博客多级评论展示功能实现
最近在看《Python基础教程(第三版)》。作者提出的编程方法挺适合我的,先写一个能跑的程序,再去谈优化。就算是一坨屎,也得先拉出来。我的感受是,在写的过程中帮助理清了思路,从而才能知道该怎么去优化。
早上突然想起了以前室友面试被问的一个问题“你如何实现一个评论展示的功能”,发现自己并不是很清楚,于是尝试写写。眼过千遍,不如手过一遍。
该功能的实现,我觉得最重要的其实是数据库的设计。
建表语句如下,article_comment中的article_id指向了被评论的文章,parent_id指向了父评论。
CREATE TABLE `article` (`article_id` int NOT NULL AUTO_INCREMENT,`author_id` int NOT NULL,`content` text,`create_time` datetime DEFAULT CURRENT_TIMESTAMP,PRIMARY KEY (`article_id`)
);CREATE TABLE `article_comment` (`comment_id` int NOT NULL AUTO_INCREMENT,`article_id` int DEFAULT NULL,`user_id` int DEFAULT NULL,`parent_id` int DEFAULT NULL,`level` int DEFAULT NULL,`create_time` datetime DEFAULT CURRENT_TIMESTAMP,`content` text,PRIMARY KEY (`comment_id`)
);python代码实现如下,主要思路:先根据article_id查出该文章下面的所有评论,然后根据parent_id将评论组装为树形结构。
import json
from contextlib import contextmanager
from dataclasses import dataclassimport uvicorn
from fastapi import FastAPI
from sqlalchemy import create_engine, Column, Integer, String, DateTime, select
from sqlalchemy.orm import DeclarativeBase, sessionmaker, Session, declarative_baseengin = create_engine(url="mysql+pymysql://root:123456@localhost/test",pool_size=10,max_overflow=10,echo = True
)Base = declarative_base()class Article(Base):__tablename__ = 'article'article_id = Column(Integer, primary_key=True)author_id = Column(Integer)content = Column(String)create_time = Column(DateTime)class ArticleComment(Base):__tablename__ = 'article_comment'comment_id = Column(Integer, primary_key=True)article_id = Column(Integer)user_id = Column(Integer)parent_id = Column(Integer)level = Column(Integer)content = Column(String)create_time = Column(DateTime)@contextmanager
def get_db_session():session_maker = sessionmaker(engin)with session_maker() as session:yield sessiondef get_article():with get_db_session() as session:stmt = select(Article).where(Article.article_id == 1)result = session.execute(stmt)# 输出的是对象模式,不是我要的json格式print(result.scalars().first())class CommentNode:def __init__(self, article_comment : ArticleComment):self.comment = article_commentself.children : list[CommentNode] = []def get_comments_tree(id : int):with get_db_session() as session:stmt = select(ArticleComment).where(ArticleComment.article_id == id)all_comment = session.execute(stmt).scalars().all()commentnode_list = [CommentNode(comment) for comment in all_comment]top_comments = []for commentnode in commentnode_list:# 如果评论的parent_id为空,说明该评论是一级评论if not commentnode.comment.parent_id:top_comments.append(commentnode)else:# 找到父节点father_commentnode = find_father_commentnode(commentnode, commentnode_list)# 加入父节点的子节点列表father_commentnode.children.append(commentnode)return top_commentsdef find_father_commentnode(input_commentnode : CommentNode, all_commentnode : list[CommentNode]):for commentnode in all_commentnode:if input_commentnode.comment.parent_id == commentnode.comment.comment_id:return commentnodereturn Noneapp = FastAPI()
@app.get("/")
async def get():return get_comments_tree(1)
uvicorn.run(app)数据库数据如下所示:
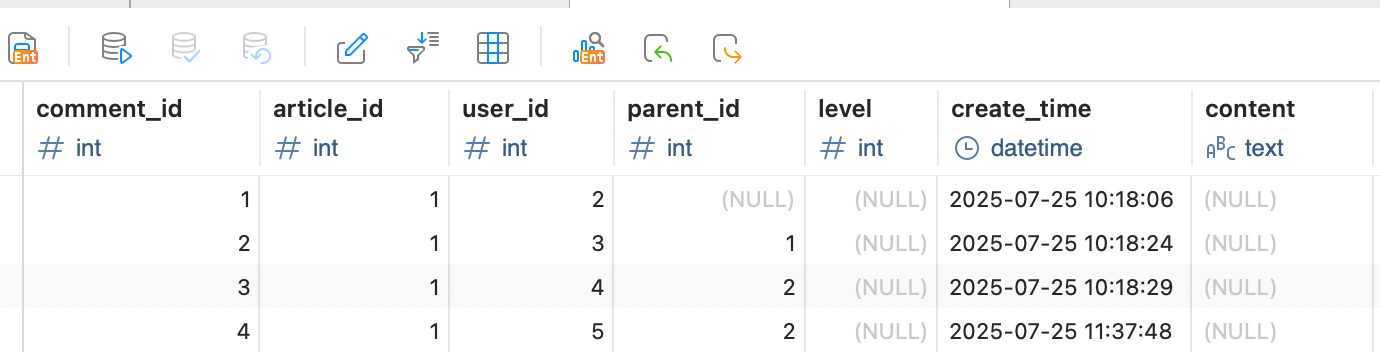
结果如下:
[{"comment": {"parent_id": null,"comment_id": 1,"content": null,"level": null,"article_id": 1,"user_id": 2,"create_time": "2025-07-25T10:18:06"},"children": [{"comment": {"parent_id": 1,"comment_id": 2,"content": null,"level": null,"article_id": 1,"user_id": 3,"create_time": "2025-07-25T10:18:24"},"children": [{"comment": {"parent_id": 2,"comment_id": 3,"content": null,"level": null,"article_id": 1,"user_id": 4,"create_time": "2025-07-25T10:18:29"},"children": []}, {"comment": {"parent_id": 2,"comment_id": 4,"content": null,"level": null,"article_id": 1,"user_id": 5,"create_time": "2025-07-25T11:37:48"},"children": []}]}]
}]还值得优化的地方:
1. 当文章评论很多的时候,查出全部评论会占用大量内存,可以分页查询
2.遍历所有评论寻找父评论的时间为o(n),可以用hash表降到o(1)