论文阅读|CVPR 2025|Mamba进一步研究|GroupMamba

论文地址:pdf
代码地址:code
文章目录
- 1.研究背景与动机
- 2. 核心方法
- 2.1 预备知识:mamba-ssm
- 2.2 整体架构
- 2.3 调制组Mamba层
- 2.3.1 视觉单选择性扫描(VSSS)块
- 2.3.2 分组Mamba算子
- 2.3.3 通道亲和调制(CAM)
- 2.4 蒸馏损失函数
- 3. 实验结果
- 3.1 图像分类任务
- 3.2 目标检测任务
- 3.3 语义分割任务
- 3.4 消融实验
- 4.局限性与结论
- 4.1 局限性
- 4.2 结论
1.研究背景与动机
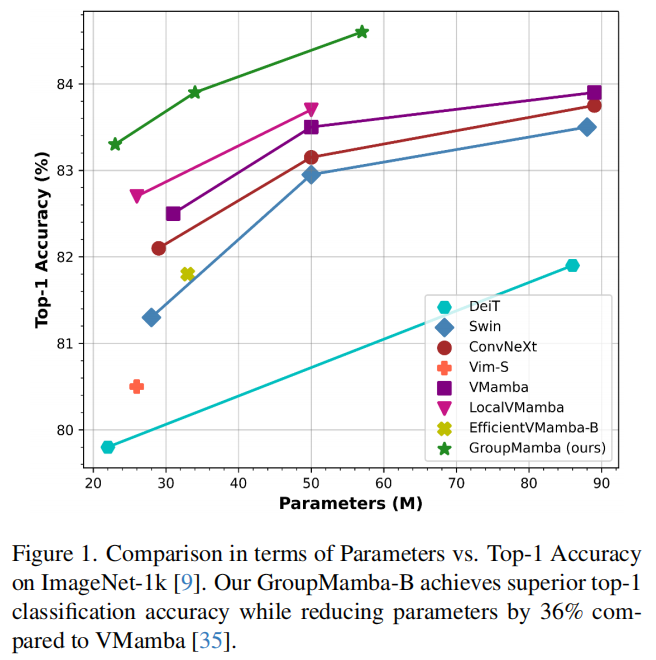
-
现有模型局限:基于 SSM 的视觉模型(如 Mamba、VMamba)在处理视觉任务时存在两大挑战:一是大模型训练不稳定(参数增多时性能下降);二是计算效率低(通道数增加会导致参数和计算成本激增),难以平衡性能与效率。
-
核心目标:设计参数高效、训练稳定的 SSM 模型,通过改进结构增强跨通道交互和空间依赖建模,在图像分类、检测、分割等任务中实现更优性能。
2. 核心方法
2.1 预备知识:mamba-ssm
状态空间模型:经典的状态空间模型(SSMs)表示一个连续系统,它将输入序列x(t)∈RLx(t) \in \mathbb{R}^{L}x(t)∈RL映射到 latent 空间表示h(t)∈RNh(t) \in \mathbb{R}^{N}h(t)∈RN,然后基于该表示预测输出序列y(t)∈RLy(t) \in \mathbb{R}^{L}y(t)∈RL。从数学上讲,SSM可描述为:
h′(t)=Ah(t)+Bx(t),y(t)=Ch(t)\begin{equation} h'(t) = A h(t) + B x(t), \quad y(t) = C h(t) \end{equation} h′(t)=Ah(t)+Bx(t),y(t)=Ch(t)
其中A∈RN×NA \in \mathbb{R}^{N ×N}A∈RN×N、B∈RN×1B \in \mathbb{R}^{N ×1}B∈RN×1和C∈R1×NC \in \mathbb{R}^{1 ×N}C∈R1×N是可学习参数。
离散化:为了使连续状态空间模型(SSMs)适用于深度学习框架,实现离散化操作至关重要。通过引入时间尺度参数Δ∈R\Delta \in \mathbb{R}Δ∈R并采用广泛使用的零阶保持(ZOH)作为离散化规则,可以推导出A和B的离散化版本(分别表示为A‾\overline{A}A和B‾\overline{B}B),据此,式1可重写为离散形式:
h(t)=A‾h(t−1)+B‾x(t),y(t)=Ch(t),where A‾=eΔA,B‾=(ΔA)−1(eΔA−I)ΔB≈ΔB\begin{equation} \begin{aligned} h(t) &= \overline{A} h(t-1) + \overline{B} x(t), \quad y(t) = C h(t), \\ \text{where } \overline{A} &= e^{\Delta A}, \quad \overline{B} = (\Delta A)^{-1} \left(e^{\Delta A} - I\right) \Delta B \approx \Delta B \end{aligned} \end{equation} h(t)where A=Ah(t−1)+Bx(t),y(t)=Ch(t),=eΔA,B=(ΔA)−1(eΔA−I)ΔB≈ΔB
离散化的详细推导可见这篇文章
其中III表示单位矩阵。
2.2 整体架构
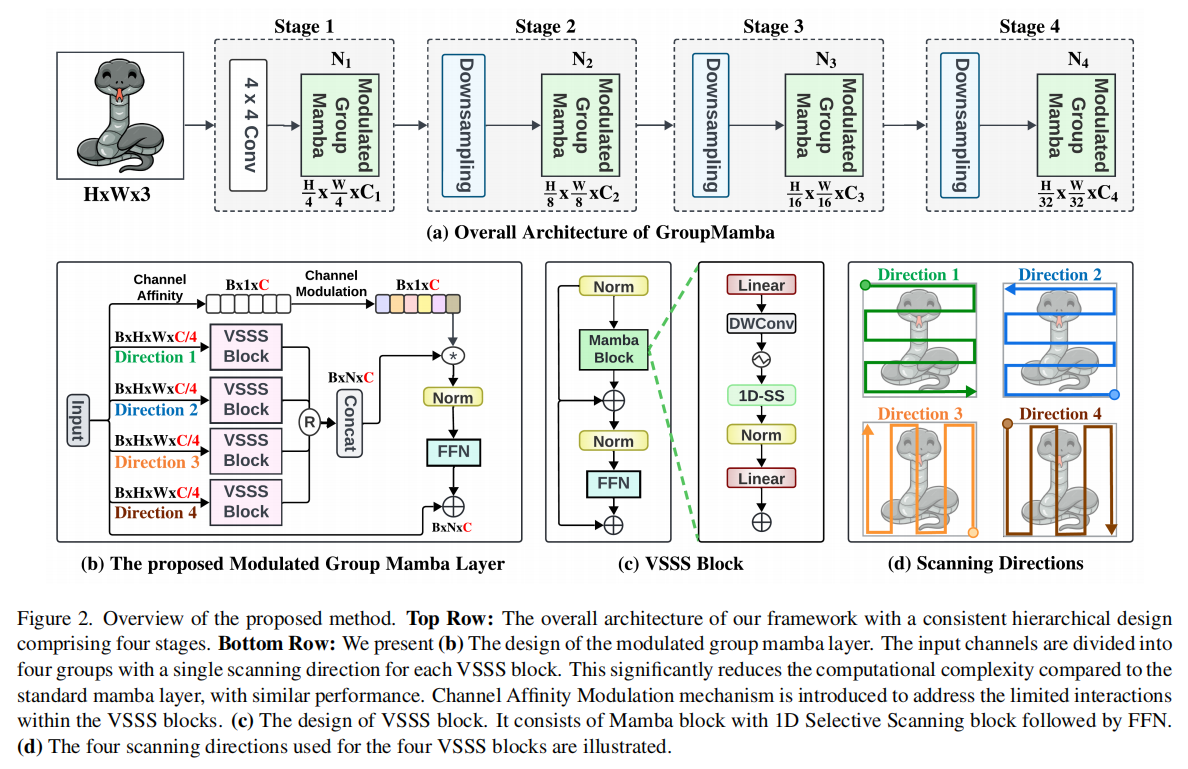
如图2(a)所示,模型采用分层架构,类似于Swin-Transformer,包含四个阶段,可高效处理不同分辨率的图像。假设输入图像为I∈RH0×W0×3I \in \mathbb{R}^{H_0 \times W_0 \times 3}I∈RH0×W0×3,我们首先应用补丁嵌入层将图像分割为4×4的非重叠补丁(实质还是一个特征,只是包含了4×4的非重叠补丁的信息),并将每个补丁嵌入到CCC维特征向量中。补丁嵌入层通过两个3×3卷积实现,步长为2。这在第一阶段产生大小为H1×W1×CH_1 \times W_1 \times CH1×W1×C的特征图,其中H1=H0/4H_1 = H_0/4H1=H0/4,W1=W0/4W_1 = W_0/4W1=W0/4。这些特征图通过N1N_1N1个提出的调制组Mamba块(详见3.3节)处理。在后续每个阶段中,下采样层合并2×2区域的补丁,随后是N2,N3,N4N_2, N_3, N_4N2,N3,N4个调制组Mamba层块。因此,第二、三、四阶段的特征大小分别为H2×W2×2CH_2 \times W_2 \times 2CH2×W2×2C、H3×W3×4CH_3 \times W_3 \times 4CH3×W3×4C和H4×W4×8CH_4 \times W_4 \times 8CH4×W4×8C,其中Hi+1=Hi/2H_{i+1} = H_i/2Hi+1=Hi/2,Wi+1=Wi/2W_{i+1} = W_i/2Wi+1=Wi/2。
2.3 调制组Mamba层
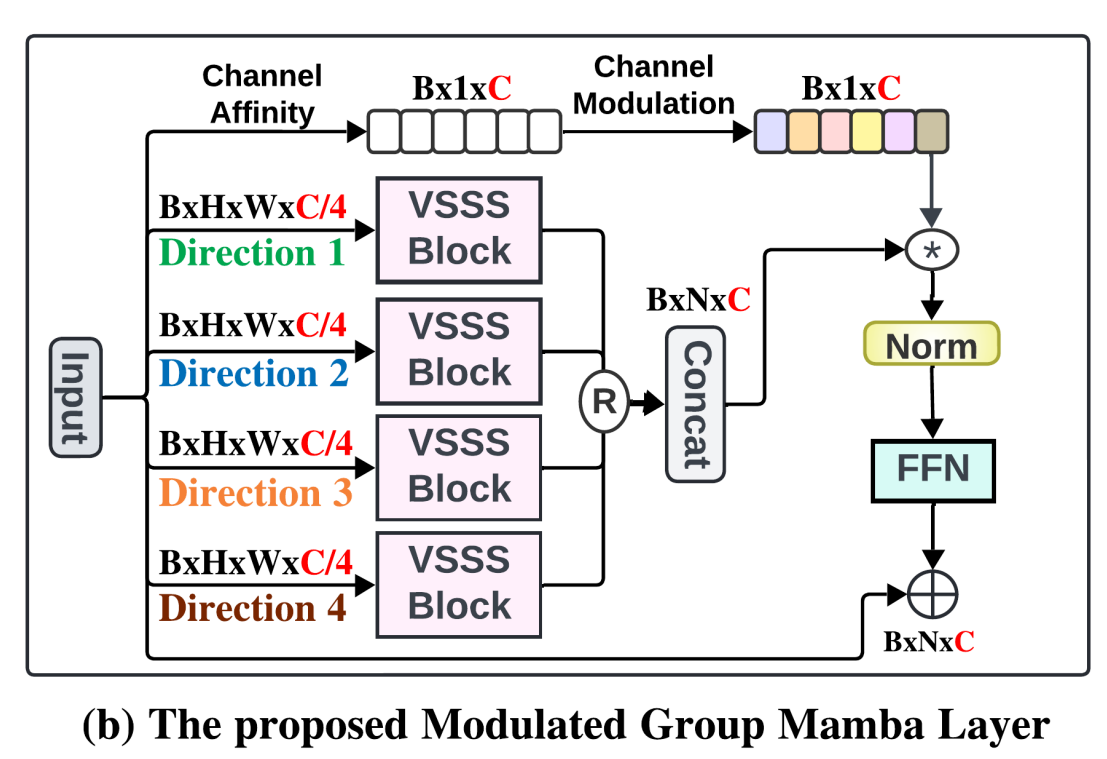
在式3中给出了所提出的调制组Mamba层(图2(b))对输入序列Xin∈RB×H×W×CX_{in} \in \mathbb{R}^{B \times H \times W \times C}Xin∈RB×H×W×C的整体操作,其中BBB是批大小,CCC是输入通道数,H/WH/WH/W是特征图的高度和宽度。
XGM=GroupedMamba(Xin,Θ)XCAM=CAM(XGM,Affinity(Xin))Xout=Xin+FFN(LN(XCAM))\begin{equation} \begin{aligned} X_{GM} &= \text{GroupedMamba} \left(X_{in }, \Theta\right) \\ X_{CAM } &= \text{CAM}\left(X_{GM }, \text{Affinity}\left(X_{in }\right)\right) \\ X_{out } &= X_{in } + \text{FFN}\left(\text{LN}\left(X_{CAM }\right)\right) \end{aligned} \end{equation} XGMXCAMXout=GroupedMamba(Xin,Θ)=CAM(XGM,Affinity(Xin))=Xin+FFN(LN(XCAM))
其中,XGMX_{GM}XGM是式6的输出,XCAMX_{CAM}XCAM是式9的输出,LN是层归一化操作,FFN是式5描述的前馈网络,XoutX_{out}Xout是调制组Mamba块的最终输出。各个操作(即分组Mamba算子、分组Mamba算子中使用的VSSS块和CAM算子)分别在2.3.1节、2.3.2节和2.3.3节中介绍。
2.3.1 视觉单选择性扫描(VSSS)块
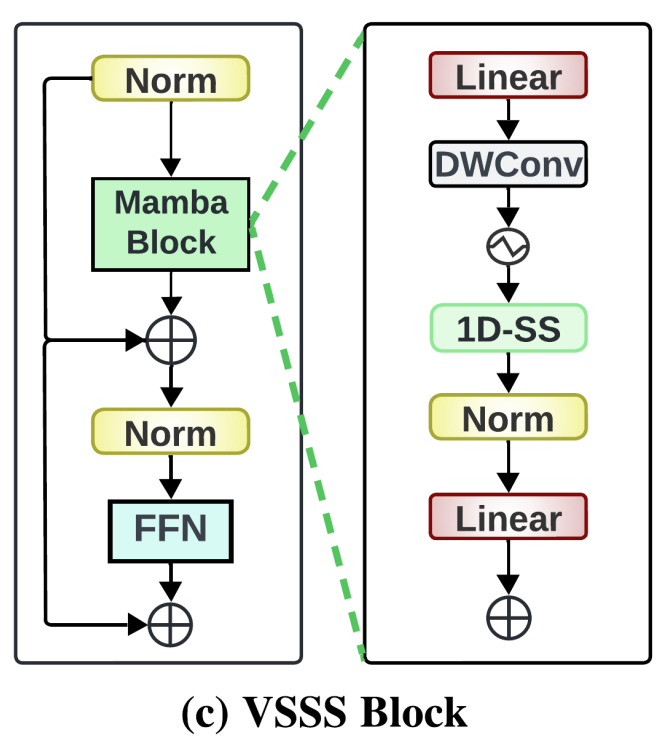
VSSS块(图2(c))是基于Mamba算子的令牌和通道混合器,由一个Mamba块和一个前馈网络组成,每个网络前都有一个层归一化。从数学上讲,对于输入令牌序列ZinZ_{in}Zin,VSSS块执行式4中描述的操作:
Zout′=Zin+Mamba(LN(Zin))Zout=Zout′+FFN(LN(Zout′))\begin{equation} \begin{aligned} & Z_{out }' = Z_{in } + \text{Mamba}\left(\text{LN}\left(Z_{in }\right)\right) \\ & Z_{out } = Z_{out }' + \text{FFN}\left(\text{LN}\left(Z_{out }'\right)\right) \end{aligned} \end{equation} Zout′=Zin+Mamba(LN(Zin))Zout=Zout′+FFN(LN(Zout′))
其中,ZoutZ_{out}Zout是输出序列,Mamba是式2中描述的离散化Mamba SSM算子。
FFN(LN(Zout′))=GELU(LN(Zout′)W1+b1)W2+b2\begin{equation} \text{FFN}\left(\text{LN}\left(Z_{out }'\right)\right) = \text{GELU}\left(\text{LN}\left(Z_{out }'\right) W_1 + b_1\right) W_2 + b_2 \end{equation} FFN(LN(Zout′))=GELU(LN(Zout′)W1+b1)W2+b2
其中,GELU是激活函数,W1,W2W_1, W_2W1,W2和b1,b2b_1, b_2b1,b2是线性投影的权重和偏置。
2.3.2 分组Mamba算子
鉴于Mamba在输入序列通道数较多时计算效率较低,我们受分组卷积启发,提出了一种分组变体算子。分组Mamba操作是2.3.1节中介绍的VSSS块的变体,其中输入通道被分为多个组,VSSS算子分别应用于每个组。具体来说,我们将输入通道分为4组,每组大小为C/4C/4C/4,每个组应用一个独立的VSSS块。因此,所提出的分组Mamba算子通过将通道分成更小的组来提高模型效率。为了更好地建模输入中的空间依赖,四个组中的每个组都沿四个空间方向之一扫描(图2(d)所示的左右、右左、上下、下上)。
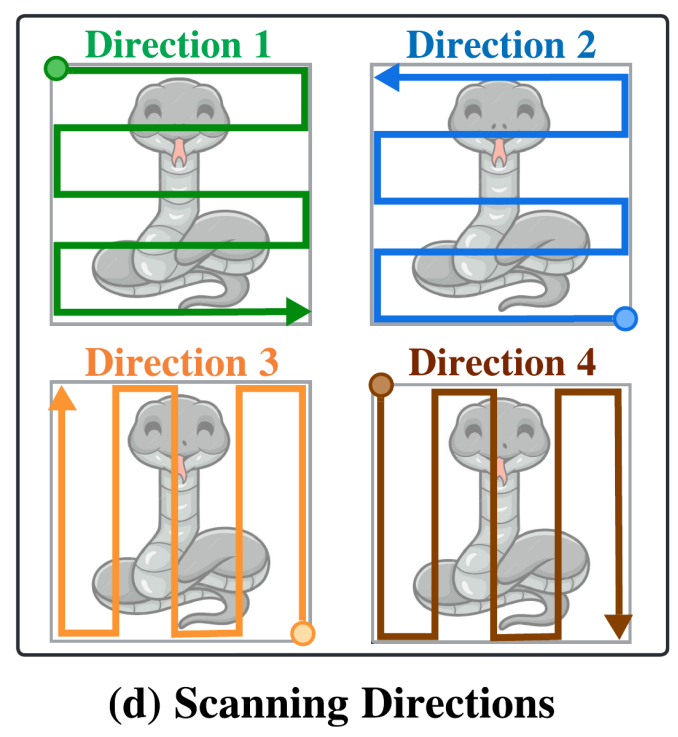
设G=4G=4G=4为表示四个扫描方向(左右、右左、上下、下上)的组数。我们从输入序列XinX_{in}Xin中形成四个序列,即XLRX_{LR}XLR、XRLX_{RL}XRL、XTBX_{TB}XTB和XBTX_{BT}XBT,每个序列的形状为(B,H,W,C/4)(B, H, W, C/4)(B,H,W,C/4),分别对应上述四个方向。然后将它们展平为单个令牌序列,形状为(B,N,C/4)(B, N, C/4)(B,N,C/4),其中N=W×HN=W×HN=W×H是序列中的令牌数。四个组中每个组的参数可分别由ΘLR\Theta_{LR}ΘLR、ΘRL\Theta_{RL}ΘRL、ΘTB\Theta_{TB}ΘTB和ΘBT\Theta_{BT}ΘBT指定,分别代表每个VSSS块的参数。
基于上述定义,分组Mamba算子的整体关系如式6所示:
XGM=GroupedMamba(Xin,Θ)=Concat(VSSS(XLR,ΘLR),VSSS(XRL,ΘRL),VSSS(XTB,ΘTB),VSSS(XBT,ΘBT))\begin{equation} \begin{aligned} X_{GM} &= \text{GroupedMamba} \left(X_{in}, \Theta\right) = \text{Concat}( \\ & \text{VSSS}\left(X_{LR}, \Theta_{LR}\right), \text{VSSS}\left(X_{RL}, \Theta_{RL}\right), \\ & \left.\text{VSSS}\left(X_{TB}, \Theta_{TB}\right), \text{VSSS}\left(X_{BT}, \Theta_{BT}\right)\right) \end{aligned} \end{equation} XGM=GroupedMamba(Xin,Θ)=Concat(VSSS(XLR,ΘLR),VSSS(XRL,ΘRL),VSSS(XTB,ΘTB),VSSS(XBT,ΘBT))
其中:
- XLRX_{LR}XLR、XRLX_{RL}XRL、XTBX_{TB}XTB和XBTX_{BT}XBT表示沿相应方向扫描的输入张量。
- ΘLR\Theta_{LR}ΘLR、ΘRL\Theta_{RL}ΘRL、ΘTB\Theta_{TB}ΘTB和ΘBT\Theta_{BT}ΘBT表示每个方向的VSSS块参数。
- 每个Mamba算子的输出被重新整形为(B,H,W,C/4)(B, H, W, C/4)(B,H,W,C/4),并拼接回形状为(B,H,W,C)(B, H, W, C)(B,H,W,C)的令牌序列XGMX_{GM}XGM。
2.3.3 通道亲和调制(CAM)
就其本身而言,分组Mamba算子可能存在一个缺点,即跨通道的信息交换有限,因为组中的每个算子仅对C/4C/4C/4个通道进行操作。为促进跨通道的信息交换,我们提出了通道亲和调制算子,该算子重新校准通道方向的特征响应,以增强网络的表示能力。在该块中,我们首先对输入进行平均池化以计算通道统计量,如式7所示:
ChannelStat(Xin)=AvgPool(Xin)\begin{equation} \text{ChannelStat} \left(X_{in }\right) = \text{AvgPool}\left(X_{in }\right) \end{equation} ChannelStat(Xin)=AvgPool(Xin)
其中,XinX_{in}Xin是输入张量,AvgPoolAvgPoolAvgPool表示全局平均池化操作。接下来是如式8所示的亲和计算操作:
Affinity(Xin)=σ(W2δ(W1ChannelStat(Xin)))\begin{equation} \text{Affinity}\left(X_{in }\right) = \sigma\left(W_2 \delta\left(W_1 \text{ChannelStat}\left(X_{in }\right)\right)\right) \end{equation} Affinity(Xin)=σ(W2δ(W1ChannelStat(Xin)))
其中,δ\deltaδ和σ\sigmaσ表示非线性函数,W1W_1W1和W2W_2W2是可学习权重。σ\sigmaσ的作用是为每个通道分配一个重要性权重以计算亲和度。亲和度计算的结果用于重新校准分组Mamba算子的输出,如式9所示:
XCAM=CAM(XGM,Affinity(Xin))=XGM⋅Affinity(Xin)\begin{equation} X_{CAM } = \text{CAM}\left(X_{GM}, \text{Affinity}\left(X_{in }\right)\right) = X_{GM} \cdot \text{Affinity}\left(X_{in }\right) \end{equation} XCAM=CAM(XGM,Affinity(Xin))=XGM⋅Affinity(Xin)
其中,XCAMX_{CAM}XCAM是重新校准的输出,XGMX_{GM}XGM是式6中四个VSSS组的拼接输出,XinX_{in}Xin是输入张量,Affinity(Xin)\text{Affinity}(X_{in})Affinity(Xin)是从式8中的通道亲和计算操作获得的通道方向注意力分数。
虽然CAM模块采用的平均池化和亲和过程类似于挤压-激励(SE)块,但它引入了一种独特的机制,专门为多组变换中的跨通道注意力量身定制。具体而言,CAM允许组间信息交换,以克服“分组Mamba算子”固有的限制(即仅允许组内交互)。相比之下,SE块通常专注于重新校准单个特征组,尚未在基于Mamba的架构中进行研究。
2.4 蒸馏损失函数
因为Mamba在扩展到大型模型时训练不稳定。为缓解这一问题,我们建议在标准交叉熵目标之外利用蒸馏目标。知识蒸馏包括训练学生模型从教师模型的行为中学习,方法是最小化分类损失和蒸馏损失的组合。蒸馏损失通过教师模型和学生模型的logits之间的交叉熵目标计算。给定学生模型的logits(Zs)logits(Z_s)logits(Zs)、教师模型(在我们的案例中为RegNetY-16G)的logits(Zt)logits(Z_t)logits(Zt)、真实标签yyy 以及 教师的硬决策yt=argmaxcZt(c)y_t = \text{argmax}_c Z_t(c)yt=argmaxcZt(c),联合损失函数如式10所示:
Ltotal =αLCE(Zs,y)+(1−α)LCE(Zs,yt)\begin{equation} \mathcal{L}_{\text{total }} = \alpha \mathcal{L}_{\text{CE}}\left(Z_s, y\right) + (1-\alpha) \mathcal{L}_{\text{CE}}\left(Z_s, y_t\right) \end{equation} Ltotal =αLCE(Zs,y)+(1−α)LCE(Zs,yt)
其中,LCE\mathcal{L}_{\text{CE}}LCE是交叉熵损失,α\alphaα是权重参数。我们在补充材料中证明,引入蒸馏损失可增强训练稳定性,为更大的模型变体带来持续的性能提升。
3. 实验结果
3.1 图像分类任务

3.2 目标检测任务
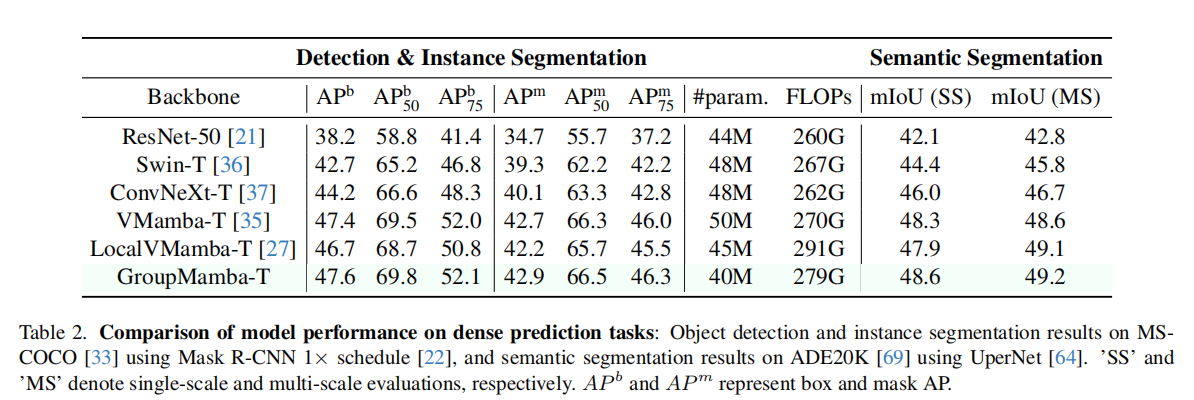
3.3 语义分割任务

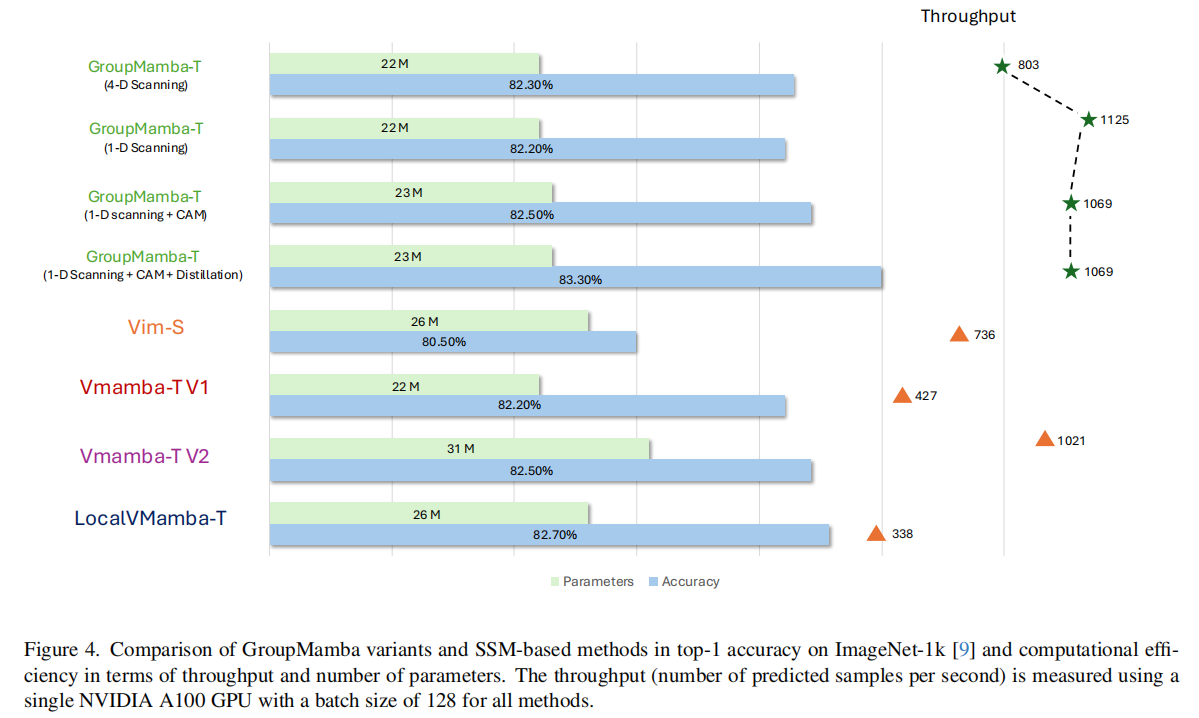
3.4 消融实验
4.局限性与结论
4.1 局限性
- 任务覆盖范围有限:研究主要集中在图像分类、目标检测、实例分割和语义分割任务,尚未在视频识别、时间序列数据等更广泛的视觉或序列任务中验证模型的泛化能力
- 大模型稳定性验证不足:尽管引入蒸馏损失缓解了训练不稳定性,但针对更大参数规模模型(如超大规模 GroupMamba)的稳定性和性能表现仍需进一步探索
4.2 结论
核心贡献有效性:提出的调制组 Mamba 层通过分组扫描和多方向空间建模,在降低计算成本的同时增强了特征表达能力;通道亲和调制(CAM)算子有效解决了分组操作导致的跨通道交互不足问题;蒸馏损失函数显著提升了大模型训练的稳定性
- 性能优势:GroupMamba 系列模型在多个视觉任务中表现优异,例如 tiny 变体(23M 参数)在 ImageNet-1K 上实现 83.3% 的 Top-1 准确率,参数效率比同类 Mamba 模型高 26%;base 变体(57M 参数)准确率达 84.5%,参数比 VMamba-B 少 36%
- 效率与性能平衡:GroupMamba 在保持状态空间模型(SSMs)线性复杂度优势的同时,实现了参数效率与任务性能的更优权衡,为高效视觉骨干网络设计提供了新方案
- 未来方向:计划将模型扩展到视频识别、时间序列等任务,进一步验证调制组 Mamba 层的泛化能力和局限性