【AI论文】Franca:用于可扩展视觉表示学习的嵌套套娃聚类
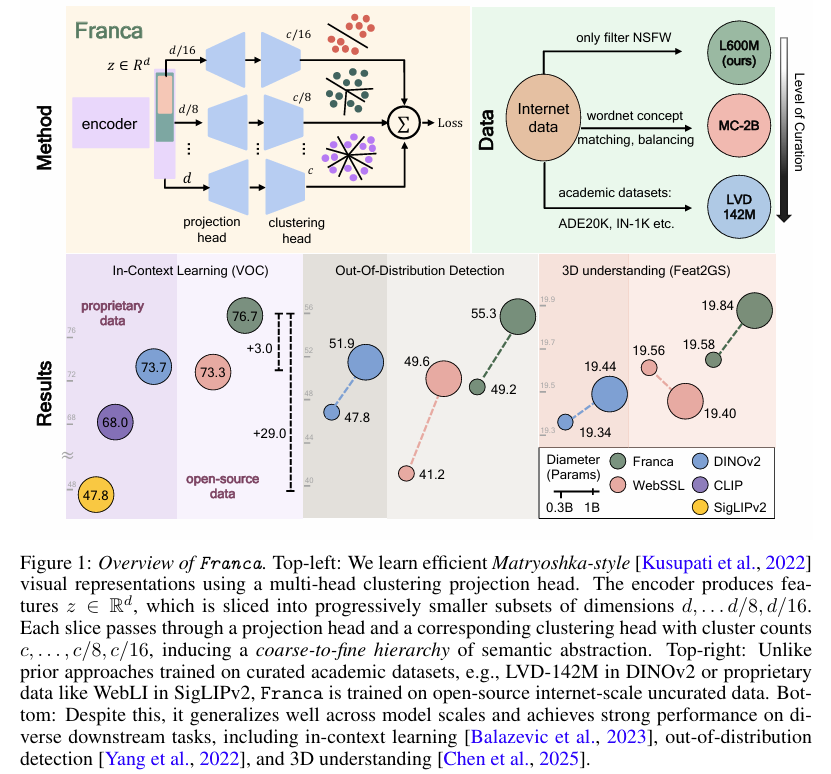
摘要:我们推出Franca(发音为“Fran-ka”):一款免费开源的视觉基础模型(在数据、代码、权重层面均完全开源),其性能在众多场景中可媲美甚至超越当前最先进的专有模型,例如DINOv2、CLIP、SigLIPv2等。我们的方法基于受Web-SSL启发的透明训练流程,并采用公开数据集:ImageNet-21K和ReLAION-2B的子集。除发布模型外,我们还着力解决了自监督学习(SSL)聚类方法中的关键局限性。尽管现代模型依赖诸如Sinkhorn-Knopp等聚类算法将图像特征分配至大型码本,但这些方法未能充分考虑聚类语义中固有的模糊性。为解决这一问题,我们提出了一种基于嵌套套娃表示的参数高效型多头聚类投影器。该设计通过渐进式优化,将特征细化为更精细的聚类,且无需增加模型规模,从而兼顾性能与内存效率。此外,我们提出了一种新颖的位置解耦策略,可显式消除密集表示中的位置偏差,进而提升语义内容的编码质量。实验表明,该方法在多个下游基准测试中均取得了一致的性能提升,验证了更纯净特征空间的有效性。我们的贡献为透明、高性能的视觉模型树立了新标杆,并为构建更具可复现性和泛化能力的基础模型开辟了新路径,以造福更广泛的AI社区。代码与模型检查点已开源,详见:Github。Huggingface链接:Paper page,论文链接:2507.14137
一、研究背景和目的
研究背景
随着人工智能技术的快速发展,视觉基础模型(Vision Foundation Models, VFMs)在计算机视觉领域中扮演着越来越重要的角色。这些模型不仅在传统的图像分类、目标检测等任务中取得了显著成效,还为3D理解、多模态大语言模型(LLMs)等复杂系统提供了关键支撑。然而,当前最先进的视觉基础模型,如DINOv2、SEER、MAE和SigLIPv2等,往往依赖于专有数据集进行训练,导致模型的可复现性、可访问性和科学进步受到严重限制。此外,这些模型在训练过程中使用的聚类方法也面临着语义模糊性、空间位置偏差等挑战,影响了模型的泛化能力和性能。
研究目的
本研究旨在开发一个完全开源的视觉基础模型Franca,该模型不仅在数据、代码和权重上完全开放,而且在性能上能够媲美甚至超越现有的专有模型。具体目标包括:
- 解决现有模型的局限性:通过引入新的聚类方法和训练策略,解决现有模型在聚类语义模糊性、空间位置偏差等方面的问题。
- 提高模型的泛化能力:通过在大规模公开数据集上进行训练,使模型能够在不同的下游任务中表现出色。
- 推动视觉基础模型的透明度和可复现性:通过公开所有训练细节和模型权重,促进科学研究的进步和社区的发展。
二、研究方法
数据集选择
Franca模型在ImageNet-21K和ReLAION-2B的子集上进行预训练。ImageNet-21K是一个包含约1310万张高质量图像的大型数据集,覆盖了21,841个类别。ReLAION-2B则是一个更大规模的图像数据集,为模型提供了更广泛的视觉覆盖。
模型架构
Franca采用了基于Vision Transformer(ViT)的架构,包括ViT-B、ViT-L和ViT-G三种不同规模的模型,分别具有86M、300M和1.1B个参数。模型的核心创新点包括:
- 嵌套套娃聚类(Matryoshka Clustering):引入了一种参数高效的多头聚类投影器,通过嵌套的Matryoshka表示法,将特征逐步细化为不同粒度的聚类,而无需增加模型大小。
- 循环掩码策略(CyclicMask):通过循环移动掩码位置,确保所有图像块在训练过程中获得均匀的曝光,从而减少空间位置偏差。
- 位置解耦策略(RASA):通过学习并移除特征中的位置信息,提高模型对语义内容的编码能力。
训练策略
- 多头聚类损失:在ViT骨干网络的每个子空间上应用独立的投影头和聚类头,鼓励不同粒度的特征专业化。
- 高分辨率微调:在较高分辨率(518x518)下对模型进行微调,进一步提高性能。
- 大规模自监督预训练:在ImageNet-21K和LAION-600M数据集上进行大规模自监督预训练,无需任何人工标注。
三、研究结果
图像分类
在ImageNet-1K、ImageNet-ReaL和ImageNet-v2等基准测试中,Franca模型展示了与DINOv2相当甚至更优的性能。特别是在ImageNet-v2上,Franca-G模型达到了85.9%的top-1准确率,与Web-SSL-7B相当,但使用了更少的数据和参数。
鲁棒性和泛化能力
Franca在多种自然分布偏移测试中表现出色,如在ImageNet-A、ImageNet-R和Sketch等数据集上,Franca-G模型在多个模型规模上均优于DINOv2和OpenCLIP-G。
密集预测任务
- 上下文学习:在Hummingbird基准测试中,Franca在Pascal VOC和ADE20K数据集上实现了较高的mIoU(平均交并比),尤其是在ViT-G/14规模上,超过了DINOv2-G和WebSSL。
- 线性分割:在COCO-Stuff、Pascal VOC和ADE20K数据集上,Franca在所有模型规模上均表现出色,特别是在ViT-G/14规模上,达到了最高的mIoU。
- 过度聚类:在无监督设置下,Franca在Pascal VOC和COCO-Things数据集上实现了较高的mIoU,表明其能够生成更精细和语义一致的伪分割。
3D理解
- 关键点匹配:在SPair-71K数据集上,Franca在ViT-L和ViT-G规模上均优于DINOv2,表明其在几何变形下的对应关系更准确。
- 单目深度估计:在NYUv2数据集上,Franca实现了较低的SI-RMSE(尺度不变均方根误差),表明其对3D结构的理解更好。
- Feat2GS评估:在几何和纹理评估中,Franca在多个数据集上均优于其他先进模型,表明其具有更强的3D几何感知能力。
四、研究局限
数据依赖性问题
尽管Franca在公开数据集上取得了显著成效,但其性能仍受到训练数据规模和多样性的限制。未来研究可以探索如何利用更多样化和大规模的数据集进一步提升模型性能。
模型复杂度与效率平衡
虽然Franca通过嵌套聚类和多头设计提高了参数效率,但在处理极大规模数据集或极高分辨率图像时,模型的计算复杂度和内存需求仍然较高。未来研究可以探索更高效的算法和硬件加速技术,以进一步降低计算成本。
特定任务适应性
尽管Franca在多个下游任务中表现出色,但在某些特定任务(如细粒度图像分类、特定场景下的目标检测)中可能仍需进一步微调。未来研究可以探索更通用的特征表示学习方法,以提高模型对不同任务的适应性。
五、未来研究方向
扩大数据集规模和多样性
未来可以进一步收集和整理更多样化和大规模的图像数据集,特别是那些包含丰富语义信息和复杂场景的数据集。这将有助于提升模型的泛化能力和鲁棒性。
优化模型架构和训练策略
可以探索更高效的模型架构和训练策略,如引入注意力机制、改进损失函数等。同时,可以利用迁移学习和领域适应技术,使模型能够更好地适应不同场景和任务的需求。
增强模型的可解释性和鲁棒性
深入研究视觉基础模型的可解释性和鲁棒性,提高模型在复杂环境下的稳定性和可靠性。这将有助于推动视觉基础模型在更多实际应用场景中的落地。
推动多模态学习的发展
结合文本、语音等其他模态的信息,构建更强大的多模态基础模型。这将有助于实现更全面的场景理解和更智能的人机交互。
推动开源社区和标准化建设
通过开源代码和模型权重,促进学术界和工业界的合作与交流。同时,推动建立统一的评估标准和测试基准,促进视觉基础模型的健康发展。