时序数据库选型指南:工业大数据场景下基于Apache IoTDB技术价值与实践路径
文章目录
- 一、工业大数据场景下的时序数据库需求重构
- 大数据角度
- 二、国外主流时序数据库的技术代差分析
- 1. 架构设计对比
- 2. 核心性能对比
- 3. 生态集成对比
- 三、IoTDB 的技术突破与架构
- 1. 自主可控的全栈技术体系
- 2. 工业场景深度优化
- 3. 国产化替代标杆案例
- 四、选型决策框架与实施路径建议
- 三维度评估模型
- 实施路径建议
- 五、工业数据智能的国产化突围之路

一、工业大数据场景下的时序数据库需求重构
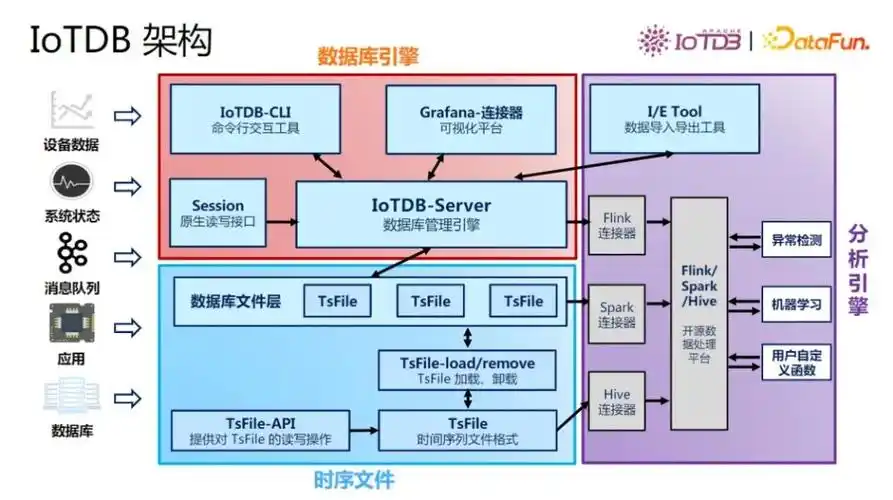
随着大模型和数据产业的发展,在工业互联网与智能制造的浪潮中,设备传感器、生产控制系统产生的时序数据呈现出高频写入、多源异构、时序强关联三大特征。以钢铁行业为例,单条生产线需实时采集温度、压力、振动等 2000 + 参数,数据规模年增 TB 级,传统关系型数据库因缺乏时间维度优化和压缩能力,导致存储成本翻倍且查询响应滞后。这一背景下,时序数据库(TSDB)成为解决工业数据管理痛点的核心工具。
大数据角度
我们从大数据角度看,工业场景对时序数据库提出了三维度技术挑战:
- 存储密度革命:传统的方案需区分热数据(SSD)与冷数据(HDD),硬件投入增加 100%。IoTDB 通过自研 TsFile 文件格式与自适应压缩算法(如 Gorilla、Delta 编码),实现单节点存储效率提升 5-10 倍,且无需数据分层管理。在宝武集团的实测中,IoTDB 将 3TB 原始数据压缩至 100GB,存储成本降低 97%。
- 写入性能跃迁:钢铁生产线要求毫秒级延迟的百万级测点并发写入。IoTDB 通过内存缓冲 + 批量持久化机制,单机写入吞吐量达千万点 / 秒,较 InfluxDB 开源版提升 3 倍以上。某汽车零部件工厂实测显示,IoTDB 单机 8 核稳定输出 50 万 TPS,CPU 利用率仅 65%,而 InfluxDB 2.7 版在同等硬件下仅能达到 10 万 TPS。
- 分析能力进化:工业数据分析需支持有:多维度聚合(如按设备 / 区域 / 时间统计能耗)、时间窗口计算(滑动平均、异常检测)等复杂操作。IoTDB 内置 SQL-like 查询语言,扩展
GROUP BY TIME、LAST_VALUE等时序专用函数,并通过树状数据模型天然适配工业设备层级结构(如root.factory.line.device.sensor),使设备关联性查询效率提升 70%。
二、国外主流时序数据库的技术代差分析
当前市场上,IoTDB 与 InfluxDB、TimescaleDB 等国外产品形成差异化竞争格局。从工业场景适配性角度,可从架构设计、核心性能、生态集成三个维度展开对比:
1. 架构设计对比
IoTDB:主要采用树状数据模型 + 分布式时序引擎架构,专为工业设备层级化管理设计。其双层乱序处理机制(内存层时间窗口排序 + 磁盘层全局合并)可有效解决工业网络不稳定导致的乱序写入问题,在弱网环境下仍能保持 99.9% 的数据完整性。
InfluxDB:主要基于标签(Tag)的扁平化结构,需预先定义测量(Measurement)与字段(Field),在复杂设备建模时灵活性不足。开源版仅支持单机部署,企业版虽提供集群功能,但元数据管理依赖独立节点,运维复杂度较高。
TimescaleDB:基于 PostgreSQL 扩展,同事采用 Hypertables 实现时间分片。虽支持 SQL 语法,但缺乏对时序数据的深度优化,在处理亿级测点时易出现索引膨胀问题。
2. 核心性能对比
在相同硬件配置(8C/32G/SSD)下的实测数据显示结果:
写入性能:IoTDB 单机 50 万 TPS,InfluxDB 2.7 版 10 万 TPS,TimescaleDB 15 万 TPS。
压缩效率:IoTDB 通过 Gorilla 编码 + 二阶差分算法实现 18:1 压缩比,InfluxDB 为 8:1,TimescaleDB 为 12:1。某储能电站案例中,IoTDB 将 4.8TB 原始数据压缩至 267GB,月度存储成本从 5760 元降至 1015 元。
查询延迟:在 10 万测点、10 年跨度数据查询中,IoTDB P99 延迟 < 500ms,InfluxDB 为 3.2s,TimescaleDB 为 1.1s。
3. 生态集成对比
IoTDB:与 Hadoop、Spark、Flink 深度集成,支持通过 Flink SQL 直接处理 TsFile 文件。在中车四方的列车监控系统中,IoTDB 与 Flink 结合实现 300 辆列车并发数据的实时分析。
InfluxDB:生态聚焦监控领域,与 Prometheus、Grafana 无缝集成,但缺乏工业协议(如 OPC UA)原生支持。
TimescaleDB:依赖 PostgreSQL 生态,适合混合分析场景,但需额外开发时序数据预处理模块。
三、IoTDB 的技术突破与架构
IoTDB 作为国产时序数据库的标杆,通过三大核心技术创新构建了工业场景护城河:
1. 自主可控的全栈技术体系
存储引擎革新:TsFile 格式采用列式存储与多级索引设计,支持乱序数据重组与延迟压缩。在上海电气国轩的储能场景中,IoTDB 处理 500 万测点、秒级采集频率数据时,单节点存储效率较传统方案提升 8 倍。
分布式架构优化:通过 IoTConsensus 共识协议框架,用户可灵活选择强一致性(Ratis)或高性能(IoTConsensus)模式。某核电项目部署的 IoTDB 集群,在 300 万测点并发写入时实现 99.99% 可用性。
边缘计算融合:IoTDB Edge 轻量版(<50MB)支持边缘设备本地存储,断网缓存 7 天数据,并通过 TsFile 文件实现低带宽同步。在宝武集团的钢铁产线中,边缘节点与云端数据同步带宽消耗降低 90%。
2. 工业场景深度优化
设备建模能力:树状数据模型天然适配工业设备层级关系。中国恩菲在有色金属智能工厂中,通过 IoTDB 清晰映射 “列车 - 车厢 - 设备 - 传感器” 四级结构,实现 10 万测点的毫秒级查询。
时序分析增强:IoTDB 2.0 引入树表双模型,既支持 OT 领域的树形设备管理,又兼容 IT 领域的 SQL 分析习惯。在中核武汉的核电平台中,通过表模型实现静态属性(设备型号)与动态时序数据的关联查询,分析效率提升 40%。
AI 原生集成:内置时序大模型训练框架,支持直接对接 TensorFlow/PyTorch。在某热电厂案例中,IoTDB 通过实时数据训练振动预测模型,将设备故障预警准确率从 65% 提升至 92%。
3. 国产化替代标杆案例
能源电力领域:在华润电力的新能源智慧运营系统中,IoTDB 管理 1000 万测点、秒级采集数据,日增数据超 10 亿条,存储成本降低 80%。其跨网闸同步功能支持南瑞 syskeeper2000 等国产设备,满足电力行业安全隔离要求。
智能制造领域:某汽车零部件工厂采用 IoTDB 后,写入性能提升 5 倍,查询延迟从 18 秒降至 400 毫秒,实时监控页面白屏问题彻底解决。
核电场景:中核集团部署的 IoTDB 集群管理 50.3 万测点,处理 4000 亿条时序数据,支持核电设备可靠性管理、数字孪生等核心应用,实现 “一总部多基地” 的数据集中管控。
四、选型决策框架与实施路径建议
三维度评估模型
在面对工业大数据场景,时序数据库选型需遵循三维度评估模型:
- 技术适配层:
设备建模复杂度:树状结构优先选择 IoTDB,标签化场景可考虑 InfluxDB。
数据规模与增长预测:亿级测点、十年跨度数据优先 IoTDB 分布式集群。
分析深度要求:需时序预测、异常检测等 AI 功能,IoTDB 的内置大模型框架更具优势。
- 成本控制层:
硬件投入:IoTDB 的高压缩率可减少 50% 以上存储服务器采购成本。
运维成本:InfluxDB 企业版授权费用高昂,IoTDB 开源生态降低长期持有成本。
- 生态协同层:
现有技术栈:已部署 Hadoop/Spark 的企业,IoTDB 的无缝集成可减少开发工作量。
国产化要求:涉及关键基础设施的项目,IoTDB 的自主可控特性更符合政策导向。
实施路径建议
- 原型验证阶段:
使用 IoTDB Benchmark 工具模拟实际场景,测试写入吞吐量、查询延迟等核心指标。
对比 InfluxDB、TimescaleDB 的相同数据集性能,量化 IoTDB 的技术优势。
- 迁移实施阶段:
采用 TsFile 文件实现数据无缝迁移,某储能厂商将 3TB InfluxDB 数据迁移至 IoTDB 仅耗时 8 小时。
利用 IoTDB 的流批协同机制(重点数据实时同步 + 全量数据按需汇聚),实现生产系统平滑切换。
- 长期演进阶段:
基于 IoTDB 2.0 的树表双模型,构建 OT-IT 融合的数据中台。
探索 AI in SQL 功能,在数据库内核实现预测性维护、能耗优化等智能应用。

五、工业数据智能的国产化突围之路
在工业互联网与智能制造的数字化转型中,时序数据库已从工具选择上升为数据战略基础设施。IoTDB 凭借自主可控的技术架构、工业场景深度优化、端边云一体化能力,正在打破国外产品的垄断格局。从宝武钢铁的产线监控到中核集团的核电运维,从上海电气的储能云平台到中国恩菲的智能工厂,IoTDB 用千万级 TPS 写入、18:1 压缩比、毫秒级查询响应的硬核实力,证明了国产技术在工业大数据领域的可行性与领先性。
随着人工智能技术的快速发展,IoTDB 在 AI 融合应用方面展现出独特优势。其内置的 AI 时序大模型框架可直接对接 TensorFlow、PyTorch 等主流深度学习框架,实现从数据存储到智能分析的无缝衔接。在某热电厂设备预测性维护项目中,IoTDB 基于 LSTM 网络训练的振动预测模型,将故障预警准确率从传统阈值报警的 65% 提升至 92%,显著降低了非计划停机风险。同时,IoTDB 支持在数据库内核直接执行 AI 推理任务,通过 SQL 接口调用训练好的模型,实现异常检测、趋势预测等智能分析功能,大幅降低了工业智能应用的门槛。
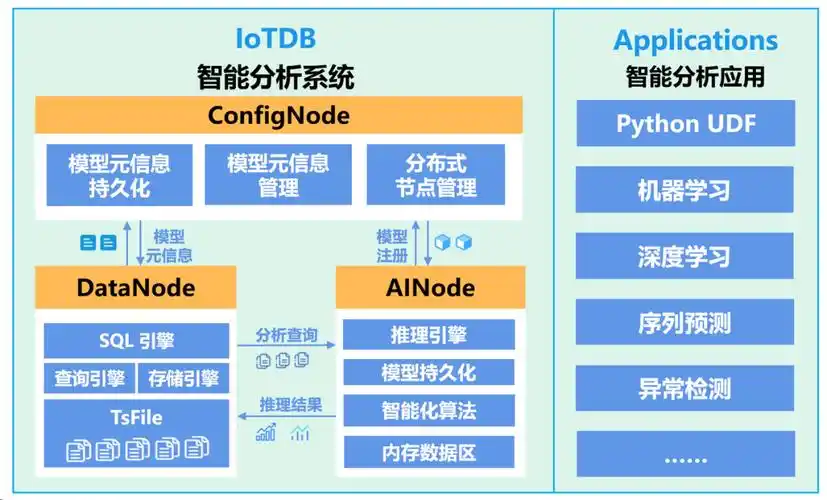
在边缘计算场景中,IoTDB Edge 版本集成了轻量级机器学习模型,可在边缘端实现本地化的实时智能分析。例如在某智能制造工厂的焊接质量监控中,IoTDB Edge 结合集成学习算法,在边缘侧完成焊缝质量的实时判定,判定延迟小于 100ms,避免了云端传输延迟对生产节拍的影响。此外,IoTDB 还支持联邦学习框架,可在保护数据隐私的前提下,实现跨工厂、跨区域的协同模型训练,为集团化制造企业构建统一的智能运维体系。随着 AI 与边缘计算的深度融合,IoTDB 将持续迭代智能压缩算法与分布式一致性协议,助力中国工业企业构建更高效、更安全的数字孪生系统。
下载链接:https://iotdb.apache.org/zh/Download/
企业版官网链接:https://timecho.com