KNN 算法中的各种距离:从原理到应用
在机器学习领域,KNN(K - 近邻)算法以其直观易懂的特性占据着重要地位。它的核心思想是 “物以类聚”—— 通过计算待分类样本与已知样本之间的距离,选取距离最近的 K 个样本,再根据这 K 个样本的类别来判断待分类样本的类别。而距离的计算方式直接决定了 KNN 算法对 “相似性” 的判断标准,不同的距离度量适用于不同的数据场景。下面,我们就来详细了解 KNN 算法中常用的各种距离及其应用。
一、欧氏距离(Euclidean Distance)
欧氏距离是我们最熟悉的距离度量方式,源于几何学中两点间的直线距离概念,在二维平面或三维空间中有着直观的体现。
在 n 维空间中,假设有两个样本点 A(x₁,x₂,…,xₙ)和 B(y₁,y₂,…,yₙ),它们之间的欧氏距离计算公式为:
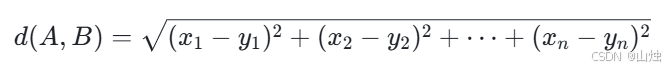
欧氏距离的优势在于计算简单、几何意义明确,适用于连续型数据,且数据各维度的量纲一致的场景。比如在人脸识别中,每个样本点的维度代表人脸的不同特征(如眼睛大小、鼻子长度等),这些特征通常具有相同的量纲,使用欧氏距离能较好地衡量两个人脸特征的相似性。
不过,欧氏距离也有明显的局限性。当数据各维度的量纲差异较大时,它会过分强调数值大的维度对距离的影响。例如,在分析一个人的身高(单位:厘米)和体重(单位:千克)时,身高的数值通常远大于体重,欧氏距离会更受身高差异的影响,而忽略体重差异的作用。此外,它对异常值比较敏感,一个极端的异常值可能会极大地改变距离的计算结果。
二、曼哈顿距离(Manhattan Distance)
曼哈顿距离又被称为城市街区距离,其名称源于美国纽约曼哈顿街区的布局 —— 在曼哈顿,人们从一个地点到另一个地点,通常需要沿着街道横竖行走,而不能直接走直线。
在 n 维空间中,样本点 A(x₁,x₂,…,xₙ)和 B(y₁,y₂,…,yₙ)之间的曼哈顿距离计算公式为:
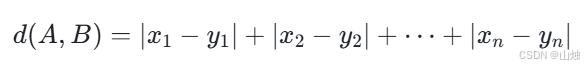
曼哈顿距离的特点是计算过程中只涉及绝对值运算,计算成本相对较低。它适用于数据维度存在明显 “网格状” 分布的场景,比如在地图上计算两个地点的实际行走距离(不考虑直线穿行),或者在推荐系统中,当用户的行为数据(如浏览时长、购买数量等)维度差异较大时,使用曼哈顿距离能减少量纲差异带来的影响。
与欧氏距离相比,曼哈顿距离对异常值的敏感度更低。因为它采用绝对值相加的形式,单个维度的极端值对整体距离的影响相对较小。但它丢失了欧氏距离中 “直线距离” 的几何意义,在需要衡量样本间整体相似程度的连续型数据场景中,效果可能不如欧氏距离。
三、切比雪夫距离(Chebyshev Distance)
切比雪夫距离刻画的是两个样本点在各维度上最大差异的绝对值,其灵感来源于国际象棋中王的走法 —— 王可以向任意方向走一步,从一个格子到另一个格子的最少步数就是切比雪夫距离。
在 n 维空间中,样本点 A(x₁,x₂,…,xₙ)和 B(y₁,y₂,…,yₙ)之间的切比雪夫距离计算公式为:
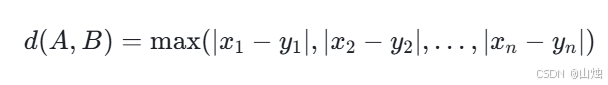
切比雪夫距离适用于关注样本在某一维度上最大差异的场景。例如在生产质量控制中,需要检测产品的多个指标(如尺寸、重量、硬度等),只要有一个指标超出标准范围,产品就被判定为不合格,此时用切比雪夫距离可以快速判断产品与标准样本的差异是否在可接受范围内。
该距离的优势是能够直接聚焦于最大差异的维度,但也正因如此,它忽略了其他维度的差异信息,在需要综合考虑多个维度相似性的场景中并不适用。
四、余弦距离(Cosine Distance)
余弦距离并非严格意义上的距离,而是通过计算两个向量的夹角余弦值来衡量它们的方向相似性。当两个向量的方向越接近,余弦值越接近 1;方向完全相反时,余弦值为 - 1;垂直时,余弦值为 0。
在 n 维空间中,样本点 A(x₁,x₂,…,xₙ)和 B(y₁,y₂,…,yₙ)对应的向量的余弦相似度计算公式为:
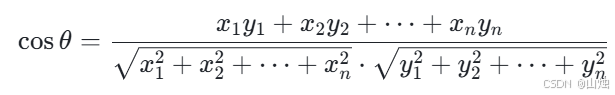
而余弦距离则可以表示为:
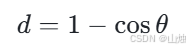
余弦距离适用于关注样本方向相似性而非数值大小的场景。在文本分类中,每个文本被转化为一个词向量,向量的维度代表不同的词语,数值代表词语出现的频率。此时,我们更关心两个文本谈论的主题是否相似(即向量方向是否一致),而不是词语出现频率的绝对大小,余弦距离就能够很好地满足这一需求。
但余弦距离没有考虑向量的模长差异,当需要关注样本数值大小差异时,它就不再适用。例如在衡量两个商品的销量特征时,销量的绝对大小很重要,此时使用欧氏距离会更合适。
五、闵可夫斯基距离(Minkowski Distance)
闵可夫斯基距离是一种更具一般性的距离度量方式,它可以看作是欧氏距离、曼哈顿距离的推广。
其计算公式为:
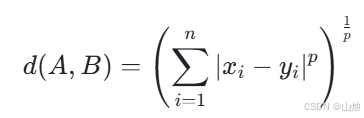
其中,p 是一个参数。当 p=1 时,闵可夫斯基距离就变成了曼哈顿距离;当 p=2 时,它就等同于欧氏距离;当 p 趋近于无穷大时,它则趋近于切比雪夫距离。
闵可夫斯基距离的灵活性在于可以通过调整参数 p 来适应不同的场景,但它同样继承了欧氏距离和曼哈顿距离的一些局限性,比如对量纲敏感、没有考虑维度之间的相关性等,因此在使用时需要结合具体数据特点选择合适的 p 值。
六、汉明距离(Hamming Distance)
汉明距离主要用于衡量两个等长字符串之间的差异,它的定义是:将一个字符串转换为另一个字符串所需替换的字符个数。在 KNN 算法中,当处理离散型数据(尤其是二进制数据) 时,汉明距离是常用的度量方式。
例如,对于两个二进制样本点 A(0,1,0,1)和 B(0,0,1,1),它们的汉明距离为 2—— 因为需要将 A 中的第二个字符 “1” 替换为 “0”,第三个字符 “0” 替换为 “1” 才能得到 B。
汉明距离的优势在于对离散特征的适配性,比如在图像识别中,当图像被转化为二进制特征向量(如 “有边缘” 记为 1,“无边缘” 记为 0)时,汉明距离可以有效衡量两个图像特征的差异。但它仅适用于等长的离散数据,对连续型数据或长度不等的字符串并不适用。
七、马氏距离(Mahalanobis Distance)
马氏距离是一种考虑数据分布特性的距离度量,它解决了欧氏距离对量纲和维度相关性敏感的问题。其核心思想是:先将数据投影到一个新的空间,消除维度之间的相关性,再进行距离计算。
在 n 维空间中,若样本集的协方差矩阵为 Σ(可逆矩阵),样本点 A 和 B 之间的马氏距离计算公式为:
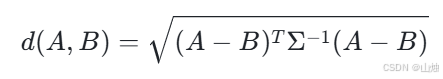
马氏距离的最大优势是不受量纲影响(因为它通过协方差矩阵消除了维度尺度差异),且能处理维度之间的相关性。例如,在分析身高(厘米)和体重(千克)时,两者存在明显的相关性(身高越高通常体重越大),马氏距离会先消除这种相关性,再计算距离,结果更合理。
但马氏距离的计算需要样本集的协方差矩阵,当样本量较小时,协方差矩阵的估计可能不准确,会影响距离的可靠性。因此,它更适用于样本量较大、维度存在相关性的场景。
八、标准化欧氏距离(Standardized Euclidean Distance)
标准化欧氏距离是对欧氏距离的改进,它通过对数据进行标准化处理(消除量纲影响),解决了欧氏距离对量纲敏感的问题。
其计算步骤分为两步:
1.对每个维度的数据进行标准化:

(其中 μᵢ为第 i 维的均值,σᵢ为第 i 维的标准差);
2.对标准化后的样本点计算欧氏距离。
例如,在身高(均值 160cm,标准差 10cm)和体重(均值 60kg,标准差 5kg)的例子中,样本 A(170cm,65kg)标准化后为(1,1),样本 B(160cm,60kg)标准化后为(0,0),两者的标准化欧氏距离为√2,避免了身高数值(厘米)对距离的过度影响。
标准化欧氏距离适用于各维度量纲差异大但维度间相关性较低的场景,它保留了欧氏距离的几何意义,同时消除了量纲干扰。但它没有考虑维度之间的相关性,若数据维度存在强相关,马氏距离会是更好的选择。
九、距离选择的原则与总结
在 KNN 算法中,选择合适的距离度量方式需要综合考虑数据的特性:
- 若数据是连续型且各维度量纲一致、相关性低,优先考虑欧氏距离;
- 若数据维度量纲差异大但相关性低,可使用标准化欧氏距离;
- 若数据维度量纲差异大或存在网格状分布,可尝试曼哈顿距离;
- 若关注样本方向相似性而非数值大小,余弦距离是更好的选择;
- 若需关注最大维度差异,切比雪夫距离更为合适;
- 若处理离散型(尤其是二进制)数据,汉明距离更适配;
- 若数据维度存在相关性且样本量较大,马氏距离更合理;
- 闵可夫斯基距离则可通过调整参数 p 来模拟其他距离,适合需要灵活调整的场景。
总之,距离度量是 KNN 算法的核心,每一种距离都有其独特的适用场景和优缺点。在实际应用中,我们需要深入了解数据的特点(如连续 / 离散、量纲是否一致、维度是否相关等),通过实验对比不同距离下算法的性能(如分类准确率),才能选出最适合的距离度量方式,让 KNN 算法发挥出最佳效果。