Python----大模型(量化 Quantization)
一、量化
1.1、目的
大模型量化的主要目的是压缩模型参数,降低计算复杂度,提高推理效率。
存储优化:将高精度的浮点型参数转换为低精度的整数参数,减少模型存储空间。
计算加速:使用低精度整数进行计算,降低计算复杂度,提高推理速度。
硬件适配:某些硬件(如嵌入式设备、移动端芯片)对低精度计算支持更好,量化可以提高 适配性。
| 精度 | 存储位数 | 结构 |
|---|---|---|
| Float32 (FP32) | 32 位 | 1位符号位,8位指数位,23位尾数位 |
| Float16 (FP16) | 16 位 | 1位符号位,5位指数位,10位尾数位 |
| Bfloat16 (BF16) | 16 位 | 1位符号位,8位指数位,7位尾数位 |
| Int8 | 8 位 | 仅整数,无指数部分 |
| Int4 | 4 位 | 仅整数,无指数部分 |
举例:7B(70亿参数)的大模型在不同精度下的存储大小:
-
FP16:约 14GB
-
INT8:约 8GB
-
INT4:约 4GB
1.2、量化分类
量化方法可以根据是否使用额外数据进行校准,分为两大类:
在线量化 (On Quantization):使用额外的数据集进行量化,主要目的是减少精度损失, 保证模型效果。
离线量化 (Off Quantization):直接对已有的模型进行量化,可能使用少量或不使用额外 数据。
1.3、量化的优缺点
| 类别 | 优点 | 局限性 |
|---|---|---|
| 减少存储 | 显著减少模型权重的存储空间。 | - |
| 推理速度 | 降低计算开销,适用于移动设备和云端推理。 | - |
| 节约能耗 | 降低计算功耗,使模型适用于嵌入式设备。 | - |
| 精度损失 | - | 可能导致模型推理精度下降,尤其是大规模 LLM。 |
| 训练开销 | - | 某些量化方法需要额外的训练或微调。 |
| 硬件支持 | - | 低精度计算(如 INT4、NF4)需要特定硬件支持。 |
1.4、量化的应用场景
边缘计算:在移动设备、智能摄像头上运行高效 AI 模型。
服务器部署:减少 GPU/TPU 显存占用,提高吞吐量。
模型压缩:降低存储需求,便于模型分发。
1.5、量化计算方式


反量化(Dequantization)主要用于将量化后的整数值恢复为浮点数,以便进行更精确的计 算,尤其是在推理过程中。
在大模型推理时,量化的参数(如 INT8 或 INT4)用于计算,以提高推理效率。但最终模型的 某些计算(如 Softmax、LayerNorm)仍然需要浮点精度,因此需要在适当的地方进行反量化。
import torchfloat_tensor = torch.tensor([2.5, -3.1, 7.6, -1.2, 5.8], dtype=torch.float32)
# x_int = round(x_float / scale + zero_point)
quantized_tensor = torch.quantize_per_tensor(float_tensor, scale=0.1, zero_point=0, dtype=torch.qint8)print("Float32:", float_tensor)
print("Int8:", quantized_tensor.int_repr())# Float32: tensor([ 2.5000, -3.1000, 7.6000, -1.2000, 5.8000])
# Int8: tensor([ 25, -31, 76, -12, 58], dtype=torch.int8)注意: 离群值(outliers)可能会影响 scale,导致大部分数据的量化误差增加。 解决方案包括截断离群值,或者使用更复杂的分组量化方法。
import torch
import torch.nn as nn
import os# 创建 FP16 模型
fp16_model = nn.Sequential(nn.Linear(1280, 1280),nn.Linear(1280, 1280)
).to(torch.float16).to(0)# 保存 FP16 模型
torch.save(fp16_model.state_dict(), "model_fp16.pt")# 进行动态量化
quantized_model = torch.quantization.quantize_dynamic(fp16_model, # 原始模型{nn.Linear}, # 需要量化的层dtype=torch.qint8 # 量化为 INT8
)# 保存 INT8 量化模型
torch.save(quantized_model.state_dict(), "model_int8.pt")# 计算文件大小
size_fp16 = os.path.getsize("model_fp16.pt")
size_int8 = os.path.getsize("model_int8.pt")print("Model: FP16\tSize (KB):", size_fp16 / 1e3)
print("Model: INT8\tSize (KB):", size_int8 / 1e3)
print("Compression Ratio: {:.2f}x".format(size_fp16 / size_int8))
'''
Model: FP16 Size (KB): 6560.872
Model: INT8 Size (KB): 3285.412
Compression Ratio: 2.00x
'''二、GPTQ量化
GPTQ:ACCURATE POST-TRAINING QUANTIZATION FOR GENERATIVE PRE-TRAINED TRANSFORMERS(用于生成式预训练变换器的高精度训练后量化)
GPTQ :[2210.17323] GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
GPTQ (GPT Quantization) 是一种训练后量化 (Post-Training Quantization, PTQ) 方法,旨 在将预训练的 Transformer 模型权重精确地量化到低精度,而无需额外的训练数据。GPTQ 的 核心思想来源于 Optimal Brain Damage (OBD) 及其后续的优化方法。即其核心思想源自 Optimal Brain Damage (OBD),随后经过 OBS、 OBQ等优化,最终形成 GPTQ。
OBD (剪枝) -> OBS (剪枝) -> OBQ (量化) -> GPTQ (量化)。

逐层独立的量化(Layer-wise Independent Quantization)
GPTQ 不是一次性量化整个模型,而是逐层进行。
贪婪量化(Greedy Quantization based on Loss Minimization)
GPTQ 采用 逐个权重量化 的方式,而不是同时量化所有权重。
分组量化(Group-wise Quantization)
GPTQ 不是一个权重一个权重地量化,而是按小组(group)进行量化
int4 / fp16 混合精度量化 (W4A16)
GPTQ 采用了一种 混合精度(Mixed Precision)策略:
| 组件 | 精度 | 说明 |
|---|---|---|
| 权重(Weights) | int4 (4-bit 整数) | 体积减少 8 倍,节省存储和计算。 |
| 激活值(Activations) | fp16 (16-bit 浮点数) | 保持一定的计算精度,避免信息丢失。 |
GPTQ 加速了 OBQ,减少计算复杂度,使 Transformer 量化可行,兼顾效率和精度,成为高效 的 LLM 量化方案。
# 安装 auto-gptq 库,用于执行 GPTQ 量化
# pip install auto-gptq# 升级 accelerate, optimum 和 transformers 库,确保使用最新版本以获得最佳兼容性和功能
# pip install --upgrade accelerate optimum transformers# 从 transformers 库导入必要的类
from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig# 指定要量化的预训练模型的 ID (这里是 Facebook 的 OPT-125m 模型)
model_id = "facebook/opt-125m"# 使用 AutoTokenizer 加载与指定模型 ID 对应的 tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id)# 配置 GPTQ 量化的参数
gptq_config = GPTQConfig(bits=4, # 将模型权重进行 4 比特量化dataset="c4", # 使用 "c4" 数据集进行量化校准tokenizer=tokenizer # 将加载的 tokenizer 传递给 GPTQ 配置
) # GPTQ 量化 参数# 使用 AutoModelForCausalLM 加载预训练模型,并应用 GPTQ 量化
quantized_model = AutoModelForCausalLM.from_pretrained(model_id,device_map="auto", # 自动将模型分配到可用的设备 (GPU 或 CPU)quantization_config=gptq_config # 应用之前定义的 GPTQ 配置
) # 进行 量化 操作# 保存量化后的模型到本地目录 "opt-125m-gptq"
quantized_model.save_pretrained("opt-125m-gptq") # 保存 量化 后 的 模型# 保存模型的 tokenizer 到相同的本地目录
tokenizer.save_pretrained("opt-125m-gptq") # 保存 模型 字典 文件三、AWQ量化
AWQ:Activation-aware Weight Quantization for LLM Compression and Acceleration(用于 LLM 压缩和加速的激活感知权重的量化)。
原论文地址:https://arxiv.org/pdf/2306.00978。
源码:https://github.com/mit-han-lab/llm-awq。
AWQ发现,模型的权重并不同等重要,权重中有一小部分突出的权重(salient weights)对模型精度至关重要。只要跳过这一部分权重的量化,就可以很大程度上提高量化后的模型精度。作者发现仅保留0.1%-1%的权重通道为FP16格式,可以显著提高量化模型的性能。这表明基于激活分布选择关键权重是有效的。
所以如何来找到这0.1%-1%的权重通道是至关重要的:


在FP16中保持较小的权重分数(0.1%-1%),在四舍五入到最近(RTN)上显著提高了量化模型的性能。只有当我们通过观察激活分布而不是权重分布来选择 FP16 中的重要权重时,它才有效。我们用128的组大小使用INT3量化并测量了维基文本困惑度(↓)。
因此,基于激活值分布挑选显著权重是最为合理的方式。只要把这部分权重保持FP16精度,对其他权重进行低比特量化,就可以在保持精度几乎不变的情况下,大幅降低模型内存占用,并提升推理速度。
为了避免方法在实现上过于复杂,在挑选显著权重时,并非在“元素”级别进行挑选,而是在“通道(channel)”级别进行挑选,即权重矩阵的一行作为一个单位(attention是linear层)。在计算时,首先将激活值对每一列求绝对值的平均值,然后把平均值较大的一列对应的通道视作显著通道,保留FP16精度。对其他通道进行低比特量化,如下图:
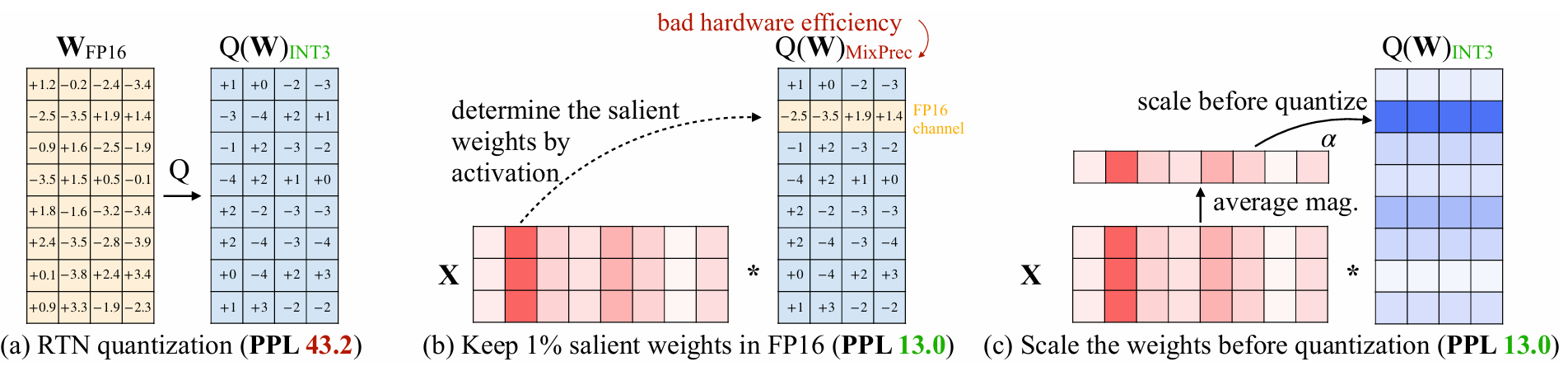 我们观察到,我们可以在LLMs基于激活分布(中)中找到1%的显著权重。保持FP16中的显著权重可以显著提高量化性能(PPL从43.2(左)到13.0(中)),但混合精度格式的硬件效率不高。我们遵循激活意识原则并提出AWQ(右)。AWQ执行每通道缩放顶保护突出权重和减少量化误差。我们测量OPT-6.7BunderINT3-g128量化的困惑度
我们观察到,我们可以在LLMs基于激活分布(中)中找到1%的显著权重。保持FP16中的显著权重可以显著提高量化性能(PPL从43.2(左)到13.0(中)),但混合精度格式的硬件效率不高。我们遵循激活意识原则并提出AWQ(右)。AWQ执行每通道缩放顶保护突出权重和减少量化误差。我们测量OPT-6.7BunderINT3-g128量化的困惑度