CIFAR100数据集实测-基于 AlexNet模型的压缩/Bagging/Boosting 探索
注:笔者使用的深度学习框架为pytorch,使用COLAB NVIDIA TESLA T4 GPU(2560个CUDA 核) / Intel i5 CPU / NVIDIA RTX GeForce 5070显卡(6144个CUDA核,需要安装>=2.8.0的torch版本,见参考链接1)训练模型,操作系统为Windows11。
代码文件已经上传个人中心-资源,可以免费下载使用。
目录
一、数据集介绍与数据预处理操作... 1
二、AlexNet压缩版本名词解释... 1
三、Bagging与Boosting设计说明... 2
四、实测结果与超参数设定... 4
4.1 AlexNet是否加入批处理层、张量是否标准化(Bagging模型数量)... 5
4.2 输入图片是否进行灰度变换... 8
4.3 数据增广:在线变换vs单次变换多轮复用(缓存,cached training,适用于数据集样本容量较小的情形)... 15
4.4 训练集批量间数据是否打乱(shuffle)... 17
4.5 多分类AdaBoost:适合CIFAR100的初始学习率(0.03较合适) 19
4.6 Bagging策略:丢弃层丢弃率p对于模型效果的影响(0.3vs0.5) 25
4.7 Bagging策略:学习率和模型数量(以及批量大小、学习率衰减方式)对于多模型学习效果的影响... 28
4.8 题外话:CIFAR10与AlexNet压缩版2. 33
五、参考资料... 36
一、数据集介绍与数据预处理操作
CIFAR100数据集由100x500张训练集图片和100x100张测试集图片构成,包含100个类,所有图片均为32x32x3(HWC)的PIL.Image.Image类型对象。标签分为20大类和100小类两种模式,在torch框架内(torchvision)似乎并没有20大类的标签下载选项,笔者训练AlexNet完成100类物体分类的任务。MxNet框架支持两种标签模式的下载。

图 1 CIFAR100数据集(增广)展示(4x4)
读取数据后转换为tensor张量并统一调整尺寸为3x224x224(CHW,单样本大小约为0.6MB),笔者的代码提供了4种预处理方式,分别如下:
- 张量是否标准化,AlexNet是否加入批处理层。
- 灰度图预处理或彩色图直接输入;
- (训练集样本)实时在线变换(每轮训练都进行随机的水平翻转、亮度对比度饱和度调整、随机裁剪后缩放)或单次变换多轮复用(速度快5倍左右,5070一轮从26s->5s);
- 训练集样本批量每轮采取打乱/不打乱的方式;
二、AlexNet压缩版本名词解释
首先说明一下AlexNet压缩版本的意思,对于参数体量极其庞大的大语言模型,比如DeepSeek(671B)和Qwen(235B),为了方便部署,常常使用“量化” (Quantized)和“蒸馏”(Distilled)两步操作对模型进行压缩,笔者对两种压缩方式的解读是:前者在理论参数量不变的前提下通过线性代数(SVD矩阵奇异值分解)、阈值过滤(稀疏索引)、类型转换(4-8比特量化)等方式降低参数精度,后者通过基于大模型不同概率输出(软分类)而非直接的标签分类(硬分类)的小模型训练,降低模型的参数体量。
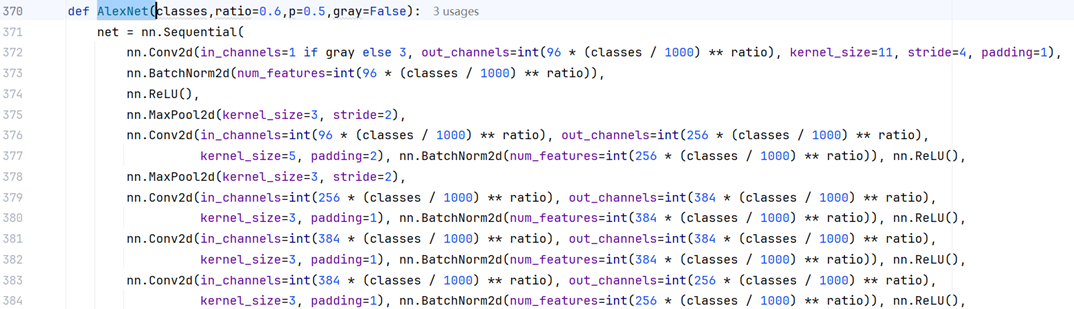
而在本文中的压缩方式,不属于以上两种方法,压缩原理其实是在保持AlexNet模型结构参数【5层卷积层,3层最大池化层,1层展平层,3层全连接层, 7层丢弃层,5层批处理层(可选,原模型没有,因为批处理层是2015年提出来的,而AlexNet是2012年提出的模型,目标是ImageNet的1000类图像分类挑战赛,百万样本数据集)】不变的前提下,按照比例降低卷积核的输入输出通道数和全连接层(线性层)的节点数,从而降低AlexNet参数总量,确保准确率较高的同时模型体量合适,追求Occam‘s Razor原理。
|
|
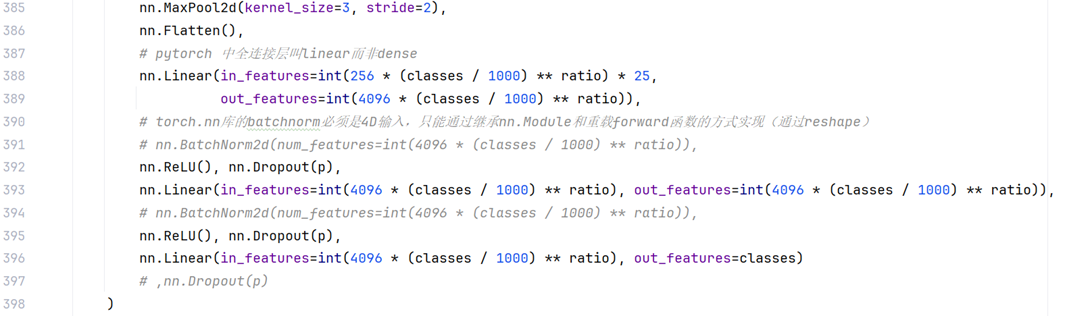 图 2 根据分类类别对AlexNet卷积层输入输入通道数进行比例压缩(加入批处理层)
图 2 根据分类类别对AlexNet卷积层输入输入通道数进行比例压缩(加入批处理层)def AlexNet(classes,ratio=0.6,p=0.5,gray=False):net = nn.Sequential(nn.Conv2d(in_channels=1 if gray else 3, out_channels=int(96 * (classes / 1000) ** ratio), kernel_size=11, stride=4, padding=1),nn.BatchNorm2d(num_features=int(96 * (classes / 1000) ** ratio)),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(in_channels=int(96 * (classes / 1000) ** ratio), out_channels=int(256 * (classes / 1000) ** ratio),kernel_size=5, padding=2), nn.BatchNorm2d(num_features=int(256 * (classes / 1000) ** ratio)), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(in_channels=int(256 * (classes / 1000) ** ratio), out_channels=int(384 * (classes / 1000) ** ratio),kernel_size=3, padding=1), nn.BatchNorm2d(num_features=int(384 * (classes / 1000) ** ratio)), nn.ReLU(),nn.Conv2d(in_channels=int(384 * (classes / 1000) ** ratio), out_channels=int(384 * (classes / 1000) ** ratio),kernel_size=3, padding=1), nn.BatchNorm2d(num_features=int(384 * (classes / 1000) ** ratio)), nn.ReLU(),nn.Conv2d(in_channels=int(384 * (classes / 1000) ** ratio), out_channels=int(256 * (classes / 1000) ** ratio),kernel_size=3, padding=1), nn.BatchNorm2d(num_features=int(256 * (classes / 1000) ** ratio)), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Flatten(),# pytorch 中全连接层叫linear而非densenn.Linear(in_features=int(256 * (classes / 1000) ** ratio) * 25,out_features=int(4096 * (classes / 1000) ** ratio)),# torch.nn库的batchnorm必须是4D输入,只能通过继承nn.Module和重载forward函数的方式实现(通过reshape)# nn.BatchNorm2d(num_features=int(4096 * (classes / 1000) ** ratio)),nn.ReLU(), nn.Dropout(p),nn.Linear(in_features=int(4096 * (classes / 1000) ** ratio), out_features=int(4096 * (classes / 1000) ** ratio)),# nn.BatchNorm2d(num_features=int(4096 * (classes / 1000) ** ratio)),nn.ReLU(), nn.Dropout(p),nn.Linear(in_features=int(4096 * (classes / 1000) ** ratio), out_features=classes)# ,nn.Dropout(p))# layer-level verificationX = torch.randn(1, 1 if gray else 3, 224, 224)for layer in net:X = layer(X)print(layer.__class__.__name__, 'shape:\t', X.shape)# 模型参数初始化def init_weights(m):if type(m) == nn.Linear or type(m) == nn.Conv2d:nn.init.xavier_uniform_(m.weight)# nn.init.normal_(m.weight,0,0.01)net.apply(init_weights)return net
三、Bagging与Boosting设计说明
Bagging和Boosting是集成学习(机器学习)中的两种模式。
Bagging类似众议院或者人民代表大会的等权重投票机制,基于共同的数据集可重复抽取数量等同于数据集样本容量的样本,以此训练单个模型;因此不同模型的数据集因为抽取的随机性和重复性存在差异,除了参数初始化不同之外,进一步加大了不同模型(投票者)的独立性。结合概率论与数理统计学的知识,对于一个二项分布(二分类问题)或者狄利克雷分布(多分类问题),理论上符合(完全)独立同分布的多个变量可以使得最终的准确率接近100%。
举一个例子,二分类问题,最差的分类器的准确率是0.5,假设现有的分类器准确率在0.7附近(必须大于0.5), 现在有3个/5个/7个独立的二分类网络,那么只要有多于2个/3个/4个的分类器结果相同,那么就选择这个结果作为最终预测结果,计算得到的准确率依次为0.784、0.837、0.874。多分类的Bagging问题更复杂,原理此处不做讨论,但是结论是一致的。
需要指出,本实验的Bagging对于不同的模型(投票者)选取的样本空间是完全相同的,不进行可重复抽取,所有样本空间都等同于增广或者不进行增广处理的数据集;对于策略的极限精度存在不可忽略的影响,但是代码编写更为简单。
Boosting采用较为经典的AdaBoost,下面给出二分类问题的AdaBoost流程:
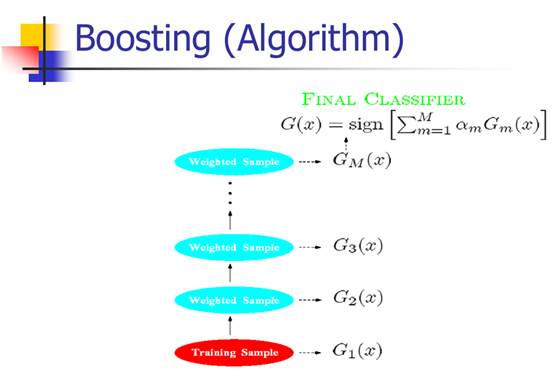

图 3 二分类AdaBoost流程
AdaBoost本质上是一种带权重的投票,而且这种投票只产生一个预测结果,而且投票环节在模型的概率输出(二分类sigmoid,多分类softmax)之前进行,具体是一种线性加权。
在CIFAR100的100分类情景中,笔者对AdaBoost做了一些修改,首先是图1第3步![]() 的计算公式,
的计算公式,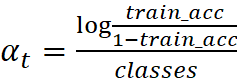 ,确保αt
,确保αt![]() 非负。
非负。
最终输出时对![]() 序列作了类似softmax的第二步处理,确保权重系数非负且和为1。
序列作了类似softmax的第二步处理,确保权重系数非负且和为1。
四、实测结果与超参数设定
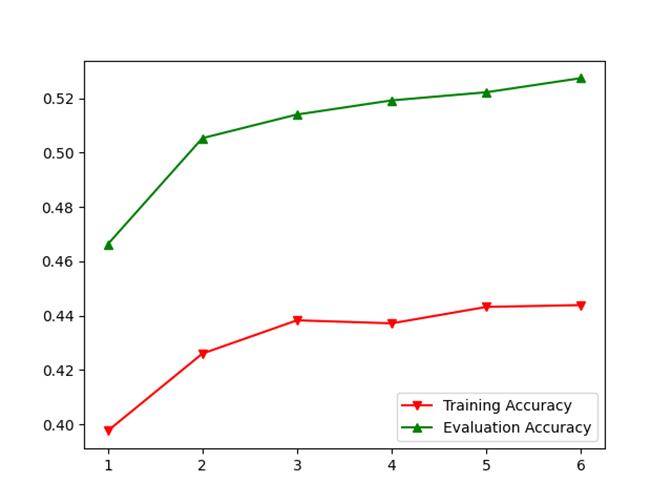
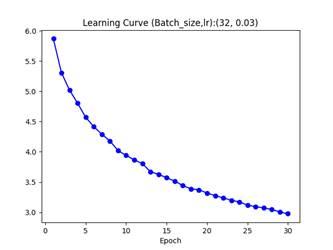
注:下面展示的大部分实验的共同特征主要包括:模型压缩参数ratio(均为0.6)、损失函数(softmax概率输出+cross entropy交叉熵损失复合)、批量大小(大部分是32,其余是64)、初始学习率(主要是0.03)、学习率规划(主要采用周期指数衰减,周期为4,衰减系数0.8)、优化方法(全部采用SGD+零动量设定,由于批处理层使得优化过车更加平滑,同时笔者的实验表明使用常规的动量参数会使准确率严重下降,比如下图,AdaBoost策略)
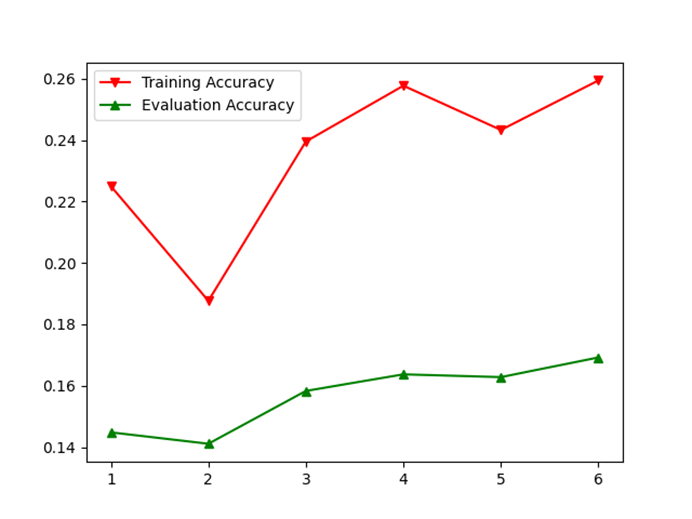
图 4 SGD+Momentum(rho=0.9)导致adaboost集成学习效果显著低于单模型学习效果
4.1 AlexNet是否加入批处理层、张量是否标准化(Bagging模型数量)
AlexNet (No BatchNorm2D) ratio=0.6 p=0.5 batch_size=32 lr0=0.03+cosine decay SGD Bagging n=3 Epochs=20 Data preprocessing: no augmentation and no normalization
Epoch 1 loss 6.5423 training accuracy 2.8 test accuracy 2.7 learning rate 0.0300 time elapsed 1752661044.3
Epoch 2 loss 6.1076 training accuracy 8.8 test accuracy 9.1 learning rate 0.0298 time elapsed 1752661217.8
Epoch 3 loss 5.6550 training accuracy 16.1 test accuracy 15.8 learning rate 0.0293 time elapsed 1752661389.9
Epoch 4 loss 5.2193 training accuracy 21.6 test accuracy 20.6 learning rate 0.0284 time elapsed 1752661562.4
Epoch 5 loss 4.8570 training accuracy 27.7 test accuracy 26.3 learning rate 0.0271 time elapsed 1752661734.3
Epoch 6 loss 4.5542 training accuracy 31.8 test accuracy 29.1 learning rate 0.0256 time elapsed 1752661904.1
Epoch 7 loss 4.2975 training accuracy 35.0 test accuracy 31.6 learning rate 0.0238 time elapsed 1752662076.5
Epoch 8 loss 4.0710 training accuracy 39.2 test accuracy 34.5 learning rate 0.0218 time elapsed 1752662247.4
Epoch 9 loss 3.8618 training accuracy 43.0 test accuracy 37.2 learning rate 0.0196 time elapsed 1752662418.7
Epoch 10 loss 3.6615 training accuracy 47.0 test accuracy 38.9 learning rate 0.0173 time elapsed 1752662596.5
Epoch 11 loss 3.4663 training accuracy 49.7 test accuracy 40.7 learning rate 0.0150 time elapsed 1752662770.6
Epoch 12 loss 3.2835 training accuracy 52.8 test accuracy 42.3 learning rate 0.0127 time elapsed 1752662945.2
Epoch 13 loss 3.0941 training accuracy 56.6 test accuracy 43.4 learning rate 0.0104 time elapsed 1752663118.3
Epoch 14 loss 2.9193 training accuracy 58.4 test accuracy 44.0 learning rate 0.0082 time elapsed 1752663292.4
Epoch 15 loss 2.7637 training accuracy 62.4 test accuracy 45.6 learning rate 0.0062 time elapsed 1752663466.6
Epoch 16 loss 2.6081 training accuracy 65.2 test accuracy 45.8 learning rate 0.0044 time elapsed 1752663644.6
Epoch 17 loss 2.4878 training accuracy 67.0 test accuracy 46.9 learning rate 0.0029 time elapsed 1752663819.6
Epoch 18 loss 2.3863 training accuracy 67.9 test accuracy 46.6 learning rate 0.0016 time elapsed 1752663994.1
Epoch 19 loss 2.3181 training accuracy 69.2 test accuracy 47.1 learning rate 0.0007 time elapsed 1752664168.3
Epoch 20 loss 2.2769 training accuracy 69.3 test accuracy 47.2 learning rate 0.0002 time elapsed 1752664343.0
AlexNet (With BatchNorm2D) ratio=0.6 p=0.5 batch_size=32 lr0=0.03+mixture exponential decay (period=4, decay rate=0.8) SGD Bagging n=1 Epochs=20 Data preprocessing: no augmentation and with pixel value normalization
cuda:0
epoch 1 loss 5.9338 train_accuracy 0.07 test_accuracy 0.15 time 82.1 s
epoch 2 loss 5.1187 train_accuracy 0.15 test_accuracy 0.22 time 83.5 s
epoch 3 loss 4.6468 train_accuracy 0.21 test_accuracy 0.27 time 83.4 s
epoch 4 loss 4.2284 train_accuracy 0.26 test_accuracy 0.31 time 82.5 s
epoch 5 loss 3.8399 train_accuracy 0.32 test_accuracy 0.35 time 82.6 s
epoch 6 loss 3.6042 train_accuracy 0.35 test_accuracy 0.40 time 83.6 s
epoch 7 loss 3.3854 train_accuracy 0.38 test_accuracy 0.41 time 83.5 s
epoch 8 loss 3.2018 train_accuracy 0.41 test_accuracy 0.45 time 82.7 s
epoch 9 loss 2.9767 train_accuracy 0.44 test_accuracy 0.47 time 83.4 s
epoch 10 loss 2.8418 train_accuracy 0.46 test_accuracy 0.47 time 83.4 s
epoch 11 loss 2.7297 train_accuracy 0.48 test_accuracy 0.48 time 83.7 s
epoch 12 loss 2.6227 train_accuracy 0.50 test_accuracy 0.49 time 83.5 s
epoch 13 loss 2.4473 train_accuracy 0.53 test_accuracy 0.50 time 83.0 s
epoch 14 loss 2.3523 train_accuracy 0.54 test_accuracy 0.50 time 84.0 s
epoch 15 loss 2.2639 train_accuracy 0.56 test_accuracy 0.51 time 83.3 s
epoch 16 loss 2.1780 train_accuracy 0.57 test_accuracy 0.51 time 82.3 s
epoch 17 loss 2.0348 train_accuracy 0.59 test_accuracy 0.53 time 82.3 s
epoch 18 loss 1.9677 train_accuracy 0.61 test_accuracy 0.52 time 83.1 s
epoch 19 loss 1.8956 train_accuracy 0.62 test_accuracy 0.54 time 82.9 s
epoch 20 loss 1.8458 train_accuracy 0.63 test_accuracy 0.53 time 82.0 s
4.2 输入图片是否进行灰度变换
注:由于此时训练集每轮进行了包含大量随机性的数据增广变换而测试集是固定预变换,因此测试集的准确率高出训练集平均10%左右,并不是代码的问题。AlexNet (With BatchNorm2D) ratio=0.6 p=0.5 batch_size=32 lr0=0.06+mixure exponential decay (period=4, decay rate=0.8) SGD Boosting (after softmax) n=6 Boosting alpha divider: (classes) Epochs=30 Data preprocessing: real-time augmentation and with grayscale and pixel value normalization, shuffled
Model 6
cuda:0
epoch 1 loss 6.5662 train_accuracy 0.02 test_accuracy 0.05 time 19.7 s
epoch 2 loss 6.3568 train_accuracy 0.04 test_accuracy 0.05 time 20.2 s
epoch 3 loss 6.1720 train_accuracy 0.06 test_accuracy 0.10 time 21.4 s
epoch 4 loss 5.9924 train_accuracy 0.07 test_accuracy 0.12 time 24.0 s
epoch 5 loss 5.7844 train_accuracy 0.09 test_accuracy 0.16 time 19.7 s
epoch 6 loss 5.6122 train_accuracy 0.11 test_accuracy 0.17 time 19.6 s
epoch 7 loss 5.4784 train_accuracy 0.13 test_accuracy 0.22 time 19.3 s
epoch 8 loss 5.3619 train_accuracy 0.14 test_accuracy 0.25 time 19.8 s
epoch 9 loss 5.2081 train_accuracy 0.16 test_accuracy 0.27 time 19.3 s
epoch 10 loss 5.1335 train_accuracy 0.17 test_accuracy 0.30 time 19.2 s
epoch 11 loss 5.0448 train_accuracy 0.18 test_accuracy 0.24 time 19.2 s
epoch 12 loss 4.9814 train_accuracy 0.18 test_accuracy 0.28 time 19.5 s
epoch 13 loss 4.8923 train_accuracy 0.20 test_accuracy 0.31 time 19.3 s
epoch 14 loss 4.8426 train_accuracy 0.20 test_accuracy 0.35 time 19.2 s
epoch 15 loss 4.7861 train_accuracy 0.21 test_accuracy 0.35 time 19.1 s
epoch 16 loss 4.7480 train_accuracy 0.21 test_accuracy 0.32 time 19.1 s
epoch 17 loss 4.6599 train_accuracy 0.22 test_accuracy 0.34 time 19.1 s
epoch 18 loss 4.6214 train_accuracy 0.23 test_accuracy 0.36 time 19.2 s
epoch 19 loss 4.5891 train_accuracy 0.24 test_accuracy 0.34 time 19.2 s
epoch 20 loss 4.5568 train_accuracy 0.24 test_accuracy 0.38 time 19.1 s
epoch 21 loss 4.4939 train_accuracy 0.25 test_accuracy 0.39 time 19.1 s
epoch 22 loss 4.4783 train_accuracy 0.25 test_accuracy 0.39 time 19.4 s
epoch 23 loss 4.4515 train_accuracy 0.25 test_accuracy 0.40 time 19.1 s
epoch 24 loss 4.4300 train_accuracy 0.26 test_accuracy 0.40 time 19.2 s
epoch 25 loss 4.3841 train_accuracy 0.26 test_accuracy 0.41 time 19.3 s
epoch 26 loss 4.3700 train_accuracy 0.27 test_accuracy 0.40 time 19.1 s
epoch 27 loss 4.3269 train_accuracy 0.27 test_accuracy 0.41 time 19.2 s
epoch 28 loss 4.3050 train_accuracy 0.27 test_accuracy 0.39 time 19.3 s
epoch 29 loss 4.2761 train_accuracy 0.28 test_accuracy 0.42 time 19.2 s
epoch 30 loss 4.2597 train_accuracy 0.28 test_accuracy 0.43 time 19.0 s
alphas:[0.05324954959364244, 0.05254167232479702, 0.05261916700544978, 0.05253304946193044, 0.05243373330919752, 0.05242364201953164]
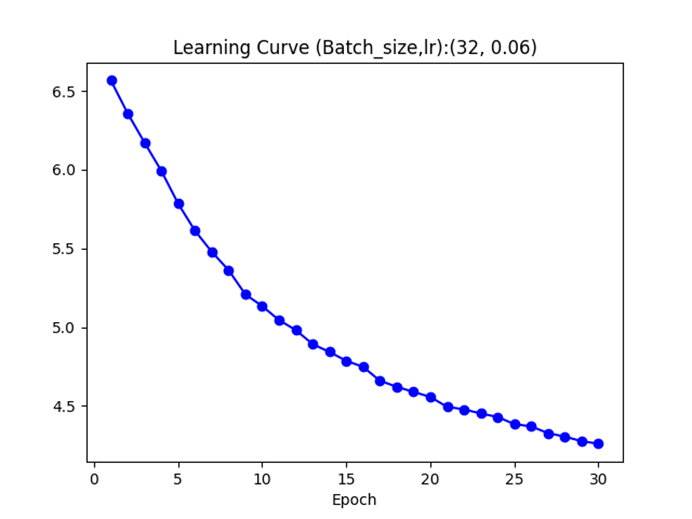
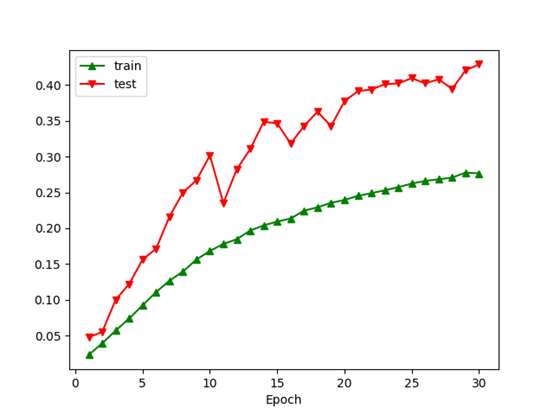
final accuracy: 36.2% 46.4%
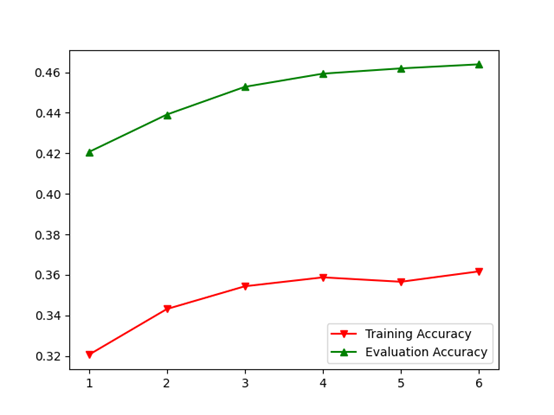
AlexNet (With BatchNorm2D) ratio=0.6 p=0.5 batch_size=32 lr0=0.06+mixure exponential decay (period=4, decay rate=0.8) SGD Boosting (after softmax) n=6 Boosting alpha divider: (classes) Epochs=30 Data preprocessing: real-time augmentation and with RGB channels and pixel value normalization, shuffled
Model 6
cuda:0
epoch 1 loss 6.2375 train_accuracy 0.04 test_accuracy 0.09 time 26.4 s
epoch 2 loss 5.8031 train_accuracy 0.08 test_accuracy 0.13 time 26.3 s
epoch 3 loss 5.5644 train_accuracy 0.11 test_accuracy 0.18 time 26.2 s
epoch 4 loss 5.3586 train_accuracy 0.13 test_accuracy 0.21 time 26.3 s
epoch 5 loss 5.1751 train_accuracy 0.15 test_accuracy 0.23 time 26.4 s
epoch 6 loss 5.0454 train_accuracy 0.17 test_accuracy 0.26 time 26.3 s
epoch 7 loss 4.9448 train_accuracy 0.18 test_accuracy 0.28 time 26.3 s
epoch 8 loss 4.8407 train_accuracy 0.20 test_accuracy 0.29 time 26.2 s
epoch 9 loss 4.7053 train_accuracy 0.21 test_accuracy 0.32 time 26.3 s
epoch 10 loss 4.6216 train_accuracy 0.22 test_accuracy 0.31 time 26.4 s
epoch 11 loss 4.5609 train_accuracy 0.23 test_accuracy 0.33 time 26.4 s
epoch 12 loss 4.4699 train_accuracy 0.24 test_accuracy 0.35 time 26.4 s
epoch 13 loss 4.3654 train_accuracy 0.26 test_accuracy 0.38 time 26.5 s
epoch 14 loss 4.3208 train_accuracy 0.26 test_accuracy 0.37 time 26.4 s
epoch 15 loss 4.2781 train_accuracy 0.27 test_accuracy 0.39 time 26.3 s
epoch 16 loss 4.2139 train_accuracy 0.28 test_accuracy 0.40 time 26.4 s
epoch 17 loss 4.1388 train_accuracy 0.29 test_accuracy 0.42 time 26.2 s
epoch 18 loss 4.0954 train_accuracy 0.29 test_accuracy 0.41 time 26.4 s
epoch 19 loss 4.0643 train_accuracy 0.30 test_accuracy 0.42 time 26.3 s
epoch 20 loss 4.0273 train_accuracy 0.30 test_accuracy 0.43 time 26.4 s
epoch 21 loss 3.9564 train_accuracy 0.31 test_accuracy 0.44 time 26.3 s
epoch 22 loss 3.9256 train_accuracy 0.32 test_accuracy 0.44 time 26.2 s
epoch 23 loss 3.9106 train_accuracy 0.32 test_accuracy 0.45 time 26.4 s
epoch 24 loss 3.8677 train_accuracy 0.32 test_accuracy 0.46 time 26.4 s
epoch 25 loss 3.8283 train_accuracy 0.33 test_accuracy 0.46 time 26.3 s
epoch 26 loss 3.8010 train_accuracy 0.34 test_accuracy 0.46 time 26.2 s
epoch 27 loss 3.7750 train_accuracy 0.34 test_accuracy 0.46 time 26.3 s
epoch 28 loss 3.7575 train_accuracy 0.34 test_accuracy 0.46 time 26.4 s
epoch 29 loss 3.7035 train_accuracy 0.35 test_accuracy 0.48 time 26.4 s
epoch 30 loss 3.6900 train_accuracy 0.35 test_accuracy 0.48 time 26.2 s
alphas:[0.05673453771391314, 0.057352569814457015, 0.05747799562187809, 0.056973021186447426, 0.057071387338757724, 0.057360181523446865]
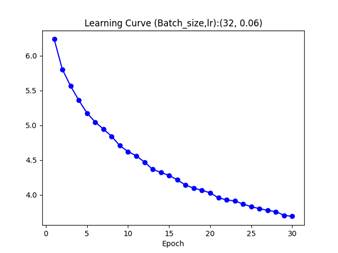
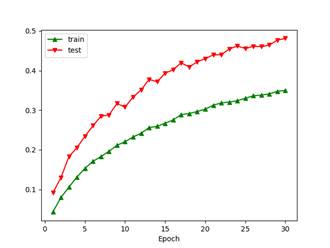
Final accuracy: 44.4% 52.7%
在多分类Adaboost的策略中,灰度预处理导致模型在训练集上准确率低8%,测试集低6%。
4.3 数据增广:在线变换vs单次变换多轮复用(缓存,cached training,适用于数据集样本容量较小的情形)
AlexNet (With BatchNorm2D) ratio=0.6 p=0.5 batch_size=64 lr0=0.06+mixture exponential decay (period=4, decay rate=0.8) SGD Bagging n=1 Epochs=30 Data preprocessing: augmentation and with pixel value normalization,30000/50000+2000/10000, cached training!
cuda:0
epoch 1 loss 6.3497 train_accuracy 0.04 test_accuracy 0.07 time 3.4 s
epoch 2 loss 5.9791 train_accuracy 0.06 test_accuracy 0.07 time 3.0 s
epoch 3 loss 5.8164 train_accuracy 0.08 test_accuracy 0.12 time 2.9 s
epoch 4 loss 5.6814 train_accuracy 0.09 test_accuracy 0.12 time 3.0 s
epoch 5 loss 5.5281 train_accuracy 0.11 test_accuracy 0.16 time 3.0 s
epoch 6 loss 5.4294 train_accuracy 0.12 test_accuracy 0.13 time 2.9 s
epoch 7 loss 5.3087 train_accuracy 0.14 test_accuracy 0.10 time 3.0 s
epoch 8 loss 5.2248 train_accuracy 0.15 test_accuracy 0.14 time 3.1 s
epoch 9 loss 5.0962 train_accuracy 0.16 test_accuracy 0.22 time 3.0 s
epoch 10 loss 4.9984 train_accuracy 0.17 test_accuracy 0.16 time 3.0 s
epoch 11 loss 4.9174 train_accuracy 0.18 test_accuracy 0.23 time 3.1 s
epoch 12 loss 4.8299 train_accuracy 0.19 test_accuracy 0.22 time 3.3 s
epoch 13 loss 4.7085 train_accuracy 0.20 test_accuracy 0.11 time 3.0 s
epoch 14 loss 4.6236 train_accuracy 0.22 test_accuracy 0.27 time 3.0 s
epoch 15 loss 4.5736 train_accuracy 0.22 test_accuracy 0.27 time 3.1 s
epoch 16 loss 4.5095 train_accuracy 0.23 test_accuracy 0.30 time 3.0 s
epoch 17 loss 4.3685 train_accuracy 0.25 test_accuracy 0.29 time 3.0 s
epoch 18 loss 4.3103 train_accuracy 0.26 test_accuracy 0.22 time 3.0 s
epoch 19 loss 4.2434 train_accuracy 0.27 test_accuracy 0.28 time 3.0 s
epoch 20 loss 4.1713 train_accuracy 0.27 test_accuracy 0.33 time 3.0 s
epoch 21 loss 4.0673 train_accuracy 0.29 test_accuracy 0.18 time 2.9 s
epoch 22 loss 3.9997 train_accuracy 0.30 test_accuracy 0.17 time 3.0 s
epoch 23 loss 3.9465 train_accuracy 0.30 test_accuracy 0.25 time 3.0 s
epoch 24 loss 3.8848 train_accuracy 0.31 test_accuracy 0.32 time 3.0 s
epoch 25 loss 3.7897 train_accuracy 0.32 test_accuracy 0.33 time 2.9 s
epoch 26 loss 3.7138 train_accuracy 0.34 test_accuracy 0.21 time 3.1 s
epoch 27 loss 3.6721 train_accuracy 0.34 test_accuracy 0.29 time 3.0 s
epoch 28 loss 3.6290 train_accuracy 0.35 test_accuracy 0.36 time 3.0 s
epoch 29 loss 3.5270 train_accuracy 0.36 test_accuracy 0.26 time 3.0 s
epoch 30 loss 3.4564 train_accuracy 0.37 test_accuracy 0.37 time 3.1 s
AlexNet (With BatchNorm2D) ratio=0.6 p=0.5 batch_size=64 lr0=0.06+mixture exponential decay (period=4, decay rate=0.8) SGD Bagging n=9 Epochs=30 Data preprocessing: augmentation and with pixel value normalization,30000/50000+2000/10000, cached training!
Epoch 30 loss 3.4950 training accuracy 49.6 test accuracy 36.0 learning rate 0.0126 time elapsed 186.9
AlexNet (With BatchNorm2D) ratio=0.6 p=0.5 batch_size=64 lr0=0.1+mixture exponential decay (period=4, decay rate=0.8) SGD Bagging n=9 Epochs=30 Data preprocessing: real-time augmentation and with pixel value normalization
Epoch 30 loss 1.7537 training accuracy 75.8 test accuracy 58.3 learning rate 0.0210 time elapsed 893.7
4.3可以看出,Bagging策略对于缓存训练的测试集评估(实际效果)几乎没有精度上的提升,但在训练集上带来了12%左右的准确率提升。同时,由于在线变换包含随机变换,作为数据增广(Data Augmentation)的方式,可以减少模型过拟合,提升模型的泛化能力。实验结果表面,提升了至少21%的分类准确率(CIFAR100细标签-100分类)。
4.4 训练集批量间数据是否打乱(shuffle)
AlexNet (With BatchNorm2D) ratio=0.6 p=0.5 batch_size=32 lr0=0.04+cosine decay SGD Boosting (before softmax) n=6 Boosting alpha divider: classes Epochs=20 Data preprocessing: preprocessed augmentation and with pixel value normalization, unshuffled 50000/50000+10000/10000
Model 6
cuda:0
epoch 1 loss 6.5154 train_accuracy 0.02 test_accuracy 0.03 time 30.6 s
epoch 2 loss 5.9642 train_accuracy 0.07 test_accuracy 0.05 time 30.6 s
epoch 3 loss 5.5234 train_accuracy 0.12 test_accuracy 0.06 time 30.7 s
epoch 4 loss 5.1589 train_accuracy 0.16 test_accuracy 0.10 time 30.7 s
epoch 5 loss 4.8279 train_accuracy 0.21 test_accuracy 0.14 time 30.7 s
epoch 6 loss 4.5288 train_accuracy 0.25 test_accuracy 0.15 time 30.7 s
epoch 7 loss 4.2787 train_accuracy 0.28 test_accuracy 0.18 time 30.7 s
epoch 8 loss 4.0706 train_accuracy 0.32 test_accuracy 0.19 time 32.4 s
epoch 9 loss 3.8976 train_accuracy 0.34 test_accuracy 0.18 time 31.1 s
epoch 10 loss 3.7389 train_accuracy 0.37 test_accuracy 0.23 time 30.8 s
epoch 11 loss 3.6040 train_accuracy 0.39 test_accuracy 0.24 time 30.5 s
epoch 12 loss 3.4710 train_accuracy 0.41 test_accuracy 0.27 time 31.4 s
epoch 13 loss 3.3562 train_accuracy 0.42 test_accuracy 0.24 time 32.3 s
epoch 14 loss 3.2466 train_accuracy 0.44 test_accuracy 0.28 time 31.7 s
epoch 15 loss 3.1565 train_accuracy 0.46 test_accuracy 0.30 time 30.9 s
epoch 16 loss 3.0562 train_accuracy 0.47 test_accuracy 0.28 time 31.7 s
epoch 17 loss 2.9694 train_accuracy 0.48 test_accuracy 0.27 time 31.8 s
epoch 18 loss 2.8953 train_accuracy 0.50 test_accuracy 0.30 time 32.0 s
epoch 19 loss 2.8017 train_accuracy 0.51 test_accuracy 0.28 time 30.9 s
epoch 20 loss 2.7248 train_accuracy 0.52 test_accuracy 0.30 time 30.7 s
ws:tensor([2.6814e-05, 1.3475e-05, 1.3475e-05, ..., 2.0390e-05, 2.6743e-05,
1.3475e-05])
alphas:[0.06989933750639002, 0.0694278265326512, 0.06907209612868313, 0.06820185291722021, 0.06811724914901615, 0.06742406344917204]
final accuracy: 69.8% 39.1%
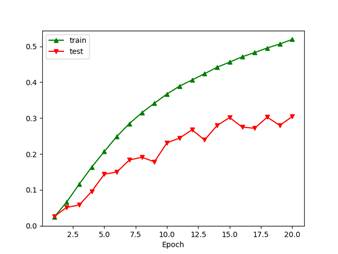
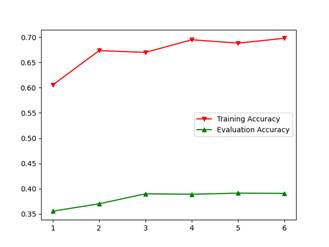
对照组可以参考4.2 的第二个,不打乱训练集样本时,测试集准确率低了13.6%,当然4.2的对照组使用了在线变换,而此处的实验组,即不打乱训练样本的训练使用的是单次变换多轮复用。
原因也比较直观,每次各批量内样本如果都和前n轮保持一致,那么将会使模型过拟合,且无法通过增大卷积层丢弃层丢弃率p或者在线随机变换抑制这种现象。接近30%的训练集-测试集 准确率差距(accuracy gap)足以说明这一点。
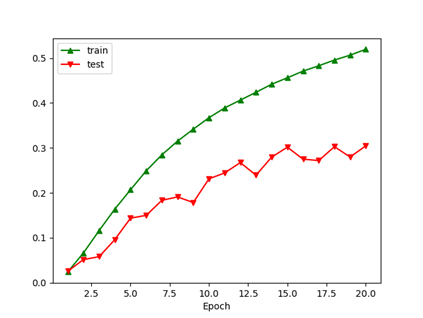
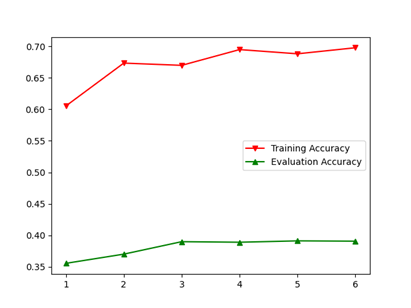
4.5 多分类AdaBoost:适合CIFAR100的初始学习率(0.03较合适)
AdaBoost实现必须使用自定义数据集对象,重载__getitem__和__len__函数。自定义数据集将所有样本一次存储到内存中,每轮训练时间可缩短4-5s。
注:由于此时训练集每轮进行了包含大量随机性的数据增广变换而测试集是固定预变换,因此测试集的准确率高出训练集平均10%左右,不一定是代码的问题。但是AdaBoost相比于单模型训练和Bagging策略,同样使用大随机性的数据增广变换操作,其他两种情况的accuracy gap仍然为正数。如果有读者发现是代码问题,欢迎指正。
AlexNet (With BatchNorm2D) ratio=0.6 p=0.5 batch_size=32 lr0=0.06+mixure exponential decay (period=4, decay rate=0.8) SGD Boosting (after softmax) n=6 Boosting alpha divider: (classes) Epochs=30 Data preprocessing: real-time augmentation and with RGB channels and pixel value normalization, shuffled
Model 6
cuda:0
epoch 1 loss 6.2375 train_accuracy 0.04 test_accuracy 0.09 time 26.4 s
epoch 2 loss 5.8031 train_accuracy 0.08 test_accuracy 0.13 time 26.3 s
epoch 3 loss 5.5644 train_accuracy 0.11 test_accuracy 0.18 time 26.2 s
epoch 4 loss 5.3586 train_accuracy 0.13 test_accuracy 0.21 time 26.3 s
epoch 5 loss 5.1751 train_accuracy 0.15 test_accuracy 0.23 time 26.4 s
epoch 6 loss 5.0454 train_accuracy 0.17 test_accuracy 0.26 time 26.3 s
epoch 7 loss 4.9448 train_accuracy 0.18 test_accuracy 0.28 time 26.3 s
epoch 8 loss 4.8407 train_accuracy 0.20 test_accuracy 0.29 time 26.2 s
epoch 9 loss 4.7053 train_accuracy 0.21 test_accuracy 0.32 time 26.3 s
epoch 10 loss 4.6216 train_accuracy 0.22 test_accuracy 0.31 time 26.4 s
epoch 11 loss 4.5609 train_accuracy 0.23 test_accuracy 0.33 time 26.4 s
epoch 12 loss 4.4699 train_accuracy 0.24 test_accuracy 0.35 time 26.4 s
epoch 13 loss 4.3654 train_accuracy 0.26 test_accuracy 0.38 time 26.5 s
epoch 14 loss 4.3208 train_accuracy 0.26 test_accuracy 0.37 time 26.4 s
epoch 15 loss 4.2781 train_accuracy 0.27 test_accuracy 0.39 time 26.3 s
epoch 16 loss 4.2139 train_accuracy 0.28 test_accuracy 0.40 time 26.4 s
epoch 17 loss 4.1388 train_accuracy 0.29 test_accuracy 0.42 time 26.2 s
epoch 18 loss 4.0954 train_accuracy 0.29 test_accuracy 0.41 time 26.4 s
epoch 19 loss 4.0643 train_accuracy 0.30 test_accuracy 0.42 time 26.3 s
epoch 20 loss 4.0273 train_accuracy 0.30 test_accuracy 0.43 time 26.4 s
epoch 21 loss 3.9564 train_accuracy 0.31 test_accuracy 0.44 time 26.3 s
epoch 22 loss 3.9256 train_accuracy 0.32 test_accuracy 0.44 time 26.2 s
epoch 23 loss 3.9106 train_accuracy 0.32 test_accuracy 0.45 time 26.4 s
epoch 24 loss 3.8677 train_accuracy 0.32 test_accuracy 0.46 time 26.4 s
epoch 25 loss 3.8283 train_accuracy 0.33 test_accuracy 0.46 time 26.3 s
epoch 26 loss 3.8010 train_accuracy 0.34 test_accuracy 0.46 time 26.2 s
epoch 27 loss 3.7750 train_accuracy 0.34 test_accuracy 0.46 time 26.3 s
epoch 28 loss 3.7575 train_accuracy 0.34 test_accuracy 0.46 time 26.4 s
epoch 29 loss 3.7035 train_accuracy 0.35 test_accuracy 0.48 time 26.4 s
epoch 30 loss 3.6900 train_accuracy 0.35 test_accuracy 0.48 time 26.2 s
alphas:[0.05673453771391314, 0.057352569814457015, 0.05747799562187809, 0.056973021186447426, 0.057071387338757724, 0.057360181523446865]
Final accuracy:44.4% 52.7%
AlexNet (With BatchNorm2D) ratio=0.6 p=0.1 batch_size=32 lr0=0.03+mixure exponential decay (period=4, decay rate=0.8) SGD Boosting (after softmax) n=6 Boosting alpha divider: (classes) Epochs=30 Data preprocessing: real-time augmentation and with RGB channels and pixel value normalization, shuffled
cuda:0
epoch 1 loss 5.8677 train_accuracy 0.08 test_accuracy 0.14 time 26.5 s
epoch 2 loss 5.3050 train_accuracy 0.14 test_accuracy 0.21 time 26.6 s
epoch 3 loss 5.0196 train_accuracy 0.17 test_accuracy 0.23 time 26.5 s
epoch 4 loss 4.8007 train_accuracy 0.20 test_accuracy 0.28 time 26.6 s
epoch 5 loss 4.5686 train_accuracy 0.23 test_accuracy 0.31 time 26.7 s
epoch 6 loss 4.4147 train_accuracy 0.25 test_accuracy 0.32 time 26.6 s
epoch 7 loss 4.2884 train_accuracy 0.27 test_accuracy 0.35 time 26.7 s
epoch 8 loss 4.1775 train_accuracy 0.28 test_accuracy 0.37 time 26.5 s
epoch 9 loss 4.0192 train_accuracy 0.30 test_accuracy 0.39 time 26.5 s
epoch 10 loss 3.9400 train_accuracy 0.31 test_accuracy 0.40 time 26.6 s
epoch 11 loss 3.8651 train_accuracy 0.32 test_accuracy 0.41 time 26.5 s
epoch 12 loss 3.8044 train_accuracy 0.33 test_accuracy 0.43 time 26.4 s
epoch 13 loss 3.6696 train_accuracy 0.35 test_accuracy 0.45 time 27.0 s
epoch 14 loss 3.6277 train_accuracy 0.36 test_accuracy 0.46 time 26.5 s
epoch 15 loss 3.5693 train_accuracy 0.37 test_accuracy 0.45 time 26.6 s
epoch 16 loss 3.5156 train_accuracy 0.38 test_accuracy 0.46 time 26.5 s
epoch 17 loss 3.4413 train_accuracy 0.39 test_accuracy 0.48 time 26.5 s
epoch 18 loss 3.3881 train_accuracy 0.39 test_accuracy 0.49 time 26.5 s
epoch 19 loss 3.3700 train_accuracy 0.40 test_accuracy 0.49 time 26.6 s
epoch 20 loss 3.3188 train_accuracy 0.41 test_accuracy 0.49 time 26.5 s
epoch 21 loss 3.2750 train_accuracy 0.41 test_accuracy 0.49 time 26.6 s
epoch 22 loss 3.2374 train_accuracy 0.42 test_accuracy 0.51 time 26.5 s
epoch 23 loss 3.1973 train_accuracy 0.43 test_accuracy 0.51 time 26.8 s
epoch 24 loss 3.1711 train_accuracy 0.43 test_accuracy 0.52 time 26.7 s
epoch 25 loss 3.1164 train_accuracy 0.44 test_accuracy 0.52 time 26.4 s
epoch 26 loss 3.0941 train_accuracy 0.44 test_accuracy 0.53 time 26.5 s
epoch 27 loss 3.0704 train_accuracy 0.44 test_accuracy 0.53 time 26.5 s
epoch 28 loss 3.0486 train_accuracy 0.45 test_accuracy 0.54 time 26.5 s
epoch 29 loss 3.0040 train_accuracy 0.45 test_accuracy 0.53 time 26.4 s
epoch 30 loss 2.9759 train_accuracy 0.46 test_accuracy 0.54 time 27.3 s
alphas:[0.0639779866049337, 0.06372224625470922, 0.06406392590329454, 0.06354066006240107, 0.0638129623395603, 0.06393384080278285]
final accuracy: 54.4% 58.9%
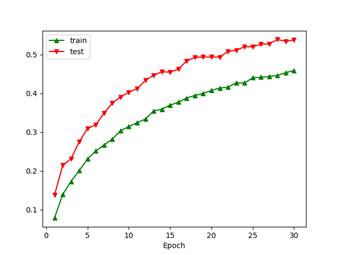
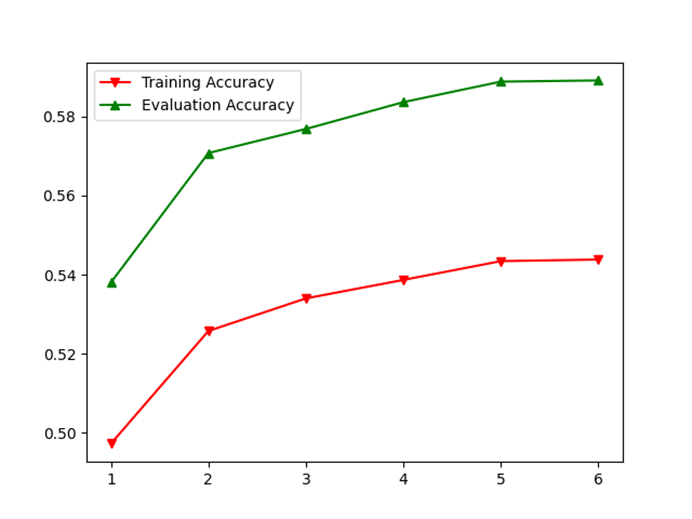
和下面讲到的Bagging策略不同,本实验中AdaBoost策略得到的accuracy gap是负数,主要原因如前面所述——训练集每轮都进行随机性较大的裁剪放缩变换,导致模型在训练时学习难度较大,因此虽然在训练准确率远低于Bagging训练准确率的情况下,仍然取得了接近60%的与Bagging相近的泛化(测试)准确率。就像高考前的模拟考试和高考一样。
因此此处丢弃率p设置为0.1,以适应这种数据增广操作带来的增大的训练难度。在我看来大随机度的数据增广具有更大的模型训练潜力,可以适当调高训练总轮数并调整衰减系数和衰减周期,模型的泛化准确率还有提升的空间。
4.6 Bagging策略:丢弃层丢弃率p对于模型效果的影响(0.3vs0.5)
AlexNet (With BatchNorm2D) ratio=0.6 p=0.3 batch_size=32 lr0=0.03+mixture exponential decay (period=4, decay rate=0.8) SGD Bagging n=6 Epochs=20 Data preprocessing: no augmentation and with pixel value normalization
Device:cpu
Epoch 1 loss 5.5379 training accuracy 24.4 test accuracy 23.8 learning rate 0.0300 time elapsed 990.0
Epoch 2 loss 4.5680 training accuracy 35.4 test accuracy 33.2 learning rate 0.0300 time elapsed 1642.3
Epoch 3 loss 3.9769 training accuracy 43.2 test accuracy 39.4 learning rate 0.0300 time elapsed 26518.5
Epoch 4 loss 3.5429 training accuracy 48.9 test accuracy 44.0 learning rate 0.0300 time elapsed 1119.3
Epoch 5 loss 3.1418 training accuracy 56.0 test accuracy 48.1 learning rate 0.0240 time elapsed 1136.9
Epoch 6 loss 2.9065 training accuracy 60.9 test accuracy 50.7 learning rate 0.0240 time elapsed 1074.4
Epoch 7 loss 2.7025 training accuracy 64.4 test accuracy 52.5 learning rate 0.0240 time elapsed 3966.5
Epoch 8 loss 2.5131 training accuracy 68.3 test accuracy 53.4 learning rate 0.0240 time elapsed 1050.6
Epoch 9 loss 2.2605 training accuracy 72.8 test accuracy 55.0 learning rate 0.0192 time elapsed 4465.0
Epoch 10 loss 2.1098 training accuracy 76.5 test accuracy 56.0 learning rate 0.0192 time elapsed 1000.7
Epoch 11 loss 1.9747 training accuracy 79.3 test accuracy 56.6 learning rate 0.0192 time elapsed 9857.5
Epoch 12 loss 1.8481 training accuracy 82.1 test accuracy 57.1 learning rate 0.0192 time elapsed 1009.5
Epoch 13 loss 1.6342 training accuracy 86.5 test accuracy 58.3 learning rate 0.0154 time elapsed 4257.5
Epoch 14 loss 1.5204 training accuracy 88.6 test accuracy 58.9 learning rate 0.0154 time elapsed 3190.3
Epoch 15 loss 1.4165 training accuracy 90.9 test accuracy 58.5 learning rate 0.0154 time elapsed 3250.6
Epoch 16 loss 1.3205 training accuracy 92.8 test accuracy 59.6 learning rate 0.0154 time elapsed 1594.5
Epoch 17 loss 1.1437 training accuracy 95.0 test accuracy 59.6 learning rate 0.0123 time elapsed 1339.0
Epoch 18 loss 1.0594 training accuracy 96.2 test accuracy 60.1 learning rate 0.0123 time elapsed 11939.6
Epoch 19 loss 0.9912 training accuracy 97.1 test accuracy 60.3 learning rate 0.0123 time elapsed 16671.8
Epoch 20 loss 0.9224 training accuracy 97.7 test accuracy 60.0 learning rate 0.0123 time elapsed 6013.3
AlexNet (With BatchNorm2D) ratio=0.6 p=0.5 batch_size=32 lr0=0.03+mixture exponential decay (period=4, decay rate=0.8) SGD Bagging n=6 Epochs=20 Data preprocessing: no augmentation and with pixel value normalization
Device:cuda:0
Epoch 1 loss 5.9219 training accuracy 17.7 test accuracy 17.2 learning rate 0.0300 time elapsed 252.4
Epoch 2 loss 5.1554 training accuracy 26.6 test accuracy 25.8 learning rate 0.0300 time elapsed 253.0
Epoch 3 loss 4.6581 training accuracy 33.3 test accuracy 30.9 learning rate 0.0300 time elapsed 255.0
Epoch 4 loss 4.2459 training accuracy 39.1 test accuracy 35.7 learning rate 0.0300 time elapsed 252.5
Epoch 5 loss 3.8560 training accuracy 45.0 test accuracy 40.7 learning rate 0.0240 time elapsed 254.3
Epoch 6 loss 3.6071 training accuracy 48.7 test accuracy 43.5 learning rate 0.0240 time elapsed 253.9
Epoch 7 loss 3.4016 training accuracy 52.7 test accuracy 46.1 learning rate 0.0240 time elapsed 254.3
Epoch 8 loss 3.2184 training accuracy 55.6 test accuracy 48.3 learning rate 0.0240 time elapsed 254.3
Epoch 9 loss 2.9945 training accuracy 59.6 test accuracy 50.6 learning rate 0.0192 time elapsed 254.8
Epoch 10 loss 2.8614 training accuracy 61.1 test accuracy 50.4 learning rate 0.0192 time elapsed 254.1
Epoch 11 loss 2.7473 training accuracy 64.7 test accuracy 52.7 learning rate 0.0192 time elapsed 253.4
Epoch 12 loss 2.6348 training accuracy 66.7 test accuracy 53.3 learning rate 0.0192 time elapsed 253.9
Epoch 13 loss 2.4642 training accuracy 69.8 test accuracy 55.1 learning rate 0.0154 time elapsed 253.7
Epoch 14 loss 2.3677 training accuracy 71.5 test accuracy 54.9 learning rate 0.0154 time elapsed 256.1
Epoch 15 loss 2.2857 training accuracy 73.5 test accuracy 55.8 learning rate 0.0154 time elapsed 253.8
Epoch 16 loss 2.2028 training accuracy 74.5 test accuracy 55.8 learning rate 0.0154 time elapsed 255.5
Epoch 17 loss 2.0596 training accuracy 77.6 test accuracy 56.8 learning rate 0.0123 time elapsed 256.1
Epoch 18 loss 1.9889 training accuracy 79.4 test accuracy 57.2 learning rate 0.0123 time elapsed 257.0
Epoch 19 loss 1.9204 training accuracy 80.7 test accuracy 57.4 learning rate 0.0123 time elapsed 256.1
Epoch 20 loss 1.8559 training accuracy 82.1 test accuracy 57.9 learning rate 0.0123 time elapsed 255.2
本实战应用过程中,使用数据增广和丢弃层作为增强模型泛化能力的两种方式。丢弃率p越小,模型越倾向于过拟合。p=0.3时第20轮训练准确率接近98%,但是accuracy gap接近38%;p=0.5时第20轮训练准确率82%左右,accuracy gap接近24%。笔者从这一组对照实验推测,accuracy gap和丢弃率在一定的参数空间内,存在着正比例的关系。
4.7 Bagging策略:学习率和模型数量(以及批量大小、学习率衰减方式)对于多模型学习效果的影响

# 输入批量大小的多模型预测向量,输出批量大小的bagging预测向量
# 核心逻辑:排序+计数+选择
# 性能设计:如果不排序,用set和count方法,时间复杂度ceta(n+nk),如果排序ceta(nlnn+n)
def batch_bagging(pred_mat):device=try_gpu()pred_mat=torch.Tensor(pred_mat)final_yhat=[]# 排序:升序还是降序不重要pred_mat, _ = torch.sort(pred_mat, dim=0)assert(len(pred_mat.shape)==2)pred_mat=pred_mat.Tfor pred_vec in pred_mat:# 计数counts = []mark = 0for i in range(len(pred_vec) - 1):if pred_vec[i + 1] != pred_vec[i]:counts.append(i + 1 - mark)mark = i + 1if i == len(pred_vec) - 2:if pred_vec[-1] == pred_vec[-2]:counts.append(len(pred_vec) - mark)else:counts.append(1)# 找出最大值并选择,如果个数相等选第一个(随机抽取)maxv, maxp = counts[0], 0for i in range(1, len(counts)):if counts[i] > maxv:maxv = counts[i]maxp = ipos = 0for i in range(maxp):pos += counts[i]final_yhat.append(pred_vec[pos])# 记得把返回张量移动到显存上return torch.Tensor(final_yhat).to(device)注:此处的数据增广不包括随机裁剪缩放,随机性有所下降,因此训练准确率高于测试准确率。
AlexNet (With BatchNorm2D) ratio=0.6 p=0.5 batch_size=32 lr0=0.03+mixture exponential decay (period=4, decay rate=0.8) SGD Bagging n=6 Epochs=20 Data preprocessing: no augmentation and with pixel value normalization
device:cuda:0
Epoch 1 loss 5.9219 training accuracy 17.7 test accuracy 17.2 learning rate 0.0300 time elapsed 252.4
Epoch 20 loss 1.8559 training accuracy 82.1 test accuracy 57.9 learning rate 0.0123 time elapsed 255.2
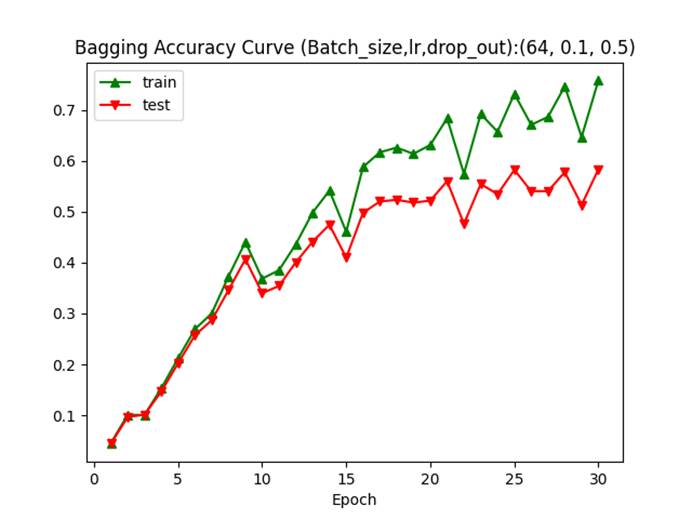
AlexNet (With BatchNorm2D) ratio=0.6 p=0.5 batch_size=64 lr0=0.1+mixture exponential decay (period=4, decay rate=0.8) SGD Bagging n=9 Epochs=30 Data preprocessing: real-time augmentation and with pixel value normalization
device:cuda:0
Epoch 1 loss 6.3803 training accuracy 4.5 test accuracy 4.4 learning rate 0.1000 time elapsed 862.4
Epoch 30 loss 1.7537 training accuracy 75.8 test accuracy 58.3 learning rate 0.0210 time elapsed 893.7
AlexNet (With BatchNorm2D) ratio=0.6 p=0.5 batch_size=64 lr0=0.1+cosine decay SGD Bagging n=12 Epochs=30 Data preprocessing: real-time augmentation and with pixel value normalization
device:cuda:0
Epoch 1 loss 6.5703 training accuracy 4.1 test accuracy 4.3 learning rate 0.1000 time elapsed 1707.8
Epoch 30 loss 2.1637 training accuracy 71.9 test accuracy 59.4 learning rate 0.0003 time elapsed 1884.9
AlexNet (With BatchNorm2D) ratio=0.6 p=0.5 batch_size=64 lr0=0.1+mixture exponential decay (period=4, decay rate=0.8) SGD Bagging n=12 Epochs=30 Data preprocessing: real-time augmentation and with pixel value normalization
device:cuda:0
Epoch 1 loss 6.5218 training accuracy 4.9 test accuracy 4.6 learning rate 0.1000 time elapsed 2183.0
Epoch 30 loss 2.1780 training accuracy 71.4 test accuracy 58.1 learning rate 0.0210 time elapsed 2135.7
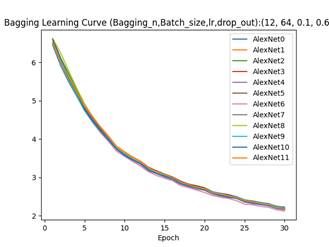
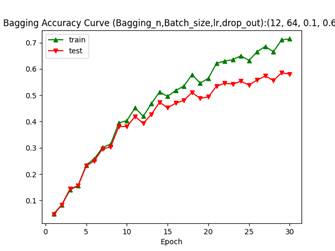
以上4个相互对照的实验,训练准确率波动在10%以内,测试准确率均在57-60%的范围内,说明Bagging策略对于学习率的鲁棒性远高于Bagging,但是最终模型的泛化能力和普适精确度和AdaBoost策略相近。笔者对两者的最终调优结果,相较于4.1的第二个单模型学习结果,泛化准确率提升在5%-7%左右。
Bagging的模型数量对于模型精度的提升不能够简单的按照完全独立的概率分布进行计算,虽然引入了具有较强随机性的数据增广操作,但是样本空间本质仍然是完全相同的数据集。同时结合其他实验结果表明:一定范围内,较小的批量(32vs64)和较低的初始学习率(0.03vs0.06vs0.1)可以给模型带来更高的初始准确率。
在CIFAR100数据集上以及本实验的参数空间设定中,余弦式学习率衰减和周期指数衰减并无较大差异。
4.8 题外话:CIFAR10与AlexNet压缩版2
AlexNet (With BatchNorm2D) ratio=0.6 p=0.5 batch_size=32 lr0=0.03+mixture exponential decay (period=4, decay rate=0.8) SGD Bagging n=1 Epochs=30 Data preprocessing: real-time augmentation and with pixel value normalization
epoch 1 loss 3.0479 train_accuracy 0.20 test_accuracy 0.27 time 33.4 s
epoch 2 loss 2.7643 train_accuracy 0.28 test_accuracy 0.30 time 33.2 s
epoch 3 loss 2.6430 train_accuracy 0.32 test_accuracy 0.28 time 35.2 s
epoch 4 loss 2.5530 train_accuracy 0.35 test_accuracy 0.31 time 34.4 s
epoch 5 loss 2.4638 train_accuracy 0.38 test_accuracy 0.37 time 32.9 s
epoch 6 loss 2.3915 train_accuracy 0.40 test_accuracy 0.38 time 32.7 s
epoch 7 loss 2.3271 train_accuracy 0.42 test_accuracy 0.34 time 32.4 s
epoch 8 loss 2.2873 train_accuracy 0.43 test_accuracy 0.38 time 33.3 s
epoch 9 loss 2.2525 train_accuracy 0.44 test_accuracy 0.36 time 33.0 s
epoch 10 loss 2.2225 train_accuracy 0.45 test_accuracy 0.40 time 33.1 s
epoch 11 loss 2.1675 train_accuracy 0.47 test_accuracy 0.43 time 32.9 s
epoch 12 loss 2.1412 train_accuracy 0.47 test_accuracy 0.41 time 32.7 s
epoch 13 loss 2.1336 train_accuracy 0.47 test_accuracy 0.44 time 32.4 s
epoch 14 loss 2.0998 train_accuracy 0.48 test_accuracy 0.43 time 32.6 s
epoch 15 loss 2.0927 train_accuracy 0.48 test_accuracy 0.42 time 32.4 s
epoch 16 loss 2.0598 train_accuracy 0.49 test_accuracy 0.47 time 32.8 s
epoch 17 loss 2.0460 train_accuracy 0.50 test_accuracy 0.42 time 32.4 s
epoch 18 loss 2.0343 train_accuracy 0.50 test_accuracy 0.48 time 32.3 s
epoch 19 loss 2.0223 train_accuracy 0.50 test_accuracy 0.45 time 31.6 s
epoch 20 loss 2.0099 train_accuracy 0.50 test_accuracy 0.43 time 31.4 s
epoch 21 loss 1.9774 train_accuracy 0.51 test_accuracy 0.48 time 31.6 s
epoch 22 loss 1.9764 train_accuracy 0.51 test_accuracy 0.48 time 31.9 s
epoch 23 loss 1.9676 train_accuracy 0.52 test_accuracy 0.47 time 31.9 s
epoch 24 loss 1.9591 train_accuracy 0.52 test_accuracy 0.47 time 31.8 s
epoch 25 loss 1.9612 train_accuracy 0.52 test_accuracy 0.49 time 31.9 s
epoch 26 loss 1.9364 train_accuracy 0.52 test_accuracy 0.50 time 32.1 s
epoch 27 loss 1.9201 train_accuracy 0.53 test_accuracy 0.48 time 32.2 s
epoch 28 loss 1.9212 train_accuracy 0.53 test_accuracy 0.49 time 33.0 s
epoch 29 loss 1.9242 train_accuracy 0.53 test_accuracy 0.51 time 32.8 s
epoch 30 loss 1.9057 train_accuracy 0.53 test_accuracy 0.53 time 32.9 s
使用相同的ratio=0.6对卷积核的输入输出通道数、线性层的节点数进行缩减。30轮训练的结果表明,AlexNet的“内禀属性”和不同形式的数据集关联较小,参考4.1 第二个结果(对照组),30轮训练后的模型泛化准确率均为53%,但CIFAR10的accuracy gap为0%,CIFAR100的accuracy gap为10%。此时可以考虑降低丢弃率和压缩系数ratio重新训练。

| 图 5 AlexNet原始模型错误率 |
原始的全量AlexNet模型在2012年ImageNet挑战赛上一举夺魁,top1-error 37.5%,top5-error 17.0% (见下图),本实测测量的是AlexNet压缩版本的top1-error,最高的泛化准确率目前调出来是4.6中的第一个结果,即60%。一定程度上进一步说明了AlexNet架构的普适能力。
五、参考资料
[1] (25 封私信 / 15 条消息) 50系显卡(Blackwell架构)安装Pytorch、MMDetection教程 - 知乎
[2] 超详细解释奇异值分解(SVD)【附例题和分析】-CSDN博客