RAG工作流程总览
引言
检索增强生成(Retrieval-Augmented Generation)系统通过知识检索与大模型生成的融合,解决了传统LLM的幻觉、知识滞后问题。本流程图清晰展示了RAG从知识库构建到问答生成的全流程,分为两大阶段,分别是知识库生成阶段,和问答检索阶段和六大核心模块,如图:
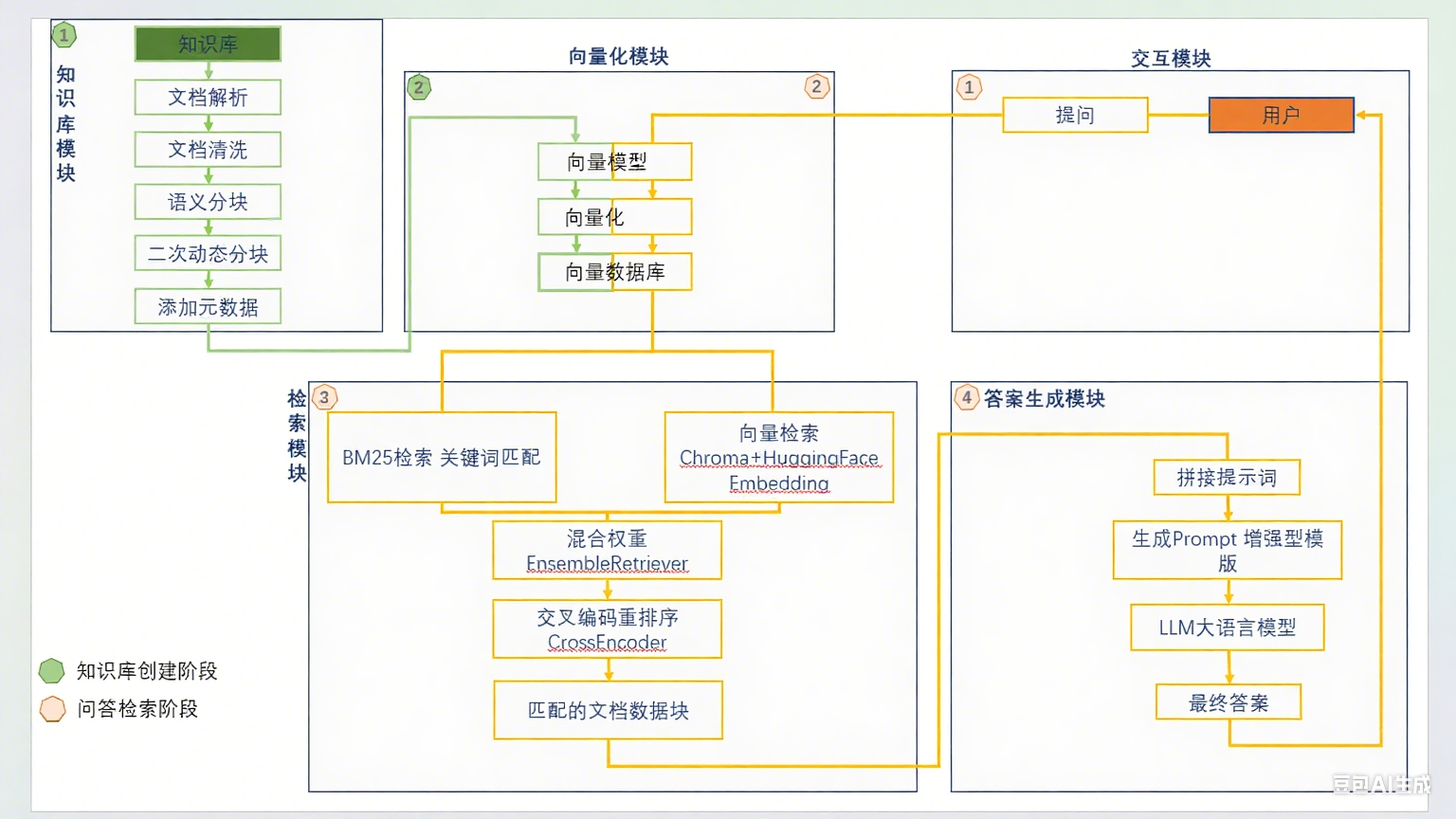
阶段1:知识库构建阶段
该阶段根据原始文件,经过预处理,向量化等操作,最终将向量化模型,与知识库内容的向量化结果存储在向量知识库中备用;
阶段2:问答检索阶段
问答检索阶段,首先将问题通过向量化模型,进行向量化转换,再在向量数据库中,通过不同检索等手段,匹配知识库中相关内容,再将匹配结果通过大模型润色后作为答案输出;
1.知识库模块
目标:将原始知识转化为可检索的结构化数据
文档解析
支持PDF/Word/HTML等多格式文本提取
关键工具:Apache Tika、Unstructured.io
文档清洗
清除乱码、广告、页眉页脚等噪声
规范化文本编码(UTF-8)和特殊符号
语义分块
按主题/段落切分(如每块500字符)
保留语义连贯性避免断句
二次动态分块
根据内容密度自适应调整块大小
示例:法律条文按条款分块,论文按章节分块
添加元数据
注入来源、日期、章节标题等上下文
增强检索精准度(如过滤过时文档)
输出:清洗后的结构化文本块 → 输入向量化模块
2.向量化模块
目标:将文本转化为机器可理解的数值向量
向量模型
选用Text2Vec、BGE-M3等Embedding模型
将文本映射为768/1024维高密度向量
向量化
批量处理分块文本生成向量
关键优化:GPU加速降低延迟
向量数据库
存储向量+元数据(Chroma/HuggingFace)
支持毫秒级相似度搜索(余弦相似度)
3.检索模块
目标:从海量知识中精准定位相关信息
输入:用户提问(例:“新冠疫苗有哪些类型?”)
双路并行检索:
向量检索
用相同Embedding模型处理提问
在Chroma中查Top-50相似块
关键词检索(BM25)
匹配“疫苗”“类型”等关键词
解决术语变体问题(如“COVID-19”→新冠病毒)
混合权重(EnsembleRetriever)
动态融合双路结果(例:向量权重70%+关键词30%)
公式:
综合分 = α·向量相似度 + β·关键词匹配度
交叉编码重排序(CrossEncoder)
用BERT类模型深度理解问题与文本关联
示例:将“mRNA疫苗”块从第5位提升至第1位
输出:筛选Top-3最相关文本块
创新点:
重排序使准确率提升30%+
混合检索解决语义鸿沟问题(如搜索“苹果公司”不返回水果信息)
4.答案生成模块
目标:基于检索结果生成自然语言答案
拼接提示词
采用增强型模板注入上下文:
LLM生成
选用GPT-4、Claude等生成模型
关键机制:温度系数=0.3保证确定性
最终答案
输出带引用来源的结构化答案:
“根据2023年《柳叶刀》报告(来源1),主流疫苗包括:
mRNA疫苗(辉瑞)
灭活疫苗(科兴)...”
安全设计:
置信度阈值过滤低质量结果(<0.7分触发拒答)
避免生成未检索到的信息