Focusing on Tracks for Online Multi-Object Tracking—CVPR2025多目标跟踪(TrackTrack)
Focusing on Tracks for Online Multi-Object Tracking—以轨迹为中心的在线多目标跟踪算法
文章目录
- Focusing on Tracks for Online Multi-Object Tracking—以轨迹为中心的在线多目标跟踪算法
- 前言
- 摘要
- 介绍
- 方法策略
- Track-Perspective-Based Association (TPA)
- Track-Aware Initialization(TAI)
- Tracking Pipeline
- 消融实验和比较
前言
趁着导师看写的研究生期间第一篇论文空闲下来的时间,打算补充学习总结回顾一下MOT和视觉跟踪等一些领域中在最新的时间段上的研究成果和论文。首先学习回顾CVPR2025和多目标跟踪相关的三篇论文,第一篇也就是这一篇个人认为是实现和理解起来最简单的一篇文章。
到这个时候自己也是学习了MOT一年左右的时间了。虽然没有学的很精通多少是能够有了一些理解。随着自己研究实验和写第一篇论文的过程也是逐步的对MOT领域的顶刊顶会的论文有了从不同初学过程中的一些理解了
根据自己最近闲下来的时间看的经验来说。CVPR,ICCV,ECCV,AAAI等相关的顶会文章所录用的文章中,传统的ByteTrack,FairMOT,甚至MOTR的相关的文章在顶会的角度上来说已经很少能看到了,这一年中的针对传统方面改进的文章已经很少了。现在的研究角度更多的感觉是向开放词汇跟踪这种向多模态或者统一的角度上靠拢。可以也是未来的一个研究趋势,针对传统的MOT17 MOT20的研究也许日后会被逐步的取代。
这里我们单讨论传统的MOT上的研究文章。
-
这一篇提出的概念:以轨迹为中心,让我想起了OC-SORT中提到的以观察为中心改进卡尔曼滤波的这个思路有异曲同工之妙。这里改进的则是关联策略的角度,取代了自己写论文用的匈牙利算法或者说线性最优匹配这种。这里属于是第一次改变了关联方式可以说是一种全新模式的跟踪器。
-
第二篇南京大学MeMOTR的团队提出的论文发表在CVPR2025,这个了解起来感觉档次上要高不少,首次将多目标跟踪的关联任务看成是id预测任务,把数据关联看作是模式的一个回归的结果。也是一个全新的跟踪模式。
-
第三篇则是浙大第一次提出大规模数据集用于多视角的跟踪。
现在的论文上的创新在效果好的情况下,跟容易接受的是全新提出的一个模式或者算法,而非完善或者改进的算法。
摘要
这篇文章理解起来的难度相对来说,感觉出现在CVPR上是有点让我觉得有点吃惊的,代码没有开源但是官网上的效果确实名列前茅。没有训练网络是手工设计的启发式算法。没有复杂的数学公式,却吊打了Gmtracker这种复杂公式的关联算法,而且它这个角度只能说也许我看完也能做,确实是很简单的思路方式。却得到了外界的肯定。
多目标跟踪(MOT)是计算机视觉中的一项关键任务,需要对视频帧中的多个目标进行准确识别和连续跟踪。然而,现有的方法主要依赖于全局优化技术和多级级联关联策略,往往忽略了MOT中任务分配的特殊性和可能代表遮挡目标的有用检测结果。为解决该问题,提出了一种新的以轨迹为中心的在线多目标跟踪器(TrackTrack),该跟踪器具有两个关键策略:
这个地方看完我就觉得是有点不靠谱的,这种改动有用吗?现在的TBD不都是在最后的代价矩阵上不管是手工设计的还是模型给出用匈牙利算法去做,多级的关联策略ByteTrack之后不都是变得越来越复杂了。这里两个策略直接就把根本的地方改动了。
当前 SOTA 方法常见做法:
-
全局优化技术(global optimization technique):
-
比如网络流(network flow)、匈牙利算法(Hungarian)、图优化等
-
试图在整段视频或长时间窗口内一次性求解最佳目标轨迹
-
-
多阶段级联关联(multi-stage cascade association):
-
先短期关联 → 再长时关联
-
或先用高置信度检测 → 再补低置信度检测
-
TPA 策略通过从所有可用的检测结果中选择与轨迹距离最小的检测结果,
以轨迹为视角(track-perspective)的方式,将每个轨迹与最合适的检测结果关联起来。
track-perspective manner:从轨迹的视角出发:
对每一条轨迹单独寻找最佳检测,而不是全局同时优化所有轨迹
不一定要求全局最优,而是局部最优(更简单,也可能更高效)
TAI(Track-Aware Initialization)通过抑制那些与当前活跃轨迹以及置信度更高的检测结果高度重叠的检测结果的轨迹初始化,从而在轨迹感知层面避免生成虚假的轨迹。
TAI(Track-Aware Initialization) 是一种策略,主要用于避免错误地创建多余的(虚假的)轨迹。
它关注的是“轨迹感知”层面:也就是说,知道当前已经存在的轨迹,避免因为检测器检测到的多个重叠框导致重复创建轨迹。
具体做法是: 对于当前帧中检测结果,如果它们与已有活跃轨迹的预测位置重叠很大,并且有比它们更置信的检测结果,就抑制对这些检测结果的轨迹初始化,避免它们被误认为新目标,从而减少假阳性轨迹。
这个地方其实就可以看作是ByteTrack在初始化判断置信度的一个改进。
介绍
随着目标检测技术的最新发展大多数方法主要通过构建多阶段关联流程和引入额外的度量指标(例如伪深度或运动方向)来提升数据关联的性能,同时利用匈牙利算法来解决轨迹与检测结果之间的匹配问题。
之后就马上介绍了文章最核心的一个思想。
因为轨迹和检测结果高度相关,因为它们都代表相同的真实目标,且每次关联都有唯一正确的答案。因此,将多目标跟踪中的数据关联问题视为为每条轨迹选择最优匹配项,比单纯地最小化全局代价更为合理,尤其是在涉及遮挡的场景下。

看到这个图我自己就有了一个很大的感受了,很多误差的存在就是因为在匈牙利匹配的时候一个目标关联错误之后,导致后续的Detection被关联完了,导致原本能正确的选项后面也就逐步的出现了新的错误了。
轨迹和检测结果的高度依赖性
-
轨迹(tracks)是跟踪器对目标的历史估计,
-
检测结果(detection results)是当前帧检测器输出的候选目标,
-
两者都指向同一组真实存在的物体,密切相关。
每次关联有正确答案
-
对于每条轨迹,都存在一个最合适的检测结果对应它,即“正确的匹配”,
-
关联任务实际上是“为轨迹找到正确检测”的问题。
传统方法的不足
- 传统方法多采用全局代价最小化(如匈牙利算法全局匹配)
但- 这忽略了轨迹个体的特点,可能在遮挡等复杂场景中导致错误匹配。
更合适的框架
-
从“轨迹视角”逐条选择最优检测
-
这种方式更贴合实际目标关联过程
另一方面,许多传统方法 试图通过引入低置信度检测结果(这些检测结果可能对应部分可见的目标)来提升性能,具体做法是采用多阶段的级联匹配策略(multi-stage matching cascade)。然而,在这种级联流程中,首先会将高置信度检测结果与轨迹进行匹配,之后只将低置信度检测结果与剩余未匹配的轨迹进行匹配。因此,这导致了低置信度检测结果的次优利用——而这些检测结果本可以是部分轨迹更好的匹配选项,最终在存在遮挡的场景中降低了跟踪性能。
这个地方我感觉没啥太多可以解释的,跑过ByteTrack的实验代码就能发现低分框的两个缺陷,错误的关联导致虚假的轨迹是一个方面,第二个是低分框需要关联的Detection,高分框已经关联错误了,低分框结合IOU在密集的遮挡条件上可能又关联错误。
针对该问题,该文提出了一种基于轨迹视角的关联方法TPA,该方法利用所有可用的检测结果,包括高置信度和低置信度检测结果,甚至包括在非最大抑制(NMS)期间丢弃的高置信度检测结果,同时关注每个轨迹的局部透视。此外,我们引入了航迹感知初始化(TAI),它选择性地初始化新航迹,仅使用冗余候选航迹中最可行的检测框。
- 最后提出了文章的创新点,看完创新点基本上后面的方法部分都不用看了就基本上完全能够理解了。
- 提出了一种新的基于轨迹的在线多目标跟踪器(TrackTrack),该跟踪器由基于轨迹透视的关联(TPA)和基于轨迹感知的初始化(TAI)两个主要部分组成。·
- 我们提出了TPA,它优先考虑局部匹配精度,通过单级联合关联,在考虑每个成对距离与所有可用检测结果的同时,确保每个轨迹与最合适的检测结果合并,从而增强了数据关联过程中的鲁棒性。·
- 我们提出了TAI,它利用活动轨迹来防止在轨迹初始化过程中产生冗余磁道,并提高了总体跟踪稳定性。·
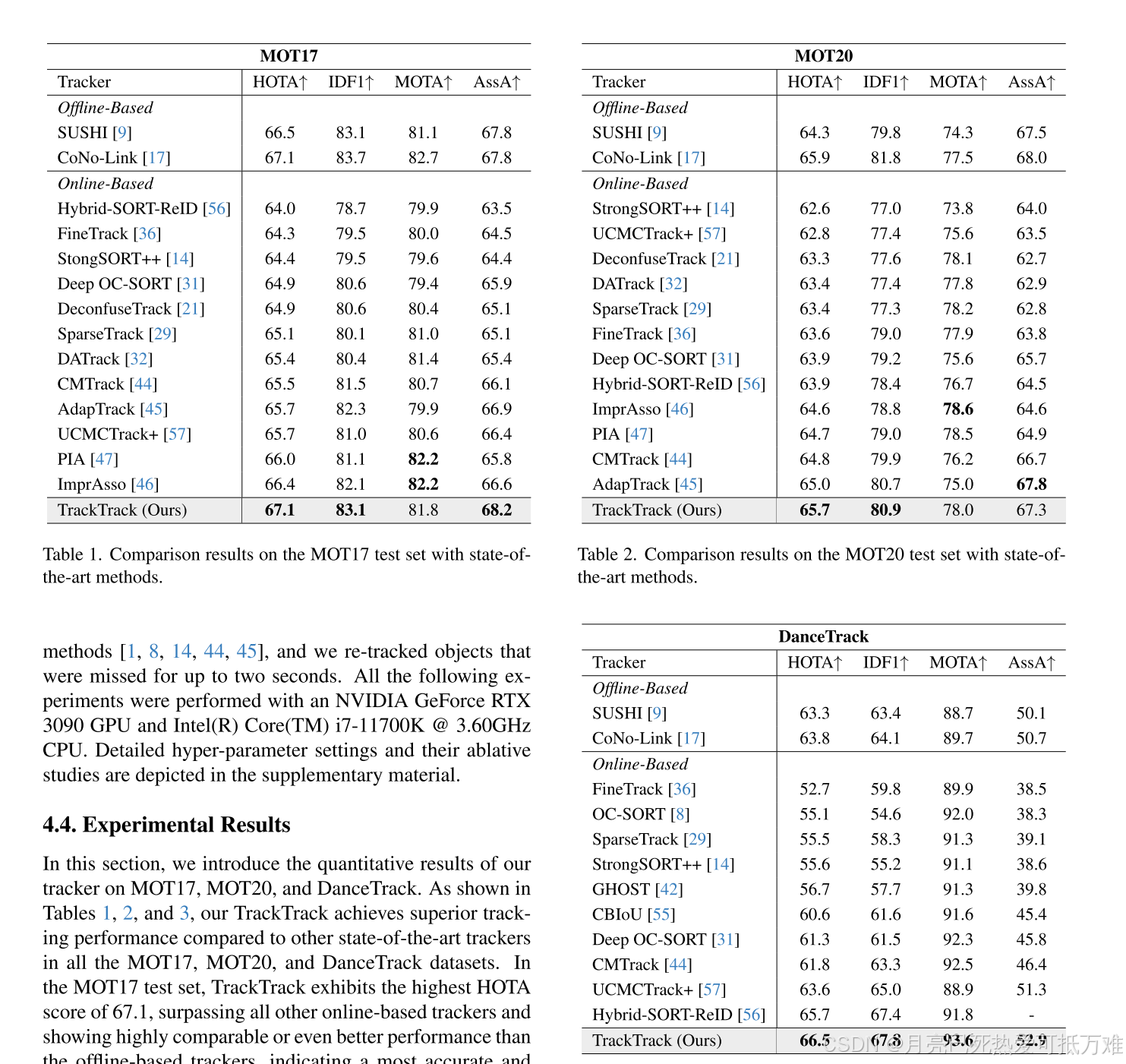
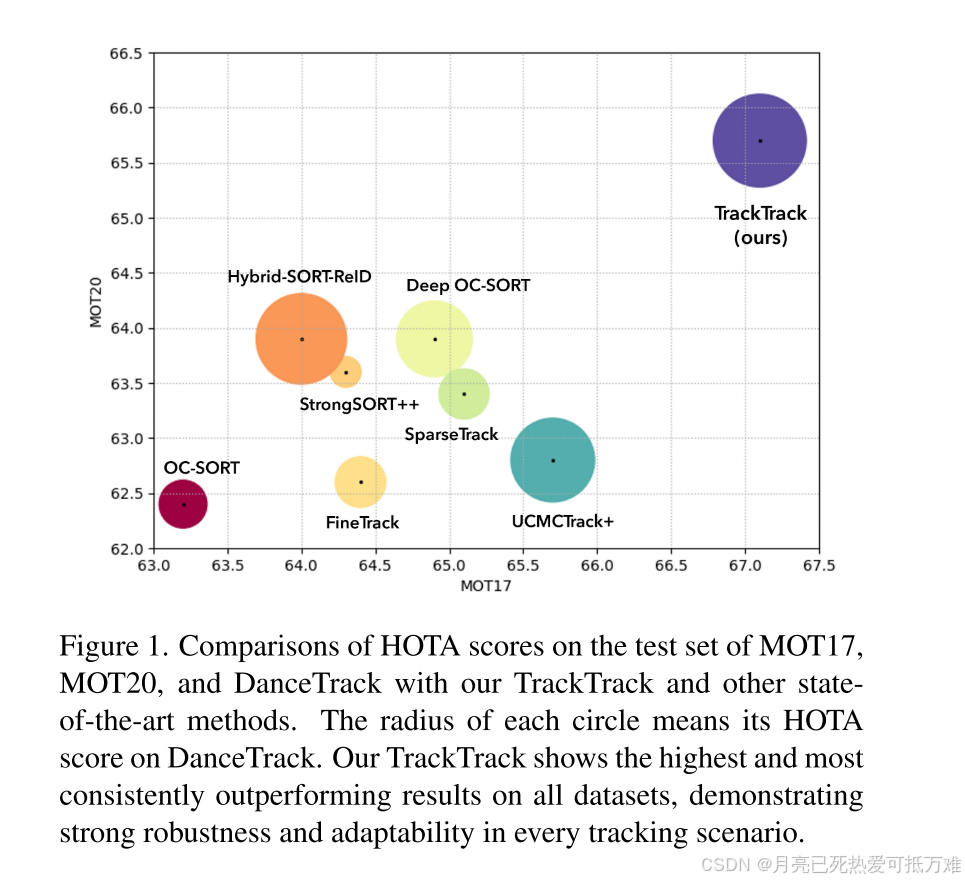
- 我们通过在MOT17、MOT20和DanceTrack上进行的大量实验,验证了TrackTrack的有效性和鲁棒性。与之前的尖端方法相比,它在所有数据集上始终实现了最先进的性能。
相关工作部分省略即可
方法策略
Track-Perspective-Based Association (TPA)
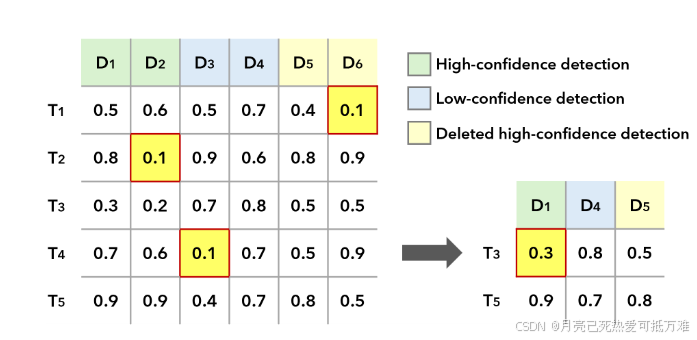
从这个图也能简单的看出就是类似迭代的算法,先选择行和列都是最小的关联完成之后,在去掉这些部分继续进行迭代。之后都小于阈值在停止。检测部分的构成也是由三个部分构成加上了NMS抑制的高分框的部分。
更具体来说,对于轨迹集合 𝒯 和检测结果集合 𝒟,TPA 算法会迭代地选择合适的配对 (𝑇ᵢ, 𝑑ⱼ):
对于每条轨迹 𝑇ᵢ,找到所有检测结果中代价(cost)最小的检测结果 𝑑ⱼ;
同时,对于每个检测结果 𝑑ⱼ,也找到所有轨迹中代价最小的轨迹 𝑇ᵢ。
满足条件的匹配对 ℳ 定义如下:
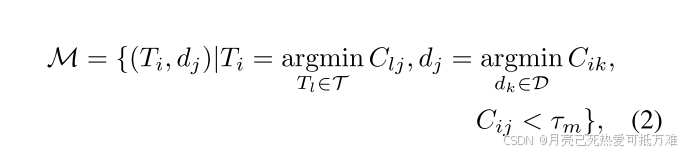
其中 τₘ 是匹配阈值。
确定了匹配对 ℳ 后,从原始集合 𝒯 和 𝒟 中删除这些已匹配的轨迹和检测结果,形成新的集合:
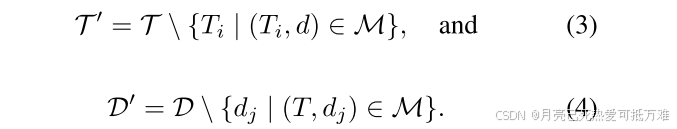
这个策略的创新感觉都不用改很多的代码。
首先,我们计算轨迹和检测结果全集之间的两两代价矩阵;
其中检测结果全集包括:高置信度检测结果、低置信度检测结果,以及 NMS 阶段被省略掉的高置信度检测结果。接着,在代价矩阵中,找到那些在对应行和列中都是最小值的可匹配对;将这些找到的匹配对进行关联,并将它们对应的行和列从矩阵中删除(避免重复匹配)。然后,再次从剩余的矩阵中,以相同的方式寻找下一批距离最小的匹配对;不断重复这一关联过程,直到所有剩余的代价值都大于匹配阈值为止。
Track-Aware Initialization(TAI)
传统上,在基于 TBD(Tracking-by-Detection)的跟踪器中,对于未能与已有轨迹匹配且置信度超过某个阈值的高置信度检测结果,通常会将其初始化为新的轨迹,以应对视频中出现的新目标。在本工作中,我们提出了一种Track-Aware Initialization (TAI) 策略,通过利用活动轨迹的信息,克服了这种传统方法的局限性。
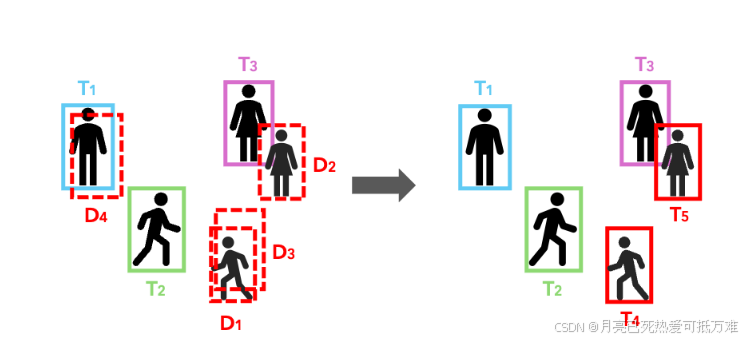
具体来说:
-
将 TPA 过程中的匹配轨迹的最终位置视为不可删除的锚点,
或者相当于置信度为 1 的检测结果。 -
然后,我们对这些预定义锚点与TPA 中未被关联的高置信度检测结果的组合集合,应用非极大值抑制(NMS)。
-
经过 NMS(非极大值抑制)处理后,保留下来的检测结果会被初始化为新的轨迹。
这种基于轨迹感知(track-aware)的初始化过程,能够通过减少伪轨迹的数量,让轨迹初始化更准确;因为它会舍弃那些与当前活跃轨迹以及其他高置信度检测结果显著重叠的检测结果,不将它们作为新的轨迹候选。因此,TAI 通过提高轨迹初始化的质量,增强了整体跟踪的稳定性和可靠性,特别是在检测噪声大、目标被遮挡等复杂场景中效果更明显。
TAI 可以通过降低 NMS 阶段的 IoU 阈值,优先保证目标存在的确定性(保守策略);也可以通过提高阈值来适应更密集的人群场景(宽松策略)这种需要人手工进行设计和需要根据不同的场景去动态调整阈值的做法可以是以后一个改进的方向。
Tracking Pipeline
在我们提出的 TrackTrack 框架中,首先通过检测模型检测感兴趣的目标,
然后使用 NSA Kalman Filter(作为运动模型)预测当前已有轨迹的位置。
接着,将这些轨迹与检测结果全集进行比较:
检测结果全集包括:
-
高置信度检测结果
-
低置信度检测结果
-
被丢弃的高置信度检测结果
通过 TPA 方法,为每条轨迹找到合适的匹配检测结果。
然后,对剩余的高置信度检测结果:与最近初始化的轨迹(指刚刚初始化、还没积累足够时序信息的轨迹)进行再次关联这个过程也用一种与 TPA 类似的分配算法具体来说:
我们将长度不足三帧的轨迹视为“最近初始化的轨迹”这些通常是噪声或误检,比如反射等单独的分配步骤有两个目的:
防止这些不可靠的短轨迹(1–2 帧)在与已确认轨迹(连续跟踪 ≥ 3 帧)关联时产生干扰
优先让已确认轨迹与检测结果关联,避免被短噪声轨迹“截胡”
另外,值得注意的是:我们的方法不需要额外训练就能提升跟踪器的数据关联阶段
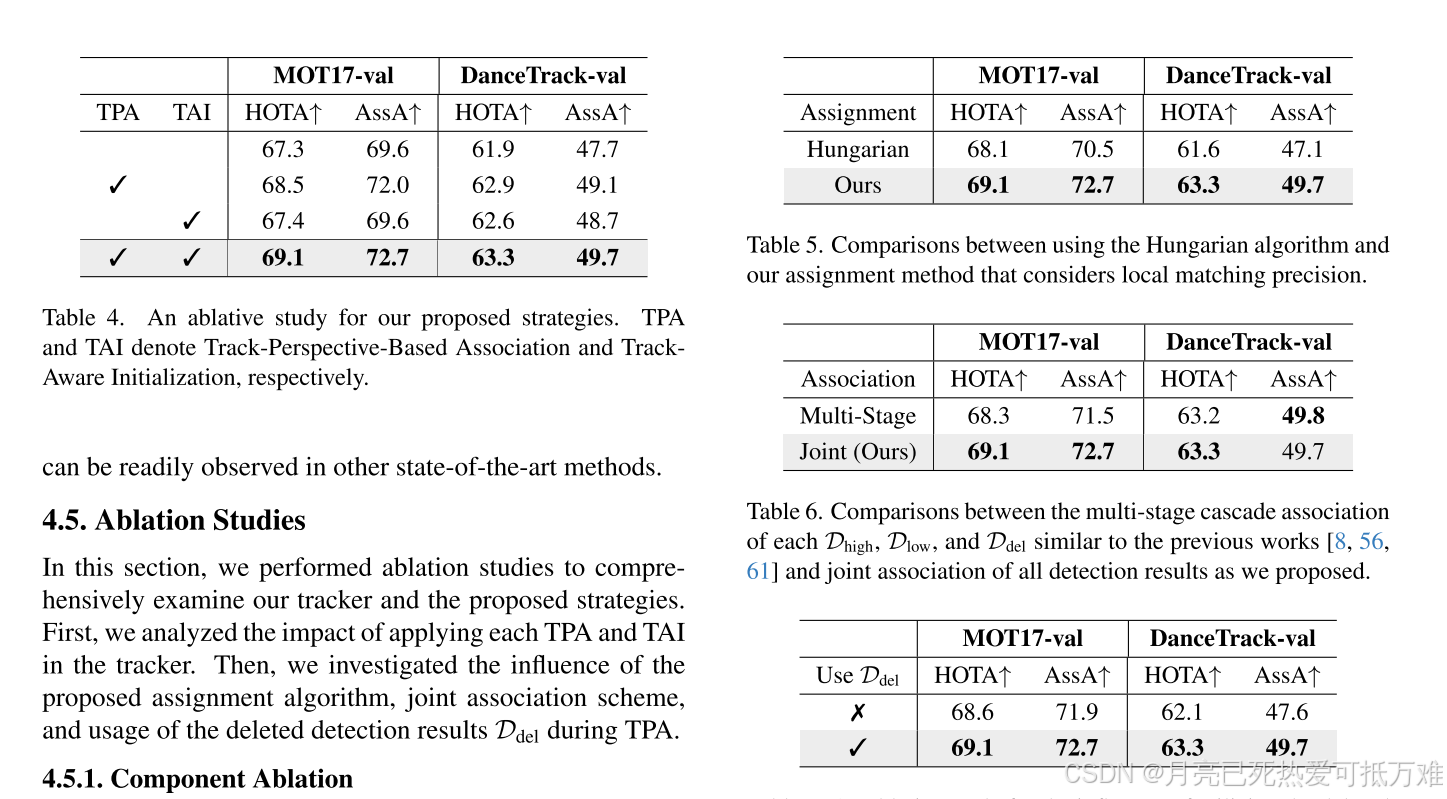
消融实验和比较
消融实验相对来说没有那么充分但是验证的角度上已经足够了,比较关键的地方还是在于取得了很好的实验效果。