深度学习 目标检测常见指标和yolov1分析
目录
一、常见指标
1、IoU
2、Confidence置信度
3、精准度和召回率
4、mAP
5、NMS方法
6、检测速度
前传耗时
FPS
7、FLOPs
二、YOLOv1
检测流程
1、图像网格划分
2、类别预测
3、输出张量
损失函数
优点
缺点
如题,这篇介绍一下目标检测中常见的一些指标以及简单分析一下 yolov1 的模型结构。
首先得知道什么是目标检测:目标检测(Object Detection)是计算机视觉领域的核心任务之一,旨在识别图像或视频中感兴趣的物体,并确定它们的位置和类别。与图像分类(仅识别物体类别)不同,目标检测需要同时解决分类(whats)和定位(where)两个问题。
一、常见指标
1、IoU
I 代表【交集】Intersection ,U 代表【并集】Union,IoU全称是 Intersection over Union,也就是交并比,举个例子:
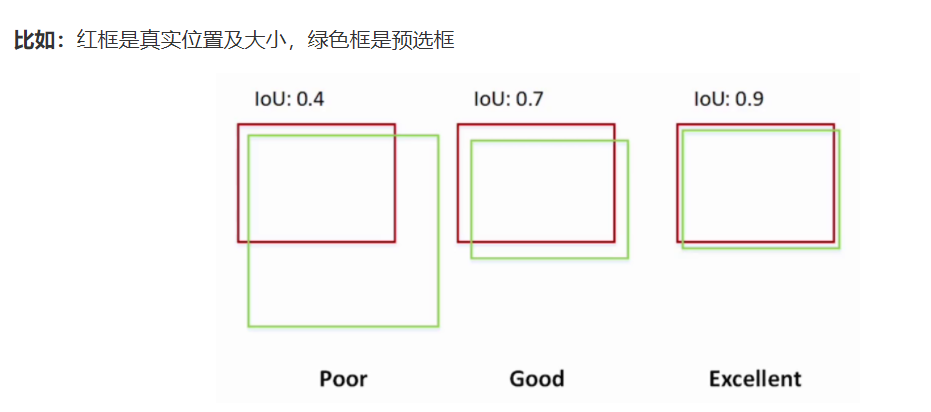
IoU 值越大代表两个框的重叠度就越高
2、Confidence置信度
在 YOLO 中,每个预测框都有一个 置信度分数,表示该框包含目标的概率以及预测框的定位准确性,公式如下:
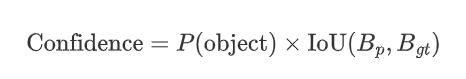
因此,一个框的置信度越高说明:模型认为该框中高概率存在目标,以及预测框和真实框的位置高度吻合。
3、精准度和召回率
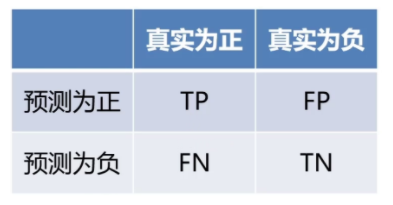
首先要了解混淆矩阵:
-
TP(真正例):模型正确预测为正类(如“是猫”且真是猫)。
-
FN(假反例):模型错误预测为负类(真实是猫但预测“非猫”)。
-
FP(假正例):模型错误预测为正类(真实非猫但预测“是猫”)。
-
TN(真反例):模型正确预测为负类(真实非猫且预测“非猫”)。
混淆矩阵可以直观展示分类模型的预测结果与真实标签的对比,而由混淆矩阵又衍生出精准度(Precision )和召回率(Recall )。
精准度(Precision )定义:模型预测为正类的样本中,有多少是真正的正类,一句话:检查误检的情况。
公式:
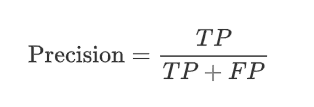
召回率(Recall )定义:真正为正类的样本中,有多少被模型正确地预测,一句话:检查漏检的情况。
公式:
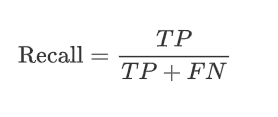
4、mAP
首先要知道 AP是什么,AP 是针对单个类别的检测质量评估,综合考量不同置信度阈值下的精准率(Precision)和召回率(Recall),而 mAP(Mean Average Precision) 就是所有类别的AP的平均值,综合评估模型在所有类别上的整体性能。先计算AP才能得到 mAP,举个小例子:
现在假设有8个目标,但是检测出来有20个目标框,目标框的置信度以及正负样本预测结果如下(IoU阈值假设为0.5):
| ID | Confidence | TP | FP | IoU | Label |
|---|---|---|---|---|---|
| 1 | 0.23 | 0 | 1 | 0.1 | 0 |
| 2 | 0.76 | 1 | 0 | 0.8 | 1 |
| 3 | 0.01 | 0 | 1 | 0.2 | 0 |
| 4 | 0.91 | 1 | 0 | 0.9 | 1 |
| 5 | 0.13 | 0 | 1 | 0.2 | 0 |
| 6 | 0.45 | 0 | 1 | 0.3 | 0 |
| 7 | 0.12 | 1 | 0 | 0.8 | 1 |
| 8 | 0.03 | 0 | 1 | 0.2 | 0 |
| 9 | 0.38 | 1 | 0 | 0.9 | 1 |
| 10 | 0.11 | 0 | 1 | 0.1 | 0 |
| 11 | 0.03 | 0 | 1 | 0.2 | 0 |
| 12 | 0.09 | 0 | 1 | 0.4 | 0 |
| 13 | 0.65 | 0 | 1 | 0.3 | 0 |
| 14 | 0.07 | 0 | 1 | 0.2 | 0 |
| 15 | 0.12 | 0 | 1 | 0.1 | 0 |
| 16 | 0.24 | 1 | 0 | 0.8 | 1 |
| 17 | 0.10 | 0 | 1 | 0.1 | 0 |
| 18 | 0.23 | 0 | 1 | 0.1 | 0 |
| 19 | 0.46 | 0 | 1 | 0.1 | 0 |
| 20 | 0.08 | 1 | 0 | 0.9 | 1 |
计算AP步骤:首先将所有目标框按置信度从高到低排序(这里严格来讲是要再重新标记TP 和FP的,但是因为表格的 TP/FP 列严格基于 IoU≥0.5 和 Label 匹配规则所以可以直接使用,然后我直接用 label 为1 表示 TP,为0 表示 FP ):
| ID | Confidence | Label |
|---|---|---|
| 4 | 0.91 | 1 |
| 2 | 0.76 | 1 |
| 13 | 0.65 | 0 |
| 19 | 0.46 | 0 |
| 6 | 0.45 | 0 |
| 9 | 0.38 | 1 |
| 16 | 0.24 | 1 |
| 1 | 0.23 | 0 |
| 18 | 0.23 | 0 |
| 5 | 0.13 | 0 |
| 7 | 0.12 | 1 |
| 15 | 0.12 | 0 |
| 10 | 0.11 | 0 |
| 17 | 0.10 | 0 |
| 12 | 0.09 | 0 |
| 20 | 0.08 | 1 |
| 14 | 0.07 | 0 |
| 8 | 0.03 | 0 |
| 11 | 0.03 | 0 |
| 3 | 0.01 | 0 |
然后对前 N 个框计算 Precision 和 Recall,N取 1-20:例如 N 为5时,前五行的 TP=2,FP=3,目标一共有8个,则 Precision = 2/5 = 40%,Recall = 2/8 = 25%,计算表格如下:
| 前N行 | Confidence | Label | Recall | Precision |
|---|---|---|---|---|
| 1 | 0.91 | 1 | 1/8(0.125) | 1/1 |
| 2 | 0.76 | 1 | 2/8(0.25) | 2/2 |
| 3 | 0.65 | 0 | 2/8(0.25) | 2/3 |
| 4 | 0.46 | 0 | 2/8(0.25) | 2/4 |
| 5 | 0.45 | 0 | 2/8(0.25) | 2/5 |
| 6 | 0.38 | 1 | 3/8(0.375) | 3/6 |
| 7 | 0.24 | 1 | 4/8(0.5) | 4/7 |
| 8 | 0.23 | 0 | 4/8(0.5) | 4/8 |
| 9 | 0.23 | 0 | 4/8(0.5) | 4/9 |
| 10 | 0.13 | 0 | 4/8(0.5) | 4/10 |
| 11 | 0.12 | 1 | 5/8(0.625) | 5/11 |
| 12 | 0.12 | 0 | 5/8(0.625) | 5/12 |
| 13 | 0.11 | 0 | 5/8(0.625) | 5/13 |
| 14 | 0.10 | 0 | 5/8(0.625) | 5/14 |
| 15 | 0.09 | 0 | 5/8(0.625) | 5/15 |
| 16 | 0.08 | 1 | 6/8(0.75) | 6/16 |
| 17 | 0.07 | 0 | 6/8(0.75) | 6/17 |
| 18 | 0.03 | 0 | 6/8(0.75) | 6/18 |
| 19 | 0.03 | 0 | 6/8(0.75) | 6/19 |
| 20 | 0.01 | 0 | 6/8(0.75) | 6/20 |
最后再由11点插值法计算 AP,公式如下:

比如当 Recall=0.1时,精度值为 Recall=0.1-0.2 (当前阈值和下一级阈值都能取到)之间的最大值,即1,当Recall=0.2时, 精度值为 Recall=0.2-0.3 之间的最大值,也为1,依次计算得到:
| R | 0 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 1.0 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| P | 1.0 | 1.0 | 1.0 | 0.5 | 0.571 | 0.571 | 0.455 | 0.375 | 0 | 0 | 0 |
所以 AP 为:

这里因为只有一个类别,所以 mAP = AP = 49.75%,若再多一个类别 label = 2,则再重复上面的操作,假设得到 label = 2的 AP 为70.25%,则整个 mAP 为 (0.4975+0.7025)/2 = 0.6,即 60%
5、NMS方法
NMS 非极大值抑制(Non-maximum suppression)不是一个指标,而是一个目标检测的后处理方法,当检测目标有多个目标框时就需要 NMS来确定最终的一个框,主要用于优化检测结果,计算步骤如下:
-
设定目标框置信度阈值,常用阈值0.5,小于该值的框(质量不太好)会被过滤掉;
-
根据置信度降序排列候选框;
-
选取置信度最高的框A 将其添加到输出列表,并从候选框列表中删除;
-
候选框列表中所有框依次与 框A 计算 loU,删除大于IoU阈值(高度重叠)的框(可以检测同一个类别的多个目标,比如一张图中不会只有一个人,如果光找置信度最高的框,只会选出一个人的框,因为置信度包含某一个大类别的概率)
-
重复上述过程,直到候选框列表为空;
-
输出列表就是最后留下的目标框,在保留多个目标的同时,去掉对同一个目标的重复预测框。
但是缺点也比较明显,就是一个框只能预测一个结果,如果有两个及其以上的目标重叠在一起,则可能会丢失目标,所以后续会优化
6、检测速度
前传耗时
单位 ms,从输入图像到输出最终结果所消耗的时间,包括前处理耗时(如图像归一化)、网络前传耗时、后处理耗时(如非极大值抑制)。
FPS
Frames Per Second,每秒钟能处理的图像数量,一般每秒处理36帧才能处理实时数据。
7、FLOPs
浮点运算量,处理一张图像所需要的浮点运算数量,跟具体软硬件没有关系,可以公平地比较不同算法之间的检测速,计算公式为:
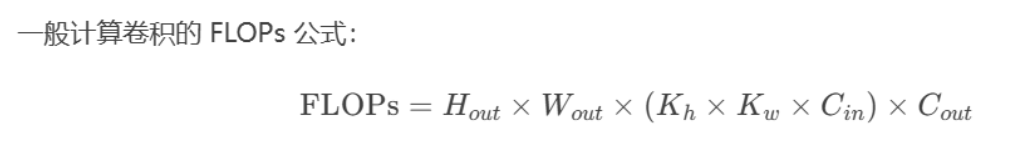
例如,一张64x64x128的特征图用 3x3 的卷积核卷完后,最终输出的通道数为256,则这个过程中的浮点运算量为 (64x64) x128x (3x3) x256 .
二、YOLOv1
YOLOv1(You Only Look Once version 1)是2016年由Joseph Redmon等人提出的首个基于单阶段(one-stage)目标检测算法,其核心思想是将目标检测任务转化为单一的回归问题,通过一次前向传播即可直接预测目标的类别和位置,下面具体讲解一下检测流程(网络结构这些苯人就不说了):
检测流程
1、图像网格划分
将输入图像划分为 SxS 个网格(论文中S=7),每个格子预测 B 个 Bounding Box(论文中B=2),其中每个框包括中心点坐标(x, y)、宽w、高h、置信度conf
2、类别预测
每个格子预测 20 个类别的概率(当时VOC数据集是20分类 )
3、输出张量
最终输出维度为 7x7x30:
这里的 7x7 代表格子数,30 = 2x5+20,2x5 表示两个框内的中心坐标、宽高以及置信度,20表示每个格子代表的20个类别概率,最终会选择置信度较大的框作为预测结果。
损失函数
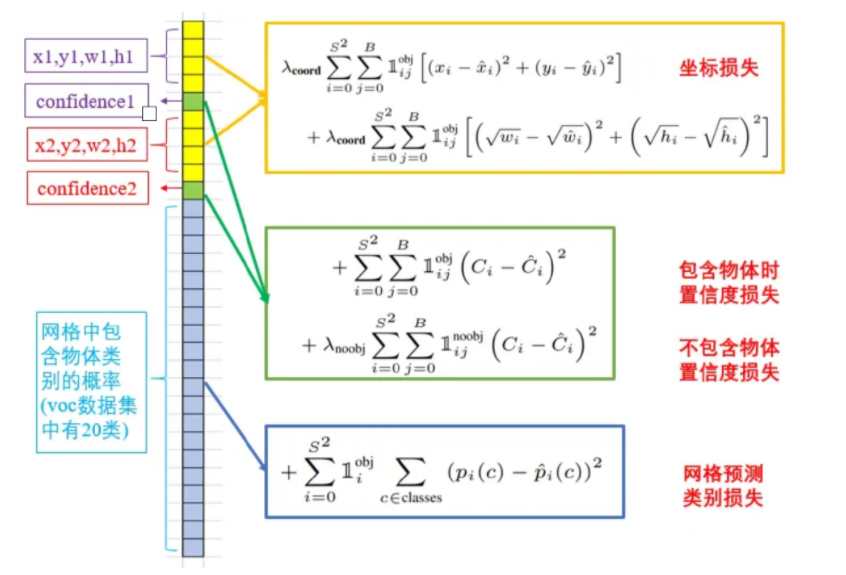
整个YOLOv1的损失函数由五部分组成:
合并后的公式如下:

这里就不详细介绍了,可以自己研究研究,那个 (下标为ij) 代表的意思是如果第i个格子第j个框有物体时则值为1,反之为0.
优点
-
速度快:单阶段检测,实时性强(45 FPS,快速版达150 FPS)。
-
全局推理:直接处理整张图像,减少背景误检(相比R-CNN系列)。
-
端到端训练:简化流程,无需区域提议。
缺点
-
定位精度较低:尤其对小目标和密集目标检测效果差(网格划分限制)。
-
每个网格仅预测一类:难以处理重叠目标。
-
边界框形状受限:预设的Anchor机制未引入(YOLOv2改进)
这篇就到此为止,下一篇可能是YOLOv2 ~ (๑•̀ㅂ•́)و✧
以上有问题可以指出。