电商项目_性能优化_高并发缓存一致性
如果说要对你的项目进行优化,最先想到的就是使用缓存。说到缓存,最先想到Redis, 可是缓存可不仅仅只有Redis。 缓存有哪些类型?如果保存缓存一致性?是本文要回答的问题。
缓存类型
客户端缓存
1.页面缓存
- 页面自身对某些元素或全部元素进行缓存;
- 服务端将静态页面或动态页面的元素进行缓存,然后给客户端使用。
当用户二次访问页面时可以避开网络连接,从而减少负载,提升性能和用户体验。
2.浏览器缓存
浏览器缓存是根据一套 与服务器约定的规则 进行工作的。比如:
- 服务器侧设置 Expires的HTTP头来告诉客户端在重新请求文件之前缓存多久是安全的。
-
在HTML页面的节点中加入meta标签,可以告诉浏览器当前页面不被缓存
浏览器会在硬盘上专门开辟一个空间来存储资源副本作为缓存。浏览器缓存相关的场景:
- 在用户触发“后退”操作
- 点击一个之前看过的链接
- 访问系统中的同一张图片
3. APP上的缓存
网络缓存
网络中的缓存位于客户端和服务端之间,代理或响应客户端的网络请求,从而对重复的请求返回缓存中的数据资源。同时,接受服务端的请求,更新缓存中的内容。
- 正向代理:为客户端提供代理服务,即服务器不知道真正的客户端是谁。
- 反向代理:为服务器提供代理服务,即客户端不知道真正的服务器是谁
- 透明代理:客户端根本不需要知道有代理服务器的存在。
正向与反向代理 两者区别:
1. 位置和功能: 正向代理和反向代理都位于客户端和真实服务器之间,它们的主要功能都是将客户端的请求转发给服务器,然后再将服务器的响应转发给客户端。
2. 提高访问速度: 两者都能通过缓存机制提高访问速度。当客户端请求某个资源时,如果代理服务器已经缓存了该资源,就可以直接从缓存中提供,而无需再次从原始服务器获取,从而节省了时间和带宽。
参考:
图文总结:正向代理与反向代理 - Hello-Brand - 博客园
服务端缓存
这个是后端开发人员最关注的部分。
1. 数据库缓存(InnoDB缓冲池)
在Mysql篇,分析过Mysql Server层的查询缓存用户不大,在Mysql8版本已经去掉。查询缓存,缓存的是SQL语句及结果,移除的原因是:
- 缓存失效频繁
- 为保证缓存和DB数据一致性,高并发场景下锁竞争严重
- 内存管理复杂:缓存占用内存,但是管理效率低下
innodb_buffer_pool_size 是 InnoDB 存储引擎的核心缓存配置,用于缓存 表数据、索引、插入缓冲等,与查询缓存完全不同。需要合理设置值,专用服务器:50%-80% 物理内存,混合部署:25%-50%,避免影响其他服务
-
减少磁盘 I/O:频繁访问的表数据和索引会被缓存到内存,避免每次查询都访问磁盘
-
提升查询性能:缓冲池命中率越高,SQL 执行速度越快(理想情况应 >95%)
-
支持事务和并发:InnoDB 的 MVCC(多版本并发控制)依赖缓冲池管理数据版本
| 对比项 | 查询缓存(Query Cache) | InnoDB 缓冲池(Buffer Pool) |
|---|---|---|
| 缓存内容 | 存储 SQL 语句及其结果 | 缓存表数据、索引、插入缓冲等 |
| 失效机制 | 表数据修改即失效 | LRU 算法管理,按页替换 |
| 适用场景 | 静态数据、极少更新 | 所有 InnoDB 表 |
| 并发影响 | 全局锁,高并发下性能差 | 细粒度锁,支持高并发 |
| MySQL 8.0 | 已移除 | 核心组件,必须优化 |
2. 应用级缓存
在Java语言中,缓存框架更多,例如 Guava Cache(google提供的缓存)、Ehcache 、Caffeine等等。
1. com.google.common.cache.CacheBuilder
import com.google.common.cache.CacheBuilder;
import com.google.common.cache.CacheLoader;
import com.google.common.cache.LoadingCache;public class DistrictProCacheImpl implements DistrictProCache{private LoadingCache<String, String> UPTODATE_ADDRESS =CacheBuilder.newBuilder().expireAfterWrite(7, TimeUnit.DAYS).build(new CacheLoader<String, String>() {@Overridepublic String load(String key) {return queryDistrictNameByCode(key);}});
}2. Ehcache
import org.ehcache.Cache;
import org.ehcache.CacheManager;
import org.ehcache.config.builders.CacheConfigurationBuilder;
import org.ehcache.config.builders.CacheManagerBuilder;
import org.ehcache.config.builders.ResourcePoolsBuilder;public class EhcacheExample {public static void main(String[] args) {// 1. 创建缓存管理器CacheManager cacheManager = CacheManagerBuilder.newCacheManagerBuilder().build();cacheManager.init();// 2. 创建缓存Cache<String, String> myCache = cacheManager.createCache("myCache",CacheConfigurationBuilder.newCacheConfigurationBuilder(String.class, String.class,ResourcePoolsBuilder.heap(100) // 堆内存中存储100个条目));// 3. 使用缓存myCache.put("key1", "value1");String value = myCache.get("key1");System.out.println("从缓存中获取的值: " + value);// 4. 关闭缓存管理器cacheManager.close();}
}3. Caffeine(有资料表明Caffeine性能是Guava Cache的6倍)
Cache<String, Object> cache = Caffeine.newBuilder().expireAfterWrite(10, TimeUnit.MINUTES).maximumSize(1000).build();cache.put("key1", "value1");
Object value = cache.getIfPresent("key1");3.平台级缓存
Redis、 MongoDB、 Memcached都可以作为平台级缓存的重要技术。
Redis、Memcached用的更多一些,MongoDB更多的时候是做为持久化的NoSQL数据库来说使用的。
如何保证缓存数据一致性
缓存一致性指的是有修改数据时,在同一时刻,如何保证缓存和DB的一致性的问题。本地缓存和Redis缓存都存在一致性的问题。
在不使用分布式锁、分布式事务的情况下,分析缓存一致性的几种方案:
1、先更新缓存,再更新数据库
一般不考虑。原因是更新缓存成功,更新数据库出现异常了,因为缓存中数据一直都在,不易察觉。
即使有本地事务,也无法回滚缓存。
2、先更新数据库,再更新缓存
同上。
说明:如果更新缓存失败,虽然可以使用本地事务回滚数据库,保持数据的最终一致性。但是在正常操作情况下,数据不一致的问题仍然存在。
3、先删除缓存,后更新数据库
- 线程1:删缓存 -》 写主库
- 线程2:读缓存 -》 读从库
- 数据库:写主库 -》 同步从库
这里的操作不是原子性的, 所以一定会存在问题。
数据不一致场景: 主从库同步数据的间隙, 读线程在从库中读到了修改前的数据
解决方案:
- 延时双删, 写线程写完主库,延迟几百ms(主从同步时间),在删除下缓存。也可以异步线程做延迟删缓存。
- 缓存不存在时,直接读主库。
4、先更新DB,后删除缓存
- 线程1:写主库 -》 删缓存
- 线程2:读缓存 -》 读从库
- 数据库:写主库 -》 同步从库
这里的操作不是原子性的, 所以一定会存在问题。
数据不一致场景1:在线程1写主库和删缓存的中间,线程2读到了旧缓存值,和主库不一致
数据不一致场景2:缓存失败,线程2在从库读到数据;线程1更新了DB并删除了缓存; 线程1将读到的数据写入缓存,出现缓存和数据库不一致。
解决方案:
- 延时删除
- 使用消息队列,通过消息再次进行删除缓存,保证缓存一定可以删除成功。 缺点是引入了消息中间件,对代码的侵入性较大,另外要考虑消息的可靠性。
-
订阅 Mysql 数据库的 binlog 日志对缓存进行操作,利用工具(canal)将binlog日志采集发送到MQ中,然后通过ACK机制确认处理删除缓存。
缓存更新模式
Cache aside:先写DB后删缓存
Read through/Write through:
Cache Aside套路中,我们的应用代码需要维护两个数据存储,一个是缓存(Cache),一个是数据库(Repository),而Read/Write Through套路是把更新数据库(Repository)的操作由缓存自己代理了,所以,对于应用层,可以理解为只操作一个单一存储。
- Read through:在查询操作中,如果缓存未查到则更新缓存。
- Write through:在更新操作中,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后再由Cache自己更新数据库。
Write behind caching(write back):在更新数据的时候,只更新缓存,不更新数据库。缓存会异步地批量更新数据库。
电商平台缓存应用
缓存应用
1. 首页促销产品, 放到redis
2. 促销产品,放到内存级缓存
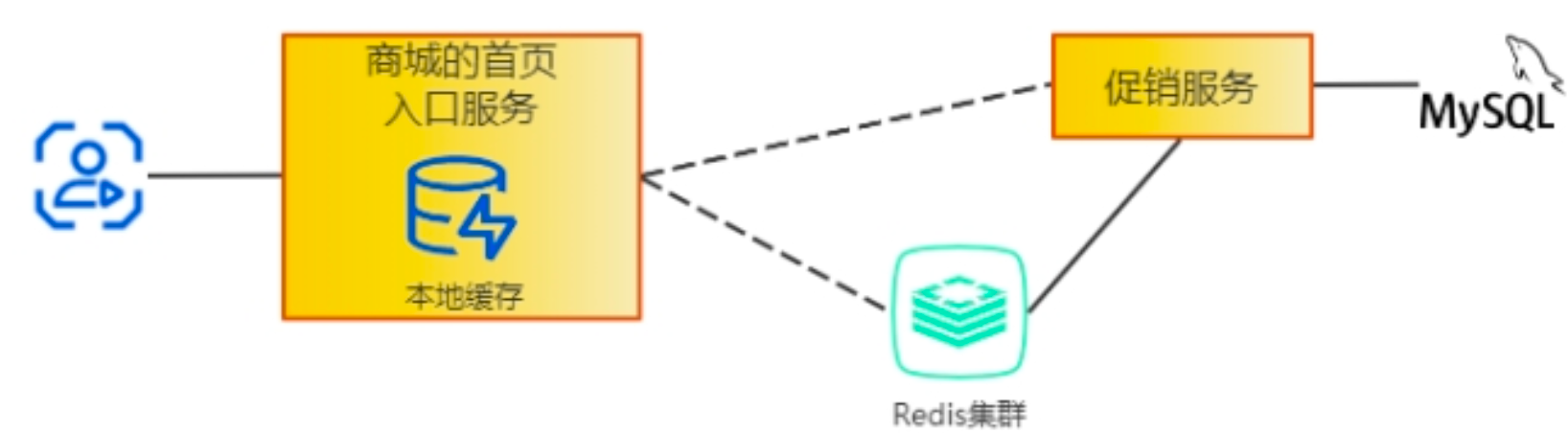
缓存预热
首页服务如果出现重启会导致缓存中的数据丢失,导致查询请求直接访问数据库,所以针对缓存要有专门的缓存预热机制。
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.stereotype.Component;@Component
public class PreheatCache implements CommandLineRunner {@Autowiredprivate HomeService homeService;@Overridepublic void run(String... args) throws Exception {for(String str : args) {log.info("系统启动命令行参数: {}",str);}homeService.preheatCache();}}
数据一致性
1. 缓存过期时间
2. 定时任务刷新缓存
3. Mysql数据库,利用Canal检测数据库的更新,然后删除缓存中对应部分。
缓存过期引起毛刺现象
private Cache<String, HomeContentResult> promotionCache;private Cache<String, HomeContentResult> promotionCacheBak;/*先从本地缓存中获取推荐内容*/HomeContentResult result = allowLocalCache ?promotionCache.getIfPresent(brandKey) : null;if(result == null){result = allowLocalCache ?promotionCacheBak.getIfPresent(brandKey) : null;}对促销数据,使用双缓存。两个缓存使用了不同的策略:
- 正式缓存是最后一次写入后经过固定时间过期
- 备份缓存是设置最后一次访问后经过固定时间过期。意味着备份缓存中内容不管是读写后,实际过期时间都会后延。
在本地缓存的异步刷新机制上:
- 正式缓存只有无效才会被重新写入,保证对客户端的稳定响应。
- 备份缓存无论是否无效都会重新写入,一则可以保证数据不至于真的永久无法过期而太旧,二则使过期时间不管用户是否访问首页都可以不断后延。
手动干预缓存
后端的一个兜底操作, 可以手动刷新缓存