【论文阅读】ON THE ROLE OF ATTENTION HEADS IN LARGE LANGUAGE MODEL SAFETY
ON THE ROLE OF ATTENTION HEADS IN LARGE LANGUAGE MODEL SAFETY
-
原文摘要
-
研究背景与现状
-
背景
- LLMs 在多种语言任务上表现出色,但其安全防护措施可能被绕过,从而生成有害内容。
- 已有研究发现,当模型的安全性表示或相关组件被压制时,其安全能力会受损。
-
现状
- 尽管安全机制的研究不断深入,但目前的研究普遍忽视了多头注意力机制对模型安全性的影响。
- 然而,多头注意力在模型功能中扮演着至关重要的角色。
-
-
研究目标与贡献
-
目标:探索标准注意力机制与安全能力之间的联系,以填补安全性相关的可解释性研究空白。
-
贡献:提出的新方法与指标
-
Safety Head ImPortant Score (Ships)
- 一个新的指标,用于评估单个注意力头对模型安全性的贡献。
-
Safety Attention Head AttRibution Algorithm (Sahara)
- 基于 Ships 指标的扩展,能够在数据集层面归因并识别模型中关键的“安全注意力头”。
-
-
-
实验发现
-
存在特殊的“安全注意力头”,它们对模型安全有显著影响。
-
仅移除一个安全注意力头,就会使得一个对齐过的模型生成的有害回答数量增加 16 倍
-
而模型参数只需改动 0.006%,这远小于之前研究中约需修改的 5% 参数。
-
-
注意力头主要充当了安全特征提取器的角色。
-
从同一基础模型微调得到的不同模型,会有部分“安全注意力头”重叠,这表明这些注意力头具有可迁移性。
-
-
1. Introduction
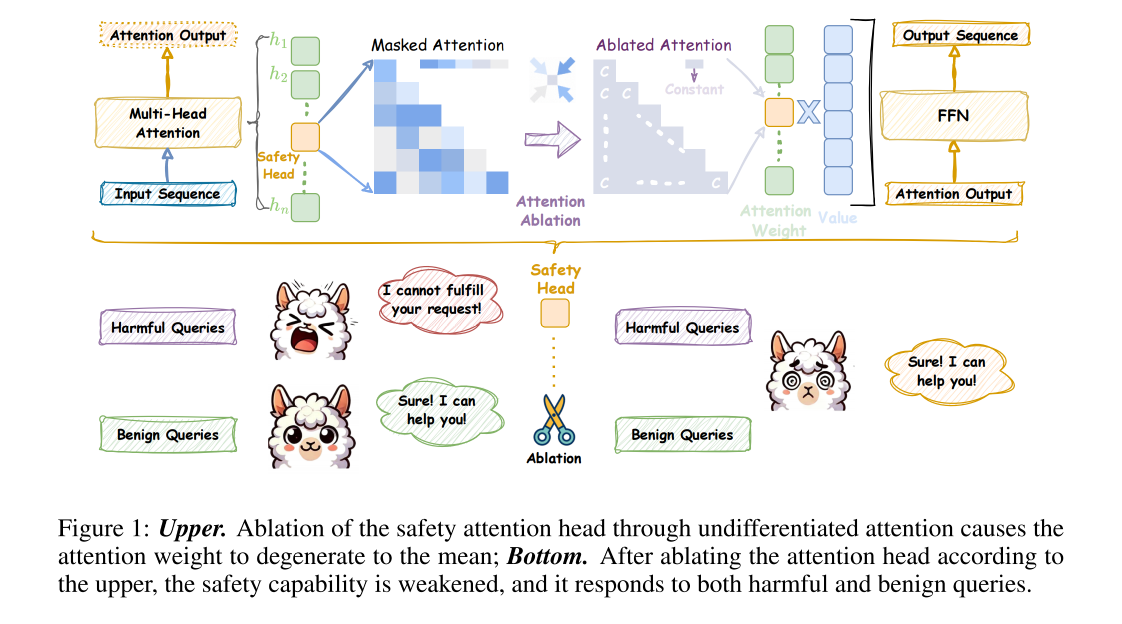
-
研究背景与动机
-
LLMs 能力提升与安全风险
- 大型语言模型在更大规模的预训练数据集上学习,能力显著提升
- 但是,它们仍可能对有害查询作出响应,生成 不安全或有害内容,从而引发潜在风险
-
对齐与绕过问题
- 为了确保 LLM 的安全性,研究者们通过 alignment 方法(如 RLHF,人类反馈强化学习)使模型输出与人类价值观保持一致。
- 然而,已有研究表明,恶意攻击者仍能绕过安全防护。
- 因此,需要深入理解 LLM 内部的安全机制,这对开发至关重要。
-
-
现有研究与不足
-
黑箱与机制解释
-
当前揭示 LLM 安全机制的主要手段是 机制解释方法。
- 这些方法从 特征、神经元、层、参数 等角度进行细粒度分析,以帮助理解模型行为。
-
现有研究集中于神经元与表示
- 近期研究发现,安全能力可以归因于模型内部的 表示和特定神经元。
- 但“多头注意力机制”在安全可解释性中研究较少,尽管它已被证实在其他模型能力中至关重要。
-
-
多头注意力安全解释的挑战
- 由于组件和表示的特殊性,直接将已有的解释方法迁移到安全注意力归因非常困难。
- 同时,一些通用的方法往往只依赖一次 forward 过程的结果变化来分析,但 安全任务需要多轮生成才能评估模型对有害查询的拒绝能力。
-
-
本文研究目标与核心方法
-
本文旨在 解释多头注意力中的安全能力。为此提出了两项新方法:
-
Ships(Safety Head ImPortant Scores)
- 用于量化每个注意力头对模型安全性的贡献。
- 它通过 因果追踪 衡量注意力头对 有害查询拒绝概率 的影响。
-
Sahara(Safety Attention Head AttRibution Algorithm)
-
基于 Ships 的扩展,用于归因并找出模型中关键的安全注意力头组合。
-
它通过在有害查询数据集上迭代选择和消融注意力头,找到一组对安全性影响显著的头。
-
-
-
-
核心实验结果
-
在三个有害查询数据集上,使用 Ships 找到安全头并进行无差别注意力消融(仅修改约 0.006% 的参数),即可显著削弱模型安全性:
- Llama-2-7b-chat 的攻击成功率从 0.04 提升至 0.64 ↑
- Vicuna-7b-v1.5 从 0.27 提升至 0.55 ↑
-
进一步基于 Sahara 迭代选择关键头,ASR 提升至 0.72 ↑。
-
-
研究洞察
-
基于 Ships 和 Sahara 的分析揭示了几个关键洞察:
-
某些注意力头是安全特征整合的关键。
- 修改注意力权重矩阵的值会显著改变模型输出,而单纯缩放注意力输出影响不大。
-
从相同基础模型微调的 LLM,其安全头具有重叠性。
- 说明基础模型的安全特征同样关键,而不仅仅是 alignment 过程。
-
影响安全性的注意力头可独立作用,而对有用性影响较小。
-
-
-
论文贡献总结
-
首次发现并验证了 LLM 中存在特定的“安全注意力头”,填补了安全可解释性研究的空白。
-
提出了 Ships 方法评估注意力头的安全影响,并设计 Sahara 算法寻找会显著降低安全性的头组。
-
全面分析了标准多头注意力机制在 LLM 安全中的重要性,并基于大量实验提供了新的洞察,有助于提高透明度并减轻 LLM 风险。
-
2. Preliminary
2.1 Large Language Models
-
Next token prediction
-
主流的 LLM 多采用 decoder-only 架构,通过自回归地预测下一个 token 来生成文本。
-
给定输入序列 x=x1,x2,…,xsx = x_1, x_2, \ldots, x_sx=x1,x2,…,xs,模型对下一 token 的分布为:
p(xs+1=vi∣x1,…,xs)=exp(os⋅W:,i)∑j=1∣V∣exp(os⋅W:,j),(1) p(x_{s+1} = v_i \mid x_1, \ldots, x_s) = \frac{\exp(o_s \cdot W_{:, i})} {\sum_{j=1}^{|V|} \exp(o_s \cdot W_{:, j})}, \tag{1} p(xs+1=vi∣x1,…,xs)=∑j=1∣V∣exp(os⋅W:,j)exp(os⋅W:,i),(1)-
oso_sos:最后一层的残差流表征
- 在 Transformer 中每一层都有残差连接,最终的残差流向量聚合了先前层的信息。
-
WWW:输出层的线性投影矩阵,将隐藏表征 oso_sos 映射到词表 ∣V∣|V|∣V∣ 上的 logits。
- W:,iW_{:, i}W:,i:矩阵 WWW 的第 iii 列,对应词表中第 iii 个 token 的 logit 权重向量。
-
分母是对所有词(∣V∣|V|∣V∣)进行 Softmax 归一化 得到的概率分布。
-
-
-
生成过程:
- 从该分布中采样得到新 token xs+1x_{s+1}xs+1,再把它接到输入后继续迭代,得到最终回复R=xs+1,xs+2,…,xs+RR = x_{s+1}, x_{s+2}, \ldots, x_{s+R}R=xs+1,xs+2,…,xs+R。
2.2 Multi-Head Attention
-
背景
- 注意力机制在 LLM 中捕获输入序列特征至关重要。
- 先前工作表明,不同的注意力头在不同任务上具有功能特化。
-
多头注意力的形式化
MHAWq,Wk,Wv=(h1⊕h2⊕⋯⊕hn)Wo,hi=Softmax(WqiWkiTdk/n)Wvi,(2) \text{MHA}_{W_q, W_k, W_v} = (h_1 \oplus h_2 \oplus \cdots \oplus h_n) W_o, \quad h_i = \text{Softmax}\left( \frac{W_q^i W_k^{iT}}{\sqrt{d_k / n}} \right) W_v^i, \tag{2} MHAWq,Wk,Wv=(h1⊕h2⊕⋯⊕hn)Wo,hi=Softmax(dk/nWqiWkiT)Wvi,(2)-
nnn:注意力头的数量。
-
⊕\oplus⊕:按维度拼接(concatenation)。
-
Wqi,Wki,WviW_q^i, W_k^i, W_v^iWqi,Wki,Wvi:第 iii 个注意力头的 Query、Key、Value 投影矩阵。
-
WoW_oWo:将各个头拼接后的表示再映射回隐藏维度的输出矩阵。
-
dkd_kdk:Key 矩阵 WkW_kWk 的总维度大小。
- 缩放因子 dk/n\sqrt{d_k/n}dk/n:与 Transformer 中的 dhead\sqrt{d_{\text{head}}}dhead 一致,用来稳定点积注意力的数值范围。
-
2.3 LLM Safety and Jailbreak Attack
-
安全对齐目标
- LLM 可能生成不道德/非法内容。
- 为降低风险,采用安全对齐,让模型在面对有害查询 xHx_HxH 时,以高概率拒绝回答。
-
对齐训练目标(最大化拒绝概率)
argminθ−logp(R⊥∣xH=x1,x2,…,xs;θ),(3) \arg\min_{\theta} - \log p(R_{\perp} \mid x_H = x_1, x_2, \ldots, x_s; \theta), \tag{3} argθmin−logp(R⊥∣xH=x1,x2,…,xs;θ),(3)-
θ\thetaθ:模型参数。
-
R⊥R_{\perp}R⊥:拒绝式的响应(例如 “I cannot …”, “As a responsible AI assistant …” 等)。
-
含义:通过最小化负对数似然,等价于最大化模型在有害输入 xHx_HxH 下生成拒绝响应 R⊥R_{\perp}R⊥ 的概率。
-
目标:把拒绝 token 的概率拉高,使模型更倾向于拒绝。
-
-
Jailbreak 攻击目标
-
攻击者试图绕过安全防护,让模型输出有害内容。其目标可形式化为:
maxp(D(R)=True∣xH=x1,x2,…,xs;θ),(4) \max p(D(R) = \text{True} \mid x_H = x_1, x_2, \ldots, x_s; \theta), \tag{4} maxp(D(R)=True∣xH=x1,x2,…,xs;θ),(4)-
DDD:一个安全判别器,当它判定回复 RRR 为有害时 D(R)=TrueD(R) = \text{True}D(R)=True。
-
含义:最大化生成的回复被判为“有害”的概率,即提高攻击成功率。
-
-
-
已有发现的关键点:
-
把分布往“肯定/执行类 token”上偏移能显著提升 ASR。
-
压制拒绝 token也能产生类似效果。
-
结论:LLM 的安全性本质上依赖于在有害输入下最大化拒绝 token 的生成概率。
-
2.4 Safety Parameters
-
背景与目标
-
机制可解释性尝试把模型能力归因到具体参数上,以提升透明度。
- 近期关于安全可解释性的工作试图识别对安全最关键的参数:
-
一旦这些参数被修改/消融,模型的安全护栏会被削弱,导致不道德内容的生成概率上升。
-
-
Safety Parameters的定义
ΘS,K=Top-K{θS:argmaxθC∈θOΔp(θC)}, \Theta_{S, K} = \text{Top-}K \left\{ \theta_S : \arg\max_{\theta_C \in \theta_O} \Delta p(\theta_C) \right\}, ΘS,K=Top-K{θS:argθC∈θOmaxΔp(θC)},-
其中
Δp(θC)=DKL(p(R⊥∣xH; θO) ∥ p(R⊥∣xH; (θO∖θC))), \Delta p(\theta_C) = \mathrm{D_{KL}} \big( p(R_{\perp} \mid x_H;\, \theta_O) \,\|\, p(R_{\perp} \mid x_H;\, (\theta_O \setminus \theta_C)) \big), Δp(θC)=DKL(p(R⊥∣xH;θO)∥p(R⊥∣xH;(θO∖θC))),-
θO\theta_OθO:原始模型的所有参数。
-
θC\theta_CθC:候选参数子集。
-
θO∖θC\theta_O \setminus \theta_CθO∖θC:对候选参数 θC\theta_CθC 做消融 后的模型(可理解为把这些参数置零、替换或断开其功能)。
-
Δp(θC)\Delta p(\theta_C)Δp(θC):当把 θC\theta_CθC 消融后,模型在有害输入下生成拒绝的分布发生了多大“退化”(差异越大意味着这组参数越关键)。
-
Top-K:从所有候选参数中,挑出让 Δp\Delta pΔp 最大的 K 组参数,作为 安全参数集合 ΘS,K\Theta_{S,K}ΘS,K。
-
-
原理:
-
核心思想:如果移除一组参数会显著降低模型对有害输入的拒绝概率,那么它们就是安全关键参数。
-
用 KL 散度 来度量“拒绝分布”的变化幅度:变化越大,说明该参数对维持安全分布的作用越重要。
-
-
3. Safety Head ImPortant Score
-
本节的目标是识别多头注意力机制中与安全性相关的参数,特别是在应对某个有害查询时,找出最关键的 安全注意力头。
-
3.1:提出两种注意力头消融方法,用以控制某个注意力头对安全性的贡献;
-
3.2:基于消融结果定义 Ships;
-
3.3:通过实验验证 Ships 的有效性。
-
3.1 ATTENTION HEAD ABLATION
-
研究背景
-
以往研究通常通过 将注意力头输出设为 0 来消融该头,从而分析该头对模型的影响。
MHAWq,Wk,WvA=(h1⊕h2⋯⊕himod⋯⊕hn)Wo \text{MHA}^A_{W_q, W_k, W_v} = (h_1 \oplus h_2 \cdots \oplus h_i^{\text{mod}} \cdots \oplus h_n) W_o MHAWq,Wk,WvA=(h1⊕h2⋯⊕himod⋯⊕hn)Wo- 符号说明:
- Wq,Wk,WvW_q, W_k, W_vWq,Wk,Wv:对应 Query、Key、Value 矩阵。
- hih_ihi:第 iii-个注意力头的输出。
- himodh_i^{\text{mod}}himod:对第 iii-个注意力头进行消融后的输出。
- ⊕\oplus⊕:拼接操作,将各头的输出拼接成一大向量后再乘 WoW_oWo。
- 符号说明:
-
与标准 MHA 相比,这里用 himodh_i^{\text{mod}}himod 替换了第 iii-个注意力头,以实现对该头贡献的控制或消除。
-
-
创新点:增强消融方法
-
与直接置零不同,本文通过缩放或变形参数矩阵 Wq,Wk,WvW_q, W_k, W_vWq,Wk,Wv 来获得 更精细的控制。
-
无差异注意力
-
缩放贡献
-
-
这两种方法都是通过将某些矩阵乘以一个 非常小的系数 ϵ\epsilonϵ 来实现消融效果。
-
3.1.1 Undifferentiated Attention
-
核心思路:通过缩放 WqW_qWq 或 WkW_kWk,让注意力权重塌缩成一个特殊矩阵 AAA,从而阻止该头有效提取输入序列的关键信息。
-
特殊矩阵 A 的定义
-
AAA 是一个下三角矩阵:
aij={1i,if i≥j,0,if i<j. a_{ij} = \begin{cases} \frac{1}{i}, & \text{if } i \ge j, \\ 0, & \text{if } i < j. \end{cases} aij={i1,0,if i≥j,if i<j.- 行 iii 的元素为 1i\frac{1}{i}i1 直到对角线位置,之后为 0。
- 这种结构会削弱注意力机制的区分能力,使注意力分布几乎无信息量。
-
论文指出:无论是缩放 WqW_qWq 还是 WkW_kWk,最终效果等价(附录有证明)。
-
-
Undifferentiated Attention
himod=Softmax(ϵWqiWkiTdk/n)Wvi=AWvi h_i^{\text{mod}} = \text{Softmax} \left( \frac{\epsilon W_q^i W_k^{iT}}{\sqrt{d_k / n}} \right) W_v^i = A W_v^i himod=Softmax(dk/nϵWqiWkiT)Wvi=AWvi-
解释:
- 在 Softmax 之前,WqiWkiTW_q^i W_k^{iT}WqiWkiT 被 ϵ\epsilonϵ 大幅缩放,导致注意力打分几乎趋于无效化。
- 这样得到的注意力权重矩阵近似于 AAA。
- 最终输出 himodh_i^{\text{mod}}himod 变为 AWivA W^v_iAWiv,即使用 AAA 代替正常注意力权重。
-
原理: 把注意力权重人为限制成一种无区分性结构,等同于让该头丧失“从输入序列中抽取关键安全特征”的能力。
-
3.1.2 Scaling Contribution
-
核心思路:通过直接缩放 WvW_vWv 矩阵,将该头的输出幅度大幅减小,使其对最终 MHA 输出的贡献微乎其微。
-
Scaling Contribution
himod=Softmax(WqiWkiTdk/n)ϵWvi h_i^{\text{mod}} = \text{Softmax} \left( \frac{W_q^i W_k^{iT}}{\sqrt{d_k / n}} \right) \epsilon W_v^i himod=Softmax(dk/nWqiWkiT)ϵWvi- 解释:
- 与Undifferentiated Attention不同,这里 不改变注意力权重的结构,而是直接将 WivW^v_iWiv 乘以 ϵ\epsilonϵ。
- 拼接所有头输出后,乘以 WoW^oWo 时,这个头的贡献几乎被压缩到可以忽略。
- 解释:
3.1.3 两种方法的比较
-
Undifferentiated Attention:
- 破坏注意力分布,使头无法提取有效信息。
- 通过修改 WqW_qWq 或 WkW_kWk 实现。
-
**Scaling Contribution **:
- 保留注意力结构,但直接压低头的贡献幅度。
- 通过缩放 WvW_vWv 实现。
-
两者都通过小系数 ϵ\epsilonϵ 控制消融强度,但侧重点不同。
3.2 EVALUATE THE IMPORTANCE OF PARAMETERS FOR SPECIFIC HARMFUL QUERY
-
场景设定
-
对齐模型共有 LLL 层。
-
在第 lll 层(l∈(0,L)l \in (0, L)l∈(0,L))的多头注意力中,第 iii 个注意力头记为 hilh_i^lhil,其对应的(待被消融的)参数记为 θhil\theta_{h_i^l}θhil
-
消融后的模型会产生一个新的概率分布,论文把它记为:p(θhil)=p(θO∖θhil),p(\theta_{h_i^l}) = p(\theta_O \setminus \theta_{h_i^l}),p(θhil)=p(θO∖θhil),
-
θO∖θhil\theta_O \setminus \theta_{h_i^l}θO∖θhil:表示把第 lll 层第 iii 个头的参数从模型中“移除/削弱”后的参数集合;
-
消融某个头 = 用 θO∖θhil\theta_O \setminus \theta_{h_i^l}θO∖θhil 这个新参数集来前向生成,从而得到新的分布。
-
-
-
核心动机
-
对齐模型是通过最大化对有害查询的拒绝概率训练得到的。因此:
-
如果我们消融了一个真正与安全强相关的注意力头,就会降低拒绝相关分布的概率
-
因此,比较原模型的分布与消融该头后的分布的差异大小,就能评估这个头对于安全的重要性。
-
-
-
Ships 的定义
Ships(qH,θhil)=DKL(p(qH;θO) ∥ p(qH;θO∖θhil)),(9) \text{Ships}(q_H, \theta_{h_i^l}) = D_{\mathrm{KL}}\Big( p(q_H; \theta_O) \,\Big\|\, p\big(q_H; \theta_O \setminus \theta_{h_i^l}\big) \Big), \tag{9} Ships(qH,θhil)=DKL(p(qH;θO)p(qH;θO∖θhil)),(9)- qHq_HqH:特定的有害查询(harmful query)。
3.3 ABLATE ATTENTION HEADS FOR SPECIFIC QUERY IMPACT SAFETY
-
研究目的:实验证明 Ships 指标能够有效识别出 安全注意力头。
-
实验设置
-
使用的模型:Llama-2-7b-chat、Vicuna-7b-v1.5
-
使用的有害查询数据集:Advbench、Jailbreakbench、Malicious Instruct
-
生成设置:
-
对每个有害查询 qHq_HqH,生成长度为 128 个 token 的输出,用以评估模型安全性。
-
解码策略:
- 贪婪搜索:确保实验结果可复现。
- Top-k sampling:用于捕捉概率分布的变化。
-
-
评估指标:攻击成功率
ASR=1∣QH∣∑xi∈QH(D(xn+1:xn+R∣xi)=True) \text{ASR} = \frac{1}{|Q_H|} \sum_{x^i \in Q_H} \Big( D(x_{n+1} : x_{n+R} \mid x^i) = \text{True} \Big) ASR=∣QH∣1xi∈QH∑(D(xn+1:xn+R∣xi)=True)- 符号说明:
- QHQ_HQH:有害查询数据集。
- xn+1:xn+Rx_{n+1} : x_{n+R}xn+1:xn+R:模型对输入 xix_ixi 生成的连续 128 个 token 输出序列。
- D(⋅)D(\cdot)D(⋅):安全判别器,用于判断生成的回复是否属于“有害内容”。
- 符号说明:
-
-
实验结果
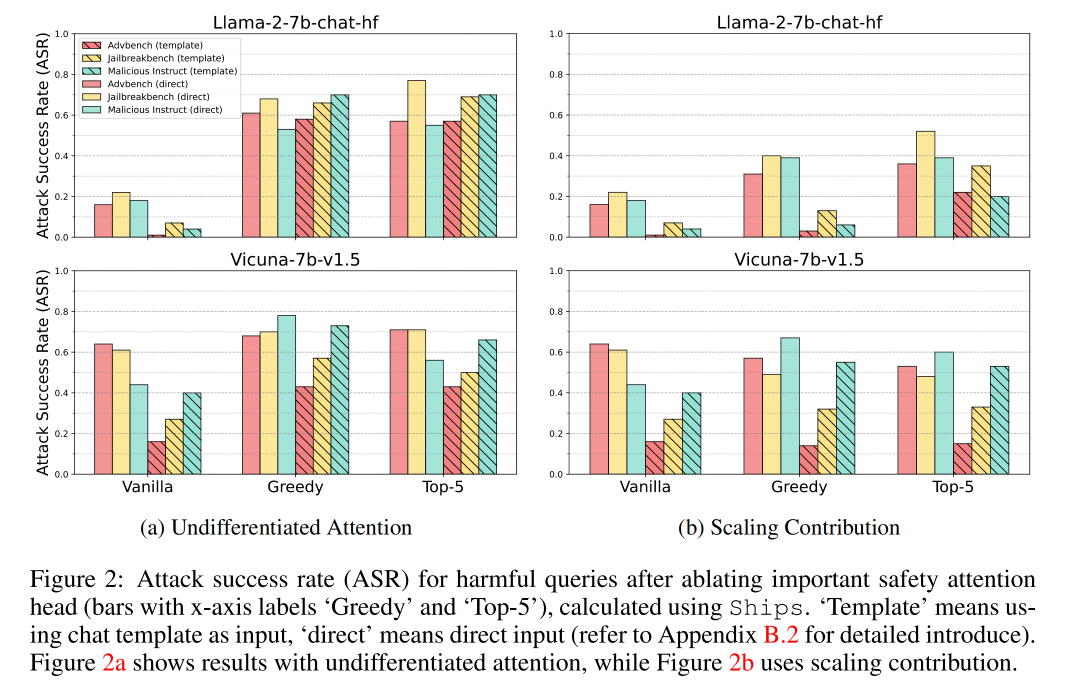
-
实验结论
-
通过 Ships 指标挑选出的特殊注意力头,对 LLM 的安全性具有 关键影响。
-
仅仅消融一个安全头(占比非常小的参数量),就能显著提高攻击成功率,证明了安全头在模型内部的集中性和重要性。
-
4. SAFETY ATTENTION HEAD ATTRIBUTION ALGORITHM
-
本节总体思路
-
第 3 节里,Ships 评估的是:针对单个有害查询 qHq_HqH,某个注意力头被消融后对“拒绝分布”造成的影响,从而度量该头的安全重要性。
-
第 4 节将 Ships 推广到数据集层面(跨多个有害查询 QHQ_HQH),以消除与特定查询绑定的偶然性,找出在不同有害查询上都稳定发挥作用的注意力头。
- 这些“跨查询一致重要”的头,更可能是注意力机制内部真正的安全参数。
-
4.1 GENERALIZE THE IMPACT OF SAFETY HEAD ABLATION
-
关键背景与依据
-
Residual stream 激活 aaa 含有安全关键特征
- 先前研究指出,顶层残差流(top residual stream)的激活 aaa 中包含与安全强相关的特征。
-
用 SVD 提取安全关键特征
-
奇异值分解(SVD)是标准的特征提取技术。
-
近期研究发现,左奇异矩阵 UUU 能刻画与安全相关的关键表示方向。
-
-
-
构造表示矩阵并做 SVD
-
收集方式:对整个有害查询数据集 QHQ_HQH,在顶层残差流处收集所有有害查询的激活向量 aaa。
-
堆叠成矩阵:把所有查询对应的激活向量按行(或按样本)堆叠,得到矩阵MMM
-
SVD 分解:
SVD(M)=UΣVT \text{SVD}(M) = U \Sigma V^T SVD(M)=UΣVT- UθU_\thetaUθ:在原始(未消融)模型 θ\thetaθ 下得到的左奇异矩阵,维度为 ∣QH∣×dk|Q_H| \times d_k∣QH∣×dk,它表示有害查询表示空间中的关键特征方向。
-
在消融后模型上重复上述过程
-
对第 lll 层第 iii 个注意力头 hilh_i^lhil 做消融。
-
用消融后的模型重复同样的数据收集与 SVD 步骤,得到新的左奇异矩阵 UAU_AUA。
目的:比较 UθU_\thetaUθ(原模型)与 UAU_AUA(消融某头后)之间的子空间差异,来衡量该头对安全表示空间的影响。
-
-
-
用主角度(Principal Angles)比较两个子空间
-
由于 SVD 的前 rrr 个奇异向量(即 UUU 的前 rrr 列)通常捕获最主要的特征,论文只比较这 前 rmainr_{\text{main}}rmain 个维度。
- Uθ(r)U_\theta^{(r)}Uθ(r):UθU_\thetaUθ 的前 rmainr_{\text{main}}rmain 列
- UA(r)U_A^{(r)}UA(r):UAU_AUA 的前 rmainr_{\text{main}}rmain 列
-
计算二者之间的主角度(principal angles)。
- 直观上,主角度衡量两个子空间的夹角大小,角度越大,表示两个子空间越“偏离”,即消融后安全表示发生了更大的改变。
φr=cos−1(σr(Uθ(r),UA(r))) \varphi_r = \cos^{-1}\big(\sigma_r(U_\theta^{(r)}, U_A^{(r)})\big) φr=cos−1(σr(Uθ(r),UA(r)))
-
-
Ships 推广
-
子空间主角度之和定义为数据集级的 Ships,记作:
Ships(QH,hil)=∑r=1rmainφr=∑r=1rmaincos−1(σr(Uθ(r),UA(r))) \text{Ships}(Q_H, h_i^l) = \sum_{r=1}^{r_{\text{main}}} \varphi_r = \sum_{r=1}^{r_{\text{main}}} \cos^{-1}\Big( \sigma_r\big(U_\theta^{(r)}, U_A^{(r)}\big) \Big) Ships(QH,hil)=r=1∑rmainφr=r=1∑rmaincos−1(σr(Uθ(r),UA(r)))-
σr\sigma_rσr:第 rrr 个奇异值(用于得到两个子空间之间的第 rrr 个主角度)。
-
φr\varphi_rφr:对应的主角度。
-
rmainr_{\text{main}}rmain:只取前 rmainr_{\text{main}}rmain 维进行累加,强调“最重要的特征子空间”的变化。
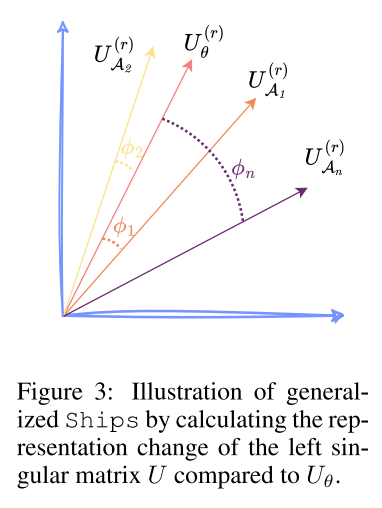
-
-
4.2 SAFETY ATTENTION HEAD ATTRIBUTION ALGORITHM
-
动机与假设
-
4.1 节已经把 Ships 推广到数据集层面,可以度量单个注意力头被消融后,对整份有害查询数据集 QHQ_HQH 的安全表示(顶层残差流子空间)造成的改变。
-
但已有研究表明:LLM 的组件之间常常存在协同效应。
-
作者据此假设:这种协同主要发生在注意力头之间。
- 因此,需要从单头重要性扩展到头组的重要性,去找一组协同工作的安全头。
-
-
Sahara算法
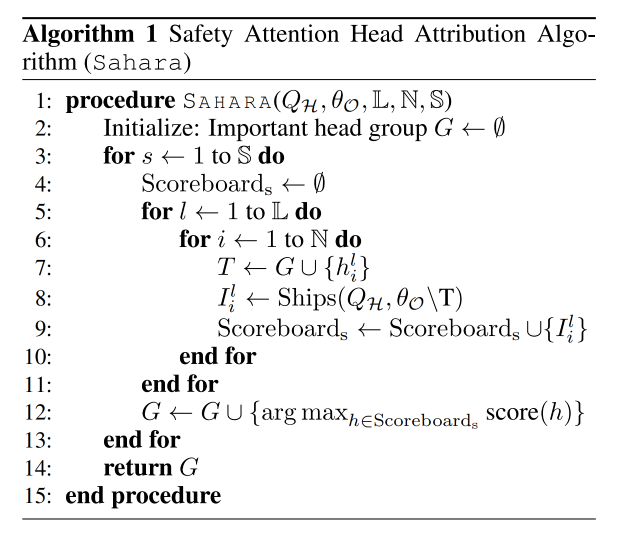
-
输入&输出
-
输入
-
QHQ_HQH:有害查询数据集
-
θO\theta_OθO:对齐后的 LLM(共有 LLL 层,每层 NNN 个注意力头)
-
SSS:要选出的“重要安全头组” GGG 的目标大小(head 的个数)
-
-
输出
- GGG:大小为 SSS 的安全注意力头组。消融该组,会在数据集级安全表示上造成显著偏移,进而削弱模型安全性。
-
-
算法流程
-
初始化:令 G←∅G \leftarrow \varnothingG←∅(空集)
-
迭代(共 SSS 轮)
-
每一轮做两步:
-
消融当前已在 GGG 中的所有头;
-
枚举其余尚未加入 GGG 的头,对把该头加入 GGG 并一起消融后的模型进行度量:
-
使用 数据集级 Ships 衡量顶层残差流安全表示子空间的变化幅度;
-
选择使该度量最大的那个头,加入 GGG。
-
-
-
-
结束:经过 SSS 次迭代,得到一个 能协同破坏安全表示 的注意力头集合 GGG。
-
-
-
算法关键点
-
目标函数:每一轮用Ships 指标来评估当前G∪{候选头}G ∪ \{候选头\}G∪{候选头}被一起消融对数据集级安全表示造成的改变。
-
策略本质:贪心式前向选择——每次加入“当前增量伤害最大”的头。
-
组大小 SSS:由于 Ships 度量的是表示变化且计算成本较高,作者建议 SSS 较小(通常不超过 5),即可找出对 QHQ_HQH 安全性影响最显著的一组头。
-
4.3 HOW DOES SAFETY HEADS AFFECT SAFETY?
4.3.1 消融注意力头会显著削弱安全性
-
做法:作者用 4.1 节的广义 Ships在数据集层面找出“最能改变拒绝表示”的注意力头,然后对这些头做消融。
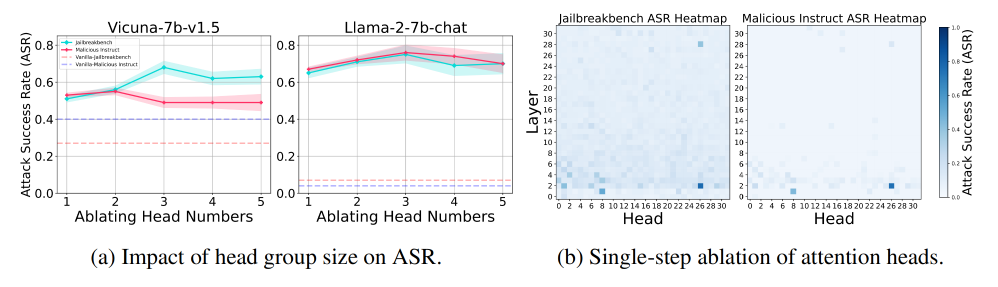
- 图a:
- 消融这些被识别的头会显著削弱模型的安全能力。
- 说明:广义Ships 能有效锁定真正的数据集级安全头(不是只对单一 query 起作用的偶然头)。
- 图b:
- 在 Jailbreakbench 与 Malicious Instruct 两个数据集上,用 Undifferentiated Attention 对所有头逐个消融,统计 ASR 变化。
- 显著提升 ASR 的头在两个数据集上是一致的,进一步证明这些头是“稳定的、安全关键的”。
- 图a:
4.3.2 头组大小的影响
- 方法:用 Sahara 寻找一个大小为 SSS 的“安全头组” GGG,逐步把能最大化表示变化(广义 Ships)的头加入。
- 结果
- 一般来说,较小的头组(通常大小为 3)会带来最大的安全能力削弱。
- 当继续扩大组的规模(S>3S > 3S>3)后,ASR 反而下降。
- 原因分析:
- 头移除过多会让模型输出无意义字符串,在其 ASR 评估框架中,这类“胡言乱语”被记为失败,因此 ASR下降。
- 这说明 定点、少量、关键头 的消融比大范围粗暴切除更能精准破坏安全而不直接把模型整体打垮。
4.3.3 安全头是稀疏的
- 现象:只有极少数头对安全至关重要,大多数头的消融对 ASR 几乎没影响。
- 具体例子:
- 在 Llama-2-7b-chat 中,head 2-26(第 2 层的第 26 个头)被识别为最关键的安全头之一。
- 单独消融就能显著削弱模型安全性。
- 意义:安全能力在注意力头上呈现高度稀疏且可定位的结构。
4.3.4 更细粒度地定位安全参数
- 论文方法的优势:
- 在获得相近 ASR的前提下,本方法把需要修改的参数比例从 5% 缩小到仅 0.018%(3 个头)
- Ships + Sahara 能在注意力头这一更细粒度上高精度定位安全参数,而不是动辄剪掉一大层或大块参数。
4.3.5 效率
-
问题:
- 在 安全评估场景下,必须做完整生成,否则无法可靠判断 ASR,这在大模型上计算成本极高。
-
论文结果:
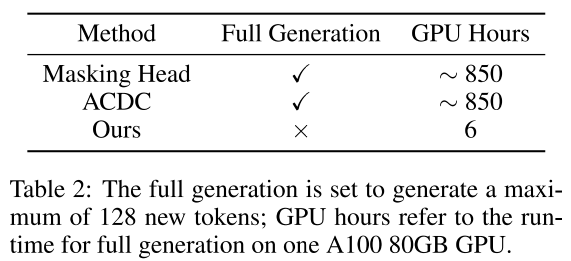
- 作者做了部分生成实验并估算推理时间,表明他们的方法(利用表达子空间的度量 + 启发式小规模迭代)显著降低了相较于逐头完整生成评估的计算开销。
- 核心点:
- 不用对每个头做全量文本生成、逐个计算全套下游指标;
- 通过 SVD + 主角度 在表示空间比较,大幅缩减评估成本。
5. AN IN-DEPTH ANALYSIS FOR SAFETY ATTENTION HEADS
5.1 Attention Weight 与 Attention Output 的差异
- 研究问题:对比第 3.1 节提出的两种消融方法,考察 WqW_qWq、WkW_kWk 和 WvW_vWv 在安全性中的不同作用。
- 发现:
- Undifferentiated Attention(修改 WqW_qWq 或 WkW_kWk,使注意力权重矩阵接近均匀)在数据集级和单查询级都会显著削弱安全能力。
- Scaling Contribution(缩放 WvW_vWv)对单一查询的影响更明显,但在数据集级影响有限。
- 原因:说明安全头的作用主要是 有效提取安全关键信息,而不是简单依赖输出缩放。
- 其他观察:
- 两种方法识别出的 Top-10 安全头几乎没有重合。
- Undifferentiated Attention 识别出的安全头在不同数据集更稳定,说明其更能代表真正的安全特征。
5.2 预训练对安全性的影响
- 结论:安全机制不仅来自对齐,预训练阶段对安全能力的形成起关键作用。
- 实验支持:
- 在 Malicious Instruct 数据集上,Llama-2-7b-chat 和 Vicuna-7b-v1.5 的安全头有显著重合,说明使用同一基础模型会出现相似的安全头。
- 用基础模型的注意力参数替换对齐模型的同类参数,模型仍能保持接近对齐模型的安全性,证明注意力头的安全特性主要由预训练塑造。
5.3 有用性与无害性权衡
- 问题:消融安全头会不会影响模型的有用性?
- 结果:
- 用 lm-eval 测试 Llama-2-7b-chat 在 BoolQ、RTE、WinoGrande、ARC Challenge、OpenBookQA 等零样本任务上的表现:
- 消融安全头几乎不影响模型的有用性,但安全性明显下降。
- 与 SparseGPT、Wanda 等剪枝方法相比,安全头消融对有用性的影响更小,尤其是 Undifferentiated Attention。
- 将安全头替换为所有头的均值权重,结论仍一致。
- 用 lm-eval 测试 Llama-2-7b-chat 在 BoolQ、RTE、WinoGrande、ARC Challenge、OpenBookQA 等零样本任务上的表现: