机器学习之决策树(二)
基于决策树的电信客户流失预测模型实现与解析
在客户关系管理中,电信客户流失预测是一项重要的任务。通过机器学习模型预测可能流失的客户,有助于企业采取针对性措施挽留客户。本文将详细解析如何使用决策树算法构建电信客户流失预测模型,并通过代码实现整个过程。
一、代码整体功能概述
这段代码主要实现了一个基于决策树的电信客户流失预测模型。整体流程包括:数据读取、数据集划分、处理类别不平衡问题、通过交叉验证寻找最优参数、模型训练与评估以及决策树可视化。通过这一系列步骤,我们可以构建一个性能较好的客户流失预测模型,为企业决策提供支持。
二、代码实现过程
1.关键库导入
代码开头导入了一系列必要的库,这些库在模型构建过程中发挥着重要作用:
import pandas as pd # 用于数据读取和处理
from sklearn.model_selection import train_test_split # 用于数据集划分
from sklearn.tree import DecisionTreeClassifier # 决策树分类器
from sklearn import metrics # 用于模型评估指标计算
from imblearn.over_sampling import SMOTE # 用于处理类别不平衡问题
from sklearn.model_selection import cross_val_score # 用于交叉验证
import numpy as np # 用于数值计算
import matplotlib.pyplot as plt # 用于绘图
from sklearn.tree import plot_tree # 用于决策树可视化这些库涵盖了从数据处理到模型构建、评估和可视化的各个环节,是完成整个机器学习任务的基础。
2.数据准备与划分
(1) 数据读取
data = pd.read_excel('电信客户流失数据.xlsx')这行代码读取了存储电信客户流失数据的 Excel 文件。数据集中包含了客户的各种属性信息以及是否流失的标签。在实际应用中,我们需要确保数据文件路径正确,并且数据格式符合要求。
(2)特征与标签分离
x = data.iloc[:, 0:-1] # 提取所有行,除最后一列外的所有列作为特征
y = data.iloc[:, -1] # 提取所有行的最后一列作为标签(是否流失)这里使用iloc方法对数据进行切片,将特征和标签分离。通常,我们将特征矩阵记为x,标签向量记为y,这种表示方式在机器学习中是比较规范的。
(3) 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=100)train_test_split函数将数据集划分为训练集和测试集,其中test_size=0.2表示测试集占总数据的 20%,random_state=100用于保证每次运行划分结果一致,便于实验复现。训练集用于模型训练,测试集用于评估模型泛化能力。
3.处理类别不平衡问题
在客户流失预测中,通常流失的客户占比较少,导致数据集中类别不平衡,这会影响模型的性能,尤其是召回率。代码中使用 SMOTE 算法来处理这个问题:
oversampler = SMOTE(random_state=0)
x1, y1 = oversampler.fit_resample(x_train, y_train)SMOTE(Synthetic Minority Over-sampling Technique)是一种常用的过采样方法,它通过为少数类生成合成样本,来平衡数据集。fit_resample方法对训练集进行处理,得到平衡后的特征x1和标签y1。处理后的数据更有利于模型学习到少数类(流失客户)的特征,提高模型对流失客户的识别能力。
4.参数调优(网格搜索思想)
为了找到决策树的最优参数,代码采用了网格搜索的思想,遍历不同的参数组合,通过交叉验证选择性能最好的参数:
max_recall = -1
best_params = None
# 定义参数搜索范围
md = [5, 6, 7, 8, 9] # max_depth参数候选值
mss = [3, 4, 5, 6, 7] # min_samples_split参数候选值
msl = [9,10,11,12,13] # min_samples_leaf参数候选值# 遍历所有参数组合
for i in md:for j in mss:for k in msl:dt = DecisionTreeClassifier(max_depth=i, min_samples_split=j, min_samples_leaf=k, random_state=100)# 5折交叉验证,以召回率为评价指标cv_score = cross_val_score(dt, x1, y1, cv=5, scoring='recall')current_mean = cv_score.mean()# 更新最优参数if current_mean > max_recall:max_recall = current_meanbest_params = (i, j, k)max_depth:决策树的最大深度,控制树的复杂度,过深可能导致过拟合。
min_samples_split:分裂内部节点所需的最小样本数,值越大,树越简单。
min_samples_leaf:叶节点所需的最小样本数,同样影响树的复杂度。
通过 5 折交叉验证,以召回率为评价指标,选择召回率最高的参数组合作为最优参数。这里选择召回率作为评价指标,是因为在客户流失预测中,我们更关注尽可能多地识别出可能流失的客户,避免漏判。
最后输出最优参数结果:
print(f"最高交叉验证召回率: {max_recall:.4f}")
print(f"最优参数组合:")
print(f" max_depth: {best_params[0]}")
print(f" min_samples_split: {best_params[1]}")
print(f" min_samples_leaf: {best_params[2]}")5.模型训练与评估
(1)模型训练
使用找到的最优参数构建决策树模型,并在平衡后的训练集上进行训练:
best_dt = DecisionTreeClassifier(max_depth=best_params[0],min_samples_split=best_params[1],min_samples_leaf=best_params[2],random_state=100)
best_dt.fit(x1, y1)fit方法用于模型训练,通过学习训练集中的特征与标签之间的关系,构建决策树模型。
(2)模型评估
使用训练好的模型对测试集进行预测,并评估模型性能:
y_test_pred = best_dt.predict(x_test)
print("\n测试集评估结果:")
print(metrics.classification_report(y_test, y_test_pred))
test_recall = metrics.recall_score(y_test, y_test_pred)
print(f"\n测试集召回率: {test_recall:.4f}")classification_report函数提供了精确率、召回率、F1 值等多个评估指标,全面反映模型在测试集上的表现。而单独输出测试集召回率,是为了与交叉验证时的召回率进行对比,判断模型是否存在过拟合或欠拟合现象。
如果测试集召回率与交叉验证时的召回率相差不大,说明模型泛化能力较好;如果相差较大,则需要进一步调整模型或参数。
6.决策树可视化
为了更直观地理解决策树的决策过程,代码对训练好的最优决策树进行了可视化:
fig, ax = plt.subplots(figsize=(32, 32))
plot_tree(best_dt, filled=True, ax=ax)
plt.show()plot_tree函数可以绘制决策树,filled=True表示根据节点的类别对节点进行着色,便于区分。设置较大的figsize是为了保证决策树的细节能够清晰显示。
通过可视化的决策树,我们可以看到每个节点的分裂条件、样本数量、类别分布等信息,有助于理解模型是如何进行决策的,也为业务人员提供了可解释性的依据。
三、完整代码及运行结果
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn import metrics
from imblearn.over_sampling import SMOTE
from sklearn.model_selection import cross_val_score
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
data= pd.read_excel('电信客户流失数据.xlsx')
x = data.iloc[:, 0:-1]
y = data.iloc[:, -1]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=100)
oversampler = SMOTE(random_state=0)
x1, y1 = oversampler.fit_resample(x_train, y_train)
max_recall = -1
best_params = None
md = [5, 6, 7, 8, 9]
mss = [3, 4, 5, 6, 7]
msl = [9,10,11,12,13]
for i in md:for j in mss:for k in msl:dt = DecisionTreeClassifier(max_depth=i, min_samples_split=j, min_samples_leaf=k, random_state=100)cv_score = cross_val_score(dt, x1, y1, cv=5, scoring='recall')current_mean = cv_score.mean()if current_mean > max_recall:max_recall = current_meanbest_params = (i, j, k)
print(f"最高交叉验证召回率: {max_recall:.4f}")
print(f"最优参数组合:")
print(f" max_depth: {best_params[0]}")
print(f" min_samples_split: {best_params[1]}")
print(f" min_samples_leaf: {best_params[2]}")
best_dt = DecisionTreeClassifier(max_depth=best_params[0],min_samples_split=best_params[1],min_samples_leaf=best_params[2],random_state=100)
best_dt.fit(x1, y1)
y_test_pred = best_dt.predict(x_test)
print("\n测试集评估结果:")
print(metrics.classification_report(y_test, y_test_pred))
test_recall = metrics.recall_score(y_test, y_test_pred)
print(f"\n测试集召回率: {test_recall:.4f}")
fig,ax=plt.subplots(figsize=(32,32))
plot_tree(best_dt,filled=True,ax=ax)
plt.show()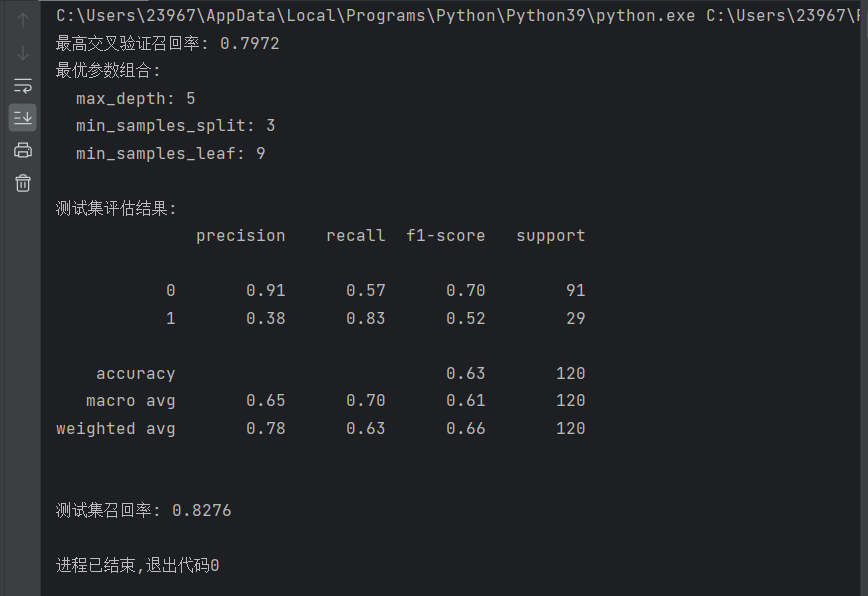
四、总结与展望
本文通过代码实现了一个基于决策树的电信客户流失预测模型,详细解析了从数据准备到模型评估和可视化的全过程。通过处理类别不平衡问题和参数调优,提高了模型对流失客户的识别能力。
在实际应用中,我们还可以尝试以下改进方向:
1.尝试更多的特征工程方法,如特征选择、特征转换等,提高特征质量。
2.对比其他机器学习算法(如随机森林、梯度提升树等)的性能,选择更优的模型。
3.进一步优化参数搜索范围,使用更高效的参数搜索方法(如随机搜索)。后续会继续进行学习