YOLO--目标检测基础
一、基本认知
1.1目标检测的定义
目标检测(Object Detection):在图像或视频中检测出目标图像的位置,并进行分类和识别的相关任务。
主要是解决图像是什么,在哪里的两个具体问题。
1.2使用场景
目标检测的使用场景众多,比如疫情期间有是否带口罩的目标检测,现在十分火爆的智能驾驶、安防监控、人脸检测等都用到了目标检测。
1.3目标识别与标注
目标识别包含了分类标签信息和图像坐标信息(x,y,w,h),其中(x,y)是中心点的位置坐标,w为宽度,h为高度。
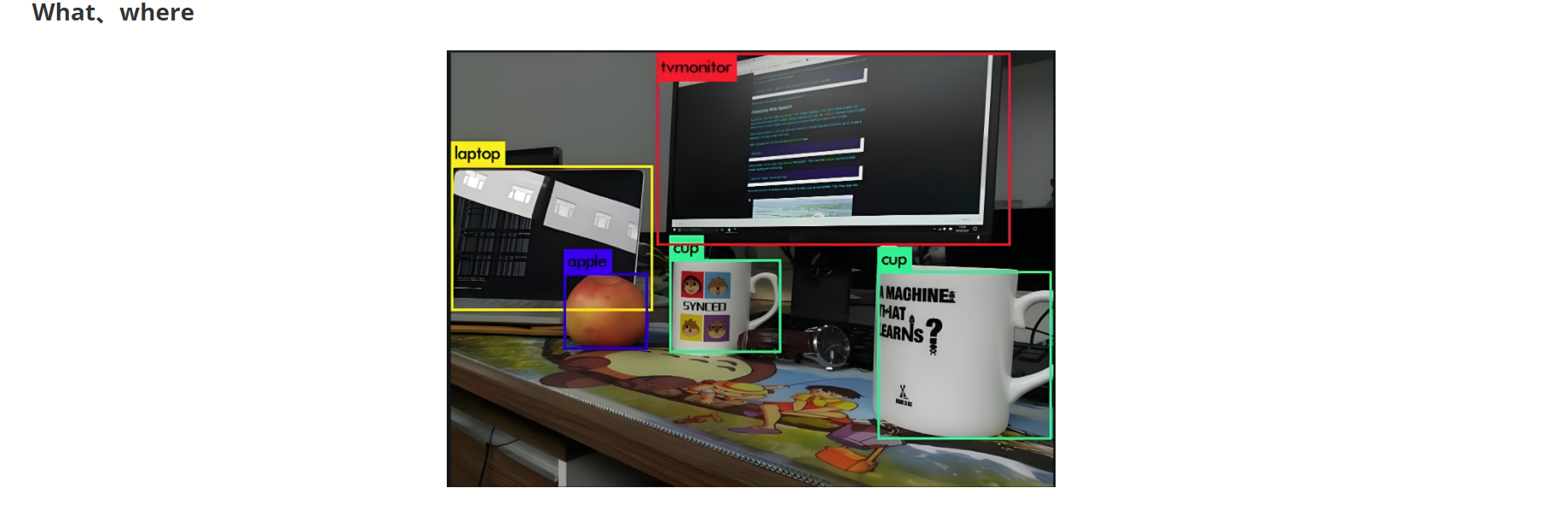
目标标注可以选择使用labelimg或者labelme ,但是常用的是labelimg,它可以直接生成txt文件,直接用在YOLO算法中。
labelimg下载指令:
#创建虚拟环境
conda create -n labelenv python=3.9 -y
#激活虚拟环境
conda activate labelenv
#下载pyqt和sip
conda install -c conda-forge pyqt=5.15.4 sip=6.5.1 -y
#阿里云下载labelimg,注释的内容是降低Set的版本的,根据实际情况查看是否需要
#pip install setuptools==65.5.0 -i https://mirrors.aliyun.com/pypi/simple/
pip install labelimg==1.8.6 -i https://mirrors.aliyun.com/pypi/simple/
#启动labelimg开始进行图像标注
labelimg二、网络基础
2.1目标检测方法
这里主要介绍一步到位法:one-stage
one-stage是单阶段,一步到位,特点如下:
(1)直接从图像中提取特征并进行分类和回归,即同时进行目标分类、位置回归;
(2)计算速度快,适合实时使用;
(3)经典算法:YOLO系列、SSD。
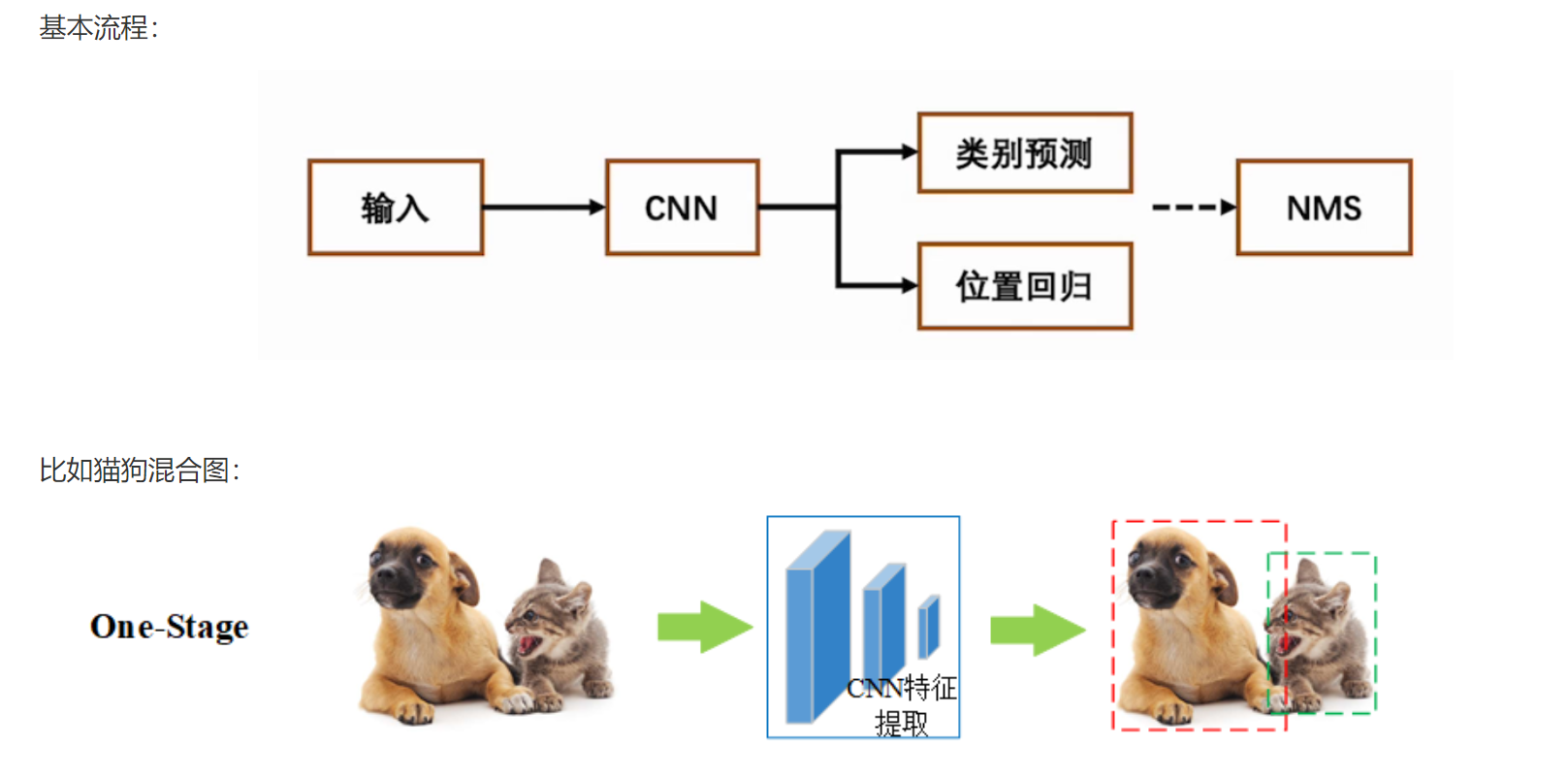
注意:NMS 是 Non-Maximum Suppression(非极大值抑制) 的缩写,是一种用于去除冗余检测框的关键后处理技术。
2.2目标检测指标
2.2.1目标框指标
目标框(Bounding Box):检测目标物体时,会带有的一个标注框,用于表示目标的位置和大小。
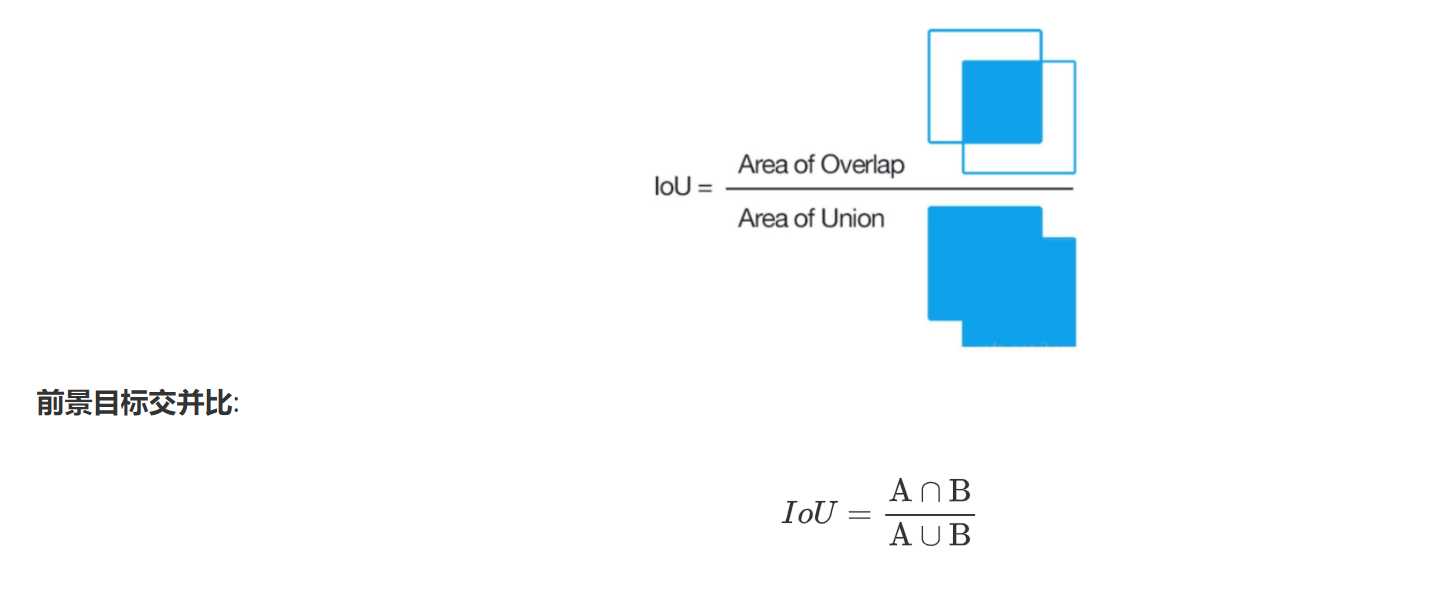
IoU
IoU:预选框正确性的度量指标,其中A通常表示真实框,B表示预测框。计算公式如下:
confidence
confidence:置信度,表示该框包含目标的概率以及预测框的定位准确性。
计算公式:

2.2.2精度和召回率
在了解精度和召回率之前,我们要了解的是混淆矩阵:
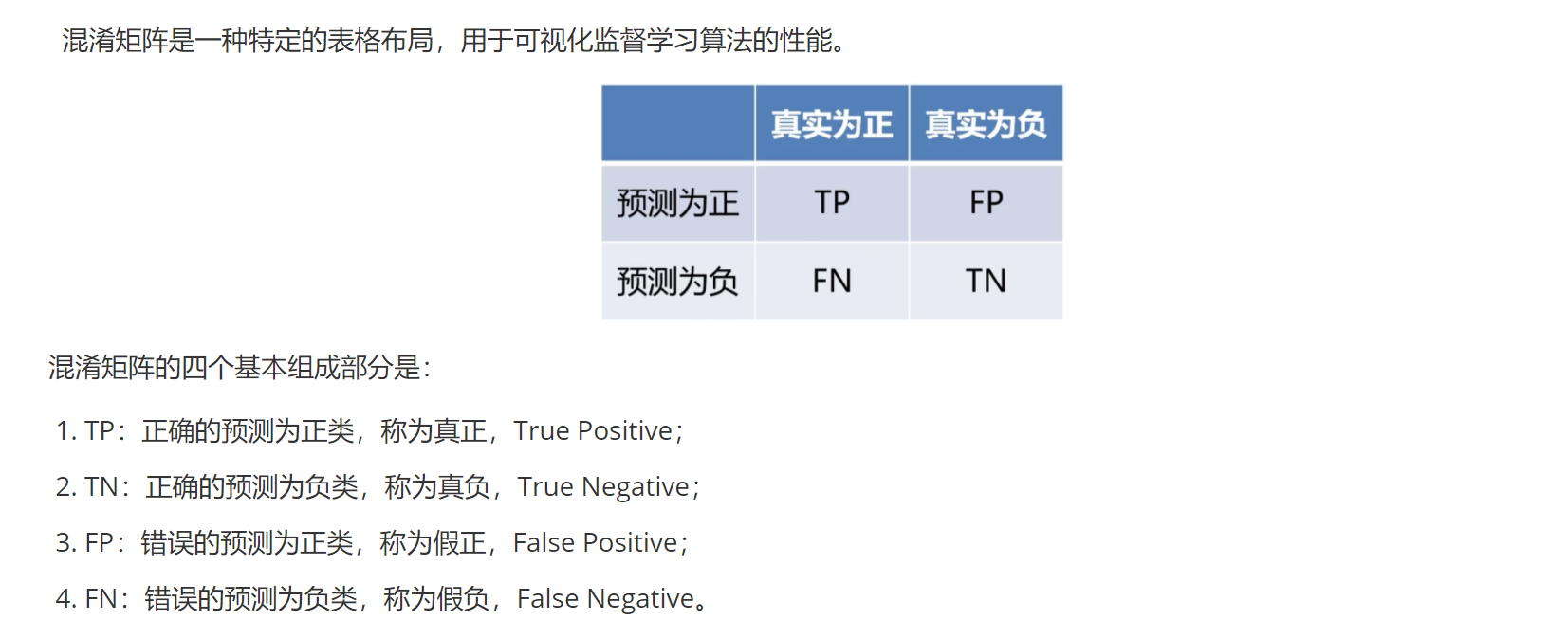
注意:这里的正类和负类不能按照平常认知来区分,只要是根据目标任务的要求来,若要求检测的是工厂里的残次品,那么此刻这里的正类就是残次品。
准确度:预测正确的样本数与总数的比例
A = TP+TN/(TP+TN+FP+FN)
精确度:正类中预测正确的比例
P = TP/(TP+FP)
召回率:目标检测中找到的正类的比例
R = TP/(TP+FN)
F1分数:精确度和召回率的平均数
F = 2*(P * R)/(P + R)
2.2.3mAP的计算
mAP是评估模型的综合指标,主要是根据召回率和精确度进行计算的。但是暂时只记录AP的计算方法。
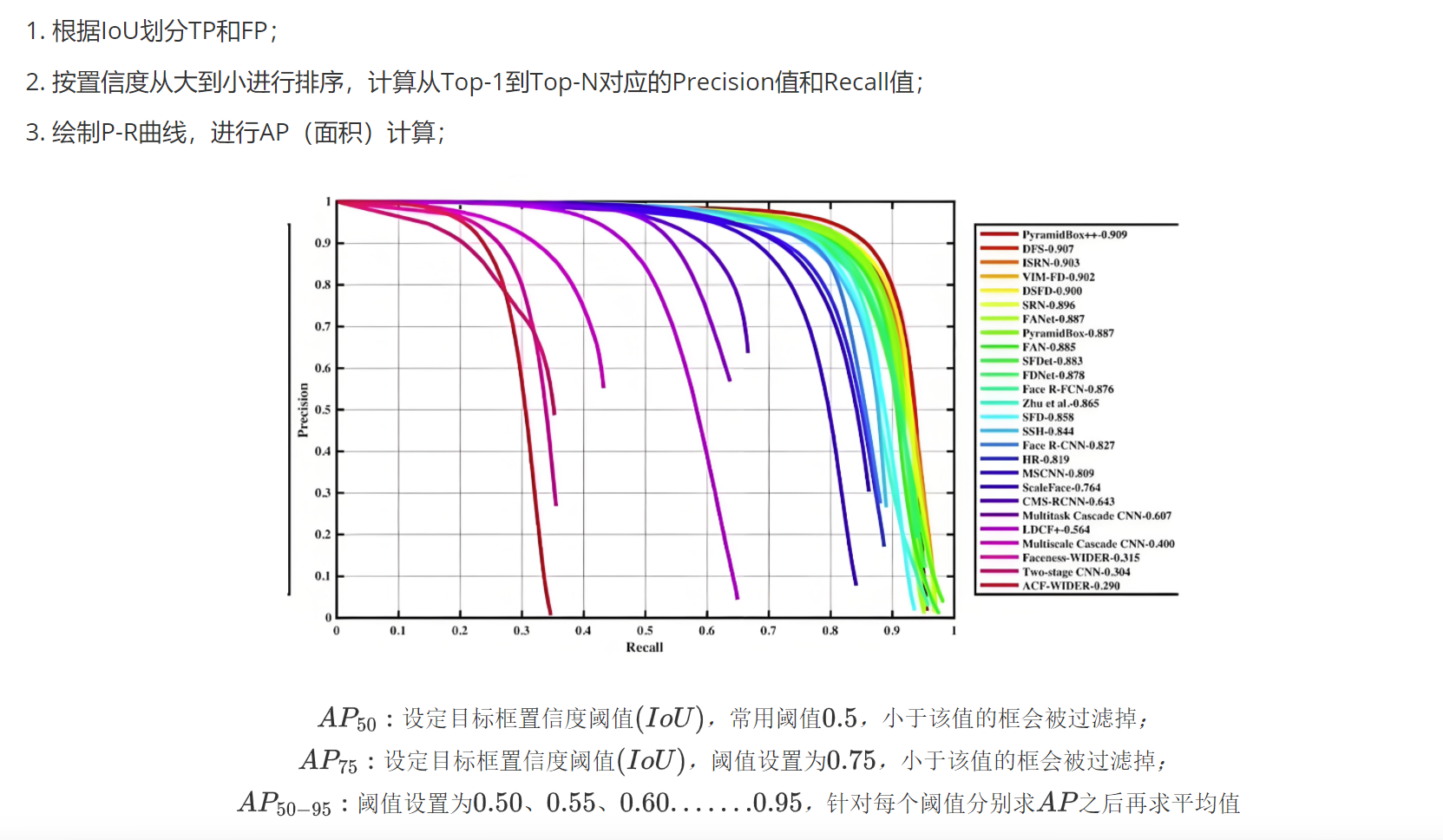
Top-N: 返回前N个框计算指标
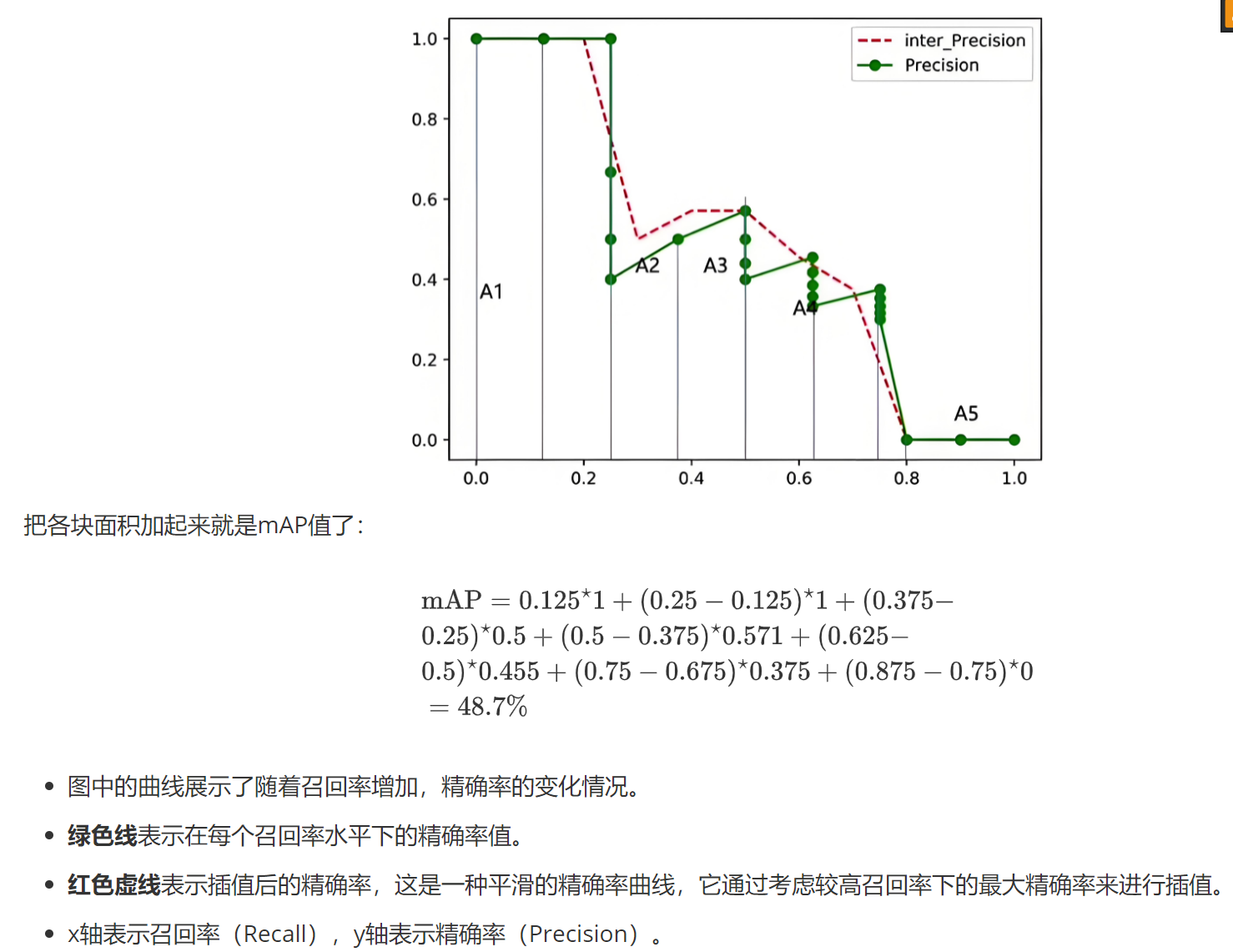
AP(平均精度):
(1)根据公式计算,直接求平均值得到AP值
(2)还是会利用公式,然后根据最大值所在高度的矩形面积相加得到AP值
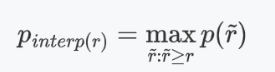
三、NMS
3.1简单介绍
NMS(Non-Maxmum suppression)非极大值抑制:是目标检测目标库后处理的方法。
它的出现主要是为了解决对同一个检测目标出现多个目标框的问题。
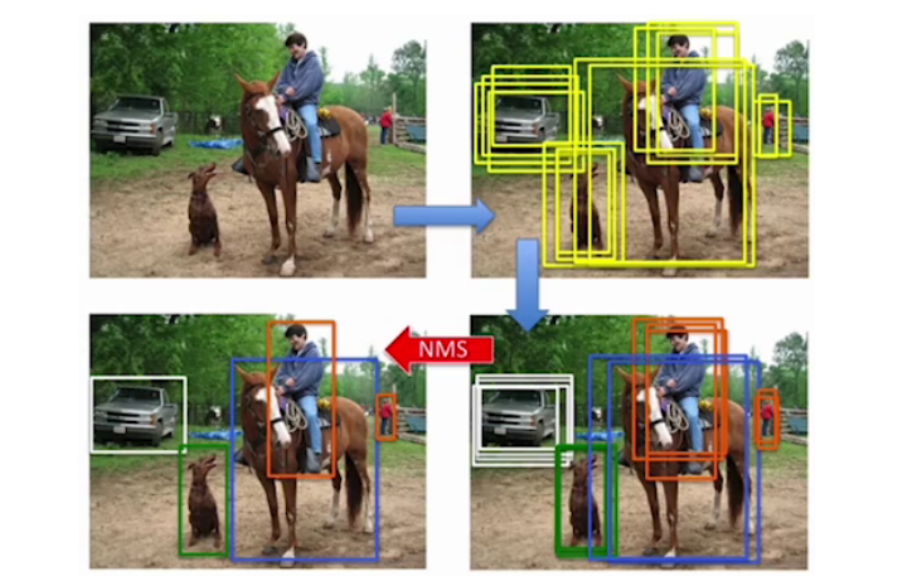
如图,在最后的结果中,我们往往只需要一个最终的,最准确的目标框,所以NMS就发挥了很大的作用。
3.2运算流程
(1)设置IoU(目标框置信度阈值),一般设为0.5,小于这个值的框会被过滤,一般是用来过滤网格中心Bounding Box中没有预测到目标的目标框;
(2)根据置信度进行降序排列候选框;
(3)将置信度最大的框添加到输出列表,并将这个框从候选框中删除;
(4)候选框中的所有框与输出列表的框计算IoU,删除大于IoU阈值的框(这是因为大于阈值的框可能与目标框相似,预测的是同一个目标,这就有一个去重的意思在的感觉)
(5)重复三、四步骤,直到候选框列表为空;
(6)输出列表就是最后的目标框。
3.3 API
pred = non_max_suppression(pred,conf_thres=0.25,iou_thres=0.45,classes,agnostic_nms,max_det=max_det)
参数解释:
classes:
类别限制(Classes):这个参数用于指定只对特定类别的目标进行NMS操作。如果它是一个整数(例如
classes=0),则仅对类别0的目标进行NMS;如果它是一个列表(例如classes=[0, 2, 3]),则仅对类别0、2、3的目标进行NMS。如果不传递该参数,NMS会对所有类别进行操作。
agnostic_nms:
类别无关的NMS(Class-Agnostic NMS):如果该参数设置为
True,NMS会忽略目标的类别信息,所有的框会一起进行NMS处理,不论它们属于哪个类别。如果设置为False(默认值),则会分别对每个类别进行NMS操作,意味着同一类别的框才会相互抑制,而不同类别的框不会相互影响。
max_det=max_det:
最大检测数量(Maximum Detection):这个参数控制NMS后返回的最大框数。它限制了每张图片中最多保留多少个框(目标)。例如,
max_det=100表示每张图片最多保留100个框,超出这个数量的框会被删除。
四、检测速度
4.1前传耗时
从输入图像到输出结果所消耗的时间。单位毫秒。
4.2FPS
FPS(frames per second),每秒钟能处理的图像数量。YOLO目标检测中要求实时监测的最低要求就是一秒钟处理30张图像。
4.3FLOPs
浮点运算量,处理一张图像所需要的浮点运算数量。
五、整体网络结构
5.1网络结构图
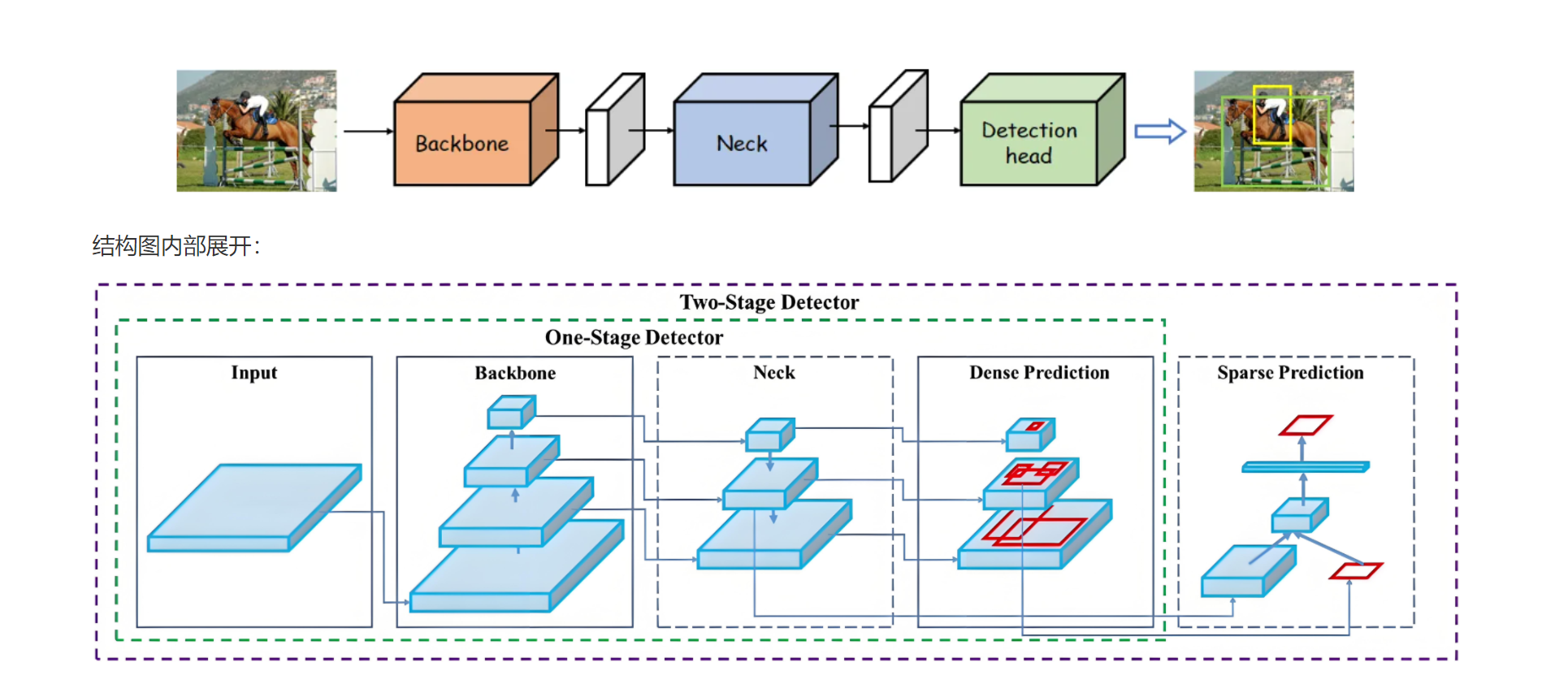
简单理解:
输入图像input:
模型的输入是图像,图像经过后续的处理,生成预测结果。
单阶段检测器(One-Stage Detector):
Backbone:负责提取图像的特征,通常使用卷积神经网络(CNN)来获取图像的特征表示。
Neck:通常由额外的网络层(如FPN,特征金字塔网络)组成,用于进一步处理特征图并增强不同尺度的信息。
Dense Prediction:在这个阶段,模型对图像进行密集的预测,通常会生成大量的候选框,并为每个候选框预测类别和边界框回归。
Detection Head:最后,模型的检测头会处理预测结果,选择最优的边界框并进行分类。
双阶段检测器(Two-Stage Detector):
Backbone & Neck:与单阶段检测器类似,特征提取和处理。
Sparse Prediction:与单阶段检测器的密集预测不同,双阶段检测器会在第一阶段产生少量候选框(即稀疏预测),然后通过第二阶段(如RPN, 区域提议网络)对这些候选框进行精细调整。
5.2YOLO网络结构

该图展示了目标检测模型的架构,模型主要是YOLOv1-v5。参数部分要注意:
FC → 7×7×(5+5+20)(v1):这是一个全连接层(Fully Connected)到7×7的输出,5表示边界框的4个坐标(x,y,h,w)加一个置信度值,20表示类别数(即分类任务中的类别数)。
13×13×5×(5+20)(v2):通过卷积层进行目标检测,每个特征图位置有5个锚框(Anchor boxes),每个锚框有5个参数(4个坐标(这四个坐标主要是预测参数----边界框回归参数(t_x, t_y, t_w, t_h))和1个置信度)和20个类别预测。
13×13×3×(5+80)(v3-v5):这个结构表示输出为3个尺度的特征图,每个尺度对应一个不同大小的特征图,预测5个锚框的坐标和80个类别。不同版本的模型在Head的结构上略有差异。