学习笔记-中华心法问答系统的性能提升
1.简介
本周主要任务是自行查找文献,针对源代码进行性能提升,主要包括三个方面:
- 预处理:分词、关键词提取、词向量生成;
- 文本分析:从多个关键词的词向量,如何到一句话的语义理解;问题分类;
- 相似问题匹配:检索到相似问答对,并对候选答案进行排序。
针对上面三个方面,这一周主要是进行第三条:相似度匹配的性能提升。由于此次任务是在上次的代码里进行性能提升,所以先进行上次代码的回顾(具体补充在上一篇博客),再寻找性能提升的方法。
2. 算法回顾
上面三个方面的性能提升,可以在上一篇博客的数据处理图里面体现。
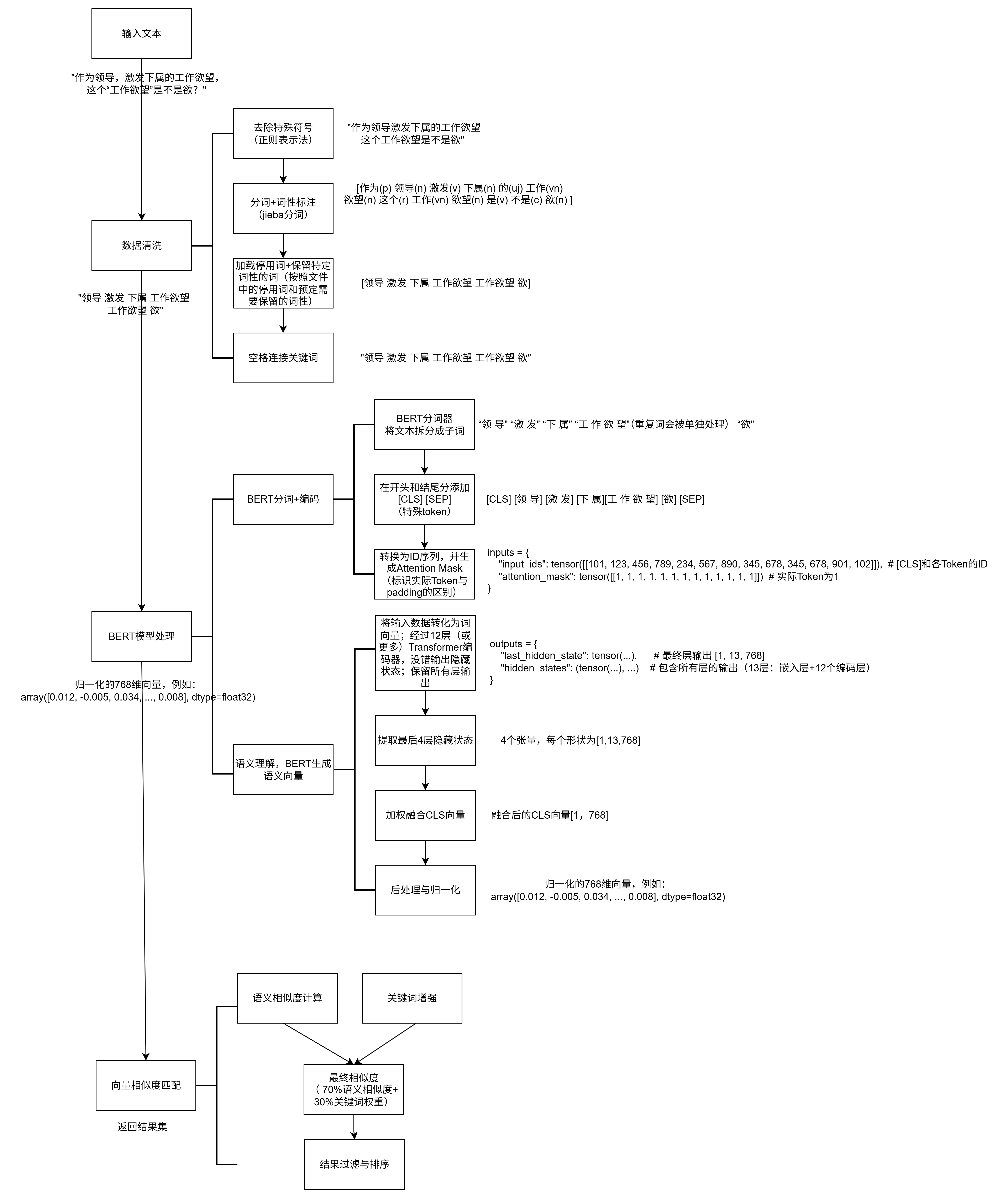
关于相似度匹配的问题,源代码里主要是采用语义相似度和关键词重叠的混合的相似度得到的,细节如下:
1. 向量准备阶段
预计算(系统启动时):
对库中每个问题(如
Q1: "Python怎么学?")生成768维归一化向量,存储为矩阵question_vectors(形状[N, 768],N=问题数量)。(_prepare_vectors)不处理答案:相似度仅对比问题文本,答案仅作为最终返回内容。
实时计算(用户搜索时):
对用户查询(如
"学习Python的技巧")生成768维归一化向量query_vector(形状[768,])。(_get_embedding)2. 语义相似度计算
(1)计算原始相似度(余弦相似度):
计算公式:
操作步骤:
将
query_vector形状转为[1, 768]。与
question_vectors([N, 768])做矩阵乘法(点积)。输出
[1, N]的相似度数组,每个元素表示用户查询与一个库内问题的余弦相似度。数学展开:
其中:
simi=∑k=1768qk⋅Qi,ksimi=∑k=1768qk⋅Qi,k(即余弦相似度)
(2)相似度校准(Sigmoid函数):非线性放大高相似度(>0.88)的结果
原始余弦相似度的范围是 [−1,1],通过Sigmoid函数将其压缩到 [0,1],并锐化差异:
作用:将相似度大于0.88的结果推向1,小于0.88的结果推向0,增强区分度。
- 参数选择:k=25(陡峭度),x0=0.88(阈值)
(3) 混合相似度(原始+校准):保留20%原始相似度,80%校准后结果
3. 关键词重叠度
计算原理:
关键词提取:
对用户查询和库内问题,使用
jieba分词,返回分词后的词语列表例如:
用户查询:
"如何快速学习Python"→ 关键词:{"学习", "Python"}库内问题:
"怎样高效掌握Python编程"→ 关键词:{"掌握", "Python", "编程"}重叠度计算:
分子:共有关键词数量(如
{"Python"}→ 1个)。分母:用户查询的关键词数量(防止除零)。
归一化:
得分范围天然在 [0,1][0,1] 之间,无需额外处理。
3. 混合相似度计算
- 最终相似度 = 70%语义相似度 + 30%关键词权重
- 添加微小偏移(0.0266)避免零相似度
4. 结果过滤与排序
- 先将所有的最终结果集进行降序排序
- 四级过滤机制:
- 数量限制:确保不超过TOP-K(默认1000)
- 阈值过滤:丢弃相似度<0.6的结果(可配置)
- 内容去重:基于问题和答案前20字符的哈希值
- 语义去重:新结果与已有结果的相似度>0.93时跳过
- 将过滤后的答案添加到结果列表
- 结果保障机制:确保始终返回足够数量的结果(即使部分结果相似度较低),避免因严格过滤导致空结果
- 最终结果严格按相似度降序排列
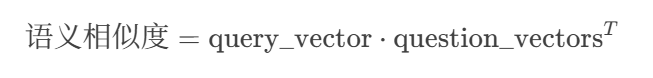

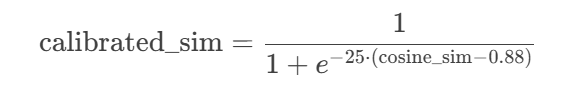
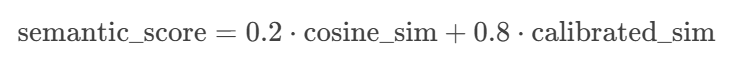
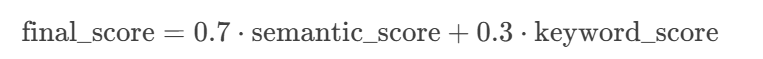
3. 性能提升
3.1 《基于深度学习的水稻知识智能问答系统理论与方法研究》
关于相似度匹配的性能提升,我主要是重新看了之前发过的《基于深度学习的水稻知识智能问答系统理论与方法研究》这一篇论文,这里面的第4章提到了相似度匹配的方法,第5章提到了关于排序的方法。
3.1.1 关于相似度匹配--DenseBiGRU 和协同注意力机制、交互分类层
与传统深度学习模型相比,首先本文使用 12 层 Transformer 的中文 BERT 预训练模型得到问句特征向量化表示;其次本文提出的模型利用 DenseBiGRU 和协同注意力机制提取文本不同粒度的局部特征;最后将提取的特征向量输入到交互分类层(Wang et al.,2021)。模型架构图如下:
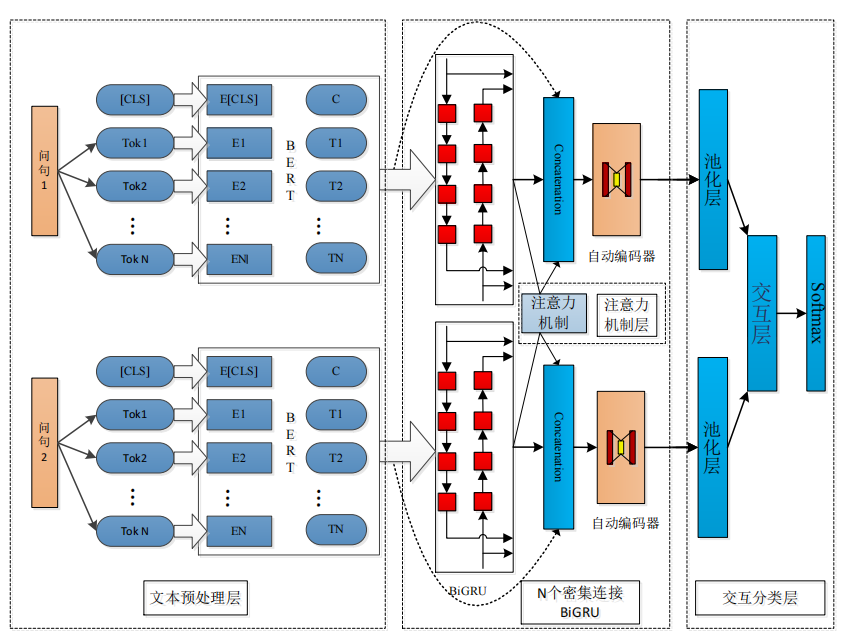
流程:BERT词向量 → DenseBiGRU多层次编码 → 协同注意力交互 → 池化聚合 → 全连接分类。
经过BERT生成词向量后,进入相似度匹配主要包括以下流程:
(1)密集连接BiGRU(DenseBiGRU)特征提取
下面是一些有关概念介绍:
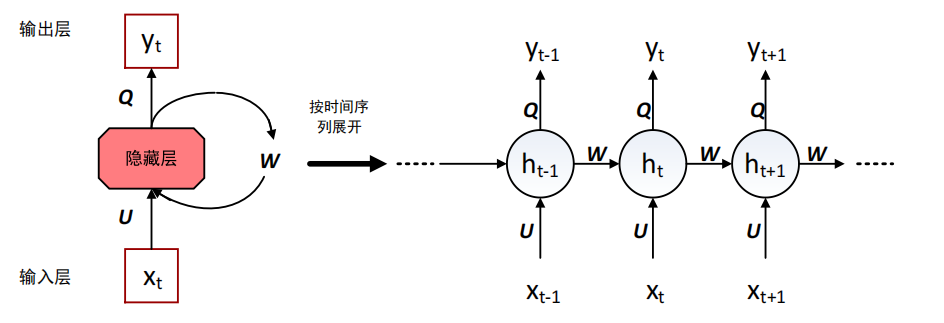
①RNN:循环神经网络(RNN)是一种用于处理序列数据的神经网络。RNN 会记住句子前面部分的特征信息,并利用这些特征信息来影响后续节点特征的输出。RNN 隐藏层之间的节点是拼接在一起的,隐藏层的输入不仅包括输入层的输出,还包括上一时刻隐藏层的输出。如下图所示:
②GRU:GRU是特殊的RNN,它引入重置门(Reset Gate)和更新门(Update Gate),解决RNN的长期依赖问题。
- 重置门:决定多少历史信息参与候选状态计算。
- 公式:
rt取值0~1,0表示完全忽略历史,1表示完全保留。
- 更新门:控制历史信息保留量(控制历史信息的当前输入的权重)。公式如下:
- zt 取值0~1,接近1时保留更多历史,接近0时倾向新信息。
③BiGRU(双向GRU),包括:
前向GRU:从左到右处理序列 (x1→xT)(x1→xT)
反向GRU:从右到左处理序列 (xT→x1)(xT→x1)
保证可以同时捕捉前后文信息。
本文的模型采用了多层 BiGRU 堆叠在一起的结构并循环了 5 次,在每个密集连接的 BiGRU 层都将之前层的输入和本层的输出合并之后向后传递。
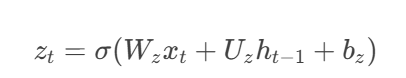
①预处理
输入:BERT生成的词向量序列(假设句子长度为N,每个词768维,形状为
[N, 768])。预处理:通过线性层将768维向量投影到更低维度(如100维),适配BiGRU的输入尺寸。
②双向GRU(BiGRU)
前向GRU:从左到右处理序列,每个时间步
t的隐藏状态依赖前一时间步t-1。后向GRU:从右到左处理序列,隐藏状态依赖
t+1。输出拼接:
若单GRU隐藏单元为100维,BiGRU输出为[前向100维; 后向100维] = 200维。
公式:
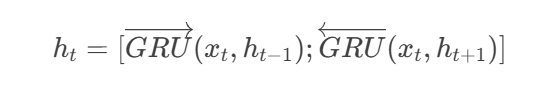
③密集连接(Dense Connection)
输入来源:
第l层BiGRU的输入 = 拼接所有前面层的输出:[H^{l-1}; H^{l-2}; ...; H^0]。例如,若第1层输出
H^1为[N, 200],第2层输入为[N, 200 + 200](假设仅两层)。
数学表达:
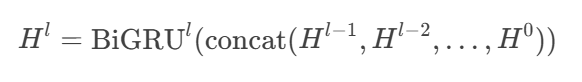
最终输出:经过5层BiGRU后,每时间步输出为
[N, 200](假设每层隐藏单元数不变)。
(2)协同注意力机制(Co-attention)
以下是概念介绍:
注意力机制:学习上下文向量在特定序列上匹配的技术。给定 2 个问句,即在每个 BiGRU 层基于协同注意力机制的 2 句话,计算上下文向量。计算出的注意信息值代表了两句话之间的对齐关系。
本文使用连接操作将注意力机制对 2 个问句交互的信息合并到密集连接的重复特征中。
输入
输入:两个问句P和Q的BiGRU输出(形状均为
[N, 200],N为词数,200为BiGRU隐藏层维度)。
交互对齐步骤如下:
①相似度矩阵计算:
计算问句P的第
i个词与问句Q的第j个词的余弦相似度:
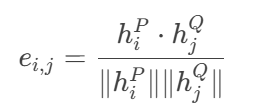
输出矩阵
E形状为[N, N],表示所有词对的相似度。ei ,j 代表 2 个问句向量的相似度,hpi、hqi 代表问句向量表示。
②注意力权重归一化:
对矩阵
E的行和列分别做Softmax,得到权重矩阵α:
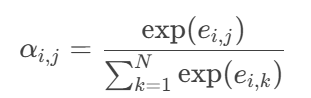
α_{i,j}表示P的第i个词对Q的第j个词的关注程度,αi ,j , 代表注意力权重。
③上下文向量生成:
对问句P的每个词
h_i^P,用权重α_{i,j}加权求和Q的所有词向量:
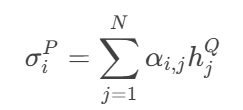
- 输出:
σ^P形状与h^P相同([N, 200]),表示P的词在Q中的语义对齐结果。
④特征增强:
将原始BiGRU输出
h^P与上下文向量σ^P拼接,得到[h^P; σ^P]([N, 400])。
输出与传递
下一层输入:拼接后的
[N, 400]向量作为下一BiGRU层的输入(继续密集连接,和BiGRU 隐藏特征类似,一共5层)。BiGRU的输出给交互层维度恢复为
[N, 200]。
(3)交互分类层
输入
输入:经过所有BiGRU和注意力层后的两个问句特征(形状
[N, 200])。
池化操作
最大池化:沿时间步(词序列)维度取最大值,得到句子级向量:
输入
[N, 200]→ 输出[200](每个维度保留最显著特征)。
作用
压缩变长序列为固定长度,聚焦关键语义(如“病虫害防治”中的“防治”被保留)。
减少噪声词影响(如停用词“的”通常不会被池化选中)。
特征聚合
合并两个问句的池化向量
p和q:
![]()
p-q:捕捉差异特征(如“水稻”vs“小麦”的种植差异)。|p-q|:强化非线性差异(类似曼哈顿距离)。输出
v维度为[800](假设p和q各200维)。
作用:显式编码相似性和差异性,提升分类器决策边界清晰度。
全连接分类
第一层全连接:
输入
[800]→ 输出[1000](ReLU激活)。作用:非线性变换,学习高阶交互特征。
第二层全连接:
输入
[1000]→ 输出[2](对应相似/不相似两类)。
Softmax:
输出概率分布,如
[0.92, 0.08]表示92%概率相似。
监督信号:交叉熵损失函数反向传播优化模型参数。
3.1.2 关于答案优化+排序--动态注意力机制和多匹配策略的 BiGRU 答案选择模型
模型结构图:
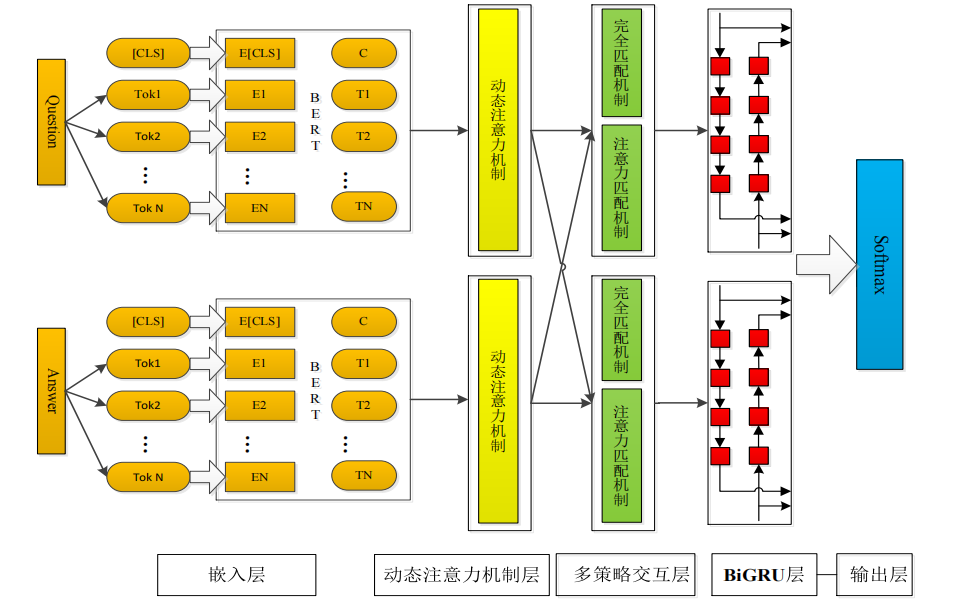
流程图:
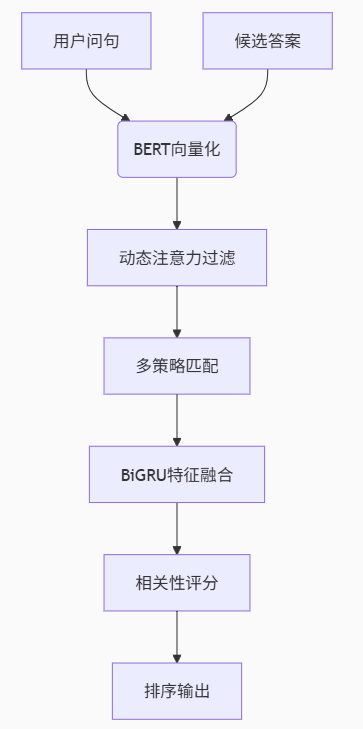
细节:
(1)文本向量化(BERT编码)
输入:用户问句+候选答案(问答对里的答案,不再关注问题)
处理:
使用12层中文BERT模型对问句和答案分别编码:每个词生成768维向量(
[CLS]向量作为句子整体表示)。最大序列长度为128,超出部分截断。输出形状:问句
[N_q, 768],答案[N_a, 768](N为词数)。
(2)动态注意力过滤(过滤文本特征信息的无用信息)
输入:BERT输出的问句和答案词向量。
计算步骤:
计算词级相似度矩阵:余弦相似度

Softmax归一化:
问句对答案的注意力权重:
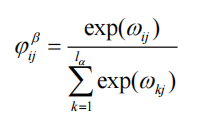
答案对问句的注意力权重:
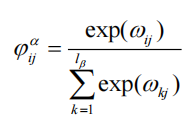
动态过滤:
保留权重Top-K的词(如
"纹枯病"对"井冈霉素"权重0.85保留(权重高)),其余置零。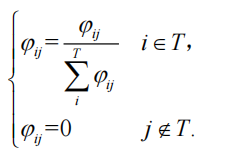
输出:过滤后的问句向量(
[n词 × 768])和答案向量([N词 × 768])。作用:提升关键信息的权重,减少无关词干扰。
(3)多策略匹配交互
输入:动态注意力过滤后的问句和答案向量。
匹配策略:
① 完全匹配(Full-Matching):计算问句每个词与答案整体向量的余弦相似度:
例如:
"纹枯病"与答案整体相似度=0.7 → 特征向量部分值[..., 0.7, ...]
② 注意力匹配(Attentive-Matching):问句词
α_i对答案词的注意力加权和: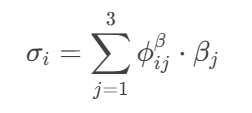
- 计算
α_i与σ_i的相似度: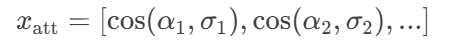
例如:
"防治"与加权答案向量σ_i相似度=0.8 → 特征向量部分值[..., 0.8, ...]
输出:
每个策略生成4个特征向量(如[x_full, x_att]),拼接后为[N, 1600](假设每策略400维)。
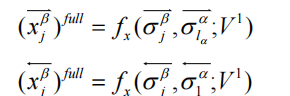
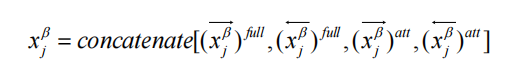
作用:
增强模型对同义表述(如“防治” vs “治疗”)和隐含关联的捕捉能力。
(4)BiGRU特征融合
输入:多策略匹配后的特征(
[N, 1600])。处理:
双向GRU分别处理正向和反向序列:
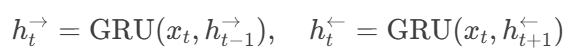
参数示例:
GRU隐藏单元:200(双向拼接为400维)。
输出取最后时间步:
[h^{\rightarrow}; h^{\leftarrow}]
输出:问答对综合特征向量(
[400])。作用:捕捉特征间的时序依赖,例如:
"喷施"动作需在"井冈霉素"之前才合理。
(5)相关性评分与排序
输入:BiGRU输出的特征向量。
处理:
全连接层计算得分:
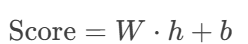
Softmax归一化为概率:
[0.92, 0.05, 0.03](对应3个候选答案)。Softmax归一化的核心目的是将模型的原始输出分数(logits)转化为概率分布,使得所有候选答案的得分满足以下条件:
概率和为1:所有答案的分数归一化为[0,1]之间的值,且总和为1(如0.92+0.05+0.03=1)。
可比性:通过指数函数放大高分项的差距,便于区分最相关答案(如0.92远高于0.05)。
输出:按概率降序排序的答案列表。
作用:实现自动化答案推荐,Top-1答案直接返回给用户。
3.2 《使用分层可导航小世界图进行高效、稳健的近似最近邻搜索》
关于相似度匹配,我找了另一篇论文(
《Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs》),该论文提出了一种名为“分层可导航小世界图”(HNSW)的方法,用于解决近似K近邻搜索(K-ANNS)问题。
该方法牺牲了一些精确度,但是可以在大量的数据集里迅速找到答案。
以下是一些介绍:
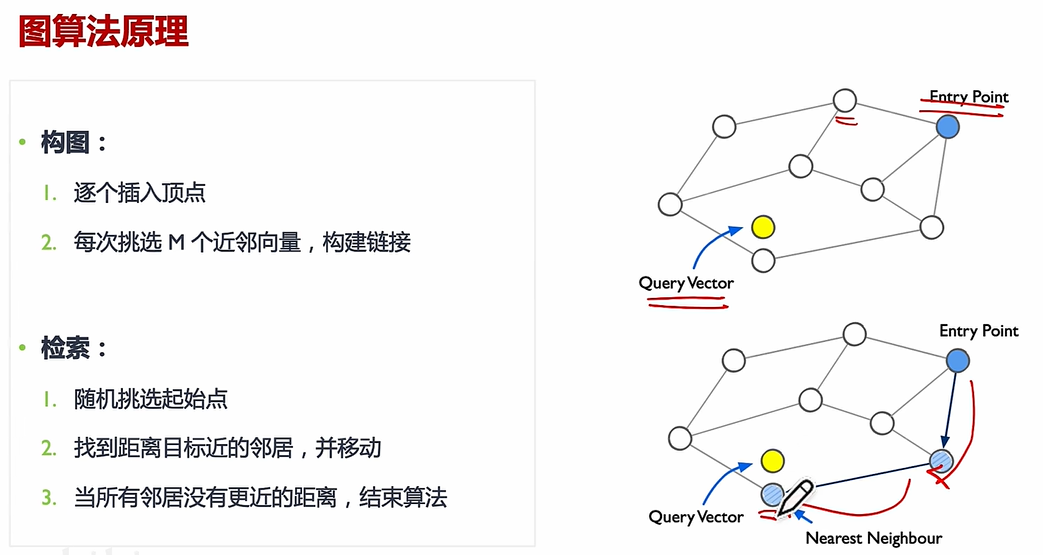
(1)图算法原理:
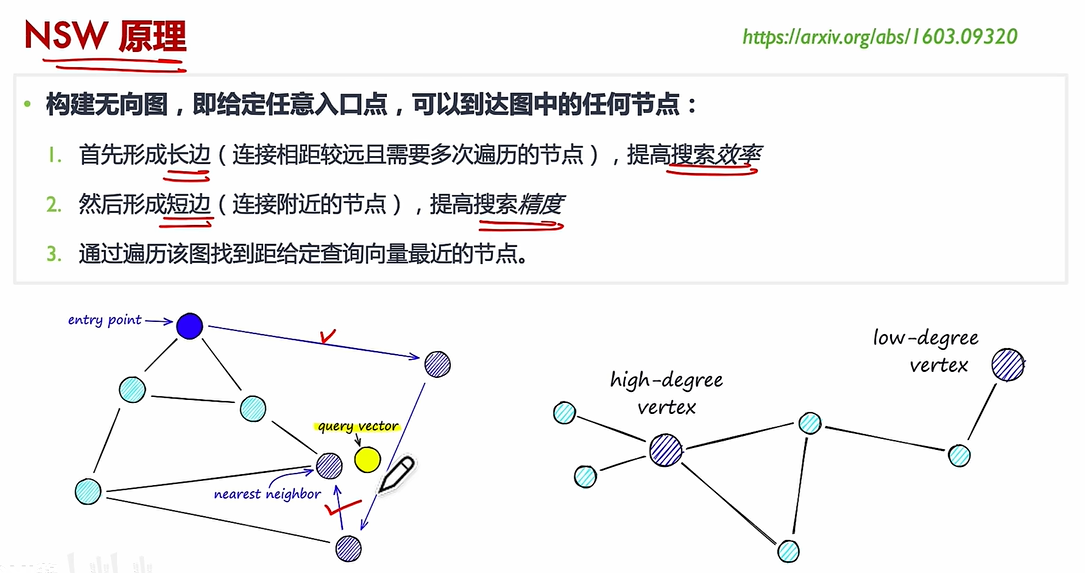
(2)NSW:
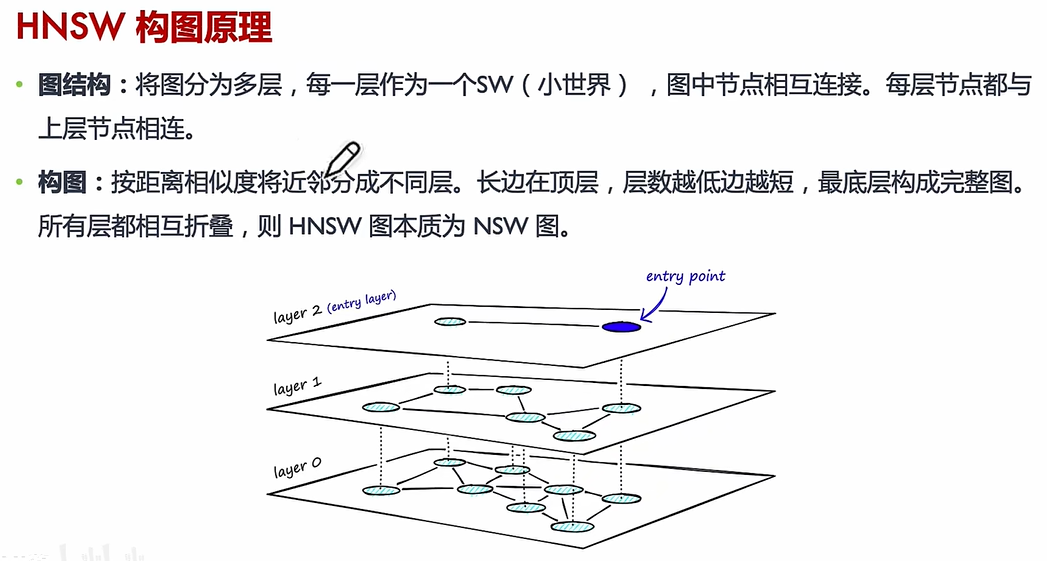
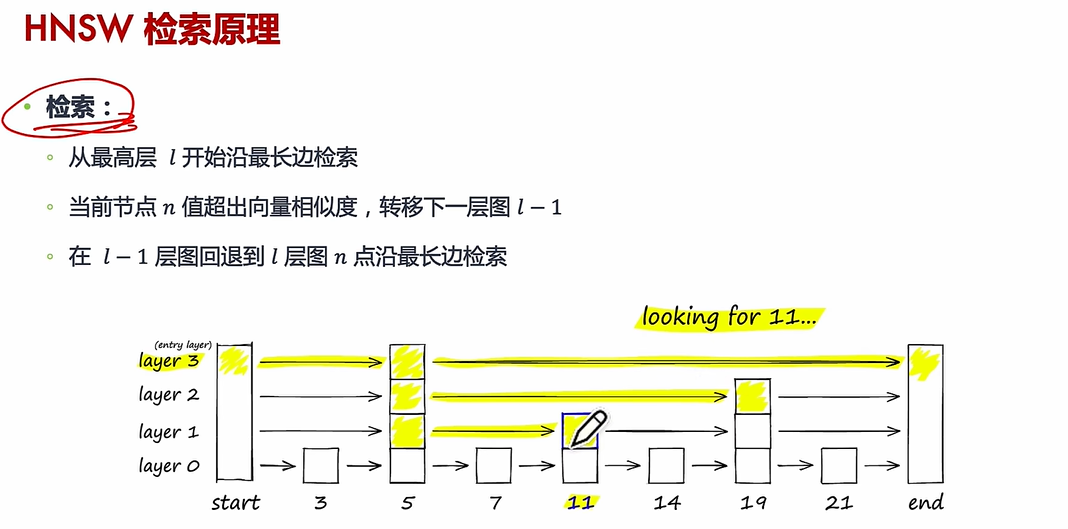
(3)HNSW
核心思想:HNSW 通过构建多层图结构,将数据点按距离分层组织,高层保留“远距离”连接(全局结构),低层保留“近距离”连接(局部细节)。
搜索过程:给定一个查询点,算法从顶层开始逐步向下层搜索,利用贪心策略快速定位最近邻,最终在底层返回最相似的候选结果。
相似度度量:支持任意可计算的距离函数(如欧氏距离、余弦相似度、Jaccard 相似度等),因此适用于多种相似度匹配任务。
所以如果采用HNSW在相似度计算上并没有改变,只是改变了候选集的检索。所以下面是如果采用HNSW的话,在源代码里需要做的修改:
(1)初始化阶段
在
QASystem类初始化时,增加HNSW索引的构建:加载所有问答对的BERT向量后,用这些向量初始化HNSW图结构
设置参数:每层连接数(
M)、构建时的候选规模(ef_construction)
分层图结构:
- 高层(稀疏连接):存储远距离的“导航边”,用于快速定位大致区域
- 底层(密集连接):存储近距离的“细节边”,用于精确搜索
向量映射表:
- 每个节点(对应一个问答对)关联其原始BERT向量,用于后续相似度计算
(2)搜索逻辑改造
替换原有的暴力相似度计算(
np.dot全量计算):调用HNSW的
knn_query接口,传入查询向量和需要的TopK数量直接获取候选问题的索引和原始余弦相似度(与原有接口对齐)
1. 直接计算查询向量与所有向量的相似度
# 伪代码:原有暴力计算
query_vec = [0.1, 0.3, ...] # 查询向量
all_vectors = [ # 所有问答对的BERT向量[0.2, 0.4, ...], # 问题0[0.5, 0.1, ...], # 问题1[0.1, 0.3, ...], # 问题2[0.9, 0.0, ...], # 问题3[0.4, 0.2, ...] # 问题4
]
# 全量计算余弦相似度
similarities = [np.dot(query_vec, vec) for vec in all_vectors]
# 排序后返回Top2
top_indices = [3, 0] # 假设问题3和问题0最相似
top_scores = [0.95, 0.88]2. 调用HNSW接口跳过全量计算
# 伪代码:HNSW近似搜索
top_indices, top_scores = hnsw_index.knn_query(query_vec, k=2)
# 返回结果示例
top_indices = [3, 0] # 直接得到最相似的2个问题的索引
top_scores = [0.95, 0.88] # 对应的余弦相似度分数后续处理完全不变:
校准(Sigmoid)、关键词加权、过滤去重等
(3)增量更新处理
当新增问答对时:
生成新问题的BERT向量后,同步调用HNSW的
add_items插入索引确保新数据可被后续搜索立即访问
4. 总结
本周主要是对相似度匹配这一块代码进行性能提升。可以使用DenseBiGRU (提取多层次文本特征,保留关键信息。)和协同注意力机制(动态聚焦问答中相关的词或短语,抑制噪声。)、交互分类层(聚合交互特征,输出匹配概率或排序结果)来从候选答案中快速、准确地识别或排序出最符合问句语义的答案;可以使用动态注意力机制和多匹配策略的 BiGRU 答案选择模型对候选答案进行精准排序,确保最匹配答案排名靠前;关于HNSW可以使得当有大量数据集时,可以保证快速的搜索到答案。