江协科技STM32 11-4 SPI通信外设
STM32内部集成了硬件SPI收发电路,可以由硬件自动执行时钟生成、数据收发等功能,减轻CPU的负担。可配置8位/16位数据帧、高位先行/低位先行,这里,我们最常用的配置就是8位数据帧,高位先行;时钟频率就是SCK波形的频率,一个SCK时钟交换一个bit,所以时钟频率一般体现的是传输速度,单位时Hz或者bit/s。这里的时钟频率是 fPCLK /分频系数 (2, 4, 8, 16, 32, 64, 128, 256)。所以可以看出,SPI的时钟其实就是由PCLK分频得来的,PCLK就是外设时钟。SPI1和SPI2挂载的总线是不一样的,SPI1挂载在APB2,PCLK是72M,SPI2挂载在APB1,PCLK是36M。支持多主机模型、主或从操作;可精简为半双工/单工通信。
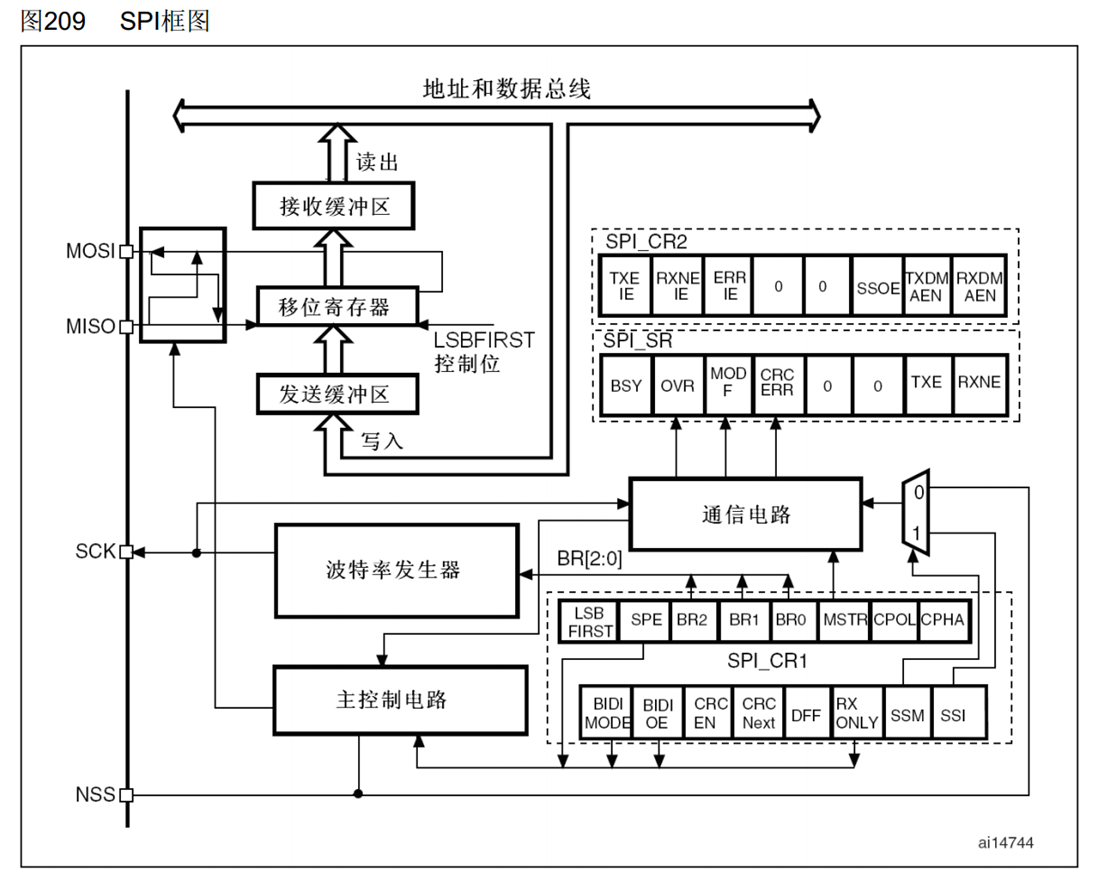
接下来我们来看一下SPI的框图,整体上我们可以大致把它分为两部分,左上角这一部分就是数据寄存器和移位寄存器打配合的过程,主要是为了实现连续的数据流,一个个数据前仆后继的效果。右下角的部分就是一些控制逻辑了,寄存器的哪些位,控制哪些部分,会产生哪些效果可以通过手册的寄存器描述来得知。
首先,左上角,核心部分,就是这个移位寄存器。右边的数据低位,一位一位地从MOSI移出去,然后MISO的数据一位一位地移入到左边的数据高位。显然移位寄存器应该是一个右移的状态,所以目前图上表示的是低位先行的配置。对应右下角有一个LSBFIRST控制位,这一位可以控制是低位先行还是高位先行。如果LSBFIRST给0,高位先行的话这个图还要变动一下,就是移位寄存器变为左移,输出从左边移出去,输入从右边移进来。继续看左边这一块,这里画了一个方框,里面把MOSI和MISO做了个交叉,这一块主要是用来进行主从模式引脚变换的。SPI外设可以做主机也可以做从机,做主机时这个交叉就不用,MOSI为MO,主机输出;MISO为MI,主机输入。如果我们STM32作为从机的话,MOSI为SI,从机输入,这时它就要走交叉的这一路输入到移位寄存器,同理MISO为SO,从机输出,这时输出的数据也走交叉的这一路输出到MISO。简而言之就是主机和从机的输入输出模式不同,如果需要切换主机和从机的话线路就需要交叉一下。
接下来两个缓冲区,就还是我们熟悉的设计。这两个缓冲区实际上就是数据寄存器DR,下面发送缓冲区就是发送数据寄存器TDR,上面接收缓冲区就是接收数据寄存器RDR。和串口那里一样,TDR和RDR占用同一个地址,统一叫做DR。数据寄存器和移位寄存器搭打配合可以实现连续的数据流。具体流程就是比如我们需要连续发送一批数据,第一个数据写入到TDR,当移位寄存器没有数据来进行移位时,TDR的数据回立刻转入移位寄存器开始移位,这个转入时刻会置状态寄存器TXE为1,表示发送数据寄存器空,当我们检查TXE置1后,紧跟着下一个数据就可以提前写到TDR里候着了,一旦上一个数据发完,下一个数据就可以立刻跟进,实现不间断的连续传输。然后移位寄存器这里一旦有数据过来了它就会自动产生时钟把数据移出去。在移出的过程中,MISO的数据也会移入,一旦数据移出完成,数据移入也完成了。这时移入的数据就会整体地从移位寄存器转入到接收缓冲区RDR。这个时刻会置状态寄存器地RXNE为1,表示接收数据寄存器非空。当我们检查RXNE置1后,就要尽快把数据从RDR读出来,在下一个数据到来之前读出RDR,就可以实现连续接收。否则如果下一个数据已经收到了,上一个数据还没从RDR读出来,那RDR的数据就会被覆盖,就不能实现连续的数据流了。这就是移位寄存器配合数据寄存器实现连续数据流的过程。
当然,这个数据流的实现和之前串口I2C的区别在于SPI是全双工,发送和接收同步进行,所以它的数据寄存器,发送和接收是分离的,而移位寄存器,发送和接收可以共用;I2C因为是半双工,发送和接收不会同时进行,所以它的数据寄存器和移位寄存器发送和接收都是公用的;串口是全双工,并且发送和接收可以异步进行,所以这就要求它的数据寄存器发送和接收是分离的,移位寄存器发送和接收也得是分离的。
接下来我们看一下右下角的内容,这就是一些控制逻辑了,首先是波特率发生器,这个主要就是用来产生SCK时钟的,它的内部主要就是一个分频器,输入时钟是PCLK,72M或36M,经过分频器之后输出到SCK引脚,当然这里生成的时钟肯定是和移位寄存器同步的。然后右边CR1寄存器的三个位BR0、BR1、BR2用来控制分频系数,这就是波特率发生器部分,接着后面这些通信电路和各种寄存器都是一些黑盒子电路,CR1寄存器中:SPE(SPI Enable),是SPI使能,就是SPI_Cmd函数配置的位;MSTR(Master),配置主从模式;CPOL和CPHA用来选择SPI的4种模式。SR状态寄存器中:TXE为发送寄存器空;RXNE为接收寄存器非空。CR2寄存器中就是一些使能位了,比如中断使能,DMA使能等。
最后最左下角还有一个NSS引脚,SS就是从机选择,低电平有效,所以这里前面加了个N,这个NSS和我们想象的从机选择可能不太一样。我们想象的应该是用来指定某个从机,但是根据手册里的描述,这里的NSS设计更偏向于实现多主机模型的功能。所以这个NSS在本次实验不会被用到。SS引脚我们直接使用一个GPIO模拟就行,因为SS引脚很简单,就置一个高低电平就行了,而且多从机的情况下,SS还会有多个,这里硬件的NSS也完成不了我们想要的功能。
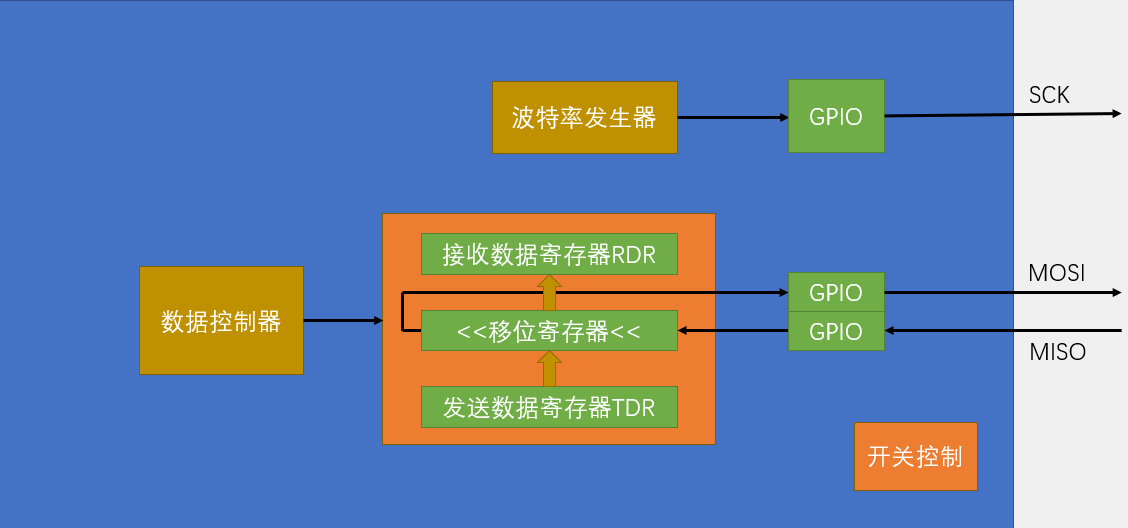
看完了详细框图,我们再来看一下总结的简化结构,其中核心部分当然是这个数据寄存器和移位寄存器了,移位寄存器是左移状态,高位移出去通过GPIO到MOSI,从MOSI输出,显然这是SPI的主机,之后移入的数据从MISO进来,通过GPIO到移位寄存器的低位,这样循环8次,就能实现主机和从机交换一个字节,然后TDR和RDR的配合可以实现连续的数据流。另外TDR数据整体移入移位寄存器的时刻置TXE标志位;移位寄存器整体转入RDR的时刻,置RXNE标志位。然后剩下的部分,波特率发生器,产生时钟,输出到SCK引脚。数据控制器就看成是一个管理员,它控制着所有电路的运行,最后开关控制就是SPI_Cmd,初始化之后给个ENABLE,使能整个外设。另外,这里并没有画SS,从机选择引脚,这个引脚我们还是使用普通的GPIO口来模拟即可,在一主多从的模型下,GPIO模拟的SS是最佳选择。
初始化部分解决之后,就要看一些运行控制的部分了,如何来产生具体的时序呢,什么时候写DR,什么时候读DR呢?我们接下来进行讲解。读写DR,产生时序的流程,主要看下面两个时序图。
第一个是主模式全双工连续传输,这个图演示的是借助缓冲区,数据前仆后继,实现连续数据流的过程,但是这个流程稍微比较复杂,也不太方便封装,所以在实际过程中,如果对性能没有极致的追求,我们更倾向使用下面这个非连续传输的示意图。这个非连续传输使用起来更加简单,实际使用的话只需要4行代码就能完成任务了
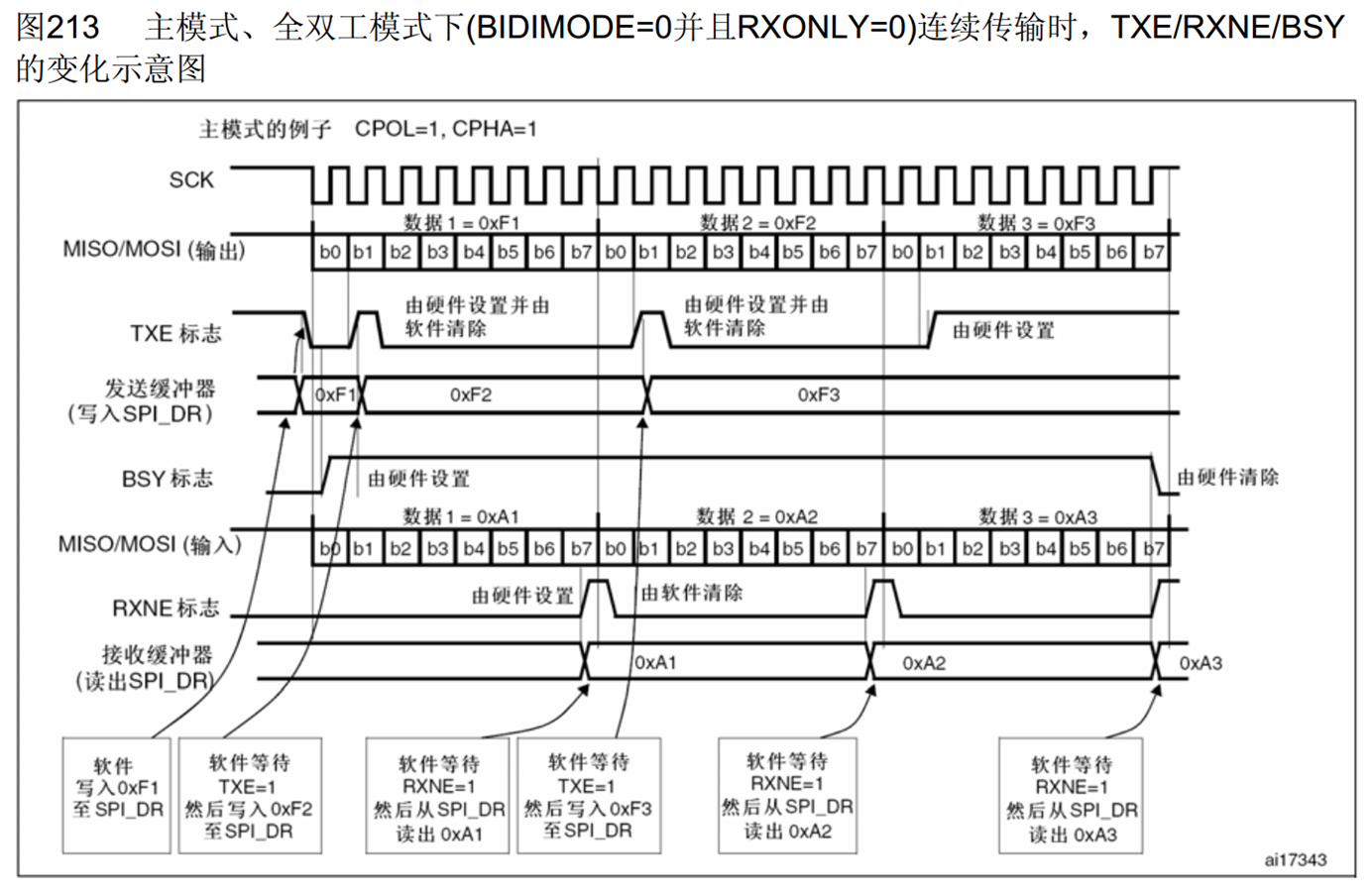
先看一下主模式全双工连续传输的示意图,首先,第一行是SCK时钟线,这里CPOL=1,CPHA=1,示例使用的是SPI模式3,所以SCK默认是高电平,然后在第一个下降沿,MOSI和MISO移出数据,之后上升沿移入数据,依次这样来进行;第二行是MOSI和MISO输出的波形,跟随SCK时钟变换,数据位依次出现。这里从前到后依次出现的是b0、b1一直到b7,所以这里实例演示的是低位先行的模式;第三行是TXE,发送寄存器空标志位;第四行是发送缓冲器(写入SPI_DR),实际上就是这里的TDR;BSY(BUSY)是由硬件自动设置和清除的,当有数据传输时,BUSY置1。
上面这部分,演示的就是输出的流程和现象。下面就是输入的流程和现象,第一个是MISO/MOSI的输入数据,之后是RXNE,接收数据寄存器非空标志位,最后是接收缓冲器(读出SPI_DR),显然就是RDR。
了解完各个信号的定义,我们来从左到右依次分析。首先SS置低电平开始时序,在刚开始时,TXE为1,表示TDR为空,可以写入数据开始传输。然后下面指示的第一步就是软件写入0xF1至SPI_DR(TDR),0xF1就是要发送的第一个数据。之后可以看到,写入之后,TDR变为0xF1,同时TXE变为0,表示TDR已经有数据了,那此时,TDR是等候区,移位寄存器才是真正的发送区。移位寄存器在刚开始肯定没有数据,所以在等候区TDR里的F1就会立刻转入移位寄存器,开始发送。转入瞬间置TXE标志为1,表示发送寄存器空。然后移位寄存器有数据了,波形就自动开始生成。在移位产生F1波形的同时,等候区TDR是空的,为了移位完成时,下一个数据能不间断地跟随,这里就要提早把下一个数据写入到TDR里等着了,所以下面指示第二步地操作是写入F1之后,软件等待TXE=1,在0xF1转移到数据移位寄存器地位置,TDR空了,我们就写入F2至SPI_DR,写入之后可以看到,TDR的内容就变成了F2,也就是把下一个数据放到TDR里候着,之后的发送流程也是同理,F1数据波形产生完毕后,F2转入移位寄存器开始发送,这时TXE=1,我们尽快把下一个数据F3放到TDR里等着,这就是0xF2被转移到数据移位寄存器之后的操作(软件等待TXE=1,然后写入F3至DR),写入之后TDR变为F3。最后如果我们只想发送3个字节的数据,F3转入移位寄存器之后,TXE=1,我们就不需要继续写入了,TXE之后一直是1。注意在最后一个TXE=1之后,还需要继续等待一段时间,F3的波形才能完整发送。等波形全部完整发送之后,BUSY标志由硬件清除,这才表示波形发送完成了,这些就是发送的流程。
然后继续看一下下面接收的流程,SPI是全双工,发送的同时,还有接收,所以可以看到,在第一个字节发送完成后,第一个字节的接收也完成了,接收到的数据1是A1。这时,移位寄存器的数据整体转入RDR,RDR随后存储的就是A1,转入的同时,RXNE标志位也置1,表示收到数据了。我们的操作是在下面写的软件等待RXNE=1,=1表示收到数据了,然后从SPI_DR,也就是RDR,读出数据A1,这就是第一个接收到的数据。接收之后,软件清除RXNE标志位,然后当下一个数据2收到之后,RXNE重新置1,我们监测到RXNE=1时,就继续读出RDR,这时第二个数据A2。最后,在最后一个字节时序完全产生之后,数据3才能收到。然后注意一个字节波形收到后,移位寄存器的数据自动转入RDR,会覆盖原有的数据,所以我们读取RDR要及时。比如A1数据,收到之后,最迟你也要在数据2被完全循环置换前读走,否则置换完成后下一个数据A2就会覆盖A1,就不能实现连续数据流的接收了。这就是整个发送和接收的流程。这个连续数据流,对软件的配合要求较高,在每个标志位产生后,你的数据都要及时处理,配合的好时钟可以连续不间断地产生,每个字节之间没有任何空隙,具有很高的传输效率,但是很容易出错,对程序设计有很高要求。
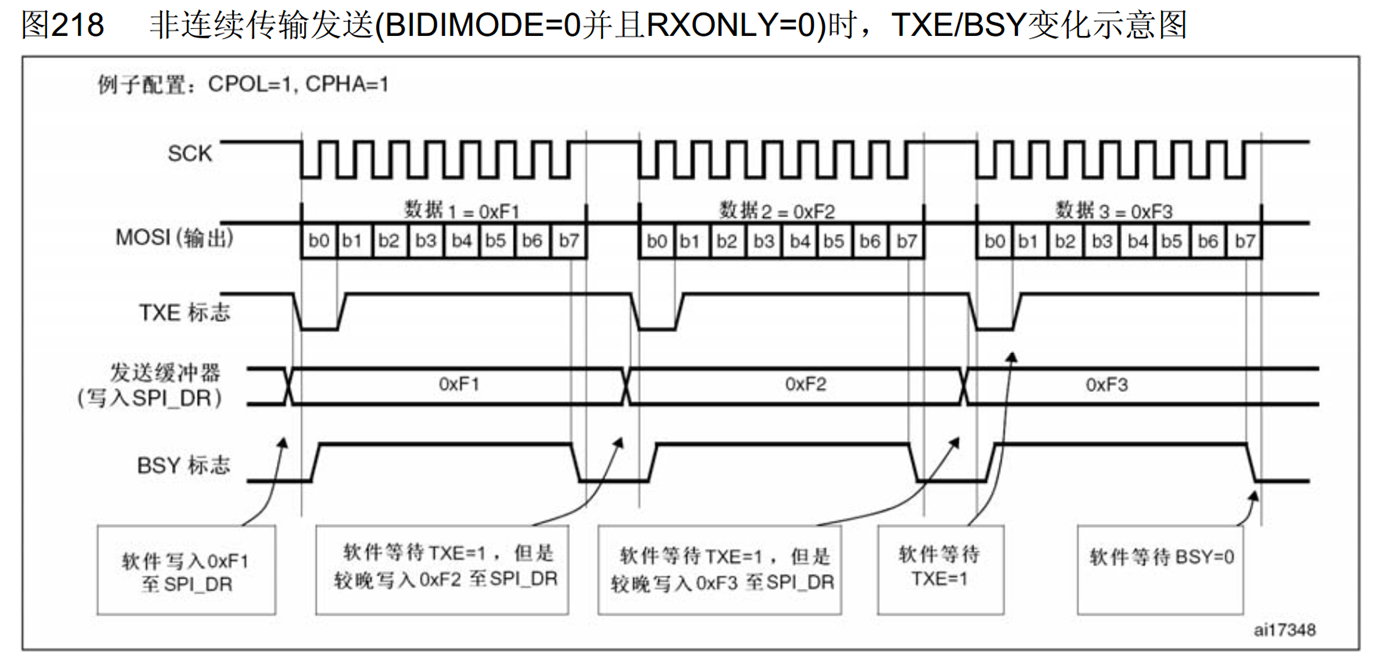
除非对传输效率有很高要求,否则更推荐使用下面的非连续传输,其对程序设计更加友好。下面是一个非连续传输发送的时序图,只有发送的一些波形,现在我们来看一下这个非连续传输和连续传输有什么区别呢。首先这个配置还是SPI模式3,SCK默认高电平。我们想发送数据时,如果检测到TXE=1了、TDR为空,就软件写入0xF1至SPI_DR(TDR),这时TDR的值变为F1,TXE变为0,目前移位寄存器也是空状态,所以这个F1会立刻转入移位寄存器开始发送,波形产生,并且TXE置回1,表示你可以把下一个数据放在TDR里候着了,但是现在区别就来了,在连续传输的这里,一旦TXE=1了,我们就会把下一个数据写到TDR里候着,这样是为了连续传输,数据衔接更紧密,但是这样的话流程比较混乱,程序写起来比较复杂。所以在非连续传输这里,TXE=1了,我们不着急把下一个数据写进去,而是一直等待,等到第一个字节时序结束,意味着接收第一个字节完成的时刻,这时接收的RXNE会置1,我们等待RXNE置1后,先把第一个接收到的数据读出来,之后再写入下一个字节数据。也就是最下方第二个箭头中的软件等待TXE=1,但是较晚写入0XF2至SPI_DR(TDR),较晚写入TDR后,数据2开始发送,我们还是不着急写数据3,等到了第三个箭头,先把接收的数据2留着,再继续写入数据3。数据3时序结束后,最后再接收数据3置换回来的数据。
按照这个流程,我们的整个步骤就是
1.等待TXE为1
2.写入发送的数据至TDR
3.等待RXNE为1
4.读取RDR接收的数据
之后交换第二个字节,重复这4步。这样我们就可以把这4步封装到一个函数,调用一次,交换一个字节,这样程序逻辑就非常简单了。
这就是非连续传输的流程,非连续传输,其缺点就是,在TDR中的值转移到数据移位寄存器后,没有把下一个数据写入TDR中等候,所以等到第一个字节时序完成后,第二个字节还没有送过来,那这个数据传输就会在原地等着,所以这里的时钟和数据的时序在字节与字节之间会产生间隙,拖慢了整体数据传输的速度。这个间隙在SCK频率低的时候影响不大,但是在SCK频率非常高时,间隙拖后腿的现象就比较严重了。
对应硬件SPI的初始化,分为以下步骤:
1.开启时钟,开启SPI和GPIO的时钟
2.初始化GPIO口,其中SCK和MOSI是由硬件外设控制的输出信号,所以配置为复用推挽输出;MISO是硬件外设的输入信号,可以配置为上拉输入,因为输入设备可以有多个,所以不存在复用输入这个东西。最后还有SS引脚,SS是软件控制的输出信号,所以配置为通用推挽输出,这就是GPIO口的初始化配置。
3.配置SPI外设,使用一个结构体选参数即可。调用以下SPI_Init,这里面的各种参数比如8位/16位数据帧、高位先行/低位先行,SPI模式几、主机还是从机,等等就都配置好了。
4.开关控制,调用SPI_Cmd,给SPI使能即可
初始化之后我们参考非连续传输的时序来执行运行控制的代码,这样就能产生交换字节的时序了。这些操作涉及的具体函数主要就是写DR、读DR和获取状态标志位这些。
下面我们介绍SPI库函数中所用到的函数,除了之前已经介绍过的相关功能相似的函数之外。新增的函数有:SPI_I2S_SendData,实际上就是写DR数据寄存器;SPI_I2S_ReceiveData,实际上就是读DR寄存器;SPI_NSSInternalSoftwareConfig函数进行NSS引脚的配置;SPI_DataSizeConfig函数进行8位或16位数据帧的配置;SPI_BiDirectionalLineConfig函数对半双工时,双向线的方向进行配置。