【SpringAI】SpringAI的介绍与简单使用
Spring AI是Spring生态系统在人工智能领域的战略级扩展,旨在为Java开发者提供标准化、模块化的AI集成方案。该框架汲取了LangChain等Python项目的设计思想,但针对企业级场景进行了深度优化,支持OpenAI、Anthropic、Google VertexAI等20+主流模型。
AI模型(Model)
AI模型是设计用来处理和生成信息的算法,常常模仿人类的认知功能。通过从大型数据集中学习模式和见解,这些模型能够做出预测、生成文本、图像或其他输出,从而增强各行业的应用。
下表根据输入和输出类型对几种模型进行了分类:
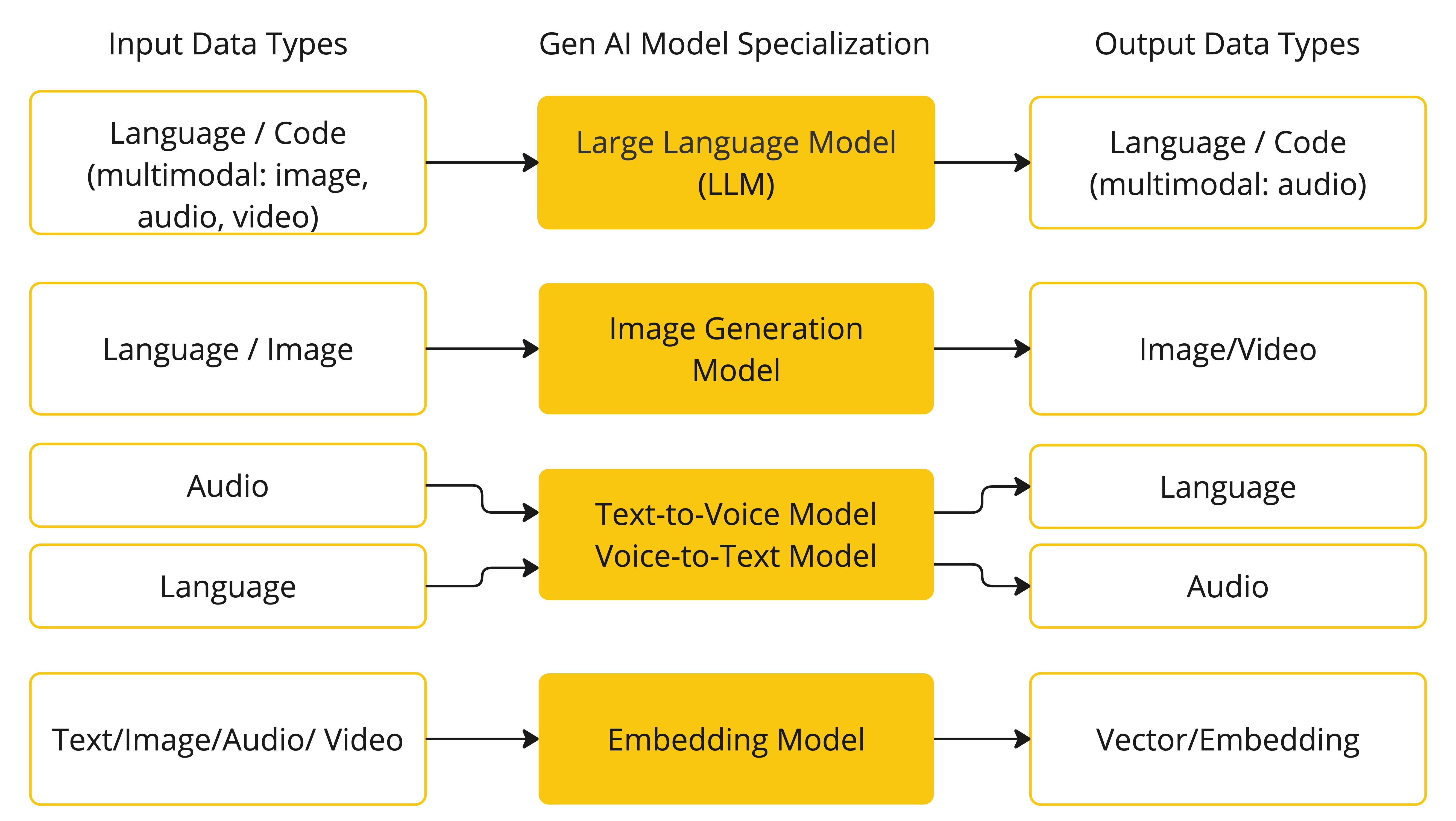
Spring AI目前支持处理语言、图像和音频作为输入和输出的模型。上表最后一行接受文本作为输入并输出数字,这更常被称为文本嵌入,代表AI模型中使用的内部数据结构。Spring AI支持嵌入以实现更高级的用例。
下面根据输入和输出类型分类的表格化呈现,包含主流模型支持情况及典型应用场景:
| 分类 | 输入类型 | 输出类型 | 支持模型 | 典型场景 |
|---|---|---|---|---|
| 文本到文本 | 纯文本 | 纯文本 | GPT-4、Claude 3、Gemini、Llama 3、ERNIE X1 | 文章生成、机器翻译、代码补全、法律文书审查 |
| 文本到图像 | 文本描述 | 静态图像 | DALL·E 3、Midjourney、Stable Diffusion XL、Adobe Firefly | 概念设计可视化、广告素材生成、艺术创作 |
| 图像到文本 | 静态图像 | 文本描述 | CLIP、BLIP-2、GIT、Flamingo、PaddlePaddle | 图像内容理解、视觉问答、商品标签生成 |
| 多模态到文本 | 文本+图像+音频 | 结构化文本 | LLaVA、Fuyu、Kosmos-2、mPLUG-Owl | 复杂文档理解(如发票/合同)、多模态客服系统 |
| 文本到音频 | 文本指令 | 语音/音乐 | Whisper、VALL-E、MusicGen、AudioLM | 语音合成、有声书制作、个性化铃声生成 |
| 文本到视频 | 文本脚本 | 动态视频 | Sora、Lumiere、Gen-2、ModelScope | 短视频创作、动画原型生成、教育演示视频制作 |
| 多模态到多模态 | 文本+图像+语音 | 文本+图像+语音 | Gemini Pro/Ultra、GPT-4 Turbo、Fuyu、PaddlePaddle | 全模态交互助手、沉浸式教育场景、智能会议系统 |
提示词(Prompt)
提示词(Prompt)是用户与人工智能模型交互时提供的输入指令或问题描述,用于引导模型生成符合预期的输出。其核心作用是将人类需求转化为机器可理解的形式,通过精准设计提升AI响应的质量和相关性。
提示词是语言输入的基础,引导AI模型生成特定输出。对于熟悉ChatGPT的用户来说,提示词可能看起来就像是对话框中输入并发送到API的文本。然而,它包含的内容远不止这些。在许多AI模型中,提示词的文本不仅仅是一个简单的字符串。
ChatGPT的API在提示词中有多个文本输入,每个文本输入都被分配了一个角色。例如,有系统角色,它告诉模型如何表现并设置交互的上下文。还有用户角色,通常是用户的输入。
设计有效的提示词既是一门艺术也是一门科学。ChatGPT是为人类对话设计的。这与使用SQL“提问”大相径庭。与AI模型交流必须类似于与另一个人交谈。
这种交互风格的重要性使得“提示工程”成为了一个独立的学科。有许多技术可以提高提示词的有效性。投入时间设计提示词可以极大地改善生成的输出。
嵌入(Embeddings)
Embeddings(嵌入)是一种将高维、离散或非结构化数据(如文本、图像、类别标签)映射到低维连续向量空间的技术。其核心目标是通过数学模型将数据转化为稠密向量,使得相似数据在向量空间中距离更近,从而捕捉数据的语义或特征信息。
嵌入是文本、图像或视频的数值表示,它们捕获了输入之间的关系。
嵌入通过将文本、图像和视频转换为称为向量的浮点数数组来工作。这些向量旨在捕获文本、图像和视频的含义。嵌入数组的长度称为向量的维度。
通过计算两个文本片段的向量表示之间的数值距离,应用程序可以确定用于生成嵌入向量的对象之间的相似性。
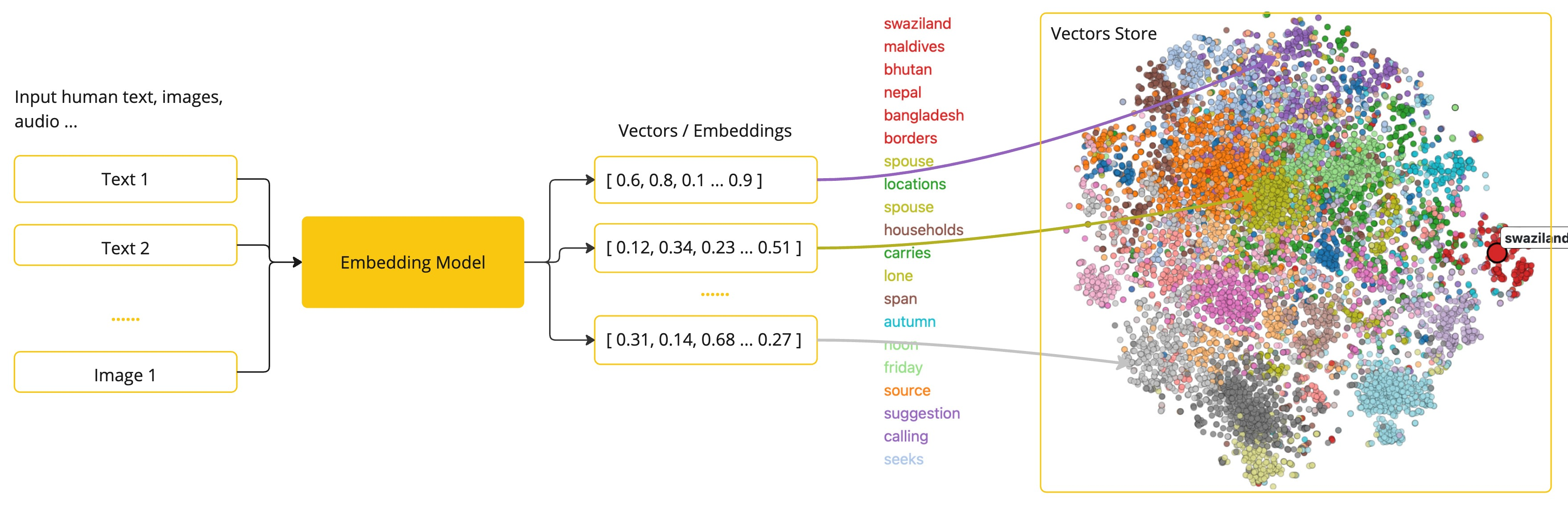
作为探索AI的Java开发者,不必理解这些向量表示背后的复杂数学理论或特定实现。对于将AI功能集成到应用程序中来说,对其角色和功能的基本理解就足够了。
嵌入在诸如检索增强生成(RAG)模式等实际应用中特别相关。它们使数据能够在语义空间中表示为点,这类似于欧几里得几何的二维空间,但维度更高。这意味着就像欧几里得几何中平面上的点可以根据其坐标靠近或远离一样,在语义空间中,点的接近程度反映了用于生成嵌入向量的对象之间的相似性。关于相似主题的句子在这个多维空间中位置更接近,就像图上的点彼此靠近一样。这种接近性有助于文本分类、语义搜索甚至产品推荐等任务,因为它允许AI根据它们在扩展语义景观中的“位置”来辨别和分组相关概念。
你可以将这种语义空间视为一个向量。
Tokens
Tokens是大模型处理文本或数据的最小单元,类似于“语言中的原子”。在大模型(如GPT、BERT、T5)中,文本会被拆分为一系列Tokens,每个Token代表一个有意义的单元(如单词、子词或字符)。
在输入时,模型将单词转换为Tokens。在输出时,它们将Tokens转换回单词。
在英语中,一个Tokens大致对应于一个单词的75%。作为参考,莎士比亚的全部作品,总计约90万字,转换为约120万个Tokens。
也许更重要的是,Tokens等于金钱。在托管AI模型的上下文中,您的费用由使用的Tokens数量决定。输入和输出都计入总Tokens数。
此外,模型受到Tokens限制,这限制了单次API调用中处理的文本量。这个阈值通常被称为“上下文窗口”。模型不会处理超过此限制的任何文本。
例如,ChatGPT3有4K Tokens限制,而GPT4提供不同的选项,如8K、16K和32K。Anthropic的Claude AI模型具有100K Tokens限制,而Meta的最新研究产生了一个1M Tokens限制的模型。
要使用GPT4总结莎士比亚的全部作品,您需要制定软件工程策略来分割数据并在模型的上下文窗口限制内呈现数据。Spring AI项目可以帮助您完成这项任务。
结构化输出
AI模型的输出传统上以java.lang.String的形式到达,即使您要求回复为JSON格式也是如此。它可能是一个正确的JSON,但它不是一个JSON数据结构。它只是一个字符串。此外,在提示词中要求“JSON”格式并不总是100%准确。
这种复杂性导致了一个专门领域的出现,该领域涉及创建提示词以产生预期输出,然后是将生成的简单字符串转换为可用于应用程序集成的可用数据结构。
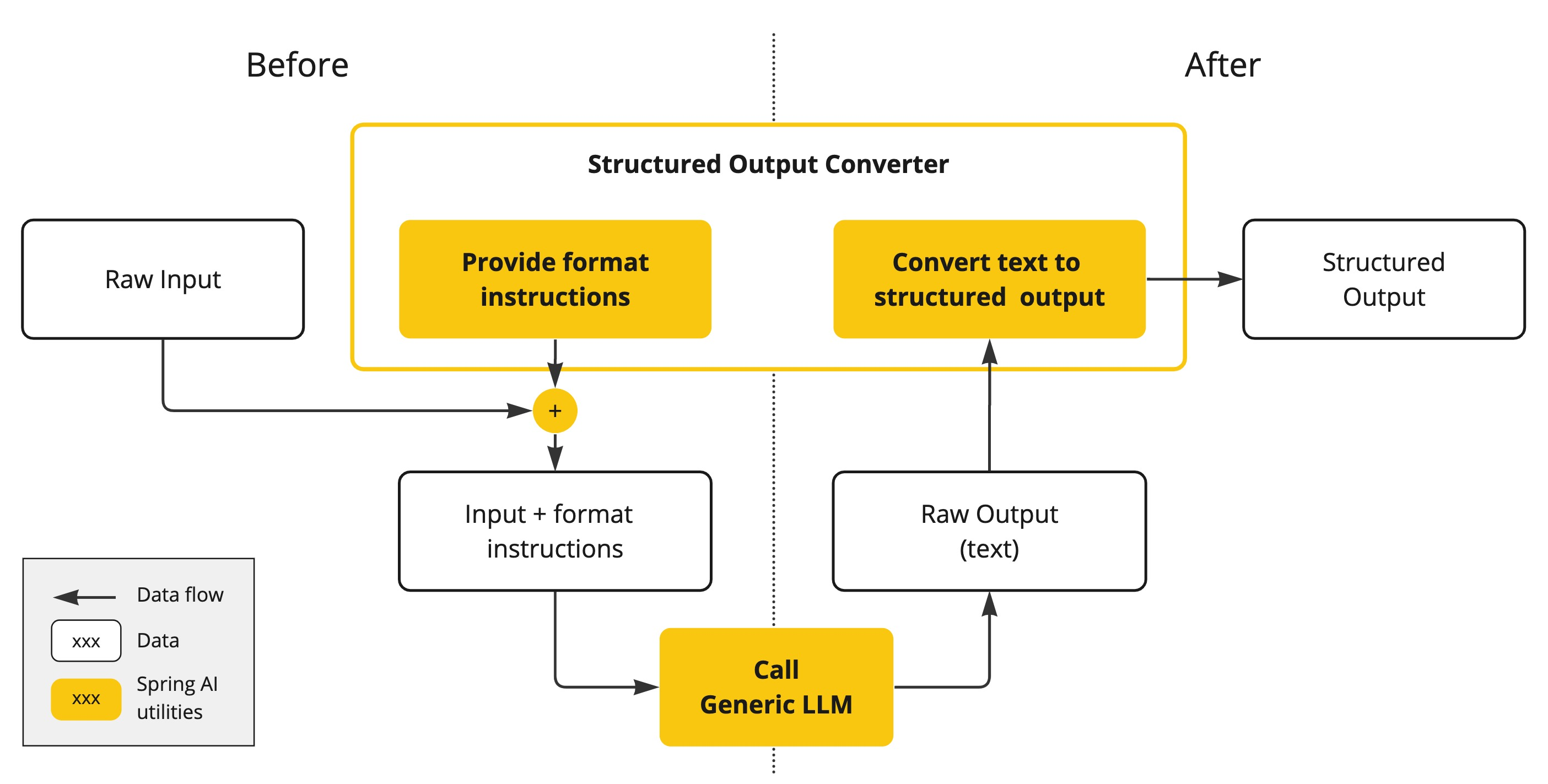
结构化输出转换采用精心设计的提示词,通常需要与模型进行多次交互以实现所需的格式。
将您的数据和API带到AI模型
如何为AI模型提供它未接受过训练的信息?
请注意,GPT 3.5/4.0数据集仅扩展到2021年9月。因此,对于需要此日期之后知识的问答,模型会表示它不知道答案。一个有趣的琐事是,这个数据集大约有650GB。
存在以下几种技术来定制AI模型以包含您的数据:
-
提示词工程(Prompt Engineering):通过设计提示词引导模型生成所需输出,适用于零样本或小样本学习。例如,使用零样本提示直接提问,或通过少量示例引导模型理解新任务。
-
检索增强生成(Retrieval-Augmented Generation,RAG):将外部知识库(如文档、数据库)分块并向量化,在生成答案前检索相关信息。适用于需要最新数据或特定领域知识的场景,如法律咨询、实时信息查询。
-
工具调用(Function Call):允许模型通过调用外部函数或API执行特定任务(如数据查询、计算、系统操作),返回结构化结果,例如调用外部的API、数据库,搜索引擎获取数据
-
微调(Fine-Tuning):通过API调用微调服务(如OpenAI的微调API),上传领域特定数据集调整模型参数,使其适应新任务。这种传统的机器学习技术涉及调整模型并更改其内部权重。然而,对于机器学习专家来说,这是一个具有挑战性的过程,对于像GPT这样的大型模型来说,资源消耗极大。此外,某些模型可能不提供此选项。
检索增强生成(RAG)
RAG(Retrieval-Augmented Generation)是一种结合了信息检索和生成模型的方法,旨在提高生成模型在处理特定任务时的准确性和上下文相关性。RAG通常包含以下几个关键部分:
-
信息检索:在生成响应之前,系统首先从一个大型文档库中检索相关信息。这通常通过使用预训练的检索模型(如BM25或DPR)来实现,以找到与用户查询相关的文档或段落。
-
生成模型:检索到的相关文档会作为输入提供给生成模型(如GPT或BART等),该模型会基于这些信息生成最终的响应。生成模型能够理解和处理自然语言,从而生成流畅且上下文相关的文本。
-
上下文增强:通过引入外部知识,RAG能够在生成过程中利用更丰富的信息,从而提高生成内容的质量。这对于需要特定知识或背景信息的任务(如问答、对话生成等)特别有用。
RAG的优势在于它不单纯依赖于模型的预训练知识,而是通过动态检索来获取最新和相关的信息,使得生成结果更加准确和可靠。在许多应用场景中,RAG已被证明能够显著提升生成模型的性能。
工具调用(Function Call)
大型语言模型(LLM)在训练后是固定的,导致知识过时,并且它们无法访问或修改外部数据。
工具调用机制解决了这些缺点。它允许您注册自己的服务作为工具,将大型语言模型连接到外部系统的API。这些系统可以为LLM提供实时数据并代表其执行数据处理操作。
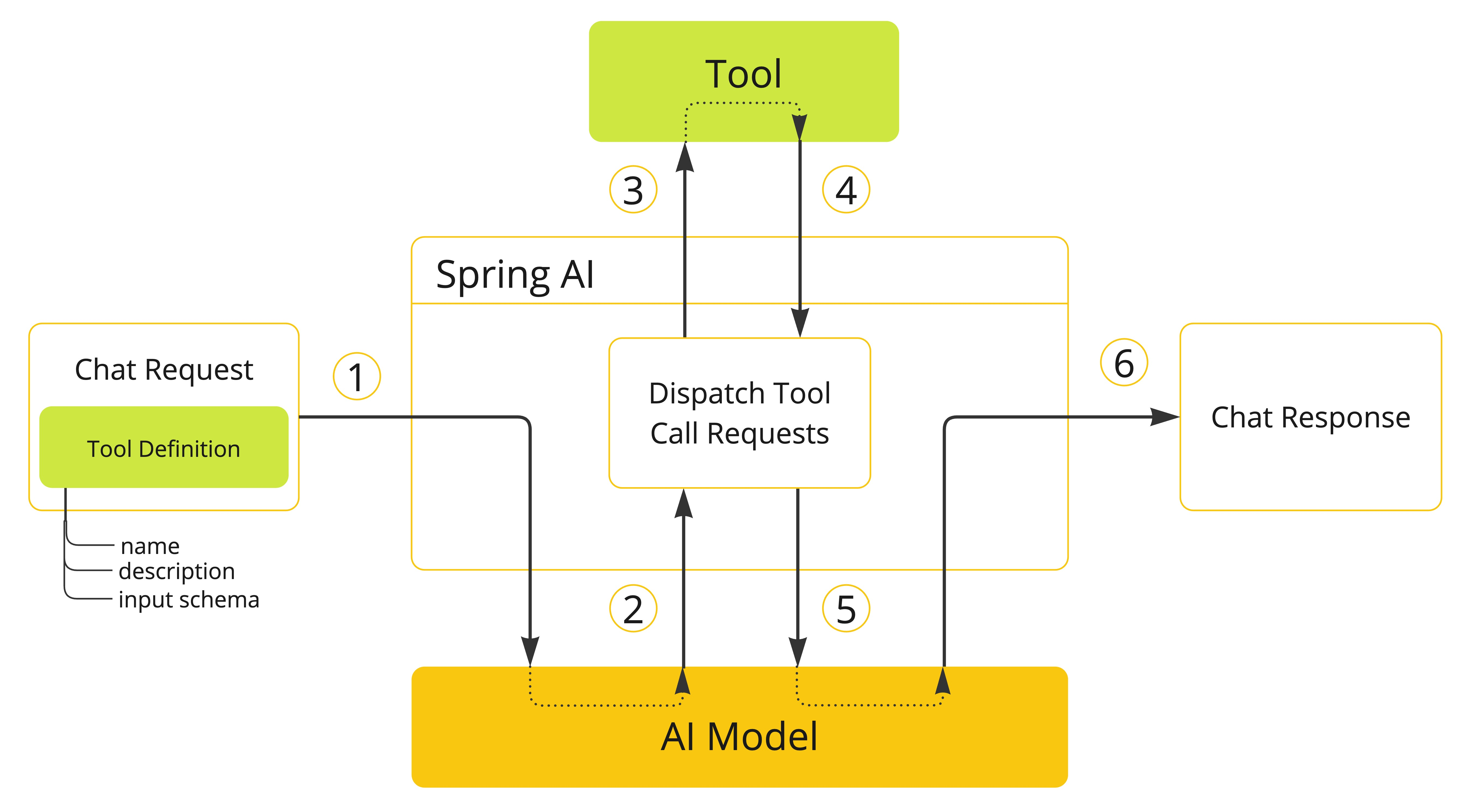
Spring AI极大地简化了支持工具调用所需的代码。它为您处理工具调用对话。您可以提供一个带有@Tool注解的方法作为您的工具,并将其提供在提示词选项中以使其对模型可用。此外,您可以在单个提示词中定义和引用多个工具。
-
当我们想使工具对模型可用时,我们在聊天请求中包含其定义。每个工具定义包括名称、描述和输入参数的架构。
-
当模型决定调用工具时,它会发送一个包含工具名称和按照定义架构建模的输入参数的响应。
-
应用程序负责使用工具名称来识别并使用提供的输入参数执行工具。
-
应用程序处理工具调用结果。
-
应用程序将工具调用结果发送回模型。
-
模型使用工具调用结果作为附加上下文生成最终响应。
Spring AI的简单使用
引入依赖
项目中使用的JDK21版本、SpringBoot版本为3.2.5版本。
完整pom.xml如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.2.5</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.morris</groupId><artifactId>open-ai-demo</artifactId><version>0.0.1-SNAPSHOT</version><name>open-ai-demo</name><description>Spring AI Demo Project</description><properties><java.version>21</java.version></properties><dependencies><!-- Spring Boot Starters --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- Test --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-openai</artifactId><version>1.0.0</version></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>
配置api-key
在application.yml中配置的OpenAI的api-key:
spring:ai:openai:api-key: {you_open_ai_api_key}api-key的获取需要注册OpenAI后,在这个页面获取:https://platform.openai.com/api-keys
文本聊天
Spring AI提供了ChatClient接口,它就像操作数据库的JdbcTemplat 一样,可以直接问问题、获取回复。
package com.morris.ai.demo;import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.ConfigurableApplicationContext;/*** OPEN AI文生文的简单使用*/
@SpringBootApplication
public class OpenAISingleDemo {public static void main(String[] args) {System.setProperty("spring.profiles.active", "openai");ConfigurableApplicationContext applicationContext = SpringApplication.run(OpenAISingleDemo.class, args);ChatModel chatModel = applicationContext.getBean(ChatModel.class);var prompt = new Prompt(new UserMessage("你是哪个大模型"));System.out.println(chatModel.call(prompt).getResult().getOutput().getText());applicationContext.close();}}
打印的输出内容如下:
我是基于OpenAI的GPT-3模型。有什么我可以帮助你的吗?