数据集归一化
一、介绍
图像归一化是计算机视觉和深度学习中的核心预处理步骤,旨在通过调整像素值范围或分布,提升模型训练的稳定性、收敛速度和泛化能力。
二、归一化的数学原理与方法
1. Min-Max归一化(线性缩放)
原理:将像素值线性映射到指定区间(如 [0, 1] 或 [-1, 1])。

作用:消除量纲差异,保留原始像素相对关系。
代码实现:
import cv2
import numpy as np
img = cv2.imread('image.jpg').astype(np.float32)
normalized = (img - img.min()) / (img.max() - img.min()) # 映射到 [0,1]
2. Z-Score标准化(标准差归一化)
原理:使数据符合标准正态分布(均值为0,标准差为1):
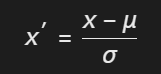
μ:所有像素均值,σ:标准差。
作用:解决数据分布偏斜问题,适用于对分布敏感的模型(如SVM、神经网络)。
代码实现:
mean = np.mean(img)
std = np.std(img)
standardized = (img - mean) / std
3. 非线性归一化
Sigmoid 归一化:
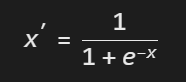
作用:将像素值压缩到 (0, 1) 区间,适用于需要非线性变换的场景(如激活函数预处理)。
L2 归一化:
作用:按像素向量单位化,常用于特征提取后的降维处理。
三、归一化的必要性
1. 加速模型收敛
归一化后梯度下降更稳定,避免参数震荡,缩短训练时间。
2. 提升模型鲁棒性
减少光照、对比度差异对特征提取的影响,提高泛化能力。
3. 避免数值溢出
防止大范围像素值导致计算溢出(如Sigmoid函数输入过大时饱和)。
4. 统一数据尺度
在多通道或混合数据源场景下,确保各通道平等参与计算。