go‑cdc‑chunkers:用 CDC 实现智能分块 强力去重
go‑cdc‑chunkers:用 CDC 实现智能分块 & 强力去重
TL;DR
Plakar 发布了一个开源的 Go 库 go‑cdc‑chunkers,实现 Content‑Defined Chunking(内容定义分块),支持多种算法(FastCDC、UltraCDC、Keyed FastCDC 等),速度极快,内存占用低,非常适合备份、同步、分布式数据处理中进行细粒度去重和抗偏移处理需求
一、为什么需要 CDC?
现代系统处理大量数据时经常会遇到重复内容:日志、备份文件、镜像、构建产物等频繁变更却高度相似。传统压缩方式难以处理跨文件重复、数据偏移变化等问题,而 CDC 能根据内容切片,自适应切割,即使插入或删除部分内容,后续相同片段仍能识别重复并去重
二、go‑cdc‑chunkers 是什么?
-
开源且 ISC 许可 的 Go 库;
-
提供统一简洁接口,可轻松切换算法;
-
支持以下算法实现:
-
Plakar 优化版 FastCDC
-
UltraCDC
-
带密钥的 Keyed FastCDC
-
JumpCondition 优化(JC)等 https://github.com/PlakarKorp/go-cdc-chunkers
-
该库适用于流式与批处理场景,API 简洁,易集成。PlakarKorp/go-cdc-chunkers: A Golang package that implements CDC chunkers with a generic interface
三、性能表现令人惊叹 🚀
下面是 Plakar 官方发布的基准测试结果(处理 1GB 随机数据):
| 算法 | ns/op | 吞吐 MB/s |
|---|---|---|
| Restic_Rabin | ~1.93e9 | ≈ 555.6 |
| Askeladdk_FastCDC | ~5.8e8 | ≈ 1852.6 |
| Jotfs_FastCDC | ~4.5e8 | ≈ 2394.0 |
| Tigerwill90 | ~3.77e8 | ≈ 2845.4 |
| PlakarKorp_FastCDC | ~1.18e8 | ≈ 9135.6 |
| PlakarKorp_KFastCDC | ~1.15e8 | ≈ 9312.2 |
| UltraCDC | ~7.9e7 | ≈ 13516.1 |
| JumpCondition (JC) | ~4.98e7 | ≈ 21568.0 |
| (单位:速度越高越好)LinkedIn+11Plakar - Effortless backup+11GitHub+11 |
可以看到 Plakar 在超高吞吐与低延迟方面遥遥领先。
四、FastCDC 的工作原理
FastCDC 使用 Gear 指纹辨识功能,该技术透过XOR将随机表中的预计算值与传入的位元组值进行加法运算来计算滚动杂凑值。这取代了传统 CDC 中使用的 CPU 密集型 Rabin 指纹辨识技术。
FastCDC 的 Gear 表在编译时预先计算:
整体流程如下:
滚动哈希计算
对于每个位元组,根据最后一个值和 Gear 表计算一个新的杂凑值:
hash = (hash << 1) + G[data[i]]
这可以在没有滑动视窗缓冲区的情况下有效地完成,从而大大加快了处理速度。
切点决策
当满足位元遮罩条件时,即声明了区块边界:
if hash & mask == value → cutpoint
此遮罩源自目标平均区块大小,确保区块围绕该目标分布且具有可控的变异性。
智慧视窗边界
FastCDC 在检查切点之前使用最小和最大视窗大小来避免非常小或非常大的区块,从而平滑区块分布。
五、Keyed CDC:隐私与安全增强
常规 FastCDC 的 Gear 表是公开的,意味着同样的输入内容,在不同机器上切块点一致,可能泄露内容分布信息。
Keyed CDC 模式解决此问题:
-
初始化时提供密钥(key),使用 Keyed BLAKE3 构造 Gear 表;
-
使用不同 key,会生成不一样的切割点,即便内容相同;
-
无任何性能损耗,只在初始化阶段开销很小 GitHub+2Plakar - Effortless backup+2Reddit+2。
这是目前少有支持安全 CDC 的 Go 库之一。
六、快速使用示例
go
複製編輯
chunker, err := chunkers.NewChunker("fastcdc", reader) if err != nil { log.Fatal(err) } offset := 0 for { chunk, err := chunker.Next() if err != nil && err != io.EOF { log.Fatal(err) } fmt.Println(offset, len(chunk)) if err == io.EOF { break } offset += len(chunk) }
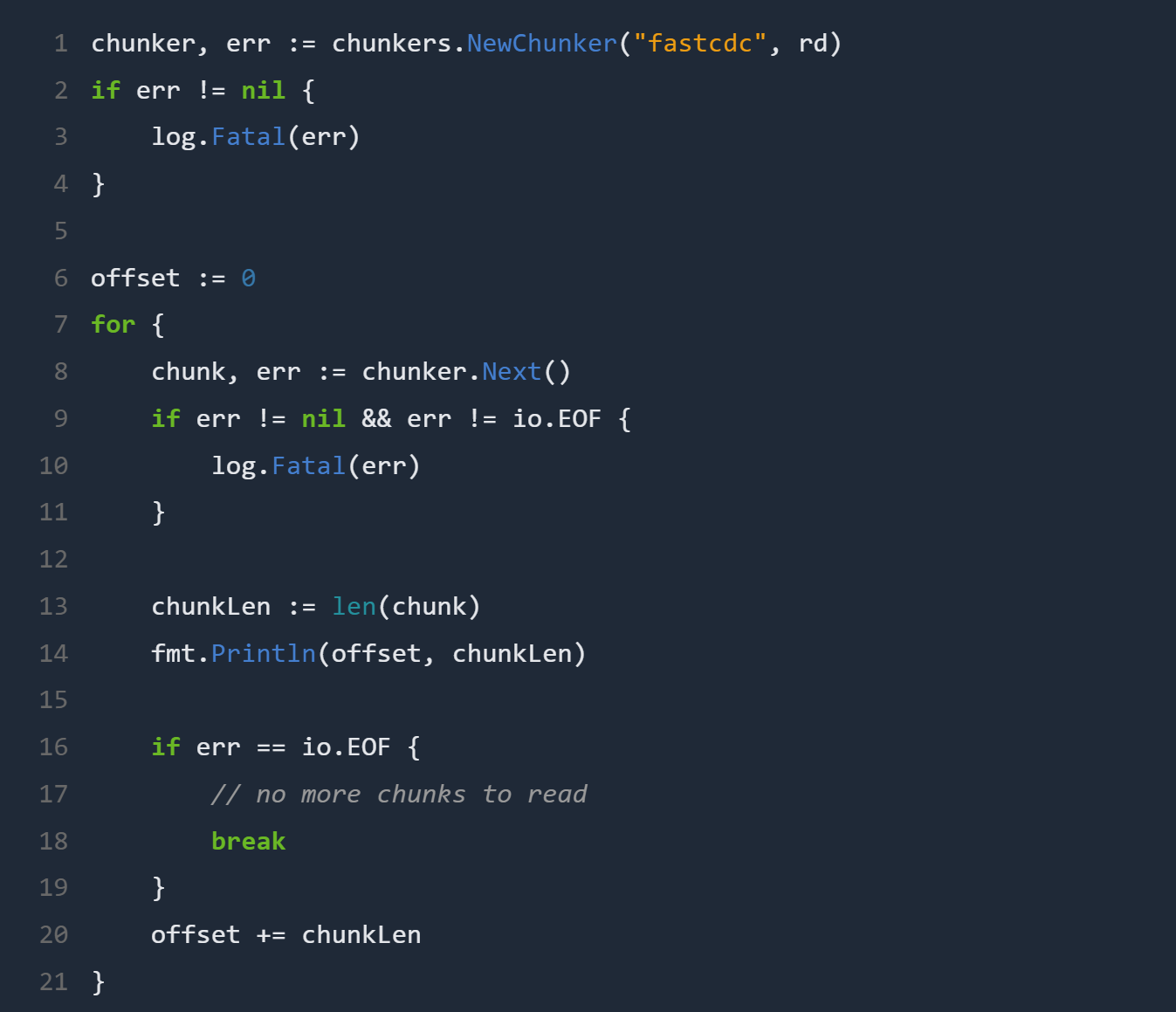
API 清晰,适合嵌入实际生产流程,支持流式处理与大数据切块操作 Plakar - Effortless backupGitHub。
七、适用场景与价值
-
数据备份与快照系统:极佳的重复内容去重,可以大幅减少存储成本;
-
同步与传输:避免多次传输相同内容,提高带宽利用;
-
CI/CD 构建缓存:检测重用构件,减少重复构建;
-
日志、文档版本管理:高效识别内容变化;
-
隐私敏感场景:Keyed 模式防止内容模式泄露。
总结而言,该项目为开发者提供了高性能、内存友好、易用、可扩展的 CDC 工具集,非常值得集成到现代储存与处理平台中 X (formerly Twitter)+8Plakar - Effortless backup+8Plakar - Effortless backup+8。
结语
Go 语言下的开源库 go‑cdc‑chunkers v1.0.0,以驯服重复数据为目标,提供业内领先的 CDC 算法实现,并提出创新的 Keyed 模式,兼顾性能与隐私保护。无论你是在构建备份系统、同步工具,还是开发高效缓存平台,都值得一试。
如需深入了解算法原理、调优参数、或如何在项目中应用,可参考授权文本与 GitHub 仓库。
内容摘要依据 Plakar 官方于 2025 年 7 月 11 日 发布的文章《Introducing go‑cdc‑chunkers: chunk and deduplicate everything》,作者 Gilles Chehade PlakarKorp/go-cdc-chunkers: A Golang package that implements CDC chunkers with a generic interface。
如需增加示例代码、部署实践、或算法细节,欢迎继续交流。