随机森林知识点整理:从原理到实战
🌲 随机森林:从原理到实战的一站式解析
在机器学习的世界里,面对复杂的数据和不完美的特征,我们很容易陷入“模型过拟合”或“泛化能力弱”的困境。有没有一种方法,能综合多个模型的判断,又具备强大的鲁棒性和可扩展性?这正是随机森林(Random Forest)登场的意义。
本文将系统梳理随机森林的核心原理、建模流程、调参策略、特征解释及其在工业级任务中的可扩展能力,并结合 Python 实践代码,为你构建全面的知识框架。
🌳 一、从集成学习谈起:人多力量大
集成学习(Ensemble Learning)通过将多个模型的结果进行整合,有效提升预测精度。它的核心理念就像咨询多个专家意见,而不是依赖一个“天才模型”。
其中最常用的两种策略是:
- Bagging(Bootstrap Aggregating):使用有放回抽样创建多个数据子集,在每个子集上训练模型,再进行结果汇总。
- Boosting:按顺序训练多个模型,每个模型都在前一个模型的“错误”上进行优化。
而随机森林正是建立在 Bagging 基础之上的典型集成算法,使用的是**决策树(Decision Tree)**作为基础学习器。
🌲 二、随机森林的工作机制
✨ 两大关键机制:
-
自举采样(Bootstrap Sampling):
每棵树训练的数据都是从原始数据中有放回抽样得到的,这保证了树之间的数据差异性。 -
特征随机子集选择:
在每个树节点分裂时,并不是查看所有特征,而是随机选择一部分特征再进行最优划分,这一步进一步增强了模型的多样性,降低过拟合风险。
📦 算法流程简述:
- 构建多个 bootstrap 数据集。
- 在每个子集上训练一棵决策树(只考虑随机选定的特征子集)。
- 将所有树的预测结果进行聚合:分类问题取投票多数,回归问题取平均。
🛠 三、模型训练与调参流程(附代码)
1️⃣ 数据准备与模型构建
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_splitX_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)
clf = RandomForestClassifier(random_state=0)
clf.fit(X_train, y_train)
2️⃣ 超参数详解
| 参数名 | 含义 | 建议设置 |
|---|---|---|
n_estimators | 森林中树的数量 | 100-500,越多越稳定 |
max_depth | 每棵树的最大深度 | 控制复杂度,避免过拟合 |
min_samples_split | 节点拆分所需最小样本数 | 2-10,越大越保守 |
min_samples_leaf | 叶节点的最小样本数 | 可防止单一数据分支 |
max_features | 每个分裂考虑的特征数量 | 通常设为 sqrt(n_features) |
3️⃣ 使用网格搜索调参(GridSearchCV)
from sklearn.model_selection import GridSearchCV, PredefinedSplitparam_grid = {'n_estimators': [100, 150],'max_depth': [None, 10, 20],'min_samples_split': [2, 4],'min_samples_leaf': [1, 2],'max_features': [3, 4, 5]
}custom_cv = PredefinedSplit([0 if i in X_val.index else -1 for i in X_train.index])
rf = RandomForestClassifier(random_state=0)grid_search = GridSearchCV(rf, param_grid, cv=custom_cv, scoring='f1', refit=True)
grid_search.fit(X_train, y_train)best_model = grid_search.best_estimator_
print("Best Params:", grid_search.best_params_)
🔍 四、特征重要性可视化
通过 feature_importances_ 属性,我们可以分析模型是如何做出决策的。
import matplotlib.pyplot as plt
import pandas as pddef plot_feature_importance(model, X):importances = model.feature_importances_features = X.columnsindices = importances.argsort()[-10:]plt.figure(figsize=(8, 6))plt.barh(features[indices], importances[indices])plt.xlabel("Importance")plt.title("Top 10 Feature Importances")plt.show()
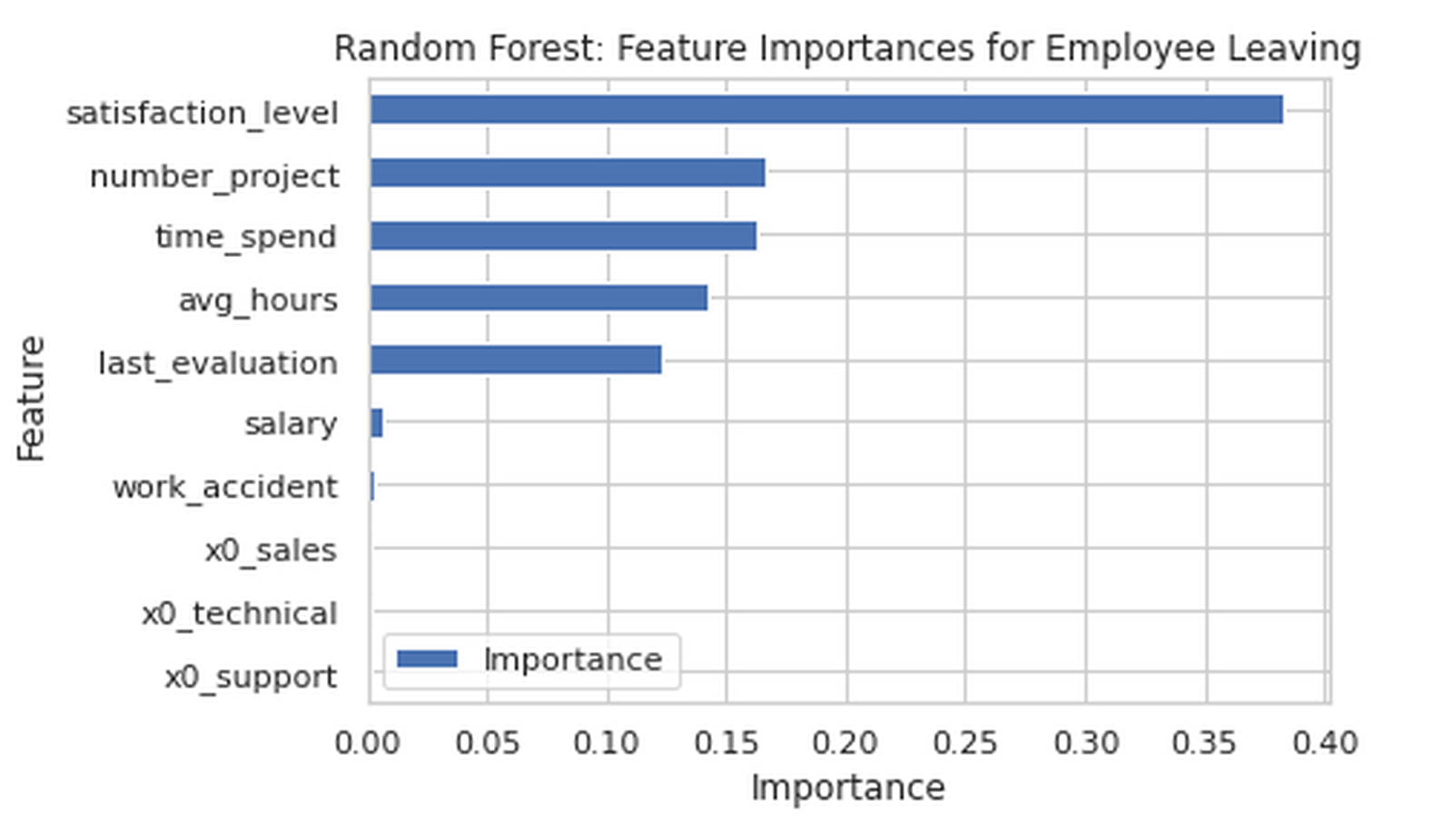
该图直观展示了哪些变量在模型预测中起主导作用,非常适合与业务部门沟通模型洞察。
🧠 五、并行化与可扩展性分析
✅ 并行训练与预测
由于每棵树是独立训练的,随机森林天然支持并行计算。在 scikit-learn 中,我们可以使用 n_jobs=-1 启用多核计算:
RandomForestClassifier(n_jobs=-1)
✅ 大规模数据适应性
在大数据场景中,随机森林可在分布式平台(如 Spark MLlib)中运行,或使用 GPU 加速的实现(如 LightGBM 的 RF 模式)。
📈 六、与 Boosting 模型对比
| 比较维度 | 随机森林 | Boosting(如 XGBoost) |
|---|---|---|
| 训练方式 | 并行建树 | 顺序建树 |
| 目标优化 | 减少方差 | 减少偏差 |
| 计算效率 | 更快,可分布式 | 相对较慢 |
| 对噪声敏感性 | 低(鲁棒) | 相对较高 |
| 泛化能力 | 稳定但可能略逊 | 通常更优(调好后) |
📦 七、模型保存与部署
随机森林模型训练时间较长,建议使用 pickle 进行序列化保存:
import pickle# 保存模型
with open("rf_model.pkl", 'wb') as f:pickle.dump(best_model, f)# 加载模型
with open("rf_model.pkl", 'rb') as f:loaded_model = pickle.load(f)
这在生产部署中尤其重要。
✅ 总结
随机森林作为一种成熟、鲁棒且高度可扩展的模型,在实际项目中表现出色。其优点总结如下:
- 🌱 抗过拟合能力强,适合结构复杂的数据
- ⚙️ 可调节性强,适合模型工程师优化模型性能
- 🔍 可解释性强,适合业务沟通和特征分析
- ⚡ 支持大规模并行计算,适合生产级部署
无论你是数据分析新手,还是需要模型部署的工程师,掌握随机森林,都是你构建强大机器学习系统的重要一步。
📝 下一步建议:
不妨用一个真实的业务场景(如员工流失预测、信用违约识别等),将随机森林应用起来,你会在调参、解释与业务对接中收获更多实际经验。