深度学习-梯度爆炸与梯度消失
在深度学习的训练过程中,梯度爆炸和梯度消失是两个极为关键且常见的问题,它们对模型的训练效果和效率有着深远的影响。
1. 梯度爆炸
梯度爆炸:与梯度消失相反,梯度爆炸则表现为梯度在反向传播中逐渐增大,甚至可能趋向于无穷大。这就好比一个失控的雪球,在下坡过程中不断积累能量和体积,最终变得不可控制。梯度爆炸会使权重的更新幅度过大,导致模型的参数在训练过程中剧烈波动。
例如,在训练迭代过程中,原本模型的权重可能以合理的步长逐步调整,但一旦出现梯度爆炸,权重的更新可能会直接跳到一个完全不合适的区域,甚至超出数值范围,使得模型无法正常训练,损失函数无法稳定收敛,严重时甚至可能导致训练完全失败,模型输出的误差反而越来越大,陷入一种 “学习失控” 的状态。
具体的例子:在训练一个图像分类模型时,输入的图片是猫狗的面部特写。如果梯度爆炸,模型可能会在某次更新后突然把一张猫的图片预测成狗,而下一次又因为巨大的梯度反向调整,又把同张图片预测成猫。这种剧烈的波动就像开车时突然猛踩油门又急刹车,最终导致训练过程完全失控。


2. 梯度消失
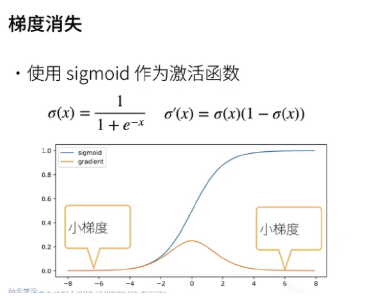
梯度消失:当神经网络的层数较深时,梯度在反向传播过程中会逐渐变小,甚至趋近于零。这就像一场信号衰减的旅程,随着网络深度的增加,来自后续层的梯度信号在向前传递时不断减弱。对于浅层网络来说,梯度消失可能还不明显,但当网络达到一定深度,如十几层甚至更深时,这种现象就会变得十分突出。
由于梯度过小,位于网络前几层的权重更新速度会变得极其缓慢,几乎可以忽略不计,这导致模型在训练初期可能会长时间停滞不前,仿佛陷入了一个学习的 “瓶颈期”,无法有效调整前几层的参数来降低损失函数。
具体的例子:在训练一个用于文本摘要的模型时,如果输入的新闻文章很长,梯度消失可能导致模型完全忽略文章开头的关键信息(如新闻的主题)。就好比一个人试图复述一篇长文章,但只记得最后几句话,完全忘了开头的主旨,最终生成的摘要毫无逻辑。


为应对这些问题,研究人员提出了多种方法。
- 针对梯度消失,可以采用合适的激活函数,如 ReLU(它在正区间的梯度为 1,能有效缓解梯度消失),或者对权重进行更好的初始化,使得训练初期的梯度能够更合理地传播。
- 对于梯度爆炸,常用的手段有梯度裁剪(在每次更新时将梯度限制在一个合理的范围之内),以及合理调整学习率,避免学习率过大导致权重更新过于剧烈。
这些策略在一定程度上可以帮助我们克服深度学习训练中的梯度难题,提高模型的训练效率和性能,确保模型能够稳定地学习和收敛,从而更好地完成复杂的任务,如图像识别CV、自然语言处理NLP等。
3. model.eval()用法
model.eval() 只做一件事:把网络中所有具有“训练/推理双模式”的层切换到“推理模式”。
哪些层会受影响?
Dropout:训练时随机置零,推理时全部保留。
BatchNorm:训练时用当前 batch 的均值/方差,推理时用滑动平均的均值/方差。
任何自定义的
self.training判断逻辑。
如果不调用 eval() 会怎样?
Dropout 继续随机掉神经元 → 输出每次都不一样。
BatchNorm 用当前 batch 统计量 → 结果抖动,严重时数值爆炸。
与 torch.no_grad() 的区别
model.eval()改行为(层内部计算方式)。torch.no_grad()关梯度(省显存、加速)。两者常常连用:
model.eval()
with torch.no_grad():out = model(x)