Deep learning--模型压缩的五种方法
一 Network Pruning(网络剪枝)
思路来源,在模型中有许多参数,有些参数可能对模型的输出正确率影响很小,这时我们可以尝试去掉。
做法:
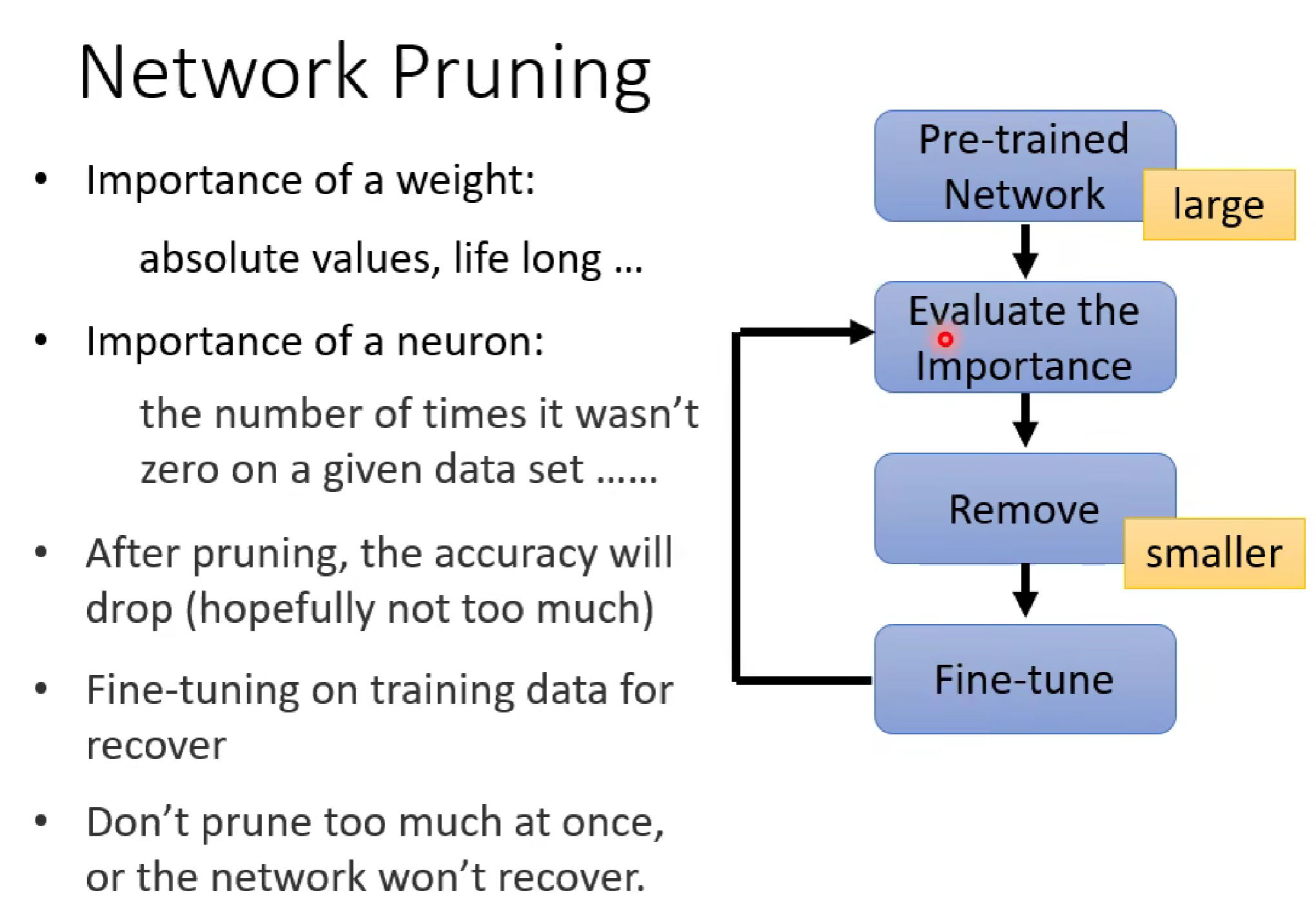
如上图,我们首先将训练的大模型进行相关参数的评估,去除相关参数/神经元(剪枝) ,这是模型的正确率肯定会下降,所以我们下一步就是对剪枝后的demo进行再训练,调整demo相关参数值,使得减小后的模型也能保持较高的正确率。之后也可以再重复上述操作。
剪枝参数的问题:
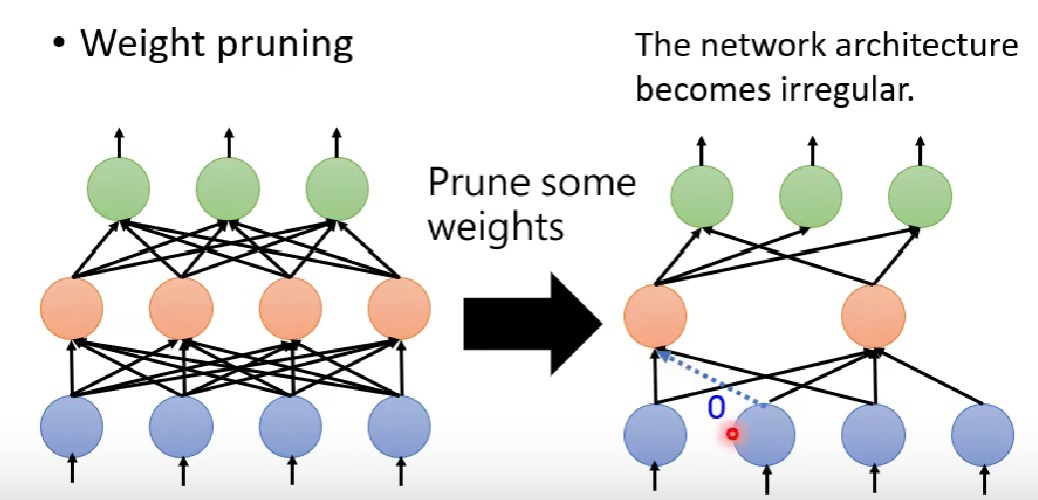
在模型剪枝中,我们一般不采取剪枝参数的形式,一方面,剪枝后的模型变得没有规律(如下图,有些删去参数后没有连接),在使用pytorch架构时难以编写代码;另一方面,不规律导致矩阵不规律,难以很好利用GPU进行硬件矩阵计算加速。
二,模型蒸馏
知识蒸馏(Knowledge Distillation) 是一种模型压缩与知识迁移技术,核心是让一个轻量型的 “学生模型” 学习一个复杂的 “教师模型” 所掌握的知识,从而在保证性能接近的同时,大幅减小模型规模和计算成本。
知识蒸馏的核心思想是通过让小型模型(学生模型)学习大型模型(教师模型)的输出(核心!!!),从而实现知识的迁移。教师模型通常是一个复杂且性能优异的模型,而学生模型则是一个更轻量级的模型。通过模仿教师模型的输出分布,学生模型能够在保持较高性能的同时,减少计算资源和存储需求
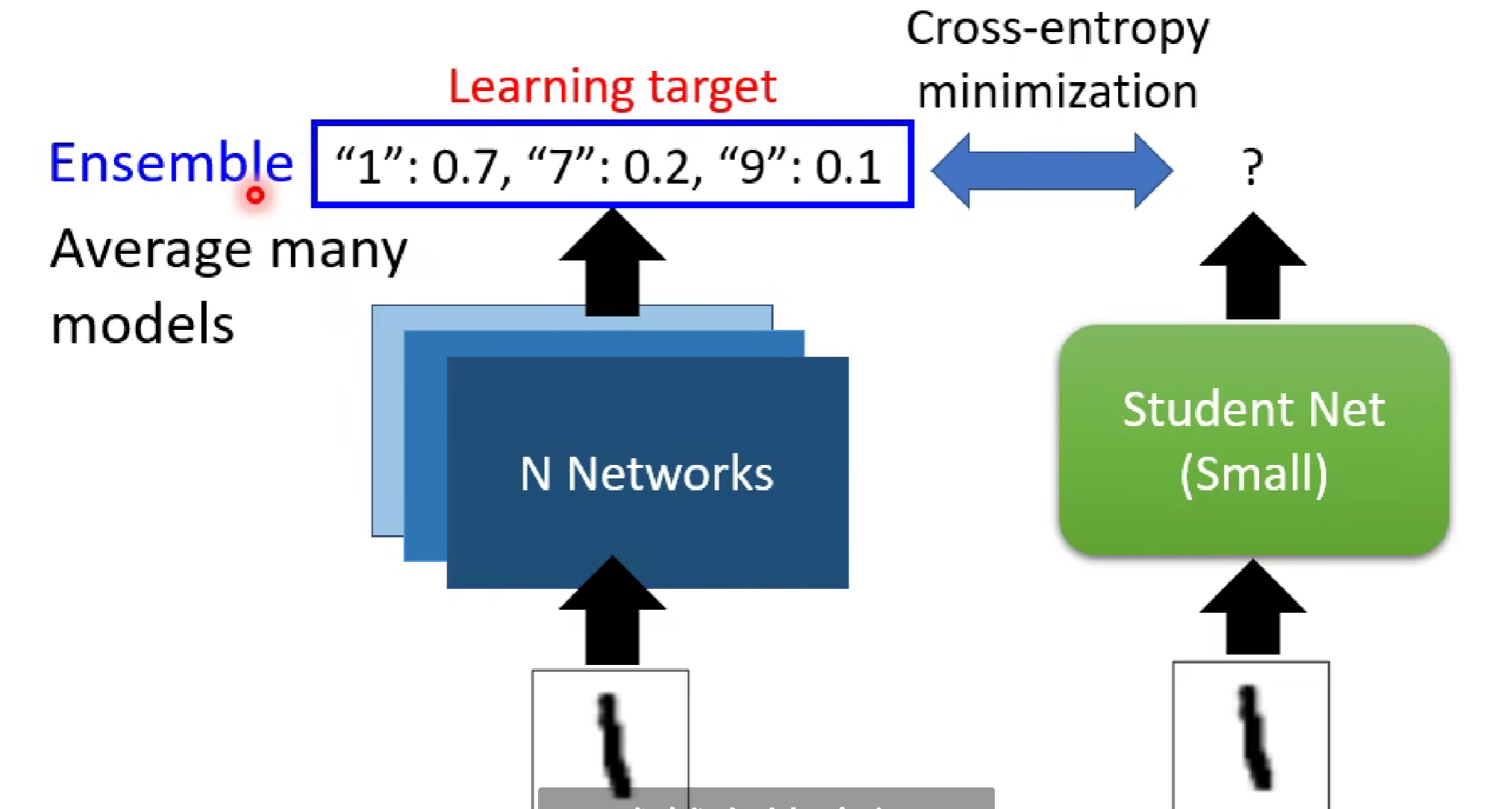
如图,在识别数字方面,我们先让教师模型进行训练, 在识别1这个任务中,教师模型输出了各种数字识别的概率,而学生模型不采取通过模型训练来学习数字一的识别,而是直接学习教师模型的输出分布概率。
关于知识蒸馏的一些操作:
(1)首先讲一下软标签与硬标签
硬标签:传统分类任务中,模型通过softmax函数输出的二进制标签(如[1, 0, 0]表示样本属于某一类别),这类输出虽然能够直接进行分类,但是不能表达出不同输出直接的联系(相似程度等信息)。
软标签:教师模型输出的概率分布(如[0.7, 0.2, 0.1]),不仅包含类别信息,还包含类别间的相似性和不确定性。软标签为模型提供了更丰富的学习信息.软标签提供了类别间的相似性信息,帮助学生模型更好地泛化,减少过拟合
(2)在知识蒸馏中,因为学生模型是学习教师模型的输出,学生模型不仅使用真实标签(硬标签),还要使用教师模型的软标签作为额外的监督信号,学习教师模型的输出分布,使其尽可能接近教师模型的行为。我们会对softmax函数进行改进,使其能够学习输出之间的关系。
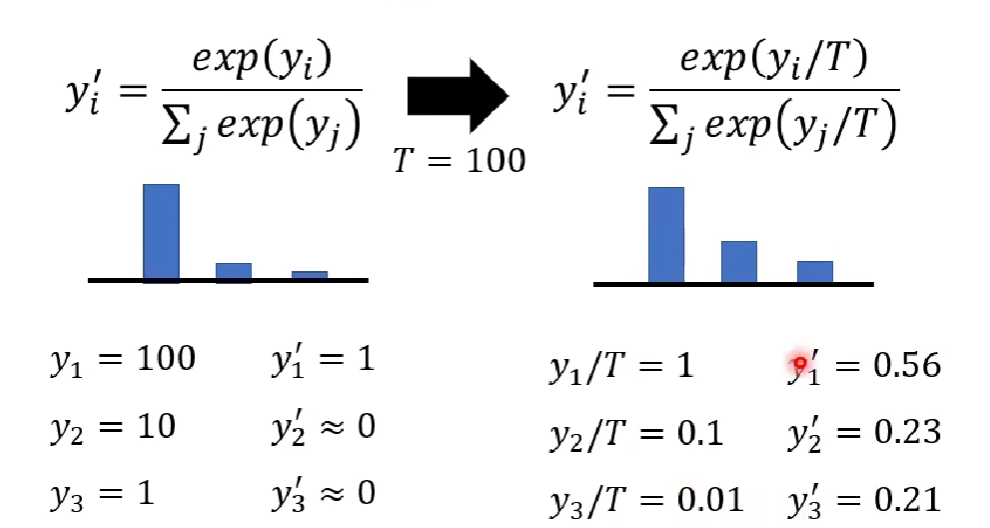
三,模型量化
模型量化是一种压缩机器学习模型大小并提高其运行速度的技术,主要通过减少模型中数值(如权重、激活值)的精度来实现。
主要 有三种方法:
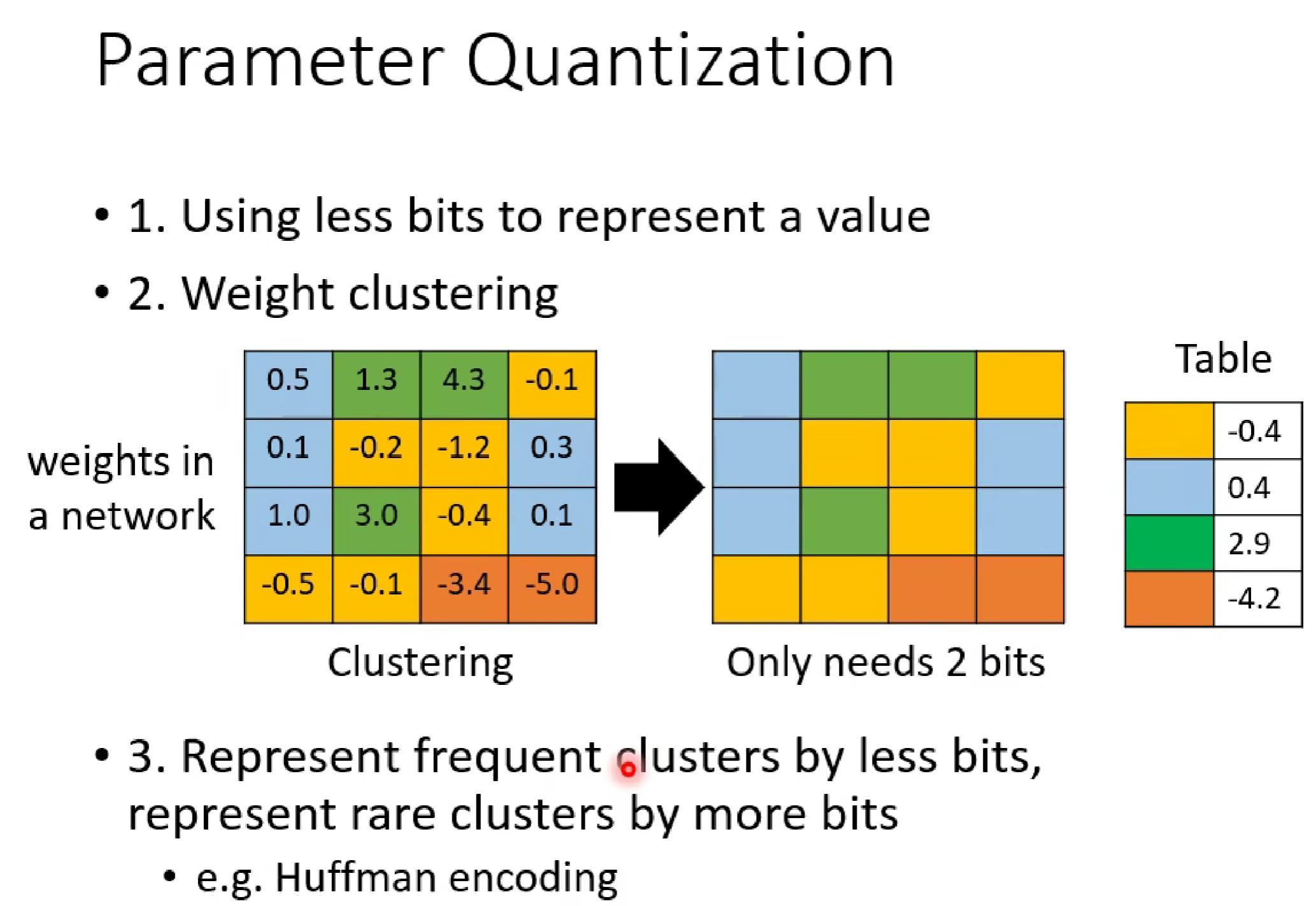
四,Architecture Design(结构设计)
Architecture Design通常指的是通过设计更高效的网络结构来减少模型的大小、计算量或加速推理过程,同时尽量保持或接近原始高精度模型的性能。它不是在已有模型上做修改,而是从头设计或优化模型架构本身。
在CNN中,我们便采用了深度可分离卷积(Depthwise Separable Convolution)的设计理念来压缩模型。
这里需要回顾CNN知识。链接呈上哈哈:CNN(卷积神经网络)--李宏毅deep-learning(起飞!!)-CSDN博客
在传统的CNN里面,我们进行卷积时,每个filter进行卷积时都要对图像的所有通道进行同时卷积。
如退,假如图片的通道数为2,那么每一个filter的通道数也要是2,这样才能对二通道的图像进行卷积,图中用了4个filter,所以最后生成4通道的feature map.
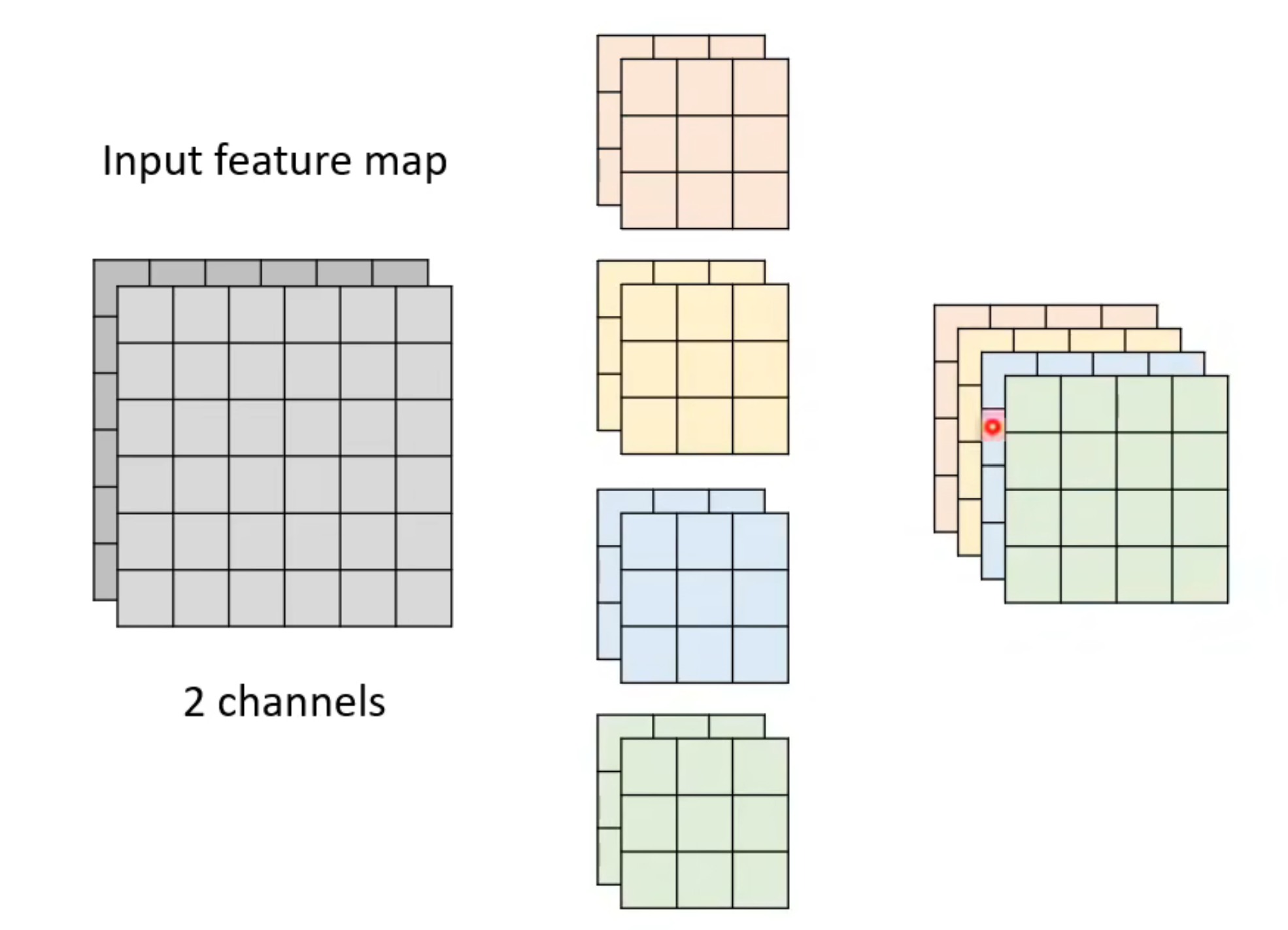
而通过图像我们可以知道,生成这个4通道的feature map需要3*3*2*4个参数。能不能降低参数但同时保证功能不变呢?
为此,我们便提出了深度可分离卷积(Depthwise Separable Convolution)。
简单来说,深度可分离卷积是一种将标准的卷积操作分解为两个更简单、更高效的操作的技术:深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)
首先是深度卷积:
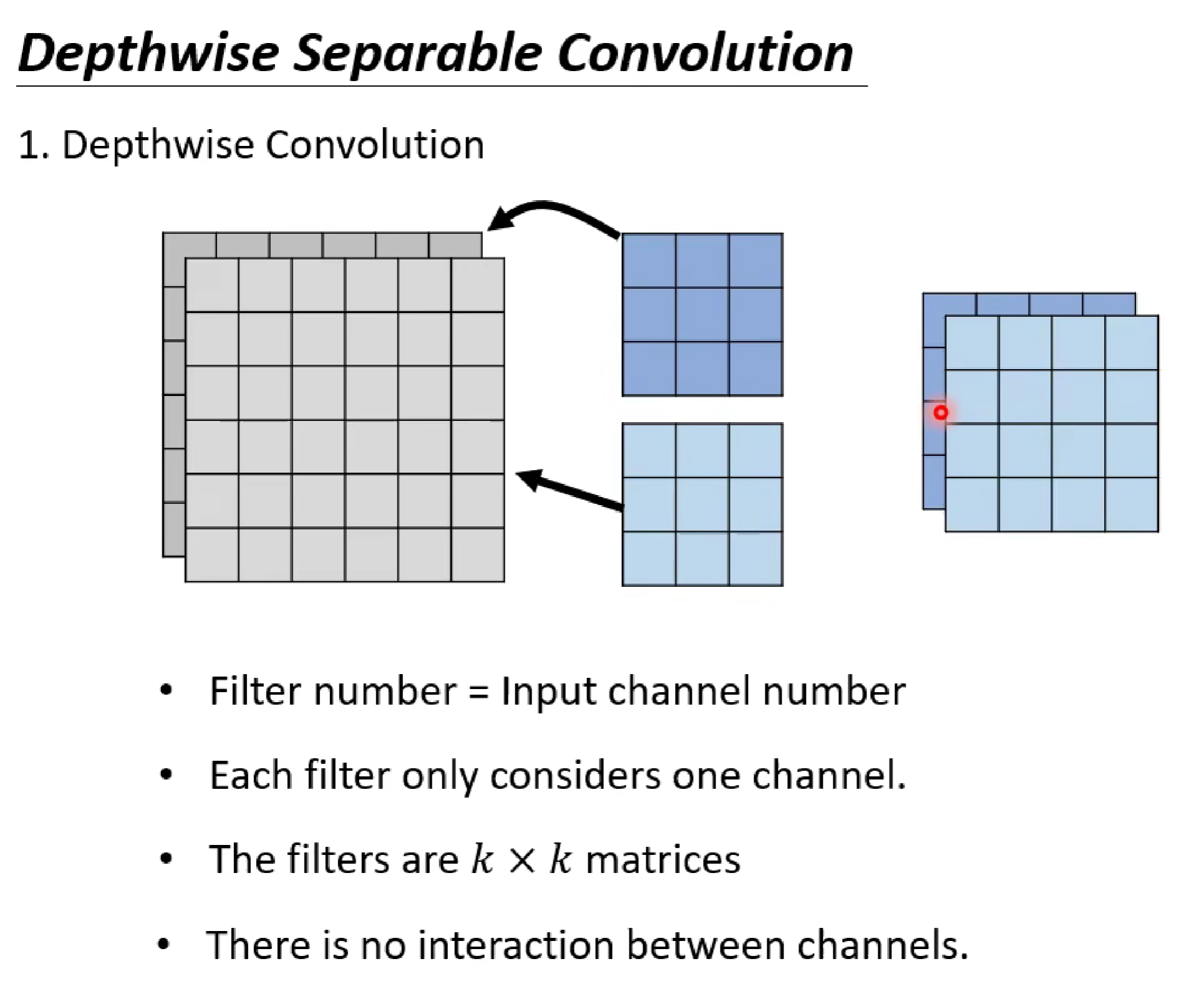
这里的操作是我们每个filter在进行卷积操作时,不需要对所有通道进行同时卷积,而是只需要卷积一层。这样子的话,图片有几个channel就有几个filtter,每个filtter卷积一个channel。
对于这一步,有几层channel就需要几个filtter
深度卷积获取的是每一层内部的信息。
接着是逐点卷积(Pointwise Convolution),该卷积时为了获取channel之间的关系信息。
该步骤和传统卷积思路一致
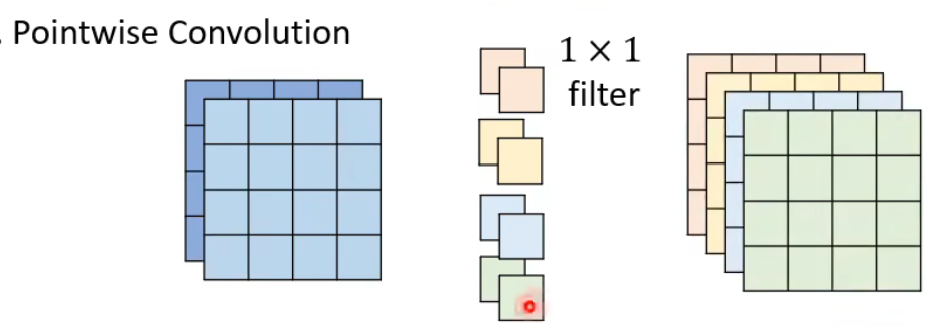
在之前的传统卷积例子中,我们用4个filter来获取不同的特征信息,这里也是用4个,不过此步骤强制使用1*1的卷积核。图片 为2channel,那么每个filter也是2channel。卷积之后即可获得4通道的feature map.
现在,让我们来计算两个小步骤需要的总参数量,在第一个步骤中,需要2*3*3=18,在第二个步骤中,需要1*1*2*4=8。
也就是说,如下图:
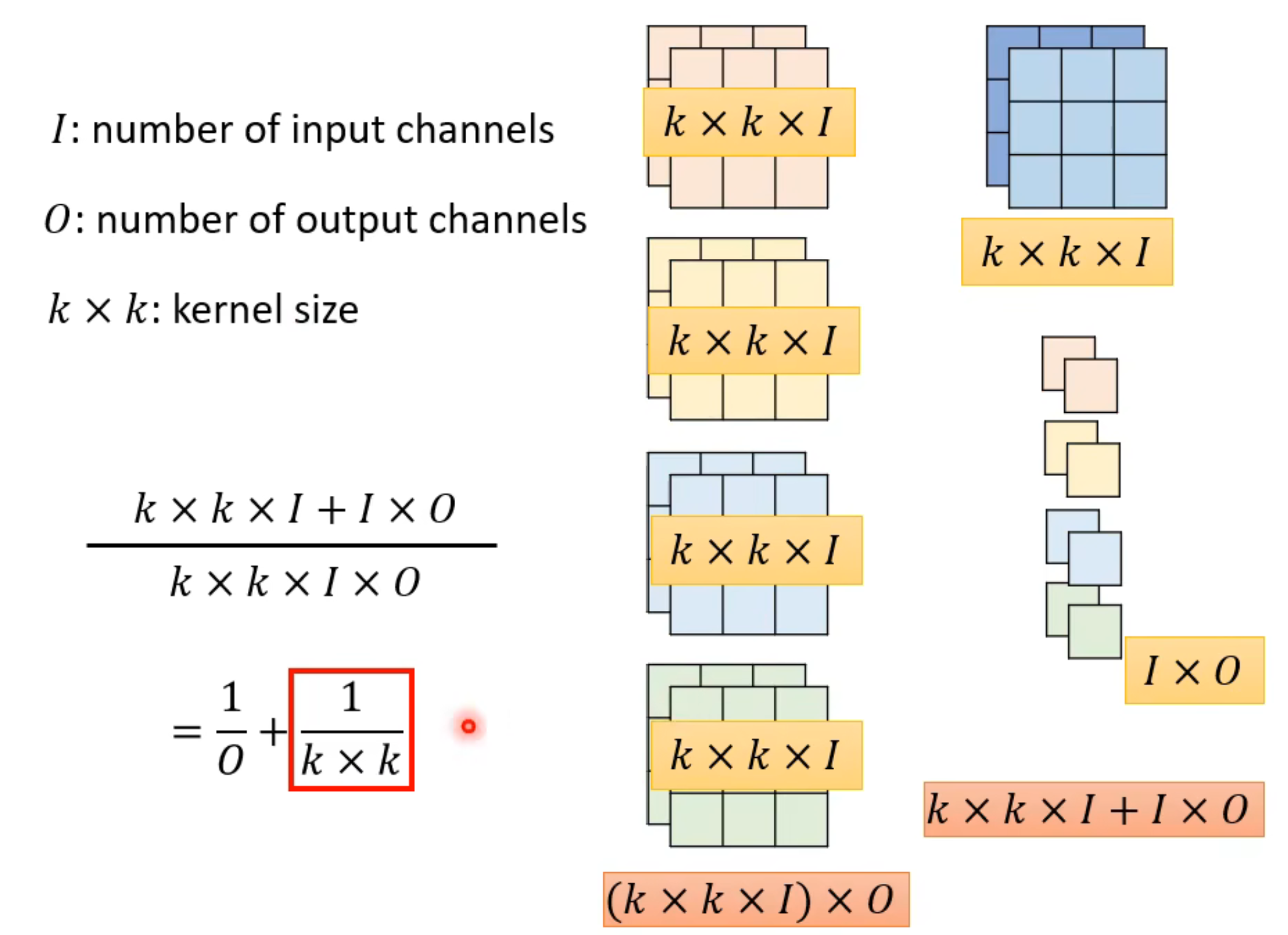
这个传统卷积的k*k*l*O就是我们上述例子的3*3(卷积核数) *2(通道数)*4(需要输出的特征通道数),而分离卷积的k*k*I +I*O就是3*3(卷积核数)*2(通道数)+1*1(卷积核数)*2(通道数)*4(需要输出的特征通道数)。很明显,需要的参数减小了
五,Dynamic Computation (动态计算)
当面对不同的运算资源或者不同难度的任务需求时,我们需要调整不同的计算,来保证有效的输出和高效的利用运算资源。利用动态计算,可以在模型运行时根据输入数据或当前计算状态,动态地决定哪些连接(剪枝)或哪些参数(量化)需要被移除或降低精度。
操作类别有:
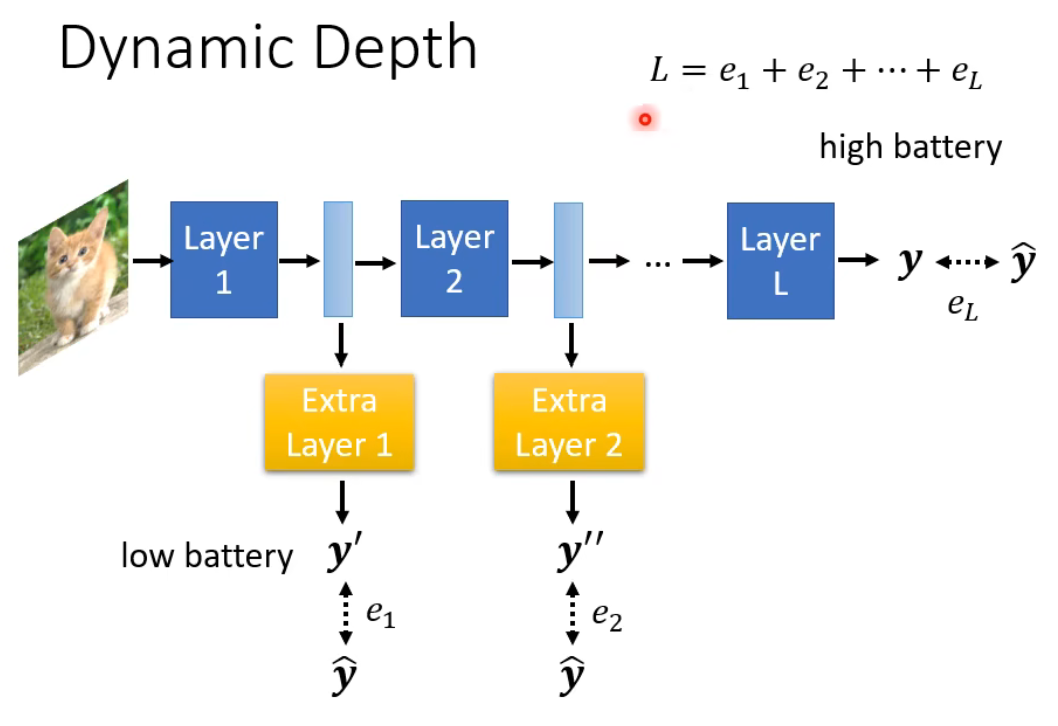
(1)动态调整模型深度
(2) 动态调整模型宽度
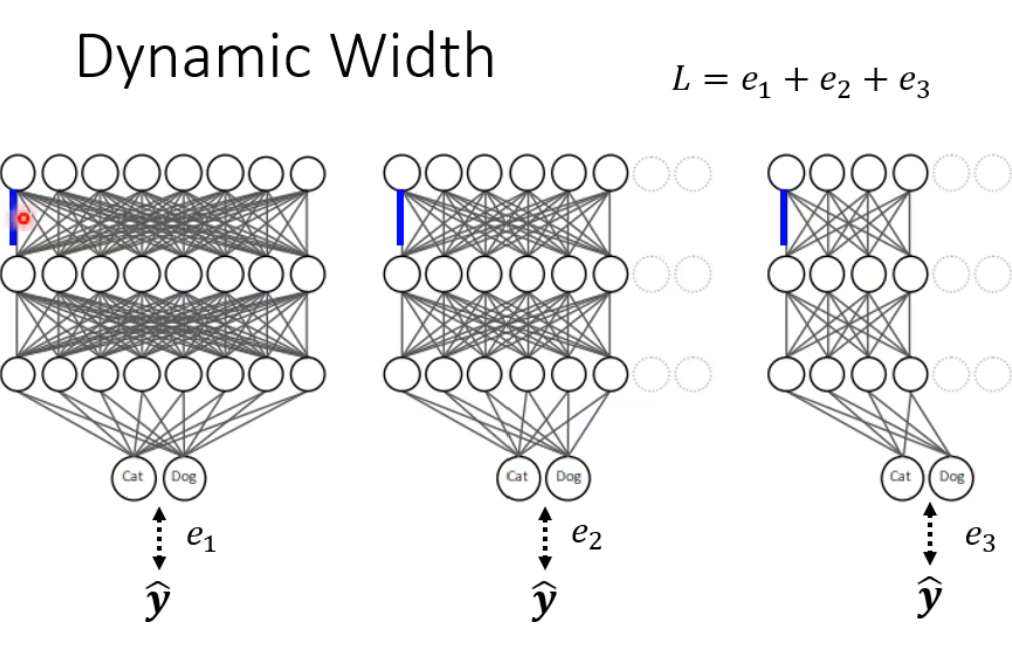
比如说:
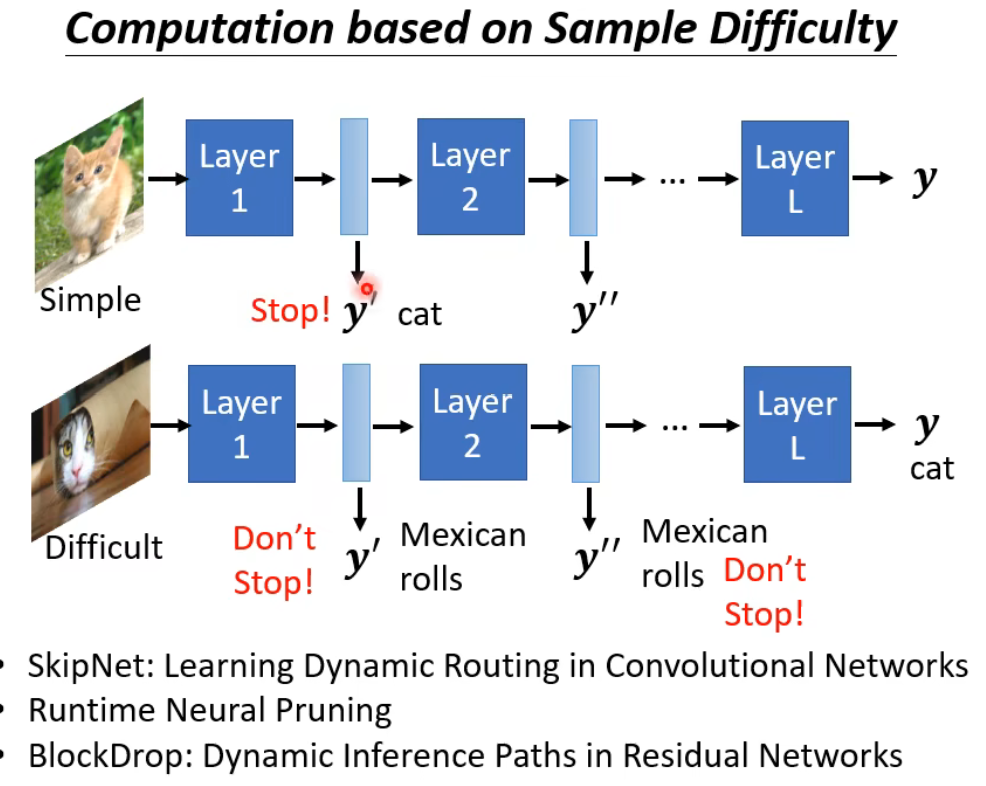
如下图,当识别的图片 比较简单时,我们或许只需要2层卷积层就能够识别出来,而对于比较难识别的,我们就希望他卷积完所有层再进行输出。为此,我们希望模型能够动态计算。
好啦,今天学到这,下期的故事下期聊,再见
![]()