第七章:进入Redis的SET核心
一.SET概念
集合类型也是保存多个字符串类型的元素的,但和列表类型不同的是,集合中1)元素之间是无序的2)元素不可重复。一个集合中最多可以存储无数个元素。Redis除了支持集合内的增删查改操作,同时还支持多个集合取交集、并集、差集,合理地使用好集合类型,能在实际开发中解决很多问题。
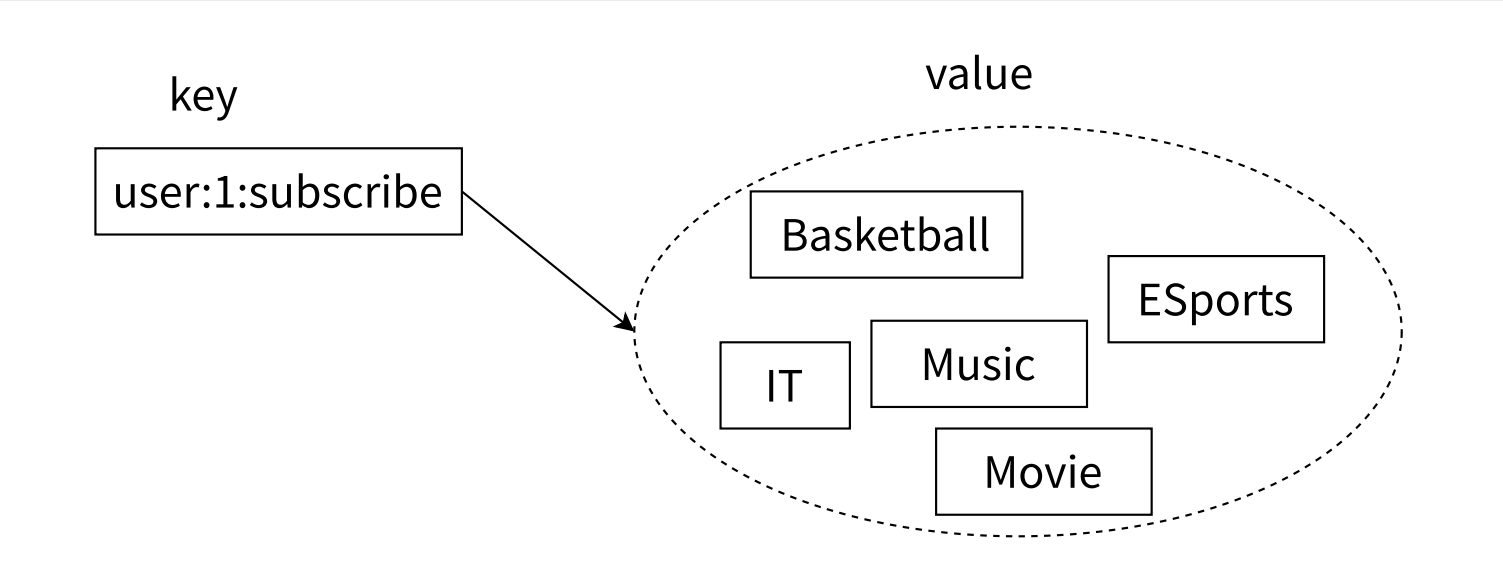
- 谈到一个术语,这个术语很可能有多种含义。
- Set:
- 集合。
- 设置(和 get 相对应)。
- 集合就是把一些有关联的数据放到一起。
- 集合中的元素是无序的!
- 集合中的元素是不能重复的(唯一的)。
- 此处说的无序和前面 list 这里的有序是对应的。
- 有序:顺序很重要。变换一下顺序,就是不同的 list 了。
- 无序:顺序不重要。变化一下顺序,集合还是那个集合。
- 示例:
- list:
[1, 2, 3]和[2, 1, 3]是两个不同的 list。 - set:
[1, 2, 3]和[2, 1, 3]是同一个集合。
- list:
- 和 list 类似,集合中的每个元素也都是 string 类型。(可以使用 json 这样的格式让 string 也能存储结构化数据)。
二.SET核心命令
SADD key member [member ...]2.1SADD

2.2SMEMBERS
SMEMBERS命令:获取⼀个 set 中的所有元素,注意,元素间的顺序是无序的。
SMEMBERS key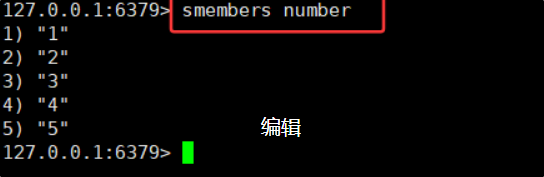
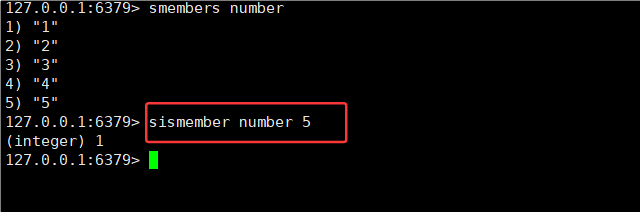
2.3SISMEMBER
SISMEMBER key member
2.4SPOP
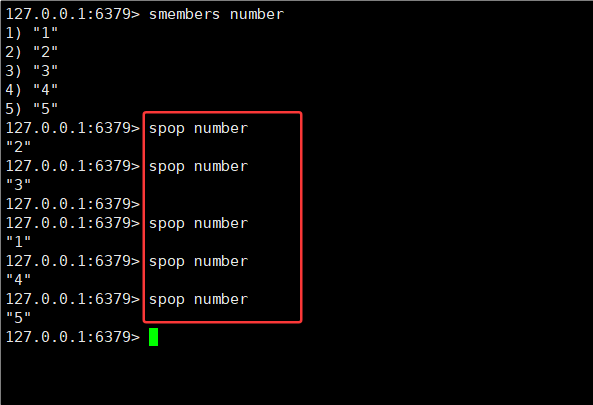
- spop 删除元素的时候其实是随机删除。
- 不写 count 的时候,随机删除一个;写 count 的时候,就写几个就删几个。
- 该操作类似于
SRANDMEMBER,SRANDMEMBER从集合中返回一个或多个随机元素但不删除它。 - 其实是在源码中,针对 spop 实现的时候采取了 “生成随机数” 的方式。
SPOP key [count]
存储元素是无序的,删除随机删
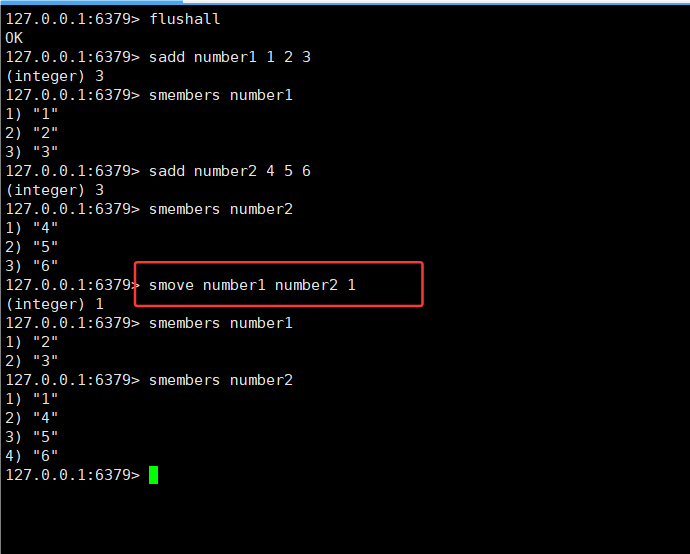
2.5SMOVE
- 把 member 从 source 上删除,再插入到 destination 中。
再次操作时,smove 不会视为出错,也会按照删除 - 插入进行执行。
如果要移动的元素在 source 中不存在,返回 (integer) 0 表示移动失败了。
SMOVE source destination member
2.6 SREM
可以一次删除一个 member,也可以一次删除多个 member。
SREM key member [member ...]

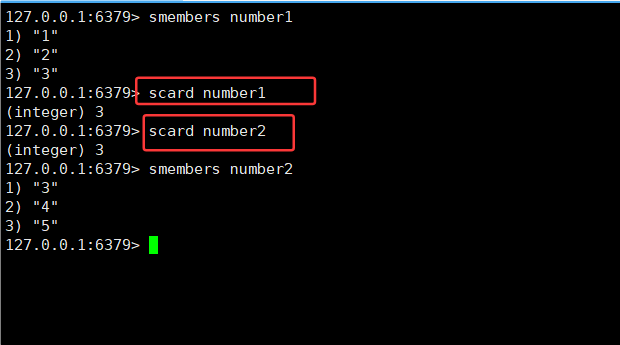
2.7SCARD
SCARD key
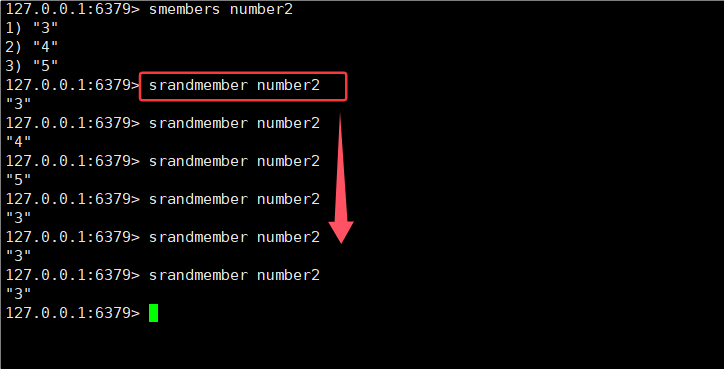
2.8 SRANDMEMBER
SRANDMEMBER命令:随机返回集合中的某个元素
相关概念:
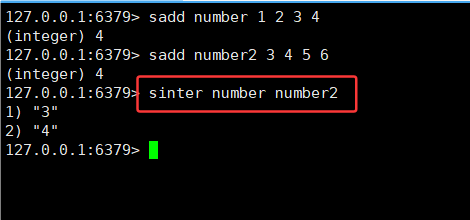
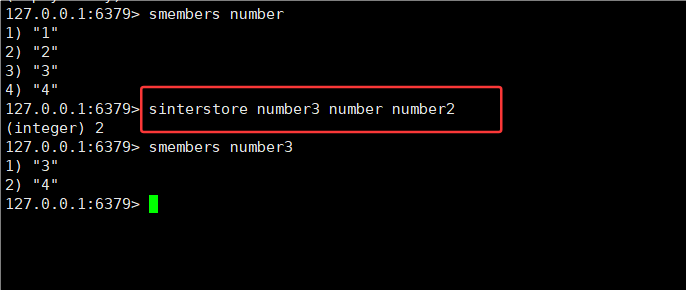
1.交集(inter):最终结果同时出现在两个集合中。
示例:A 为 {1, 2, 3, 4},B 为 {3, 4, 5, 6},A 和 B 的交集为 {3, 4}。
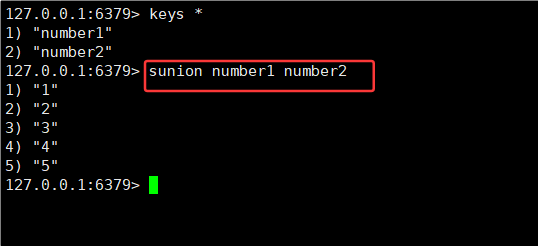
2.并集(union):把多个集合中的数据都集中放在一起,如果元素有重复,也最终只保留一份。
示例:A 为 {1, 2, 3, 4},B 为 {3, 4, 5, 6},A 和 B 的并集为 {1, 2, 3, 4, 5, 6}。
3.差集(diff):A 和 B 做差集,就是找出哪些元素在 A 中存在,同时在 B 中不存在。
示例:A 为 {1, 2, 3, 4},B 为 {3, 4, 5, 6},A 和 B 做差集为 {1, 2},B 和 A 的差集为 {5, 6}。
2.9SINTER ,SINTERSTSTORE
SINTER key [key ...]
SINTERSTORE destination key [key ...]
2.10SUNION, SUNIONSTORE
SUNION key [key ...]
SUNIONSTORE destination key [key ...]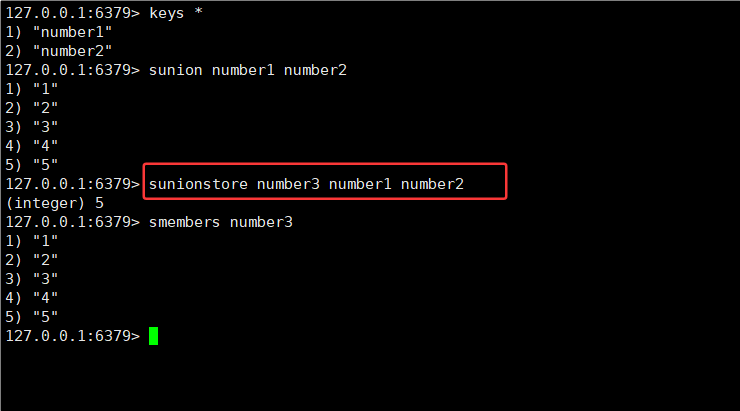
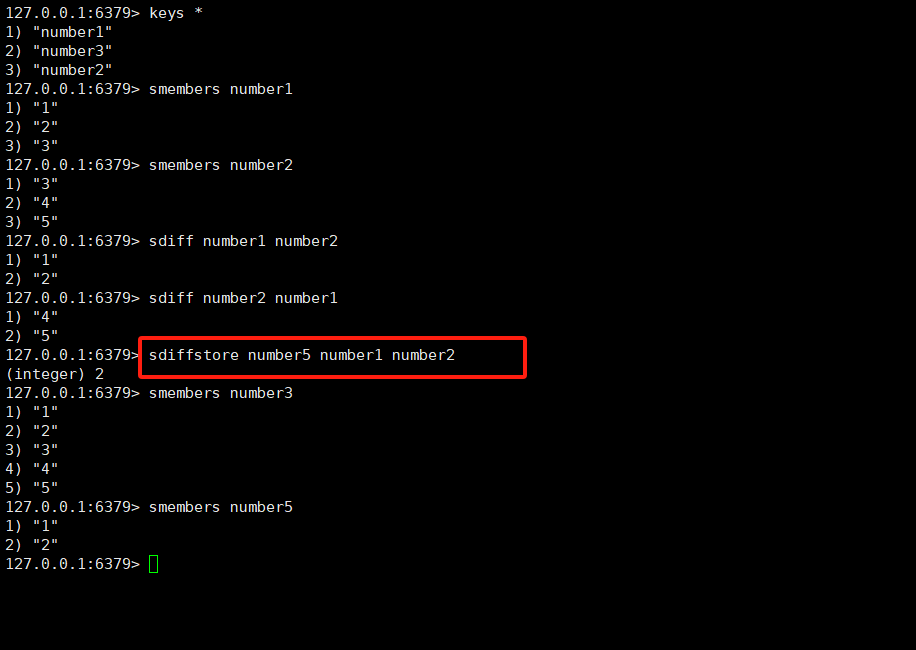
2.11SDIFF,SDIFFSTORE
SDIFF key [key ...]
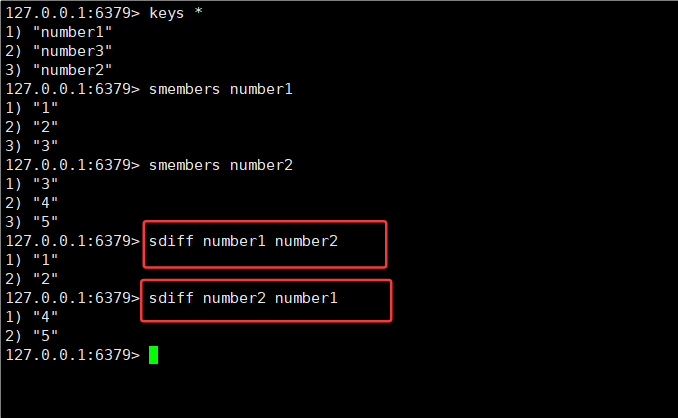
SDIFFSTORE destination key [key ...]
三.SET内部编码
- intset(整数集合):当集合中的元素都是整数并且元素的个数小于 set-max-intset-entries 配置(默认 512 个)时,Redis 会选用 intset 来作为集合的内部实现,从而减少内存的使用。
- hashtable(哈希表):当集合类型无法满足 intset 的条件时,Redis 会使用 hashtable 作为集合的内部实现。
1.当元素个数较少并且都为整数时,内部编码为 intset:
127.0.0.1:6379> sadd setkey 1 2 3 4
(integer) 4
127.0.0.1:6379> object encoding setkey
"intset"2.当元素个数超过 512 个,内部编码为 hashtable
127.0.0.1:6379> sadd setkey 1 2 3 4
(integer) 513
127.0.0.1:6379> object encoding setkey
"hashtable"3.当存在元素不是整数时,内部编码为 hashtable
127.0.0.1:6379> sadd setkey a
(integer) 1
127.0.0.1:6379> object encoding setkey
"hashtable"四.SET的应用场景
集合类型比较典型的使用场景是标签(tag)。例如 A 用户对娱乐、体育板块比较感兴趣,B 用户对历史、新闻比较感兴趣,这些兴趣点可以被抽象为标签。有了这些数据就可以得到喜欢同一个标签的人,以及用户的共同喜好的标签,这些数据对于增强用户体验和用户黏度都非常有帮助。 例如一个电子商务网站会对不同标签的用户做不同的产品推荐。
- 使用 Set 来保存用户的 “标签”(用户画像):
- 分析出个人的一些特征,分析清楚特征之后,再投其所好,实现 “千人千面”,例如可以分析出性别、年龄、居住地、爱好等特征。
- 可以根据用户的一些历史行为得出相关特征。
- 比如对于两个程序、两个账号,判断是否为同一个人,现在的程序登录主要是通过手机号和微信等入口来判断。
- 通过上述过程搜集到的用户特征,会转换成 “标签”,标签是简短的字符串,此时就可以把标签保存到 redis 的 set 中了。
- 使用 Set 来计算用户之间的共同好友:
- 基于 “集合求交集” 操作。
- 例如在 QQ 中,我加了很多好友,你也加了很多好友,基于此还可以做一些好友推荐。
- 如 A 和 B 是好友,A 和 C 是好友,B 和 C、D 都是好友,系统就会把 D 推荐给 A。
- 使用 Set 统计 UV(去重):
- 一个互联网产品,衡量用户量、用户规模主要有两方面指标:
- PV(page view):用户每次访问该服务器,每次访问都会产生一个 pv。
- UV(user view):每个用户访问服务器,都会产生一个 uv,但同一个用户多次访问,不会使 uv 增加,uv 需要按照用户进行去重,上述的去重过程,可以使用 set 来实现。
- 一个互联网产品,衡量用户量、用户规模主要有两方面指标:
- Set 方便计算交集:
- 很容易找到两个用户之间的公共标签。
- 基于这样的标签,衍生出一些 “用户关系”。