 )。
/*完成日志器模块1、抽象日志器基类2、派生出不同的子类(同步日志器类&异步日志器类)*/#define _GNU_SOURCE#include "util.hpp"#include "level.hpp"#include "format.hpp"#include "sink.hpp"#include <atomic>#include <mutex>#include <cstdarg>namespace kaizi{class Logger{public:using ptr = std::shared_ptr<Logger>; // 智能指针进行类对象的管理Logger(const std::string &logger_name, // 日志器名称LogLevel::value level, // 日志限制等级Formatter::ptr &formatter, // 日志格式化对象std::vector<LogSink::ptr> &sinks) // 日志落地对象,我们将数组传递进来进行初始化操作: _logger_name(logger_name), _limit_level(level), _formatter(formatter), _sinks(sinks.begin(), sinks.end()){}// 完成构造日志消息对象过程并进行格式化,得到格式化后的日志消息字符串,然后进行落地输出void debug(const std::string &file, size_t line, const std::string &fmt, ...) // 根据fmt取出后面的不定参数据,组成一个LogMsg对象,然后调用_log接口进行日志记录{// 按日志等级判断是否输出,将 fmt 和可变参数拼接成完整日志,最终调用 _log 落地// 通过传入的参数构造一个日志消息对象,进行日志的格式化操作,进行落地// 1、判断当前的日志是否到达了输出等级if (LogLevel::value::DEBUG < _limit_level) // 不能进行输出操作{return;}// 2、对fmt格式化字符串和不定参进行字符串组织,得到的日志消息的字符串va_list ap; // 定义可变参数列表容器,用于存储、遍历可变参数。va_start(ap, fmt); // 获取指定参数的起始地址,这里就是获取fmt参数后第一个参数的起始地址,就是...char *res; // 定义一个空间指针,后面会将格式化的结果存在这个指针中的int ret = vasprintf(&res, fmt.c_str(), ap); // 按 fmt 的格式(如 "%d %s" ),把 ap 里的可变参数拼接成完整 C 字符串,存入 res 指向的内存if (ret == -1) // 格式化组织失败了{std::cout << "vasprintf failed!\n";return;}va_end(ap); // 释放 ap 相关资源,避免内存问题serialize(LogLevel::value::DEBUG, file, line, res); // 调用日志器基类的serialize接口进行日志的格式化操作,并进行日志的落地free(res); // 释放res指针指向的内存空间}void info(const std::string &file, size_t line, const std::string &fmt, ...) // 根据fmt取出后面的不定参数据,组成一个LogMsg对象,然后调用_log接口进行日志记录{// 按日志等级判断是否输出,将 fmt 和可变参数拼接成完整日志,最终调用 _log 落地// 通过传入的参数构造一个日志消息对象,进行日志的格式化操作,进行落地// 1、判断当前的日志是否到达了输出等级if (LogLevel::value::INFO < _limit_level) // 不能进行输出操作{return;}// 2、对fmt格式化字符串和不定参进行字符串组织,得到的日志消息的字符串va_list ap; // 定义可变参数列表容器,用于存储、遍历可变参数。va_start(ap, fmt); // 获取指定参数的起始地址,这里就是获取fmt参数后第一个参数的起始地址,就是...char *res; // 定义一个空间指针,后面会将格式化的结果存在这个指针中的int ret = vasprintf(&res, fmt.c_str(), ap); // 按 fmt 的格式(如 "%d %s" ),把 ap 里的可变参数拼接成完整 C 字符串,存入 res 指向的内存if (ret == -1) // 格式化组织失败了{std::cout << "vasprintf failed!\n";return;}va_end(ap); // 释放 ap 相关资源,避免内存问题serialize(LogLevel::value::INFO, file, line, res); // 调用日志器基类的serialize接口进行日志的格式化操作,并进行日志的落地free(res); // 释放res指针指向的内存空间}void warn(const std::string &file, size_t line, const std::string &fmt, ...) // 根据fmt取出后面的不定参数据,组成一个LogMsg对象,然后调用_log接口进行日志记录{// 按日志等级判断是否输出,将 fmt 和可变参数拼接成完整日志,最终调用 _log 落地// 通过传入的参数构造一个日志消息对象,进行日志的格式化操作,进行落地// 1、判断当前的日志是否到达了输出等级if (LogLevel::value::WARN < _limit_level) // 不能进行输出操作{return;}// 2、对fmt格式化字符串和不定参进行字符串组织,得到的日志消息的字符串va_list ap; // 定义可变参数列表容器,用于存储、遍历可变参数。va_start(ap, fmt); // 获取指定参数的起始地址,这里就是获取fmt参数后第一个参数的起始地址,就是...char *res; // 定义一个空间指针,后面会将格式化的结果存在这个指针中的int ret = vasprintf(&res, fmt.c_str(), ap); // 按 fmt 的格式(如 "%d %s" ),把 ap 里的可变参数拼接成完整 C 字符串,存入 res 指向的内存if (ret == -1) // 格式化组织失败了{std::cout << "vasprintf failed!\n";return;}va_end(ap); // 释放 ap 相关资源,避免内存问题serialize(LogLevel::value::WARN, file, line, res); // 调用日志器基类的serialize接口进行日志的格式化操作,并进行日志的落地free(res); // 释放res指针指向的内存空间}void error(const std::string &file, size_t line, const std::string &fmt, ...) // 根据fmt取出后面的不定参数据,组成一个LogMsg对象,然后调用_log接口进行日志记录{// 按日志等级判断是否输出,将 fmt 和可变参数拼接成完整日志,最终调用 _log 落地// 通过传入的参数构造一个日志消息对象,进行日志的格式化操作,进行落地// 1、判断当前的日志是否到达了输出等级if (LogLevel::value::ERROR < _limit_level) // 不能进行输出操作{return;}// 2、对fmt格式化字符串和不定参进行字符串组织,得到的日志消息的字符串va_list ap; // 定义可变参数列表容器,用于存储、遍历可变参数。va_start(ap, fmt); // 获取指定参数的起始地址,这里就是获取fmt参数后第一个参数的起始地址,就是...char *res; // 定义一个空间指针,后面会将格式化的结果存在这个指针中的int ret = vasprintf(&res, fmt.c_str(), ap); // 按 fmt 的格式(如 "%d %s" ),把 ap 里的可变参数拼接成完整 C 字符串,存入 res 指向的内存if (ret == -1) // 格式化组织失败了{std::cout << "vasprintf failed!\n";return;}va_end(ap); // 释放 ap 相关资源,避免内存问题serialize(LogLevel::value::ERROR, file, line, res); // 调用日志器基类的serialize接口进行日志的格式化操作,并进行日志的落地free(res); // 释放res指针指向的内存空间}void fatal(const std::string &file, size_t line, const std::string &fmt, ...) // 根据fmt取出后面的不定参数据,组成一个LogMsg对象,然后调用_log接口进行日志记录{// 按日志等级判断是否输出,将 fmt 和可变参数拼接成完整日志,最终调用 _log 落地// 通过传入的参数构造一个日志消息对象,进行日志的格式化操作,进行落地// 1、判断当前的日志是否到达了输出等级if (LogLevel::value::FATAL < _limit_level) // 不能进行输出操作{return;}// 2、对fmt格式化字符串和不定参进行字符串组织,得到的日志消息的字符串va_list ap; // 定义可变参数列表容器,用于存储、遍历可变参数。va_start(ap, fmt); // 获取指定参数的起始地址,这里就是获取fmt参数后第一个参数的起始地址,就是...char *res; // 定义一个空间指针,后面会将格式化的结果存在这个指针中的int ret = vasprintf(&res, fmt.c_str(), ap); // 按 fmt 的格式(如 "%d %s" ),把 ap 里的可变参数拼接成完整 C 字符串,存入 res 指向的内存if (ret == -1) // 格式化组织失败了{std::cout << "vasprintf failed!\n";return;}va_end(ap); // 释放 ap 相关资源,避免内存问题serialize(LogLevel::value::FATAL, file, line, res); // 调用日志器基类的serialize接口进行日志的格式化操作,并进行日志的落地free(res); // 释放res指针指向的内存空间}protected:void serialize(LogLevel::value level, const std::string &file, size_t line, char *str){// 3、构造LogMsg日志消息类对象LogMsg msg(LogLevel::value::DEBUG, line, file, _logger_name, str); // 构造一个日志消息对象,并进行日志的格式化操作// 4、通过格式化工具对LogMsg对象进行格式化,得到格式化后的日志字符串std::stringstream ss; // 定义一个字符串流类对象_formatter->format(ss, msg); // 调用日志格式化对象进行格式化操作,将日志内容格式化后输出到ss这个内存流中// 5、日志落地log(ss.str().c_str(), ss.str().size()); // 调用日志器基类的log接口进行日志落地}// 抽象的接口完成实际的落地输出---不同的日志器会有不同的实际落地方式virtual void log(const char *data, size_t len) = 0;protected:std::mutex _mutex; // 日志器的互斥锁std::string _logger_name; // 日志器名称// 如果下面的等级进行加锁保护的话锁冲突比较多,因为这个日志等级调用的比较频繁std::atomic<LogLevel::value> _limit_level; // 日志等级,定义为原子类型的成员,就能保证在多线程里面的原子访问了Formatter::ptr _formatter; // 日志格式化对象std::vector<LogSink::ptr> _sinks; // 日志落地对象数组,可能存在多个落地方向,所以使用vector+智能指针进行管理};// 同步日志器class SyncLogger : public Logger{public:SyncLogger(const std::string &logger_name, // 日志器名称LogLevel::value level, // 日志限制等级Formatter::ptr &formatter, // 日志格式化对象std::vector<LogSink::ptr> &sinks) // 日志落地对象,我们将数组传递进来进行初始化操作: Logger(logger_name, level, formatter, sinks)//使用抽象基类进行一个实例化操作{}protected://同步日志器,是将日志直接通过落地模块句柄进行日志落地void log(const char *data, size_t len){//它通过 RAII 机制确保锁的正确获取和释放,避免死锁问题//同时提供了比 std::lock_guard 更灵活的锁管理方式std::unique_lock<std::mutex> lock(_mutex); //自动进行加锁,等lock释放了锁会自动进行解锁的if(_sinks.empty())return ;for(auto &sink:_sinks)//遍历日志落地对象数组{sink->log(data,len);//逐个调用 sink 的 log 方法,把日志数据输出到不同目标}}};}
简单说,这是一个可扩展的日志框架:通过抽象基类定义流程,同步子类实现 “立即输出”,后续还能扩展异步子类(队列 + 后台线程)
8.6.4同步日志器模块测试
同步日志器(SyncLogger)会对多个 Sink(落地地方向,比如控制台、普通文件、滚动文件)同时执行 “实时写入” 操作
测试代码
#include "util.hpp"#include "level.hpp"#include "message.hpp"#include "format.hpp"#include "sink.hpp"#include"logger.hpp"/*拓展一个以时间作为日志文件滚动切换的日志落地模块1、以时间进行文件滚动,实际上是以时间段进行滚动的,多少秒切换一次文件实现思想:以当前系统时间取模时间段大小,可以得到当前时间段时第几个时间段每次以当前系统时间取模,判断与当前文件的时间是否一致,不一致的话代表不是同一个时间段time(nullptr)%gap;time(nullptr)%60 当前就是第n个60s*/// 落地方向:指定文件enum class TimeGap // 以多长时间进行切换的{GAP_SECOND,GAP_MINUTE,GAP_HOUR,GAP_DAY,};class RollByTimeSink : public kaizi::LogSink{public:// 传入文件名,并打开文件,将操作句柄管理起来RollByTimeSink(const std::string &basename, TimeGap gap_type) // 这里用户就可以传入一个间隔时间类型,然后我们在构造中进行分辨: _basename(basename){switch (gap_type){case TimeGap::GAP_SECOND:_gap_size = 1;break;case TimeGap::GAP_MINUTE:_gap_size = 60;break;case TimeGap::GAP_HOUR:_gap_size = 3600;break;case TimeGap::GAP_DAY:_gap_size = 3600 * 24;break;}cur_gap=_gap_size==1?kaizi::util::Date::now() :kaizi::util::Date::now()%_gap_size;//获取当前时间的余数,代表当前是第几个时间段std::string filename = createNewFile();//创建一个新的文件kaizi::util::File::createDirectory(kaizi::util::File::path(filename)); // 给到一个文件名然后进行目录的创建_ofs.open(filename, std::ios::binary | std::ios::app); // 二进制的形式进行打开,并且进行数据的追加操作assert(_ofs.is_open());//断言下是否打开成功}// 将日志消息写入到指定文件,判断当前时间是否是当前文件的时间段,不是切换文件void log(const char *data, size_t len){time_t cur = kaizi::util::Date::now(); // 获取时间if ((cur % _gap_size) != cur_gap) // 如果当前时间与当前文件的时间段不一致,那么切换文件{_ofs.close();//先将当前文件进行关闭,然后创建一个新的文件进行操作//满足上面的条件我们就进行新文件的创建操作std::string filename = createNewFile();//创建一个新的文件_ofs.open(filename, std::ios::binary | std::ios::app); // 二进制的形式进行打开,并且进行数据的追加操作assert(_ofs.is_open());}_ofs.write(data, len); // 写入数据到文件assert(_ofs.good()); // 断言写入是否成功了}private:std::string createNewFile() // 利用下面的创建文件名函数,创建第一个文件{time_t t = kaizi::util::Date::now(); // 获取时间struct tm lt; // 接受转换后的时间结构的localtime_r(&t, <); // 将结构化的时间信息放到lt中,就是将时间戳转换为时间结构std::stringstream filename;filename << _basename;// 下面的lt.tm_year都是结构体里面的相关信息filename << lt.tm_year + 1900; // 得加上1900才是真正的年份filename << lt.tm_mon + 1; // 默认是从0月开始的,我们是从1月开始的filename << lt.tm_mday;filename << lt.tm_hour;filename << lt.tm_min;filename << lt.tm_sec;filename << ".log"; // 文件的后缀名return filename.str(); // 我们需要通过str()获取字符串形式的filename}private:std::string _basename; // 指定的文件名std::ofstream _ofs; // 文件输出流size_t cur_gap; // 当前是第几个时间段size_t _gap_size; // 时间段的大小};int main(){std::string logger_name="sync_logger";kaizi::LogLevel::value limit=kaizi::LogLevel::value::WARN;//限制等级kaizi::Formatter::ptr fmt(new kaizi::Formatter("[%d{%H:%M:%S}][%c][%f:%l][%p]%T%m%n"));//创建一个formatter对象让formatter指针进行智能管理//日志落地的三种方式kaizi::LogSink::ptr stdout_lsp = kaizi::SinkFactory::create<kaizi::StdoutSink>(); // 创建StdoutSink对象kaizi::LogSink::ptr file_lsp = kaizi::SinkFactory::create<kaizi::FileSink>("./logfile/test.log"); // 创建StdoutSink对象kaizi::LogSink::ptr roll_lsp = kaizi::SinkFactory::create<kaizi::RollBySizeSink>("./logfile/roll-", 1024 * 1024); // 创建StdoutSink对象std::vector<kaizi::LogSink::ptr>sinks={stdout_lsp,file_lsp,roll_lsp};//三个日志器落地方向//创建同步日志器kaizi::Logger::ptr logger(new kaizi::SyncLogger(logger_name,limit,fmt,sinks));//创建一个日志器对象,让日志器指针进行智能管理//我们上面设置的限制日志是WARN级别,所以只有WARN级别的日志才会被记录到文件中,其他级别的日志只会被记录到StdoutSink中logger->debug(__FILE__,__LINE__,"%s","测试日志");logger->info(__FILE__,__LINE__,"%s","测试日志");logger->warn(__FILE__,__LINE__,"%s","测试日志");logger->error(__FILE__,__LINE__,"%s","测试日志");logger->fatal(__FILE__,__LINE__,"%s","测试日志");//批量输出大日志文件(测试滚动文件)size_t cursize = 0;size_t count = 0;std::string str = "测试日志-";while (cursize < 1024 * 1024 * 10) // 如果小于10MB的话就不断的进行写入操作{// 每一条日志后面都追加了我们的计数器logger->fatal(__FILE__,__LINE__,"测试日志-%d",count++);cursize += 20;}return 0;
8.6.5日志器模块—建造者模块拓展(框架的搭建)
我们这里的日志器在构建的时候,每次都需要创建很多的零部件,如果用户上手的话肯定会觉得很麻烦的,增加了复杂度
那么我们这里就可以使用建造者模式进行日志器的构建、
建造者模式就是提前先将零部件给构建好了
这里我们搭建了一个建造者个框架
使用建造者模式来建造日志器,而不要让用户直接去构造日志器,简化用户的使用复杂度
建造者模式中,针对我们具体的对象得有一个建造者抽象类
然后根据我们具体的对象派生出我们具体的类
然后有了建造者类,我们通过指挥者类来指导建造者进行对象的创建
指挥建造完零部件之后然后再去建造我们的复杂对象
因为我们这里的建造是对零件顺序没有要求的,最主要的问题是参数过多,每个参数都需要进行构造
enum class LoggerType{LOGGER_SYNC, // 同步日志器LOGGER_ASYNC // 异步日志器};/*使用建造者模式来建造日志器,而不要让用户直接去构造日志器,简化用户的使用复杂度建造者模式中,针对我们具体的对象得有一个建造者抽象类然后根据我们具体的对象派生出我们具体的类然后有了建造者类,我们通过指挥者类来指导建造者进行对象的创建指挥建造完零部件之后然后再去建造我们的复杂对象因为我们这里的建造是对零件顺序没有要求的,最主要的问题是参数过多,每个参数都需要进行构造*/// 1、抽象一个日志器建造者类(完成日志器对象所需零部件的构建&日志器的构建)// 1、设置日志器类型// 2、将不同类型日志器的创建放到同一个日志建造者类中完成class LoggerBuilder{public:void buildLoggerType(LoggerType type) // 根据这个日志器的类型进行构造{}void buildLoggerName(const std::string &name) // 日志器名称{}void buildLoggerLevel(LogLevel::value level) // 日志器名称{}//构造一个格式化器,就是设置下我们日志器的输出规则void buildFormatter(const std::string &pattern) // 日志器名称{}//根据拓展性,让用户自己设定日志落地的方向,所以我们这里使用模版和不定参template<typename SinkType,typename... Args>void buildSink(Args &&... args); // 日志器名称virtual void build()=0; // 日志器的构建接口private:LoggerType _logger_type; // 日志器类型std::string _logger_name; // 日志器名称LogLevel::value _limit_level; // 日志等级Formatter::ptr _formatter; // 日志格式化对象std::vector<LogSink::ptr> _sinks; // 日志落地对象数组,可能存在多个落地方向,所以使用vector+智能指针进行管理};// 2、派生出具体的建造者类---局部日志器的建造者&全局的日志器建造者(后边添加了全局单例管理器之后,将日志器添加全局管理)class LocalLoggerBuilder : public LoggerBuilder{public:void build() override; // 日志器的构建接口private:};
8.6.6日志器模块—建造者模块拓展(代码实现)
enum class LoggerType{LOGGER_SYNC, // 同步日志器LOGGER_ASYNC // 异步日志器};/*使用建造者模式来建造日志器,而不要让用户直接去构造日志器,简化用户的使用复杂度建造者模式中,针对我们具体的对象得有一个建造者抽象类然后根据我们具体的对象派生出我们具体的类然后有了建造者类,我们通过指挥者类来指导建造者进行对象的创建指挥建造完零部件之后然后再去建造我们的复杂对象因为我们这里的建造是对零件顺序没有要求的,最主要的问题是参数过多,每个参数都需要进行构造*/// 1、抽象一个日志器建造者类(完成日志器对象所需零部件的构建&日志器的构建)// 1、设置日志器类型// 2、将不同类型日志器的创建放到同一个日志建造者类中完成class LoggerBuilder{public:LoggerBuilder(): _logger_type(LoggerType::LOGGER_SYNC)//默认生成的事同步日志器,_limit_level(LogLevel::value::DEBUG) // 默认日志等级为DEBUG{}void buildLoggerType(LoggerType type) // 根据这个日志器的类型进行构造{_logger_type=type;}void buildLoggerName(const std::string &name) // 日志器名称{_logger_name=name;}void buildLoggerLevel(LogLevel::value level) // 日志器名称{_limit_level=level;}//构造一个格式化器,就是设置下我们日志器的输出规则void buildFormatter(const std::string &pattern) // 日志器名称{//通过pattern来设置日志格式化对象_formatter=std::make_shared<Formatter>(pattern);//构造了一个Formatter对象,通过智能指针进行管理}//根据拓展性,让用户自己设定日志落地的方向,所以我们这里使用模版和不定参template<typename SinkType,typename... Args>void buildSink(Args &&... args) // 创建落地器{LogSink::ptr psink=SinkFactory::create<SinkType>(std::forward<Args>(args)...); // 对参数包进行一个完美转发,将参数展开传入,创建一个落地器_sinks.push_back(psink); // 将这个落地器添加到日志器的数组中}virtual Logger::ptr build()=0; // 日志器的构建接口,返回的是一个日志器对象protected:LoggerType _logger_type; // 日志器类型std::string _logger_name; // 日志器名称LogLevel::value _limit_level; // 日志等级Formatter::ptr _formatter; // 日志格式化对象std::vector<LogSink::ptr> _sinks; // 日志落地对象数组,可能存在多个落地方向,所以使用vector+智能指针进行管理};// 2、派生出具体的建造者类---局部日志器的建造者&全局的日志器建造者(后边添加了全局单例管理器之后,将日志器添加全局管理)class LocalLoggerBuilder : public LoggerBuilder{public://返回对应的日志器Logger::ptr build() override // 日志器的构建接口{assert(_logger_name.empty()==false);//必须有日志器名称if(_formatter.get()==nullptr)//如果是空的话就代表没有日志器{_formatter=std::make_shared<Formatter>();//构造一个默认的日志格式化对象}if(_sinks.empty())//如果没有落地对象的话就添加一个默认的落地器{buildSink<StdoutSink>();//添加一个标准输出方向的落地器}//到这里东西都有了,那么我们就得进行创建对象的操作了if(_logger_type==LoggerType::LOGGER_ASYNC){}//走到这里就是同步日志器了return std::make_shared<SyncLogger>(_logger_name, _limit_level, _formatter, _sinks); // 构造一个同步日志器对象并返回}private:};
这段代码是基于建造者模式设计的日志器构建框架,核心目的是简化用户创建日志器的复杂度
LoggerType 枚举:定义日志器类型
LoggerBuilder 抽象基类:定义构建步骤
LocalLoggerBuilder 具体实现类:完成构建逻辑
泛型 buildSink:灵活添加落地目标
无需关心 SyncLogger 需要哪些参数、怎么初始化 Formatter 和 Sink,只需调用 buildXXX 配置,最后 build() 就能得到可用的日志器。
8.6.7日志模块—建造者的模块拓展(测试)
测试代码如下:
int main(){std::string logger_name="sync_logger";kaizi::LogLevel::value limit=kaizi::LogLevel::value::WARN;//限制等级kaizi::Formatter::ptr fmt(new kaizi::Formatter("[%d{%H:%M:%S}][%c][%f:%l][%p]%T%m%n"));//创建一个formatter对象让formatter指针进行智能管理//日志落地的三种方式kaizi::LogSink::ptr stdout_lsp = kaizi::SinkFactory::create<kaizi::StdoutSink>(); // 创建StdoutSink对象kaizi::LogSink::ptr file_lsp = kaizi::SinkFactory::create<kaizi::FileSink>("./logfile/test.log"); // 创建StdoutSink对象kaizi::LogSink::ptr roll_lsp = kaizi::SinkFactory::create<kaizi::RollBySizeSink>("./logfile/roll-", 1024 * 1024); // 创建StdoutSink对象std::vector<kaizi::LogSink::ptr>sinks={stdout_lsp,file_lsp,roll_lsp};//三个日志器落地方向//创建同步日志器kaizi::Logger::ptr logger(new kaizi::SyncLogger(logger_name,limit,fmt,sinks));//创建一个日志器对象,让日志器指针进行智能管理//我们上面设置的限制日志是WARN级别,所以只有WARN级别的日志才会被记录到文件中,其他级别的日志只会被记录到StdoutSink中logger->debug(__FILE__,__LINE__,"%s","测试日志");logger->info(__FILE__,__LINE__,"%s","测试日志");logger->warn(__FILE__,__LINE__,"%s","测试日志");logger->error(__FILE__,__LINE__,"%s","测试日志");logger->fatal(__FILE__,__LINE__,"%s","测试日志");//批量输出大日志文件(测试滚动文件)size_t cursize = 0;size_t count = 0;std::string str = "测试日志-";while (cursize < 1024 * 1024 * 10) // 如果小于10MB的话就不断的进行写入操作{// 每一条日志后面都追加了我们的计数器logger->fatal(__FILE__,__LINE__,"测试日志-%d",count++);cursize += 20;}return 0;
8.7日志器模块(异步缓冲区)
8.7.1异步缓冲区设计思想
前边完成的是同步日志器:直接将消息进进行格式化写入文件
接下来完成的事异步日志器:
为了避免因为写日志的过程阻塞,导致业务线程在写日志的时候影响效率,因此,异步的思想就是不让业务线程进行日志的实际落地操作,而是将日志消息放到缓冲区中(一块指定的内存),
接下来有一个专门的异步线程,去针对缓冲区中的数据进行处理(实际的落地操作)
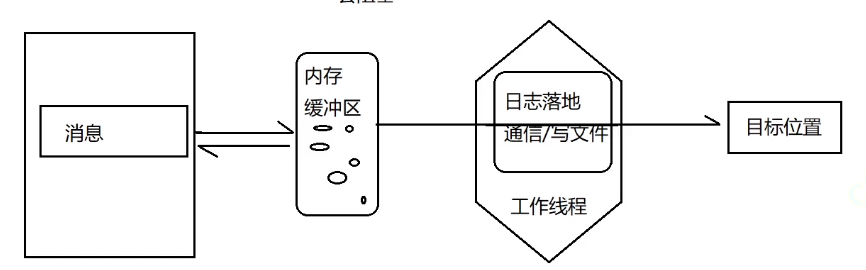
实现:实现一个线程安全的缓冲区
创建一个异步工作线程,专门负责缓冲区中日志消息的落地操作
缓冲区详细设计:
1、使用队列,缓冲日志消息,逐条处理
要求:不能涉及到空间的频繁申请与释放,否则会降低效率
结果:设计一个环形队列(提前将空间申请号,然后对空间循环利用)
这个缓冲区的操作会涉及到多线程,引发次缓冲区的操作必须满足线程安全,得加锁,不然多个线程同时访问一条数据
对于缓冲区的读写加锁
因为写日志操作,在实际开发中,并不会分配太多的资源,所以工作线程只需要一个日志器有一个就行了
涉及到的锁冲突,生产者与生产者的互斥&生产者和消费者的互斥
问题:锁冲突较为严重,因为所有线程之间都存在互斥关系
解决方案:双缓冲区
设计思想:异步处理线程 + 数据池
使⽤者将需要完成的任务添加到任务池中,由异步线程来完成任务的实际执⾏操作。
任务池的设计思想:双缓冲区阻塞数据池
优势:避免了空间的频繁申请释放,且尽可能的减少了⽣产者与消费者之间锁冲突的概率,提⾼了任务处理效率。
在任务池的设计中,有很多备选⽅案,⽐如循环队列等等,但是不管是哪⼀种都会涉及到锁冲突的情况,因为在⽣产者与消费者模型中,任何两个⻆⾊之间都具有互斥关系,因此每⼀次的任务添加与取出都有可能涉及锁的冲突,⽽双缓冲区不同,双缓冲区是处理器将⼀个缓冲区中的任务全部处理完毕后,然后交换两个缓冲区,重新对新的缓冲区中的任务进⾏处理,虽然同时多线程写⼊也会冲突,但是冲突并不会像每次只处理⼀条的时候频繁(减少了⽣产者与消费者之间的锁冲突),且不涉及到空间的频繁申请释放所带来的消耗。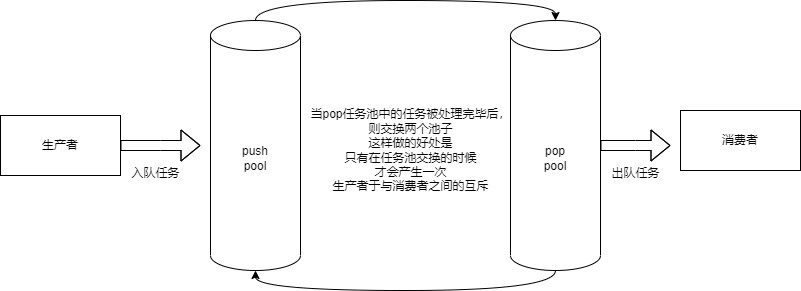
8.7.2异步缓冲区相关接口设计思想
我们先要设计单独的任务写入缓冲区
单个缓冲区的进一步设计:
设计一个缓冲区:直接存放格式化后的日志消息字符串
好处:
1、建好了LogMsg对象频繁的构造的消耗
2、可以针对缓冲区中的日志消息,一次性进行IO操作,减少 IO次数,提高效率
缓冲区设计:
1、管理一个存放字符串数据的缓冲区(使用vector进行空间管理),这里没有使用到string,因为string后面有\0,会导致结束
2、当前的写入数据位置的指针(指向可写区域的起始位置,避免数据的写入覆盖)
3、当前的读取数据位置的指针(指向可读数据区域的起始位置,当读取指针和写入指针位置相同,表示数据取完了)
提供的操作接口
1、向缓冲区中写入数据
2、获取可读数据起始地址的接口
3、获取可读数据长度的接口
4、移动读写位置的接口
5、初始化缓冲区的操作(将读写位置初始化,这个接口主要应用在交换缓冲区之前的),将一个缓冲区所有数据处理完毕之后
6、提供交换缓冲区的操作(直接进行空间指针的交换,并不交换空间数据)
8.7.3异步缓冲区代码实现
/*实现异步日志缓冲区*/#ifndef __BUFFER_HPP__#define __BUFFER_HPP__#include<vector>#include"util.hpp"#include<cassert>namespace kaizi{#define DEFAULT_BUFFER_SIZE (1024*1024*10) // 默认缓冲区大小为10M#define THRESHOLD_BUFFER_SIZE (1024*1024*80)//阈值#define INCREMENT_BUFFER_SIZE (1024*1024*10)//增值class Buffer{public:Buffer():_buffer(DEFAULT_BUFFER_SIZE),_reader_idx(0),_writer_idx(0)//默认大小和两个读写指针{}//向缓冲区中写入数据void push(const char*data,size_t len){//缓冲区剩余空间不够的情况,1、扩容 2、阻塞/返回false//先检测空间大小//1、固定大小,则直接返回//if(len>writeAbleSize())return ;//2、动态空间,用于极限性能测试---扩容ensureEnoughSize(len);//进行内存扩充操作,先进行判断,再决定扩容的方式//1、将数据拷贝到缓冲区std::copy(data,data+len,&_buffer[_writer_idx]);//将从data开始长度为len个字节的数据拷贝到_buffer缓冲区此时的_write_idx位置//2、将当前写入位置向后偏移moveWriter(len);//写入位置向后进行偏移len位}size_t writeAbleSize(){//对于扩容思路,不存在可写空间大小,因为总是可写//因此这个接口仅仅针对固定大小缓冲区提供return _buffer.size()-_writer_idx;//总大小-可写入的起始地址=剩余可写地址}//获取可读数据起始地址const char* begin(){return &_buffer[_reader_idx];//将读地址传过去就行了}//返回可读数据长度size_t readAbleSize(){//两个指针中间的就是我们实际的数据长度了,因为当前缓冲区并不是循环缓冲区,因此只会向后写//当前缓冲区的思想是双缓冲区的思想return _writer_idx-_reader_idx;//可读数据长度=可写数据长度-读数据长度}//对读写指针向后偏移操作void moveReader(size_t len)//可读空间大小{assert(len<=readAbleSize());//偏移的长度len必须小于可读数据的长度_reader_idx+=len;//进行偏移擦操作}//重置读写位置,初始化缓冲区void reset(){//将两个指针的位置都重置为0,表示此时缓冲区内的空间都是空闲空间//两个指针相等,表示没有数据可读_reader_idx=0;_writer_idx=0;}//对buffer进行交换操作,两个缓存区进行交换void swap( Buffer&buffer){//将两个buffer的读写地址进行交换,将缓冲区里面的空间地址进行交换_buffer.swap(buffer._buffer);std::swap(_reader_idx,buffer._reader_idx);std::swap(_writer_idx,buffer._writer_idx);}//判断缓冲区是否为空bool empty(){return (_reader_idx==_writer_idx);//两个指针相等,表示没有数据可读}private://对空间进行扩容操作void ensureEnoughSize(size_t len)//内存下小于80MB的进行线性增长,一次+10,如果大于的话就进行翻倍增长{if(len<=writeAbleSize())return ;//不需要扩容的情况size_t new_size=0;if(_buffer.size()<THRESHOLD_BUFFER_SIZE)//小于阈值的话则进行翻倍增长操作{//小于阈值的话则进行翻倍增长操作new_size=_buffer.size()*2+len;}else//大于等于阈值大小的话{new_size=_buffer.size()+INCREMENT_BUFFER_SIZE+len;//线性增长,一次增加10MB}_buffer.resize(new_size);//对缓冲区进行调整大小,调整为新的大小}//对读写指针向后偏移操作void moveWriter(size_t len){assert(len+_writer_idx<=_buffer.size());//偏移的长度len必须整个缓冲区的长度_writer_idx+=len;//进行偏移擦操作}private:std::vector<char>_buffer;//缓冲区使用vector进行管理size_t _reader_idx;//当前可读数据的指针,本质是下标size_t _writer_idx;//当前可写数据的指针,本质是下标};}#endif
这段代码实现了一个高性能的动态扩容日志缓冲区(Buffer 类),核心用于异步日志系统中的数据暂存
这个 Buffer 类是异步日志系统的核心组件,通过双指针管理 + 动态扩容 + 零拷贝交换,高效解决了日志写入的性能瓶颈。它的设计理念适用于任何需要批量处理、减少 IO 的场景(如网络通信、数据采集等)。
相关接口
1、向缓冲区中写入数据
2、获取可读数据起始地址的接口
3、获取可读数据长度的接口
4、移动读写位置的接口
5、初始化缓冲区的操作(将读写位置初始化,这个接口主要应用在交换缓冲区之前的),将一个缓冲区所有数据处理完毕之后
6、提供交换缓冲区的操作(直接进行空间指针的交换,并不交换空间数据)
我们进行了代码的测试,进行本地文件数据的写入操作
测试代码如下:
int main(){//读取文件数据,一点一点写入缓冲区,最终将缓冲区数据写入文件,判断生成的新文件和源文件是否一致std::ifstream ifs("./logs/test.log",std::ios::binary);//从这个地址进行数据的读取操作,以二进制的文件进行读取操作if(ifs.is_open()==false){return -1;}//如果打开失败的话那么我们直接返回-1ifs.seekg(0,std::ios::end); //读写位置跳转到文件末尾size_t fsize=ifs.tellg(); //获取当前读写位置相对于起始位置的偏移量ifs.seekg(0,std::ios::beg); //读写位置跳转到文件起始位置//通过上面三行代码就能读取到数据的总长度了//到这里就是读取到了数据了std::string body;body.resize(fsize); // 预先分配内存ifs.read(&body[0],fsize); // 读取10MB的数据if(ifs.good()==false){std::cout<<"read file error"<<std::endl;return -1;}ifs.close(); //关闭文件流//往buffer中写入数据kaizi::Buffer buffer;//缓冲区对象for(int i=0;i<body.size();i++){buffer.push(&body[i],1);//每次写1个字节}std::ofstream ofs("./logs/tmp.log",std::ios::binary);//以二进制的方式打开文件ofs.write(buffer.begin(),buffer.readAbleSize());//将缓冲区中的数据写入到文件中,可读数据大小size_t rsize=buffer.readAbleSize(); //获取一个固定的可读数据大小for(int i=0;i<rsize;i++){ofs.write(buffer.begin(),1);buffer.moveReader(1);}ofs.close(); //关闭文件流return 0;
8.7.4异步工作器设计思想
异步工作使用双缓冲区的思想
外界将任务数据源,添加到输入缓冲区中,
异步线程对数据缓冲区中的数据进行处理,处理缓冲区中没有数据了则交换缓冲区
实现:
管理的成员:
1、双缓冲区(生产,消费)
2、互斥锁//保证线程安全
3、条件变量—生产&消费(生产缓冲区没有数据,处理完消费缓冲区数据后就休眠 ,因为如果没有数据然后进行缓冲区交换的话是没有任何意义的)
4、回调函数(针对缓冲区中数据的处理接口—外界传入一个函数,告诉异步工作器数据该如何处理)
提供的操作:
1、停止异步工作器
2、添加数据到缓冲区
私有操作:
创建线程,线程入口函数中,交换缓冲区,对消费缓冲区数据使用回调函数进行处理,处理完后再次进行交换操作
我们这里先设计一个简单的框架
/*实现异步工作器*/#ifndef __LOOPER_HPP__#define __LOOPER_HPP__#include"buffer.hpp"#include<mutex>#include<thread>#include<condition_variable>#include<functional>#include<memory>namespace kaizi{using Functor=std::function<void(Buffer&)>;//回调函数类型class AsyncLooper{public:using ptr=std::shared_ptr<AsyncLooper>;//智能指针类型AsyncLooper(){};void stop(){}void push(const char*data,size_t len)//添加数据{}private:void threadEntry(){};//线程入口函数private:Functor _callBack;//具体对缓冲区数据进行处理的回调函数,由异步工作器使用者传入private:bool _stop;//工作器停止标志---异步工作器是否停止Buffer _pro_buf;//生产缓冲区Buffer _con_buf;//消费缓冲区std::mutex _mutex;std::condition_variable _cond_pro;//生产者条件变量std::condition_variable _cond_con;//消费者条件变量std::thread _thread;//异步工作器对应的工作线程};}#endif
8.7.5异步工作器代码实现
/*实现异步工作器*/#ifndef __LOOPER_HPP__#define __LOOPER_HPP__#include"buffer.hpp"#include<mutex>#include<thread>#include<condition_variable>#include<functional>#include<memory>#include<atomic>namespace kaizi{using Functor=std::function<void(Buffer&)>;//回调函数类型enum class AsyncType{ASYNC_SAFE,//安全状态,表示缓冲区满了则阻塞,避免资源耗尽的风险ASYNC_UNSAFE//不考虑资源耗尽的问题,无线扩容,常用于测试};class AsyncLooper{public:using ptr=std::shared_ptr<AsyncLooper>;//智能指针类型AsyncLooper(const Functor&cb,AsyncType loop_type=AsyncType::ASYNC_SAFE)//异步工作线程得用户告诉我们如何进行去对这个消费者缓冲区中的数据进行处理操作:_stop(false)//创建了一个新的线程对象,将这个线程对象赋值给成员变量_thread//当执行这行代码时://1.会创建一个新的线程对象//2、新线程会调用AsyncLooper类的threadEntry()方法//3、由于这是一个成员函数,需要通过this指针指定是哪个对象的方法//4、新线程独立运行,与主线程并行执行threadEntry()中的代码,_thread(std::thread(&AsyncLooper::threadEntry,this)),_callBack(cb), _looper_type(loop_type)//默认是安全状态{};~AsyncLooper(){stop();//析构函数中调用stop()函数,进行退出操作}void stop(){_stop=true;//将退出标志设置为true,说明要进行生产缓冲区停止生产了,然后通知消费者线程进行消费//那么我们就得唤醒所有的工作线程了_cond_con.notify_all();//等待工作线程退出_thread.join();}void push(const char*data,size_t len)//添加数据{//1、无线扩容--非安全 2、固定大小---生产换中区中数据满了就阻塞std::unique_lock<std::mutex> lock(_mutex);//先加个锁//条件变量控制,若我们缓冲区剩余空间大小大于数据长度的话,则可以添加数据if(_looper_type==AsyncType::ASYNC_SAFE)//如果是安全状态的话,则进行条件变量的等待,如果不是的话,则直接进行添加数据操作_cond_pro.wait(lock,[&](){return _pro_buf.writeAbleSize()>=len;});//走到这里就说明满足了条件,可以向缓冲区中进行数据的添加操作_pro_buf.push(data,len);//缓冲区进行数据插入操作//通知消费者线程进行消费_cond_con.notify_one();//唤醒消费者进行缓冲区中数据处理}private://线程入口函数---对消费缓冲区中的数据进行处理,处理完毕后初始化缓冲区,交换缓冲区void threadEntry(){//stop为true的话就退出循环了while(1)//如果没有停止运行的话我们就进行死循环操作,如果停止了的话,就跳出循环了{{ //1、要判断生产缓冲区中是否有数据,有的话就进行交换操作,无则阻塞std::unique_lock<std::mutex> lock(_mutex);//进行加锁操作//退出标志被设置,并且生产缓冲区已无数据//如果不按照这样的话,否则可能会造成生产缓冲区中有数据,但是没有完全被处理,然后随着析构函数进行析构了if(_stop==true&&_pro_buf.empty())break;//当我要退出了并且当前的生产缓冲区没有数据了,那么我就退出循环了//有生产缓冲区中有数据的话我们就进行交换操作//若当前是退出前被唤醒,或者有数据被唤醒,则返回真,继续向下运行,否则返回假重新进入休眠操作_cond_con.wait(lock,[&](){return _stop|| !_pro_buf.empty()>0;});//等待条件变量,直到生产者缓冲区有数据//如果是退出后被唤醒了的话,那么我们继续进行休眠操作_con_buf.swap(_pro_buf);//交换缓冲区//2、唤醒生产者,交换完毕了就能进行生产者的唤醒操作了 if(_looper_type==AsyncType::ASYNC_SAFE)//如果是安全状态的话就进行唤醒操作_cond_pro.notify_all();//唤醒生产者进行缓冲区中数据处理}//为互斥锁设置一个生命周期,当交换区交换完毕之后就解锁(并不对数据的处理过程加锁保护)//这里我们出了作用域了,那么锁的生命周期就结束了,就自动进行解锁操作,生产者就可以往缓冲区进行数据的填写操作//3、被唤醒后,对消费缓冲区进行数据处理,_callBack(_con_buf);//调用回调函数进行数据处理//4、处理完毕后初始化缓冲区_con_buf.reset();//重置读写位置,初始化缓冲区}}private:Functor _callBack;//具体对缓冲区数据进行处理的回调函数,由异步工作器使用者传入private:AsyncType _looper_type;//异步工作器的类型,安全还是不安全//stop的操作存在线程安全的问题,加锁又没有什么必要,我们直接将这个stop设置为原子的std::atomic<bool> _stop;//工作器停止标志---异步工作器是否停止Buffer _pro_buf;//生产缓冲区Buffer _con_buf;//消费缓冲区std::mutex _mutex;std::condition_variable _cond_pro;//生产者条件变量std::condition_variable _cond_con;//消费者条件变量std::thread _thread;//异步工作器对应的工作线程};}#endif
这里进行安全模式的区分
和我们的buffer.hpp中的代码进行了解耦合操作了,buffer.hpp只管插入数据就行了
这个代码实现了一个基于双缓冲区的异步工作器,采用生产者 - 消费者模型,具有两种工作模式:安全模式和不安全模式。
-
双缓冲区架构
_pro_buf:生产者缓冲区,主线程写入数据_con_buf:消费者缓冲区,工作线程处理数据- 通过
swap()操作实现缓冲区切换,减少锁争用
-
线程同步机制
- 使用
std::mutex保护共享资源 _cond_pro:生产者条件变量,控制缓冲区满时的等待_cond_con:消费者条件变量,控制缓冲区空时的等待
- 使用
-
两种工作模式
ASYNC_SAFE:安全模式,缓冲区满时生产者阻塞ASYNC_UNSAFE:不安全模式,缓冲区无限扩容(用于测试)
生产者流程(主线程)
- 获取互斥锁
- 在安全模式下,检查缓冲区空间是否足够,不足则等待
- 写入数据到生产缓冲区
- 通知消费者线程
- 释放锁
消费者流程(工作线程)
- 获取互斥锁
- 等待直到有数据或收到停止信号
- 交换生产和消费缓冲区
- 在安全模式下,通知等待的生产者
- 释放锁(此时生产者可以继续写入)
- 处理消费缓冲区中的数据
- 重置消费缓冲区
退出机制
- 设置
_stop标志为 true - 通知所有等待的消费者线程
- 等待工作线程完成并退出
设计亮点
-
减少锁持有时间
- 只在缓冲区交换时持有锁
- 数据处理过程不持有锁,提高并发性能
-
优雅退出
- 确保所有已提交的数据都会被处理
- 避免数据丢失
-
灵活配置
- 通过
AsyncType枚举支持两种工作模式 - 适应不同场景需求
- 通过
-
RAII 资源管理
- 使用智能指针和 RAII 原则管理线程资源
- 析构函数中自动调用
stop()确保资源正确释放
这种设计在高性能日志系统、消息队列和数据处理管道中非常常见,能够有效分离数据生产和消费逻辑,提高系统吞吐量。
8.8异步日志器设计
8.8.1异步日志器设计
思想:为了避免因为写日志的过程中,导致业务线程在写日志的时候影响效率
因此异步的思想就是不让业务线程进行业务的实际落地操作,而是将日志消息放到缓冲区中,接下来有一个专门的线程,去针对缓冲区中的数据进行处理
异步日志器设计思想:
1、继承于Logger日志器类
对于写日志操作进行函数重写(不再将数据直接写入文件,而是通过异步消息处理器,放到缓冲区中)
2、通过异步消息处理器,进行日志数据的实际落地
管理的成员:
1、异步工作器(异步消息处理器)
完成后,完成日志器建造者,进行异步日志器安全模式的选择,一共异步日志器的创建操作
我们现在日志器落地中加入一个异步日志器实现的类并且进行相关接口的实现操作
异步⽇志器类继承⾃⽇志器类, 并在同步⽇志器类上拓展了异步消息处理器。当我们需要异步输出⽇志的时候, 需要创建异步⽇志器和消息处理器, 调⽤异步⽇志器的log、error、info、fatal等函数输出不同级别⽇志。
log函数为重写Logger类的函数, 主要实现将⽇志数据加⼊异步队列缓冲区中
realLog函数主要由异步线程进⾏调⽤(是为异步消息处理器设置的回调函数),完成⽇志的实际落地⼯作
//异步日志器class AsyncLogger : public Logger{public:AsyncLogger(const std::string &logger_name, // 日志器名称LogLevel::value level, // 日志限制等级Formatter::ptr &formatter, // 日志格式化对象std::vector<LogSink::ptr> &sinks, // 日志落地对象,我们将数组传递进来进行初始化操作AsyncType _looper_type) //处理模式是什么 : Logger(logger_name, level, formatter, sinks), // 使用抽象基类进行一个实例化操作//创建一个异步工作器,传入了一个回调函数,第二个参数是实际的类型,就是安全模式和非安全模式//对reallog进行一个参数绑定,第一个是this参数,再预留一个参数//通过reallog函数生成一个新的函数,生成一个新的可调用对象,这个新的函数只需要传入一个参数就行了,就是一个缓冲区对象//就是说我们在调用calback的时候,函数内部已经绑定了一个参数进去了,这个参数就是我们的Asynclogger日志器对象,真正调用的时候calback只需要传入一个buffer就行了//原先的我们的reallog是需要传入两个参数的,还有一个this对象,因为这个是类内函数我们直接将Asynclogger绑定进去就行了,后面就只用传一个参数了_looper(std::make_shared<AsyncLooper>(std::bind(&AsyncLogger::realLog,this,std::placeholders::_1),_looper_type)) //异步工作器初始化{}void log(const char *data, size_t len)//将数据写入缓冲区{_looper->push(data,len); //将数据写入缓冲区,这里我们是不需要考虑线程安全的问题,因为push的线程就是安全的}//实际一个实际落地函数(将缓冲区中的数据 进行落地)void realLog(Buffer&buf)//传入一个缓冲区对象{if (_sinks.empty())return; // 如果这个落地对象数组是空的,那么我们直接返回了for (auto &sink : _sinks) // 遍历日志落地对象数组{//获取可读取数据的起始位置,以及可读取数据的大小,去进行一个实际的落地操作sink->log(buf.begin(),buf.readAbleSize()); // 逐个调用 sink 的 log 方法,把日志数据输出到不同目标//这个过程是不需要进行加锁操作的,因为异步工作线程本身就是串行化的工作过程,不需要进行加锁保护的,我们只要保护线程安全的落入到缓冲区里面去,线程内部就能保证串性化的写入数据}}private:AsyncLooper::ptr _looper; //异步日志循环器,利用智能指针进行对象的管理操作};
8.8.2日志器建造者完善
我们还进行了增加对异步日志器的处理方式
class LoggerBuilder{public:LoggerBuilder(): _logger_type(LoggerType::LOGGER_SYNC)//默认生成的事同步日志器,_limit_level(LogLevel::value::DEBUG) // 默认日志等级为DEBUG,_looper_type(AsyncType::ASYNC_SAFE) // 默认异步处理模式为安全模式{}void buildLoggerType(LoggerType type) // 根据这个日志器的类型进行构造{_logger_type=type;}void buildEnableUnSafeAsync()//启动一个非安全模式的操作{//设置为非安全状态_looper_type=AsyncType::ASYNC_UNSAFE;}void buildLoggerName(const std::string &name) // 日志器名称{_logger_name=name;}void buildLoggerLevel(LogLevel::value level) // 日志器名称{_limit_level=level;}//构造一个格式化器,就是设置下我们日志器的输出规则void buildFormatter(const std::string &pattern) // 日志器名称{//通过pattern来设置日志格式化对象_formatter=std::make_shared<Formatter>(pattern);//构造了一个Formatter对象,通过智能指针进行管理}//根据拓展性,让用户自己设定日志落地的方向,所以我们这里使用模版和不定参template<typename SinkType,typename... Args>void buildSink(Args &&... args) // 创建落地器{LogSink::ptr psink=SinkFactory::create<SinkType>(std::forward<Args>(args)...); // 对参数包进行一个完美转发,将参数展开传入,创建一个落地器_sinks.push_back(psink); // 将这个落地器添加到日志器的数组中}virtual Logger::ptr build()=0; // 日志器的构建接口,返回的是一个日志器对象protected:AsyncType _looper_type; //异步工作处理模式LoggerType _logger_type; // 日志器类型std::string _logger_name; // 日志器名称LogLevel::value _limit_level; // 日志等级Formatter::ptr _formatter; // 日志格式化对象std::vector<LogSink::ptr> _sinks; // 日志落地对象数组,可能存在多个落地方向,所以使用vector+智能指针进行管理};// 2、派生出具体的建造者类---局部日志器的建造者&全局的日志器建造者(后边添加了全局单例管理器之后,将日志器添加全局管理)class LocalLoggerBuilder : public LoggerBuilder{public://返回对应的日志器Logger::ptr build() override // 日志器的构建接口{assert(_logger_name.empty()==false);//必须有日志器名称if(_formatter.get()==nullptr)//如果是空的话就代表没有日志器{_formatter=std::make_shared<Formatter>();//构造一个默认的日志格式化对象}if(_sinks.empty())//如果没有落地对象的话就添加一个默认的落地器{buildSink<StdoutSink>();//添加一个标准输出方向的落地器}//到这里东西都有了,那么我们就得进行创建对象的操作了if(_logger_type==LoggerType::LOGGER_ASYNC)//如果类型是异步日志器的话,我们就返回一个异步日志器的对象{return std::make_shared<AsyncLogger>(_logger_name, _limit_level, _formatter, _sinks,_looper_type);//构造一个异步日志器对象并返回}//走到这里就是同步日志器了return std::make_shared<SyncLogger>(_logger_name, _limit_level, _formatter, _sinks); // 构造一个同步日志器对象并返回}private:};
进行一个安全模式的取消
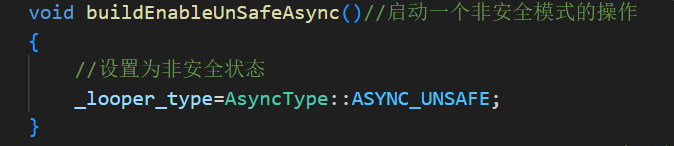
返回对应的日志器

8.9单例日志器管理类设计(单例模式)
⽇志的输出,我们希望能够在任意位置都可以进⾏,但是当我们创建了⼀个⽇志器之后,就会受到⽇志器所在作⽤域的访问属性限制。
因此,为了突破访问区域的限制,我们创建⼀个⽇志器管理类,且这个类是⼀个单例类,这样的话,我们就可以在任意位置来通过管理器单例获取到指定的⽇志器来进⾏⽇志输出了。
基于单例⽇志器管理器的设计思想,我们对于⽇志器建造者类进⾏继承,继承出⼀个全局⽇志器建造者类,实现⼀个⽇志器在创建完毕后,直接将其添加到单例的⽇志器管理器中,以便于能够在任何位置通过⽇志器名称能够获取到指定的⽇志器进⾏⽇志输出
日志器管理器
作用1:对所有创建的日志器进行管理
特性:将管理器设置为单例
作用二:可以在程序的任意位置,获取相同的单例对象,获取其中的日志器进行日志输出
拓展:单例管理器创建的时候,默认先创建一个日志器(用于标准输出的打印)
目的:让用户在不创建任何日志器的情况下,也能进行标准输出的打印,方便用户使用
设计:
管理的成员:
1、默认日志器
2、所管理的日志器数组
3、互斥锁(对数组的操作进行一个保护)
4、提供的接口:
1、添加日志器的管理
2、判断是否管理了指定名称的日志器
3、获取指定名称的日志器
4、获取默认日志器
我们在logger.hpp中进行框架的实现
class LoggerManager//日志器管理器{public://我们这里使用的是懒汉单例模式,对象用的时候再创建,不用就不创建static LoggerManager&getInstance();//获取单例对象void addLogger(Logger::ptr &logger);//添加日志器void hasLogger(const std::string &name);//判断是否存在某个日志器Logger::ptr getLogger(const std::string &name);//通过日志器名称获取日志器Logger::ptr rootLogger();//获取默认日志器private:LoggerManager(){}//构造函数私有化,不允许外部创建对象private:std::mutex _mutex; //日志器管理器的互斥锁Logger::ptr _root_logger;//默认日志器// 日志器名称和日志器对象之间的映射关系std::unordered_map<std::string, Logger::ptr> _loggers; // 日志器的数组};下面是我们实现的代码
class LoggerManager // 日志器管理器{public:// 我们这里使用的是懒汉单例模式,对象用的时候再创建,不用就不创建static LoggerManager &getInstance() // 获取单例对象{static LoggerManager eton; // 定义一个对象,静态局部变量// 在C++11之后,针对静态局部变量,编译器再编译的层面实现了线程安全,保证了单例对象的线程安全// 当静态局部变量没有构造完成之前,其他的线程进入就会阻塞,因为是静态变量,所以所有的线程获取到的都是同一个对象return eton; // 返回单例对象}void addLogger(Logger::ptr &logger) // 添加日志器{if(hasLogger(logger->name()))return ;//如果已经存在这个日志器的话,那么我们就不需要重进行添加了//日志器不存在的话我们就走进来记性日志器的添加操作了std::unique_lock<std::mutex> lock(_mutex); // 对互斥锁进行一个管理操作_loggers.insert(std::make_pair(logger->name(), logger)); // 将日志器添加到日志器数组中}bool hasLogger(const std::string &name) // 判断是否存在某个日志器{std::unique_lock<std::mutex> lock(_mutex); // 对互斥锁进行一个管理操作auto it=_loggers.find(name); // 利用find函数进行查找if(it!=_loggers.end()){return false;//说明没有找到}return true;//找到了}Logger::ptr getLogger(const std::string &name) // 通过日志器名称获取日志器{std::unique_lock<std::mutex> lock(_mutex); // 对互斥锁进行一个管理操作auto it=_loggers.find(name); // 利用find函数进行查找if(it!=_loggers.end()){return Logger::ptr()//说明没有找到,我们返回一个空的智能指针}return it->second;//找到了,就是日志器对象}Logger::ptr rootLogger() // 获取默认日志器{return _root_logger; // 返回默认日志器}private:LoggerManager() // 构造函数私有化,不允许外部创建对象{std::unique_ptr<kaizi::LoggerBuilder> builder(new kaizi::LocalLoggerBuilder());//创建一个日志器构造器对象,让构造器指针进行智能管理builder->buildLoggerName("root"); // 设置日志器名称,其他的信息我们都会默认进行设置操作_root_logger=builder->build(); // 构造默认的日志器对象//默认日志器就是参数只用传个名字就行了,其他的就系统默认就行了,我们不需要设置,让建造者帮我们进行设置就行了_loggers.insert(std::make_pair(_root_logger->name(), _root_logger)); // 将默认日志器添加到日志器数组中}private:std::mutex _mutex; // 日志器管理器的互斥锁Logger::ptr _root_logger; // 默认日志器// 日志器名称和日志器对象之间的映射关系std::unordered_map<std::string, Logger::ptr> _loggers; // 日志器的数组};
设计一个全局日志器的建造者—在局部的基础上增加一个功能:将日志器添加到单例对象中
//设计一个全局日志器的建造者---在局部的基础上增加一个功能:将日志器添加到单例对象中class GlobalLoggerBuilder : public LoggerBuilder{public:// 返回对应的日志器Logger::ptr build() override // 日志器的构建接口{assert(_logger_name.empty() == false); // 必须有日志器名称if (_formatter.get() == nullptr) // 如果是空的话就代表没有日志器{_formatter = std::make_shared<Formatter>(); // 构造一个默认的日志格式化对象}if (_sinks.empty()) // 如果没有落地对象的话就添加一个默认的落地器{buildSink<StdoutSink>(); // 添加一个标准输出方向的落地器}Logger::ptr logger ;//创建一个logger对象// 到这里东西都有了,那么我们就得进行创建对象的操作了if (_logger_type == LoggerType::LOGGER_ASYNC) // 如果类型是异步日志器的话,我们就返回一个异步日志器的对象{logger= std::make_shared<AsyncLogger>(_logger_name, _limit_level, _formatter, _sinks, _looper_type); // 构造一个异步日志器对象并返回}else{logger=std::make_shared<SyncLogger>(_logger_name, _limit_level, _formatter, _sinks);}LoggerManager::getInstance().addLogger(logger); // 将日志器添加到日志器管理器中return logger;}//外界就不用自己去添加了,实例化一个global的建造者对象,然后调用build方法就行了,我们这里就不用实现了,因为我们这里的全局日志器的建造者和局部日志器的建造者是一样的,只是多了一个功能,将日志器添加到单例对象中};
外界就不用自己去添加了,实例化一个global的建造者对象,然后调用build方法就行了,我们这里就不用实现了,因为我们这里的全局日志器的建造者和局部日志器的建造者是一样的,只是多了一个功能,将日志器添加到单例对象中
8.10全局接口设计
提供全局的⽇志器获取接⼝。
使⽤代理模式通过全局函数或宏函数来代理Logger类的log、debug、info、warn、error、fatal等接⼝,以便于控制源码⽂件名称和⾏号的输出控制,简化⽤⼾操作。
当仅需标准输出⽇志的时候可以通过主⽇志器来打印⽇志。 且操作时只需要通过宏函数直接进⾏输出即可。
提供全局接口和宏函数,对日志系统接口进行使用便捷性优化
思想:
1、提供获取指定日志器的全局接口,避免用户自己操作单例对象
2、使用宏函数对日志器接口进行代理(代理模式)简化用户操作,用户不用再去输入文件名和行号的宏了
3、提供宏函数,直接通过默认日志器进行日志的标准输出打印(不用获取日志器了)
#ifndef __KAIZI_H__#define __KAIZI_H__#include "logger.hpp"/*1、提供获取指定日志器的全局接口,避免用户自己操作单例对象2、使用宏函数对日志器接口进行代理(代理模式)简化用户操作,用户不用再去输入文件名和行号的宏了3、提供宏函数,直接通过默认日志器进行日志的标准输出打印(不用获取日志器了)*/namespace kaizi{// 1、提供获取指定日志器的全局接口,避免用户自己操作单例对象Logger::ptr getLogger(const std::string &name) // 获取指定名称的日志器{// 单例对象的获取return kaizi::LoggerManager::getInstance().getLogger(name); // 调用日志器管理器的获取日志器接口}Logger::ptr rootLogger() // 获取默认日志器{return kaizi::LoggerManager::getInstance().rootLogger();}// 2、使用宏函数对日志器接口进行代理(代理模式)简化用户操作,用户不用再去输入文件名和行号的宏了// 用户在使用的时候只需要传入两个参数就行了,自动传入文件名和行号#define debug(fmt, ...) debug(__FILE__, __LINE__, fmt, ##__VA_ARGS__)#define info(fmt, ...) info(__FILE__, __LINE__, fmt, ##__VA_ARGS__)#define warn(fmt, ...) warn(__FILE__, __LINE__, fmt, ##__VA_ARGS__)#define error(fmt, ...) error(__FILE__, __LINE__, fmt, ##__VA_ARGS__)#define fatal(fmt, ...) fatal(__FILE__, __LINE__, fmt, ##__VA_ARGS__)// 3、提供宏函数,直接通过默认日志器进行日志的标准输出打印(不用获取日志器了)// #define DEBUG(logger,fmt, ...) logger->debug(fmt, ##__VA_ARGS__)// #define DLOG(fmt, ...) DEBUG(rootLogger(),fmt, ##__VA_ARGS__)//rootlogger->debug(fmt,...)#define DEBUG(fmt, ...) rootlogger->debug(fmt, ##__VA_ARGS__)#define INFO(fmt, ...) rootlogger->info(fmt, ##__VA_ARGS__)#define WARN(fmt, ...) rootlogger->wanr(fmt, ##__VA_ARGS__)#define ERROR(fmt, ...) rootlogger->error(fmt, ##__VA_ARGS__)#define FATAL(fmt, ...) rootlogger->fatal(fmt, ##__VA_ARGS__)}#endif
用户在使用的时候只需要和下面的样子一样就行了
输入对应的宏,输入格式化字符以及信息就行了
9.项目梳理
我们在使用的时候只需要包含kaizi.h`就行了
10.性能测试
⾯对⽇志系统做⼀个性能测试,测试⼀下平均每秒能打印多少条⽇志消息到⽂件。
1、测试环境
2、测试方法
3、测试结果
主要的测试⽅法是:每秒能打印⽇志数 = 打印⽇志条数 / 总的打印⽇志消耗时间
主要测试要素:同步/异步 & 单线程/多线程
- 100w+条指定⻓度的⽇志输出所耗时间
- 每秒可以输出多少条⽇志
- 每秒可以输出多少MB⽇志
测试环境
- CPU:AMD Ryzen 7 5800H with Radeon Graphics 3.20 GH
- RAM:16G DDR4 3200
- ROM:512G-SSD
- OS:ubuntu-22.04TLS虚拟机(2CPU核⼼/4G内存)
测试工具的编写:
1、可以控制写 日志线程数量(可以控制)
2、可以控制写日志的总数量
3、分别对同步日志器&异步日志器进行格子的性能测试
需要测试单写日志线程的性能
需要测试多写日志线程的性能
实现:
封装一个接口,传入日志器名称,线程数量,日志数量,单条日志大小
在接口内,创建指定数量的线程,各自负责一部分的输出
在输出之前即是开始,在输出完毕后计时结束,
所耗时间=结束时间 -起始时间
每秒输出数量=日志数量/总耗时
每秒输出大小=日志数量 * 单条日志大小/总耗时
注意:异步日志输出这里,我们启动非安全模式,纯内存写入(不去考虑实际落地的时间)
我们这里编写了一个测试的接口
#include"../logs/kaizi.h"#include<vector>#include<thread>#include<chrono>//提供计时的操作//封装一个接口,传入日志器名称,线程数量,日志数量,单条日志大小void bench(const std::string&logger_name,size_t thr_count,size_t msg_count,size_t msg_len){//1、获取日志器kaizi::Logger::ptr logger=kaizi::getLogger(logger_name);if(logger.get()==nullptr)return ;//没有指定的日志器我们就进行退出了std::cout<<"测试日志"<<msg_count<<"条,总大小:"<<(msg_count*msg_len)/1024<<"KB\n"<<std::endl;//2、组织指定长度的日志消息---下面是构建了一条指定长度的字符串std::string msg(msg_len-1,'A');//少一个字节是为了给末尾添加换行//3、创建指定数量的线程std::vector<std::thread> threads;std::vector<double>const_arry(thr_count);size_t msg_per_thr=msg_count/thr_count;//总日志数量除以线程数量就是每个线程输出的日志数量for(int i=0;i<thr_count;i++){//emplace_back是构造并且插入元素到末尾threads.emplace_back([&,i](){//4、线程函数内部开始计时auto start=std::chrono::high_resolution_clock::now();//计时开始//5、开始循环写日志for(int j=0;j<msg_per_thr;j++){logger->fatal("%s",msg.c_str());//进行循环写入操作}//6、线程函数内部结束计时auto end=std::chrono::high_resolution_clock::now();//计时结束auto cost=end-start;//计算耗时//计算并且输出耗时多少秒const_arry[i]=cost.count();std::cout<<"线程"<<i<<":"<<"\t输出数量:"<<msg_per_thr<<"耗时:"<<cost.count()<<"s"<<std::endl;});}for(int i=0;i<thr_count;i++){threads[i].join();//等待所有线程退出}//7、计算总耗时:在多线程中,每个线程都会耗费时间,但是线程是并发处理的,所以耗时最高的那个就是总时间double max_cost=const_arry[0];for(int i=0;i<thr_count;i++)max_cost=max_cost<const_arry[i]?const_arry[i]:max_cost;size_t msg_per_sec=msg_count/max_cost;//每秒耗时size_t size_per_sec=(msg_len*msg_count)/(max_cost*1024);//每秒输出日志大小//8、进行输出打印std::cout<<"每秒输出日志数量:"<<msg_per_sec<<"条\n"<<std::endl;std::cout<<"每秒输出日志大小:"<<size_per_sec<<"KB\n"<<std::endl;}//同步日志测试void sync_bench();//异步日志测试void async_bench();
同步日志器的测试—单线程和多线程
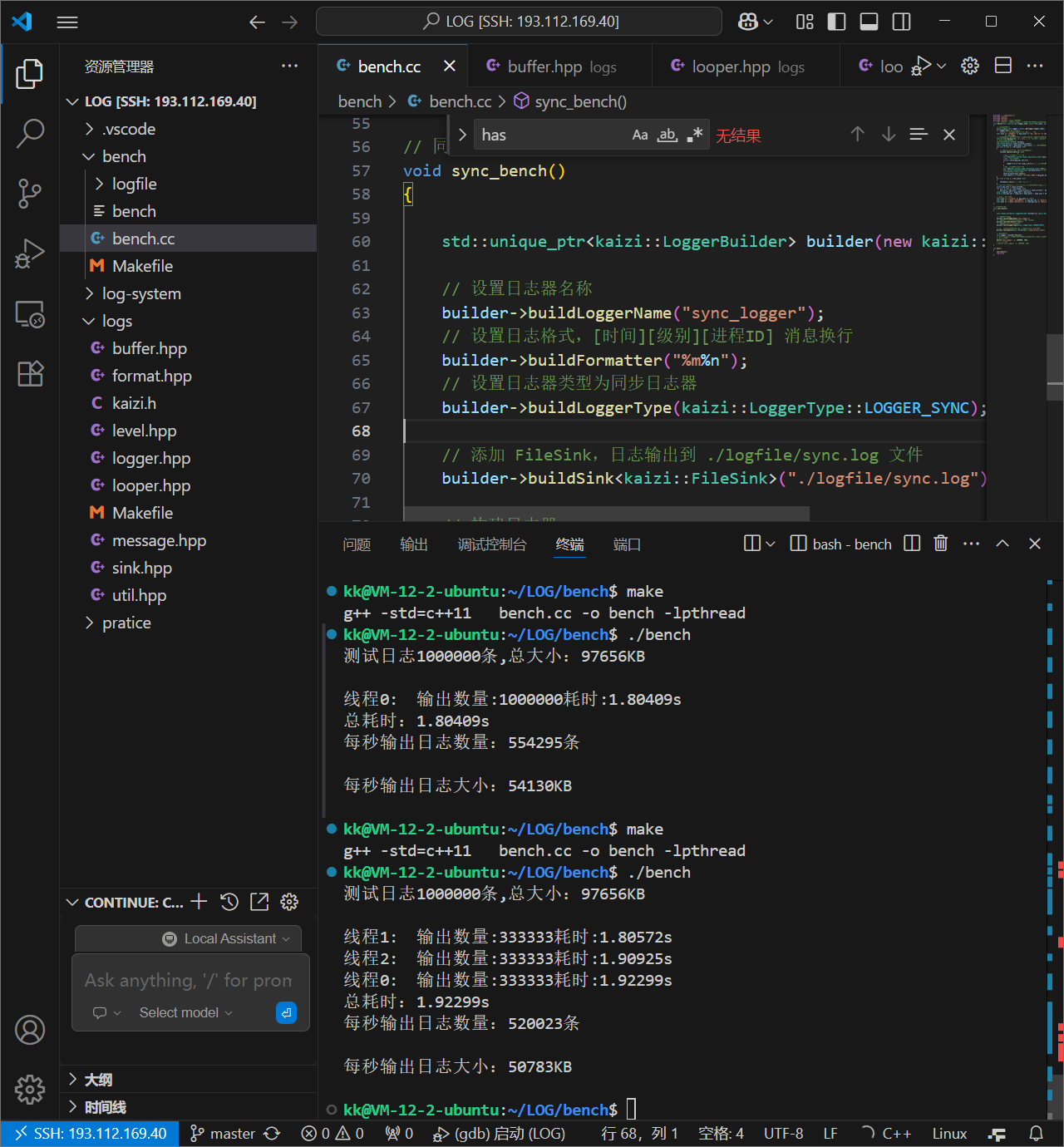
异步日志器下—这里我们还是安全模式,可以看见还没有同步的快
他等实际落地之后才能进行缓冲区的写入操作
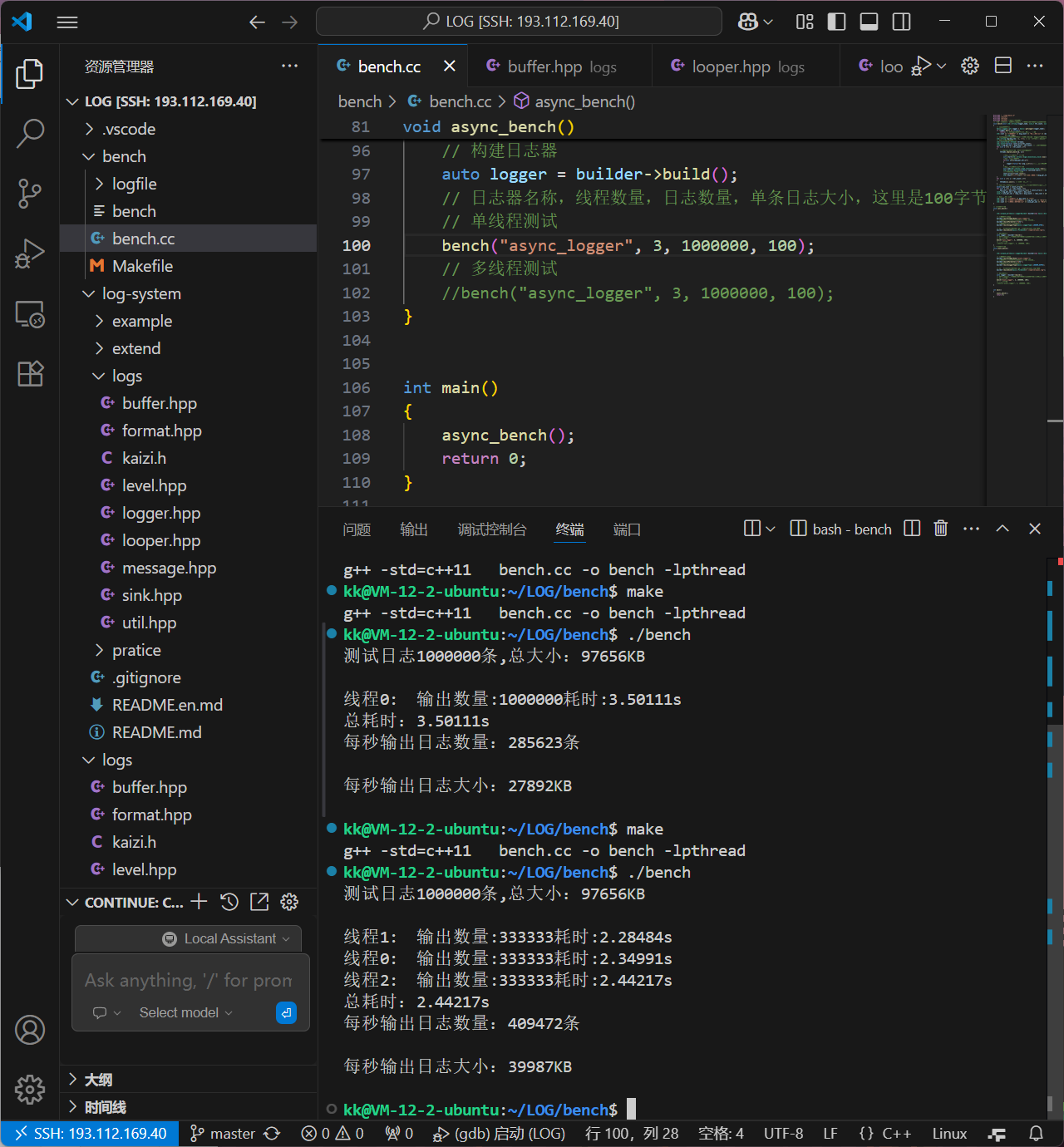
我们将非安全模式打开试试
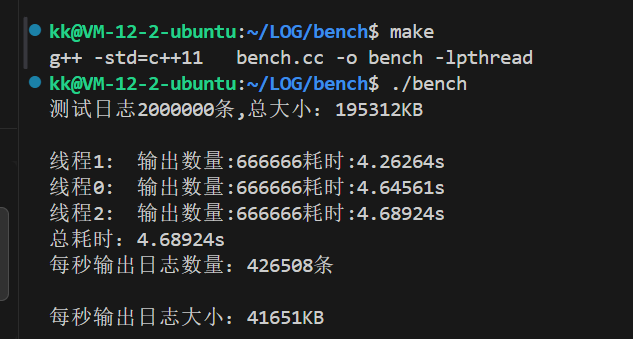
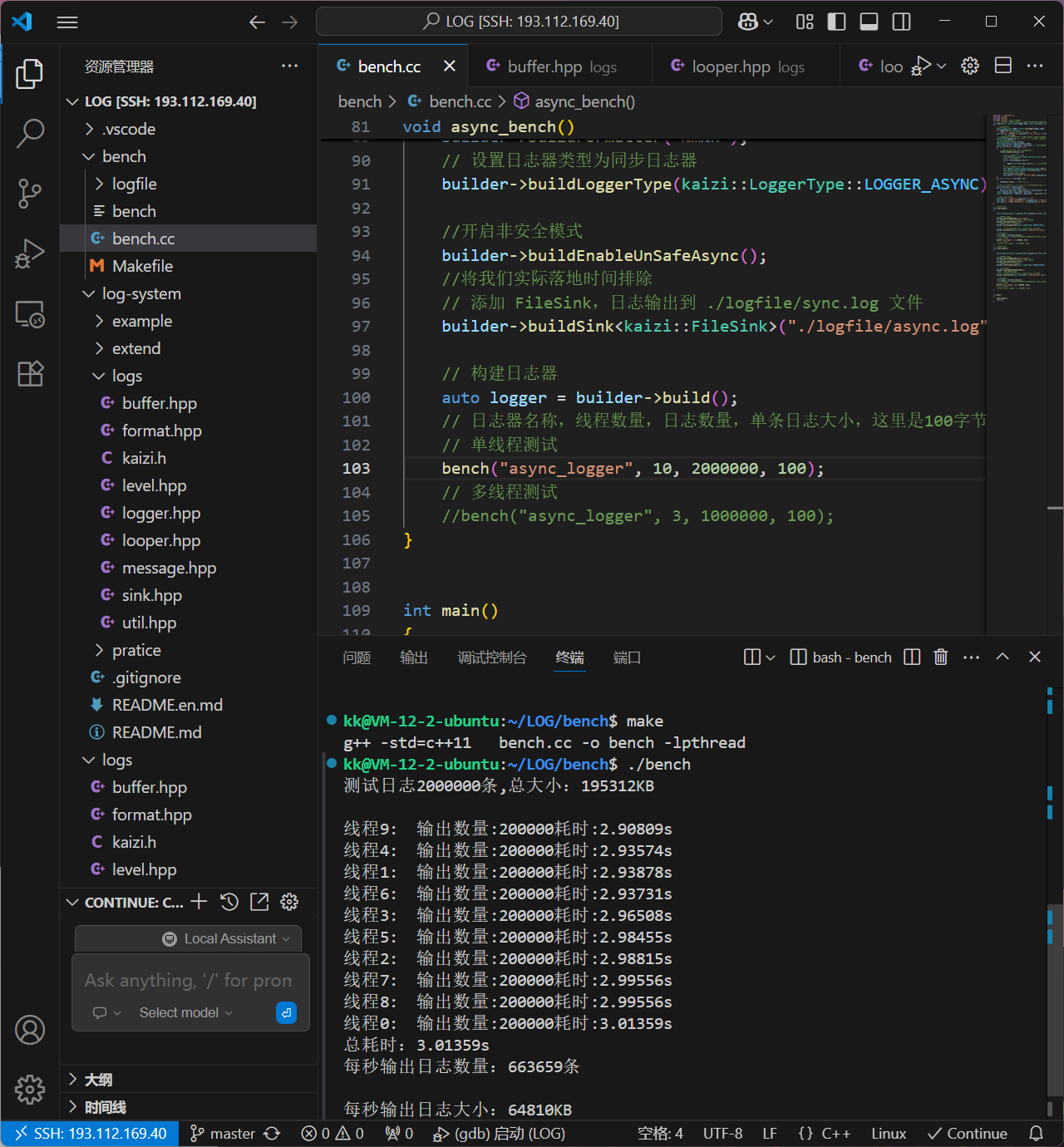
线程越多,速度越快
同步下的单线程/多线程
异步下的单线程/多线程
11、相关代码
bench.h
#include "../logs/kaizi.h"#include <vector>#include <thread>#include <chrono> //提供计时的操作// 封装一个接口,传入日志器名称,线程数量,日志数量,单条日志大小void bench(const std::string &logger_name, size_t thr_count, size_t msg_count, size_t msg_len){// 1、获取日志器kaizi::Logger::ptr logger = kaizi::getLogger(logger_name);if (logger.get() == nullptr)return; // 没有指定的日志器我们就进行退出了std::cout << "测试日志" << msg_count << "条,总大小:" << (msg_count * msg_len) / 1024 << "KB\n"<< std::endl;// 2、组织指定长度的日志消息---下面是构建了一条指定长度的字符串std::string msg(msg_len - 1, 'A'); // 少一个字节是为了给末尾添加换行// 3、创建指定数量的线程std::vector<std::thread> threads;std::vector<double> const_arry(thr_count);size_t msg_per_thr = msg_count / thr_count; // 总日志数量除以线程数量就是每个线程输出的日志数量for (int i = 0; i < thr_count; i++){// emplace_back是构造并且插入元素到末尾threads.emplace_back([&, i](){//4、线程函数内部开始计时auto start=std::chrono::high_resolution_clock::now();//计时开始//5、开始循环写日志for(int j=0;j<msg_per_thr;j++){logger->fatal("%s",msg.c_str());//进行循环写入操作}//6、线程函数内部结束计时auto end=std::chrono::high_resolution_clock::now();//计时结束std::chrono::duration<double> cost=end-start;//计算耗时//计算并且输出耗时多少秒const_arry[i]=cost.count();std::cout<<"线程"<<i<<":"<<"\t输出数量:"<<msg_per_thr<<"耗时:"<<cost.count()<<"s"<<std::endl; });}for (int i = 0; i < thr_count; i++){threads[i].join(); // 等待所有线程退出}// 7、计算总耗时:在多线程中,每个线程都会耗费时间,但是线程是并发处理的,所以耗时最高的那个就是总时间double max_cost = const_arry[0];for (int i = 0; i < thr_count; i++)max_cost = max_cost < const_arry[i] ? const_arry[i] : max_cost;size_t msg_per_sec = msg_count / max_cost; // 每秒耗时size_t size_per_sec = (msg_len * msg_count) / (max_cost * 1024); // 每秒输出日志大小// 8、进行输出打印std::cout << "总耗时:" << max_cost << "s\n";std::cout << "每秒输出日志数量:" << msg_per_sec << "条\n"<< std::endl;std::cout << "每秒输出日志大小:" << size_per_sec << "KB\n"<< std::endl;}// 同步日志测试void sync_bench(){std::unique_ptr<kaizi::LoggerBuilder> builder(new kaizi::GlobalLoggerBuilder());// 设置日志器名称builder->buildLoggerName("sync_logger");// 设置日志格式,[时间][级别][进程ID] 消息换行builder->buildFormatter("%m%n");// 设置日志器类型为同步日志器builder->buildLoggerType(kaizi::LoggerType::LOGGER_SYNC);// 添加 FileSink,日志输出到 ./logfile/sync.log 文件builder->buildSink<kaizi::FileSink>("./logfile/sync.log");// 构建日志器auto logger = builder->build();// 日志器名称,线程数量,日志数量,单条日志大小,这里是100字节大小// 单线程测试bench("sync_logger", 3, 1000000, 100);// 多线程测试//bench("sync_logger", 3, 1000000, 100);}// 异步日志测试void async_bench(){std::unique_ptr<kaizi::LoggerBuilder> builder(new kaizi::GlobalLoggerBuilder());// 设置日志器名称builder->buildLoggerName("async_logger");// 设置日志格式,[时间][级别][进程ID] 消息换行builder->buildFormatter("%m%n");// 设置日志器类型为同步日志器builder->buildLoggerType(kaizi::LoggerType::LOGGER_ASYNC);//开启非安全模式builder->buildEnableUnSafeAsync();//将我们实际落地时间排除// 添加 FileSink,日志输出到 ./logfile/sync.log 文件builder->buildSink<kaizi::FileSink>("./logfile/async.log");// 构建日志器auto logger = builder->build();// 日志器名称,线程数量,日志数量,单条日志大小,这里是100字节大小// 单线程测试bench("async_logger", 10, 2000000, 100);// 多线程测试//bench("async_logger", 3, 1000000, 100);}int main(){async_bench();return 0;}
buffer.hpp
/*实现异步日志缓冲区*/#ifndef __BUFFER_HPP__#define __BUFFER_HPP__#include<vector>#include"util.hpp"#include<cassert>namespace kaizi{#define DEFAULT_BUFFER_SIZE (1024*1024*10) // 默认缓冲区大小为10M#define THRESHOLD_BUFFER_SIZE (1024*1024*80)//阈值#define INCREMENT_BUFFER_SIZE (1024*1024*10)//增值class Buffer{public:Buffer():_buffer(DEFAULT_BUFFER_SIZE),_reader_idx(0),_writer_idx(0)//默认大小和两个读写指针{}//向缓冲区中写入数据void push(const char*data,size_t len){//缓冲区剩余空间不够的情况,1、扩容 2、阻塞/返回false//先检测空间大小//1、固定大小,则直接返回//if(len>writeAbleSize())return ;//2、动态空间,用于极限性能测试---扩容ensureEnoughSize(len);//进行内存扩充操作,先进行判断,再决定扩容的方式//1、将数据拷贝到缓冲区std::copy(data,data+len,&_buffer[_writer_idx]);//将从data开始长度为len个字节的数据拷贝到_buffer缓冲区此时的_write_idx位置//2、将当前写入位置向后偏移moveWriter(len);//写入位置向后进行偏移len位}size_t writeAbleSize(){//对于扩容思路,不存在可写空间大小,因为总是可写//因此这个接口仅仅针对固定大小缓冲区提供return _buffer.size()-_writer_idx;//总大小-可写入的起始地址=剩余可写地址}//获取可读数据起始地址const char* begin(){return &_buffer[_reader_idx];//将读地址传过去就行了}//返回可读数据长度size_t readAbleSize(){//两个指针中间的就是我们实际的数据长度了,因为当前缓冲区并不是循环缓冲区,因此只会向后写//当前缓冲区的思想是双缓冲区的思想return _writer_idx-_reader_idx;//可读数据长度=可写数据长度-读数据长度}//对读写指针向后偏移操作void moveReader(size_t len)//可读空间大小{assert(len<=readAbleSize());//偏移的长度len必须小于可读数据的长度_reader_idx+=len;//进行偏移擦操作}//重置读写位置,初始化缓冲区void reset(){//将两个指针的位置都重置为0,表示此时缓冲区内的空间都是空闲空间//两个指针相等,表示没有数据可读_reader_idx=0;_writer_idx=0;}//对buffer进行交换操作,两个缓存区进行交换void swap( Buffer&buffer){//将两个buffer的读写地址进行交换,将缓冲区里面的空间地址进行交换_buffer.swap(buffer._buffer);std::swap(_reader_idx,buffer._reader_idx);std::swap(_writer_idx,buffer._writer_idx);}//判断缓冲区是否为空bool empty(){return (_reader_idx==_writer_idx);//两个指针相等,表示没有数据可读}private://对空间进行扩容操作void ensureEnoughSize(size_t len)//内存下小于80MB的进行线性增长,一次+10,如果大于的话就进行翻倍增长{if(len<=writeAbleSize())return ;//不需要扩容的情况size_t new_size=0;if(_buffer.size()<THRESHOLD_BUFFER_SIZE)//小于阈值的话则进行翻倍增长操作{//小于阈值的话则进行翻倍增长操作new_size=_buffer.size()*2+len;}else//大于等于阈值大小的话{new_size=_buffer.size()+INCREMENT_BUFFER_SIZE+len;//线性增长,一次增加10MB}_buffer.resize(new_size);//对缓冲区进行调整大小,调整为新的大小}//对读写指针向后偏移操作void moveWriter(size_t len){assert(len+_writer_idx<=_buffer.size());//偏移的长度len必须整个缓冲区的长度_writer_idx+=len;//进行偏移擦操作}private:std::vector<char>_buffer;//缓冲区使用vector进行管理size_t _reader_idx;//当前可读数据的指针,本质是下标size_t _writer_idx;//当前可写数据的指针,本质是下标};}#endif
format.hpp
#ifndef __M_FMT_H__#define __M_FMT_H__#include "level.hpp"#include "message.hpp"#include <memory>#include <ctime>#include <vector>#include<cassert>#include<sstream>// 格式化子项类namespace kaizi{// 1、抽象格式化子项基类class FormatItem{public:using ptr = std::shared_ptr<FormatItem>; // 对FormatItem进行智能管理virtual void format(std::ostream &out, const LogMsg &msg) = 0; // 纯虚函数};// 2、派生格式化子项子类---消息、等级、时间、文件名、行号、线程ID、日志器名称、制表符、换行、其他class MsgFormatItem : public FormatItem // 消息主体{public:void format(std::ostream &out, const LogMsg &msg) override{out << msg._payload;}};class levelFormatItem : public FormatItem // 日志等级{public:void format(std::ostream &out, const LogMsg &msg) override{out << LogLevel::toString(msg._level); // 利用之前写的日志等级代码进行日志等级的转换然后将转换后的结果输出进去}};class TimeFormatItem : public FormatItem // 格式化日志中的时间{public:TimeFormatItem(const std::string &fmt = "%H:%M:%S") // 构造函数,把传入的格式化字符串赋值给私有成员变量 _time_fmt: _time_fmt(fmt){}void format(std::ostream &out, const LogMsg &msg) override{// tm 是 C/C++ 标准库的时间结构体// 先定义一个 tm 结构体变量 t ,tm 结构体用于存储分解后的时间信息struct tm t;// 把 msg._ctime 里的时间戳转换成本地时间,并填充到 tm 结构体 t 中。localtime_r(&msg._ctime, &t);// 定义一个字符数组 tmp,用来存储最终格式化的时间字符串char tmp[32] = {0};// strftime 是时间格式化核心函数,按规则把 tm 结构体的时间转成字符串strftime(tmp, 31, _time_fmt.c_str(), &t);// 把格式化好的时间字符串(存在 tmp),输出到日志流 ouout << tmp; // 输出日志的时间}private:std::string _time_fmt; //%H:%M:%S};class FileFormatItem : public FormatItem // 文件名{public:void format(std::ostream &out, const LogMsg &msg) override{out << msg._file; // 直接取出文件名添加进去就行了}};class LineFormatItem : public FormatItem // 行号{public:void format(std::ostream &out, const LogMsg &msg) override{out << msg._line; // 直接取出一个数字就行了}};class ThreadFormatItem : public FormatItem // 线程ID{public:void format(std::ostream &out, const LogMsg &msg) override{out << msg._tid; // 直接取出线程ID就行了}};class LoggerFormatItem : public FormatItem // 日志器名称{public:void format(std::ostream &out, const LogMsg &msg) override{out << msg._logger; // 直接取出日志器名称就行了}};class TabFormatItem : public FormatItem // 制表符{public:void format(std::ostream &out, const LogMsg &msg) override{out << "\t";}};class NLineFormatItem : public FormatItem // 换行{public:void format(std::ostream &out, const LogMsg &msg) override{out << "\n";}};// abcdefg[%d{%H}] 这里的话abcdefg[就属于其他字符串了class OtherFormatItem : public FormatItem // 其他{public:OtherFormatItem(const std::string &str) // 构造函数,把传入的字符串赋值给私有成员变量 _str: _str(str){}void format(std::ostream &out,const LogMsg &msg) override{out << _str;}private:std::string _str; // 原始字符串};/*%d表示日期,包含子格式{%H:%M:%S}%t表示线程ID%c表示日志器名称%f表示文件名%l表示行号%p表示日志级别%T是制表符缩进%m表示消息主体%n表示换行符*///将用户提供的格式字符串(如 [%d{%H:%M:%S}][%t][%c]...)解析为一系列 FormatItem 对象。class Formatter{public:using ptr=std::shared_ptr<Formatter>; // 对Formatter进行智能管理Formatter(const std::string &pattren = "[%d{%H:%M:%S}][%t][%c][%f:%l][%p]%T%m%n"): _pattern(pattren){assert(parsePattern());//断言格式化必须成功}//下面两行代码是对msg进行格式化void format(std::ostream &out, const LogMsg &msg)//format重载,将消息放到io流中,我们对IO流进行处理操作{//逐个遍历_items,从消息中取出内容进行一个format。得到一个数据就放到ostream中for(auto &item:_items)//遍历 _items 容器,_items 里存的是各种 FormatItem 子类的智能指针{//调用每个 FormatItem 子类重写的 format 方法,把 msg 里的对应数据//按照该子类的规则格式化后,输出到 out 流里item->format(out,msg);//这个format是基类的虚函数,我们在派生类中实现,这里我们直接调用基类的实现}}std::string format(const LogMsg &msg) // 对这条消息进行格式化操作,返回格式化后的字符串{//创建一个 stringstream,它是内存中的流,用来临时存储格式化后的日志内容。std::stringstream ss;format(ss,msg);//调用上面的接口,将日志内容格式化后输出到ss这个内存流中return ss.str(); // 返回格式化后的字符串}private://对格式化规则字符串进行解析bool parsePattern() // 解析格式化规则字符串,将其解析成格式化子项数组{//1.对格式化规则字符串进行解析std::vector<std::pair<std::string,std::string>> fmt_order; // 定义一个字符串数组,用来存储解析后的格式化子项size_t pos=0;std::string key,val;while(pos<_pattern.size()){//1. 处理原始字符串---判断是不是%,不是就是原始字符if(_pattern[pos]!='%'){// 不是%,直接输出原始字符val.push_back(_pattern[pos++]);//然后就是pos++继续往后面走了continue;}//能到这里说明pos位置就是%的,那么我们就得判断pos后面是不是%了,%%处理成为一个原始%字符if(pos+1<_pattern.size() && _pattern[pos+1]=='%')//说明是两个%{val.push_back('%');pos+=2;//往后面走两步,越过这两个%continue;}//这个时候代表我们原始字符串处理完毕if(val.empty()==false)//不为空的情况下{fmt_order.push_back(std::make_pair("",val)); // 加入到格式化子项数组中val.clear(); // 清空val}//这个时候是格式化字符的处理pos+=1;//往后面走一步,跳过%//走到了这里说明不是一个原始字符,说明后面是格式化字符了if(pos==_pattern.size())//如果pos已经到末尾了,说明格式化字符串格式不对{std::cout<<"%之后没有格式化字符"<<std::endl;return false;}key=_pattern[pos];//取出%pos+=1;//往后面走一步,跳过%//这个时候,pos指向格式化字符后的位置,//如果这个位置是{,说明后面还有子格式化字符串if(pos<_pattern.size()&&_pattern[pos]=='{'){pos+=1;//这个时候pos指向子格式化字符串的开始位置while(pos<_pattern.size()&&_pattern[pos]!='}'){val.push_back(_pattern[pos++]);}//走到了末尾跳出循环,没有遇到},说明格式化字符串格式不对if(pos==_pattern.size())//走到末尾了,都没找到},说明格式化字符串格式不对{std::cout<<"子规则花括号匹配错误"<<std::endl;return false;}pos+=1;//因为这个时候pos指向了},所以pos+1,跳过}//向后走一步,走到下次处理的新位置}fmt_order.push_back(std::make_pair(key,val)); // 加入到格式化子项数组中key.clear(); // 清空keyval.clear(); // 清空val//两个内容都进行清空操作,进行下一轮循环操作}//到这里我们就得到了处理结果了,我们就得进行解析了结果了//2.根据解析得到的数据初始化子项数组成员for(auto &it:fmt_order)//fmt_order是上面while循环的处理结果。我们进行遍历操作{//fmt_order是一个pair类型的,我们上面结束函数结束的时候是将(key,val)插入到里面了//我们这里遍历了fmt_order中的每一个pair类型进行子项对象的创建,并且插入到items数组中//并且我们在创建子项对象的时候,都返回了对应的数据了,然后将数据存储在items中,最后就是我们的日志了//往这个指针数组中加入对应的格式化子项对象_items.push_back(createItem(it.first,it.second)); // 根据格式化子项的类型字符串,创建对应的格式化子项对象,并加入到 _items 容器中}return true;}//根据不同的格式化字符创建不同的格式化子项对象FormatItem::ptr createItem(const std::string &key,const std::string &val) // 根据格式化子项的类型字符串,创建对应的格式化子项对象,并返回智能指针{/*%d表示日期,包含子格式{%H:%M:%S}%t表示线程ID%c表示日志器名称%f表示文件名%l表示行号%p表示日志级别%T是制表符缩进%m表示消息主体%n表示换行符*/if(key == "d") return std::make_shared<TimeFormatItem>(val);// 如果是日期格式化子项if(key == "t") return std::make_shared<ThreadFormatItem>();// 如果是线程ID格式化子项if(key == "c") return std::make_shared<LoggerFormatItem>();// 如果是日志器名称格式化子项if(key == "f") return std::make_shared<FileFormatItem>();// 如果是文件名格式化子项if(key == "l") return std::make_shared<LineFormatItem>();// 如果是行号格式化子项if(key == "p") return std::make_shared<levelFormatItem>();// 如果是日志级别格式化子项if(key == "T") return std::make_shared<TabFormatItem>();// 如果是制表符格式化子项if(key == "m") return std::make_shared<MsgFormatItem>();// 如果是消息主体格式化子项if(key == "n") return std::make_shared<NLineFormatItem>();// 如果是换行符格式化子项if(key=="")// 如果是空字符串,说明是其他格式化子项{return std::make_shared<OtherFormatItem>(val);// 如果是其他格式化子项}std::cout<<"没有对应的格式化字符:%"<<key<<std::endl;abort();//程序异常退出处理return FormatItem::ptr();//空对象指针}private:std::string _pattern; // 格式化规则字符串std::vector<FormatItem::ptr> _items; // 这个容器中的类型是智能指针 ,存储的是格式化子项的智能指针/*对这个子项数组按顺序的从我们的消息中取出对应的内容逐个遍历_items,从消息中取出内容进行一个format。得到一个数据就放到ostream中*/};}#endif
kaizi.h
#ifndef __KAIZI_H__#define __KAIZI_H__#include "logger.hpp"/*1、提供获取指定日志器的全局接口,避免用户自己操作单例对象2、使用宏函数对日志器接口进行代理(代理模式)简化用户操作,用户不用再去输入文件名和行号的宏了3、提供宏函数,直接通过默认日志器进行日志的标准输出打印(不用获取日志器了)*/namespace kaizi{// 1、提供获取指定日志器的全局接口,避免用户自己操作单例对象Logger::ptr getLogger(const std::string &name) // 获取指定名称的日志器{// 单例对象的获取return kaizi::LoggerManager::getInstance().getLogger(name); // 调用日志器管理器的获取日志器接口}Logger::ptr rootLogger() // 获取默认日志器{return kaizi::LoggerManager::getInstance().rootLogger();}// 2、使用宏函数对日志器接口进行代理(代理模式)简化用户操作,用户不用再去输入文件名和行号的宏了// 用户在使用的时候只需要传入两个参数就行了,自动传入文件名和行号#define debug(fmt, ...) debug(__FILE__, __LINE__, fmt, ##__VA_ARGS__)#define info(fmt, ...) info(__FILE__, __LINE__, fmt, ##__VA_ARGS__)#define warn(fmt, ...) warn(__FILE__, __LINE__, fmt, ##__VA_ARGS__)#define error(fmt, ...) error(__FILE__, __LINE__, fmt, ##__VA_ARGS__)#define fatal(fmt, ...) fatal(__FILE__, __LINE__, fmt, ##__VA_ARGS__)// 3、提供宏函数,直接通过默认日志器进行日志的标准输出打印(不用获取日志器了)// #define DEBUG(logger,fmt, ...) logger->debug(fmt, ##__VA_ARGS__)// #define DLOG(fmt, ...) DEBUG(rootLogger(),fmt, ##__VA_ARGS__)//rootlogger->debug(fmt,...)#define DEBUG(fmt, ...) kaizi::rootLogger()->debug(fmt, ##__VA_ARGS__)#define INFO(fmt, ...) kaizi::rootLogger()->info(fmt, ##__VA_ARGS__)#define WARN(fmt, ...) kaizi::rootLogger()->wanr(fmt, ##__VA_ARGS__)#define ERROR(fmt, ...) kaizi::rootLogger()->error(fmt, ##__VA_ARGS__)#define FATAL(fmt, ...) kaizi::rootLogger()->fatal(fmt, ##__VA_ARGS__)}#endif
level.hpp
/*1.定义枚举类,枚举出日志等级2,提供转换接口:将枚举转换为对应字符串*/#ifndef __M_LEVEL_H__#define __M_LEVEL_H__namespace kaizi{class LogLevel{public:enum class value{UNKONW=0,DEBUG,INFO,WARN,ERROR,FATAL,OFF};static const char*toString(LogLevel::value level)//传入一个具体日志等级的值,根据level进行转换{switch(level){case LogLevel::value::DEBUG:return "DEBUG";case LogLevel::value::INFO:return "INFO";case LogLevel::value::WARN:return "WARN";case LogLevel::value::ERROR:return "ERROR";case LogLevel::value::FATAL:return "FATAL";case LogLevel::value::OFF:return "OFF";}//如果里面都不是的话,那么直接返回一个UNKONW就行了return "UNKONW";}};}#endif
logger.hpp
/*完成日志器模块1、抽象日志器基类2、派生出不同的子类(同步日志器类&异步日志器类)*/#ifndef __M_LOGGER_H__#define __M_LOGGER_H__#ifndef _GNU_SOURCE#define _GNU_SOURCE#endif#include "util.hpp"#include "level.hpp"#include "format.hpp"#include "sink.hpp"#include <atomic>#include <mutex>#include <cstdarg>#include "looper.hpp"#include "unordered_map"namespace kaizi{// 同步日志器,对多个落地方向进行数据的写入操作class Logger{public:using ptr = std::shared_ptr<Logger>; // 智能指针进行类对象的管理// 构造函数Logger(const std::string &logger_name, // 日志器名称LogLevel::value level, // 日志限制等级Formatter::ptr &formatter, // 日志格式化对象std::vector<LogSink::ptr> &sinks) // 日志落地对象,我们将数组传递进来进行初始化操作: _logger_name(logger_name), _limit_level(level), _formatter(formatter), _sinks(sinks.begin(), sinks.end()){}// 返回日志器名称const std::string &name() // 避免未接对名称进行修改的操作{return _logger_name;}// 完成构造日志消息对象过程并进行格式化,得到格式化后的日志消息字符串,然后进行落地输出void debug(const std::string &file, size_t line, const std::string &fmt, ...) // 根据fmt取出后面的不定参数据,组成一个LogMsg对象,然后调用_log接口进行日志记录{// 按日志等级判断是否输出,将 fmt 和可变参数拼接成完整日志,最终调用 _log 落地// 通过传入的参数构造一个日志消息对象,进行日志的格式化操作,进行落地// 1、判断当前的日志是否到达了输出等级if (LogLevel::value::DEBUG < _limit_level) // 不能进行输出操作{return;}// 2、对fmt格式化字符串和不定参进行字符串组织,得到的日志消息的字符串va_list ap; // 定义可变参数列表容器,用于存储、遍历可变参数。va_start(ap, fmt); // 获取指定参数的起始地址,这里就是获取fmt参数后第一个参数的起始地址,就是...char *res; // 定义一个空间指针,后面会将格式化的结果存在这个指针中的int ret = vasprintf(&res, fmt.c_str(), ap); // 按 fmt 的格式(如 "%d %s" ),把 ap 里的可变参数拼接成完整 C 字符串,存入 res 指向的内存if (ret == -1) // 格式化组织失败了{std::cout << "vasprintf failed!\n";return;}va_end(ap); // 释放 ap 相关资源,避免内存问题serialize(LogLevel::value::DEBUG, file, line, res); // 调用日志器基类的serialize接口进行日志的格式化操作,并进行日志的落地free(res); // 释放res指针指向的内存空间}void info(const std::string &file, size_t line, const std::string &fmt, ...) // 根据fmt取出后面的不定参数据,组成一个LogMsg对象,然后调用_log接口进行日志记录{// 按日志等级判断是否输出,将 fmt 和可变参数拼接成完整日志,最终调用 _log 落地// 通过传入的参数构造一个日志消息对象,进行日志的格式化操作,进行落地// 1、判断当前的日志是否到达了输出等级if (LogLevel::value::INFO < _limit_level) // 不能进行输出操作{return;}// 2、对fmt格式化字符串和不定参进行字符串组织,得到的日志消息的字符串va_list ap; // 定义可变参数列表容器,用于存储、遍历可变参数。va_start(ap, fmt); // 获取指定参数的起始地址,这里就是获取fmt参数后第一个参数的起始地址,就是...char *res; // 定义一个空间指针,后面会将格式化的结果存在这个指针中的int ret = vasprintf(&res, fmt.c_str(), ap); // 按 fmt 的格式(如 "%d %s" ),把 ap 里的可变参数拼接成完整 C 字符串,存入 res 指向的内存if (ret == -1) // 格式化组织失败了{std::cout << "vasprintf failed!\n";return;}va_end(ap); // 释放 ap 相关资源,避免内存问题serialize(LogLevel::value::INFO, file, line, res); // 调用日志器基类的serialize接口进行日志的格式化操作,并进行日志的落地free(res); // 释放res指针指向的内存空间}void warn(const std::string &file, size_t line, const std::string &fmt, ...) // 根据fmt取出后面的不定参数据,组成一个LogMsg对象,然后调用_log接口进行日志记录{// 按日志等级判断是否输出,将 fmt 和可变参数拼接成完整日志,最终调用 _log 落地// 通过传入的参数构造一个日志消息对象,进行日志的格式化操作,进行落地// 1、判断当前的日志是否到达了输出等级if (LogLevel::value::WARN < _limit_level) // 不能进行输出操作{return;}// 2、对fmt格式化字符串和不定参进行字符串组织,得到的日志消息的字符串va_list ap; // 定义可变参数列表容器,用于存储、遍历可变参数。va_start(ap, fmt); // 获取指定参数的起始地址,这里就是获取fmt参数后第一个参数的起始地址,就是...char *res; // 定义一个空间指针,后面会将格式化的结果存在这个指针中的int ret = vasprintf(&res, fmt.c_str(), ap); // 按 fmt 的格式(如 "%d %s" ),把 ap 里的可变参数拼接成完整 C 字符串,存入 res 指向的内存if (ret == -1) // 格式化组织失败了{std::cout << "vasprintf failed!\n";return;}va_end(ap); // 释放 ap 相关资源,避免内存问题serialize(LogLevel::value::WARN, file, line, res); // 调用日志器基类的serialize接口进行日志的格式化操作,并进行日志的落地free(res); // 释放res指针指向的内存空间}void error(const std::string &file, size_t line, const std::string &fmt, ...) // 根据fmt取出后面的不定参数据,组成一个LogMsg对象,然后调用_log接口进行日志记录{// 按日志等级判断是否输出,将 fmt 和可变参数拼接成完整日志,最终调用 _log 落地// 通过传入的参数构造一个日志消息对象,进行日志的格式化操作,进行落地// 1、判断当前的日志是否到达了输出等级if (LogLevel::value::ERROR < _limit_level) // 不能进行输出操作{return;}// 2、对fmt格式化字符串和不定参进行字符串组织,得到的日志消息的字符串va_list ap; // 定义可变参数列表容器,用于存储、遍历可变参数。va_start(ap, fmt); // 获取指定参数的起始地址,这里就是获取fmt参数后第一个参数的起始地址,就是...char *res; // 定义一个空间指针,后面会将格式化的结果存在这个指针中的int ret = vasprintf(&res, fmt.c_str(), ap); // 按 fmt 的格式(如 "%d %s" ),把 ap 里的可变参数拼接成完整 C 字符串,存入 res 指向的内存if (ret == -1) // 格式化组织失败了{std::cout << "vasprintf failed!\n";return;}va_end(ap); // 释放 ap 相关资源,避免内存问题serialize(LogLevel::value::ERROR, file, line, res); // 调用日志器基类的serialize接口进行日志的格式化操作,并进行日志的落地free(res); // 释放res指针指向的内存空间}void fatal(const std::string &file, size_t line, const std::string &fmt, ...) // 根据fmt取出后面的不定参数据,组成一个LogMsg对象,然后调用_log接口进行日志记录{// 按日志等级判断是否输出,将 fmt 和可变参数拼接成完整日志,最终调用 _log 落地// 通过传入的参数构造一个日志消息对象,进行日志的格式化操作,进行落地// 1、判断当前的日志是否到达了输出等级if (LogLevel::value::FATAL < _limit_level) // 不能进行输出操作{return;}// 2、对fmt格式化字符串和不定参进行字符串组织,得到的日志消息的字符串va_list ap; // 定义可变参数列表容器,用于存储、遍历可变参数。va_start(ap, fmt); // 获取指定参数的起始地址,这里就是获取fmt参数后第一个参数的起始地址,就是...char *res; // 定义一个空间指针,后面会将格式化的结果存在这个指针中的int ret = vasprintf(&res, fmt.c_str(), ap); // 按 fmt 的格式(如 "%d %s" ),把 ap 里的可变参数拼接成完整 C 字符串,存入 res 指向的内存if (ret == -1) // 格式化组织失败了{std::cout << "vasprintf failed!\n";return;}va_end(ap); // 释放 ap 相关资源,避免内存问题serialize(LogLevel::value::FATAL, file, line, res); // 调用日志器基类的serialize接口进行日志的格式化操作,并进行日志的落地free(res); // 释放res指针指向的内存空间}protected:void serialize(LogLevel::value level, const std::string &file, size_t line, char *str) // 对下面的操作进行了一个封装操作,因为每种等级里面的这个代码都是相同的{// 3、构造LogMsg日志消息类对象LogMsg msg(level, line, file, _logger_name, str); // 构造一个日志消息对象,并进行日志的格式化操作// 4、通过格式化工具对LogMsg对象进行格式化,得到格式化后的日志字符串std::stringstream ss; // 定义一个字符串流类对象_formatter->format(ss, msg); // 调用日志格式化对象进行格式化操作,将日志内容格式化后输出到ss这个内存流中// 5、日志落地log(ss.str().c_str(), ss.str().size()); // 调用日志器基类的log接口进行日志落地}// 抽象的接口完成实际的落地输出---不同的日志器会有不同的实际落地方式virtual void log(const char *data, size_t len) = 0;protected:std::mutex _mutex; // 日志器的互斥锁std::string _logger_name; // 日志器名称// 如果下面的等级进行加锁保护的话锁冲突比较多,因为这个日志等级调用的比较频繁std::atomic<LogLevel::value> _limit_level; // 日志等级,定义为原子类型的成员,就能保证在多线程里面的原子访问了Formatter::ptr _formatter; // 日志格式化对象std::vector<LogSink::ptr> _sinks; // 日志落地对象数组,可能存在多个落地方向,所以使用vector+智能指针进行管理};// 同步日志器class SyncLogger : public Logger{public:SyncLogger(const std::string &logger_name, // 日志器名称LogLevel::value level, // 日志限制等级Formatter::ptr &formatter, // 日志格式化对象std::vector<LogSink::ptr> &sinks) // 日志落地对象,我们将数组传递进来进行初始化操作: Logger(logger_name, level, formatter, sinks) // 使用抽象基类进行一个实例化操作{}protected:// 同步日志器,是将日志直接通过落地模块句柄进行日志落地void log(const char *data, size_t len){// 它通过 RAII 机制确保锁的正确获取和释放,避免死锁问题// 同时提供了比 std::lock_guard 更灵活的锁管理方式std::unique_lock<std::mutex> lock(_mutex); // 自动进行加锁,等lock释放了锁会自动进行解锁的if (_sinks.empty())return; // 如果这个落地对象数组是空的,那么我们直接返回了for (auto &sink : _sinks) // 遍历日志落地对象数组{sink->log(data, len); // 逐个调用 sink 的 log 方法,把日志数据输出到不同目标}}};// 异步日志器class AsyncLogger : public Logger{public:AsyncLogger(const std::string &logger_name, // 日志器名称LogLevel::value level, // 日志限制等级Formatter::ptr &formatter, // 日志格式化对象std::vector<LogSink::ptr> &sinks, // 日志落地对象,我们将数组传递进来进行初始化操作AsyncType _looper_type) // 处理模式是什么: Logger(logger_name, level, formatter, sinks), // 使用抽象基类进行一个实例化操作// 创建一个异步工作器,传入了一个回调函数,第二个参数是实际的类型,就是安全模式和非安全模式// 对reallog进行一个参数绑定,第一个是this参数,再预留一个参数// 通过reallog函数生成一个新的函数,生成一个新的可调用对象,这个新的函数只需要传入一个参数就行了,就是一个缓冲区对象// 就是说我们在调用calback的时候,函数内部已经绑定了一个参数进去了,这个参数就是我们的Asynclogger日志器对象,真正调用的时候calback只需要传入一个buffer就行了// 原先的我们的reallog是需要传入两个参数的,还有一个this对象,因为这个是类内函数我们直接将Asynclogger绑定进去就行了,后面就只用传一个参数了_looper(std::make_shared<AsyncLooper>(std::bind(&AsyncLogger::realLog, this, std::placeholders::_1), _looper_type)) // 异步工作器初始化{}void log(const char *data, size_t len) // 将数据写入缓冲区{_looper->push(data, len); // 将数据写入缓冲区,这里我们是不需要考虑线程安全的问题,因为push的线程就是安全的}// 实际一个实际落地函数(将缓冲区中的数据 进行落地)void realLog(Buffer &buf) // 传入一个缓冲区对象{if (_sinks.empty())return; // 如果这个落地对象数组是空的,那么我们直接返回了for (auto &sink : _sinks) // 遍历日志落地对象数组{// 获取可读取数据的起始位置,以及可读取数据的大小,去进行一个实际的落地操作sink->log(buf.begin(), buf.readAbleSize()); // 逐个调用 sink 的 log 方法,把日志数据输出到不同目标// 这个过程是不需要进行加锁操作的,因为异步工作线程本身就是串行化的工作过程,不需要进行加锁保护的,我们只要保护线程安全的落入到缓冲区里面去,线程内部就能保证串性化的写入数据}}private:AsyncLooper::ptr _looper; // 异步日志循环器,利用智能指针进行对象的管理操作};enum class LoggerType{LOGGER_SYNC, // 同步日志器LOGGER_ASYNC // 异步日志器};/*使用建造者模式来建造日志器,而不要让用户直接去构造日志器,简化用户的使用复杂度建造者模式中,针对我们具体的对象得有一个建造者抽象类然后根据我们具体的对象派生出我们具体的类然后有了建造者类,我们通过指挥者类来指导建造者进行对象的创建指挥建造完零部件之后然后再去建造我们的复杂对象因为我们这里的建造是对零件顺序没有要求的,最主要的问题是参数过多,每个参数都需要进行构造*/// 1、抽象一个日志器建造者类(完成日志器对象所需零部件的构建&日志器的构建)// 1、设置日志器类型// 2、将不同类型日志器的创建放到同一个日志建造者类中完成class LoggerBuilder{public:LoggerBuilder(): _logger_type(LoggerType::LOGGER_SYNC) // 默认生成的事同步日志器,_limit_level(LogLevel::value::DEBUG) // 默认日志等级为DEBUG,_looper_type(AsyncType::ASYNC_SAFE) // 默认异步处理模式为安全模式{}void buildLoggerType(LoggerType type) // 根据这个日志器的类型进行构造{_logger_type = type;}void buildEnableUnSafeAsync() // 启动一个非安全模式的操作{// 设置为非安全状态_looper_type = AsyncType::ASYNC_UNSAFE;}void buildLoggerName(const std::string &name) // 日志器名称{_logger_name = name;}void buildLoggerLevel(LogLevel::value level) // 日志器名称{_limit_level = level;}// 构造一个格式化器,就是设置下我们日志器的输出规则void buildFormatter(const std::string &pattern) // 日志器名称{// 通过pattern来设置日志格式化对象_formatter = std::make_shared<Formatter>(pattern); // 构造了一个Formatter对象,通过智能指针进行管理}// 根据拓展性,让用户自己设定日志落地的方向,所以我们这里使用模版和不定参template <typename SinkType, typename... Args>void buildSink(Args &&...args) // 创建落地器{LogSink::ptr psink = SinkFactory::create<SinkType>(std::forward<Args>(args)...); // 对参数包进行一个完美转发,将参数展开传入,创建一个落地器_sinks.push_back(psink); // 将这个落地器添加到日志器的数组中}virtual Logger::ptr build() = 0; // 日志器的构建接口,返回的是一个日志器对象protected:AsyncType _looper_type; // 异步工作处理模式LoggerType _logger_type; // 日志器类型std::string _logger_name; // 日志器名称LogLevel::value _limit_level; // 日志等级Formatter::ptr _formatter; // 日志格式化对象std::vector<LogSink::ptr> _sinks; // 日志落地对象数组,可能存在多个落地方向,所以使用vector+智能指针进行管理};// 2、派生出具体的建造者类---局部日志器的建造者&全局的日志器建造者(后边添加了全局单例管理器之后,将日志器添加全局管理)class LocalLoggerBuilder : public LoggerBuilder{public:// 返回对应的日志器Logger::ptr build() override // 日志器的构建接口{assert(_logger_name.empty() == false); // 必须有日志器名称if (_formatter.get() == nullptr) // 如果是空的话就代表没有日志器{_formatter = std::make_shared<Formatter>(); // 构造一个默认的日志格式化对象}if (_sinks.empty()) // 如果没有落地对象的话就添加一个默认的落地器{buildSink<StdoutSink>(); // 添加一个标准输出方向的落地器}// 到这里东西都有了,那么我们就得进行创建对象的操作了if (_logger_type == LoggerType::LOGGER_ASYNC) // 如果类型是异步日志器的话,我们就返回一个异步日志器的对象{return std::make_shared<AsyncLogger>(_logger_name, _limit_level, _formatter, _sinks, _looper_type); // 构造一个异步日志器对象并返回}// 走到这里就是同步日志器了return std::make_shared<SyncLogger>(_logger_name, _limit_level, _formatter, _sinks); // 构造一个同步日志器对象并返回}};class LoggerManager // 日志器管理器{public:// 我们这里使用的是懒汉单例模式,对象用的时候再创建,不用就不创建static LoggerManager &getInstance() // 获取单例对象{static LoggerManager eton; // 定义一个对象,静态局部变量// 在C++11之后,针对静态局部变量,编译器再编译的层面实现了线程安全,保证了单例对象的线程安全// 当静态局部变量没有构造完成之前,其他的线程进入就会阻塞,因为是静态变量,所以所有的线程获取到的都是同一个对象return eton; // 返回单例对象}void addLogger(Logger::ptr &logger) // 添加日志器{if(hasLogger(logger->name()))return ;//如果已经存在这个日志器的话,那么我们就不需要重进行添加了//日志器不存在的话我们就走进来记性日志器的添加操作了std::unique_lock<std::mutex> lock(_mutex); // 对互斥锁进行一个管理操作_loggers.insert(std::make_pair(logger->name(), logger)); // 将日志器添加到日志器数组中}bool hasLogger(const std::string &name) // 判断是否存在某个日志器{std::unique_lock<std::mutex> lock(_mutex); // 对互斥锁进行一个管理操作auto it=_loggers.find(name); // 利用find函数进行查找if(it!=_loggers.end()){return true;//说明没有找到}return false;//找到了}Logger::ptr getLogger(const std::string &name) // 通过日志器名称获取日志器{std::unique_lock<std::mutex> lock(_mutex); // 对互斥锁进行一个管理操作auto it=_loggers.find(name); // 利用find函数进行查找if(it==_loggers.end()){return Logger::ptr();//说明没有找到,我们返回一个空的智能指针}return it->second;//找到了,就是日志器对象}Logger::ptr rootLogger() // 获取默认日志器{return _root_logger; // 返回默认日志器}private:LoggerManager() // 构造函数私有化,不允许外部创建对象{//这里不能是globalLoggerBuilder,不然是会卡主的std::unique_ptr<kaizi::LoggerBuilder> builder(new kaizi::LocalLoggerBuilder());//创建一个日志器构造器对象,让构造器指针进行智能管理builder->buildLoggerName("root"); // 设置日志器名称,其他的信息我们都会默认进行设置操作_root_logger=builder->build(); // 构造默认的日志器对象//默认日志器就是参数只用传个名字就行了,其他的就系统默认就行了,我们不需要设置,让建造者帮我们进行设置就行了_loggers.insert(std::make_pair(_root_logger->name(), _root_logger)); // 将默认日志器添加到日志器数组中}private:std::mutex _mutex; // 日志器管理器的互斥锁Logger::ptr _root_logger; // 默认日志器// 日志器名称和日志器对象之间的映射关系std::unordered_map<std::string, Logger::ptr> _loggers; // 日志器的数组};//设计一个全局日志器的建造者---在局部的基础上增加一个功能:将日志器添加到单例对象中class GlobalLoggerBuilder : public LoggerBuilder{public:// 返回对应的日志器Logger::ptr build() override // 日志器的构建接口{assert(_logger_name.empty() == false); // 必须有日志器名称if (_formatter.get() == nullptr) // 如果是空的话就代表没有日志器{_formatter = std::make_shared<Formatter>(); // 构造一个默认的日志格式化对象}if (_sinks.empty()) // 如果没有落地对象的话就添加一个默认的落地器{buildSink<StdoutSink>(); // 添加一个标准输出方向的落地器}Logger::ptr logger ;//创建一个logger对象// 到这里东西都有了,那么我们就得进行创建对象的操作了if (_logger_type == LoggerType::LOGGER_ASYNC) // 如果类型是异步日志器的话,我们就返回一个异步日志器的对象{logger= std::make_shared<AsyncLogger>(_logger_name, _limit_level, _formatter, _sinks, _looper_type); // 构造一个异步日志器对象并返回}else{logger=std::make_shared<SyncLogger>(_logger_name, _limit_level, _formatter, _sinks);}LoggerManager::getInstance().addLogger(logger); // 将日志器添加到日志器管理器中return logger;}//外界就不用自己去添加了,实例化一个global的建造者对象,然后调用build方法就行了,我们这里就不用实现了,因为我们这里的全局日志器的建造者和局部日志器的建造者是一样的,只是多了一个功能,将日志器添加到单例对象中};}#endif
looper.hpp
/*实现异步工作器*/#ifndef __LOOPER_HPP__#define __LOOPER_HPP__#include"buffer.hpp"#include<mutex>#include<thread>#include<condition_variable>#include<functional>#include<memory>#include<atomic>namespace kaizi{using Functor=std::function<void(Buffer&)>;//回调函数类型enum class AsyncType{ASYNC_SAFE,//安全状态,表示缓冲区满了则阻塞,避免资源耗尽的风险ASYNC_UNSAFE//不考虑资源耗尽的问题,无线扩容,常用于测试};class AsyncLooper{public:using ptr=std::shared_ptr<AsyncLooper>;//智能指针类型AsyncLooper(const Functor&cb,AsyncType loop_type=AsyncType::ASYNC_SAFE)//异步工作线程得用户告诉我们如何进行去对这个消费者缓冲区中的数据进行处理操作:_stop(false)//创建了一个新的线程对象,将这个线程对象赋值给成员变量_thread//当执行这行代码时://1.会创建一个新的线程对象//2、新线程会调用AsyncLooper类的threadEntry()方法//3、由于这是一个成员函数,需要通过this指针指定是哪个对象的方法//4、新线程独立运行,与主线程并行执行threadEntry()中的代码,_thread(std::thread(&AsyncLooper::threadEntry,this)),_callBack(cb), _looper_type(loop_type)//默认是安全状态{};~AsyncLooper(){stop();//析构函数中调用stop()函数,进行退出操作}void stop(){_stop=true;//将退出标志设置为true,说明要进行生产缓冲区停止生产了,然后通知消费者线程进行消费//那么我们就得唤醒所有的工作线程了_cond_con.notify_all();//等待工作线程退出_thread.join();}void push(const char*data,size_t len)//添加数据{//1、无线扩容--非安全 2、固定大小---生产换中区中数据满了就阻塞std::unique_lock<std::mutex> lock(_mutex);//先加个锁//条件变量控制,若我们缓冲区剩余空间大小大于数据长度的话,则可以添加数据if(_looper_type==AsyncType::ASYNC_SAFE)//如果是安全状态的话,则进行条件变量的等待,如果不是的话,则直接进行添加数据操作_cond_pro.wait(lock,[&](){return _pro_buf.writeAbleSize()>=len;});//走到这里就说明满足了条件,可以向缓冲区中进行数据的添加操作_pro_buf.push(data,len);//缓冲区进行数据插入操作//通知消费者线程进行消费_cond_con.notify_one();//唤醒消费者进行缓冲区中数据处理}private://线程入口函数---对消费缓冲区中的数据进行处理,处理完毕后初始化缓冲区,交换缓冲区void threadEntry(){//stop为true的话就退出循环了while(1)//如果没有停止运行的话我们就进行死循环操作,如果停止了的话,就跳出循环了{{ //1、要判断生产缓冲区中是否有数据,有的话就进行交换操作,无则阻塞std::unique_lock<std::mutex> lock(_mutex);//进行加锁操作//退出标志被设置,并且生产缓冲区已无数据//如果不按照这样的话,否则可能会造成生产缓冲区中有数据,但是没有完全被处理,然后随着析构函数进行析构了if(_stop==true&&_pro_buf.empty())break;//当我要退出了并且当前的生产缓冲区没有数据了,那么我就退出循环了//有生产缓冲区中有数据的话我们就进行交换操作//若当前是退出前被唤醒,或者有数据被唤醒,则返回真,继续向下运行,否则返回假重新进入休眠操作_cond_con.wait(lock,[&](){return _stop|| !_pro_buf.empty()>0;});//等待条件变量,直到生产者缓冲区有数据//如果是退出后被唤醒了的话,那么我们继续进行休眠操作_con_buf.swap(_pro_buf);//交换缓冲区//2、唤醒生产者,交换完毕了就能进行生产者的唤醒操作了 if(_looper_type==AsyncType::ASYNC_SAFE)//如果是安全状态的话就进行唤醒操作_cond_pro.notify_all();//唤醒生产者进行缓冲区中数据处理}//为互斥锁设置一个生命周期,当交换区交换完毕之后就解锁(并不对数据的处理过程加锁保护)//这里我们出了作用域了,那么锁的生命周期就结束了,就自动进行解锁操作,生产者就可以往缓冲区进行数据的填写操作//3、被唤醒后,对消费缓冲区进行数据处理,_callBack(_con_buf);//调用回调函数进行数据处理//4、处理完毕后初始化缓冲区_con_buf.reset();//重置读写位置,初始化缓冲区}}private:Functor _callBack;//具体对缓冲区数据进行处理的回调函数,由异步工作器使用者传入private:AsyncType _looper_type;//异步工作器的类型,安全还是不安全//stop的操作存在线程安全的问题,加锁又没有什么必要,我们直接将这个stop设置为原子的std::atomic<bool> _stop;//工作器停止标志---异步工作器是否停止Buffer _pro_buf;//生产缓冲区Buffer _con_buf;//消费缓冲区std::mutex _mutex;std::condition_variable _cond_pro;//生产者条件变量std::condition_variable _cond_con;//消费者条件变量std::thread _thread;//异步工作器对应的工作线程};}#endif
message.hpp
/*定义日志消息类,进行日志中间信息的存储1.日志输出时间 ---用于过滤日志输出的时间2.日志等级 ---用于进行日志过滤分析3.源文件名称4.源代码行号 ---用于定位出现错误的代码位置5.线程ID ---用于过滤程序出错的线程6.日志主体消息7.日志器名称(当前支持多日志器的同时使用)*/#ifndef __M_MSG_H__#define __M_MSG_H__#include <iostream>#include <thread>#include <string>#include "level.hpp"#include "util.hpp"namespace kaizi{struct LogMsg // 定义一个结构体,默认就是公有的{time_t _ctime; // 日志的时间戳LogLevel::value _level; // 日志等级size_t _line; // 源代码行号std::thread::id _tid; // 线程IDstd::string _file; // 源文件名称std::string _logger; // 日志器名称std::string _payload; // 日志主体消息---有效载荷数据LogMsg(LogLevel::value level,size_t line,const std::string file,const std::string logger,const std::string msg): _ctime(util::Date::now()),_level(level),_line(line),_tid(std::this_thread::get_id()),_file(file),_logger(logger),_payload(msg){}};}#endif
sink.hpp
/*日志落地模块的实现1、抽象落地基类2、派生落地子类---文件落地、网络落地、数据库落地3、使用工厂模式进行创建与表示的分离*/#ifndef __M_SINK_H__#define __M_SINK_H__#include "util.hpp"#include <fstream>#include <memory>#include <cassert>#include <sstream>namespace kaizi{class LogSink{public:using ptr = std::shared_ptr<LogSink>; // 对LogSink进行智能管理LogSink() {};virtual ~LogSink() {}; // 对析构进行抽象(用户在拓展的时候可能有一些释放的操作)virtual void log(const char *data, size_t len) = 0; // 起始地址和长度进行日志落地};// 落地方向:标准输出class StdoutSink : public LogSink{public:// 将日志消息写入到标准输出void log(const char *data, size_t len){std::cout.write(data, len); // 直接使用重载函数write,可以进行限制写入的长度}};// 落地方向:指定文件class FileSink : public LogSink{public:// 传入文件名,并打开文件,将操作句柄管理起来FileSink(const std::string &pathname): _pathname(pathname){// 1、创建日志文件所在的目录util::File::createDirectory(util::File::path(_pathname));// 2、创建并打开日志文件_ofs.open(_pathname, std::ios::binary | std::ios::app); // 二进制的形式进行打开,并且进行数据的追加操作assert(_ofs.is_open());}// 将日志消息写入到指定文件void log(const char *data, size_t len){_ofs.write(data, len); // 写入数据到文件assert(_ofs.good()); // 断言写入是否成功了}private:std::string _pathname; // 指定的文件名std::ofstream _ofs; // 文件输出流};// 落地方向:滚动文件(以大小进行滚动)class RollBySizeSink : public LogSink{public:RollBySizeSink(const std::string &basename, size_t max_fsize): _basename(basename), _max_fsize(max_fsize), _cur_fsize(0),_name_count(0){std::string pathname = createNewFile(); // 利用下面的创建文件名函数,创建第一个文件// 1、创建日志文件所在的目录util::File::createDirectory(util::File::path(pathname));// 2、创建并打开日志文件_ofs.open(pathname, std::ios::binary | std::ios::app); // 二进制的形式进行打开,并且进行数据的追加操作assert(_ofs.is_open());}// 将日志消息写入到指定文件,写入前判断文件大小,超过了最大大小就要切换文件了void log(const char *data, size_t len){if (_cur_fsize >= _max_fsize){//先将原来的文件给关闭掉,如果不关闭的话就会造成资源泄露的情况出现了_ofs.close();// 创建一个新的文件名std::string pathname = createNewFile();// 2、创建并打开日志文件_ofs.open(pathname, std::ios::binary | std::ios::app); // 二进制的形式进行打开,并且进行数据的追加操作assert(_ofs.is_open());_cur_fsize=0;//进行清零操作,因为我们换文件了}_ofs.write(data, len); // 写入数据到文件assert(_ofs.good()); // 断言写入是否成功了_cur_fsize+=len;//进程当前内存的更新}private:std::string createNewFile() // 创建一个新的文件名{// 获取系统时间,以时间来构建文件拓展名time_t t = util::Date::now(); // 获取时间struct tm lt; // 接受转换后的时间结构的localtime_r(&t, <); // 将结构化的时间信息放到lt中,就是将时间戳转换为时间结构std::stringstream filename;filename << _basename;// 下面的lt.tm_year都是结构体里面的相关信息filename << lt.tm_year + 1900;//得加上1900才是真正的年份filename << lt.tm_mon + 1;//默认是从0月开始的,我们是从1月开始的filename << lt.tm_mday;filename << lt.tm_hour;filename << lt.tm_min;filename << lt.tm_sec;filename<<"-";filename<<_name_count++;filename << ".log"; // 文件的后缀名return filename.str(); // 我们需要通过str()获取字符串形式的filename}private:// 通过基础文件名+扩展文件名组成一个实际的当前输出文件名// ./log/test.log-2021-08-01size_t _name_count=0;std::string _basename; // 基础文件名,最终的文件名后面会有时间std::ofstream _ofs; // 文件输出流size_t _max_fsize; // 单个文件的最大大小,超过文件大小就得进行文件的切换了size_t _cur_fsize; // 记录当前文件已经写入的数据大小};//我们可以通过模版参数进行控制,作为类型来控制我们的输出//因为上面的三种方向的参数个数都是不一样的,所以这里我们使用不定参函数class SinkFactory{public://函数模版 template<typename SinkType,typename ...Args>//传递一个具体的日志落地的方向类型static LogSink::ptr create(Args... args){//将参数包展开进行一个完美转发return std::make_shared<SinkType>(std::forward<Args>(args)...); // 通过make_shared来创建具体的日志落地对象}};}#endif // __M_SINK_H__
util.hpp
/*使实用工具类的实现:- 获取系统时间- 判断⽂件是否存在- 获取⽂件的所在⽬录路径- 创建⽬录(如果指定存放日志的文件目录不存在的话,那么我们就得进行目录的创建了)*/#ifndef __UTIL_HPP__#define __UTIL_HPP__#include <iostream>#include <ctime>#include <sys/stat.h>namespace kaizi{namespace util{class Date{public:static size_t now(){return (size_t)time(nullptr);}};class File{public:static bool exists(const std::string &pathname) // 检查路径中的文件是否存在{struct stat st;if (stat(pathname.c_str(), &st) < 0){return false;}return true;// return (access(pathname.c_str(), F_OK)==0);}static std::string path(const std::string &pathname) // 获取路径名{// ./abc/def.txt 这里我们只需要从一开始获取到def前面的/那里就行了,我们直接查找最后一个/size_t pos = pathname.find_last_of("/\\"); // '/\\' 是为了适配不同操作系统的路径分隔符if (pos == std::string::npos)return "."; // 说明没找到,我们直接返回一个点return pathname.substr(0, pos + 1); // 加上1是为了包含'/'在内的整个路径名,利用substr进行长度的截取操作}static void createDirectory(const std::string &pathname) // 递归创建目录{// ./abc/bcd/a.txt 目录得一层一层的进行创建,要创建a.txt的话就得存在bcd,要创建bcd的话就得存在abc了// 找到一个创建一个size_t pos = 0, idx = 0;while (idx < pathname.size()){pos = pathname.find_first_of("/\\", idx); // 从idx开始查找第一个路径分隔符if (pos == std::string::npos) // 说明没找到,说名我们只存在a.txt,那么我们直接进行创建目录操作{mkdir(pathname.c_str(), 0777); // 0777是为了让所有用户都有权限访问该目录}//存在路径std::string parent_dir = pathname.substr(0, pos + 1); // 获取父目录名,从0开始到pos-idx+1结束,包含了'/'的路径名if (exists(parent_dir) == true)//存在的话,我们就让idx遍历到这个路径的末尾,继续查找下一个路径分隔符{idx=pos+1; // 继续查找下一个路径分隔符continue; // 如果父目录存在,那么我们就不用再创建了}//不存在的话就进行创建mkdir(parent_dir.c_str(), 0777);idx=pos+1;//继续往后面走}}};}}#endif