多模态大模型综述:BLIP-2详解(第二篇)
一、TL;DR
- 为什么提出: VLM全参训练参数量太大,直接训练有问题
- 怎么做: 增加一个Qformer模块大幅度减少参数量(54x)
- 怎么训练: 继承BLIP的预训练+图文生成式预训练
- 什么结果: 训练速度超快且效果SOTA
paper名称:Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. ICML2023
paper:https://arxiv.org/pdf/2304.08485
code:https://github.com/salesforce/LAVIS/tree/main/projects/blip2
二、核心框架
2.1 Framework
解决什么问题:
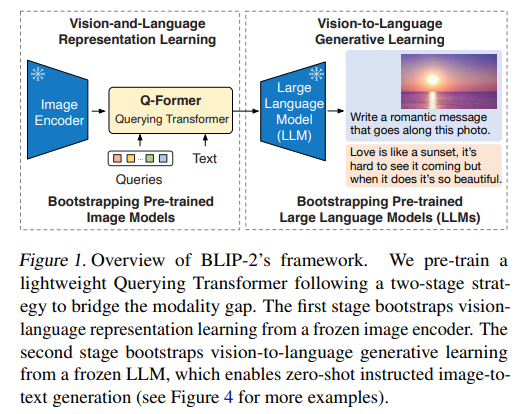
提出Qfomer(Query Transformer)模块用于对齐冻结后的语言和图像模块,解决了现有的VLM训练成本过高的问题
用什么方法:
利用Qformer连接freeze的VIT和LLM模块,仅仅只需要训练Q-former模块
取得了什么样的结果:
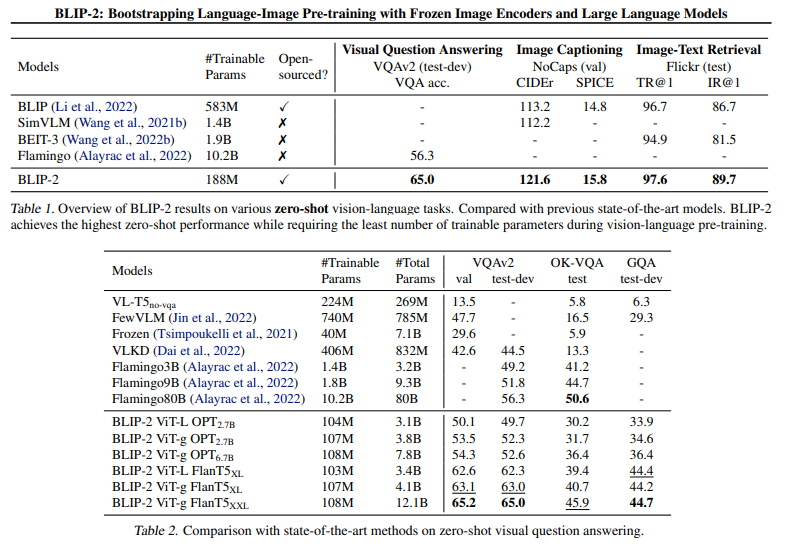
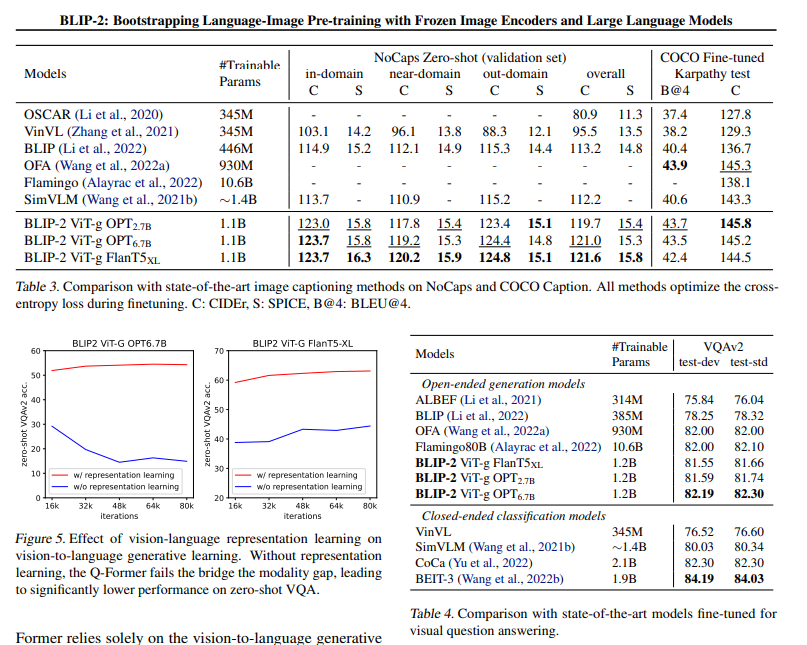
Qformer使用Bert初始化仅188M可训练参数,但在VQA(54x减少参数量)、图文描述、图文检索上实现SOTA
2.2具体方法
QFormer:
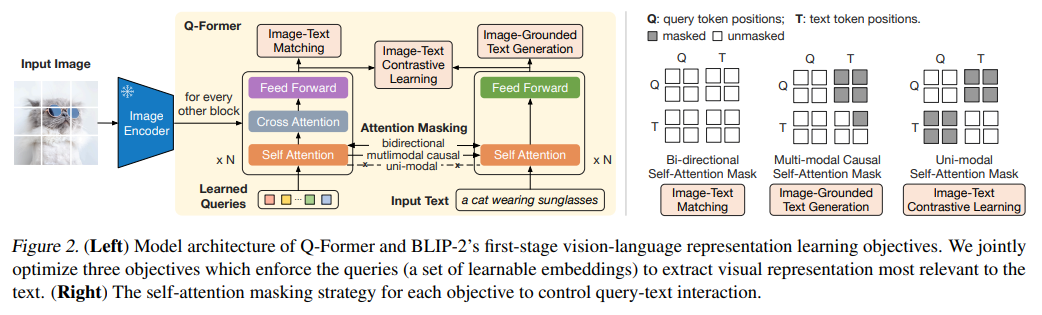
Q-Former 由两个transformer模块组成,共享相同的自注意力层:
- ImageTransformer:
- 冻结参数的Image Encoder提取的图像embeddings
- Learned Queries:Queries是一组可学习的embeddings,这些query和图像embeddings及逆行自注意力机制
- 本文采用ViT-L/14和EVA-CLIP训练过的ViT-g/14
- Text Transformer:
- 既作为文本编码器,也作为文本解码器
- 本文采用OPT和FlanT5
2.3 预训练方法
第一阶段-继承于BLIP,联合优化训练3个预训练目标:
-
图像 - 文本对比学习(ITC):旨在对齐图像表征和文本表征,以最大化它们的互信息。通过将正样本对的图像 - 文本相似度与负样本对的相似度进行对比来实现这一目标。
-
图像引导的文本生成(ITG)损失:训练 Q-Former 在输入图像作为条件的情况下生成文本。
-
图像 - 文本匹配(ITM):模型预测图像 - 文本对是正样本(匹配)还是负样本(不匹配)的二元分类任务。采用 Li 等人(2021;2022)的难负样本挖掘策略来创建具有信息量的负样本对(负样本是这样生成的)。
第二阶段-视觉到语言生成式学习:
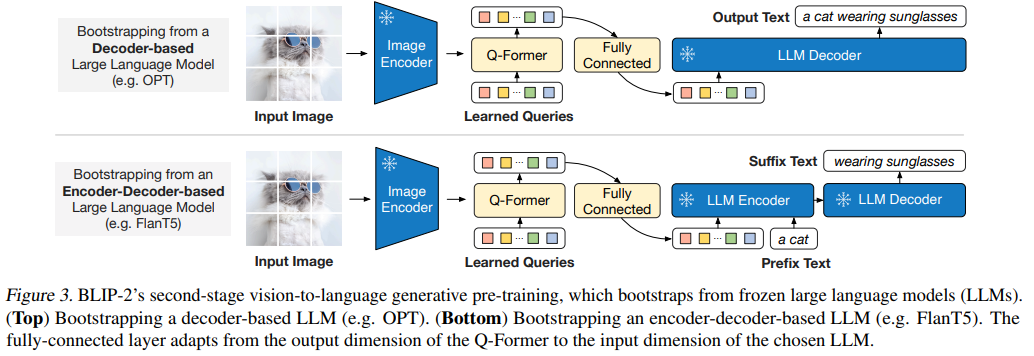
- 将 Q-Former(附加冻结的图像编码器)与冻结的 LLM 相连,以利用 LLM 的语言生成能力。
- 如图 3 所示,使用全连接(FC)层将输出查询嵌入 Z 线性投影到与 LLM 的文本嵌入相同的维度。
- 然后,将投影后的查询嵌入预先添加到输入文本嵌入中,它们充当 “软视觉提示”,使 LLM 以 Q-Former 提取的视觉表征为条件进行生成。
由于 Q-Former 已通过预训练学会提取与语言相关的视觉表征,它有效地充当了信息瓶颈,向 LLM 提供最有用的信息,同时过滤掉不相关的视觉信息。这减轻了 LLM 学习视觉 - 语言对齐的负担,从而缓解了灾难性遗忘问题。

三Experiments